Vorwort
Sehr oft sind Benutzer, Entwickler und Administratoren von MS SQL Server-DBMS mit Datenbankleistungsproblemen oder DBMS im Allgemeinen konfrontiert. Daher ist die Überwachung von MS SQL Server sehr relevant.
Dieser Artikel ist eine Ergänzung zu dem Artikel
Verwenden von Zabbix zum Überwachen der MS SQL Server-Datenbank und untersucht einige Aspekte der Überwachung von MS SQL Server, insbesondere: wie schnell festgestellt werden kann, welche Ressourcen fehlen, sowie Empfehlungen zum Setzen von Ablaufverfolgungsflags.
Damit die folgenden Skripte funktionieren, müssen Sie das Inf-Schema in der gewünschten Datenbank wie folgt erstellen:
Erstellen eines Inf-Schemasuse <_>; go create schema inf;
Methode zur Erkennung eines RAM-Mangels
Der erste Hinweis auf einen RAM-Mangel ist der Fall, wenn eine Instanz von MS SQL Server den gesamten ihr zugewiesenen RAM verbraucht.
Erstellen Sie dazu die folgende inf.vRAM-Ansicht:
Erstellen einer inf.vRAM-Ansicht CREATE view [inf].[vRAM] as select a.[TotalAvailOSRam_Mb]
Anschließend können Sie feststellen, dass die Instanz von MS SQL Server den gesamten durch die folgende Abfrage zugewiesenen Speicher belegt:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb from [inf].[vRAM];
Wenn der Indikator SQL_server_physical_memory_in_use_Mb konstant nicht kleiner als SQL_server_committed_target_Mb ist, müssen Sie die Statistik der Erwartungen überprüfen.
Erstellen Sie eine inf.vWaits-Ansicht, um den RAM-Mangel anhand der Erwartungsstatistik zu ermitteln:
Erstellen einer inf.vWaits-Ansicht CREATE view [inf].[vWaits] as WITH [Waits] AS (SELECT [wait_type],
In diesem Fall können Sie den RAM-Mangel anhand der folgenden Abfrage ermitteln:
SELECT [Percentage] ,[AvgWait_S] FROM [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Hier müssen Sie auf die Leistung von Percentage und AvgWait_S achten. Wenn sie in ihrer Gesamtheit signifikant sind, besteht eine sehr hohe Wahrscheinlichkeit, dass der RAM für eine Instanz von MS SQL Server nicht ausreicht. Wesentliche Werte werden für jedes System individuell ermittelt. Sie können jedoch mit der folgenden Metrik beginnen: Prozentsatz> = 1 und AvgWait_S> = 0,005.
Um Indikatoren an ein Überwachungssystem (z. B. Zabbix) auszugeben, können Sie die folgenden zwei Abfragen erstellen:
- Wie viel Prozent belegen die Arten von Erwartungen an RAM (die Summe für alle Arten von Erwartungen):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
- Wie viele Millisekunden belegen die Arten von Erwartungen für RAM (der Maximalwert aller durchschnittlichen Verzögerungen für alle diese Arten von Erwartungen):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Basierend auf der Dynamik der erhaltenen Werte für diese beiden Indikatoren können wir schließen, ob genügend RAM für die Instanz von MS SQL Server vorhanden ist.
Erkennungsmethode für CPU-Überlast
Verwenden Sie einfach die Systemansicht sys.dm_os_schedulers, um den Mangel an CPU-Zeit zu ermitteln. Wenn der Indikator runnable_tasks_count konstant größer als 1 ist, besteht hier eine hohe Wahrscheinlichkeit, dass die Anzahl der Kerne für die MS SQL Server-Instanz nicht ausreicht.
Um den Indikator in einem Überwachungssystem (z. B. Zabbix) anzuzeigen, können Sie die folgende Abfrage erstellen:
select max([runnable_tasks_count]) as [runnable_tasks_count] from sys.dm_os_schedulers where scheduler_id<255;
Basierend auf der Dynamik der erhaltenen Werte für diesen Indikator können wir schließen, ob genügend Prozessorzeit (die Anzahl der CPU-Kerne) für eine Instanz von MS SQL Server vorhanden ist.
Es ist jedoch wichtig, sich daran zu erinnern, dass die Anforderungen selbst mehrere Threads gleichzeitig anfordern können. Und manchmal kann der Optimierer die Komplexität der Anforderung selbst nicht richtig einschätzen. Dann können der Anforderung zu viele Threads zugewiesen werden, die zu einem bestimmten Zeitpunkt nicht gleichzeitig verarbeitet werden können. Dies führt auch zu einer Art von Wartezeit, die mit einem Mangel an Prozessorzeit verbunden ist, und das Wachstum der Warteschlange für Scheduler, die bestimmte CPU-Kerne verwenden, d. H. Der Indikator runnable_tasks_count, wächst unter solchen Bedingungen.
In diesem Fall müssen Sie vor dem Erhöhen der Anzahl der CPU-Kerne die Parallelitätseigenschaften der Instanz von MS SQL Server korrekt konfigurieren und ab der Version 2016 die Parallelitätseigenschaften der erforderlichen Datenbanken korrekt konfigurieren:

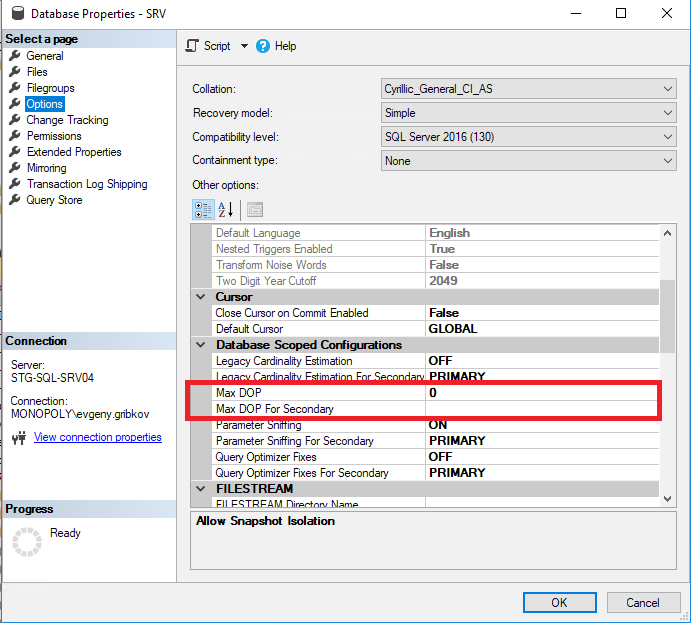
Hierbei sind folgende Parameter zu beachten:
- Maximaler Parallelitätsgrad - Legt die maximale Anzahl von Threads fest, die jeder Anforderung zugewiesen werden können (die Standardeinstellung ist 0-Einschränkung nur durch das Betriebssystem und die MS SQL Server-Edition).
- Kostenschwelle für Parallelität - geschätzte Kosten für Parallelität (Standard ist 5)
- Max DOP legt die maximale Anzahl von Threads fest, die jeder Abfrage auf Datenbankebene zugewiesen werden können (jedoch nicht mehr als den Wert der Eigenschaft "Maximaler Parallelitätsgrad") (die Standardeinstellung ist 0-Einschränkung nur durch das Betriebssystem und die MS SQL Server-Edition). sowie die Einschränkung der Eigenschaft "Maximaler Parallelitätsgrad" der gesamten MS SQL Server-Instanz)
Es ist unmöglich, für alle Fälle ein gleich gutes Rezept zu geben, dh Sie müssen schwierige Anfragen analysieren.
Aus eigener Erfahrung empfehle ich den folgenden Aktionsalgorithmus für OLTP-Systeme, um Parallelitätseigenschaften zu konfigurieren:
- Verbieten Sie zunächst die Parallelität, indem Sie die Ebene der gesamten Instanz von Max. Parallelitätsgrad auf 1 setzen
- Analysieren Sie die schwierigsten Anforderungen und wählen Sie die optimale Anzahl von Threads für sie aus
- Stellen Sie den maximalen Parallelitätsgrad auf die ausgewählte optimale Anzahl von Threads ein, die aus Punkt 2 erhalten wurden, und legen Sie für bestimmte Datenbanken den maximalen DOP-Wert fest, der aus Punkt 2 für jede Datenbank erhalten wurde
- Analysieren Sie die schwierigsten Anforderungen und identifizieren Sie die negativen Auswirkungen von Multithreading. Wenn dies der Fall ist, erhöhen Sie den Kostenschwellenwert für Parallelität.
Für Systeme wie 1C, Microsoft CRM und Microsoft NAV ist in den meisten Fällen das Verbot von Multithreading geeignet.
Wenn die Standard Edition installiert ist, ist das Multithreading-Verbot in den meisten Fällen geeignet, da diese Edition durch die Anzahl der CPU-Kerne begrenzt ist.
Für OLAP-Systeme ist der oben beschriebene Algorithmus nicht geeignet.
Aus eigener Erfahrung empfehle ich den folgenden Aktionsalgorithmus für OLAP-Systeme zum Festlegen von Parallelitätseigenschaften:
- Analysieren Sie die schwierigsten Anforderungen und wählen Sie die optimale Anzahl von Threads für sie aus
- Stellen Sie den maximalen Parallelitätsgrad auf die ausgewählte optimale Anzahl von Threads ein, die von Punkt 1 erhalten wurden, und legen Sie für bestimmte Datenbanken den maximalen DOP-Wert fest, der von Punkt 1 für jede Datenbank erhalten wird
- Analysieren Sie die schwierigsten Anforderungen und identifizieren Sie die negativen Auswirkungen des Parallelitätslimits. Wenn dies der Fall ist, senken Sie entweder den Kostenschwellenwert für Parallelität oder wiederholen Sie die Schritte 1-2 dieses Algorithmus
Das heißt, für OLTP-Systeme wechseln wir von Single-Threaded zu Multithreading, und für OLAP-Systeme gehen wir im Gegenteil von Multithreading zu Single-Threading über. Somit ist es möglich, die optimalen Einstellungen für die Parallelität sowohl für eine bestimmte Datenbank als auch für die gesamte MS SQL Server-Instanz auszuwählen.
Es ist auch wichtig zu verstehen, dass die Einstellungen für die Parallelitätseigenschaften im Laufe der Zeit basierend auf den Ergebnissen der Überwachung der Leistung von MS SQL Server geändert werden müssen.
Empfehlungen zum Setzen von Trace-Flags
Aus eigener Erfahrung und aus Erfahrung meiner Kollegen empfehle ich, die folgenden Ablaufverfolgungsflags auf der Startebene des MS SQL Server-Dienstes für Versionen 2008-2016 zu setzen, um eine optimale Leistung zu erzielen:
- 610 - Reduzieren der Protokollierung von Einfügungen in indizierten Tabellen. Es kann beim Einfügen in Tabellen mit einer großen Anzahl von Datensätzen und vielen Transaktionen hilfreich sein, wobei WRITELOG häufig lange Änderungen an Indizes erwartet
- 1117 - Wenn eine Datei in einer Dateigruppe den Schwellenwert für das automatische Wachstum erreicht, werden alle Dateien in der Dateigruppe erweitert
- 1118 - Erzwingt, dass sich alle Objekte in unterschiedlichen Bereichen befinden (Verbot gemischter Bereiche), wodurch die Notwendigkeit minimiert wird, die SGAM-Seite zu scannen, die zum Verfolgen gemischter Bereiche verwendet wird
- 1224 - Deaktiviert die Sperreneskalation basierend auf der Anzahl der Sperren. Eine übermäßige Speichernutzung kann eine Sperreneskalation umfassen.
- 2371 - Ändert den Schwellenwert für feste automatische Statistikaktualisierungen in den Schwellenwert für dynamische automatische Statistikaktualisierungen. Es ist wichtig, Abfragepläne für große Tabellen zu aktualisieren, wenn eine falsche Bestimmung der Anzahl der Datensätze zu fehlerhaften Ausführungsplänen führt
- 3226 - Unterdrückt erfolgreiche Sicherungsnachrichten im Fehlerprotokoll
- 4199 - Enthält Änderungen am Abfrageoptimierer, die im kumulativen Update und in den SQL Server-Service Packs veröffentlicht wurden
- 6532-6534 - Enthält eine verbesserte Abfrageleistung für räumliche Datentypen
- 8048 - Konvertiert NUMA-partitionierte Speicherobjekte in CPU-partitionierte Objekte
- 8780 - Aktiviert die zusätzliche Zeitzuweisung zum Planen einer Anforderung. Einige Anfragen ohne dieses Flag werden möglicherweise abgelehnt, da sie keinen Anforderungsplan haben (sehr seltener Fehler).
- 9389 - Enthält einen zusätzlichen dynamischen temporär bereitgestellten Speicherpuffer für Batch-Modus-Operatoren, der es dem Batch-Modus-Operator ermöglicht, zusätzlichen Speicher anzufordern und die Übertragung von Daten an Tempdb zu vermeiden, wenn zusätzlicher Speicher verfügbar ist
Vor der Version 2016 ist es nützlich, das Ablaufverfolgungsflag 2301 einzuschließen, das die Optimierung der erweiterten Entscheidungsunterstützung umfasst und dadurch bei der Auswahl korrekterer Abfragepläne hilft. Ab Version 2016 wirkt sich dies jedoch häufig negativ auf eine relativ lange Gesamtausführungszeit für Abfragen aus.
Außerdem empfehle ich für Systeme, in denen viele Indizes vorhanden sind (z. B. für 1C-Datenbanken), das Ablaufverfolgungsflag 2330 zu aktivieren, mit dem die Erfassung bei Verwendung von Indizes deaktiviert wird, was sich im Allgemeinen positiv auf das System auswirkt.
Erfahren Sie hier mehr über Trace-Flags.
Über den obigen Link ist es auch wichtig, die Versionen und Assemblys von MS SQL Server zu berücksichtigen, da bei neueren Versionen einige Ablaufverfolgungsflags standardmäßig aktiviert sind oder keine Auswirkungen haben. In der Version 2017 ist es beispielsweise relevant, nur die folgenden 5 Ablaufverfolgungsflags zu setzen: 1224, 3226, 6534, 8780 und 9389.
Sie können das Ablaufverfolgungsflag mit den Befehlen DBCC TRACEON bzw. DBCC TRACEOFF aktivieren oder deaktivieren. Weitere Details finden Sie hier.
Sie können den Status von Trace-Flags mit dem Befehl DBCC TRACESTATUS abrufen:
more .
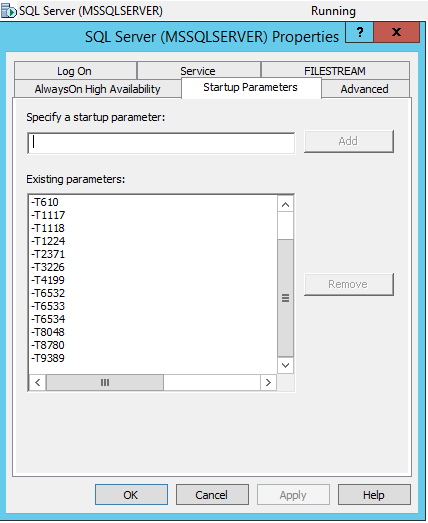
Damit die Ablaufverfolgungsflags in die automatische Ausführung des MS SQL Server-Dienstes aufgenommen werden können, müssen Sie in SQL Server Configuration Manager diese Ablaufverfolgungsflags über -T in die Diensteigenschaften einfügen:
Zusammenfassung
In diesem Artikel wurden einige Aspekte der MS SQL Server-Überwachung untersucht, mit deren Hilfe Sie schnell einen Mangel an RAM und CPU-Freizeit sowie eine Reihe anderer weniger offensichtlicher Probleme feststellen können. Die am häufigsten verwendeten Trace-Flags wurden berücksichtigt.
Quellen
»
SQL Server-Standby-Statistik»
Die Erwartungsstatistik von SQL Server oder bitte sagen Sie mir, wo es weh tut»
Systemansicht sys.dm_os_schedulers»
Verwenden von Zabbix zum Verfolgen der MS SQL Server-Datenbank»
SQL-Lebensstil»
Flaggen verfolgen»
Sql.ru.