Die Branche hat sich auf die Beschleunigung der Matrixmultiplikation konzentriert, aber die Verbesserung des Suchalgorithmus kann zu einer ernsthafteren Leistungssteigerung führen

In den letzten Jahren war die Computerindustrie damit beschäftigt, die für künstliche neuronale Netze erforderlichen Berechnungen zu beschleunigen - sowohl für das Training als auch um Schlussfolgerungen aus ihrer Arbeit zu ziehen. Insbesondere wurde viel Aufwand in die Entwicklung von Spezialeisen gesteckt, an dem diese Berechnungen durchgeführt werden können. Google hat die
Tensor Processing Unit (TPU) entwickelt, die erstmals 2016 der Öffentlichkeit vorgestellt wurde. Nvidia führte später die
V100- Grafikverarbeitungseinheit ein und beschrieb sie als einen Chip, der speziell für das Training und die Verwendung von KI sowie für andere Hochleistungsrechneranforderungen entwickelt wurde. Voller anderer Startups, die sich auf andere Arten von
Hardwarebeschleunigern konzentrieren .
Vielleicht machen sie alle einen großen Fehler.
Diese Idee wurde in der
Arbeit geäußert, die Mitte März auf der Website arXiv erschien. Darin argumentieren die Autoren
Beidi Chen ,
Tarun Medini und
Anshumali Srivastava von der Rice University, dass möglicherweise die für den Betrieb neuronaler Netze entwickelte Spezialausrüstung für den falschen Algorithmus optimiert wird.
Die Arbeit neuronaler Netze hängt normalerweise davon ab, wie schnell das Gerät die Multiplikation der Matrizen durchführen kann, mit denen die Ausgangsparameter jedes künstlichen Neutrons - seine „Aktivierung“ - für einen bestimmten Satz von Eingabewerten bestimmt werden. Matrizen werden verwendet, weil jeder Eingabewert für ein Neuron mit dem entsprechenden Gewichtungsparameter multipliziert wird und dann alle summiert werden - und diese Multiplikation mit Addition ist die Grundoperation der Matrixmultiplikation.
Forscher der Rice University stellten wie einige andere Wissenschaftler fest, dass die Aktivierung vieler Neuronen in einer bestimmten Schicht des neuronalen Netzwerks zu gering ist und den von den nachfolgenden Schichten berechneten Ausgabewert nicht beeinflusst. Wenn Sie also wissen, was diese Neuronen sind, können Sie sie einfach ignorieren.
Es scheint, dass der einzige Weg, um herauszufinden, welche Neuronen in einer Schicht nicht aktiviert sind, darin besteht, zuerst alle Operationen der Matrixmultiplikation für diese Schicht durchzuführen. Die Forscher erkannten jedoch, dass Sie sich tatsächlich für diesen effizienteren Weg entscheiden können, wenn Sie das Problem aus einem anderen Blickwinkel betrachten. "Wir betrachten dieses Problem als Lösung für das Suchproblem", sagt Srivastava.
Das heißt, anstatt Matrixmultiplikationen zu berechnen und zu prüfen, welche Neuronen für eine bestimmte Eingabe aktiviert wurden, können Sie nur sehen, welche Art von Neuronen sich in der Datenbank befinden. Der Vorteil dieses Ansatzes bei dem Problem besteht darin, dass Sie eine allgemeine Strategie verwenden können, die von Informatikern seit langem verbessert wurde, um die Suche nach Daten in der Datenbank zu beschleunigen: Hashing.
Mit Hashing können Sie schnell überprüfen, ob die Datenbanktabelle einen Wert enthält, ohne jede Zeile in einer Zeile durchgehen zu müssen. Sie verwenden einen Hash, der einfach berechnet werden kann, indem Sie eine Hash-Funktion auf den gewünschten Wert anwenden und angeben, wo dieser Wert in der Datenbank gespeichert werden soll. Dann können Sie nur einen Ort überprüfen, um herauszufinden, ob dieser Wert dort gespeichert ist.
Ähnliches haben die Forscher für Berechnungen im Zusammenhang mit neuronalen Netzen getan. Das folgende Beispiel soll ihren Ansatz veranschaulichen:
Angenommen, wir haben ein neuronales Netzwerk erstellt, das die handschriftliche Eingabe von Zahlen erkennt. Angenommen, die Eingabe besteht aus grauen Pixeln in einem 16x16-Array, dh insgesamt 256 Zahlen. Wir geben diese Daten an eine verborgene Schicht von 512 Neuronen weiter, deren Aktivierungsergebnisse von der Ausgangsschicht von 10 Neuronen gespeist werden, eine für jede der möglichen Zahlen.
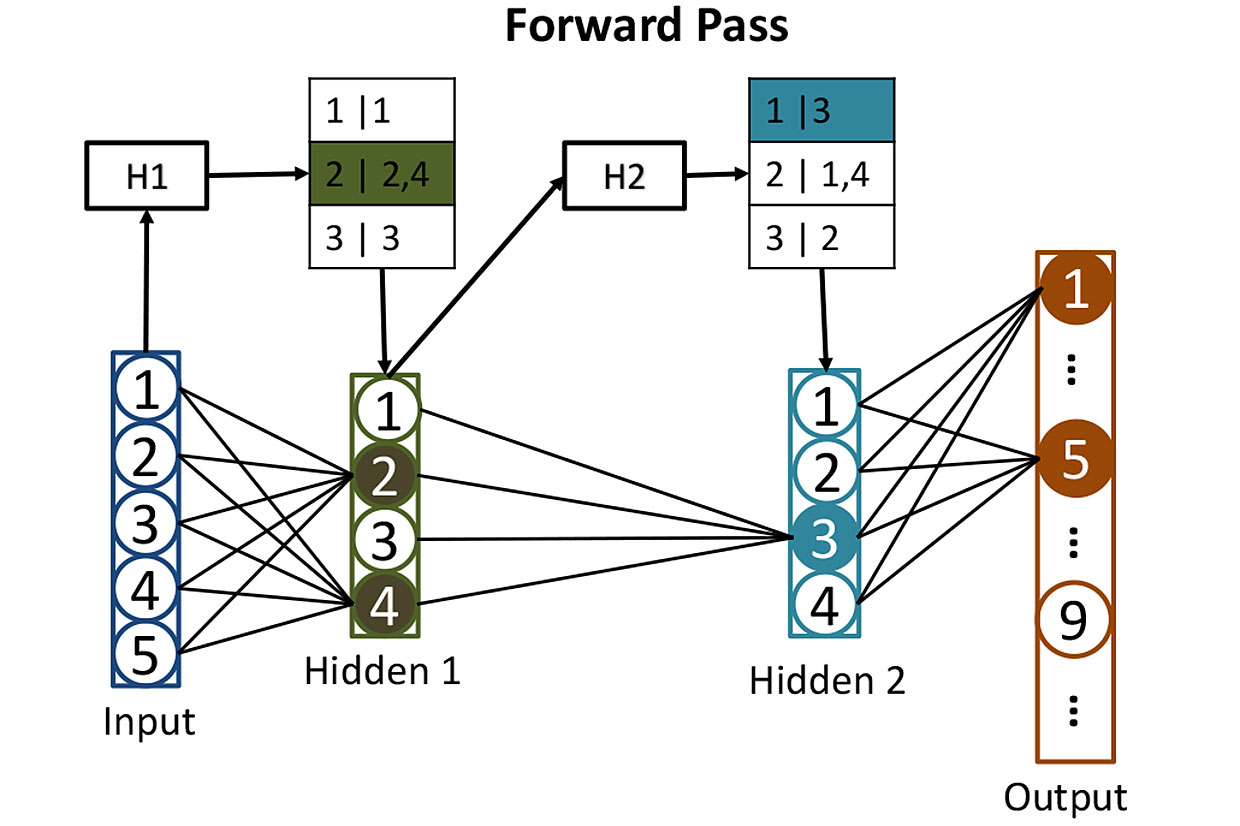 Tabellen aus Netzwerken: Bevor wir die Aktivierung von Neuronen in verborgenen Schichten berechnen, verwenden wir Hashes, um zu bestimmen, welche Neuronen aktiviert werden. Hier wird der Hash der Eingabewerte H1 verwendet, um nach den entsprechenden Neuronen in der ersten verborgenen Schicht zu suchen - in diesem Fall sind es die Neuronen 2 und 4. Der zweite Hash H2 zeigt, welche Neuronen aus der zweiten verborgenen Schicht dazu beitragen. Eine solche Strategie reduziert die Anzahl der Aktivierungen, die berechnet werden müssen.
Tabellen aus Netzwerken: Bevor wir die Aktivierung von Neuronen in verborgenen Schichten berechnen, verwenden wir Hashes, um zu bestimmen, welche Neuronen aktiviert werden. Hier wird der Hash der Eingabewerte H1 verwendet, um nach den entsprechenden Neuronen in der ersten verborgenen Schicht zu suchen - in diesem Fall sind es die Neuronen 2 und 4. Der zweite Hash H2 zeigt, welche Neuronen aus der zweiten verborgenen Schicht dazu beitragen. Eine solche Strategie reduziert die Anzahl der Aktivierungen, die berechnet werden müssen.Es ist ziemlich schwierig, ein solches Netzwerk zu trainieren, aber lassen Sie uns diesen Moment aus und stellen Sie sich vor, dass wir bereits alle Gewichte jedes Neurons so angepasst haben, dass das neuronale Netzwerk handgeschriebene Zahlen perfekt erkennt. Wenn eine leserlich geschriebene Zahl an ihrem Eingang ankommt, liegt die Aktivierung eines der Ausgangsneuronen (entsprechend dieser Zahl) nahe bei 1. Die Aktivierung der anderen neun liegt nahe bei 0. Klassischerweise erfordert der Betrieb eines solchen Netzwerks eine Matrixmultiplikation für jedes der 512 versteckten Neuronen. und noch eine für jedes Wochenende - was uns viele Multiplikationen gibt.
Forscher verfolgen einen anderen Ansatz. Der erste Schritt besteht darin, die Gewichte jedes der 512 Neuronen in der verborgenen Schicht unter Verwendung von "lokalitätsempfindlichem Hashing" zu hashen. Eine der Eigenschaften besteht darin, dass ähnliche Eingabedaten ähnliche Hashwerte ergeben. Sie können dann Neuronen mit ähnlichen Hashes gruppieren, was bedeutet, dass diese Neuronen ähnliche Gewichtssätze haben. Jede Gruppe kann in einer Datenbank gespeichert und durch den Hash der Eingabewerte bestimmt werden, die zur Aktivierung dieser Gruppe von Neuronen führen.
Nach all dem Hashing stellt sich heraus, dass es einfach ist zu bestimmen, welches der versteckten Neuronen durch eine neue Eingabe aktiviert wird. Sie müssen 256 Eingabewerte über einfach zu berechnende Hash-Funktionen ausführen und das Ergebnis verwenden, um die Datenbank nach den Neuronen zu durchsuchen, die aktiviert werden. Auf diese Weise müssen Sie die Aktivierungswerte für nur wenige wichtige Neuronen berechnen. Es ist nicht notwendig, die Aktivierung aller anderen Neuronen in der Schicht zu berechnen, um herauszufinden, dass sie nicht zum Ergebnis beitragen.
Die Eingabe eines solchen neuronalen Datennetzwerks kann als Ausführung einer Suchabfrage in einer Datenbank dargestellt werden, die nach allen Neuronen fragt, die durch direktes Zählen aktiviert würden. Sie erhalten die Antwort schnell, da Sie zur Suche Hashes verwenden. Und dann können Sie einfach die Aktivierung einer kleinen Anzahl von Neuronen berechnen, die wirklich wichtig sind.
Forscher haben diese Technik, die sie SLIDE (Sub-LInear Deep Learning Engine) nannten, verwendet, um ein neuronales Netzwerk zu trainieren - für einen Prozess, der mehr Rechenanforderungen hat als für den beabsichtigten Zweck. Anschließend verglichen sie die Leistung des Lernalgorithmus mit einem traditionelleren Ansatz unter Verwendung einer leistungsstarken GPU - insbesondere der Nvidia V100-GPU. Als Ergebnis erhielten sie etwas Erstaunliches: "Unsere Ergebnisse zeigen, dass die CPU SLIDE-Technologie im Durchschnitt um Größenordnungen schneller arbeiten kann als die bestmögliche Alternative, die auf der besten Ausrüstung und mit jeder Genauigkeit implementiert ist."
Es ist noch zu früh, um Rückschlüsse darauf zu ziehen, ob diese Ergebnisse (die von Experten noch nicht bewertet wurden) den Tests standhalten und ob sie die Chiphersteller dazu zwingen werden, die Entwicklung spezieller Geräte für Deep Learning anders zu betrachten. Die Arbeit betont jedoch definitiv die Gefahr des Mitreißens einer bestimmten Eisensorte in Fällen, in denen die Möglichkeit eines neuen und besseren Algorithmus für den Betrieb neuronaler Netze besteht.