In der Regel verwendet Nginx kommerzielle Produkte oder Open-Source-Alternativen wie Prometheus + Grafana, um die Leistung von Nginx zu überwachen und zu analysieren. Dies ist eine gute Option für die Überwachung oder Echtzeitanalyse, jedoch nicht zu praktisch für die historische Analyse. Bei jeder gängigen Ressource wächst die Datenmenge aus Nginx-Protokollen schnell, und es ist logisch, etwas Spezialisierteres zu verwenden, um eine große Datenmenge zu analysieren.
In diesem Artikel werde ich Ihnen erklären, wie Sie mit Athena Protokolle am Beispiel von Nginx analysieren und wie Sie aus diesen Daten mithilfe des Open-Source-Frameworks cube.js ein analytisches Dashboard kompilieren. Hier ist die komplette Lösungsarchitektur:

TL: DR;
Link zum fertigen Dashboard .
Wir verwenden Fluentd , um Informationen zu sammeln, AWS Kinesis Data Firehose und AWS Glue für die Verarbeitung und AWS S3 für die Speicherung. Mit diesem Bundle können Sie nicht nur Nginx-Protokolle, sondern auch andere Ereignisse sowie Protokolle anderer Dienste speichern. Sie können einige Teile durch ähnliche Teile für Ihren Stapel ersetzen, z. B. können Sie Protokolle direkt von nginx unter Umgehung von fluentd in kinesis schreiben oder logstash verwenden, um dies zu tun.
Sammeln von Nginx-Protokollen
Standardmäßig sehen Nginx-Protokolle ungefähr so aus:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
Sie können analysiert werden, aber es ist viel einfacher, die Nginx-Konfiguration so zu korrigieren, dass Protokolle in JSON angezeigt werden:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
S3 zur Aufbewahrung
Zum Speichern der Protokolle verwenden wir S3. Auf diese Weise können Sie die Protokolle an einem Ort speichern und analysieren, da Athena direkt mit Daten in S3 arbeiten kann. Später in diesem Artikel werde ich Ihnen erklären, wie Sie die Protokolle richtig falten und verarbeiten, aber zuerst benötigen wir in S3 einen sauberen Eimer, in dem nichts anderes gespeichert wird. Es lohnt sich, im Voraus zu überlegen, in welcher Region Sie den Eimer erstellen, da Athena nicht in allen Regionen verfügbar ist.
Erstellen Sie ein Diagramm in der Athena-Konsole
Erstellen Sie in Athena eine Tabelle für Protokolle. Es wird sowohl zum Schreiben als auch zum Lesen benötigt, wenn Sie Kinesis Firehose verwenden möchten. Öffnen Sie die Athena-Konsole und erstellen Sie eine Tabelle:
SQL-Tabellenerstellung CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
Erstellen Sie einen Kinesis Firehose Stream
Kinesis Firehose schreibt die von Nginx empfangenen Daten im ausgewählten Format in S3, unterteilt in Verzeichnisse im Format JJJJ / MM / TT / HH. Dies ist nützlich beim Lesen von Daten. Sie können natürlich von fluentd direkt in S3 schreiben, aber in diesem Fall müssen Sie JSON schreiben, was aufgrund der großen Dateigröße ineffizient ist. Bei Verwendung von PrestoDB oder Athena ist JSON außerdem das langsamste Datenformat. Öffnen Sie also die Kinesis Firehose-Konsole, klicken Sie auf "Lieferstrom erstellen" und wählen Sie "Direktes PUT" im Feld "Lieferung" aus:
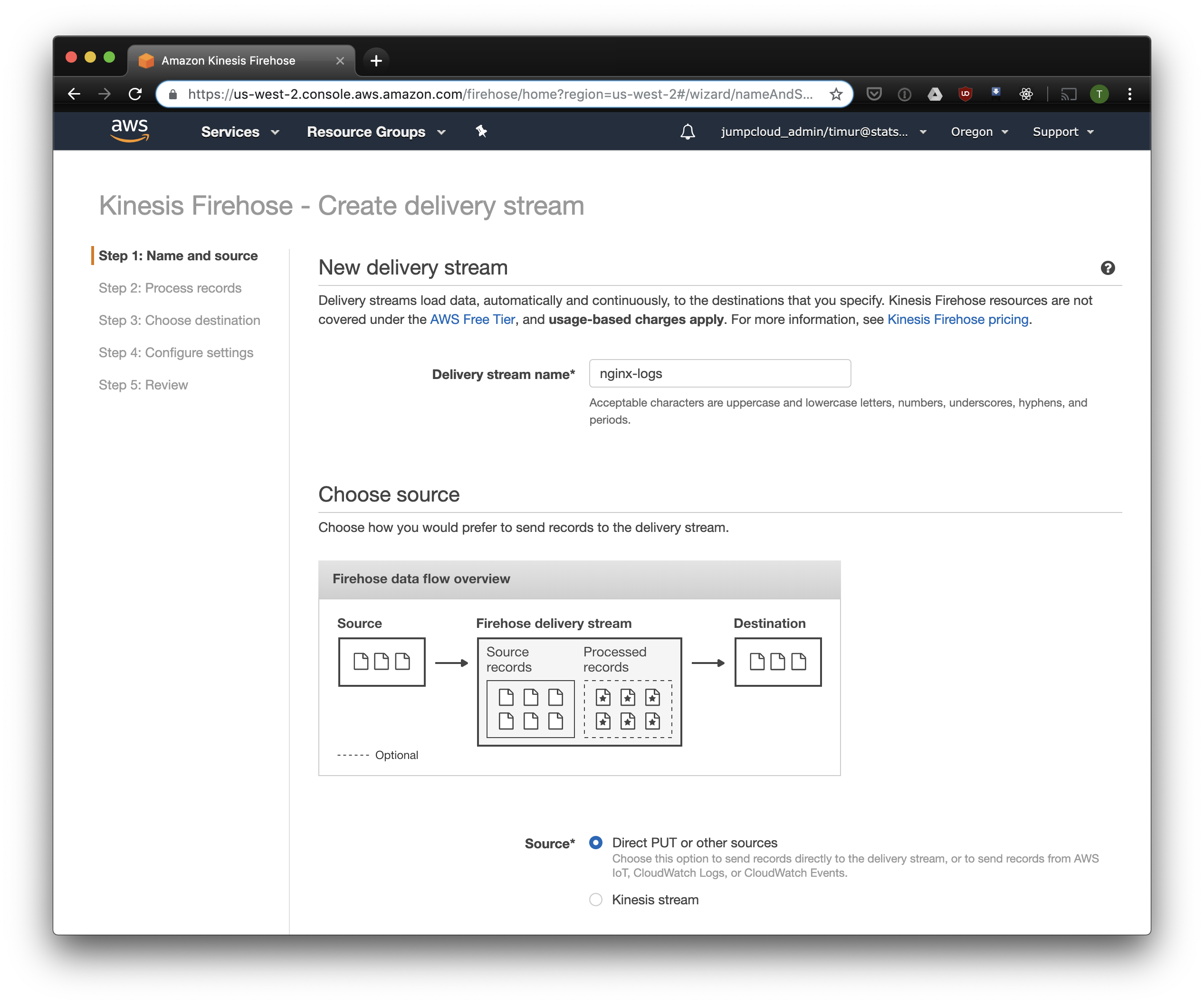
Wählen Sie auf der nächsten Registerkarte "Konvertierung des Aufnahmeformats" - "Aktiviert" und wählen Sie "Apache ORC" als Format für die Aufnahme. Laut einigen Owen O'Malley ist dies das optimale Format für PrestoDB und Athena. Als Diagramm geben wir die Tabelle an, die wir oben erstellt haben. Bitte beachten Sie, dass Sie in Kinesis einen beliebigen S3-Speicherort angeben können. In der Tabelle wird nur das Schema verwendet. Wenn Sie jedoch einen anderen S3-Speicherort angeben, funktioniert das Lesen dieser Datensätze aus dieser Tabelle nicht.
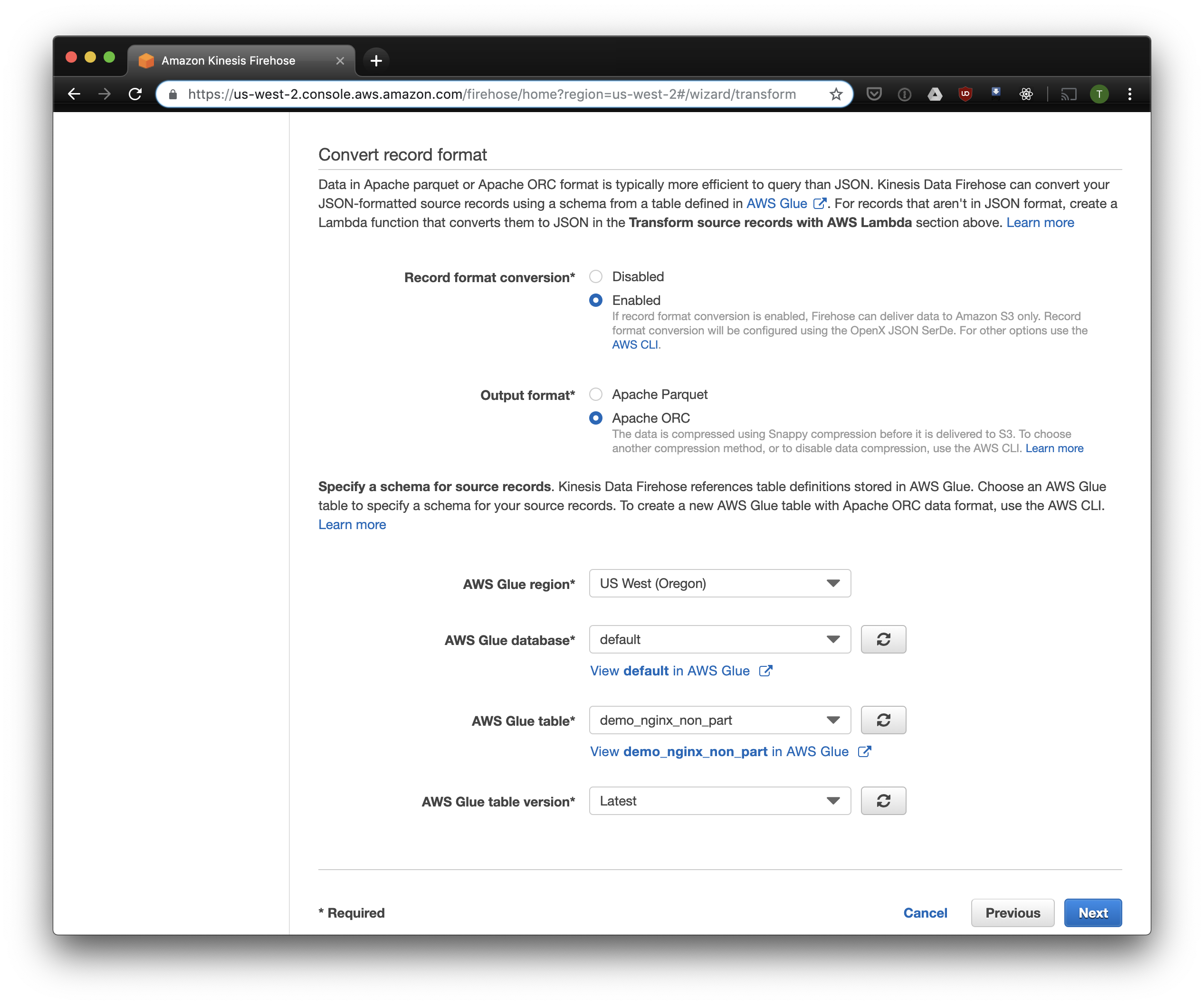
Wir wählen S3 als Speicher und den zuvor erstellten Bucket. Aws Glue Crawler, über den ich etwas später sprechen werde, weiß nicht, wie man mit Präfixen im S3-Bucket arbeitet, daher ist es wichtig, ihn leer zu lassen.

Die restlichen Optionen können abhängig von Ihrer Last geändert werden. Normalerweise verwende ich die Standardoptionen. Beachten Sie, dass die S3-Komprimierung nicht verfügbar ist, ORC jedoch standardmäßig die native Komprimierung verwendet.
Fließend
Nachdem wir die Speicherung und den Empfang von Protokollen konfiguriert haben, müssen Sie das Senden konfigurieren. Wir werden Fluentd verwenden, weil ich Ruby liebe, aber Sie können Logstash verwenden oder Protokolle direkt an kinesis senden. Sie können den Fluentd-Server auf verschiedene Arten starten. Ich werde über Docker sprechen, da dies einfach und bequem ist.
Zunächst benötigen wir die Konfigurationsdatei fluent.conf. Erstellen Sie es und fügen Sie die Quelle hinzu:
tippen Sie vorwärts
Port 24224
binden 0.0.0.0
Jetzt können Sie den Fluentd-Server starten. Wenn Sie eine erweiterte Konfiguration benötigen, bietet der Docker Hub eine detaillierte Anleitung, einschließlich der Zusammenstellung Ihres Images.
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
Diese Konfiguration verwendet den Pfad /fluentd/log um Protokolle vor dem Senden zwischenzuspeichern. Sie können darauf verzichten, aber wenn Sie neu starten, können Sie alles verlieren, was durch übermäßige Arbeit zwischengespeichert wird. Es kann auch jeder Port verwendet werden. 24224 ist der Standard-Fluentd-Port.
Nachdem Fluentd ausgeführt wird, können wir dort Nginx-Protokolle senden. Normalerweise führen wir Nginx in einem Docker-Container aus. In diesem Fall verfügt Docker über einen nativen Protokolltreiber für Fluentd:
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
Wenn Sie Nginx anders ausführen, können Sie die Protokolldateien verwenden. Fluentd verfügt über ein File-Tail-Plugin .
Fügen Sie die oben konfigurierte Protokollanalyse zur Fluent-Konfiguration hinzu:
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
Und Senden von Protokollen an Kinesis mithilfe des Kinesis Firehose-Plugins :
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
Athena
Wenn Sie alles richtig konfiguriert haben, sollten Sie nach einer Weile (standardmäßig schreibt Kinesis die empfangenen Daten alle 10 Minuten) die Protokolldateien in S3 sehen. Im Menü "Überwachung" von Kinesis Firehose können Sie sehen, wie viele Daten in S3 geschrieben wurden, sowie Fehler. Vergessen Sie nicht, für die Kinesis-Rolle Schreibzugriff auf den S3-Bucket zu gewähren. Wenn Kinesis etwas nicht analysieren konnte, fügt er Fehler in denselben Bucket ein.
Jetzt können Sie die Daten in Athena sehen. Lassen Sie uns einige neue Abfragen finden, bei denen wir Fehler gemacht haben:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
Scannen Sie alle Datensätze für jede Anforderung
Jetzt werden unsere Protokolle in S3 in ORC verarbeitet und gestapelt, komprimiert und zur Analyse bereit. Kinesis Firehose hat sie sogar jede Stunde in Verzeichnisse gestellt. Während die Tabelle nicht partitioniert ist, lädt Athena mit seltenen Ausnahmen Allzeitdaten für jede Abfrage. Dies ist aus zwei Gründen ein großes Problem:
- Die Datenmenge wächst ständig und verlangsamt die Abfragen.
- Athena wird basierend auf der Menge der gescannten Daten mit mindestens 10 MB für jede Anfrage in Rechnung gestellt.
Um dies zu beheben, verwenden wir AWS Glue Crawler, der die Daten in S3 scannt und die Partitionsinformationen im Glue Metastore aufzeichnet. Auf diese Weise können wir Partitionen als Filter für Anforderungen in Athena verwenden und nur die in der Anforderung angegebenen Verzeichnisse scannen.
Passen Sie Amazon Glue Crawler an
Amazon Glue Crawler scannt alle Daten im S3-Bucket und erstellt Partitionstabellen. Erstellen Sie einen Glue Crawler über die AWS Glue-Konsole und fügen Sie den Bucket hinzu, in dem Sie die Daten speichern. Sie können einen Crawler für mehrere Buckets verwenden. In diesem Fall werden Tabellen in der angegebenen Datenbank mit Namen erstellt, die mit den Namen der Buckets übereinstimmen. Wenn Sie diese Daten ständig verwenden möchten, müssen Sie den Startplan für den Crawler an Ihre Anforderungen anpassen. Wir verwenden einen Crawler für alle Tabellen, der stündlich ausgeführt wird.
Partitionierte Tabellen
Nach dem ersten Start des Crawlers sollten die Tabellen für jeden gescannten Bucket in der in den Einstellungen angegebenen Datenbank angezeigt werden. Öffnen Sie die Athena-Konsole und suchen Sie die Tabelle mit den Nginx-Protokollen. Versuchen wir etwas zu lesen:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
Diese Abfrage wählt alle Datensätze aus, die am 8. April 2019 von 6 bis 7 Uhr morgens eingegangen sind. Aber wie viel effektiver ist es, als nur aus einer nicht partitionierten Tabelle zu lesen? Lassen Sie uns dieselben Datensätze herausfinden und auswählen, indem wir sie nach Zeitstempel filtern:
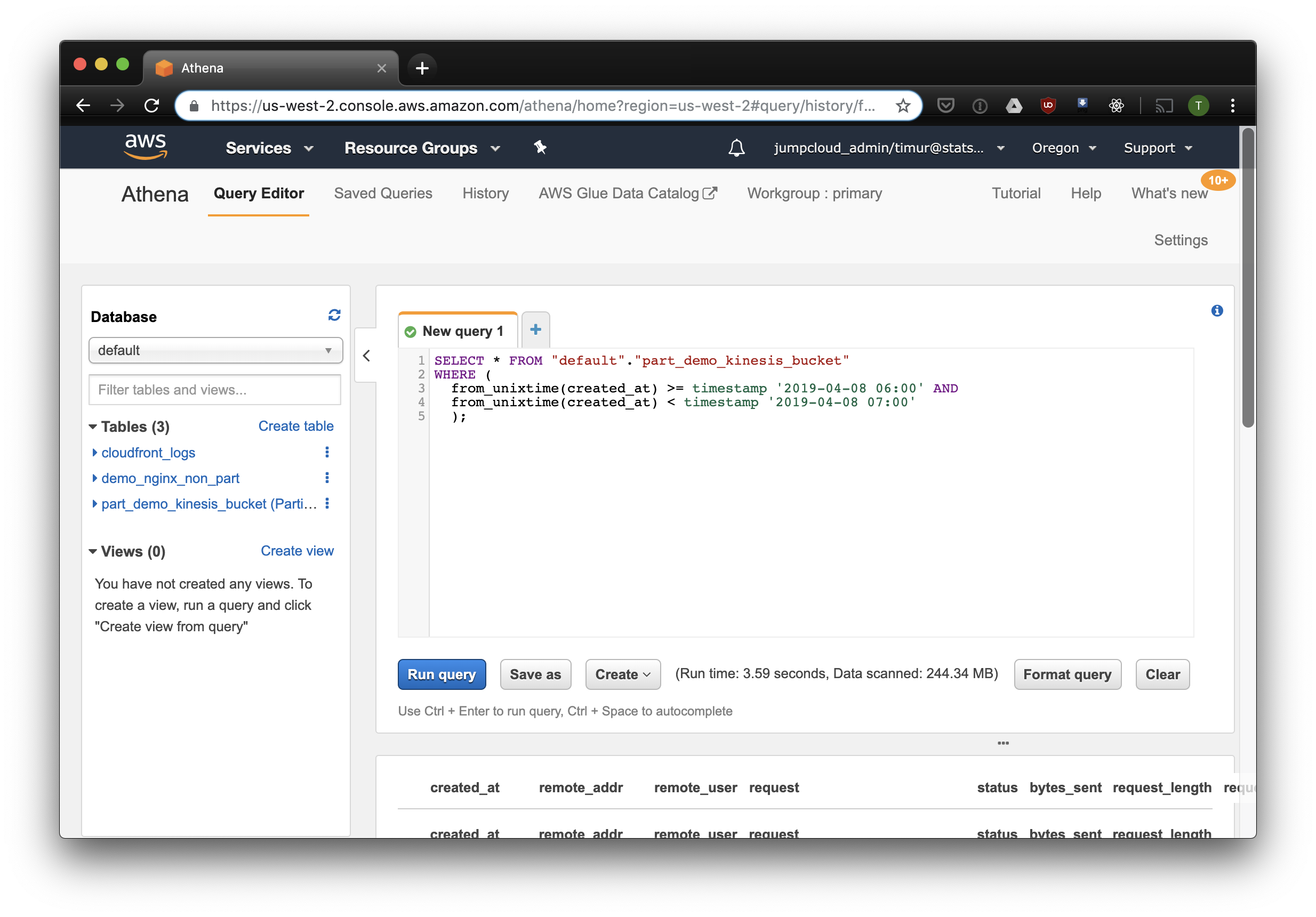
3,59 Sekunden und 244,34 Megabyte Daten im Datensatz, in dem nur eine Woche Protokolle vorhanden sind. Versuchen wir den Filter nach Partitionen:
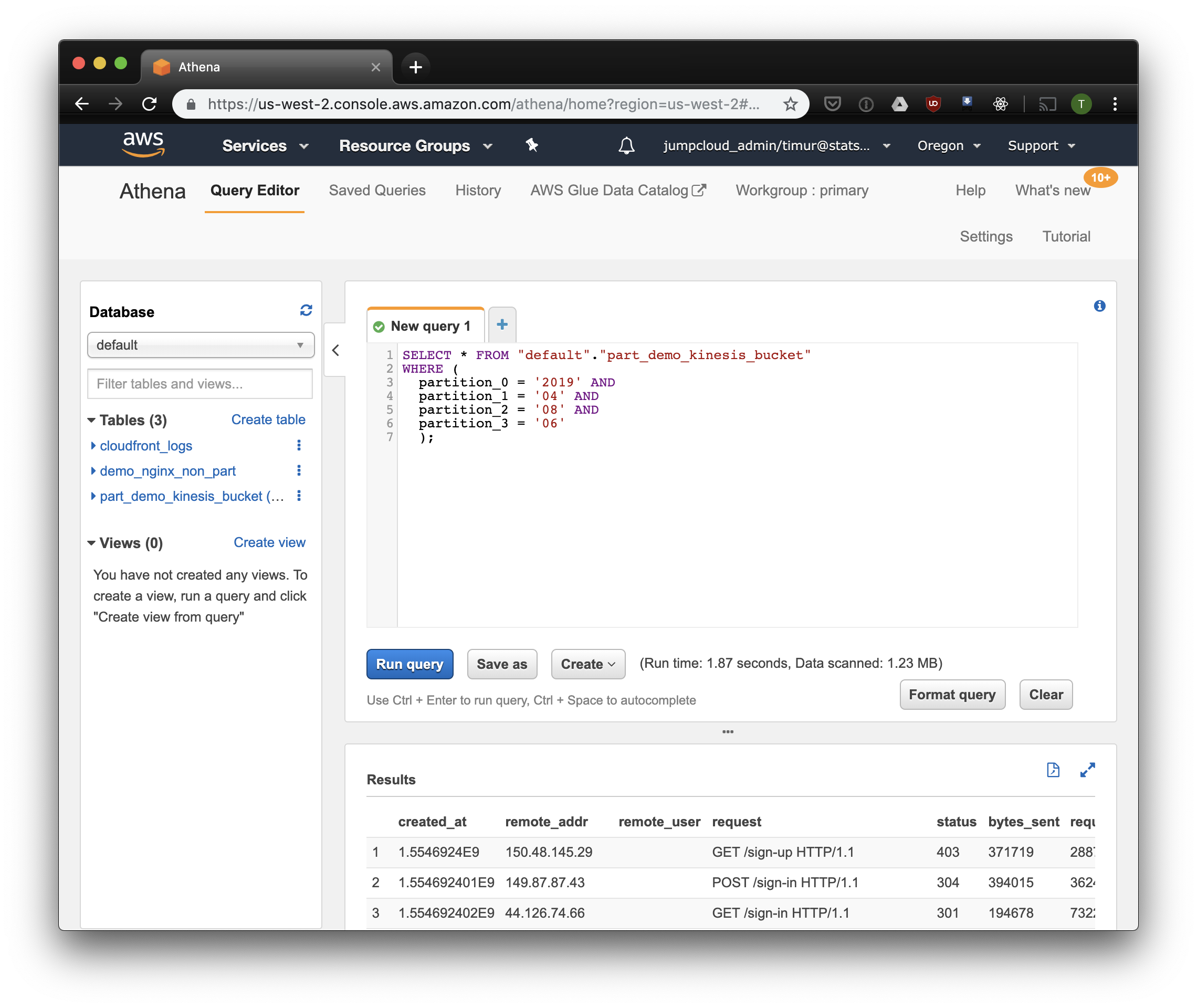
Ein bisschen schneller, aber vor allem - nur 1,23 Megabyte Daten! Es wäre viel billiger, wenn es nicht die Mindestpreise von 10 Megabyte pro Anfrage gäbe. Aber es ist trotzdem viel besser und bei großen Datenmengen wird der Unterschied viel beeindruckender sein.
Erstellen Sie ein Dashboard mit Cube.js.
Um ein Dashboard zu erstellen, verwenden wir das Analyse-Framework Cube.js. Es hat einige Funktionen, aber wir interessieren uns für zwei: die Möglichkeit, automatisch Filter für Partitionen zu verwenden und Daten vorab zu aggregieren. Es verwendet ein in Javascript geschriebenes Datenschema , um SQL zu generieren und eine Datenbankabfrage auszuführen. Von uns muss lediglich angegeben werden, wie der Partitionsfilter im Datenschema verwendet wird.
Lassen Sie uns eine neue Anwendung Cube.js erstellen. Da wir bereits AWS-Stack verwenden, ist es logisch, Lambda für die Bereitstellung zu verwenden. Sie können die Express-Vorlage zur Generierung verwenden, wenn Sie das Backend Cube.js in Heroku oder Docker hosten möchten. Die Dokumentation beschreibt andere Hosting-Methoden .
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
Umgebungsvariablen werden verwendet, um den Zugriff auf die Datenbank in cube.js zu konfigurieren. Der Generator erstellt eine .env-Datei, in der Sie Ihre Schlüssel für Athena angeben können.
Jetzt brauchen wir ein Datenschema, in dem wir angeben, wie unsere Protokolle gespeichert werden. Dort können Sie festlegen, wie Metriken für Dashboards gelesen werden sollen.
Erstellen Logs.js im schema Verzeichnis die Datei Logs.js Hier ist ein Beispiel für ein Datenmodell für Nginx:
Modellcode const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
Hier verwenden wir die Variable FILTER_PARAMS , um eine SQL-Abfrage mit einem Partitionsfilter zu generieren.
Wir geben auch die Metriken und Parameter an, die im Dashboard angezeigt werden sollen, und geben Voraggregationen an. Cube.js erstellt zusätzliche Tabellen mit voraggregierten Daten und aktualisiert die Daten automatisch, sobald sie verfügbar sind. Dies beschleunigt nicht nur Anfragen, sondern reduziert auch die Kosten für die Verwendung von Athena.
Fügen Sie diese Informationen zur Datenschemadatei hinzu:
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
In diesem Modell weisen wir darauf hin, dass die Daten für alle verwendeten Metriken vorab aggregiert und die monatliche Partitionierung verwendet werden muss. Das Partitionieren von Voraggregationen kann die Datenerfassung und -aktualisierung erheblich beschleunigen.
Jetzt können wir ein Dashboard zusammenstellen!
Das Cube.js-Backend bietet eine REST-API und eine Reihe von Client-Bibliotheken für gängige Front-End-Frameworks. Wir werden die React-Version des Clients verwenden, um das Dashboard zu erstellen. Cube.js stellt nur Daten zur Verfügung, daher benötigen wir eine Bibliothek für Visualisierungen. Ich mag Recharts , aber Sie können jede verwenden.
Der Cube.js-Server akzeptiert die Anforderung im JSON-Format , das die erforderlichen Metriken angibt. Um beispielsweise zu berechnen, wie viele Fehler Nginx pro Tag gegeben hat, müssen Sie die folgende Anfrage senden:
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
Installieren Sie den Cube.js-Client und die React-Komponentenbibliothek über NPM:
$ npm i --save @cubejs-client/core @cubejs-client/react
Wir importieren cubejs und QueryRenderer-Komponenten, um die Daten zu entladen und das Dashboard zu sammeln:
Dashboard-Code import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
Dashboard-Quellen sind in CodeSandbox verfügbar.