Wie kann man effektiv mit json in R arbeiten?
Es ist eine Fortsetzung früherer Veröffentlichungen .
Problemstellung
Die Hauptdatenquelle im JSON-Format ist in der Regel die REST-API. Die Verwendung von json ermöglicht neben der Plattformunabhängigkeit und der Bequemlichkeit der menschlichen Wahrnehmung von Daten den Austausch unstrukturierter Datensysteme mit einer komplexen Baumstruktur.
Bei der Erstellung einer API ist dies sehr praktisch. Es ist einfach, die Versionierung von Kommunikationsprotokollen sicherzustellen, und es ist einfach, die Flexibilität des Informationsaustauschs bereitzustellen. Gleichzeitig ist die Komplexität der Datenstruktur (Verschachtelungsebenen können 5, 6, 10 oder sogar mehr sein) nicht beängstigend, da das Schreiben eines flexiblen Parsers für einen einzelnen Datensatz, der alles und alles berücksichtigt, nicht so schwierig ist.
Zu den Datenverarbeitungsaufgaben gehört auch das Abrufen von Daten aus externen Quellen, einschließlich im json Format. R verfügt über eine Reihe guter Pakete, insbesondere jsonlite , mit denen json in R-Objekte konvertiert werden kann ( list oder data.frame , sofern die Datenstruktur dies zulässt).
In der Praxis treten jedoch häufig zwei Klassen von Problemen auf, wenn jsonlite und dergleichen äußerst ineffizient wird. Aufgaben sehen ungefähr so aus:
- Verarbeitung einer großen Datenmenge (Maßeinheit - Gigabyte), die während des Betriebs verschiedener Informationssysteme erhalten wird;
- Kombinieren einer großen Anzahl von Antworten mit variabler Struktur, die während eines Pakets parametrisierter REST-API-Anforderungen empfangen wurden, zu einer einheitlichen rechteckigen Darstellung (
data.frame ).
Ein Beispiel für eine ähnliche Struktur in den Abbildungen:
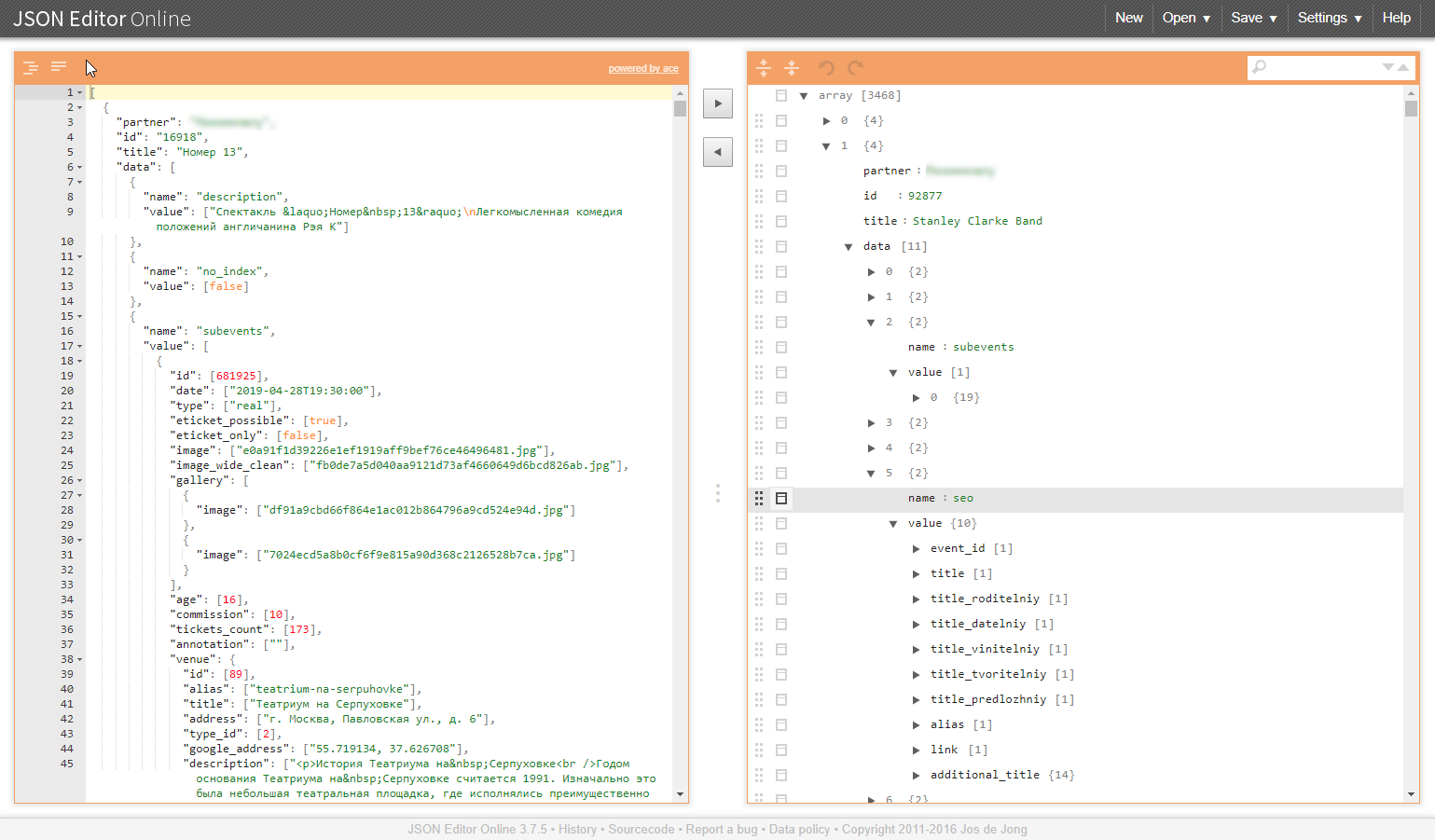
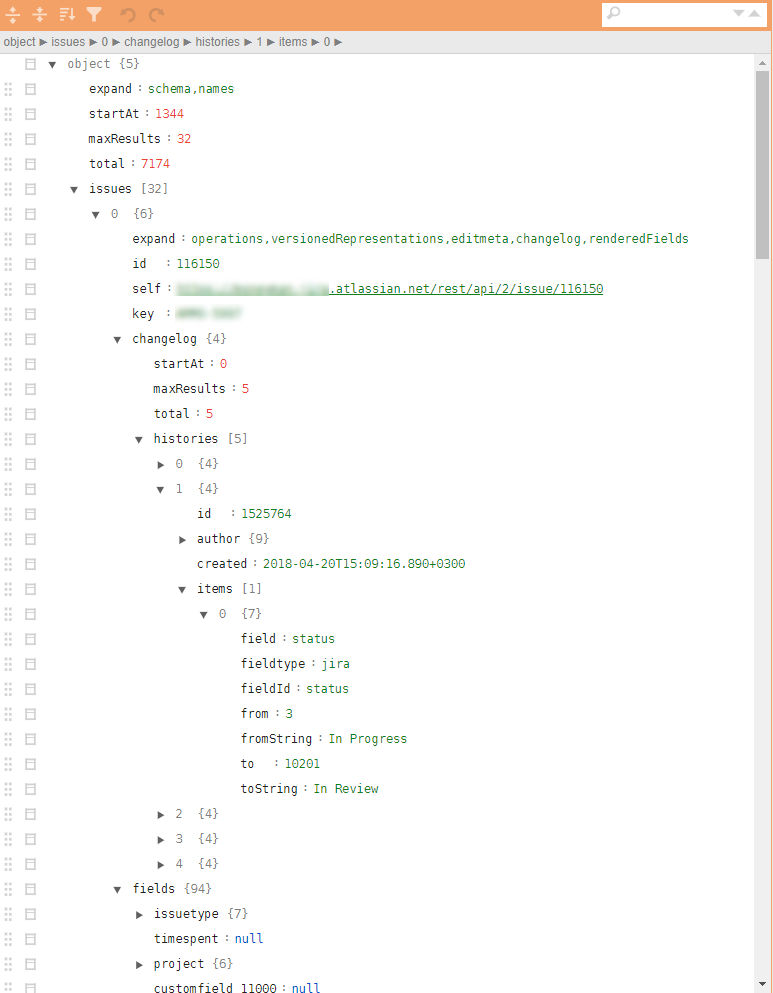
Warum sind diese Aufgabenklassen problematisch?
Große Datenmenge
Das Entladen aus Informationssystemen im JSON-Format ist in der Regel ein unteilbarer Datenblock. Um es richtig zu analysieren, müssen Sie alles lesen und das gesamte Volume durchgehen.
Induzierte Probleme:
- eine entsprechende Menge an RAM und Rechenressourcen wird benötigt;
- Die Analysegeschwindigkeit hängt stark von der Qualität der verwendeten Bibliotheken ab. Selbst wenn genügend Ressourcen vorhanden sind, kann die Konvertierungszeit zehn oder sogar Hunderte von Minuten betragen.
- Im Falle eines Analysefehlers wird am Ausgang kein Ergebnis erzielt, und es besteht kein Grund zu der Hoffnung, dass immer alles reibungslos verläuft.
- Es ist sehr erfolgreich, wenn die analysierten Daten in
data.frame konvertiert werden data.frame .
Baumstrukturen zusammenführen
Ähnliche Aufgaben ergeben sich beispielsweise, wenn die vom Geschäftsprozess für die Arbeit erforderlichen Verzeichnisse für die Arbeit eines Paketes von Anforderungen über die API erfasst werden müssen. Darüber hinaus implizieren Verzeichnisse eine Vereinheitlichung und Bereitschaft zum Einbetten in die Analysepipeline und zum potenziellen Hochladen in die Datenbank. Und dies macht es wiederum notwendig, solche zusammenfassenden Daten in data.frame .
Induzierte Probleme:
- Baumstrukturen selbst werden nicht zu flachen. JSON-Parser wandeln die Eingabedaten in eine Reihe verschachtelter Listen um, die dann manuell für eine lange Zeit und schmerzhaft bereitgestellt werden müssen.
- Die Freiheit in den Attributen der Ausgabedaten (fehlende werden möglicherweise nicht angezeigt) führt zum Auftreten von
NULL Objekten, die in den Listen relevant sind, aber nicht in den data.frame "passen" können. data.frame erschwert die Nachbearbeitung und erschwert sogar den grundlegenden Prozess des Zusammenführens einzelner data.frame data.frame ( rbindlist , bind_rows , 'map_dfr' oder rbind keine Rolle).
JQ - Ausweg
In besonders schwierigen Situationen führt die Verwendung sehr praktischer Ansätze des jsonlite Pakets "Alle in R-Objekte konvertieren" aus den oben genannten Gründen zu einer schwerwiegenden Fehlfunktion. Nun, wenn Sie es schaffen, das Ende der Verarbeitung zu erreichen. Schlimmer noch, wenn Sie in der Mitte Ihre Arme ausbreiten und aufgeben müssen.
Eine Alternative zu diesem Ansatz ist die Verwendung des JSON-Präprozessors, der direkt mit JSON-Daten arbeitet. jq Bibliothek und jqr Wrapper. Die Praxis zeigt, dass es nicht nur wenig verwendet wird, sondern nur wenige davon vergeblich gehört haben.
Vorteile der jq Bibliothek.
- Die Bibliothek kann in R, in Python und in der Befehlszeile verwendet werden.
- Alle Transformationen werden auf der JSON-Ebene ausgeführt, ohne sie in Darstellungen von R / Python-Objekten umzuwandeln.
- Die Verarbeitung kann in atomare Operationen unterteilt werden und das Prinzip der Ketten (Rohre) anwenden.
- Zyklen zur Verarbeitung von Objektvektoren sind im Parser verborgen, die Iterationssyntax wird maximal vereinfacht;
- die Fähigkeit, alle Verfahren zur Vereinheitlichung der JSON-Struktur, Bereitstellung und Auswahl der erforderlichen Elemente durchzuführen, um ein JSON-Format zu
data.frame mithilfe von jsonlite data.frame in data.frame jsonlite ; - mehrfache Reduzierung des R-Codes, der für die Verarbeitung von JSON-Daten verantwortlich ist;
- Bei enormer Verarbeitungsgeschwindigkeit kann die Verstärkung je nach Volumen und Komplexität der Datenstruktur 1-3 Größenordnungen betragen.
- viel weniger RAM-Anforderungen.
Der Verarbeitungscode wird auf den Bildschirm komprimiert und sieht möglicherweise folgendermaßen aus:
cont <- httr::content(r3, as = "text", encoding = "UTF-8") m <- cont %>% # jqr::jq('del(.[].movie.rating, .[].movie.genres, .[].movie.trailers)') %>% jqr::jq('del(.[].movie.countries, .[].movie.images)') %>% # jqr::jq('del(.[].schedules[].hall, .[].schedules[].language, .[].schedules[].subtitle)') %>% # jqr::jq('del(.[].cinema.location, .[].cinema.photo, .[].cinema.phones)') %>% jqr::jq('del(.[].cinema.goodies, .[].cinema.subway_stations)') # m2 <- m %>% jqr::jq('[.[] | {date, movie, schedule: .schedules[], cinema}]') df <- fromJSON(m2) %>% as_tibble()
jq ist sehr elegant und schnell! Für diejenigen, für die es relevant ist: herunterladen, einstellen, verstehen. Wir beschleunigen die Verarbeitung, wir vereinfachen das Leben für uns und unsere Kollegen.
Vorheriger Beitrag - „So starten Sie die Anwendung von R in Enterprise. Ein Beispiel für einen praktischen Ansatz . “