
Seit 2008 beschäftigt sich unser Unternehmen hauptsächlich mit Infrastrukturmanagement und technischem Support rund um die Uhr für Webprojekte: Wir haben mehr als 400 Kunden, was etwa 15% des E-Commerce in Russland entspricht. Dementsprechend wird eine sehr vielfältige Architektur unterstützt. Wenn etwas fällt, müssen wir es innerhalb von 15 Minuten reparieren. Um zu verstehen, dass ein Unfall aufgetreten ist, müssen Sie das Projekt überwachen und auf Vorfälle reagieren. Wie geht das?
Ich glaube, dass die Organisation des richtigen Überwachungssystems in Schwierigkeiten ist. Wenn es keine Probleme gab, bestand meine Rede aus einer These: "Bitte installieren Sie Prometheus + Grafana und die Plugins 1, 2, 3." Leider funktioniert das jetzt nicht. Und das Hauptproblem ist, dass jeder weiterhin an etwas glaubt, das 2008 in Bezug auf Softwarekomponenten existierte.
In Bezug auf die Organisation des Überwachungssystems riskiere ich zu sagen, dass ... Projekte mit kompetenter Überwachung nicht existieren. Und die Situation ist so schlimm, wenn etwas fällt, dass die Gefahr besteht, dass es unbemerkt bleibt - jeder ist sich sicher, dass „alles überwacht wird“.
Vielleicht wird alles überwacht. Aber wie?
Wir alle sind auf eine ähnliche Geschichte gestoßen: Ein bestimmter Entwickler, ein bestimmter Administrator arbeitet, ein Entwicklungsteam kommt zu ihnen und sagt: "Wir haben es, jetzt wird es überwacht." Welcher Monitor? Wie funktioniert es
Ok Wir überwachen den altmodischen Weg. Aber es ändert sich bereits und es stellt sich heraus, dass Sie Service A überwacht haben, der zu Service B wurde, der mit Service C interagiert. Aber das Entwicklungsteam sagt zu Ihnen: "Software installieren, es muss alles überwachen!"
Was hat sich also geändert? - Alles hat sich geändert!
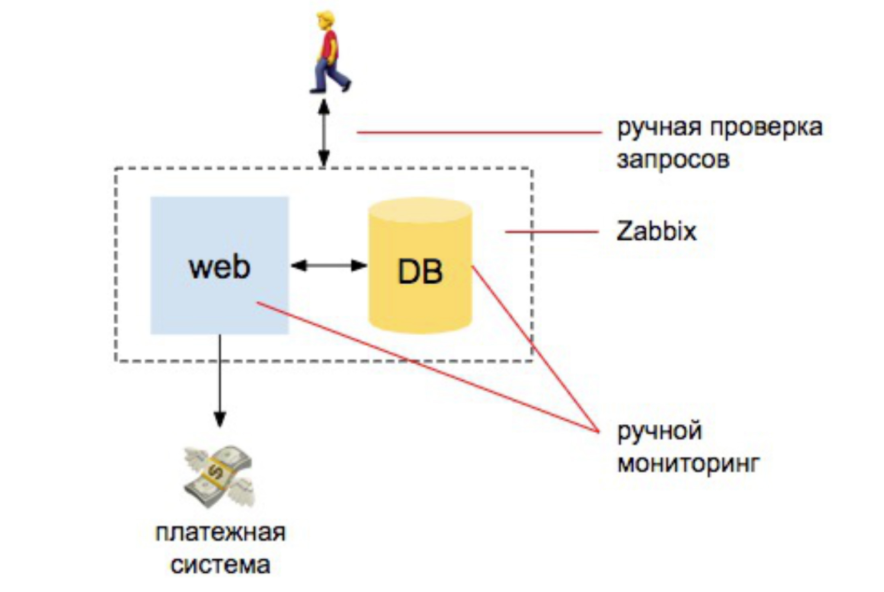
2008 Jahr. Alles ist gut
Es gibt einige Entwickler, einen Server und einen Datenbankserver. Ab hier geht alles. Wir haben einige Informationen, wir setzen Zabbix, Nagios, Kakteen. Und dann setzen wir klare Warnungen auf der CPU, auf den Betrieb der Festplatten, auf die Stelle auf den Festplatten. Wir führen auch einige manuelle Überprüfungen durch, um sicherzustellen, dass die Site antwortet, dass Bestellungen in die Datenbank eingehen. Und das war's - wir sind mehr oder weniger geschützt.
Wenn wir den Arbeitsaufwand vergleichen, den der Administrator dann geleistet hat, um die Überwachung sicherzustellen, war dies zu 98% automatisch: Die Person, die überwacht, sollte verstehen, wie Zabbix installiert, konfiguriert und Warnungen konfiguriert werden. Und 2% - für externe Überprüfungen: dass die Site antwortet und eine Anfrage an die Datenbank sendet, dass neue Bestellungen eingegangen sind.
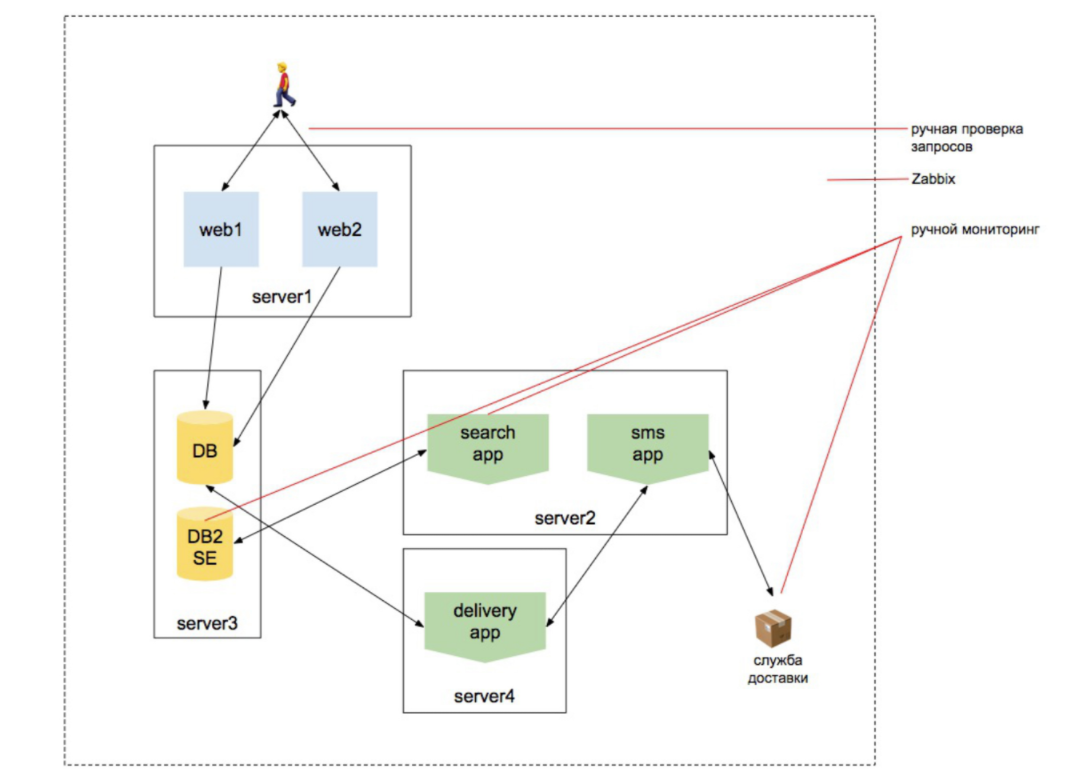
2010 Jahr. Die Last wächst
Wir beginnen das Web zu skalieren und fügen eine Suchmaschine hinzu. Wir möchten sicherstellen, dass der Produktkatalog alle Produkte enthält. Und diese Produktsuche funktioniert. Dass die Datenbank funktioniert, dass Bestellungen getätigt werden, dass die Site extern reagiert und von zwei Servern antwortet und der Benutzer nicht aus der Site geworfen wird, während er auf einen anderen Server umstellt usw. Es gibt mehr Entitäten.
Darüber hinaus bleibt die mit der Infrastruktur verbundene Einheit die größte im Kopf des Managers. Trotzdem liegt mir die Idee im Kopf, dass die Person, die überwacht, die Person ist, die zabbix installiert und konfigurieren kann.
Gleichzeitig werden externe Überprüfungen durchgeführt, eine Reihe von Skripten zum Abfragen des Suchindexers erstellt, eine Reihe von Skripten, um zu überprüfen, ob sich die Suche während des Indizierungsprozesses ändert, eine Reihe von Skripten, mit denen überprüft wird, ob Waren an den Lieferservice übertragen werden usw. usw.

Hinweis: Ich habe dreimal ein „Skript-Set“ geschrieben. Das heißt, die Person, die für die Überwachung verantwortlich ist, ist nicht mehr die Person, die nur zabbix installiert. Dies ist die Person, die mit dem Codieren beginnt. In den Köpfen des Teams hat sich jedoch noch nichts geändert.
Aber die Welt verändert sich und wird immer komplizierter. Als Virtualisierungsschicht werden mehrere neue Systeme hinzugefügt. Sie beginnen miteinander zu interagieren. Wer hat gesagt, "riecht nach Microservices?" Aber jeder Dienst sieht immer noch einzeln aus wie eine Site. Wir können uns an ihn wenden und verstehen, dass er die notwendigen Informationen herausgibt und von selbst arbeitet. Und wenn Sie ein Administrator sind, der ständig an einem Projekt beteiligt ist, das sich seit 5-7-10 Jahren entwickelt, haben Sie dieses Wissen gesammelt: Eine neue Ebene erscheint - Sie haben es erkannt, eine andere Ebene erscheint - Sie haben es erkannt ...
Aber selten begleitet jemand das Projekt 10 Jahre lang.
Zusammenfassung der Mannüberwachung
Angenommen, Sie sind zu einem neuen Startup gekommen, das sofort 20 Entwickler bewertet, 15 Microservices geschrieben hat, und Sie sind der Administrator, dem gesagt wird: „Erstellen Sie ein CI / eine CD. Bitte. " Sie haben eine CI / CD erstellt und plötzlich hören Sie: "Es ist schwierig für uns, mit der Produktion im" Cube "zu arbeiten, ohne zu verstehen, wie die Anwendung darin funktionieren wird. Machen Sie uns einen Sandkasten im selben "Würfel".
In diesem Würfel erstellen Sie eine Sandbox. Sie sagen Ihnen sofort: "Wir wollen eine Bühnendatenbank, die jeden Tag aus der Produktion aktualisiert wird, um zu verstehen, dass sie in der Datenbank funktioniert, aber die Produktionsdatenbank nicht ruiniert."
Du lebst in allem. Es sind noch 2 Wochen bis zur Veröffentlichung, sagen sie dir: "Jetzt würde alles überwacht werden ..." Das heißt Überwachen der Cluster-Infrastruktur, Überwachen der Microservice-Architektur, Überwachen der Arbeit mit externen Diensten ...
Und Kollegen nehmen ein so bekanntes Schema aus dem Kopf und sagen: „Hier ist also alles klar! Installieren Sie ein Programm, das alles überwacht. “ Ja: Prometheus + Grafana + Plugins.
Und sie fügen gleichzeitig hinzu: "Sie haben zwei Wochen Zeit, um sicherzustellen, dass alles zuverlässig ist."
In dem Haufen von Projekten, die wir sehen, wird eine Person für die Überwachung zugewiesen. Stellen Sie sich vor, wir möchten eine Person für 2 Wochen einstellen, um sie zu überwachen, und wir schreiben ihr einen Lebenslauf. Welche Fähigkeiten sollte diese Person besitzen - angesichts all dessen, was wir zuvor gesagt haben?
- Er muss die Überwachung und die Besonderheiten der Arbeit der Eiseninfrastruktur verstehen.
- Er muss die Besonderheiten der Überwachung von Kubernetes verstehen (und jeder möchte einen „Cube“, weil Sie alles ignorieren, verstecken können, weil der Administrator es herausfinden wird) - selbst, seine Infrastruktur und verstehen, wie Anwendungen darin überwacht werden.
- Er muss verstehen, dass Dienste auf besondere Weise miteinander kommunizieren, und die Besonderheiten der Interaktion von Diensten untereinander kennen. Es ist ziemlich realistisch, ein Projekt zu sehen, bei dem einige der Dienste synchron kommunizieren, da es keinen anderen Weg gibt. Beispielsweise geht das Backend auf REST, auf gRPC an den Katalogdienst, empfängt eine Warenliste und kehrt zurück. Sie können hier nicht warten. Und mit anderen Diensten funktioniert es asynchron. Übertragen Sie die Bestellung an den Lieferservice, senden Sie einen Brief usw.
Sie sind wahrscheinlich schon von all dem gesegelt? Und der Administrator, der dies überwachen muss, schwamm noch mehr. - Er muss in der Lage sein, richtig zu planen und zu planen - da die Arbeit immer mehr wird.
- Er muss daher aus dem erstellten Dienst eine Strategie erstellen, um zu verstehen, wie dieser spezifisch überwacht werden kann. Er braucht ein Verständnis der Architektur des Projekts und seiner Entwicklung + Verständnis der in der Entwicklung verwendeten Technologien.
Erinnern wir uns an einen absolut normalen Fall: Teil der Dienste in PHP, Teil der Dienste in Go, Teil der Dienste in JS. Sie arbeiten irgendwie untereinander. Daher kommt der Begriff „Microservice“: Es gibt so viele separate Systeme, dass Entwickler das Projekt als Ganzes nicht verstehen können. Ein Teil des Teams schreibt Dienste in JS, die eigenständig funktionieren und nicht wissen, wie der Rest des Systems funktioniert. Der andere Teil schreibt Dienste in Python und geht nicht auf die Funktionsweise anderer Dienste ein, sondern ist in ihrem Bereich isoliert. Drittens - schreibt Dienste in PHP oder etwas anderem.
Alle diese 20 Personen sind in 15 Dienste unterteilt, und es gibt nur einen Administrator, der dies alles verstehen sollte. Hör auf! Wir haben das System nur in 15 Microservices aufgeteilt, da 20 Personen das gesamte System nicht verstehen können.
Aber es muss irgendwie überwacht werden ...
Was ist das Ergebnis? Infolgedessen gibt es eine Person, die alles enthält, was ein ganzes Entwicklerteam nicht verstehen kann, und dennoch muss sie wissen und in der Lage sein, was wir oben angegeben haben - Eiseninfrastruktur, Kubernetes-Infrastruktur usw.
Was soll ich sagen ... Houston, wir haben Probleme.
Die Überwachung eines modernen Softwareprojekts ist ein Softwareprojekt für sich
Aus der falschen Überzeugung heraus, dass Überwachung Software ist, glauben wir an Wunder. Aber Wunder geschehen leider nicht. Sie können zabbix nicht installieren und warten, bis alles funktioniert. Es macht keinen Sinn, Grafana zu setzen und zu hoffen, dass alles in Ordnung ist. Die meiste Zeit wird für die Organisation von Überprüfungen des Betriebs von Diensten und deren Interaktion untereinander sowie für die Überprüfung der Funktionsweise externer Systeme aufgewendet. Tatsächlich werden 90% der Zeit nicht für das Schreiben von Skripten, sondern für die Softwareentwicklung aufgewendet. Und es sollte ein Team sein, das die Arbeit des Projekts versteht.
Wenn in dieser Situation eine Person zur Überwachung geworfen wird, treten Probleme auf. Was überall passiert.
Beispielsweise gibt es mehrere Dienste, die über Kafka miteinander kommunizieren. Eine Bestellung kam, wir schickten eine Nachricht über die Bestellung an Kafka. Es gibt einen Service, der Informationen über die Bestellung abhört und den Warenversand ausführt. Es gibt einen Dienst, der Informationen über die Bestellung abhört und einen Brief an den Benutzer sendet. Und dann gibt es immer noch eine Reihe von Diensten, und wir beginnen, verwirrt zu werden.
Und wenn Sie es dem Administrator und den Entwicklern zu einem Zeitpunkt noch geben, an dem noch eine kurze Zeit bis zur Veröffentlichung verbleibt, muss eine Person das gesamte Protokoll verstehen. Das heißt, Ein Projekt dieser Größenordnung nimmt viel Zeit in Anspruch, und dies sollte in die Entwicklung des Systems einbezogen werden.
Aber sehr oft, besonders beim Brennen, sehen wir in Startups, wie die Überwachung bis später verschoben wird. „Jetzt werden wir den Proof of Concept machen, wir werden damit beginnen, ihn fallen lassen - wir sind bereit zu opfern. Und dann werden wir alles überwachen. “ Wenn (oder wenn) das Projekt anfängt, Geld zu verdienen, möchte das Unternehmen noch mehr Funktionen kürzen - weil es funktioniert hat, müssen Sie also weiter gehen! Und Sie sind an dem Punkt angelangt, an dem Sie am Anfang alles vorher überwachen müssen, was nicht 1% der Zeit in Anspruch nimmt, sondern viel mehr. Übrigens müssen Entwickler überwacht werden, und es ist einfacher, sie in neue Funktionen zu integrieren. Infolgedessen werden neue Funktionen geschrieben, alles ist abgeschlossen und Sie befinden sich in einem endlosen Stillstand.
Wie überwachen Sie ein Projekt von Anfang an und was ist, wenn Sie ein Projekt haben, das Sie überwachen müssen, aber nicht wissen, wo Sie anfangen sollen?
Zuerst müssen Sie planen.
Lyrischer Exkurs: Beginnen Sie sehr oft mit der Überwachung der Infrastruktur. Zum Beispiel haben wir Kubernetes. Zunächst stellen wir Prometheus mit Grafana zusammen und stellen die Plugins unter die Überwachung des "Würfels". Nicht nur Entwickler, sondern auch Administratoren haben eine unglückliche Praxis: "Wir werden dieses Plug-In installieren, und das Plug-In weiß wahrscheinlich, wie das geht." Die Leute beginnen lieber mit einfachen und verständlichen als mit wichtigen Handlungen. Die Überwachung der Infrastruktur ist einfach.Entscheiden Sie zuerst, was und wie Sie überwachen möchten, und nehmen Sie dann das Instrument in die Hand, da andere Personen nicht für Sie denken können. Ja und sollten sie? Andere Leute dachten sich, über das universelle System - oder dachten überhaupt nicht, als dieses Plugin geschrieben wurde. Und die Tatsache, dass dieses Plugin 5.000 Benutzer hat, bedeutet nicht, dass es irgendeinen Nutzen bringt. Vielleicht werden Sie der 5001., einfach weil vorher schon 5.000 Menschen dort waren.
Wenn Sie mit der Überwachung der Infrastruktur begonnen haben und das Backend Ihrer Anwendung nicht mehr reagiert, verlieren alle Benutzer den Kontakt zur mobilen Anwendung. Ein Fehler wird herausfliegen. Sie werden zu Ihnen kommen und sagen: "Die Anwendung funktioniert nicht, was machen Sie hier?" "Wir überwachen." - "Wie überwachen Sie, wenn Sie nicht sehen, dass die Anwendung nicht funktioniert ?!"
- Ich glaube, dass es notwendig ist, die Überwachung vom Einstiegspunkt des Benutzers aus zu starten. Wenn der Benutzer nicht sieht, dass die Anwendung funktioniert, ist dies ein Fehler. Und das Überwachungssystem sollte in erster Linie davor warnen.
- Und nur dann können wir die Infrastruktur überwachen. Oder mach es parallel. Die Infrastruktur ist einfacher - hier können wir endlich einfach zabbix installieren.
- Und jetzt müssen Sie zu den Wurzeln der Anwendung gehen, um zu verstehen, wo dies nicht funktioniert.
Mein Hauptgedanke ist, dass die Überwachung parallel zum Entwicklungsprozess erfolgen sollte. Wenn Sie das Überwachungsteam für andere Aufgaben (Erstellen eines CI / CD, Sandboxes, Reorganisieren der Infrastruktur) abreißen, verzögert sich die Überwachung und Sie werden möglicherweise nie mit der Entwicklung Schritt halten (oder früher oder später muss sie gestoppt werden).
Alles nach Ebenen
So sehe ich die Organisation des Überwachungssystems.
1) Anwendungsebene:
- Überwachung der Geschäftslogik der Anwendung;
- Überwachung der Gesundheitsmetriken von Diensten;
- Integrationsüberwachung.
2) Infrastrukturebene:
- Überwachung des Orchestrierungsniveaus;
- Überwachungssystemsoftware;
- Überwachung des Eisengehalts.
3) Nochmals die Anwendungsebene - aber als Engineering-Produkt:
- Sammeln und Überwachen von Anwendungsprotokollen;
- APM
- Rückverfolgung.
4) Warnung:
- Organisation eines Warnsystems;
- Organisation eines Uhrensystems;
- Organisation einer "Wissensdatenbank" und Workflow-Incident-Verarbeitung.
Wichtig : Wir werden nicht erst, sondern sofort benachrichtigt! Es ist nicht notwendig, mit der Überwachung zu beginnen und „irgendwie später“ herauszufinden, wer Benachrichtigungen erhalten wird. Was ist schließlich die Überwachungsaufgabe: zu verstehen, wo etwas im System nicht funktioniert, und die richtigen Leute darüber zu informieren. Wenn dies bis zum Ende bleibt, werden die richtigen Leute herausfinden, dass etwas schief geht, nur indem sie "nichts funktioniert für uns" nennen.
Anwendungsschicht - Überwachung der Geschäftslogik
Hier geht es darum zu überprüfen, ob die Anwendung für den Benutzer funktioniert.
Diese Stufe sollte in der Entwurfsphase durchgeführt werden. Zum Beispiel haben wir einen bedingten Prometheus: Er kriecht zu dem Server, der Überprüfungen durchführt, zieht den Endpunkt und der Endpunkt überprüft die API.
Wenn Programmierer häufig aufgefordert werden, die Hauptseite zu überwachen, um sicherzustellen, dass die Site funktioniert, geben sie einen Stift, der jedes Mal gezogen werden kann, wenn Sie sicherstellen möchten, dass die API funktioniert. Und Programmierer nehmen und schreiben derzeit noch / api / test / helloworld
Nur so kann sichergestellt werden, dass alles funktioniert? - Nein!
- Das Erstellen solcher Prüfungen ist im Wesentlichen Aufgabe der Entwickler. Unit-Tests sollten von Programmierern geschrieben werden, die Code schreiben. Denn wenn Sie dies mit dem Administrator zusammenführen "Alter, hier ist eine Liste der API-Protokolle für alle 25 Funktionen, bitte überwachen Sie alles!" - Nichts wird funktionieren.
- Wenn Sie "Hallo Welt" drucken, wird niemand jemals wissen, dass die API funktionieren sollte und wirklich funktioniert. Jede Änderung an der API sollte zu einer Änderung der Prüfungen führen.
- Wenn Sie bereits eine solche Katastrophe haben, stoppen Sie die Funktionen und wählen Sie die Entwickler aus, die diese Prüfungen ausstellen oder mit den Verlusten abgleichen. Stellen Sie ab, dass nichts geprüft wird und fallen wird.
Technische Tipps:
- Stellen Sie sicher, dass Sie einen externen Server für die Organisation von Inspektionen organisieren. Sie müssen sicherstellen, dass Ihr Projekt für die Außenwelt zugänglich ist.
- Organisieren Sie die Validierung über das gesamte API-Protokoll, nicht nur über einzelne Endpunkte.
- Erstellen Sie einen Prometheus-Endpunkt mit Testergebnissen.
Anwendungsebene - Überwachung von Integritätsmetriken
Jetzt sprechen wir über externe Gesundheitsmetriken von Diensten.
Wir haben beschlossen, alle „Stifte“ der Anwendung mithilfe externer Überprüfungen zu überwachen, die wir von einem externen Überwachungssystem aufrufen. Dies sind jedoch genau die „Stifte“, die der Benutzer „sieht“. Wir möchten sichergehen, dass die Dienstleistungen selbst für uns funktionieren. Hier ist eine bessere Geschichte: K8s hat Gesundheitsprüfungen, damit zumindest der Cube sicherstellt, dass der Dienst funktioniert. Aber die Hälfte der Schecks, die ich gesehen habe, ist der gleiche Druck „Hallo Welt“. Das heißt, Hier zieht er einmal nach dem Einsatz, er antwortete ihm, dass alles in Ordnung ist - und das war's. Und der Dienst verfügt, wenn er über eine eigene API verfügt, über eine große Anzahl von Einstiegspunkten für dieselbe API, die ebenfalls überwacht werden müssen, da wir wissen möchten, dass er funktioniert. Und wir überwachen es bereits im Inneren.
So implementieren Sie es technisch korrekt: Jeder Dienst legt einen Endpunkt für seine aktuelle Leistung fest. In den Diagrammen von Grafana (oder einer anderen Anwendung) wird der Status aller Dienste angezeigt.
- Jede Änderung an der API sollte zu einer Änderung der Prüfungen führen.
- Erstellen Sie sofort einen neuen Service mit Integritätsmetriken.
- Der Administrator kann zu den Entwicklern kommen und fragen: "Fügen Sie mir einige Funktionen hinzu, damit ich alles verstehe und meinem Überwachungssystem Informationen dazu hinzufüge." Entwickler antworten jedoch normalerweise: "Wir werden zwei Wochen vor der Veröffentlichung nichts hinzufügen."
Lassen Sie die Entwicklungsmanager wissen, dass es solche Verluste geben wird, lassen Sie die Chefs der Entwicklungsmanager auch wissen. Denn wenn alles fällt, wird immer noch jemand anrufen und verlangen, den "ständig fallenden Dienst" zu überwachen (c) - Wählen Sie übrigens Entwickler aus, die Plugins für Grafana schreiben - dies ist eine gute Hilfe für Administratoren.
Anwendungsschicht - Integrationsüberwachung
Die Integrationsüberwachung konzentriert sich auf die Überwachung der Kommunikation zwischen geschäftskritischen Systemen.
Zum Beispiel gibt es 15 Dienste, die miteinander kommunizieren. Dies sind keine einzelnen Websites mehr. Das heißt, Wir können den Dienst nicht alleine abrufen, / helloworld erhalten und verstehen, dass der Dienst funktioniert. Da der Webservice für die Bestellung Informationen über die Bestellung an den Bus senden muss, sollte der Lagerservice diese Nachricht vom Bus empfangen und weiter damit arbeiten. Und der E-Mail-Verteilungsdienst sollte dies irgendwie weiter erledigen usw.
Dementsprechend können wir bei jedem einzelnen Service nicht verstehen, dass dies alles funktioniert. Weil wir einen bestimmten Bus haben, über den alles kommuniziert und interagiert.
Daher sollte in dieser Phase die Phase des Testens von Diensten für die Interaktion mit anderen Diensten angegeben werden. Nachdem Sie einen Nachrichtenbroker überwacht haben, können Sie die Überwachung der Kommunikation nicht organisieren. Wenn es einen Dienst gibt, der Daten ausgibt, und einen Dienst, der sie empfängt, werden bei der Überwachung eines Brokers nur Daten angezeigt, die von einer Seite zur anderen fliegen. Selbst wenn wir es irgendwie geschafft haben, die Interaktion dieser Daten im Inneren zu überwachen - dass ein Produzent die Daten veröffentlicht, jemand sie liest, dieser Stream weiterhin an Kafka geht -, gibt er uns immer noch keine Informationen, wenn ein Dienst eine Nachricht in einer Version gab, aber Ein anderer Dienst hat diese Version nicht erwartet und übersprungen. Wir werden davon nichts erfahren, da die Dienste uns mitteilen werden, dass alles funktioniert.
Wie ich empfehle:
- Für die synchrone Kommunikation: Der Endpunkt führt Anforderungen für verwandte Dienste aus. Das heißt, Wir nehmen diesen Endpunkt, ziehen das Skript innerhalb des Dienstes, das zu allen Punkten führt und sagt: "Ich kann dort ziehen und dort ziehen, ich kann ziehen ..."
- Für asynchrone Kommunikation: Eingehende Nachrichten - Der Endpunkt überprüft den Bus auf Testnachrichten und zeigt den Verarbeitungsstatus an.
- Für asynchrone Kommunikation: ausgehende Nachrichten - Endpunkt sendet Testnachrichten an den Bus.
Wie üblich: Wir haben einen Dienst, der Daten auf den Bus wirft. Wir kommen zu diesem Service und bitten Sie, über den Integrationszustand zu sprechen. Und wenn der Dienst eine Nachricht irgendwo weiter verkaufen muss (WebApp), wird diese Testnachricht erstellt. Und wenn wir den Service auf der OrderProcessing-Seite abrufen, veröffentlicht er zuerst etwas, das er unabhängig veröffentlichen kann, und wenn es abhängige Dinge gibt, liest er eine Reihe von Testnachrichten vom Bus, versteht, dass er sie verarbeiten, melden und melden kann , wenn nötig, poste sie weiter und darüber sagt er - alles ist in Ordnung, ich lebe.
Sehr oft hören wir die Frage: "Wie können wir dies an Kampfdaten testen?" Zum Beispiel sprechen wir über den gleichen Bestellservice. Die Bestellung sendet Nachrichten an das Lager, in dem die Waren abgeschrieben werden: Wir können dies nicht an den Kampfdaten testen, da "meine Waren abgeschrieben werden!" Beenden: Planen Sie in der Anfangsphase den gesamten Test. Sie haben Unit-Tests, die verspotten. Tun Sie es also auf einer tieferen Ebene, wo Sie einen Kommunikationskanal haben, der dem Geschäft keinen Schaden zufügt.
Infrastrukturebene
Die Überwachung der Infrastruktur wird seit langem als Überwachung selbst angesehen.
- Die Überwachung der Infrastruktur kann und sollte als separater Prozess gestartet werden.
- Sie sollten zunächst nicht die Infrastruktur eines Arbeitsprojekts überwachen, auch wenn Sie dies wirklich möchten. Dies ist eine Wunde für alle Entwickler. "Zuerst überwache ich den Cluster, dann die Infrastruktur" - d. H. Zunächst wird überwacht, was darunter liegt, aber es wird nicht in die Anwendung geklettert. Weil die Anwendung für den Devopa unverständlich ist. Sie haben es ihm zugespielt, und er versteht nicht, wie es funktioniert. Und er versteht die Infrastruktur und beginnt damit. Aber nein - Sie müssen die Anwendung immer zuerst überwachen.
- . , , - . on-call, , « ». .
-
:
- ELK. . - , .
- APM. APM (NewRelic, BlackFire, Datadog). , - , .
- Tracing. , . , tracing — . – ! . Jaeger/Zipkin
- : . Grafana. PagerDuty. (, …). ,
- : ( , ). Oncall : , , , — ( — , : , ). , — (« — »), .
- « » workflow : , , . , — ; .
, :
- — Prometheus + Grafana;
- — ELK;
- APM Tracing — Jaeger (Zipkin).
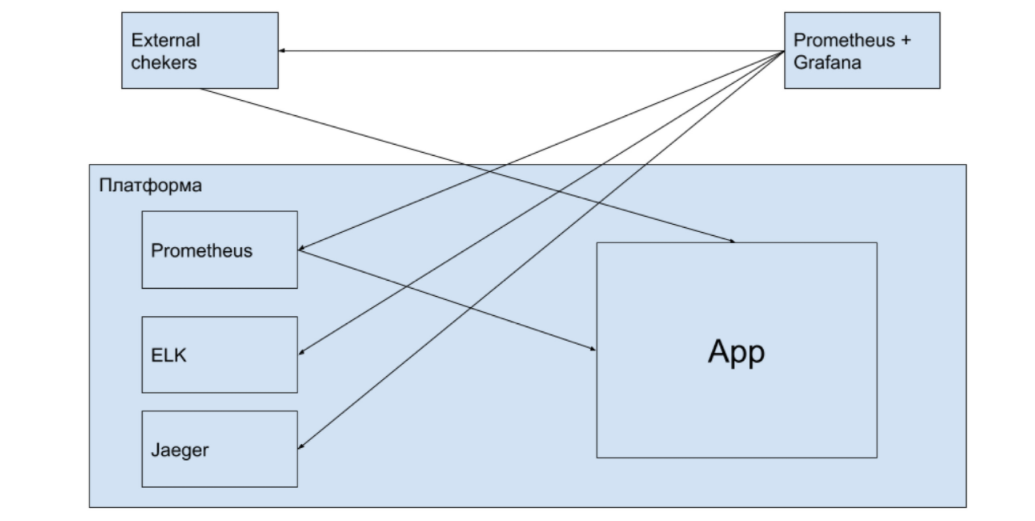
. , , , . , . , , , — .
, :
Prometheus Kubernetes — ?! , ? , , — , .
. . , Promtheus, , , . ? , , .
Schlussfolgerungen
- — , . 98% — . , , , --.
- : 30% , .
- , , - , — . , — .
- ( ) — .
- , , « » — , .
Saint Highload++.UPD ( ):
1. , , , «, , , ». , : DevOps , — , , , .
2. Ich versuche nicht anzudeuten, sie sagen: "Alles ist überall schlecht, aber hier können wir Sie überwachen - kommen Sie zu ITSumma." Nein, wenn das Projekt gestartet wird, kann die Überwachung nicht von einem Drittunternehmen durchgeführt werden. Natürlich haben wir auch Geschäftsziele, und wir denken wirklich daran, eine Beratung einzuführen, um das Projekt im Entwicklungsprozess zu unterstützen und zu vermitteln, wie der Überwachungsteil der Entwicklung ordnungsgemäß durchgeführt werden kann.Wenn du an meinen Ideen und Gedanken dazu interessiert bist und so weiter, dann kannst du
den Kanal lesen :-)