Hola! Wir setzen eine Reihe von Veröffentlichungen fort, die dem Start des Kurses
"Webentwickler in Python" gewidmet sind, und teilen Ihnen derzeit die Übersetzung eines weiteren interessanten Artikels mit.
Bei Zendesk verwenden wir Python, um Produkte für maschinelles Lernen zu erstellen. In Anwendungen für maschinelles Lernen sind Speicherverluste und -spitzen eines der häufigsten Probleme, auf die wir gestoßen sind. Python-Code wird normalerweise in Containern mit verteilten Verarbeitungsframeworks wie
Hadoop ,
Spark und
AWS Batch ausgeführt . Jedem Container wird eine feste Speichermenge zugewiesen. Sobald die Codeausführung das angegebene Speicherlimit überschreitet, funktioniert der Container aufgrund von Fehlern, die aufgrund von Speichermangel auftreten, nicht mehr.

Sie können das Problem schnell beheben, indem Sie noch mehr Speicher zuweisen. Dies kann jedoch zu Ressourcenverschwendung führen und die Stabilität von Anwendungen aufgrund unvorhersehbarer Speicherausbrüche beeinträchtigen. Die Ursachen für einen Speicherverlust können
folgende sein :
- Lange Speicherung großer Objekte, die nicht gelöscht werden;
- Loopback-Links im Code;
- Basis-C-Bibliotheken / -Erweiterungen, die zu einem Speicherverlust führen;
Es wird empfohlen, die Speichernutzung mit Anwendungen zu profilieren, um ein besseres Verständnis der Effizienz des verwendeten Codebereichs und der verwendeten Pakete zu erhalten.
Dieser Artikel beschreibt die folgenden Aspekte:
- Profilierung der Nutzung des Anwendungsspeichers im Laufe der Zeit;
- So überprüfen Sie die Speichernutzung in einem bestimmten Teil des Programms;
- Tipps zum Debuggen von Fehlern aufgrund von Speicherproblemen.
Speicherprofilierung im Laufe der ZeitMit dem
Speicherprofiler- Paket können Sie einen Blick auf die variable Speichernutzung während der Ausführung eines Python-Programms werfen.
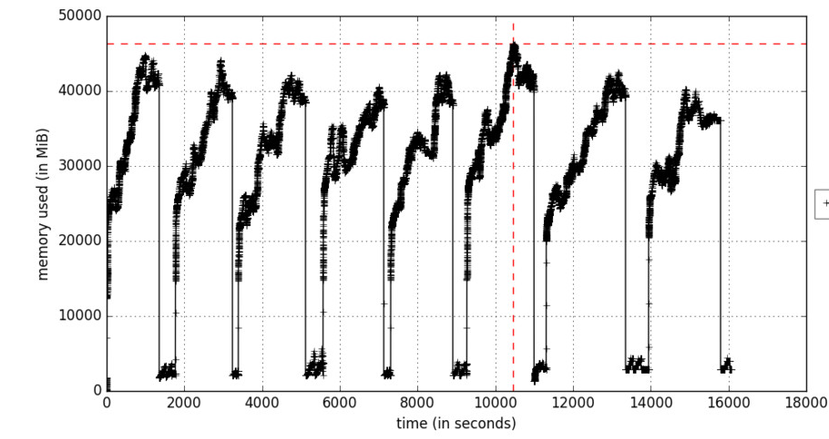 Abbildung A. Speicherprofilierung als Funktion der Zeit
Abbildung A. Speicherprofilierung als Funktion der ZeitDie
Option include-children aktiviert die Speichernutzung durch alle untergeordneten Prozesse, die von übergeordneten Prozessen erzeugt werden. Abbildung A spiegelt den iterativen Lernprozess wider, bei dem der Speicher in den Momenten, in denen Trainingsdatenpakete verarbeitet werden, in Zyklen zunimmt. Objekte werden während der Speicherbereinigung gelöscht.
Wenn die Speichernutzung ständig zunimmt, wird dies als potenzielle Gefahr eines Speicherverlusts angesehen.
Hier ist ein Beispielcode, der dies widerspiegelt:
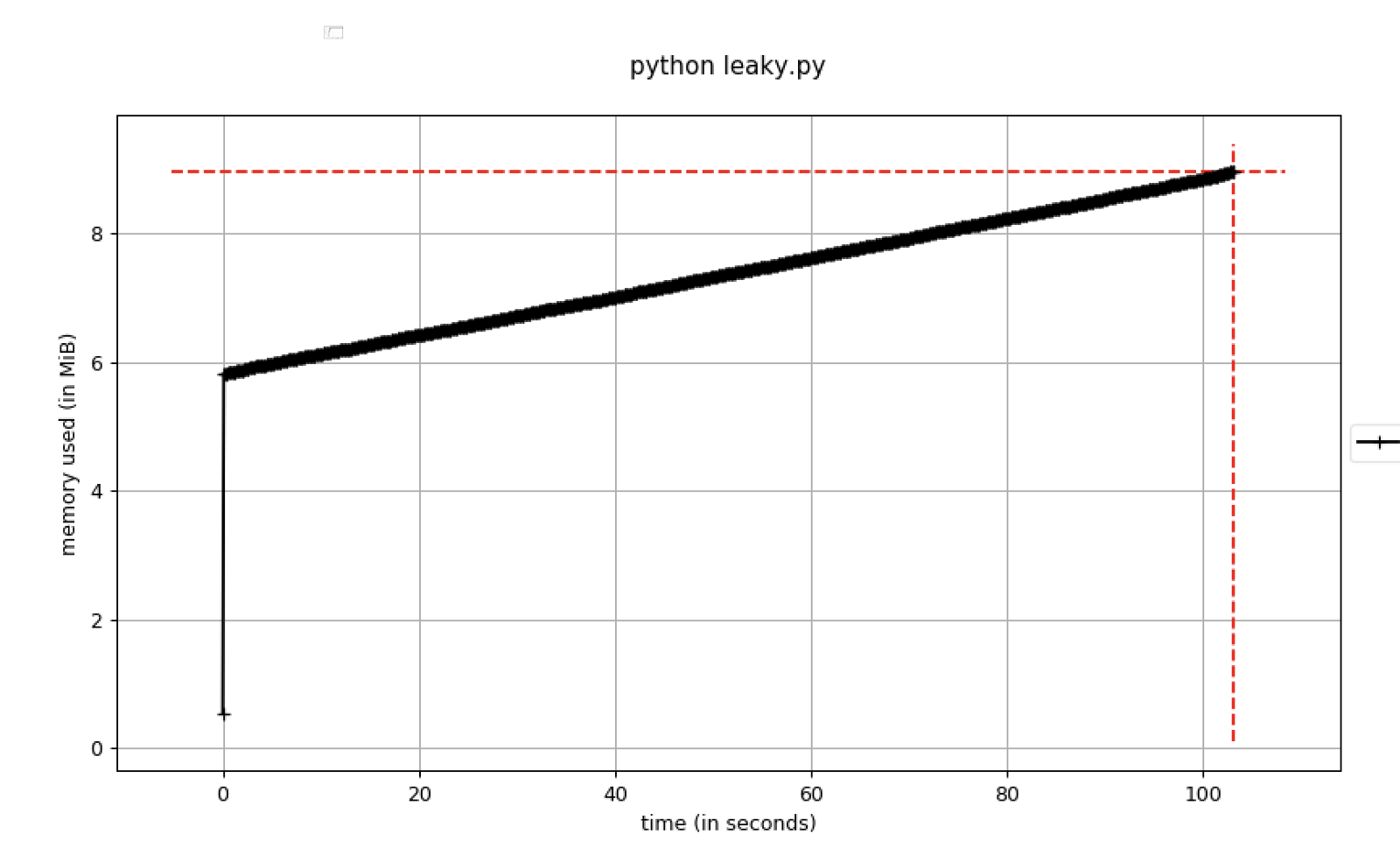 Abbildung B. Mit der Zeit zunehmende Speichernutzung
Abbildung B. Mit der Zeit zunehmende SpeichernutzungSie sollten Haltepunkte im Debugger festlegen, sobald die Speichernutzung einen bestimmten Schwellenwert überschreitet. Zu diesem
Zweck können Sie den Parameter pdb-mmem verwenden , der bei der Fehlerbehebung
hilfreich ist.
Speicherauszug zu einem bestimmten ZeitpunktEs ist nützlich, die erwartete Anzahl großer Objekte im Programm zu schätzen und zu bestimmen, ob sie dupliziert und / oder in verschiedene Formate konvertiert werden sollen.
Zur weiteren Analyse von Objekten im Speicher können Sie mit
muppy einen Dump-Heap in bestimmten Programmzeilen
erstellen .
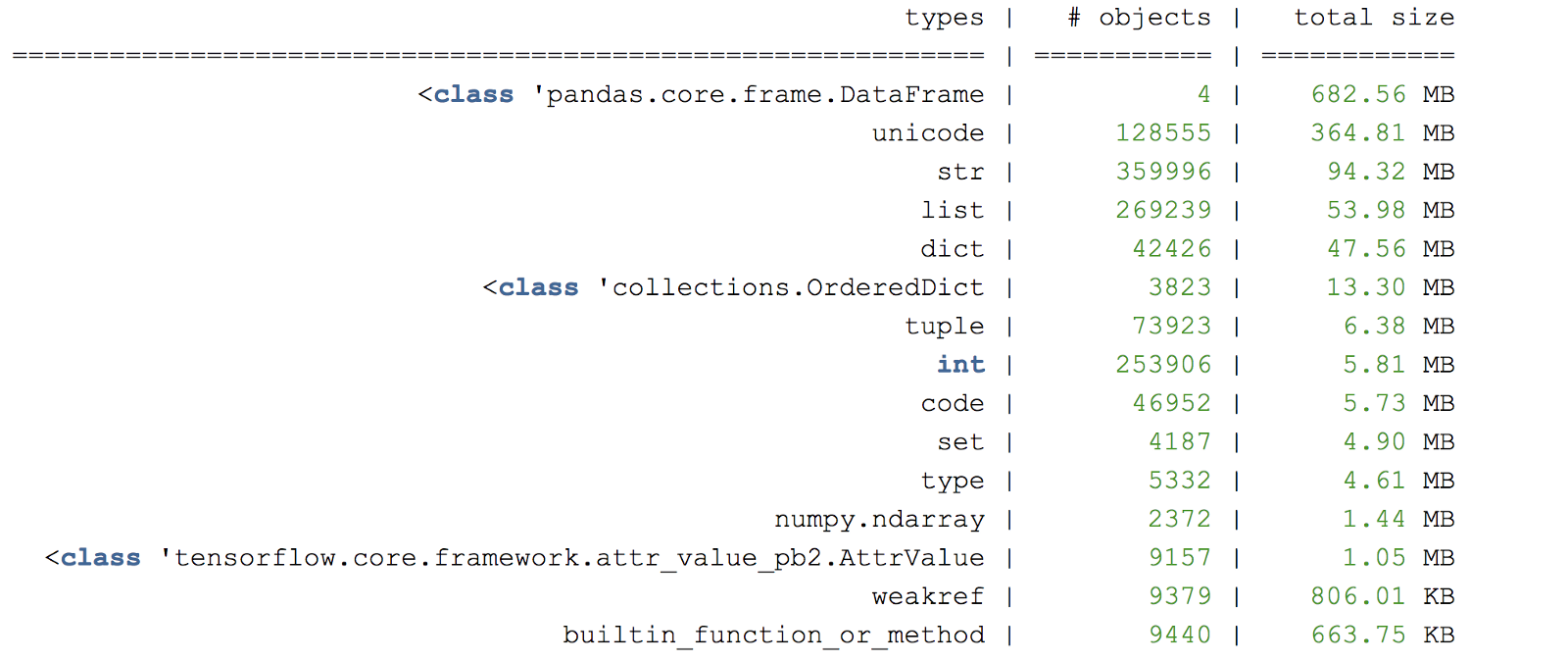 Abbildung C. Beispiel-Dump-Heap-Dump
Abbildung C. Beispiel-Dump-Heap-DumpEine weitere nützliche Bibliothek zur Speicherprofilerstellung ist
objgraph , mit der Sie Diagramme
erstellen können , um den Ursprung von Objekten zu überprüfen.
Nützliche HinweiseEin nützlicher Ansatz besteht darin, einen kleinen „Testfall“ zu erstellen, in dem der entsprechende Code ausgeführt wird, der einen Speicherverlust verursacht. Erwägen Sie die Verwendung einer Teilmenge zufällig ausgewählter Daten, wenn die Verarbeitung der vollständigen Eingabe lange dauert.
Führen Sie Aufgaben mit hoher Speicherlast in einem separaten Prozess ausPython gibt nicht unbedingt sofort Speicher für das Betriebssystem frei. Um sicherzustellen, dass der Speicher freigegeben wurde, müssen Sie nach dem Ausführen eines Codeteils einen separaten Prozess starten. Weitere Informationen zum Garbage Collector in Python finden Sie
hier .
Der Debugger kann Verweise auf Objekte hinzufügen.Wenn Sie einen Haltepunkt-Debugger wie
pdb verwenden ,
verbleiben alle erstellten Objekte, auf die der Debugger manuell verweist, im Speicher. Dies kann zu einem falschen Gefühl von Speicherverlust führen, da Objekte nicht rechtzeitig gelöscht werden.
Achten Sie auf Pakete, die zu Speicherverlusten führen können.Einige Bibliotheken in Python können möglicherweise ein Leck verursachen, z. B. haben
pandas mehrere bekannte Probleme mit
Speicherverlusten .
Gute Suche nach Lecks!
Nützliche Links:docs.python.org/3/c-api/memory.htmldocs.python.org/3/library/debug.htmlSchreiben Sie in die Kommentare, ob dieser Artikel für Sie nützlich war. Und wer mehr über unseren Kurs erfahren möchte, lädt Sie zum
Tag der
offenen Tür ein , der am 22. April stattfinden wird.