Vor nicht allzu langer Zeit stieß ich auf eine recht einfache und gleichzeitig interessante Aufgabe: die Implementierung eines schreibgeschützten Terminals in einer Webanwendung. Das Interesse an der Aufgabe wurde durch drei wichtige Aspekte geweckt:
- Unterstützung für grundlegende ANSI-Escape-Sequenzen
- Unterstützung für mindestens 50.000 Datenleitungen
- Daten anzeigen, sobald sie verfügbar sind.
In diesem Artikel werde ich darüber sprechen, wie es implementiert und wie es dann alles optimiert hat.
Haftungsausschluss: Ich bin kein erfahrener Webentwickler, daher scheinen Ihnen einige Dinge offensichtlich zu sein, und die Schlussfolgerungen oder Entscheidungen sind falsch. Für Korrekturen und Klarstellungen bin ich dankbar.
Warum war es an
Die ganze Aufgabe ist wie folgt: Ein Skript wird auf dem Server ausgeführt (Bash, Python usw.) und schreibt etwas in stdout. Und diese Schlussfolgerung muss auf der Webseite angezeigt werden, sobald sie eintrifft. Gleichzeitig sollte es wie auf dem Terminal aussehen (mit Formatierung, Cursorübertragung usw.).
Ich kontrolliere das Skript selbst und seine Ausgabe in keiner Weise und zeige es in reiner Form an.
Natürlich sollte sich zwischen der Weboberfläche und dem Skript ein Vermittler befinden - ein Webserver. Und wenn nicht zu zerstreuen - ich habe bereits eine Webanwendung und einen Server und arbeite irgendwie. Das Schema sieht ungefähr so aus:

Zuvor war der Server für die Verarbeitung und Formatierung verantwortlich. Und ich wollte es aus einer Vielzahl von Gründen verbessern:
- Doppelte Datenverarbeitung - zuerst auf dem Server analysieren, dann auf dem Client in HTML-Komponenten umwandeln
- Nicht optimaler Algorithmus aufgrund der Datenaufbereitung für den Client
- Hohe Belastung des Servers - Die Verarbeitung der Ausgabe eines einzelnen Skripts kann einen einzelnen Thread vollständig auf den Server laden
- unvollständige Unterstützung für ANSI Escape-Sequenzen
- subtile Fehler
- Der Client hat sehr schlecht mit der Anzeige von sogar 10.000 formatierten Zeilen abgeschnitten
Daher wurde beschlossen, die gesamte Parsing-Logik auf die Webanwendung zu übertragen und nur Streaming-Rohdaten auf den Server zu übertragen
Erklärung des Problems
Teile des Textes kommen zum Kunden. Der Client muss sie in Komponenten zerlegen: Nur-Text, Zeilenvorschub, Wagenrücklauf und spezielle ANSI-Befehle. Es gibt keine Garantie für die Integrität der Teile - ein Befehl oder ein Wort kann in verschiedenen Paketen enthalten sein.
ANSI-Befehle können das Format des Texts (Farbe, Hintergrund, Stil), die Position des Cursors (von wo aus der nachfolgende Text angezeigt werden soll) oder das Löschen eines Teils des Bildschirms beeinflussen.
Ein Beispiel dafür, wie es aussieht:

Darüber hinaus enthält der Text möglicherweise URLs, die ebenfalls erkannt und hervorgehoben werden müssen.
Wir nehmen die fertige Bibliothek und ...
Ich habe verstanden, dass die korrekte und schnelle Verarbeitung aller Befehle keine leichte Aufgabe ist. Deshalb habe ich mich entschlossen, nach einer fertigen Bibliothek zu suchen. Und siehe da , ich bin sofort auf xterm.js gestoßen . Eine fertige Komponente des Terminals, die bereits vielerorts eingesetzt wird und darüber hinaus "sehr schnell ist, sogar einen GPU-beschleunigten Renderer enthält" . Letzteres war für mich das Wichtigste, weil Ich wollte endlich einen sehr schnellen Kunden bekommen.
Trotz der Tatsache, dass ich gerne meine eigenen Motorräder schreibe, war ich sehr froh, dass ich nicht nur Zeit sparen, sondern auch eine Reihe nützlicher Funktionen kostenlos erhalten kann.
Ich brauchte 14 Uhr, um das Terminal anzuschließen, und konnte es nicht bewältigen. Absolut.
Unterschiedliche Zeilenhöhen, krumme Auswahl, adaptive Größe des Terminals, eine sehr seltsame API, mangelnde Dokumentation ...
Aber ich hatte immer noch ein wenig Inspiration und glaubte, dass ich mit diesen Problemen umgehen könnte.
Bis ich meinen Test 10k Leitungen zum Terminal fütterte ... Er starb. Und begrub mit mir die Überreste meiner Hoffnungen.
Beschreibung des endgültigen Algorithmus
Zunächst habe ich den in Python implementierten aktuellen Algorithmus kopiert und für Javascript angepasst (nur geschweifte Klammern und einen anderen für die Syntax entfernen).
Ich kannte alle wichtigen Vor- und Nachteile des alten Algorithmus, daher musste ich nur die ineffektiven Stellen darin verbessern.
Nach Überlegungen, Versuchen und Irrtümern habe ich mich für die folgende Option entschieden: Wir teilen den Algorithmus in zwei Komponenten auf:
- Modell zum Parsen von Text und Speichern des aktuellen Status des "Terminals"
- Mapping, das das Modell in HTML übersetzt
Modell (Struktur und Algorithmus)
- Alle Zeilen werden in einem Array gespeichert (Zeilennummer = Index im Array)
- Textstile werden in einem separaten Array gespeichert.
- Die aktuelle Cursorposition wird gespeichert und kann durch Befehle geändert werden
- Der Algorithmus selbst prüft die Eingabedaten zeichenweise:
- Wenn dies nur Text ist, fügen Sie ihn der aktuellen Zeile hinzu
- Wenn ein Zeilenumbruch vorliegt, erhöhen Sie den aktuellen Zeilenindex
- Wenn dies eines der Befehlszeichen ist, legen wir es in den Befehlspuffer und warten auf das nächste Zeichen
- Wenn der Befehlspuffer korrekt ist, führen Sie diesen Befehl aus, andernfalls schreiben wir diesen Puffer als Text
- Das Modell benachrichtigt die Hörer darüber, welche Zeilen sich nach der Verarbeitung eingehender Texte geändert haben
In meiner Implementierung ist die Komplexität des Algorithmus O ( n log n ), wobei log n die Vorbereitung geänderter Zeilen für die Benachrichtigung ist (Eindeutigkeit und Sortierung). Zum Zeitpunkt dieses Schreibens wurde mir klar, dass Sie in einem speziellen Fall log n entfernen können, da die Zeilen am häufigsten am Ende hinzugefügt werden.
Anzeige
- Zeigt Text als HTML-Elemente an
- Wenn sich die Zeichenfolge geändert hat, werden alle Elemente der Zeichenfolge vollständig ersetzt
- Unterbricht jede Linie basierend auf Stilen: Jedes stilisierte Segment hat ein eigenes Element
Mit einer solchen Struktur ist das Testen eine ziemlich einfache Aufgabe - wir übertragen den Text in das Modell (in einem einzelnen Paket oder in Teilen) und überprüfen einfach den aktuellen Status aller darin enthaltenen Linien und Stile. Und um nur ein paar Tests anzuzeigen, weil Die geänderten Zeilen werden immer neu gezeichnet.
Ein wichtiger Vorteil ist auch eine gewisse Faulheit des Displays. Wenn wir in einem Text dieselbe Zeile überschreiben (z. B. Fortschrittsbalken), sieht es nach der Arbeit des Modells für die Anzeige wie eine geänderte Zeile aus.
DOM gegen Leinwand
Ich möchte ein wenig darüber nachdenken, warum ich mich für das DOM entschieden habe, obwohl das Ziel die Leistung war. Die Antwort ist einfach - Faulheit. Für mich scheint es eine ziemlich entmutigende Aufgabe zu sein, alles in Canvas selbst zu rendern. Unter Beibehaltung der Benutzerfreundlichkeit: Hervorheben, Kopieren, Ändern der Bildschirmgröße, Ordentliches Aussehen usw. Das Beispiel xterm.js hat mir deutlich gezeigt, dass dies überhaupt nicht einfach ist. Ihre Darstellung auf Leinwand war alles andere als ideal.
Darüber hinaus ist das Debuggen des DOM-Baums im Browser und die Möglichkeit, Unit-Tests abzudecken, ein wichtiger Vorteil.
Am Ende war mein Ziel 50.000 Zeilen, und ich wusste, dass das DOM damit umgehen musste, basierend auf der Arbeit des alten Algorithmus.
Optimierungen
Der Algorithmus war bereit, debuggt und funktionierte langsam aber sicher. Es war Zeit, den Profiler zu öffnen und zu optimieren. Mit Blick auf die Zukunft werde ich sagen, dass die meisten Optimierungen für mich eine Überraschung waren (wie es normalerweise der Fall ist).
Die Profilerstellung wurde auf 10.000 Linien durchgeführt, von denen jede stilisierte Elemente enthielt. Die Gesamtzahl der DOM-Elemente beträgt ca. 100.000.
Es wurden keine speziellen Ansätze und Werkzeuge verwendet. Nur Chrome Dev Tools und ein paar Starts für jede Messung. In der Praxis unterschieden sich bei den Starts nur die absoluten Werte der Messungen (wie viele Sekunden bis zum Abschluss), nicht jedoch das prozentuale Verhältnis zwischen den Methoden. Daher halte ich diese Technik für bedingt ausreichend.
Im Folgenden möchte ich näher auf die interessantesten Verbesserungen eingehen. Und für den Anfang eine Grafik von dem, was war:

Alle Profilgrafiken wurden nach der Implementierung erstellt, indem der Code aus dem Speicher deoptimiert wurde.
string.trim
Zunächst stieß ich auf eine unverständliche string.trim, die sehr viel CPU verbrauchte (es scheint mir, dass dies etwa 10-20% waren).

trim () ist die Grundfunktion der Sprache. Warum benutzt es eine Art Bibliothek? Und selbst wenn es sich um eine Art Polyfill handelt, warum wurde dann die neueste Version von Chrome aktiviert?
Ein wenig googeln und die Antwort ist gefunden: https://babeljs.io/docs/en/babel-preset-env . Standardmäßig wird Polyfill für eine relativ große Anzahl von Browsern aktiviert, und zwar in der Kompilierungsphase. Die Lösung für mich bestand darin, 'targets': '> 0.25%, not dead' anzugeben 'targets': '> 0.25%, not dead'
Aber am Ende habe ich den Trimmaufruf als unnötig gelöscht.
Vue.js
Letztes Jahr habe ich die Terminalkomponente auf Vue.js übertragen. Jetzt musste ich es wieder auf Vanille übertragen, der Grund ist im folgenden Screenshot (siehe die Anzahl der Zeilen mit Vue.js):
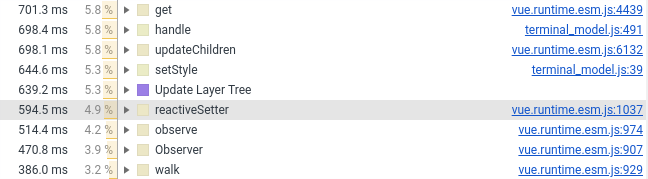
Ich habe nur Wrapper, Stile und Mausverarbeitung in der Vue-Komponente belassen. Alles, was mit dem Erstellen von DOM-Elementen zu tun hat, ging in reines JS über, das als normales Feld (das nicht vom Framework überwacht wird) mit der Vue-Komponente verbunden ist.
created() { this.terminalModel = new TerminalModel(); this.terminal = new Terminal(this.terminalModel); },
Ich halte dies nicht für ein Minus oder einen Fehler in Vue.js. Es ist nur so, dass Frameworks und Leistung selbst nicht gut zusammenpassen. Wenn Sie Zehntausende von Objekten in ein reaktives Framework ablegen, ist es sehr schwierig, innerhalb weniger Millisekunden eine Verarbeitung zu erwarten. Und um ehrlich zu sein, bin ich sogar überrascht, dass Vue.js ziemlich gut abgeschnitten hat.
Neue Elemente hinzufügen
Hier ist alles einfach - wenn Sie mehrere tausend neue Elemente haben und diese der übergeordneten Komponente hinzufügen möchten, ist es keine gute Idee, appendChild auszuführen. Der Browser muss die Verarbeitung etwas häufiger durchführen und mehr Zeit für das Rendern aufwenden. Eine der Nebenwirkungen in meinem Fall war eine Verlangsamung des Autoscrolls Es erzwingt eine Nachzählung aller hinzugefügten Komponenten.

Um das Problem zu lösen, gibt es ein DocumentFragment. Zuerst fügen wir alle Elemente hinzu und dann fügen wir es der übergeordneten Komponente hinzu. Der Browser kümmert sich um die Inline der eingehenden Komponenten.
Dieser Ansatz reduziert die Zeit, die der Browser für das Rendern und Anordnen von Elementen benötigt.
Ich habe auch andere Möglichkeiten ausprobiert, um das Hinzufügen von Elementen zu beschleunigen. Keiner von ihnen konnte etwas über das DocumentFragment hinzufügen.
span vs div
Tatsächlich könnte dies als display:inline (span) vs display:block (div) bezeichnet werden.
Anfangs hatte ich jede Zeile in der Spanne und endete mit einem Zeilenumbruch. In Bezug auf die Leistung ist dies jedoch nicht sehr effektiv: Der Browser muss herausfinden, wo das Element beginnt und endet. Mit display: block sind solche Berechnungen viel einfacher.
Das Ersetzen durch ein Div beschleunigte das Rendern um fast das Zweifache.
Leider sieht es im Fall von display:block schlechter aus display:block mehrere Textzeilen hervorzuheben:

Lange Zeit konnte ich mich nicht entscheiden, was besser ist - zusätzliche 2 Sekunden Rendering oder menschliche Auswahl. Infolgedessen besiegte die Praktikabilität die Schönheit.
CSS-Assistent der Stufe 10
Weitere ~ 10% der Renderzeit wurden durch CSS- "Optimierung" abgeschnitten, mit der ich Text formatiere.
Unerfahrenheit in der Webentwicklung und Verständnis der Grundlagen spielten gegen mich. Ich dachte, je genauer die Selektoren sind, desto besser, aber speziell in meinem Fall war dies nicht der Fall.
Um den Text im Terminal zu formatieren, habe ich die folgenden Selektoren verwendet:
#script-panel-container .log-content > div > span.text_color_green,
Aber (in Chrom) ist die folgende Option etwas schneller:
span.text_color_green
Ich mag diesen Selektor nicht wirklich, weil zu global, aber die Leistung ist teurer.
string.split
Wenn Sie aufgrund eines der vorherigen Punkte ein Deja Vu haben, ist es falsch. Diesmal geht es nicht um Polyfill, sondern um die Standardimplementierung in Chrome:

(Ich habe string.split in defSplit eingeschlossen, damit die Funktion im Profiler angezeigt wird.)
1% sind Kleinigkeiten. Aber der idealistische Radfahrer in mir wurde verfolgt. In meinem Fall erfolgt die Aufteilung immer zeichenweise und ohne Stammgäste. Daher habe ich eine einfache Option implementiert. Hier ist das Ergebnis:

fastSplit function fastSplit(str, separatorChar) { if (str === '') { return ['']; } let result = []; let lastIndex = 0; for (let i = 0; i < str.length; i++) { const char = str[i]; if (char === separatorChar) { const chunk = str.substr(lastIndex, i - lastIndex); lastIndex = i + 1; result.push(chunk); } } if (lastIndex < str.length) { const lastChunk = str.substr(lastIndex, str.length - lastIndex); result.push(lastChunk); } return result; }
Ich glaube, dass sie mich danach ohne Interview zum Google Chrome-Team bringen müssen.
Optimierung, Nachwort
Optimierung ist ein Prozess ohne Ende und etwas kann auf unbestimmte Zeit verbessert werden. Insbesondere wenn man bedenkt, dass unterschiedliche Anwendungsfälle unterschiedliche (und widersprüchliche) Optimierungen erfordern.
Für meinen Fall habe ich den Hauptanwendungsfall ausgewählt und die Betriebszeit von 15 Sekunden auf 5 Sekunden optimiert. Daraufhin habe ich beschlossen aufzuhören.

Es gibt noch einige Orte, die ich verbessern möchte, aber dies ist den gesammelten Erfahrungen zu verdanken.
Bonus Mutationstests.
So kam es, dass ich in den letzten Monaten oft auf den Begriff "Mutationstests" stieß. Und ich entschied, dass diese Aufgabe eine großartige Möglichkeit ist, dieses Biest auszuprobieren. Besonders nachdem ich in Webstorm keine Codeabdeckung für Karma-Tests erhalten hatte.
Da sowohl die Technik als auch die Bibliothek für mich neu sind, habe ich mich entschlossen, mit ein wenig Blut auszukommen: nur eine Komponente zu testen - das Modell. In diesem Fall können Sie klar angeben, welche Datei wir testen und welche Testsuite dafür vorgesehen ist.
Aber was auch immer man sagen mag, ich musste viel basteln, um eine Integration mit Karma und Webpack zu erreichen.
Am Ende fing alles an und nach einer halben Stunde sah ich traurige Ergebnisse: Etwa die Hälfte der Mutanten überlebte. Ich habe einen Teil sofort getötet, einen Teil für die Zukunft übrig (als ich die fehlenden ANSI-Befehle implementiert habe).
Danach gewann die Faulheit und im Moment sind die Ergebnisse wie folgt (für 128 Tests):
Ran 79.04 tests per mutant on average. ------------------|---------|----------|-----------|------------|---------| File | % score | # killed | # timeout | # survived | # error | ------------------|---------|----------|-----------|------------|---------| terminal_model.js | 73.10 | 312 | 25 | 124 | 1 | ------------------|---------|----------|-----------|------------|---------| 23:01:08 (18212) INFO Stryker Done in 26 minutes 32 seconds.
Im Allgemeinen erschien mir dieser Ansatz sehr nützlich (offensichtlich besser als die Codeabdeckung) und lustig. Das einzig Negative ist eine furchtbar lange Zeit - 30 Minuten pro Klasse sind zu viel.
Und vor allem hat mich dieser Ansatz dazu gebracht, noch einmal über eine 100% ige Abdeckung nachzudenken und darüber, ob es sich lohnt, alles mit Tests abzudecken: Jetzt ist meine Meinung bei der Beantwortung dieser Frage noch näher an „Ja“.
Fazit
Leistungsoptimierung ist meiner Meinung nach ein guter Weg, um etwas Tieferes zu lernen. Es ist auch ein gutes Training für das Gehirn. Und es ist sehr bedauerlich, dass dies selten wirklich benötigt wird (zumindest in meinen Projekten).
Und wie immer funktioniert der Ansatz „Erst Profilerstellung, dann Optimierung“ viel besser als Intuition.
Referenzen
Alte Implementierung:
Neue Implementierung:
Leider gibt es keine Webkomponenten-Demo, sodass Sie sie einfach nicht anstoßen können. Also entschuldige ich mich im Voraus
Vielen Dank für Ihre Zeit, ich freue mich über Kommentare, Vorschläge und vernünftige Kritik!