
Am 1. April endete das Finale des SNA Hackathons 2019 , dessen Teilnehmer an der Sortierung der sozialen Netzwerke mit modernen Technologien für maschinelles Lernen, Computer Vision, Testverarbeitung und Empfehlungssystemen teilnahmen. Harte Online-Auswahl und zwei Tage harte Arbeit an 160 Gigabyte Daten waren nicht umsonst :). Wir sprechen darüber, was den Teilnehmern zum Erfolg verholfen hat und über andere interessante Beobachtungen.
Über Daten und Aufgaben
Der Wettbewerb präsentierte Daten aus den Mechanismen zur Vorbereitung des Feeds für Benutzer des sozialen Netzwerks OK , das aus drei Teilen besteht:
- Inhaltsanzeigeprotokolle in Benutzer-Feeds mit einer großen Anzahl von Attributen, die den Benutzer, den Inhalt, den Autor und andere Eigenschaften beschreiben.
- Texte zum angezeigten Inhalt;
- im Inhalt verwendete Bildkörper.
Die Gesamtdatenmenge übersteigt 160 Gigabyte, von denen mehr als 3 Protokolle, 3 weitere Texte und der Rest Bilder darstellen. Die große Datenmenge hat die Teilnehmer nicht erschreckt: Laut ML Bootcamp- Statistiken nahmen fast 200 Personen an dem Wettbewerb teil, die mehr als 3.000 Einreichungen verschickten, und die aktivsten schafften es, die Messlatte von 100 gesendeten Lösungen zu überschreiten. Vielleicht waren sie durch den Preispool von 700.000 Rubel + 3 GTX 2080 Ti-Grafikkarten motiviert.

Die Teilnehmer des Wettbewerbs mussten das Problem des Sortierens des Bandes lösen: Sortieren Sie für jeden einzelnen Benutzer die angezeigten Objekte so, dass diejenigen, die die Note „Klasse!“ Erhalten haben, näher am Kopf der Liste stehen.
ROC-AUC wurde als Qualitätsbewertungsmetrik verwendet. Gleichzeitig wurde die Metrik nicht für alle Daten als Ganzes berücksichtigt, sondern für jeden Benutzer separat und dann gemittelt. Diese Berechnungsoption ist insofern bemerkenswert, als die Algorithmen, die gelernt haben, Benutzer zu unterscheiden, die viele Klassen eingeben, keine Vorteile erhalten. Auf der anderen Seite gibt es in Standard-Python-Paketen keine solche Option, die einige interessante Punkte enthüllte, die unten diskutiert werden.
Über Technologie
Traditionell handelt es sich beim SNA Hackathon nicht nur um Algorithmen, sondern auch um Technologien. Das gelieferte Datenvolumen übersteigt 160 Gigabyte, was die Teilnehmer vor interessante technische Aufgaben stellt.
Parkett vs. Csv
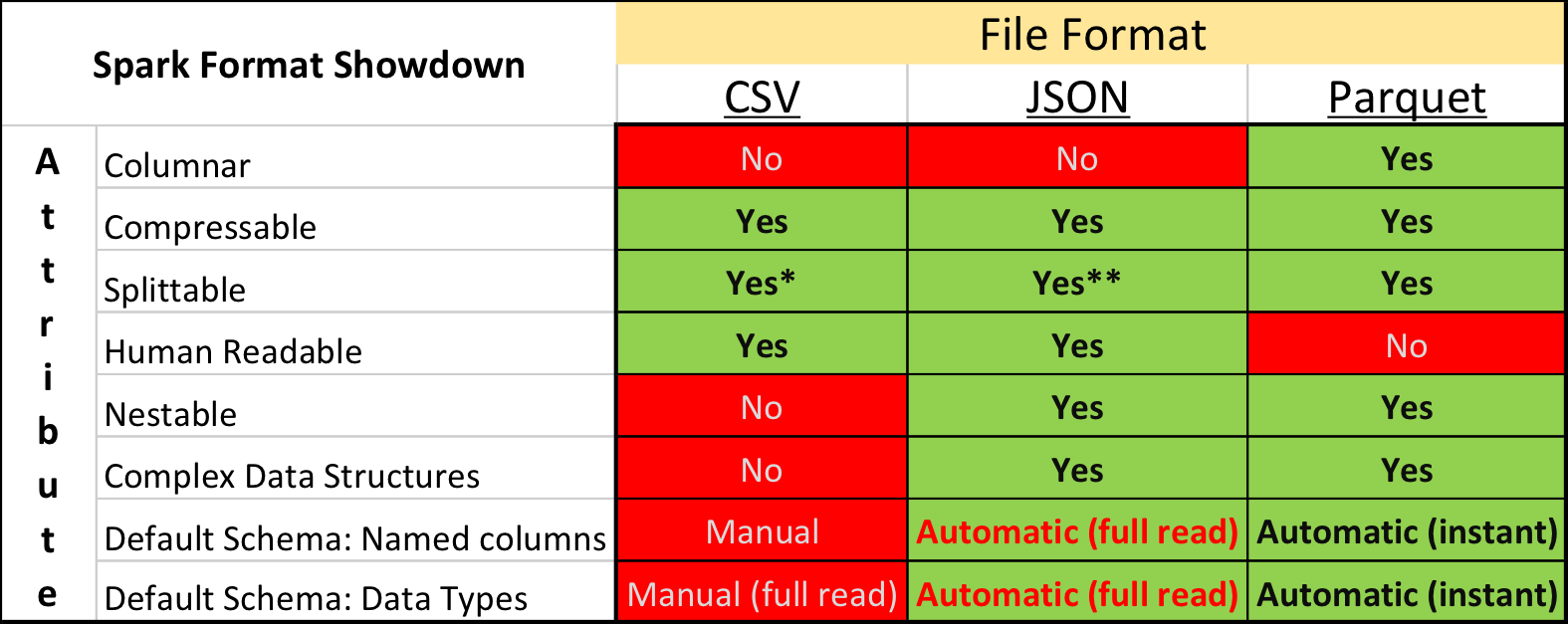
In der akademischen Forschung und bei Kaggle ist das dominierende Datenformat CSV sowie andere Klartextformate. Die Situation in der Branche ist jedoch etwas anders - wesentlich kompakter und Verarbeitungsgeschwindigkeiten können mit "binären" Speicherformaten erreicht werden.
Insbesondere in dem auf Apache Spark basierenden Ökosystem ist Apache Parquet das beliebteste - ein Spalten-Datenspeicherformat mit Unterstützung für viele wichtige Betriebsfunktionen:
- eine explizit spezifizierte Schaltung mit Evolutionsunterstützung;
- nur die notwendigen Spalten von der Festplatte lesen;
- Grundlegende Unterstützung für Indizes und Filter beim Lesen;
- String-Komprimierung.
Trotz der offensichtlichen Vorteile stieß die Einreichung von Daten für den Wettbewerb im Apache Parquet-Format bei einigen Teilnehmern auf heftige Kritik. Neben dem Konservatismus und der Unwilligkeit, Zeit damit zu verbringen, etwas Neues zu entwickeln, gab es einige wirklich unangenehme Momente.
Erstens ist die Unterstützung für das Format in der Apache Arrow- Bibliothek, dem Hauptwerkzeug für die Arbeit mit Parkett aus Python, alles andere als perfekt. Bei der Vorbereitung der Daten mussten alle Strukturfelder auf flach erweitert werden. Beim Lesen von Texten stießen viele Teilnehmer auf einen Fehler und mussten die alte Version der Bibliothek 0.11.1 anstelle der aktuellen Version 0.12 installieren. Zweitens können Sie die Parkettdatei nicht mit einfachen Konsolendienstprogrammen anzeigen: cat, less usw. Dieser Nachteil lässt sich jedoch relativ leicht durch die Verwendung des Parkettwerkzeugpakets ausgleichen.
Diejenigen, die zunächst versuchten, alle Daten in CSV zu konvertieren und dann in der vertrauten Umgebung zu arbeiten, gaben diese Idee schließlich auf - schließlich arbeitet Parkett deutlich schneller.
Boosting und GPU

Auf der SmartData-Konferenz in St. Petersburg, die „in engen Kreisen weithin bekannt“ ist, verglich Alexey Natekin die Leistung mehrerer beliebter Boosting-Tools während der Arbeit an der CPU / GPU und kam zu dem Schluss, dass die GPU keinen spürbaren Gewinn bringt. Aber selbst dann führte diese Schlussfolgerung zu einer aktiven Polemik, vor allem bei den Entwicklern des inländischen CatBoost- Tools.
In den letzten zwei Jahren haben die Fortschritte bei der Entwicklung von GPUs und der Anpassung von Algorithmen nicht aufgehört, und das SNA-Hackathon-Finale kann als Triumph des CatBoost + GPU-Paares angesehen werden - alle Gewinner haben es verwendet und die Metrik hauptsächlich aufgrund der Fähigkeit gezogen, mehr Bäume pro Zeiteinheit zu züchten.
Die integrierte Implementierung der mittleren Zielcodierung trug ebenfalls zum hohen Ergebnis von Lösungen bei, die auf CatBoost basierten, aber die Anzahl und Tiefe der Bäume führte zu einem deutlicheren Anstieg.
Andere Boosting-Tools bewegen sich in eine ähnliche Richtung und fügen die GPU-Unterstützung hinzu und verbessern sie. Wachsen Sie also mehr Bäume!
Spark vs. Pyspark

Das Apache Spark- Tool ist auch dank der Python-API ein starker Marktführer in der industriellen Datenwissenschaft. Die Verwendung von Python bringt jedoch zusätzlichen Aufwand für die Integration zwischen verschiedenen Laufzeiten und Dolmetscherarbeiten mit sich.
Dies ist an sich kein Problem, wenn dem Benutzer bekannt ist, inwieweit die Höhe der zusätzlichen Kosten zu einer bestimmten Aktion führt. Es stellte sich jedoch heraus, dass so viele das Ausmaß des Problems nicht erkennen - trotz der Tatsache, dass die Teilnehmer Apache Spark nicht verwendeten, diskutierten Diskussionen über Python vs. Scala erschien regelmäßig im Hackathon-Chat, was zum Erscheinen des entsprechenden analysierten Posts führte .
Kurz gesagt, die Verlangsamung der Verwendung von Spark über Python im Vergleich zur Verwendung von Spark über Scala / Java kann in die folgenden Ebenen unterteilt werden:
- Nur die Spark SQL-API wird ohne benutzerdefinierte Funktionen (User Defined Functions, UDF) verwendet. In diesem Fall entsteht praktisch kein Overhead, da der gesamte Abfrageausführungsplan im Rahmen der JVM berechnet wird.
- UDF wird in Python verwendet, ohne Pakete mit C ++ - Code aufzurufen. In diesem Fall sinkt die Leistung der Phase, in der UDF berechnet wird, um das 7- bis 10-fache .
- UDF wird in Python mit Zugriff auf das C ++ - Paket (numpy, sklearn usw.) verwendet. In diesem Fall sinkt die Leistung um das 10-50-fache .
Teilweise kann der negative Effekt durch die Verwendung von PyPy (JIT für Python) und vektorisierten UDFs kompensiert werden. In diesen Fällen ist der Leistungsunterschied jedoch vielfältig, und die Komplexität der Implementierung und Bereitstellung ist mit einem zusätzlichen "Bonus" verbunden.
Über Algorithmen
Das Interessanteste an Data Science-Hackathons sind natürlich nicht die Technologien, sondern neue modische und altbewährte Algorithmen. CatBoost dominierte dieses Jahr den SNA Hackathon, aber es gab mehrere alternative Ansätze. Wir werden darüber reden :).
Differenzierbare Graphen

Eine der ersten Veröffentlichungen von Entscheidungen, die auf den Ergebnissen der Qualifikationsrunde basierten, war nicht Bäumen gewidmet, sondern differenzierbaren Graphen (auch künstliche neuronale Netze genannt). Der Autor ist ein Mitarbeiter von OK, daher kann er es sich nicht leisten, Preise zu jagen, sondern genießt es, eine vielversprechende Lösung auf der Grundlage einer soliden mathematischen Grundlage zu entwickeln.
Die Hauptidee der vorgeschlagenen Lösung bestand darin, ein einzelnes rechnerisch differenzierbares Diagramm zu erstellen, das die verfügbaren Funktionen in eine Prognose übersetzt, die verschiedene Aspekte der Eingabedaten berücksichtigt:
- Mit Objekt- und Benutzergewerkschaften können Sie ein Element klassischer Empfehlungen für die Zusammenarbeit hinzufügen.
- Durch den Übergang von der skalaren Einbettung zur Aggregation durch MLP können Sie beliebige Merkmale hinzufügen.
- Durch die Beachtung des Abfrageschlüsselwerts konnte sich das Modell dynamisch an das Verhalten eines zuvor unbekannten Benutzers anpassen, der seine jüngste Geschichte betrachtet.
Dieses Modell erwies sich bei der Online-Auswahl als sehr gut bei der Lösung des Problems der Empfehlung von Textinhalten. Daher versuchten mehrere Teams, es gleichzeitig im Finale zu spielen, was jedoch nicht gelang. Dies lag zum einen daran, dass dies Zeit und Erfahrung erfordert, und zum anderen daran, dass die Anzahl der Attribute im Finale viel größer war und die auf Bäumen basierenden Methoden aufgrund dieser einen signifikanten Vorteil erhielten.
Kollaborative Dominante

Bei der Organisation des Wettbewerbs wussten wir natürlich, dass die Protokolle ein ziemlich starkes Signal enthalten, da die dort gesammelten Zeichen einen erheblichen Teil der in OK geleisteten Arbeit zur Einstufung des Feeds widerspiegeln. Trotzdem hofften sie bis zum Ende, dass es den Teilnehmern gelingen würde, mit dem „Fluch des dritten Charakters“ fertig zu werden - Situationen, in denen enorme personelle und maschinelle Ressourcen, die in die Entwicklung eines Modells zum Extrahieren von Attributen aus Inhalten (Texte und Fotos) investiert wurden, im Vergleich zu bereits zu äußerst bescheidenen Qualitätsgewinnen führen vorbereitete, hauptsächlich kollaborative Eigenschaften.
Da wir dieses Problem kannten, teilten wir die Aufgabe in der Qualifikationsrunde zunächst in drei Strecken auf und bildeten erst im Finale einen kombinierten Datensatz. Im Hackathon-Format mit einer festen Metrik befanden sich die Teams, die in die Entwicklung von Inhaltsmodellen investierten, in einer absichtlich verlorenen Situation im Vergleich zu Teams, die eine Zusammenarbeit entwickelten Teil.
Der Preis der Jury hat dazu beigetragen, diese Ungerechtigkeit auszugleichen ...
Tiefer Cluster

Das wurde fast einstimmig für die Arbeit an der Reproduktion und dem Testen des Deep Cluster- Algorithmus von Facebook vergeben. Die einfache und nicht erforderliche anfängliche Markup-Methode zum Erstellen von Clustern und Bildeinbettungen beeindruckte durch neue Ideen und vielversprechende Ergebnisse.
Das Wesentliche der Methode ist äußerst einfach:
- Berechnen von Einbettungsvektoren für Bilder mit einem sinnvollen neuronalen Netzwerk;
- Cluster die Vektoren im resultierenden Raum mit k-Mitteln;
- einen neuronalen Netzwerkklassifikator trainieren, um eine Gruppe von Bildern vorherzusagen;
- Wiederholen Sie die Schritte 2-3 bis zur Konvergenz (wenn Sie 800 GPUs haben) oder solange genügend Zeit vorhanden ist.
Mit einem Minimum an Aufwand gelang es uns, ein qualitativ hochwertiges Clustering von OK-Bildern, gute Einbettungen und eine metrische Erhöhung der dritten Ziffer zu erzielen.
Schau in die Zukunft

In allen Daten finden Sie "Lücken", um die Prognose zu verbessern. An sich ist dies nicht so schlimm, es ist viel schlimmer, wenn die Lücken selbst gefunden werden und lange Zeit nur in Form von unverständlichen Diskrepanzen zwischen den Ergebnissen der Validierung historischer Daten und A / B-Tests auftreten.
Eine der am weitesten verbreiteten Lücken dieser Art ist die Verwendung von Informationen aus der Zukunft. Solche Informationen sind oft ein sehr starkes Signal, und wenn der Algorithmus für maschinelles Lernen aktiviert ist, beginnt er, sie mit Sicherheit zu verwenden. Wenn Sie ein Modell für Ihr Produkt erstellen, versuchen Sie auf jede erdenkliche Weise, das Auslaufen von Informationen aus der Zukunft zu vermeiden. Beim Hackathon ist dies jedoch eine gute Chance, die von den Teilnehmern verwendete Metrik zu erhöhen.
Die offensichtlichste Lücke war das Vorhandensein von numLikes und numDislikes in diesen Feldern mit Reaktionszählungen am Objekt zum Zeitpunkt der Show. Durch den Vergleich der beiden zeitlich engsten Ereignisse in Bezug auf dasselbe Objekt konnte mit hoher Genauigkeit festgestellt werden, wie die Reaktion auf das Objekt im ersten von ihnen war. Die Daten enthielten mehrere ähnliche Zähler, deren Verwendung einen spürbaren Vorteil bot. Im tatsächlichen Gebrauch sind solche Informationen natürlich nicht verfügbar.
Im Leben kann ein ähnliches Problem entdeckt werden, ohne es zu bemerken, normalerweise mit negativen Ergebnissen. Zum Beispiel Statistiken über die Anzahl der Noten "Klasse!" für das Objekt nach allen Daten und als separates Attribut. Oder, wie in einem der teilnehmenden Teams, dem Modell eine Objektkennung als kategoriales Attribut hinzufügen. Bei einem Trainingssatz funktioniert ein Modell mit einer solchen Funktion gut, kann jedoch nicht auf einen Testsatz verallgemeinert werden.
Anstelle einer Schlussfolgerung

Alle Materialien des Wettbewerbs, einschließlich Daten und Präsentationen von Entscheidungen der Teilnehmer, sind in der Mail.ru Cloud verfügbar. Daten stehen für Forschungsprojekte ohne Einschränkungen zur Verfügung, mit Ausnahme der Verfügbarkeit von Links. Lassen Sie uns für die Geschichte den Final Table hier mit den Metriken der Final Teams verlassen:
- Hier hockst du Scala, versteckst Python - 0.7422 und analysierst die Lösung. Der Code ist hier und hier .
- Magische Stadt - 0,7256
- Kefir - 0,7226
- Team 6 - 0,7205
- Drei in einem Boot - 0,7188
- Halle Nr. 14 - 0.7167 und Preis der Jury
- BezSNA - 0,7147
- PONGA - 0,7117
- Team 5 - 0,7112
Der SNA Hackathon 2019 war wie die vorherigen Veranstaltungen der Serie in jeder Hinsicht ein Erfolg. Wir haben es geschafft, coole Profis in verschiedenen Bereichen unter einem Dach zu sammeln und eine fruchtbare Zeit zu haben, wofür wir uns bei den Teilnehmern selbst und allen bedanken, die bei der Organisation mitgeholfen haben.
Könnte etwas noch besser gemacht worden sein? Ja natürlich! Jeder Wettbewerb bereichert uns mit neuen Erfahrungen, die wir bei der Vorbereitung des nächsten berücksichtigen und dort nicht aufhören werden. Bis bald beim SNA Hackathon!