Bei der Entwicklung eines Hochlastprodukts tritt manchmal die Situation auf, dass nicht so viele Anforderungen wie möglich verarbeitet werden müssen, sondern die Anzahl der Anforderungen pro Zeiteinheit begrenzt werden muss. In unserem Fall ist dies die Anzahl der Push-Benachrichtigungen, die an Endbenutzer gesendet werden. Lesen Sie mehr über Ratenbegrenzungsalgorithmen, ihre Vor- und Nachteile - unter dem Strich.
Zunächst ein wenig über uns. Pushwoosh ist ein B2B-Dienst für die Kommunikation zwischen unseren Kunden und ihren Benutzern. Wir bieten Unternehmen umfassende Lösungen für die Kommunikation mit Benutzern über Push-Benachrichtigungen, E-Mail und andere Kommunikationskanäle. Neben dem eigentlichen Senden von Nachrichten bieten wir Tools zum Segmentieren der Zielgruppe, Sammeln und Verarbeiten von Statistiken und vieles mehr. Zu diesem Zweck haben wir von Grund auf ein Hochlastprodukt an der Schnittstelle vieler Technologien entwickelt, von denen nur ein kleiner Teil PHP, Golang, PostgreSQL, MongoDB und Apache Kafka sind. Viele unserer Lösungen sind einzigartig, beispielsweise Hochgeschwindigkeitsbenachrichtigungen. Wir verarbeiten mehr als 2 Milliarden API-Anfragen pro Tag, wir haben mehr als 3 Milliarden Geräte in unserer Datenbank und über die gesamte Zeit haben wir mehr als 500 Milliarden Benachrichtigungen an diese Geräte gesendet.
Und hier kommen wir zu einer Situation, in der Benachrichtigungen nicht so schnell wie möglich (wie bei der bereits erwähnten Hochgeschwindigkeit) an Millionen von Geräten gesendet werden müssen, sondern die Geschwindigkeit künstlich begrenzen, damit die Server unserer Clients, zu denen Benutzer gehen, wenn sie die Benachrichtigung öffnen, nicht unter dieselbe Zeit fallen laden.
Hier helfen uns verschiedene Algorithmen zur Ratenbegrenzung, mit denen wir die Anzahl der Anforderungen pro Zeiteinheit begrenzen können. In der Regel wird dies beispielsweise beim Entwerfen einer API verwendet, da wir auf diese Weise das System vor versehentlichem oder böswilligem Übermaß an Anforderungen schützen können, wodurch eine Verzögerung oder ein Denial-of-Service für andere Clients auftritt. Wenn eine Ratenbegrenzung implementiert ist, sind alle Clients auf eine feste Anzahl von Anforderungen pro Zeiteinheit beschränkt. Darüber hinaus kann die Ratenbegrenzung verwendet werden, wenn auf Teile des Systems zugegriffen wird, die vertraulichen Daten zugeordnet sind. Wenn ein Angreifer Zugriff auf sie erhält, kann er nicht schnell auf alle Daten zugreifen.
Es gibt viele verschiedene Möglichkeiten, eine Ratenbegrenzung zu implementieren. In diesem Artikel werden die Vor- und Nachteile verschiedener Algorithmen sowie die Probleme betrachtet, die bei der Skalierung dieser Lösungen auftreten können.
Algorithmen zur Geschwindigkeitsbegrenzung für die Anforderungsverarbeitung
Undichter Eimer (undichter Eimer)
Leaky Bucket ist ein Algorithmus, der den einfachsten und intuitivsten Ansatz zur Begrenzung der Verarbeitungsgeschwindigkeit mithilfe einer Warteschlange bietet, die als "Bucket" mit Anforderungen dargestellt werden kann. Wenn eine Anfrage empfangen wird, wird sie am Ende der Warteschlange hinzugefügt. In regelmäßigen Abständen wird das erste Element in der Warteschlange verarbeitet. Dies wird auch als FIFO- Warteschlange bezeichnet. Wenn die Warteschlange voll ist, werden zusätzliche Anforderungen verworfen (oder "Leck").

Der Vorteil dieses Algorithmus besteht darin, dass er Ausbrüche glättet und Anforderungen mit ungefähr derselben Geschwindigkeit verarbeitet. Er ist einfach auf einem einzelnen Server oder Load Balancer zu implementieren und effizient im Speicher zu verwenden, da die Warteschlangengröße für jeden Benutzer begrenzt ist.
Bei einem starken Anstieg des Datenverkehrs kann die Warteschlange jedoch mit alten Anforderungen gefüllt sein und dem System die Möglichkeit nehmen, neuere Anforderungen zu verarbeiten. Er garantiert auch nicht, dass Anfragen zu einem festgelegten Zeitpunkt bearbeitet werden. Wenn Sie Balancer laden, um Fehlertoleranz bereitzustellen oder den Durchsatz zu erhöhen, müssen Sie außerdem eine Koordinierungsrichtlinie implementieren und eine globale Einschränkung zwischen ihnen sicherstellen.
Es gibt eine Variation dieses Algorithmus - Token Bucket ("Bucket with Token" oder "Marker Basket Algorithmus").
In einer solchen Implementierung werden Token mit einer konstanten Geschwindigkeit zum "Bucket" hinzugefügt, und bei der Verarbeitung der Anforderung wird das Token aus dem "Bucket" gelöscht. Wenn nicht genügend Token vorhanden sind, wird die Anforderung verworfen. Sie können den Zeitstempel einfach als Token verwenden.
Es gibt Variationen, bei denen mehrere "Eimer" verwendet werden, während sowohl die Größe als auch die Empfangsrate der darin enthaltenen Token für einzelne "Eimer" unterschiedlich sein können. Wenn im ersten "Bucket" nicht genügend Token vorhanden sind, um die Anforderung zu verarbeiten, wird deren Vorhandensein im zweiten usw. überprüft, aber die Priorität der Anforderungsverarbeitung wird verringert (dies wird in der Regel beim Entwurf von Netzwerkschnittstellen verwendet, wenn Sie beispielsweise den Feldwert ändern können DSCP- verarbeitetes Paket).
Der Hauptunterschied zur Implementierung von Leaky Bucket besteht darin, dass sich Token ansammeln können, wenn das System inaktiv ist, und Bursts später auftreten können, während die Anforderungen verarbeitet werden (da genügend Token vorhanden sind), während Leaky Bucket die Last garantiert glättet auch bei Ausfallzeiten.
Festes Fenster
Dieser Algorithmus verwendet ein Fenster von n Sekunden, um Anforderungen zu verfolgen. In der Regel werden Werte wie 60 Sekunden (Minute) oder 3600 Sekunden (Stunde) verwendet. Jede eingehende Anfrage erhöht den Zähler für dieses Fenster. Wenn der Zähler einen bestimmten Schwellenwert überschreitet, wird die Anforderung verworfen. In der Regel wird das Fenster durch die untere Grenze des aktuellen Zeitintervalls bestimmt. Wenn das Fenster also 60 Sekunden breit ist, wird die um 12:00:03 Uhr eintreffende Anforderung an das Fenster 12:00:00 Uhr gesendet.
Der Vorteil dieses Algorithmus besteht darin, dass er die Verarbeitung neuerer Anforderungen ermöglicht, ohne von der Verarbeitung alter Anforderungen abhängig zu sein. Ein einzelner Verkehrsstoß in der Nähe des Fensterrahmens kann jedoch die Anzahl der verarbeiteten Anforderungen verdoppeln, da Anforderungen für das aktuelle und das nächste Fenster für einen kurzen Zeitraum zulässig sind. Wenn viele Benutzer beispielsweise am Ende der Stunde auf das Zurücksetzen des Fensterzählers warten, können sie zu diesem Zeitpunkt eine Erhöhung der Last provozieren, da sie gleichzeitig auf die API zugreifen.
Schiebeprotokoll
Dieser Algorithmus beinhaltet das Verfolgen von Zeitstempeln jeder Benutzeranforderung. Diese Datensätze werden beispielsweise in einem Hash-Set oder einer Hash-Tabelle gespeichert und nach Zeit sortiert. Datensätze außerhalb des überwachten Intervalls werden verworfen. Wenn eine neue Anfrage eingeht, berechnen wir die Anzahl der Datensätze, um die Häufigkeit der Anfragen zu bestimmen. Wenn die Anforderung außerhalb der zulässigen Menge liegt, wird sie verworfen.
Der Vorteil dieses Algorithmus besteht darin, dass er keinen Problemen unterliegt, die an den Rändern des festen Fensters auftreten , dh die Geschwindigkeitsbegrenzung wird strikt eingehalten. Da die Anforderungen jedes Clients einzeln überwacht werden, gibt es außerdem an bestimmten Punkten kein Spitzenlastwachstum, was ein weiteres Problem des vorherigen Algorithmus darstellt.
Das Speichern von Informationen zu jeder Anforderung kann jedoch teuer sein. Darüber hinaus muss für jede Anforderung die Anzahl der vorherigen Anforderungen berechnet werden, möglicherweise für den gesamten Cluster. Infolgedessen lässt sich dieser Ansatz nicht gut skalieren, um große Verkehrsstöße und Denial-of-Service-Angriffe zu bewältigen.
Schiebefenster
Dies ist ein hybrider Ansatz, der die geringen Kosten für die Verarbeitung eines festen Fensters und die erweiterte Behandlung von Grenzsituationen kombiniert. Wie im einfachen festen Fenster verfolgen wir den Zähler für jedes Fenster und berücksichtigen dann den gewichteten Wert der Anforderungshäufigkeit des vorherigen Fensters basierend auf dem aktuellen Zeitstempel, um Verkehrsstöße auszugleichen. Wenn beispielsweise 25% der Zeit des aktuellen Fensters vergangen sind, berücksichtigen wir 75% der Anforderungen des vorherigen Fensters. Die relativ geringe Datenmenge, die für die Verfolgung der einzelnen Schlüssel benötigt wird, ermöglicht es uns, in einem großen Cluster zu skalieren und zu arbeiten.

Mit diesem Algorithmus können Sie die Ratenbegrenzung skalieren und gleichzeitig eine gute Leistung erzielen. Darüber hinaus ist dies eine verständliche Möglichkeit, Kunden Informationen zur Begrenzung der Anzahl von Anforderungen zu übermitteln und die Probleme zu vermeiden, die bei der Implementierung anderer Algorithmen zur Ratenbegrenzung auftreten.
Ratenbegrenzung in verteilten Systemen
Richtlinien synchronisieren
Wenn Sie beim Zugriff auf einen Cluster, der aus mehreren Knoten besteht, die globale Ratenbegrenzung festlegen möchten, müssen Sie eine Einschränkungsrichtlinie implementieren. Wenn jeder Knoten nur seine eigene Einschränkung verfolgt, kann der Benutzer diese umgehen, indem er einfach Anforderungen an verschiedene Knoten sendet. Je größer die Anzahl der Knoten ist, desto größer ist die Wahrscheinlichkeit, dass der Benutzer das globale Limit überschreiten kann.
Der einfachste Weg, Limits festzulegen, besteht darin, eine „Sticky-Sitzung“ auf dem Balancer so zu konfigurieren, dass der Benutzer zum selben Knoten geleitet wird. Die Nachteile dieser Methode sind das Fehlen von Fehlertoleranz und Skalierungsproblemen, wenn Clusterknoten überlastet sind.
Die beste Lösung, die flexiblere Regeln für den Lastausgleich ermöglicht, ist die Verwendung eines zentralen Data Warehouse (Ihrer Wahl). Es kann Zähler für die Anzahl der Anforderungen für jedes Fenster und jeden Benutzer speichern. Die Hauptprobleme dieses Ansatzes sind die Verlängerung der Antwortzeit aufgrund von Speicheranforderungen und Rennbedingungen.
Rennbedingungen
Eines der größten Probleme bei einem zentralen Data Warehouse ist die Möglichkeit von Rennbedingungen im Wettbewerb. Dies geschieht, wenn Sie den natürlichen Get-Then-Set-Ansatz verwenden, bei dem Sie den aktuellen Zähler extrahieren, inkrementieren und dann den resultierenden Wert an den Speicher zurücksenden. Das Problem bei diesem Modell besteht darin, dass während der Zeit, die erforderlich ist, um den vollständigen Zyklus dieser Operationen abzuschließen (dh Lesen, Inkrementieren und Schreiben), andere Anforderungen eingehen können, bei denen der Zähler jeweils mit einem ungültigen (niedrigeren) Wert gespeichert wird. Auf diese Weise kann der Benutzer mehr Anforderungen senden, als der Algorithmus zur Ratenbegrenzung bereitstellt.
Eine Möglichkeit, dieses Problem zu vermeiden, besteht darin, eine Sperre um den betreffenden Schlüssel zu setzen, um den Zugriff auf das Lesen oder Schreiben anderer Prozesse auf den Zähler zu verhindern. Dies kann jedoch schnell zu einem Leistungsengpass werden und lässt sich nicht gut skalieren, insbesondere wenn Remote-Server wie Redis als zusätzlicher Datenspeicher verwendet werden.
Ein viel besserer Ansatz ist set-then-get, der sich auf atomare Operatoren stützt, mit denen Sie den Zähler schnell inkrementieren und überprüfen können, ohne die atomaren Operationen zu beeinträchtigen.
Leistungsoptimierung
Ein weiterer Nachteil der Verwendung eines zentralen Data Warehouse ist die Verlängerung der Antwortzeit aufgrund der Verzögerung bei der Überprüfung der Zähler, die zur Implementierung der Ratenbegrenzung verwendet werden ( Umlaufzeit oder „Umlaufverzögerung“). Leider führt selbst die Überprüfung auf schnellen Speicher wie Redis zu zusätzlichen Verzögerungen von einigen Millisekunden pro Anforderung.
Um die Definition einer Einschränkung mit einer minimalen Verzögerung vorzunehmen, müssen Überprüfungen im lokalen Speicher durchgeführt werden. Dies kann erreicht werden, indem die Bedingungen für die Überprüfung der Geschwindigkeit gelockert und schließlich ein konsistentes Modell verwendet wird.
Beispielsweise kann jeder Knoten einen Datensynchronisationszyklus erstellen, in dem er mit dem Repository synchronisiert wird. Jeder Knoten überträgt regelmäßig den Zählerwert für jeden Benutzer und das betroffene Fenster an den Speicher, der die Werte atomar aktualisiert. Dann kann der Knoten neue Werte empfangen und Daten im lokalen Speicher aktualisieren. Dieser Zyklus ermöglicht es schließlich, dass alle Knoten im Cluster auf dem neuesten Stand sind.
Der Zeitraum, in dem die Knoten synchronisiert werden, muss anpassbar sein. Kürzere Synchronisationsintervalle führen zu einer geringeren Datenabweichung, wenn die Last gleichmäßig auf mehrere Knoten des Clusters verteilt ist (z. B. wenn der Balancer die Knoten nach dem Round-Robin-Prinzip ermittelt), während längere Intervalle weniger Lese- / Schreiblast für den Speicher verursachen und reduzieren Sie die Kosten an jedem Knoten, um synchronisierte Daten zu empfangen.
Vergleich von Ratenbegrenzungsalgorithmen
Insbesondere sollten wir in unserem Fall keine Clientanforderungen für die API ablehnen, sondern sie auf der Grundlage von Daten nicht erstellen. Wir haben jedoch kein Recht, Anfragen zu "verlieren". Zu diesem Zweck verwenden wir beim Senden einer Benachrichtigung den Parameter send_rate, der die maximale Anzahl von Benachrichtigungen angibt, die beim Senden pro Sekunde gesendet werden.
Wir haben also einen bestimmten Worker, der die Arbeit in der zugewiesenen Zeit ausführt (in meinem Beispiel das Lesen aus einer Datei), der die RateLimitingInterface-Schnittstelle als Eingabe empfängt und angibt, ob eine Anforderung zu einem bestimmten Zeitpunkt ausgeführt werden kann und wie lange sie ausgeführt wird.
interface RateLimitingInterface { public function __construct(int $rate); public function canDoWork(float $currentTime): bool; }
Alle Codebeispiele finden Sie hier auf GitHub.
Ich werde sofort erklären, warum Sie eine Zeitscheibe an Worker übertragen müssen. Tatsache ist, dass es zu teuer ist, einen separaten Daemon auszuführen, um das Senden einer Nachricht mit einer Geschwindigkeitsbegrenzung zu verarbeiten. Daher wird send_rate tatsächlich als Parameter „Anzahl der Benachrichtigungen pro Zeiteinheit“ verwendet, der je nach Auslastung zwischen 0,01 und 1 Sekunde liegt.
Tatsächlich verarbeiten wir bis zu 100 verschiedene Anforderungen mit send_rate pro Sekunde und weisen 1 / N Sekunden für jedes Zeitquantum zu, wobei N die Anzahl der von diesem Dämon verarbeiteten Pushs ist. Der Parameter, an dem wir während der Verarbeitung am meisten interessiert sind, ist, ob send_rate eingehalten wird (kleine Fehler sind in die eine oder andere Richtung zulässig) und die Belastung unserer Hardware (minimale Anzahl von Zugriffen auf Speicher, CPU und Speicherverbrauch).
Lassen Sie uns zunächst herausfinden, zu welchen Zeitpunkten Worker wirklich funktioniert. In diesem Beispiel wurde der Einfachheit halber eine Datei mit 10.000 Zeilen mit send_rate = 1000 verarbeitet (dh wir lesen 1000 Zeilen pro Sekunde aus der Datei).
In den Screenshots markieren Markierungen die Momente und die Anzahl der Fgets-Aufrufe für alle Algorithmen. In der Realität kann dies ein Aufruf an eine Datenbank, eine Ressource eines Drittanbieters oder andere Abfragen sein, deren Anzahl wir pro Zeiteinheit begrenzen möchten.
Auf der X-Skala - die Zeit vom Beginn der Verarbeitung an, von 0 bis 10 Sekunden, wird jede Sekunde in Zehntel unterteilt, sodass der Zeitplan von 0 bis 100 reicht).
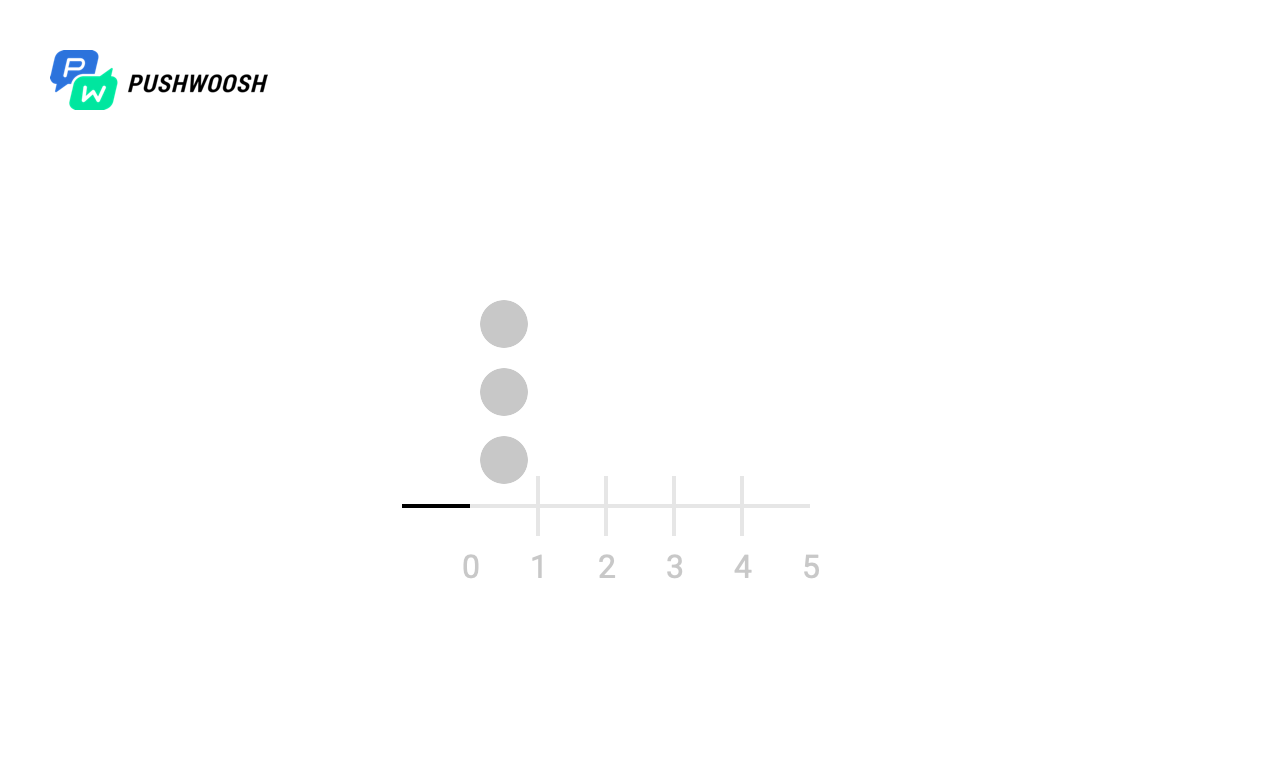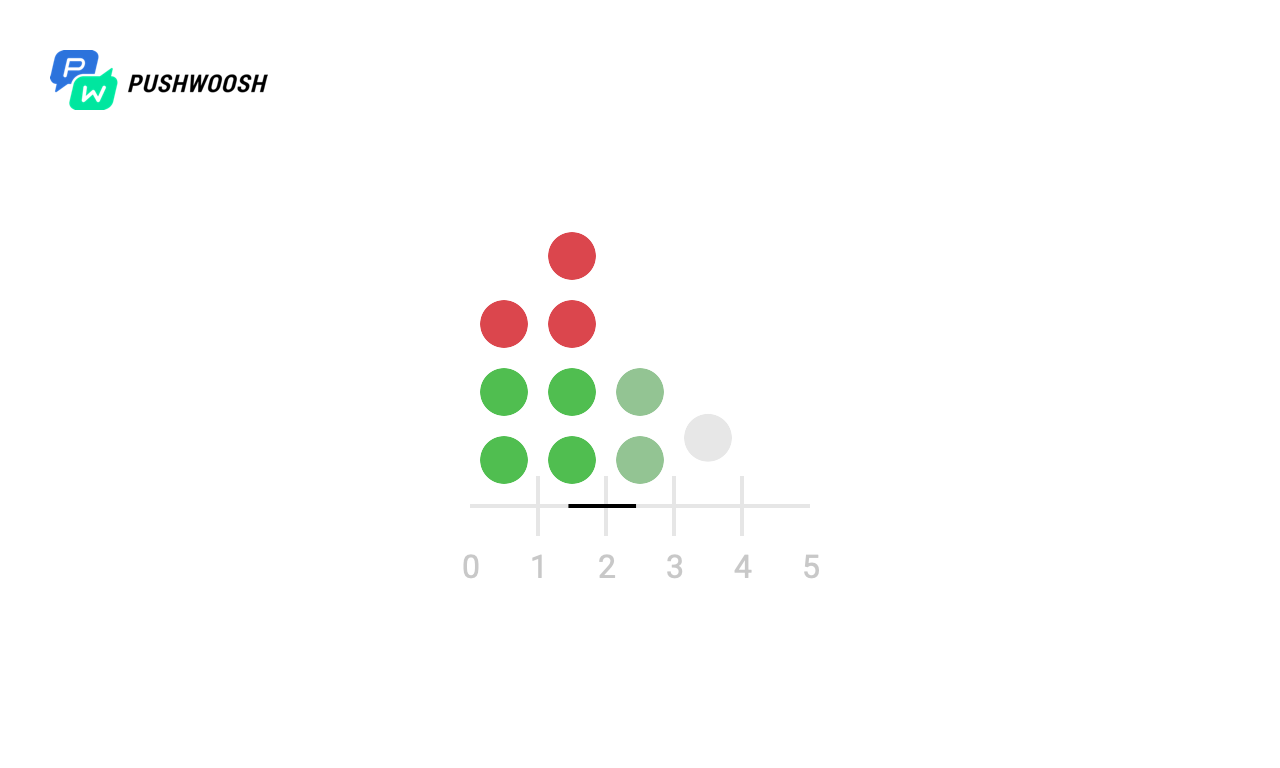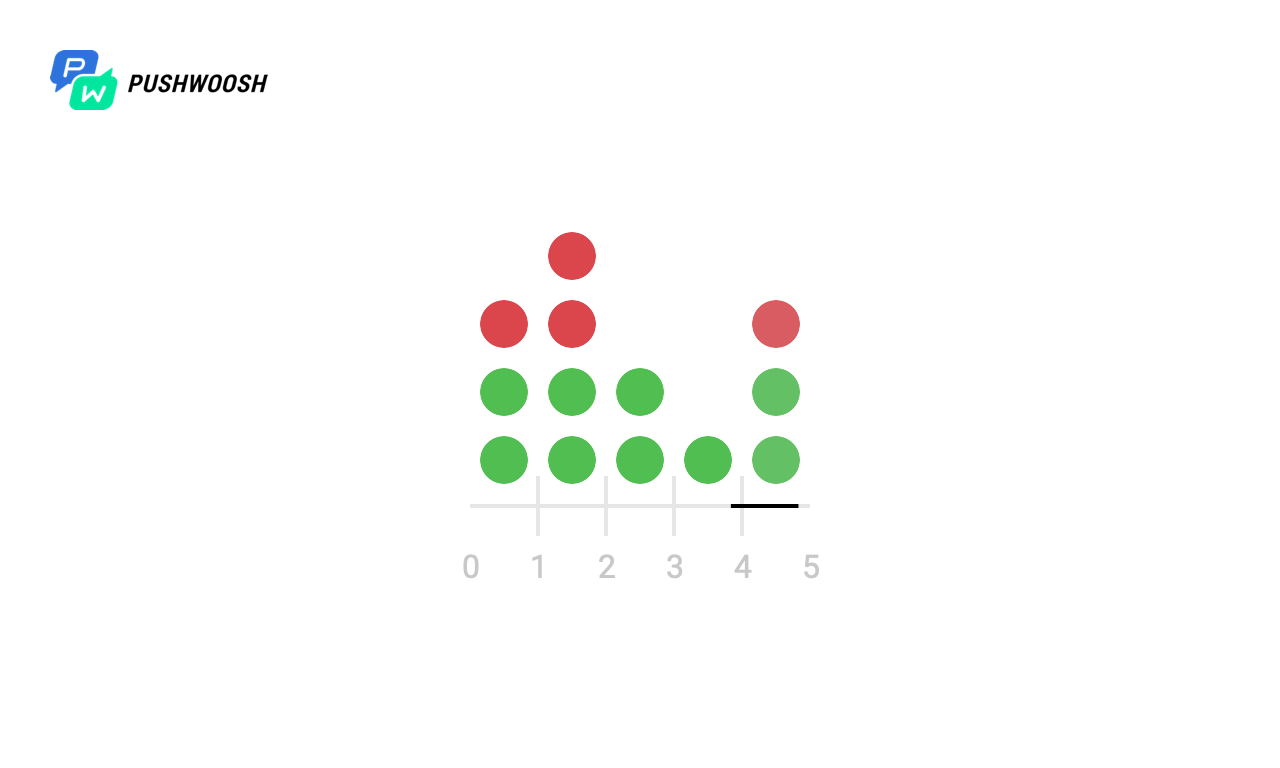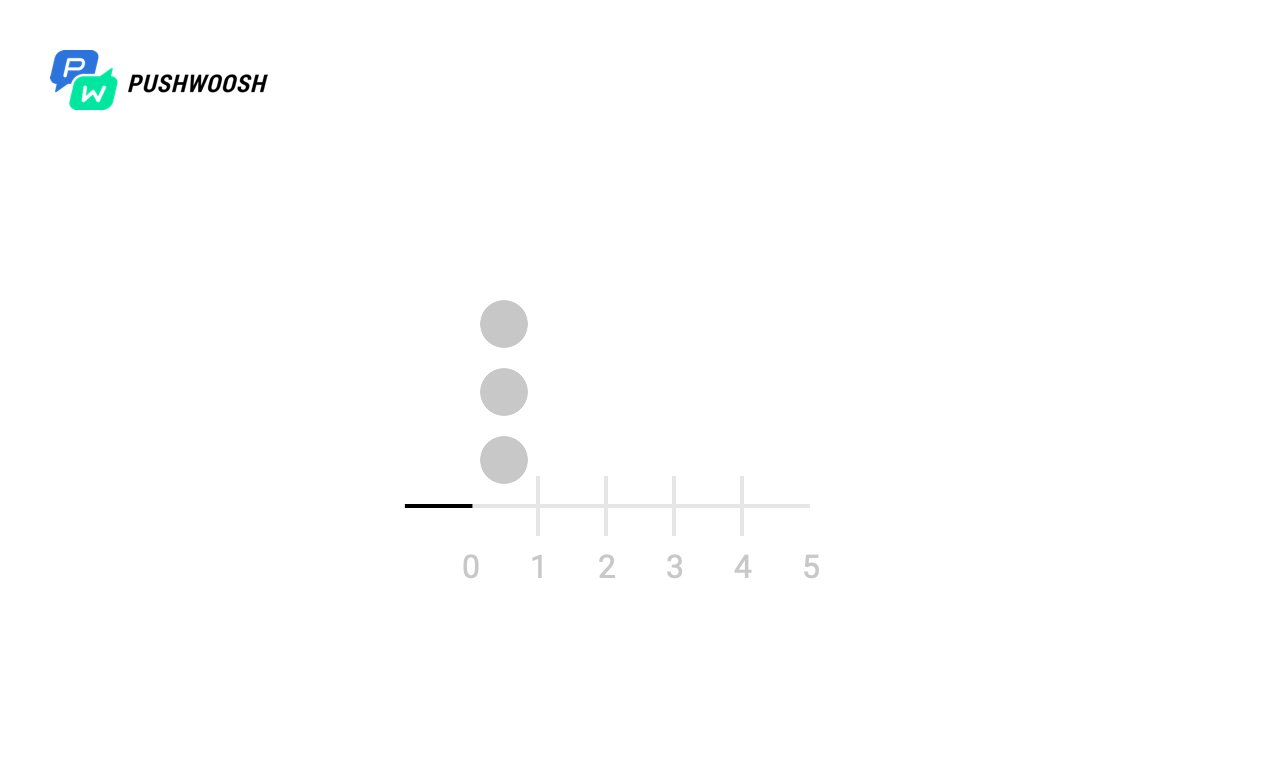
Wir sehen, dass trotz der Tatsache, dass alle Algorithmen die Einhaltung von send_rate bewältigen (dafür sind sie vorgesehen), das feste Fenster und das Schiebeprotokoll die gesamte Last fast gleichzeitig "ausgeben", was für uns nicht sehr geeignet ist, während Token Bucket und Sliding Windows verteilt es gleichmäßig pro Zeiteinheit (mit Ausnahme der Spitzenlast zum Zeitpunkt des Starts, da zu früheren Zeitpunkten keine Daten über die Last vorliegen).
Aufgrund der Tatsache, dass der Code in der Realität normalerweise nicht mit dem lokalen Dateisystem funktioniert, aber bei einem Speicher eines Drittanbieters die Antwort verzögert sein kann, Netzwerkprobleme und viele andere Probleme auftreten können, werden wir versuchen zu überprüfen, wie sich dieser oder jener Algorithmus verhält, wenn Anforderungen einige Zeit dauern war nicht. Zum Beispiel nach 4 und 6 Sekunden.
Hier scheint es, dass das feste Fenster nicht richtig funktioniert und 2-mal mehr als die erwarteten Anforderungen in der ersten und von 7 bis 8 Sekunden verarbeitet hat. Dies ist jedoch nicht der Fall, da die Zeit ab dem Zeitpunkt des Starts im Diagramm gezählt wird und der Algorithmus den aktuellen Unix-Zeitstempel verwendet .
Im Allgemeinen hat sich nichts grundlegend geändert, aber wir sehen, dass der Token Bucket die Last reibungsloser glättet und niemals das angegebene Ratenlimit überschreitet, aber das Gleitprotokoll im Falle von Ausfallzeiten den zulässigen Wert überschreiten kann.
Fazit
Wir haben alle grundlegenden Algorithmen zur Implementierung der Ratenbegrenzung untersucht, von denen jeder seine Vor- und Nachteile hat und für verschiedene Aufgaben geeignet ist. Wir hoffen, dass Sie nach dem Lesen dieses Artikels den am besten geeigneten Algorithmus zur Lösung Ihres Problems auswählen.