Hallo an alle. Bis zum Start des Kurses
"Sicherheit von Informationssystemen" bleibt immer weniger Zeit, daher teilen wir auch heute noch Veröffentlichungen, die dem Start dieses Kurses gewidmet sind. Diese Veröffentlichung ist übrigens eine Fortsetzung dieser beiden Artikel:
„Grundlagen von JavaScript-Engines: Allgemeine Formulare und Inline-Caching. Teil 1 " ,
" Grundlagen von JavaScript-Engines: Allgemeine Formulare und Inline-Caching. Teil 2 " .
Der Artikel beschreibt die wichtigsten Grundlagen. Sie sind allen JavaScript-Engines gemeinsam und nicht nur dem
V8 , an dem die Autoren arbeiten (
Benedict und
Matthias ). Als JavaScript-Entwickler kann ich sagen, dass ein tieferes Verständnis der Funktionsweise der JavaScript-Engine Ihnen dabei hilft, effizienten Code zu schreiben.

In einem
früheren Artikel haben wir erläutert, wie JavaScript-Engines den Zugriff auf Objekte und Arrays mithilfe von Formularen und Inline-Caches optimieren. In diesem Artikel werden wir uns mit der Optimierung von Pipeline-Kompromissen und der Beschleunigung des Zugriffs auf Prototyp-Eigenschaften befassen.
Hinweis: Wenn Sie lieber Präsentationen als Artikel lesen möchten, sehen Sie sich dieses Video an . Wenn nicht, überspringen Sie es und lesen Sie weiter.
Optimierungs- und KompromissstufenDas letzte Mal haben wir herausgefunden, dass alle modernen JavaScript-Engines tatsächlich dieselbe Pipeline haben:
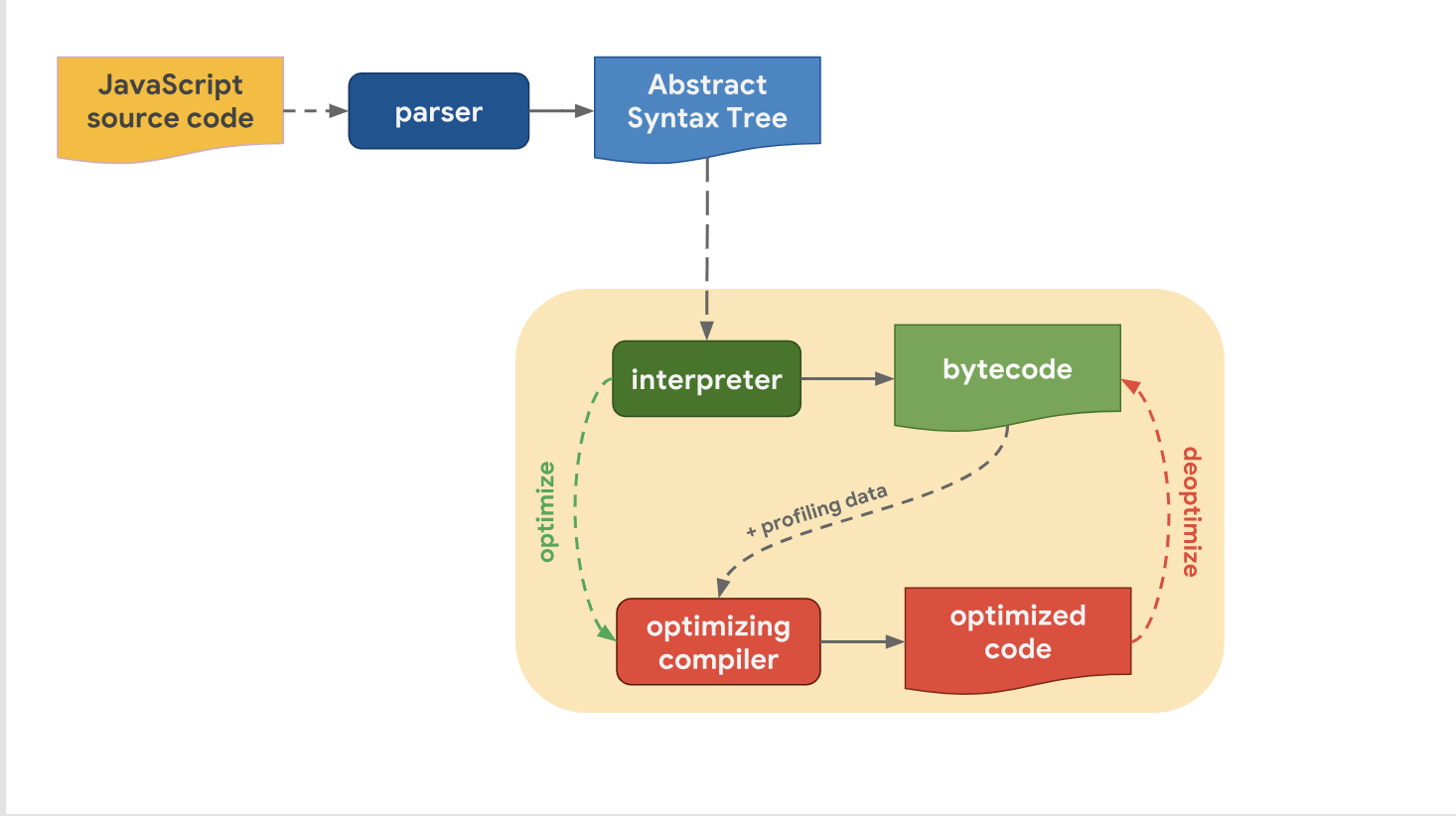
Wir haben auch festgestellt, dass es trotz der Tatsache, dass hochrangige Pipelines von Motor zu Motor ähnlich aufgebaut sind, einen Unterschied in der Optimierungspipeline gibt. Warum ist das so? Warum haben einige Motoren mehr Optimierungsstufen als andere? Es geht darum, einen Kompromiss zwischen einem schnellen Übergang in die Phase der Codeausführung oder einem etwas längeren Zeitaufwand für die Ausführung des Codes mit optimaler Leistung einzugehen.

Der Interpreter kann schnell Bytecode generieren, aber Bytecode allein ist in Bezug auf die Geschwindigkeit nicht effizient genug. Die Einbeziehung eines optimierenden Compilers in diesen Prozess nimmt eine gewisse Zeit in Anspruch, ermöglicht jedoch einen effizienteren Maschinencode.
Werfen wir einen Blick darauf, wie der V8 damit umgeht. Denken Sie daran, dass der Interpreter in V8 als Ignition bezeichnet wird und als der schnellste Interpreter unter den vorhandenen Engines gilt (in Bezug auf die Geschwindigkeit der Ausführung von Rohbytecode). Der Optimierungs-Compiler in V8 heißt TurboFan und generiert hochoptimierten Maschinencode.

Der Kompromiss zwischen Startverzögerung und Ausführungsgeschwindigkeit ist der Grund, warum einige JavaScript-Engines es vorziehen, zwischen den Schritten zusätzliche Optimierungsstufen hinzuzufügen. Zum Beispiel fügt SpiderMonkey eine Baseline-Ebene zwischen seinem Interpreter und dem vollständig optimierenden IonMonkey-Compiler hinzu:
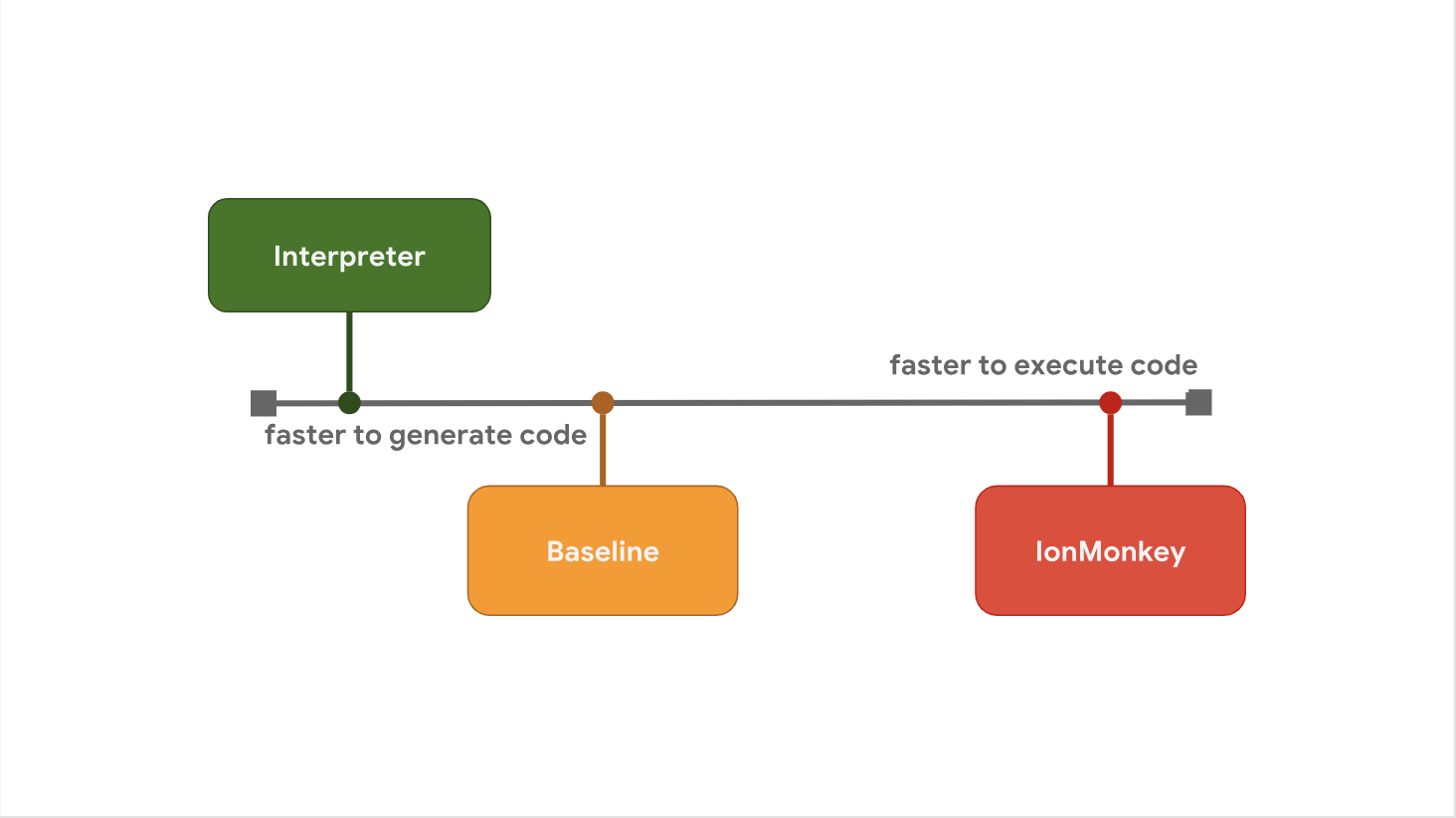
Der Interpreter generiert schnell Bytecode, aber der Bytecode selbst ist relativ langsam. Baseline generiert Code etwas länger, bietet jedoch zur Laufzeit eine verbesserte Leistung. Schließlich verbringt der optimierende Compiler IonMonkey die meiste Zeit damit, Maschinencode zu generieren, aber dieser Code ist äußerst effizient.
Schauen wir uns ein konkretes Beispiel an und sehen, wie die Pipelines verschiedener Motoren mit diesem Problem umgehen. Hier in der Hot-Loop wird der gleiche Code oft wiederholt.
let result = 0; for (let i = 0; i < 4242424242; ++i) { result += i; } console.log(result);
V8 startet mit dem Starten des Bytecodes im Ignition-Interpreter. Irgendwann stellt die Engine fest, dass der Code heiß ist, und startet die TurboFan-Schnittstelle, die Profildaten integriert und eine grundlegende Maschinendarstellung des Codes erstellt. Anschließend wird es zur weiteren Verbesserung in einem anderen Thread an den TurboFan-Optimierer gesendet.

Während der Optimierung führt V8 weiterhin Code in Ignition aus. Irgendwann, wenn das Optimierungsprogramm fertig ist und wir ausführbaren Maschinencode erhalten haben, geht es sofort zur Ausführungsphase über.
SpyderMonkey startet auch die Bytecode-Ausführung im Interpreter. Es gibt jedoch eine zusätzliche Baseline-Ebene, was bedeutet, dass der Hot-Code zuerst dorthin gesendet wird. Der Baseline-Compiler generiert Baseline-Code im Hauptthread und setzt die Ausführung am Ende seiner Generierung fort.

Wenn der Baseline-Code seit einiger Zeit ausgeführt wird, startet SpiderMonkey schließlich die IonMonkey-Schnittstelle (IonMonkey-Frontend) und führt den Optimierer aus. Der Vorgang ist V8 sehr ähnlich. All dies funktioniert gleichzeitig in Baseline weiter, während IonMonkey sich mit der Optimierung befasst. Wenn der Optimierer seine Arbeit beendet hat, wird der optimierte Code anstelle des Baseline-Codes ausgeführt.
Die Architektur von Chakra ist SpiderMonkey sehr ähnlich, aber Chakra versucht, mehr Prozesse gleichzeitig auszuführen, um zu vermeiden, dass der Haupt-Thread blockiert wird. Anstatt einen Teil des Compilers im Hauptthread auszuführen, kopiert Chakra den Bytecode und die Profildaten, die der Compiler benötigt, und sendet sie an den dedizierten Compilerprozess.

Wenn der generierte Code fertig ist, führt die Engine diesen SimpleJIT-Code anstelle des Bytecodes aus. Das gleiche passiert mit FullJIT. Der Vorteil dieses Ansatzes besteht darin, dass die beim Kopieren auftretende Pause normalerweise viel kürzer ist als beim Starten eines vollwertigen Compilers (Frontend). Andererseits hat dieser Ansatz einen Nachteil. Es liegt in der Tatsache, dass die Kopierheuristik einige Informationen überspringen kann, die für die Optimierung erforderlich sind. Wir können also sagen, dass die Qualität des Codes in gewissem Maße beeinträchtigt wird, um die Arbeit zu beschleunigen.
In JavaScriptCore arbeiten alle optimierenden Compiler vollständig parallel zur grundlegenden Ausführung von JavaScript. Es gibt keine Kopierphase. Stattdessen beginnt der Hauptthread einfach mit dem Kompilieren in einem anderen Thread. Compiler verwenden dann ein komplexes Sperrschema, um auf Profildaten vom Hauptthread zuzugreifen.

Der Vorteil dieses Ansatzes besteht darin, dass die Menge an Müll reduziert wird, die nach der Optimierung im Hauptthread auftritt. Der Nachteil dieses Ansatzes besteht darin, dass komplexe Multithreading-Probleme und einige Blockierungskosten für verschiedene Vorgänge gelöst werden müssen.
Wir haben über die Kompromisse zwischen der schnellen Codegenerierung bei laufendem Interpreter und der schnellen Codegenerierung mit dem optimierenden Compiler gesprochen. Es gibt jedoch noch einen Kompromiss, der die Verwendung von Speicher betrifft. Um dies zu veranschaulichen, habe ich ein einfaches JavaScript-Programm geschrieben, das zwei Zahlen hinzufügt.
function add(x, y) { return x + y; } add(1, 2);
Sehen Sie sich den Bytecode an, der vom Zündinterpreter in V8 für die Add-Funktion generiert wird.
StackCheck Ldar a1 Add a0, [0] Return
Machen Sie sich keine Sorgen um den Bytecode, Sie müssen ihn nicht lesen können. Hierbei ist darauf zu achten, dass es
nur 4 Anweisungen enthält.
Wenn der Code heiß wird, generiert TurboFan hochoptimierten Maschinencode, der im Folgenden dargestellt wird:
leaq rcx,[rip+0x0] movq rcx,[rcx-0x37] testb [rcx+0xf],0x1 jnz CompileLazyDeoptimizedCode push rbp movq rbp,rsp push rsi push rdi cmpq rsp,[r13+0xe88] jna StackOverflow movq rax,[rbp+0x18] test al,0x1 jnz Deoptimize movq rbx,[rbp+0x10] testb rbx,0x1 jnz Deoptimize movq rdx,rbx shrq rdx, 32 movq rcx,rax shrq rcx, 32 addl rdx,rcx jo Deoptimize shlq rdx, 32 movq rax,rdx movq rsp,rbp pop rbp ret 0x18
Es gibt wirklich viele Teams hier, besonders im Vergleich zu den vier, die wir im Bytecode gesehen haben. Im Allgemeinen ist der Bytecode viel umfangreicher als der Maschinencode und insbesondere der optimierte Maschinencode. Der Bytecode hingegen wird vom Interpreter ausgeführt, während der optimierte Code direkt vom Prozessor ausgeführt werden kann.
Dies ist einer der Gründe, warum JavaScript-Engines nicht einfach „alles optimieren“. Wie wir bereits gesehen haben, nimmt das Generieren von optimiertem Maschinencode viel Zeit in Anspruch und erfordert daher mehr Speicher.
 Zusammenfassend:
Zusammenfassend: Der Grund, warum JavaScript-Engines unterschiedliche Optimierungsstufen aufweisen, besteht darin, einen Kompromiss zwischen der schnellen Codegenerierung mit dem Interpreter und der schnellen Codegenerierung mit dem optimierenden Compiler zu finden. Durch Hinzufügen weiterer Optimierungsstufen können Sie fundiertere Entscheidungen treffen, basierend auf den Kosten für zusätzliche Komplexität und Overhead während der Ausführung. Darüber hinaus besteht ein Kompromiss zwischen Optimierungsgrad und Speichernutzung. Aus diesem Grund versuchen JavaScript-Engines, nur Hot-Funktionen zu optimieren.
Optimieren Sie den Zugriff auf PrototypeneigenschaftenDas letzte Mal haben wir darüber gesprochen, wie JavaScript-Engines das Laden von Objekteigenschaften mithilfe von Formularen und Inline-Caches optimieren. Denken Sie daran, dass die Engines die Formen von Objekten getrennt von den Werten des Objekts speichern.
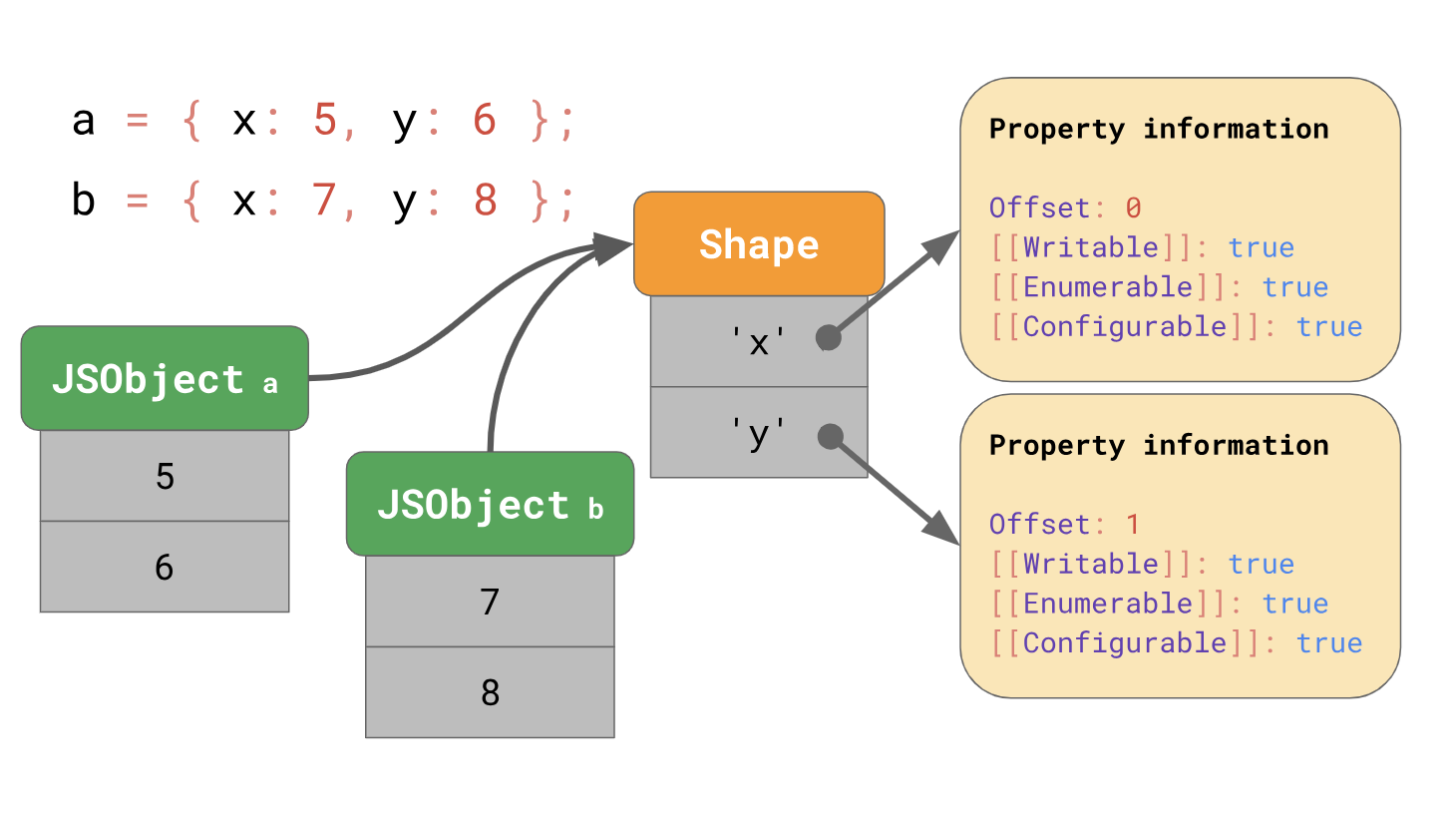
Mit Formularen können Sie die Optimierung mithilfe von Inline-Caches oder abgekürzten ICs verwenden. Bei der Zusammenarbeit können Formulare und ICs den wiederholten Zugriff auf Eigenschaften an derselben Stelle in Ihrem Code beschleunigen.
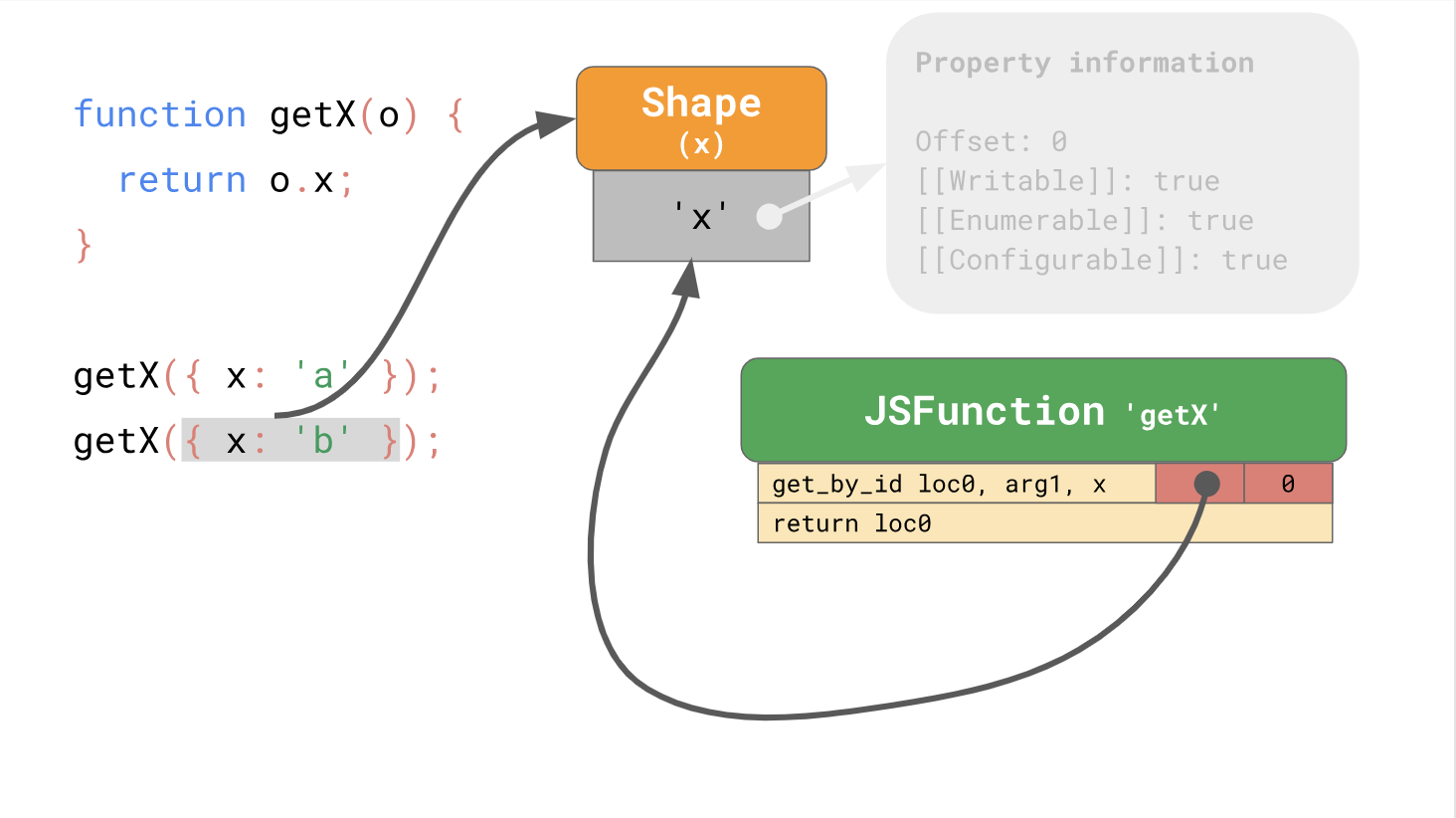
So ging der erste Teil der Veröffentlichung zu Ende, und im
zweiten Teil finden Sie Informationen zu Klassen und Prototypenprogrammierung. Traditionell warten wir auf Ihre Kommentare und stürmischen Diskussionen und laden Sie zu einem
Tag der
offenen Tür in den Kurs "Sicherheit von Informationssystemen" ein.