Wir haben uns bereits mit der PostgreSQL-
Indexierungs-Engine und der Schnittstelle von Zugriffsmethoden vertraut gemacht und
Hash-Indizes ,
B-Bäume sowie
GiST- und
SP-GiST- Indizes
erörtert . Und dieser Artikel wird GIN-Index enthalten.
Gin
"Gin? .. Gin ist anscheinend so ein amerikanischer Schnaps? .."
"Ich bin kein Getränk, oh, neugieriger Junge!" wieder flammte der alte Mann auf, wieder erkannte er sich und nahm sich wieder in die Hand. "Ich bin kein Getränk, sondern ein mächtiger und unerschrockener Geist, und es gibt keine solche Magie auf der Welt, die ich nicht tun könnte."- Lazar Lagin, "Old Khottabych".
Gin steht für Generalized Inverted Index und sollte als Geist betrachtet werden, nicht als Getränk.-
READMEAllgemeines Konzept
GIN ist der abgekürzte Generalized Inverted Index. Dies ist ein sogenannter
invertierter Index . Es manipuliert Datentypen, deren Werte nicht atomar sind, sondern aus Elementen bestehen. Wir werden diese Typen zusammengesetzt nennen. Und dies sind nicht die Werte, die indiziert werden, sondern einzelne Elemente; Jedes Element verweist auf die Werte, in denen es vorkommt.
Eine gute Analogie zu dieser Methode ist der Index am Ende eines Buches, der für jeden Begriff eine Liste der Seiten enthält, auf denen dieser Begriff vorkommt. Die Zugriffsmethode muss eine schnelle Suche nach indizierten Elementen gewährleisten, genau wie der Index in einem Buch. Daher werden diese Elemente als vertrauter
B-Baum gespeichert (eine andere, einfachere Implementierung wird dafür verwendet, spielt in diesem Fall jedoch keine Rolle). Ein geordneter Satz von Verweisen auf Tabellenzeilen, die zusammengesetzte Werte mit dem Element enthalten, ist mit jedem Element verknüpft. Die Ordnungsmäßigkeit ist für das Abrufen von Daten nicht erforderlich (die Sortierreihenfolge der TIDs bedeutet nicht viel), aber wichtig für die interne Struktur des Index.
Elemente werden niemals aus dem GIN-Index gelöscht. Es wird angenommen, dass Werte, die Elemente enthalten, verschwinden, entstehen oder variieren können, aber die Menge der Elemente, aus denen sie bestehen, ist mehr oder weniger stabil. Diese Lösung vereinfacht Algorithmen für die gleichzeitige Arbeit mehrerer Prozesse mit dem Index erheblich.
Wenn die Liste der TIDs ziemlich klein ist, kann sie auf dieselbe Seite wie das Element passen (und wird als "Buchungsliste" bezeichnet). Wenn die Liste jedoch groß ist, ist eine effizientere Datenstruktur erforderlich, und wir sind uns dessen bereits bewusst - es ist wieder ein B-Baum. Ein solcher Baum befindet sich auf separaten Datenseiten (und wird als "Buchungsbaum" bezeichnet).
Der GIN-Index besteht also aus dem B-Baum der Elemente, und B-Bäume oder flache Listen von TIDs sind mit Blattzeilen dieses B-Baums verknüpft.
Genau wie die zuvor beschriebenen GiST- und SP-GiST-Indizes bietet GIN einem Anwendungsentwickler die Schnittstelle zur Unterstützung verschiedener Operationen über zusammengesetzte Datentypen.
Volltextsuche
Der Hauptanwendungsbereich für die GIN-Methode ist die Beschleunigung der Volltextsuche. Daher ist es sinnvoll, sie als Beispiel für eine detailliertere Diskussion dieses Index zu verwenden.
Der Artikel zu GiST enthält bereits eine kleine Einführung in die Volltextsuche.
Kommen wir also ohne Wiederholungen direkt zum Punkt. Es ist klar, dass zusammengesetzte Werte in diesem Fall
Dokumente sind und Elemente dieser Dokumente
Lexeme sind .
Betrachten wir das Beispiel aus einem GiST-Artikel:
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc); postgres=# create index on ts using gin(doc_tsv);
Eine mögliche Struktur dieses Index ist in der Abbildung dargestellt:
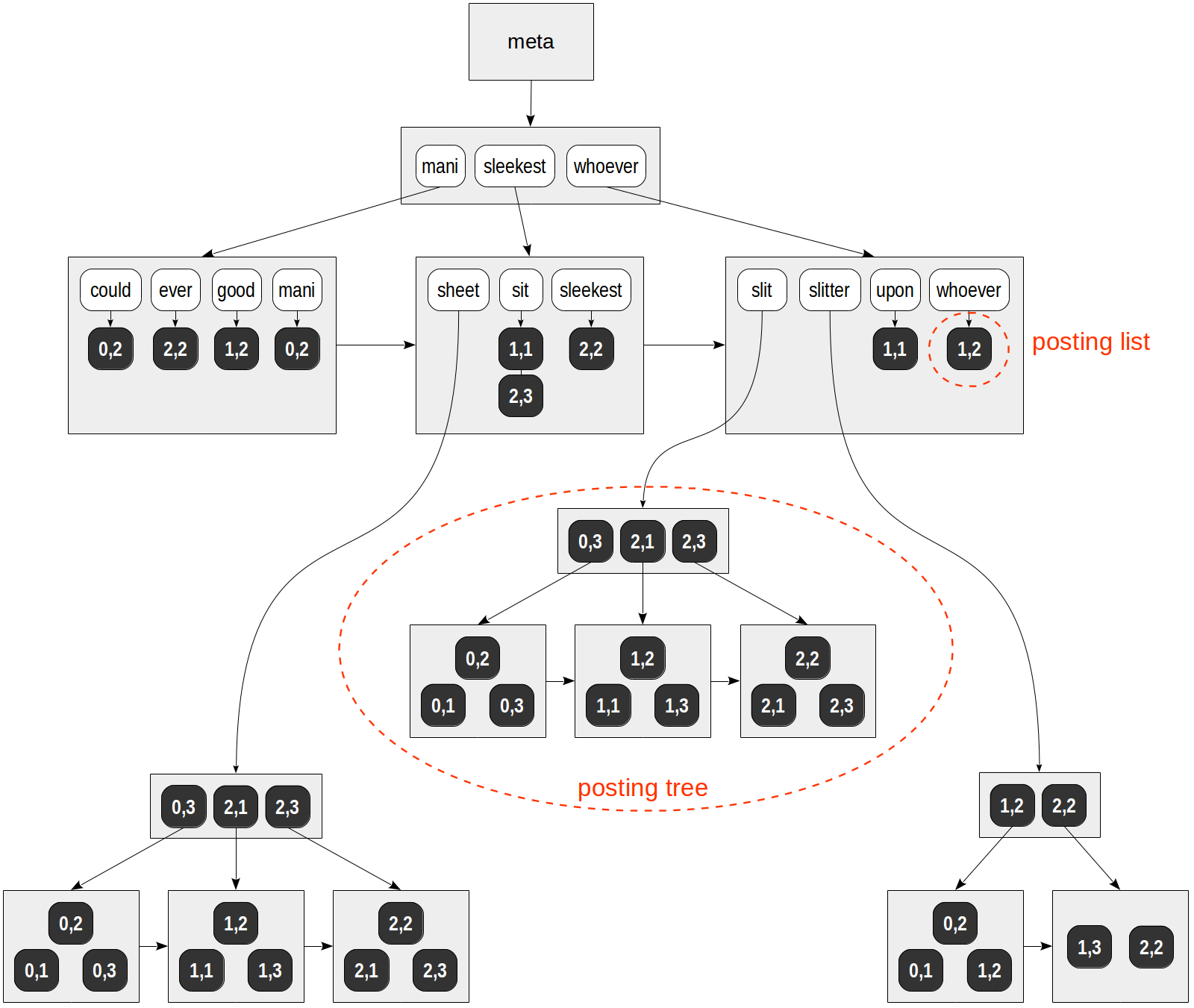
Im Gegensatz zu allen vorherigen Abbildungen werden Verweise auf Tabellenzeilen (TIDs) nicht mit Pfeilen, sondern mit numerischen Werten auf dunklem Hintergrund (Seitenzahl und Position auf der Seite) gekennzeichnet.
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
In diesem spekulativen Beispiel passt die Liste der TIDs in reguläre Seiten für alle Lexeme außer "Blatt", "Schlitz" und "Schlitz". Diese Lexeme kamen in vielen Dokumenten vor, und die Listen der TIDs für sie wurden in einzelne B-Bäume eingefügt.
Wie können wir übrigens herausfinden, wie viele Dokumente ein Lexem enthalten? Für einen kleinen Tisch funktioniert eine „direkte“ Technik (siehe unten), aber wir werden weiter lernen, wie man mit größeren Tischen umgeht.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count ----------+------- sheet | 9 slit | 8 slitter | 5 sit | 2 upon | 1 mani | 1 whoever | 1 sleekest | 1 good | 1 could | 1 ever | 1 (11 rows)
Beachten Sie auch, dass Seiten des GIN-Index im Gegensatz zu einem normalen B-Baum eher durch eine unidirektionale als durch eine bidirektionale Liste verbunden sind. Dies ist ausreichend, da eine Baumüberquerung nur in eine Richtung erfolgt.
Beispiel einer Abfrage
Wie wird die folgende Abfrage für unser Beispiel durchgeführt?
postgres=# explain(costs off) select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) (4 rows)
Einzelne Lexeme (Suchschlüssel) werden zuerst aus der Abfrage extrahiert: "mani" und "slitter". Dies erfolgt durch eine spezielle API-Funktion, die den von der Operatorklasse festgelegten Datentyp und die Strategie berücksichtigt:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'tsvector_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- @@(tsvector,tsquery) | 1 matching search query @@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility) (2 rows)
Im B-Baum der Lexeme finden wir als nächstes beide Schlüssel und gehen die fertigen Listen der TIDs durch. Wir bekommen:
für "mani" - (0,2).
für "Slitter" - (0,1), (0,2), (1,2), (1,3), (2,2).
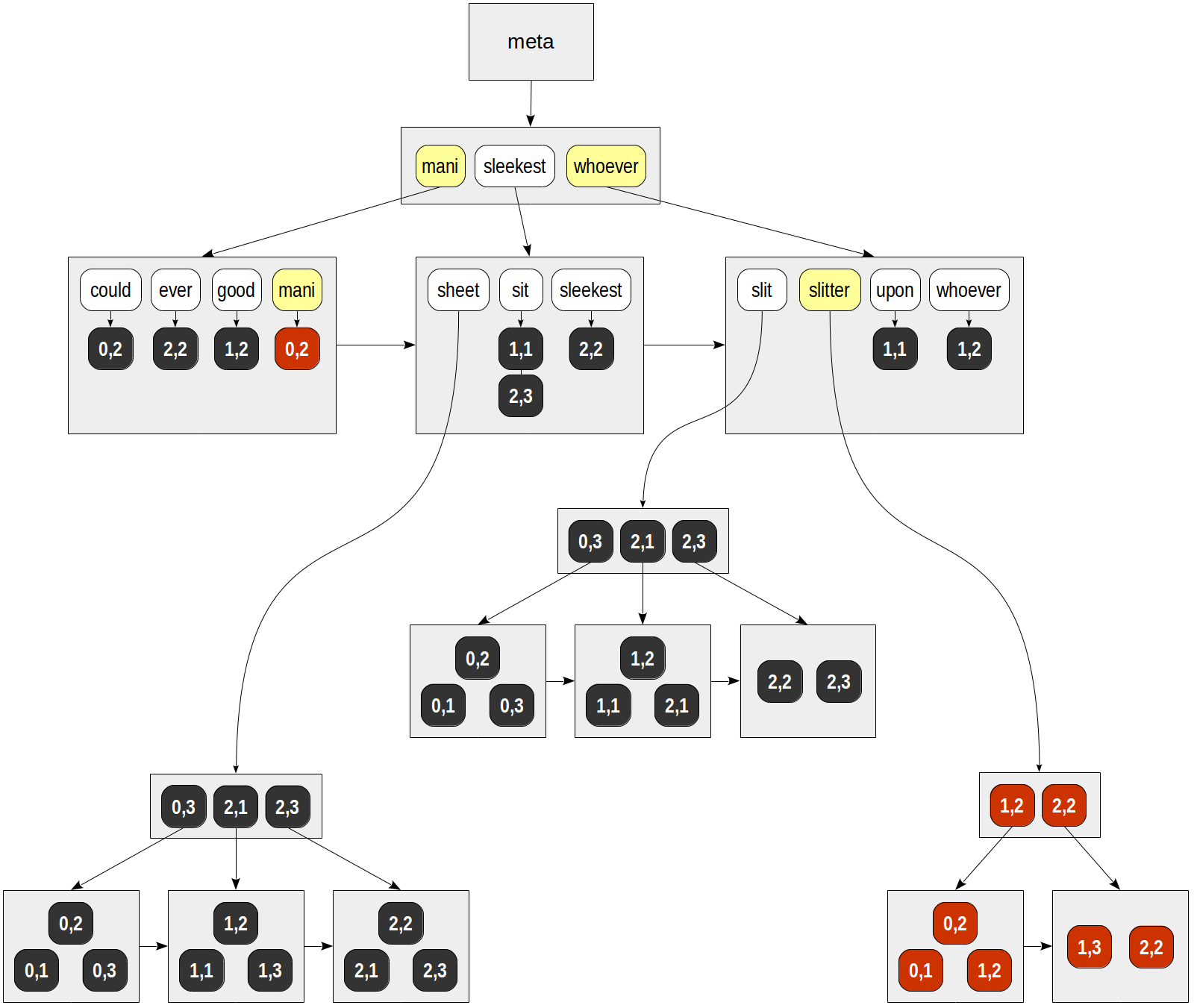
Schließlich wird für jede gefundene TID eine API-Konsistenzfunktion aufgerufen, die bestimmen muss, welche der gefundenen Zeilen mit der Suchabfrage übereinstimmen. Da die Lexeme in unserer Abfrage durch Boolesche Werte "und" verknüpft sind, wird nur (0,2) zurückgegeben:
| | | consistency | | | function TID | mani | slitter | slit & slitter -------+------+---------+---------------- (0,1) | f | T | f (0,2) | T | T | T (1,2) | f | T | f (1,3) | f | T | f (2,2) | f | T | f
Und das Ergebnis ist:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc --------------------------------------------- How many sheets could a sheet slitter slit? (1 row)
Wenn wir diesen Ansatz mit dem bereits für GiST diskutierten vergleichen, erscheint der Vorteil von GIN für die Volltextsuche offensichtlich. Aber es steckt mehr dahinter als man denkt.
Das Problem eines langsamen Updates
Die Sache ist, dass das Einfügen oder Aktualisieren von Daten in den GIN-Index ziemlich langsam ist. Jedes Dokument enthält normalerweise viele zu indizierende Lexeme. Wenn daher nur ein Dokument hinzugefügt oder aktualisiert wird, müssen wir den Indexbaum massiv aktualisieren.
Wenn andererseits mehrere Dokumente gleichzeitig aktualisiert werden, können einige ihrer Lexeme gleich sein, und der Gesamtaufwand ist geringer als bei der Aktualisierung von Dokumenten nacheinander.
Der GIN-Index verfügt über den Speicherparameter "fastupdate", den wir bei der Indexerstellung angeben und später aktualisieren können:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
Wenn dieser Parameter aktiviert ist, werden Aktualisierungen in einer separaten ungeordneten Liste (auf einzelnen verbundenen Seiten) gesammelt. Wenn diese Liste groß genug ist oder während des Staubsaugens, werden alle akkumulierten Aktualisierungen sofort am Index vorgenommen. Welche Liste als "groß genug" zu betrachten ist, wird durch den Konfigurationsparameter "gin_pending_list_limit" oder durch den gleichnamigen Speicherparameter des Index bestimmt.
Dieser Ansatz hat jedoch Nachteile: Erstens wird die Suche verlangsamt (da die ungeordnete Liste zusätzlich zum Baum durchsucht werden muss), und zweitens kann eine nächste Aktualisierung unerwartet viel Zeit in Anspruch nehmen, wenn die ungeordnete Liste übergelaufen ist.
Suche nach einer Teilübereinstimmung
Wir können Teilübereinstimmungen in der Volltextsuche verwenden. Betrachten Sie beispielsweise die folgende Abfrage:
gin=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc -------------------------------------------------------- Can a sheet slitter slit sheets? How many sheets could a sheet slitter slit? I slit a sheet, a sheet I slit. Upon a slitted sheet I sit. Whoever slit the sheets is a good sheet slitter. I am a sheet slitter. I slit sheets. I am the sleekest sheet slitter that ever slit sheets. She slits the sheet she sits on. (9 rows)
Diese Abfrage findet Dokumente, die Lexeme enthalten, die mit "slit" beginnen. In diesem Beispiel sind solche Lexeme "Schlitz" und "Schlitz".
Eine Abfrage wird sicherlich auch ohne Indizes funktionieren, aber GIN ermöglicht es auch, die folgende Suche zu beschleunigen:
postgres=# explain (costs off) select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN ------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) (4 rows)
Hier werden alle Lexeme mit dem in der Suchabfrage angegebenen Präfix im Baum nachgeschlagen und durch ein boolesches "oder" verbunden.
Häufige und seltene Lexeme
Um zu sehen, wie die Indizierung für Live-Daten funktioniert, nehmen wir das Archiv der "pgsql-hackers" -E-Mails, die wir bereits bei der Erörterung von GiST verwendet haben.
Diese Version des Archivs enthält 356125 Nachrichten mit dem Versanddatum, dem Betreff, dem Autor und dem Text.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
Betrachten wir ein Lexem, das in vielen Dokumenten vorkommt. Die Abfrage mit "unnest" funktioniert bei einer so großen Datenmenge nicht. Die richtige Technik besteht darin, die Funktion "ts_stat" zu verwenden, die Informationen zu Lexemen, die Anzahl der Dokumente, in denen sie aufgetreten sind, und die Gesamtzahl der Vorkommen bereitstellt.
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') order by ndoc desc limit 3;
word | ndoc -------+-------- re | 322141 wrote | 231174 use | 176917 (3 rows)
Wählen wir "geschrieben".
Und wir werden ein Wort nehmen, das für Entwickler-E-Mails selten vorkommt, sagen wir "Tattoo":
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc --------+------ tattoo | 2 (1 row)
Gibt es Dokumente, in denen diese beiden Lexeme vorkommen? Es scheint, dass es gibt:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row)
Es stellt sich die Frage, wie diese Abfrage durchgeführt werden soll. Wenn wir, wie oben beschrieben, Listen mit TIDs für beide Lexeme erhalten, ist die Suche offensichtlich ineffizient: Wir müssen mehr als 200.000 Werte durchlaufen, von denen nur einer übrig bleibt. Glücklicherweise versteht der Algorithmus unter Verwendung der Planerstatistik, dass "geschriebenes" Lexem häufig vorkommt, während "Tätowierung" selten vorkommt. Daher wird die Suche nach dem seltenen Lexem durchgeführt, und die beiden abgerufenen Dokumente werden dann auf das Auftreten eines "geschriebenen" Lexems überprüft. Und das geht aus der Abfrage hervor, die schnell durchgeführt wird:
fts=# \timing on fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row) Time: 0,959 ms
Die Suche nach "geschrieben" allein dauert deutlich länger:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count -------- 231174 (1 row) Time: 2875,543 ms (00:02,876)
Diese Optimierung funktioniert sicherlich nicht nur für zwei Lexeme, sondern auch in komplexeren Fällen.
Einschränkung des Abfrageergebnisses
Ein Merkmal der GIN-Zugriffsmethode ist, dass das Ergebnis immer als Bitmap zurückgegeben wird: Diese Methode kann das Ergebnis TID für TID nicht zurückgeben. Aus diesem Grund verwenden alle Abfragepläne in diesem Artikel den Bitmap-Scan.
Daher ist die Einschränkung des Index-Scan-Ergebnisses mithilfe der LIMIT-Klausel nicht sehr effizient. Beachten Sie die vorhergesagten Kosten der Operation (Feld "Kosten" des Knotens "Limit"):
fts=# explain (costs off) select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN ----------------------------------------------------------------------------------------- Limit (cost=1283.61..1285.13 rows=1) -> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207) Recheck Cond: (tsv @@ to_tsquery('wrote'::text)) -> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207) Index Cond: (tsv @@ to_tsquery('wrote'::text)) (5 rows)
Die Kosten werden auf 1285,13 geschätzt, was etwas höher ist als die Kosten für die Erstellung der gesamten Bitmap 1249.30 (Feld "Kosten" des Bitmap-Index-Scan-Knotens).
Daher verfügt der Index über eine spezielle Funktion, um die Anzahl der Ergebnisse zu begrenzen. Der Schwellenwert wird im Konfigurationsparameter "gin_fuzzy_search_limit" angegeben und ist standardmäßig gleich Null (es findet keine Einschränkung statt). Aber wir können den Schwellenwert einstellen:
fts=# set gin_fuzzy_search_limit = 1000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 5746 (1 row)
fts=# set gin_fuzzy_search_limit = 10000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 14726 (1 row)
Wie wir sehen können, unterscheidet sich die Anzahl der von der Abfrage zurückgegebenen Zeilen für verschiedene Parameterwerte (wenn der Indexzugriff verwendet wird). Die Einschränkung ist nicht streng: Es können mehr Zeilen als angegeben zurückgegeben werden, was einen "unscharfen" Teil des Parameternamens rechtfertigt.
Kompakte Darstellung
GIN-Indizes sind unter anderem dank ihrer Kompaktheit gut. Erstens, wenn ein und dasselbe Lexem in mehreren Dokumenten vorkommt (und dies ist normalerweise der Fall), wird es nur einmal im Index gespeichert. Zweitens werden TIDs in geordneter Weise im Index gespeichert, und dies ermöglicht es uns, eine einfache Komprimierung zu verwenden: Jede nächste TID in der Liste wird tatsächlich als Differenz zur vorherigen gespeichert. Dies ist normalerweise eine kleine Zahl, die viel weniger Bits benötigt als eine vollständige Sechs-Byte-TID.
Um eine Vorstellung von der Größe zu bekommen, erstellen wir einen B-Baum aus dem Text der Nachrichten. Aber ein fairer Vergleich wird sicherlich nicht passieren:
- GIN basiert auf einem anderen Datentyp ("tsvector" anstelle von "text"), der kleiner ist.
- Gleichzeitig muss die Größe der Nachrichten für den B-Baum auf ungefähr zwei Kilobyte verkürzt werden.
Trotzdem fahren wir fort:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
Wir werden auch den GiST-Index erstellen:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
Die Größe der Indizes bei "Vakuum voll":
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin, pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist, pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree --------+--------+-------- 179 MB | 125 MB | 546 MB (1 row)
Aufgrund der Kompaktheit der Darstellung können wir versuchen, den GIN-Index während der Migration von Oracle als Ersatz für Bitmap-Indizes zu verwenden (ohne auf Details einzugehen,
verweise ich für neugierige Köpfe
auf Lewis 'Beitrag ). In der Regel werden Bitmap-Indizes für Felder mit wenigen eindeutigen Werten verwendet, was auch für GIN hervorragend ist. Und wie
im ersten Artikel gezeigt , kann PostgreSQL eine Bitmap basierend auf jedem Index, einschließlich GIN, im laufenden Betrieb erstellen.
GiST oder GIN?
Für viele Datentypen stehen Operatorklassen sowohl für GiST als auch für GIN zur Verfügung, was die Frage aufwirft, welcher Index verwendet werden soll. Vielleicht können wir bereits einige Schlussfolgerungen ziehen.
In der Regel übertrifft GIN GiST in Genauigkeit und Suchgeschwindigkeit. Wenn die Daten nicht häufig aktualisiert werden und eine schnelle Suche erforderlich ist, ist GIN höchstwahrscheinlich eine Option.
Wenn andererseits die Daten intensiv aktualisiert werden, scheinen die Gemeinkosten für die Aktualisierung von GIN zu hoch zu sein. In diesem Fall müssen wir beide Optionen vergleichen und die auswählen, deren Eigenschaften besser ausgewogen sind.
Arrays
Ein weiteres Beispiel für die Verwendung von GIN ist die Indizierung von Arrays. In diesem Fall werden Array-Elemente in den Index aufgenommen, wodurch eine Reihe von Operationen über Arrays beschleunigt werden können:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- &&(anyarray,anyarray) | 1 intersection @>(anyarray,anyarray) | 2 contains array <@(anyarray,anyarray) | 3 contained in array =(anyarray,anyarray) | 4 equality (4 rows)
Unsere
Demo-Datenbank bietet eine Routenansicht mit Informationen zu Flügen. Diese Ansicht enthält unter anderem die Spalte "days_of_week" - eine Reihe von Wochentagen, an denen Flüge stattfinden. Zum Beispiel startet ein Flug von Vnukovo nach Gelendzhik dienstags, donnerstags und sonntags:
demo=# select departure_airport_name, arrival_airport_name, days_of_week from routes where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week ------------------------+----------------------+-------------- Vnukovo | Gelendzhik | {2,4,7} (1 row)
Um den Index zu erstellen, "materialisieren" wir die Ansicht in einer Tabelle:
demo=# create table routes_t as select * from routes; demo=# create index on routes_t using gin(days_of_week);
Jetzt können wir den Index verwenden, um alle Flüge kennenzulernen, die dienstags, donnerstags und sonntags abfliegen:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (4 rows)
Es scheint, dass es sechs von ihnen gibt:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week -----------+------------------------+----------------------+-------------- PG0005 | Domodedovo | Pskov | {2,4,7} PG0049 | Vnukovo | Gelendzhik | {2,4,7} PG0113 | Naryan-Mar | Domodedovo | {2,4,7} PG0249 | Domodedovo | Gelendzhik | {2,4,7} PG0449 | Stavropol | Vnukovo | {2,4,7} PG0540 | Barnaul | Vnukovo | {2,4,7} (6 rows)
Wie wird diese Abfrage durchgeführt? Genau so wie oben beschrieben:
- Aus dem Array {2,4,7}, das hier die Rolle der Suchabfrage spielt, werden Elemente (Suchschlüsselwörter) extrahiert. Offensichtlich sind dies die Werte von "2", "4" und "7".
- Im Baum der Elemente werden die extrahierten Schlüssel gefunden, und für jeden von ihnen wird die Liste der TIDs ausgewählt.
- Von allen gefundenen TIDs wählt die Konsistenzfunktion diejenigen aus der Abfrage aus, die dem Operator entsprechen. Für den Operator
= stimmen nur die TIDs überein, die in allen drei Listen aufgetreten sind (mit anderen Worten, das ursprüngliche Array muss alle Elemente enthalten). Dies reicht jedoch nicht aus: Es wird auch benötigt, damit das Array keine anderen Werte enthält, und wir können diese Bedingung nicht mit dem Index überprüfen. In diesem Fall fordert die Zugriffsmethode die Indizierungs-Engine daher auf, alle mit der Tabelle zurückgegebenen TIDs erneut zu überprüfen.
Interessanterweise gibt es Strategien (z. B. "in Array enthalten"), die nichts überprüfen können und alle in der Tabelle gefundenen TIDs erneut überprüfen müssen.
Aber was tun, wenn wir die Flüge kennen müssen, die dienstags, donnerstags und sonntags von Moskau abfliegen? Der Index unterstützt die zusätzliche Bedingung nicht, die in die Spalte "Filter" gelangt.
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) Filter: (departure_city = 'Moscow'::text) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (5 rows)
Hier ist dies in Ordnung (der Index wählt sowieso nur sechs Zeilen aus), aber in Fällen, in denen die zusätzliche Bedingung die Selektionsfähigkeit erhöht, ist eine solche Unterstützung erwünscht. Wir können jedoch nicht einfach den Index erstellen:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin" HINT: You must specify an operator class for the index or define a default operator class for the data type.
Die Erweiterung "
btree_gin " hilft jedoch,
indem GIN-Operatorklassen
hinzugefügt werden, die die Arbeit eines regulären B-Baums simulieren.
demo=# create extension btree_gin; demo=# create index on routes_t using gin(days_of_week,departure_city); demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) -> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) (4 rows)
Jsonb
Ein weiteres Beispiel für einen zusammengesetzten Datentyp mit integrierter GIN-Unterstützung ist JSON. Um mit JSON-Werten arbeiten zu können, sind derzeit eine Reihe von Operatoren und Funktionen definiert, von denen einige mithilfe von Indizes beschleunigt werden können:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname in ('jsonb_ops','jsonb_path_ops') and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str ----------------+------------------+----- jsonb_ops | ?(jsonb,text) | 9 top-level key exists jsonb_ops | ?|(jsonb,text[]) | 10 some top-level key exists jsonb_ops | ?&(jsonb,text[]) | 11 all top-level keys exist jsonb_ops | @>(jsonb,jsonb) | 7 JSON value is at top level jsonb_path_ops | @>(jsonb,jsonb) | 7 (5 rows)
Wie wir sehen können, stehen zwei Operatorklassen zur Verfügung: "jsonb_ops" und "jsonb_path_ops".
Die erste Operatorklasse "jsonb_ops" wird standardmäßig verwendet. Alle Schlüssel, Werte und Array-Elemente werden als Elemente des anfänglichen JSON-Dokuments in den Index aufgenommen. Jedem dieser Elemente wird ein Attribut hinzugefügt, das angibt, ob dieses Element ein Schlüssel ist (dies wird für "vorhandene" Strategien benötigt, die zwischen Schlüsseln und Werten unterscheiden).
Stellen wir zum Beispiel einige Zeilen aus "Routen" als JSON wie folgt dar:
demo=# create table routes_jsonb as select to_jsonb(t) route from ( select departure_airport_name, arrival_airport_name, days_of_week from routes order by flight_no limit 4 ) t; demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty -------+------------------------------------------------- (0,1) | { + | "days_of_week": [ + | 1 + | ], + | "arrival_airport_name": "Surgut", + | "departure_airport_name": "Ust-Ilimsk" + | } (0,2) | { + | "days_of_week": [ + | 2 + | ], + | "arrival_airport_name": "Ust-Ilimsk", + | "departure_airport_name": "Surgut" + | } (0,3) | { + | "days_of_week": [ + | 1, + | 4 + | ], + | "arrival_airport_name": "Sochi", + | "departure_airport_name": "Ivanovo-Yuzhnyi"+ | } (0,4) | { + | "days_of_week": [ + | 2, + | 5 + | ], + | "arrival_airport_name": "Ivanovo-Yuzhnyi", + | "departure_airport_name": "Sochi" + | } (4 rows)
demo=# create index on routes_jsonb using gin(route);
Der Index kann wie folgt aussehen:
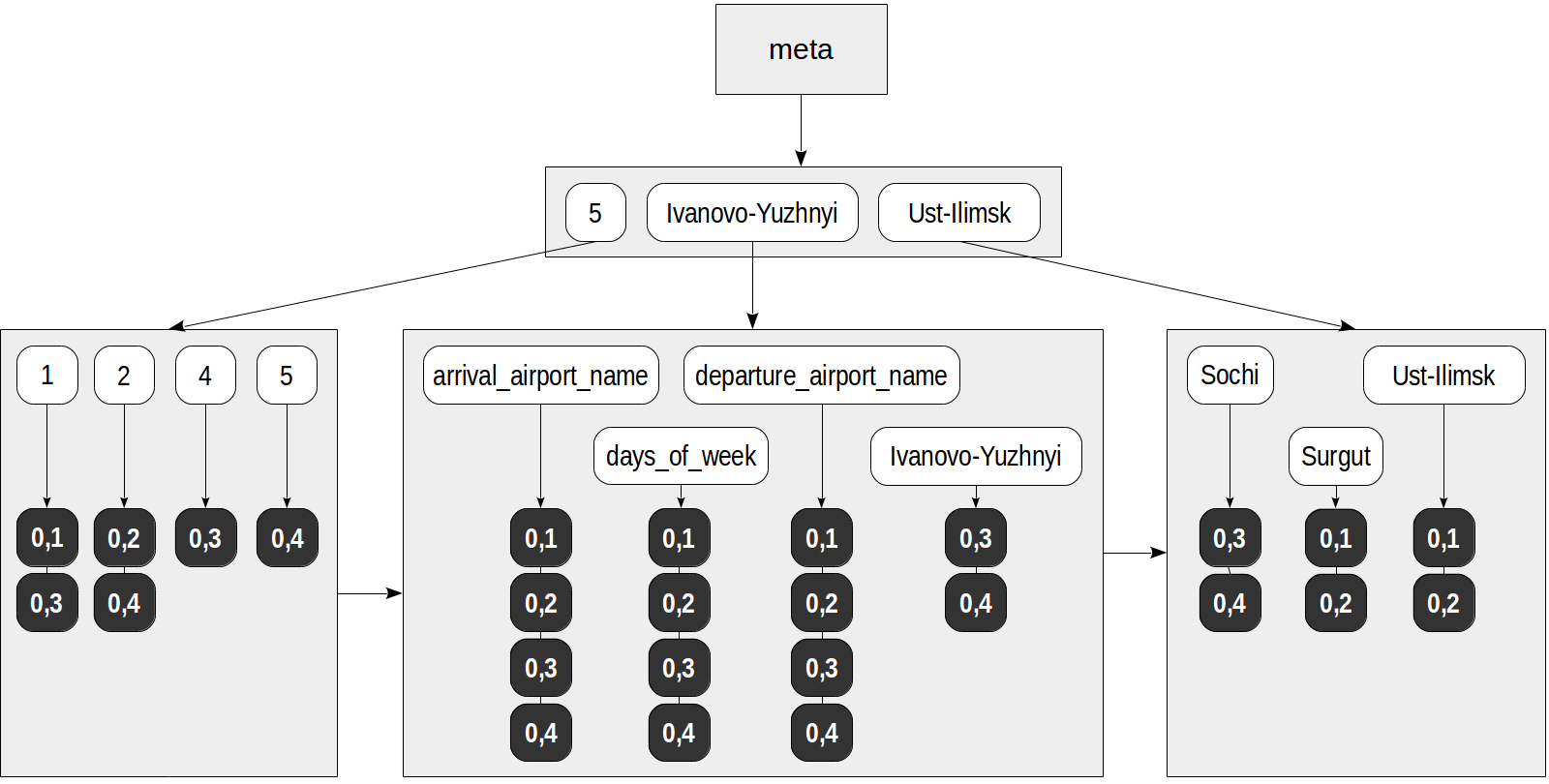
Eine Abfrage wie diese kann nun beispielsweise mithilfe des Index ausgeführt werden:
demo=# explain (costs off) select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
QUERY PLAN --------------------------------------------------------------- Bitmap Heap Scan on routes_jsonb Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb) -> Bitmap Index Scan on routes_jsonb_route_idx Index Cond: (route @> '{"days_of_week": [5]}'::jsonb) (4 rows)
Beginnend mit dem Stammverzeichnis des JSON-Dokuments prüft der Operator
@> , ob die angegebene Route (
"days_of_week": [5] ) auftritt. Hier gibt die Abfrage eine Zeile zurück:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty ------------------------------------------------ { + "days_of_week": [ + 2, + 5 + ], + "arrival_airport_name": "Ivanovo-Yuzhnyi",+ "departure_airport_name": "Sochi" + } (1 row)
Die Abfrage wird wie folgt durchgeführt:
- In der Suchabfrage (
"days_of_week": [5] ) werden Elemente (Suchschlüssel) extrahiert: "days_of_week" und "5".
- Im Baum der Elemente werden die extrahierten Schlüssel gefunden, und für jeden von ihnen wird die Liste der TIDs ausgewählt: für "5" - (0,4) und für "Tage der Woche" - (0,1), (0,2) ), (0,3), (0,4).
- Von allen gefundenen TIDs wählt die Konsistenzfunktion diejenigen aus der Abfrage aus, die dem Operator entsprechen. Für den Operator
@> sind Dokumente, die nicht alle Elemente aus der Suchabfrage enthalten, nicht sicher, sodass nur (0,4) übrig bleibt. Wir müssen jedoch die mit der Tabelle verbleibende TID erneut überprüfen, da aus dem Index nicht ersichtlich ist, in welcher Reihenfolge die gefundenen Elemente im JSON-Dokument vorkommen.
Weitere Informationen zu anderen Operatoren finden Sie in
der Dokumentation .
Zusätzlich zu herkömmlichen Operationen für den Umgang mit JSON ist seit langem die Erweiterung "jsquery" verfügbar, die eine Abfragesprache mit umfangreicheren Funktionen (und sicherlich mit Unterstützung von GIN-Indizes) definiert. Außerdem wurde 2016 ein neuer SQL-Standard herausgegeben, der seine eigenen Operationen und die Abfragesprache "SQL / JSON-Pfad" definiert. Eine Implementierung dieses Standards wurde bereits durchgeführt, und wir glauben, dass er in PostgreSQL 11 erscheinen wird.
Der SQL / JSON-Pfad-Patch wurde schließlich für PostgreSQL 12 festgeschrieben , während andere Teile noch unterwegs sind. Hoffentlich sehen wir die vollständig implementierte Funktion in PostgreSQL 13.
Interna
Wir können mit der Erweiterung "
pageinspect " in den GIN-Index
schauen .
fts=# create extension pageinspect;
Die Informationen auf der Metaseite zeigen allgemeine Statistiken:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+----------- pending_head | 4294967295 pending_tail | 4294967295 tail_free_size | 0 n_pending_pages | 0 n_pending_tuples | 0 n_total_pages | 22968 n_entry_pages | 13751 n_data_pages | 9216 n_entries | 1423598 version | 2
Die Seitenstruktur bietet einen speziellen Bereich, in dem Zugriffsmethoden ihre Informationen speichern. Dieser Bereich ist für gewöhnliche Programme wie Vakuum "undurchsichtig". Die Funktion "Gin_page_opaque_info" zeigt diese Daten für GIN an. Zum Beispiel können wir die Indexseiten kennenlernen:
fts=# select flags, count(*) from generate_series(1,22967) as g(id),
flags | count ------------------------+------- {meta} | 1 meta page {} | 133 internal page of element B-tree {leaf} | 13618 leaf page of element B-tree {data} | 1497 internal page of TID B-tree {data,leaf,compressed} | 7719 leaf page of TID B-tree (5 rows)
Die Funktion "Gin_leafpage_items" bietet Informationen zu TIDs, die auf Seiten {Daten, Blatt, komprimiert} gespeichert sind:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]--------------------------------------------------------------------- first_tid | (239,44) nbytes | 248 tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",... -[ RECORD 2 ]--------------------------------------------------------------------- first_tid | (247,40) nbytes | 248 tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",... ...
Beachten Sie hier, dass die verbleibenden Seiten des TID-Baums tatsächlich kleine komprimierte Listen von Zeigern auf Tabellenzeilen und nicht einzelne Zeiger enthalten.
Eigenschaften
Schauen wir uns die Eigenschaften der GIN-Zugriffsmethode an (Abfragen
wurden bereits bereitgestellt ).
amname | name | pg_indexam_has_property --------+---------------+------------------------- gin | can_order | f gin | can_unique | f gin | can_multi_col | t gin | can_exclude | f
Interessanterweise unterstützt GIN die Erstellung von mehrspaltigen Indizes. Im Gegensatz zu einem regulären B-Baum speichert ein mehrspaltiger Index anstelle von zusammengesetzten Schlüsseln jedoch weiterhin einzelne Elemente, und die Spaltennummer wird für jedes Element angegeben.
Die folgenden Indexschicht-Eigenschaften sind verfügbar:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Beachten Sie, dass die Rückgabe von Ergebnissen TID für TID (Index-Scan) nicht unterstützt wird. Es ist nur ein Bitmap-Scan möglich.
Der Rückwärtsscan wird ebenfalls nicht unterstützt: Diese Funktion ist nur für den Indexscan erforderlich, nicht jedoch für den Bitmap-Scan.
Und die folgenden Eigenschaften sind Spaltenebenen:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Hier ist nichts verfügbar: keine Sortierung (was klar ist), keine Verwendung des Index als Deckung (da das Dokument selbst nicht im Index gespeichert ist), keine Manipulation von NULL-Werten (da dies für Elemente vom zusammengesetzten Typ nicht sinnvoll ist) .
Andere Datentypen
Es stehen einige weitere Erweiterungen zur Verfügung, die für einige Datentypen die Unterstützung von GIN hinzufügen.
- " pg_trgm " ermöglicht es uns, die "Ähnlichkeit" von Wörtern zu bestimmen, indem wir vergleichen, wie viele gleiche Drei-Buchstaben-Sequenzen (Trigramme) verfügbar sind. Es werden zwei Operatorklassen hinzugefügt, "gist_trgm_ops" und "gin_trgm_ops", die verschiedene Operatoren unterstützen, einschließlich des Vergleichs mit LIKE und regulären Ausdrücken. Wir können diese Erweiterung zusammen mit der Volltextsuche verwenden, um Wortoptionen zur Behebung von Tippfehlern vorzuschlagen.
- " hstore " implementiert "Schlüsselwert" -Speicher. Für diesen Datentyp stehen Operatorklassen für verschiedene Zugriffsmethoden zur Verfügung, einschließlich GIN. Mit der Einführung des Datentyps "jsonb" gibt es jedoch keine besonderen Gründe für die Verwendung von "hstore".
- " intarray " erweitert die Funktionalität von Integer-Arrays. Die Indexunterstützung umfasst sowohl GiST als auch GIN (Operatorklasse "gin__int_ops").
Und diese beiden Erweiterungen wurden bereits oben erwähnt:
- " btree_gin " fügt GIN-Unterstützung für reguläre Datentypen hinzu, damit diese zusammen mit zusammengesetzten Typen in einem mehrspaltigen Index verwendet werden können.
- " jsquery " definiert eine Sprache für die JSON-Abfrage und eine Operatorklasse für die Indexunterstützung dieser Sprache. Diese Erweiterung ist in einer Standard-PostgreSQL-Lieferung nicht enthalten.
Lesen Sie weiter .