Was sind GLTF und GLB?
GLTF (GL Transmission Format) ist ein Dateiformat zum Speichern von 3D-Szenen und -Modellen, das äußerst einfach zu verstehen ist (die Struktur ist im JSON-Standard geschrieben), erweiterbar ist und problemlos mit modernen Webtechnologien interagiert. Dieses Format komprimiert dreidimensionale Szenen gut und minimiert die Laufzeitverarbeitung von Anwendungen mithilfe von WebGL und anderen APIs. Der GLTF wird jetzt von der Khronos Group aktiv als JPEG aus der 3D-Welt beworben. Derzeit wird GLTF Version 2.0 verwendet. Es gibt auch eine binäre Version dieses Formats namens GLB, deren einziger Unterschied darin besteht, dass alles in einer Datei mit der Erweiterung GLB gespeichert ist.
Dieser Artikel ist Teil 1 von 2. Darin werden Formatartefakte und ihre Attribute wie Szene, Knoten, Puffer, Pufferansicht, Accessor und Netz betrachtet . Und im zweiten Artikel werden wir uns den Rest ansehen: Material, Textur, Animationen, Haut und Kamera. Weitere allgemeine Formatinformationen finden Sie hier .
Wenn Sie beim Anzeigen eines Artikels persönlich mit diesem Format arbeiten möchten, können Sie GLTF 2.0-Modelle aus dem offiziellen Khronos-Repository auf GitHub herunterladen

Das Problem und seine Lösung
Ursprünglich wurde das GLTF-Format von der Khronos Group als Lösung für die Übertragung von 3D-Inhalten über das Internet konzipiert und so konzipiert, dass die Anzahl der Importeure und Konverter minimiert wird, von denen beim Arbeiten mit grafischen APIs verschiedene Arten erstellt werden.
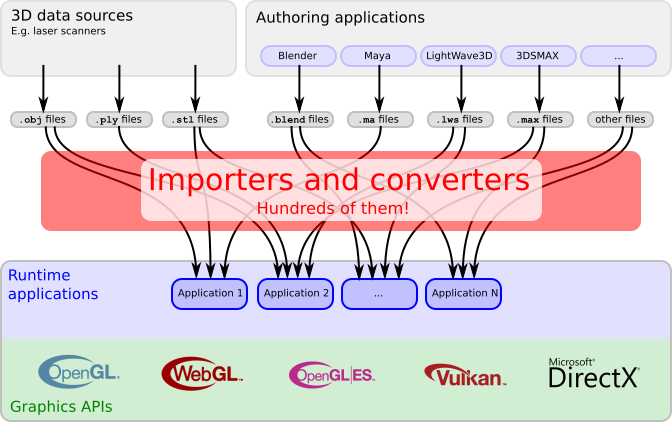
Derzeit werden GLTF und sein binärer Bruder GLB als einheitliche Formate in CAD-Programmen (Autodesk Maya, Blender usw.), in Game-Engines (Unreal Engine, Unity usw.), AR / VR-Anwendungen und sozialen Diensten verwendet. Netzwerke usw.
Vertreter der Khronos-Gruppe geben Folgendes an:
- GLTF ist universell - es kann sowohl für einfache Geometrie als auch für komplexe Szenen mit Animationen, verschiedenen Materialien usw. verwendet werden.
- Es ist ziemlich kompakt. Ja, dies kann argumentiert werden, da alles von den Konvertierungsalgorithmen abhängt und ich persönlich Fälle kenne, in denen GLTF größer als das Original war, z. B. FBX-Datei, aber in den meisten Fällen ist dies der Fall.
- Die einfache Datenanalyse ist das Plus dieses Formats. Die GLTF-Hierarchie verwendet JSON und die Geometrie wird in binärer Form gespeichert. Es ist keine Dekodierung erforderlich!
Koordinatensystem und Einheiten
GLTF verwendet ein rechtshändiges Koordinatensystem, dh das Kreuzprodukt von + X und + Y ergibt + Z, wobei + Y die obere Achse ist. Die Vorderseite des 3D-GLTF-Assets zeigt zur + Z-Achse. Die Maßeinheiten für alle linearen Abstände sind Meter, die Winkel werden im Bogenmaß gemessen und die positive Drehung von Objekten erfolgt gegen den Uhrzeigersinn. Knotentransformationen und Kanalpfade von Animationen sind dreidimensionale Vektoren oder Quaternionen mit den folgenden Datentypen und Semantiken:
Translation : Ein dreidimensionaler Vektor, der die Translation entlang der x-, y- und z-Achse enthält
Rotation : Quaternion (x, y, z, w), wobei w ein Skalar ist
Maßstab : Ein dreidimensionaler Vektor, der x-, y- und z-Skalierungsfaktoren enthält

GLTF - ein Einblick
Wie oben erwähnt, besteht GLTF in der Regel aus zwei Dateien: der ersten mit dem .gltf-Format, in dem die Struktur der 3D-Szene in Form von JSON gespeichert ist, und der zweiten Datei mit dem .bin-Format, in der alle Daten dieser Szene direkt gespeichert sind.
Die Formatstruktur ist streng hierarchisch und hat folgende Form:
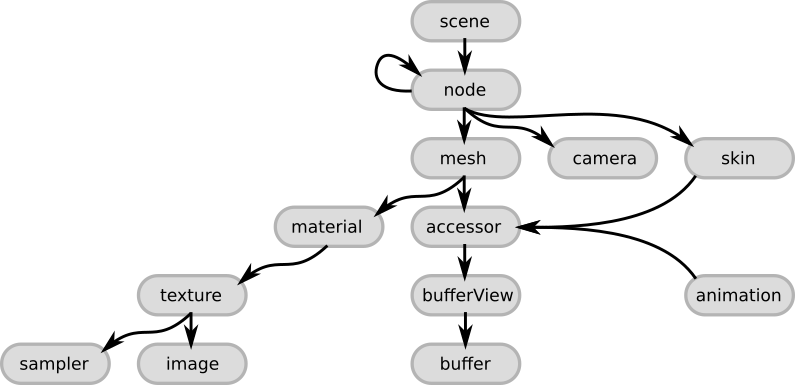
Wenn ich weiter über die Struktur spreche, werde ich Beispiele der einfachsten GLTF-Datei verwenden, in der 1 einseitiges Dreieck mit dem Standardmaterial gespeichert ist. Wenn Sie möchten, können Sie es kopieren und in einen beliebigen GLTF-Viewer einfügen, um den Inhalt der Datei persönlich zu "fühlen". In meiner Praxis habe ich verschiedene verwendet, mich aber dafür entschieden , dass Three.js unter der Haube verwendet wird. Eine gute Option wäre auch die Verwendung von Visual Studio Code mit dem GLTF-Plugin. Sie haben also sofort die Wahl zwischen 3 Motoren: Babylon.js, Caesium, Three.js
Szenen- und Knotenelemente
Das Wichtigste zuerst ist der Hauptknoten namens Szene. Dies ist der Stammpunkt in der Datei, an dem alles beginnt. Dieser Knoten enthält eine Reihe von Szenen, die GLTF speichert, und die Auswahl der Szenen, die standardmäßig nach dem Öffnen der Datei geladen werden. Der Inhalt der 3D-Szene beginnt mit dem nächsten Objekt, das als „Knoten“ bezeichnet wird. Eine Reihe von Szenen und Knoten wurde nicht umsonst erwähnt, weil Die Möglichkeit, mehrere Szenen in einer Datei zu speichern, ist implementiert. In der Praxis wird jedoch versucht, eine Szene in einer Datei zu speichern.
{ "scenes" : [ { "nodes" : [ 0 ] } ], "nodes" : [ { "mesh" : 0 } ], "scene": 0
Jeder Knoten ist ein „Einstiegspunkt“ zur Beschreibung einzelner Objekte. Wenn das Objekt komplex ist und aus mehreren Maschen besteht, wird ein solches Objekt durch die Knoten "Eltern" und "Kind" beschrieben. Beispielsweise kann ein Auto, das aus einer Karosserie und Rädern besteht, wie folgt beschrieben werden: Der Hauptknoten beschreibt das Auto und insbesondere seine Karosserie. Dieser Knoten enthält eine Liste von „untergeordneten Knoten“, die wiederum die verbleibenden Komponenten beschreiben, wie z. B. Räder. Alle Elemente werden rekursiv verarbeitet. Knoten können TRS-Animationen (Translation, Rotation, Scale aka Displacement, Rotation und Scaling) enthalten. Neben der Tatsache, dass solche Transformationen das Netz selbst direkt beeinflussen, wirken sie sich genauso auf untergeordnete Knoten aus. Zusätzlich zu all dem oben Genannten ist es erwähnenswert, dass die internen "Kameras", falls vorhanden, die für die Anzeige des Objekts im Rahmen für den Benutzer verantwortlich sind, auch an das Knotenobjekt angehängt sind. Objekte verweisen unter Verwendung der entsprechenden Attribute aufeinander: Szene hat ein Knotenattribut, ein Knotenobjekt hat ein Netzattribut. Zum einfacheren Verständnis sind alle oben genannten Punkte in der folgenden Abbildung dargestellt.

Buffer, BufferView und Accessor
Pufferobjekt bedeutet Speicherung von binären, unverarbeiteten Daten ohne Struktur, ohne Vererbung, ohne Wert. Der Puffer speichert Informationen zu Geometrie, Animationen und Skinning. Der Hauptvorteil von Binärdaten besteht darin, dass sie von der GPU äußerst effizient verarbeitet werden erfordern keine zusätzliche Analyse, außer möglicherweise Dekomprimierung. Die Daten im Puffer können durch das URI-Attribut gefunden werden, wodurch deutlich wird, wo sich die Daten befinden, und es gibt nur zwei Optionen: Entweder werden die Daten in einer externen Datei im .bin-Format gespeichert oder sie sind in JSON selbst eingebettet. Im ersten Fall enthält der URI einen Link zu einer externen Datei. In diesem Fall wird der Ordner, in dem sich die GLTF-Datei befindet, als Stammverzeichnis betrachtet. Im zweiten Fall hat die Datei das .glb-Format, was uns auf das kompaktere GLTF-Zwillingsbruder, das GLB-Format, in Bezug auf die Anzahl der Dateien verweist. Die Daten in der Binärdatei werden byteweise gespeichert.

JSON in unserem Dreiecksbeispiel sieht folgendermaßen aus:
Ein Beispiel für einen Base64-codierten Puffer:
"buffers" : [ { "uri" : "data:application/octet-stream;base64,AAABAAIAAAAAAAAAAAAAAAAAAAAAAIA/AAAAAAAAAAAAAAAAAACAPwAAAAA=", "byteLength" : 44 } ],
Wenn Sie eine externe Datei haben, konvertiert JSON die Ansicht in Folgendes:
"buffers" : [ { "uri" : "duck.bin", "byteLength" : 102040 } ],
Der Pufferblock verfügt außerdem über ein zusätzliches Attribut byteLength, in dem der Wert der Puffergröße gespeichert wird.
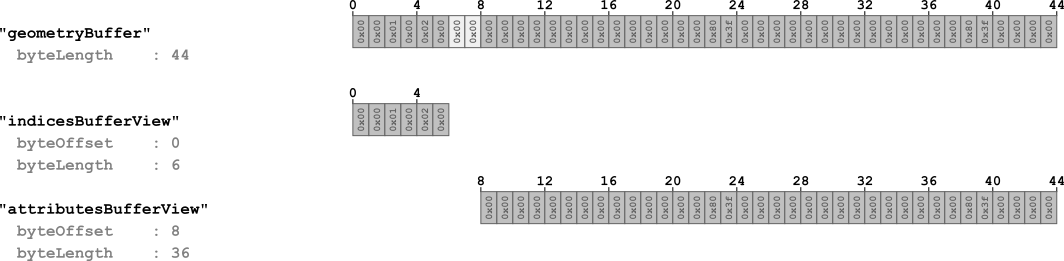
Der erste Schritt bei der Strukturierung der Daten aus dem Puffer ist das BufferView-Objekt. BufferView kann als "Informationsscheibe" von Buffer bezeichnet werden, die durch eine bestimmte Verschiebung von Bytes vom Anfang des Puffers gekennzeichnet ist. Dieses "Slice" wird anhand von zwei Attributen beschrieben: der Anzahl der "Verschiebungen" vom Anfang des Lesepuffers und der Länge des Slice selbst. Ein einfaches Beispiel für mehrere BufferView-Objekte zur Veranschaulichung ihrer Verwendung anhand unseres Beispiels:
"bufferViews" : [ { "buffer" : 0, "byteOffset" : 0, "byteLength" : 6, "target" : 34963 }, { "buffer" : 0, "byteOffset" : 8, "byteLength" : 36, "target" : 34962 } ],
Wie Sie sehen können, enthält dieses Beispiel 4 Hauptattribute:
- Der Puffer zeigt auf den Index des Puffers (die Sequenznummer im Pufferarray beginnt bei 0).
- byteOffset - definiert die "Verschiebung" des Ursprungs in Bytes für dieses "Slice"
- byteLength - definiert die Länge des "Slice"
- Ziel - Definiert den Datentyp, der in bufferView enthalten ist
Die erste BufferView enthält die ersten 6 Bytes des Puffers und hat keine Verschiebung. Beim zweiten „Slice“ ist alles etwas komplizierter: Wie Sie sehen, liegt die Verschiebung bei 8 MB anstelle des erwarteten sechsten. Diese 2 Bytes sind leer und wurden während des Puffergenerierungsprozesses dank eines Prozesses namens "Auffüllen" hinzugefügt. Der Wert muss den Wert der Grenzbytes auf 4 Bytes einstellen. Dieser Trick wird zum schnelleren und einfacheren Lesen von Daten aus dem Puffer benötigt.
Es lohnt sich, ein paar Worte über das Zielattribut zu sagen. Es wird verwendet, um den Informationstyp zu klassifizieren, auf den bufferView verweist. Es gibt nur zwei Optionen: Entweder ist es der Wert 34962, der verwendet wird, um auf die Scheitelpunktattribute (Scheitelpunktattribute - 34962 - ARRAY_BUFFER) zu verweisen, oder 34963, der für die Scheitelpunktindizes (Scheitelpunktindizes - 34963 - ELEMENT_ARRAY_BUFFER) verwendet wird. Der letzte Schliff für das Verständnis und die Strukturierung aller Informationen in Buffer ist das Accessor-Objekt.
Accessor ist ein Objekt, das auf BufferView zugreift und Attribute enthält, die den Typ und den Speicherort von Daten aus BufferView bestimmen. Der Accessor-Datentyp ist in type und componentType codiert. Der Wert des Typattributs ist eine Zeichenfolge und hat die folgenden Werte: SCALAR für Skalarwerte, VEC3 für dreidimensionale Vektoren und MAT4 für eine 4x4-Matrix oder das Quaternion, das zur Beschreibung der Rotation verwendet wird.
ComponentType gibt wiederum den Komponententyp dieser Daten an. Dies ist eine GL-Konstante, die Werte wie 5126 (FLOAT) oder 5123 (UNSIGNED_SHORT) haben kann, um beispielsweise anzuzeigen, dass die Elemente einen Gleitkomma usw. haben.
Verschiedene Kombinationen dieser Eigenschaften können verwendet werden, um beliebige Datentypen zu beschreiben. Ein Beispiel basierend auf unserem Dreieck.
"accessors" : [ { "bufferView" : 0, "byteOffset" : 0, "componentType" : 5123, "count" : 3, "type" : "SCALAR", "max" : [ 2 ], "min" : [ 0 ] }, { "bufferView" : 1, "byteOffset" : 0, "componentType" : 5126, "count" : 3, "type" : "VEC3", "max" : [ 1.0, 1.0, 0.0 ], "min" : [ 0.0, 0.0, 0.0 ] } ],
Lassen Sie uns die in JSON dargestellten Attribute analysieren:
- bufferView - Gibt die Sequenznummer der BufferView aus dem von Accessor verwendeten BufferView-Array an. BufferView speichert wiederum Informationen zu Indizes.
- byteOffset - Byteverschiebung , um mit dem Lesen von Daten vom aktuellen Accessor zu beginnen. Mehrere Accessor-Objekte können auf eine BufferView verweisen.
- componentType ist eine Konstante, die den Typ der Elemente angibt. Es kann Werte 5123 haben, die dem Datentyp UNSIGNED_SHORT entsprechen, oder 5126 für FLOAT.
- count - Zeigt an, wie viele Elemente im Puffer gespeichert sind.
- Typ - Definiert den Datentyp: Skalar, Vektor, Matrix.
- max und min - Attribute, die den minimalen und maximalen Wert der Position dieser Elemente im Raum bestimmen.
Mesh
Das Meshes- Objekt enthält Informationen zu den in der Szene befindlichen Meshes . Ein Knoten (Knotenobjekt) kann nur 1 Netz speichern. Jedes Objekt vom Typ mesh enthält ein Array vom Typ mesh.primitive Primitive wiederum sind primitive Objekte (z. B. Dreiecke), aus denen das Netz selbst besteht. Dieses Objekt enthält viele zusätzliche Attribute, aber all dies dient einem Zweck - der korrekten Speicherung von Informationen über die Anzeige des Objekts. Die Hauptattribute des Netzes:
- POSITION - Position der Eckpunkte entlang der XYZ-Achsen
- NORMAL - Normalisierte XYZ-Scheitelpunktnormalen
- TANGENT - XYZW-Tangenten von Eckpunkten. W gibt an, wohin die Tangente gerichtet ist und hat einen Wert von entweder +1 oder -1.
- TEXCOORD_0 - UV-Texturkoordinaten. Es können mehrere Sets gespeichert werden.
- COLOR_0 - RGB- oder RGBA-Farben von Eckpunkten.
- JOINTS_0 - Dieses Attribut enthält die Indizes der Gelenke / Gelenke aus dem entsprechenden Gelenkarray , die sich auf den Scheitelpunkt (Scheitelpunkt) auswirken sollten.
- WEIGHTS_0 - Die Daten dieses Attributs bestimmen die Gewichte, die angeben, wie stark das Gelenk den Scheitelpunkt beeinflusst.
- Gewichte - Attribut, das für die Morphing-Gewichte verantwortlich ist.
- material - enthält den Index, der die Anzahl der Materialien im Materials-Array angibt
Dieses Objekt hat für unseren Fall die folgende Form:
"meshes" : [ { "primitives" : [ { "attributes" : { "POSITION" : 1 }, "indices" : 0 } ] } ],
Leider passte aufgrund der Einschränkung nicht das gesamte Material in einen Artikel, sodass der Rest im zweiten Artikel zu finden ist , in dem wir die verbleibenden Artefakte betrachten: Material, Textur, Animationen, Haut und Kamera sowie eine minimal funktionierende GLTF-Datei sammeln.
Fortsetzung im 2. Teil: https://habr.com/en/post/448298/