Hallo, ich bin Sergey Elantsev und entwickle einen
Netzwerklastenausgleich in Yandex.Cloud. Zuvor leitete ich die Entwicklung des L7-Balancers des Yandex-Portals - meine Kollegen scherzen, dass ich unabhängig von meiner Tätigkeit einen Balancer bekomme. Ich werde den Lesern von Habr erklären, wie die Last in der Cloud-Plattform verwaltet wird, wie wir das ideale Tool zur Erreichung dieses Ziels sehen und wie wir dieses Tool entwickeln.
Zunächst stellen wir einige Begriffe vor:
- VIP (Virtual IP) - Balancer-IP-Adresse
- Server, Backend, Instanz - eine virtuelle Maschine, auf der eine Anwendung ausgeführt wird
- RIP (Real IP) - Server-IP-Adresse
- Healthcheck - Serververfügbarkeitsprüfung
- Availability Zone, AZ - isolierte Infrastruktur im Rechenzentrum
- Region - die Vereinigung verschiedener AZ
Load Balancer lösen drei Hauptaufgaben: Sie führen den Ausgleich selbst durch, verbessern die Fehlertoleranz des Dienstes und vereinfachen dessen Skalierung. Die Fehlertoleranz wird durch die automatische Verkehrssteuerung sichergestellt: Der Balancer überwacht den Status der Anwendung und schließt Instanzen vom Balancing aus, die den Lebendigkeitstest nicht bestehen. Die Skalierung wird durch eine gleichmäßige Lastverteilung auf die Instanzen sowie durch die Aktualisierung der Liste der Instanzen im laufenden Betrieb sichergestellt. Wenn der Ausgleich nicht einheitlich genug ist, erhalten einige Instanzen eine Last, die ihre Arbeitskapazitätsgrenze überschreitet, und der Dienst wird weniger zuverlässig.
Der Load Balancer wird häufig nach Protokollebene aus dem OSI-Modell klassifiziert, auf dem er ausgeführt wird. Der Cloud Balancer arbeitet auf der TCP-Ebene, die der vierten Ebene, L4, entspricht.
Kommen wir zu einem Überblick über die Cloud-Balancer-Architektur. Wir werden den Detaillierungsgrad schrittweise erhöhen. Wir teilen die Balancer-Komponenten in drei Klassen ein. Die Konfigurationsebenenklasse ist für die Benutzerinteraktion verantwortlich und speichert den Zielstatus des Systems. Die Steuerebene speichert den aktuellen Status des Systems und verwaltet Systeme aus der Datenebenenklasse, die direkt für die Übermittlung des Datenverkehrs von Clients an Ihre Instanzen verantwortlich sind.
Datenebene
Der Datenverkehr fällt auf teure Geräte, die als Grenzrouter bezeichnet werden. Um die Fehlertoleranz zu erhöhen, arbeiten mehrere solcher Geräte gleichzeitig in einem Rechenzentrum. Anschließend wird der Datenverkehr an Balancer weitergeleitet, die allen AZs über BGP eine Anycast-IP-Adresse für Clients mitteilen.
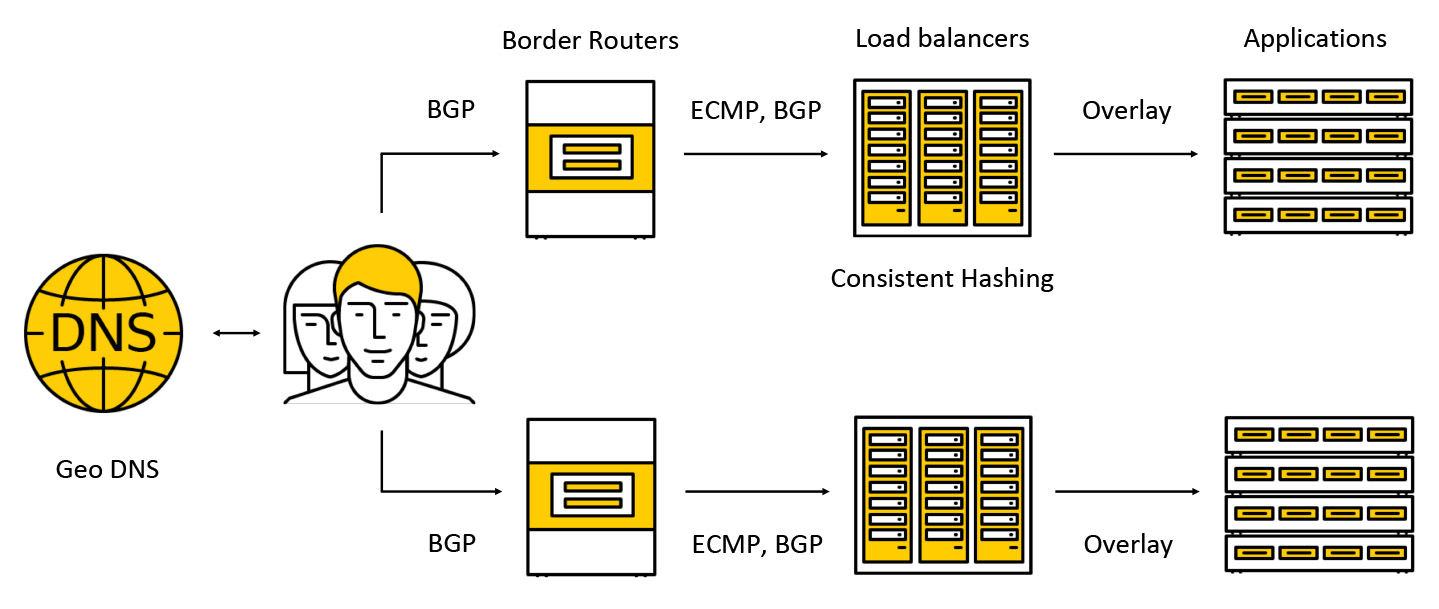
Der Datenverkehr wird über ECMP übertragen. Dies ist eine Routing-Strategie, nach der es mehrere gleich gute Routen zum Ziel geben kann (in unserem Fall ist das Ziel die Ziel-IP-Adresse) und Pakete an eine von ihnen gesendet werden können. Wir unterstützen auch die Arbeit in mehreren Zugangszonen nach folgendem Schema: Wir geben die Adresse in jeder der Zonen bekannt, der Verkehr fällt in die nächste und geht nicht bereits darüber hinaus. Weiter unten in der Post werden wir genauer untersuchen, was mit dem Verkehr passiert.
Konfigurationsflugzeug
Die Schlüsselkomponente der Konfigurationsebene ist die API, über die die grundlegenden Operationen mit Balancern ausgeführt werden: Erstellen, Löschen, Ändern der Zusammensetzung von Instanzen, Abrufen von Healthcheck-Ergebnissen usw. Einerseits handelt es sich um eine REST-API, andererseits verwenden wir häufig das Framework in der Cloud gRPC, also "übersetzen" wir REST in gRPC und verwenden dann nur gRPC. Jede Anforderung führt zur Erstellung einer Reihe von asynchronen idempotenten Aufgaben, die in einem gemeinsam genutzten Pool von Yandex.Cloud-Mitarbeitern ausgeführt werden. Aufgaben werden so geschrieben, dass sie jederzeit angehalten und anschließend neu gestartet werden können. Dies bietet Skalierbarkeit, Wiederholbarkeit und Protokollierungsvorgänge.

Infolgedessen sendet die Aufgabe von der API eine Anforderung an den Balancer-Service-Controller, der in Go geschrieben ist. Er kann Balancer hinzufügen und entfernen, die Zusammensetzung von Backends und Einstellungen ändern.
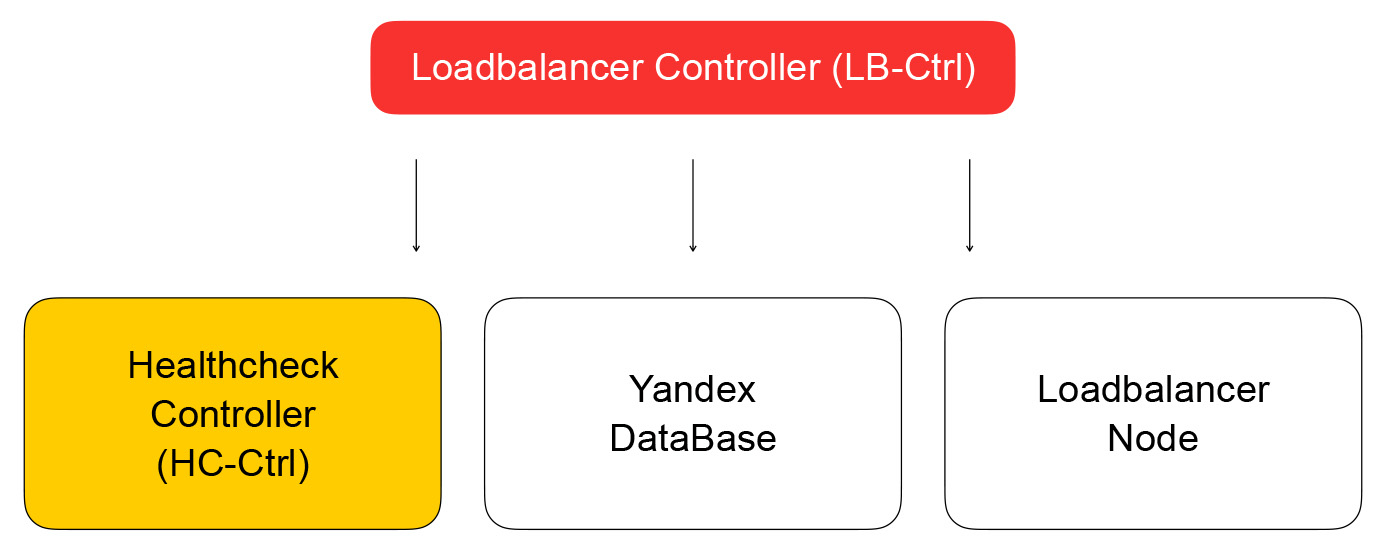
Der Dienst speichert seinen Status in der Yandex-Datenbank - einer verteilten verwalteten Datenbank, die Sie auch bald verwenden können. In Yandex.Cloud funktioniert, wie bereits erwähnt, das Hundefutterkonzept: Wenn wir unsere Dienstleistungen selbst nutzen, werden unsere Kunden sie auch gerne nutzen. Die Yandex-Datenbank ist ein Beispiel für die Implementierung eines solchen Konzepts. Wir speichern alle unsere Daten in YDB und müssen nicht über die Pflege und Skalierung der Datenbank nachdenken. Diese Probleme sind für uns gelöst. Wir verwenden die Datenbank als Service.
Wir kehren zum Balancer-Controller zurück. Seine Aufgabe besteht darin, Informationen über den Balancer zu speichern und die Bereitschaft zur Überprüfung der Bereitschaft der virtuellen Maschine an den Healthcheck-Controller zu senden.
Healthcheck-Controller
Es empfängt Anforderungen zum Ändern von Inspektionsregeln, speichert sie in YDB, verteilt Aufgaben an Healtcheck-Knoten und aggregiert die Ergebnisse, die dann in der Datenbank gespeichert und an den Loadbalancer-Controller gesendet werden. Er sendet seinerseits eine Anfrage, um die Zusammensetzung des Clusters in der Datenebene an den Loadbalancer-Knoten zu ändern, worauf ich weiter unten eingehen werde.

Lassen Sie uns mehr über Gesundheitschecks sprechen. Sie können in mehrere Klassen unterteilt werden. Audits haben unterschiedliche Erfolgskriterien. TCP-Prüfungen müssen in einer festgelegten Zeit erfolgreich eine Verbindung herstellen. HTTP-Prüfungen erfordern sowohl eine erfolgreiche Verbindung als auch eine Antwort mit einem Statuscode von 200.
Außerdem unterscheiden sich die Prüfungen in der Aktionsklasse - sie sind aktiv und passiv. Passive Überprüfungen überwachen einfach, was mit dem Verkehr passiert, ohne besondere Maßnahmen zu ergreifen. Dies funktioniert bei L4 nicht sehr gut, da es von der Logik der übergeordneten Protokolle abhängt: Bei L4 gibt es keine Informationen darüber, wie lange der Vorgang gedauert hat und ob die Verbindung gut oder schlecht war. Bei aktiven Überprüfungen muss der Balancer Anforderungen an jede Serverinstanz senden.
Die meisten Load Balancer führen ihre Lebendigkeitsprüfungen selbst durch. Wir bei Cloud haben beschlossen, diese Teile des Systems zu trennen, um die Skalierbarkeit zu verbessern. Dieser Ansatz ermöglicht es uns, die Anzahl der Balancer zu erhöhen und gleichzeitig die Anzahl der Healthcheck-Anforderungen an den Service beizubehalten. Überprüfungen werden von separaten Healthcheck-Knoten durchgeführt, die zum Sharding und Replizieren von Testzielen verwendet werden. Es ist unmöglich, Überprüfungen von einem Host aus durchzuführen, da dies fehlschlagen kann. Dann erhalten wir nicht den Status der Instanzen, die er überprüft hat. Wir führen Überprüfungen für jede Instanz von mindestens drei Healthcheck-Knoten durch. Die Ziele von Überprüfungen werden zwischen Knoten mithilfe konsistenter Hashing-Algorithmen aufgeteilt.

Die Trennung von Balancing und Healthcheck kann zu Problemen führen. Wenn der Healthcheck-Knoten unter Umgehung des Balancers (der derzeit keinen Datenverkehr bedient) Anforderungen an die Instanz stellt, tritt eine seltsame Situation auf: Die Ressource scheint aktiv zu sein, aber der Datenverkehr erreicht sie nicht. Wir lösen dieses Problem auf diese Weise: Wir erhalten garantiert Healthcheck-Verkehr durch Balancer. Mit anderen Worten, das Schema des Verschiebens von Paketen mit Datenverkehr von Clients und von Integritätsprüfungen unterscheidet sich minimal: In beiden Fällen werden Pakete an die Balancer gesendet, die sie an die Zielressourcen liefern.
Der Unterschied besteht darin, dass Kunden Anfragen nach VIPs stellen und sich die Gesundheitsprüfungen auf jeden einzelnen RIP beziehen. Hier ergibt sich ein interessantes Problem: Wir geben unseren Benutzern die Möglichkeit, Ressourcen in grauen IP-Netzwerken zu erstellen. Stellen Sie sich vor, es gibt zwei verschiedene Cloud-Besitzer, die ihre Dienste für Balancer versteckt haben. Jeder von ihnen verfügt außerdem über Ressourcen im Subnetz 10.0.0.1/24 mit denselben Adressen. Sie müssen in der Lage sein, sie auf irgendeine Weise zu unterscheiden, und hier müssen Sie in das Gerät des virtuellen Netzwerks Yandex.Cloud eintauchen. Weitere Informationen finden Sie im
Video zum Ereignis about: cloud. Für uns ist es jetzt wichtig, dass das Netzwerk mehrschichtig ist und über Tunnel verfügt, die anhand der Subnetz-ID unterschieden werden können.
Healthcheck-Knoten greifen über sogenannte Quasi-IPv6-Adressen auf Balancer zu. Eine Quasi-Adresse ist eine IPv6-Adresse, innerhalb derer die IPv4-Adresse und die Benutzer-Subnetz-ID geschützt sind. Der Datenverkehr fällt auf den Balancer, er extrahiert die IPv4-Adresse der Ressource daraus, ersetzt IPv6 durch IPv4 und sendet das Paket an das Netzwerk des Benutzers.
Der umgekehrte Datenverkehr verläuft auf die gleiche Weise: Der Balancer erkennt anhand von Integritätsprüfungen, dass das Ziel ein graues Netzwerk ist, und konvertiert IPv4 in IPv6.
VPP - das Herz der Datenebene
Der Balancer basiert auf der Technologie der Vector Packet Processing (VPP) - einem Framework von Cisco für die Paketverarbeitung des Netzwerkverkehrs. In unserem Fall läuft das Framework auf der Bibliothek zur Verwaltung des Benutzerraums von Netzwerkgeräten - Data Plane Development Kit (DPDK). Dies bietet eine hohe Paketverarbeitungsleistung: Es gibt viel weniger Unterbrechungen im Kernel, es gibt keine Kontextwechsel zwischen Kernelraum und Benutzerraum.
VPP geht noch weiter und bringt noch mehr Leistung aus dem System, indem Pakete zu Stapeln kombiniert werden. Eine erhöhte Produktivität ist auf den aggressiven Einsatz von Caches moderner Prozessoren zurückzuführen. Beide Datencaches werden verwendet (Pakete werden von „Vektoren“ verarbeitet, Daten liegen nahe beieinander) und Befehls-Caches: In VPP folgt die Paketverarbeitung einem Diagramm, in dessen Knoten Funktionen vorhanden sind, die eine Aufgabe ausführen.
Beispielsweise wird die Verarbeitung von IP-Paketen in VPP in der folgenden Reihenfolge fortgesetzt: Zuerst werden Paket-Header im Analyseknoten analysiert und dann an den Knoten gesendet, der die Pakete gemäß den Routing-Tabellen weiterleitet.
Ein bisschen Hardcore. VPP-Autoren gehen bei der Verwendung von Prozessor-Caches keine Kompromisse ein, daher enthält ein typischer Paketvektor-Verarbeitungscode eine manuelle Vektorisierung: Es gibt einen Verarbeitungszyklus, in dem die Situation wie "Wir haben vier Pakete in der Warteschlange" verarbeitet wird, dann dieselbe für zwei, dann - für einen. Oft werden Prefetch-Anweisungen verwendet, die Daten in Caches laden, um den Zugriff auf sie bei den folgenden Iterationen zu beschleunigen.
n_left_from = frame->n_vectors; while (n_left_from > 0) { vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
Healthchecks wandeln also IPv6 an VPP um, wodurch sie in IPv4 umgewandelt werden. Dies geschieht durch den Graphknoten, den wir algorithmisches NAT nennen. Für den umgekehrten Verkehr (und die Konvertierung von IPv6 nach IPv4) gibt es denselben Knoten für algorithmisches NAT.
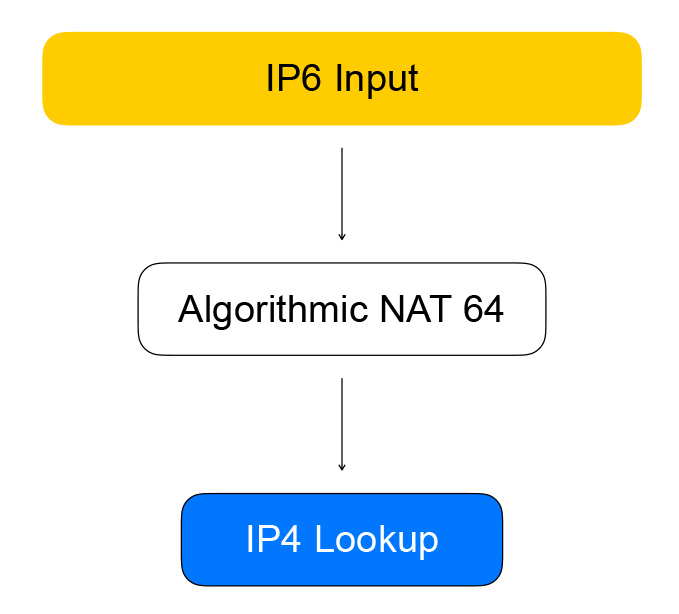
Der direkte Datenverkehr von den Balancer-Clients durchläuft die Knoten des Diagramms, die den Ausgleich selbst durchführen.

Der erste Knoten sind Sticky Sessions. Es speichert einen
5-Tupel- Hash für etablierte Sitzungen. 5-Tupel enthält die Adresse und den Port des Clients, von dem Informationen übertragen werden, die Adresse und die Ports der Ressourcen, die für den Empfang von Verkehr verfügbar sind, sowie das Netzwerkprotokoll.
Der 5-Tupel-Hash hilft uns, weniger Berechnungen im nachfolgenden konsistenten Hash-Knoten durchzuführen und auch die Änderung in der Liste der Ressourcen hinter dem Balancer besser zu handhaben. Wenn ein Paket beim Balancer ankommt, für das es keine Sitzung gibt, wird es an den konsistenten Hashing-Knoten gesendet. Hier erfolgt der Ausgleich mithilfe von konsistentem Hashing: Wir wählen eine Ressource aus der Liste der verfügbaren "Live" -Ressourcen aus. Anschließend werden die Pakete an den NAT-Knoten gesendet, der die Zieladresse ersetzt und die Prüfsummen neu berechnet. Wie Sie sehen können, befolgen wir die Regeln von VPP - ähnlich wie bei ähnlichen, gruppenähnlichen Berechnungen, um die Effizienz von Prozessor-Caches zu erhöhen.
Konsequentes Hashing
Warum haben wir ihn gewählt und worum geht es? Betrachten Sie zunächst die vorherige Aufgabe - Auswahl einer Ressource aus der Liste.
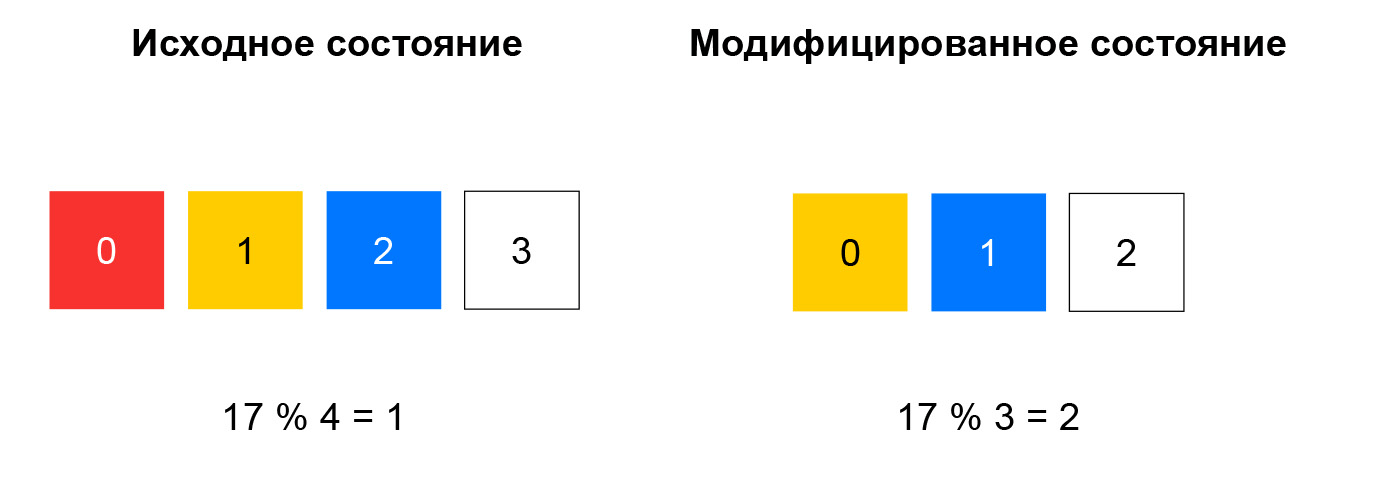
Bei nicht konsistentem Hashing wird der Hash aus dem eingehenden Paket berechnet und die Ressource aus der Liste ausgewählt, indem der Rest dieses Hash durch die Anzahl der Ressourcen dividiert wird. Solange die Liste unverändert bleibt, funktioniert ein solches Schema gut: Wir senden immer Pakete mit demselben 5-Tupel an dieselbe Instanz. Wenn beispielsweise eine Ressource nicht mehr auf Integritätsprüfungen reagiert, ändert sich für einen erheblichen Teil der Hashes die Auswahl. TCP-Verbindungen werden auf dem Client unterbrochen: Ein Paket, das zuvor an Instanz A gesendet wurde, fällt möglicherweise auf Instanz B, die mit der Sitzung für dieses Paket nicht vertraut ist.
Konsistentes Hashing löst das beschriebene Problem. Der einfachste Weg, dieses Konzept zu erklären, ist folgender: Stellen Sie sich vor, Sie haben einen Ring, in den Sie Ressourcen per Hash (z. B. per IP: Port) verteilen. Die Wahl einer Ressource ist die Drehung des Rades um einen Winkel, der durch den Hash aus dem Paket bestimmt wird.
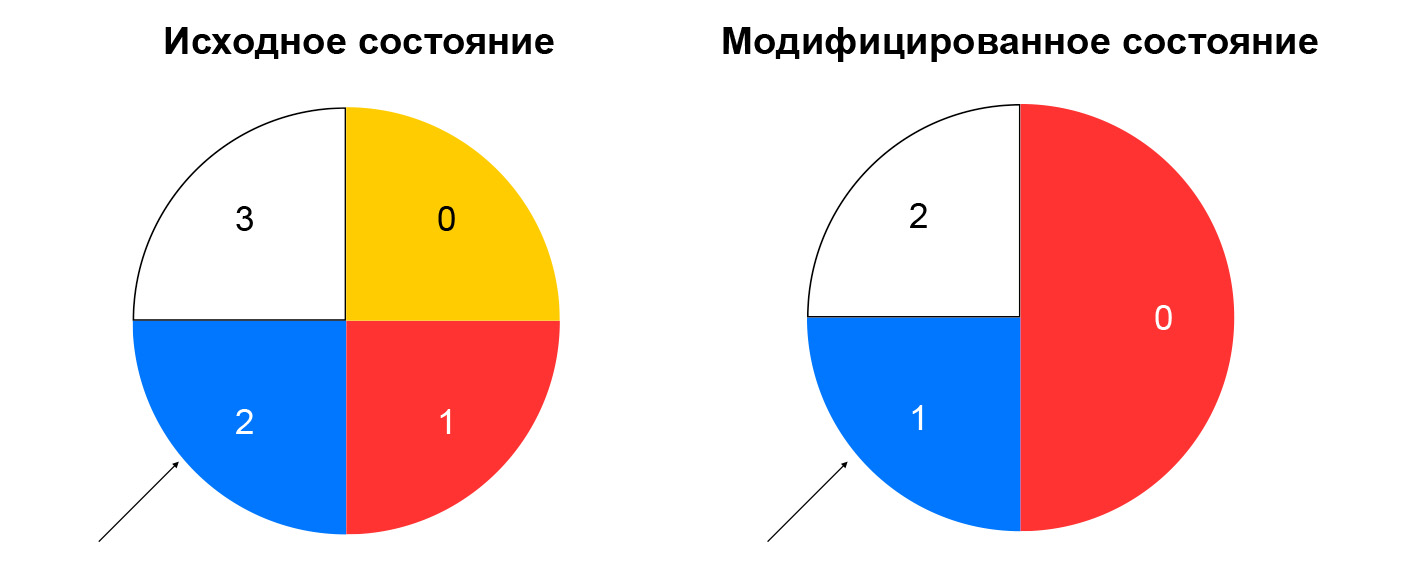
Dies minimiert die Umverteilung des Datenverkehrs, wenn die Zusammensetzung der Ressourcen geändert wird. Das Löschen einer Ressource wirkt sich nur auf den Teil des konsistenten Hash-Rings aus, auf dem sich die angegebene Ressource befand. Das Hinzufügen einer Ressource ändert auch die Verteilung, aber wir haben einen Sticky-Sessions-Knoten, mit dem wir bereits eingerichtete Sitzungen nicht auf neue Ressourcen umstellen können.
Wir haben untersucht, was mit dem direkten Verkehr zwischen dem Balancer und den Ressourcen passiert. Lassen Sie uns nun den umgekehrten Verkehr behandeln. Es folgt dem gleichen Muster wie der Verifizierungsverkehr - durch algorithmisches NAT, dh durch umgekehrtes NAT 44 für den Clientverkehr und über NAT 46 für den Healthchecks-Verkehr. Wir halten uns an unser eigenes Schema: Wir vereinen den Healthchecks-Verkehr und den realen Benutzerverkehr.
Baugruppe aus Loadbalancer-Knoten und Komponenten
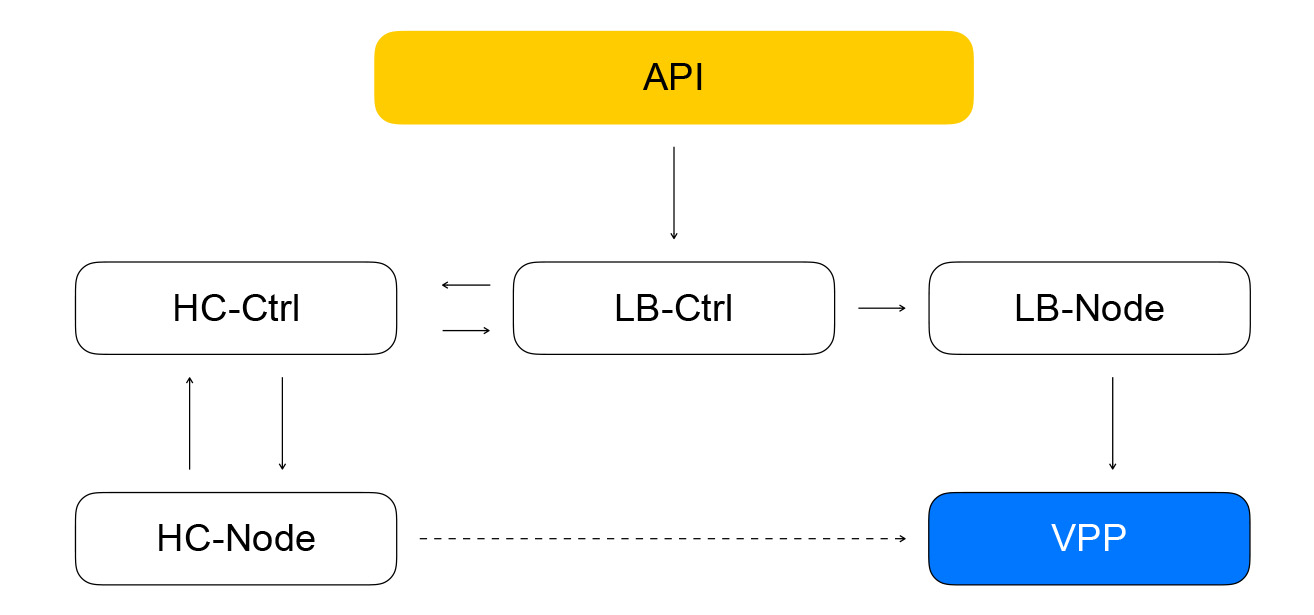
Die Zusammensetzung der Balancer und Ressourcen in VPP wird vom lokalen Dienst - Loadbalancer-Node - gemeldet. Er abonniert den Ereignisfluss vom Loadbalancer-Controller und kann die Differenz zwischen dem aktuellen Status des VPP und dem vom Controller empfangenen Zielstatus erstellen. Wir erhalten ein geschlossenes System: Ereignisse von der API kommen zum Balancer-Controller, der die Healthcheck-Controller-Aufgaben festlegt, um die "Lebendigkeit" der Ressourcen zu überprüfen. Dadurch werden wiederum Aufgaben im Healthcheck-Knoten festgelegt und die Ergebnisse aggregiert. Anschließend werden sie an den Balancer-Controller zurückgesendet. Der Loadbalancer-Knoten abonniert Ereignisse vom Controller und ändert den Status des VPP. In einem solchen System weiß jeder Dienst nur, was er über benachbarte Dienste benötigt. Die Anzahl der Verbindungen ist begrenzt und wir haben die Möglichkeit, die verschiedenen Segmente unabhängig voneinander zu nutzen und zu skalieren.
Welche Fragen wurden vermieden
Alle unsere Dienste in der Steuerebene sind in Go geschrieben und verfügen über gute Skalierungs- und Zuverlässigkeitsfunktionen. Go verfügt über viele Open Source-Bibliotheken zum Erstellen verteilter Systeme. Wir verwenden GRPC aktiv, alle Komponenten enthalten eine Open-Source-Implementierung der Serviceerkennung - unsere Services überwachen die Leistung des anderen, können ihre Zusammensetzung dynamisch ändern und haben sie mit dem GRPC-Balancing verknüpft. Für Metriken verwenden wir auch eine Open Source-Lösung. In der Datenebene haben wir eine anständige Leistung und eine große Ressourcenreserve: Es stellte sich als sehr schwierig heraus, einen Stand aufzubauen, auf dem man sich auf die Leistung von VPP stützen konnte, und nicht auf eine eiserne Netzwerkkarte.
Probleme und Lösungen
Was hat nicht sehr gut funktioniert? In Go erfolgt die Speicherverwaltung automatisch, es treten jedoch Speicherlecks auf. Der einfachste Weg, mit ihnen umzugehen, besteht darin, Goroutinen zu starten und nicht zu vergessen, sie zu vervollständigen. Fazit: Überwachen Sie den Speicherverbrauch von Go-Programmen. Oft ist ein guter Indikator die Menge an Goroutine. Diese Geschichte hat ein Plus: In Go ist es einfach, Daten zur Laufzeit abzurufen - zum Speicherverbrauch, zur Anzahl der gestarteten Goroutinen und zu vielen anderen Parametern.
Darüber hinaus ist Go möglicherweise nicht die beste Wahl für Funktionstests. Sie sind ziemlich ausführlich und der Standardansatz „Alles in CI-Paketen ausführen“ ist für sie nicht sehr geeignet. Tatsache ist, dass Funktionstests höhere Anforderungen an die Ressourcen stellen und bei ihnen echte Zeitüberschreitungen auftreten. Aus diesem Grund können Tests fehlschlagen, da die CPU mit Komponententests beschäftigt ist. Schlussfolgerung: Führen Sie nach Möglichkeit „schwere“ Tests getrennt von Unit-Tests durch.
Die Microservice-Ereignisarchitektur ist komplizierter als ein Monolith: Das Abrufen von Protokollen auf Dutzenden verschiedener Computer ist nicht sehr praktisch. Fazit: Wenn Sie Microservices durchführen, denken Sie sofort an die Rückverfolgung.
Unsere Pläne
Wir werden den internen Balancer IPv6-Balancer starten, Unterstützung für Kubernetes-Skripte hinzufügen, unsere Dienste weiterhin sharden (jetzt sind nur noch Healthcheck-Node und Healthcheck-Ctrl schattiert), neue Healthchecks hinzufügen und auch die Smart-Check-Aggregation implementieren. Wir erwägen die Möglichkeit, unsere Dienste noch unabhängiger zu gestalten, damit sie nicht direkt miteinander kommunizieren, sondern eine Nachrichtenwarteschlange verwenden. Der SQS-kompatible
Yandex Message Queue- Dienst wurde kürzlich in der Cloud veröffentlicht.
Vor kurzem wurde Yandex Load Balancer öffentlich veröffentlicht. Lesen Sie die
Dokumentation für den Service, verwalten Sie die Balancer auf eine für Sie bequeme Weise und erhöhen Sie die Fehlertoleranz Ihrer Projekte!