Einführung in Betriebssysteme
Hallo Habr! Ich möchte Sie auf eine Reihe von Artikelübersetzungen einer meiner Meinung nach interessanten Literatur aufmerksam machen - OSTEP. Dieser Artikel beschreibt ziemlich ausführlich die Arbeit von Unix-ähnlichen Betriebssystemen, nämlich die Arbeit mit Prozessen, verschiedenen Schedulern, Speicher und anderen ähnlichen Komponenten, aus denen das moderne Betriebssystem besteht. Das Original aller Materialien können Sie
hier sehen . Bitte beachten Sie, dass die Übersetzung unprofessionell (ziemlich frei) durchgeführt wurde, aber ich hoffe, dass ich die allgemeine Bedeutung beibehalten habe.
Laborarbeiten zu diesem Thema finden Sie hier:
Andere Teile:
Und du kannst meinen Kanal im
Telegramm ansehen =)
Einführung in den Scheduler
Das Wesentliche des Problems: Wie man eine Planerpolitik entwickelt
Wie sollten die grundlegenden Frameworks für Scheduler-Richtlinien entwickelt werden? Was sollten die wichtigsten Annahmen sein? Welche Metriken sind wichtig? Welche grundlegenden Techniken wurden im frühen Computing verwendet?Annahmen zur Arbeitsbelastung
Bevor wir mögliche Richtlinien diskutieren, werden wir zunächst einige vereinfachende Abweichungen von den im System ausgeführten Prozessen vornehmen, die zusammen als
Workload bezeichnet werden . Indem Sie eine Arbeitslast als wichtigen Bestandteil der Erstellung von Richtlinien definieren und je mehr Sie über die Arbeitslast wissen, desto besser können Sie Richtlinien schreiben.
Wir machen die folgenden Annahmen über die im System laufenden Prozesse, manchmal auch
Jobs (Tasks) genannt. Fast alle diese Annahmen sind nicht realistisch, aber für die Entwicklung des Denkens notwendig.
- Jede Aufgabe läuft gleich lange.
- Alle Aufgaben werden gleichzeitig eingestellt,
- Die Aufgabe bis zu ihrem Abschluss,
- Alle Aufgaben verwenden nur die CPU,
- Die Laufzeit jeder Aufgabe ist bekannt.
Scheduler-Metriken
Zusätzlich zu einigen Annahmen zur Auslastung benötigen Sie ein weiteres Tool zum Vergleichen verschiedener Planungsrichtlinien: die Scheduler-Metriken. Eine Metrik ist nur ein Maß für etwas. Es gibt eine Reihe von Metriken, mit denen Planer verglichen werden können.
Zum Beispiel werden wir eine Metrik verwenden, die als Bearbeitungszeit bezeichnet wird. Die Bearbeitungszeit einer Aufgabe ist definiert als die Differenz zwischen der Zeit, die zum Ausführen der Aufgabe benötigt wird, und der Zeit, zu der die Aufgabe in das System eingeht.
Tturnaround = Tcompletion - TarrivalDa wir davon ausgegangen sind, dass alle Aufgaben gleichzeitig angekommen sind, ist Ta = 0 und damit Tt = Tc. Dieser Wert wird sich natürlich ändern, wenn wir die obigen Annahmen ändern.
Eine andere Metrik ist
Fairness (Fairness, Ehrlichkeit). Produktivität und Ehrlichkeit sind oft gegensätzliche Merkmale in der Planung. Beispielsweise kann ein Scheduler die Leistung optimieren, jedoch auf Kosten des Wartens auf die Ausführung anderer Aufgaben, wodurch die Integrität verringert wird.
FIRST IN FIRST OUT (FIFO)
Der grundlegendste Algorithmus, den wir implementieren können, heißt FIFO oder
First Come (In), First Served (Out) . Dieser Algorithmus hat mehrere Vorteile: Er ist sehr einfach zu implementieren und entspricht all unseren Annahmen. Er erledigt die Aufgabe ziemlich gut.
Betrachten Sie ein einfaches Beispiel. Angenommen, 3 Aufgaben wurden gleichzeitig festgelegt. Angenommen, Aufgabe A kam etwas früher als alle anderen, sodass sie früher als die anderen auf der Ausführungsliste steht, genau wie B in Bezug auf C. Angenommen, jeder von ihnen dauert 10 Sekunden. Was ist die durchschnittliche Zeit, um diese Aufgaben zu erledigen?
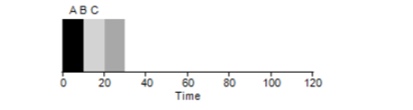
Wenn wir die Werte 10 + 20 + 30 zählen und durch 3 teilen, erhalten wir eine durchschnittliche Ausführungszeit des Programms von 20 Sekunden.
Versuchen wir nun, unsere Annahmen zu ändern. Insbesondere Annahme 1, und daher gehen wir nicht mehr davon aus, dass jede Aufgabe dieselbe Zeit benötigt. Wie wird sich das FIFO diesmal zeigen?
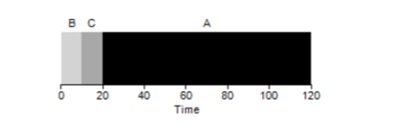
Wie sich herausstellt, wirken sich unterschiedliche Ausführungszeiten von Aufgaben äußerst negativ auf die Produktivität des FIFO-Algorithmus aus. Angenommen, Aufgabe A wird 100 Sekunden lang ausgeführt, während B und C jeweils noch 10 sind.

Wie aus der Abbildung ersichtlich ist, beträgt die durchschnittliche Zeit für das System (100 + 110 + 120) / 3 = 110. Dieser Effekt wird als
Konvoieffekt bezeichnet , wenn einige kurzfristige Verbraucher einer Ressource nach einem starken Verbraucher in einer Linie stehen. Es sieht aus wie ein Lebensmittelgeschäft, wenn ein Kunde mit einem vollen Wagen vor Ihnen steht. Die beste Lösung für das Problem ist, zu versuchen, die Kassiererin zu wechseln oder sich zu entspannen und tief zu atmen.
Kürzester Job zuerst
Ist es möglich, eine ähnliche Situation mit schweren Prozessen zu lösen? Natürlich. Eine andere Art der Planung wird als
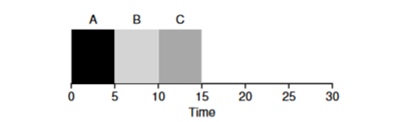
Shortest Job First (SJF) bezeichnet. Sein Algorithmus ist auch ziemlich primitiv - wie der Name schon sagt, werden die kürzesten Aufgaben zuerst nacheinander gestartet.
In diesem Beispiel führt das Starten derselben Prozesse zu einer Verbesserung der durchschnittlichen Durchlaufzeit der Programme und zu
50 statt 110 , was fast zweimal besser ist.
Unter der gegebenen Annahme, dass alle Aufgaben zur gleichen Zeit eintreffen, scheint der SJF-Algorithmus der optimalste Algorithmus zu sein. Unsere Annahmen erscheinen jedoch immer noch nicht realistisch. Dieses Mal ändern wir die Annahme 2 und stellen uns diesmal vor, dass Aufgaben jederzeit und nicht alle gleichzeitig ausgeführt werden können. Zu welchen Problemen kann dies führen?

Stellen Sie sich vor, dass Aufgabe A (100s) zuerst eintrifft und ausgeführt wird. Zum Zeitpunkt t = 10 treffen die Aufgaben B, C ein, von denen jede 10 Sekunden dauert. Die durchschnittliche Ausführungszeit beträgt also (100+ (110-10) + (120-10)) \ 3 = 103. Was könnte der Planer tun, um die Situation zu verbessern?
Kürzeste Zeit bis zur Fertigstellung zuerst (STCF)
Um die Situation zu verbessern, lassen wir die Annahme 3 weg, dass das Programm bis zum Abschluss läuft. Darüber hinaus benötigen wir Hardware-Unterstützung, und wie Sie vielleicht vermutet haben, verwenden wir einen
Timer, um eine Arbeitsaufgabe zu unterbrechen und den
Kontext zu wechseln . Somit kann der Scheduler zum Zeitpunkt des Eintreffens der Tasks B und C etwas tun - die Ausführung von Task A stoppen und die Tasks B und C in die Verarbeitung einbeziehen und nach Abschluss den Prozess A fortsetzen. Dieser Scheduler wird als
STCF oder
Preemptive Job First bezeichnet .
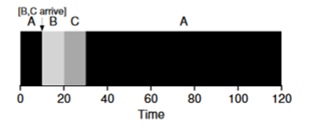
Das Ergebnis dieses Schedulers ist das folgende: ((120-0) + (20-10) + (30-10)) / 3 = 50. Somit wird ein solcher Scheduler für unsere Aufgaben noch optimaler.
Metrische Antwortzeit
Wenn wir also die Laufzeit der Aufgaben kennen und wissen, dass diese Aufgaben nur die CPU verwenden, ist STCF die beste Lösung. Und einmal in den frühen Tagen funktionierten diese Algorithmen und ziemlich gut. Jetzt verbringt der Benutzer jedoch die meiste Zeit am Terminal und erwartet von ihm eine produktive interaktive Interaktion. So wurde eine neue Metrik geboren -
Antwortzeit (Antwort).
Die Reaktionszeit wird wie folgt berechnet:
Tresponse = Tfirstrun - TarrivalFür das vorherige Beispiel ist die Antwortzeit also wie folgt: A = 0, B = 0, B = 10 (abg = 3,33).
Und es stellt sich heraus, dass der STCF-Algorithmus in einer Situation, in der 3 Aufgaben gleichzeitig eintreffen, nicht so gut ist - er muss warten, bis die kleinen Aufgaben vollständig abgeschlossen sind. Somit ist der Algorithmus gut für die Durchlaufzeitmetrik, aber schlecht für die Interaktivitätsmetrik. Stellen Sie sich vor, Sie müssten am Terminal sitzen und versuchen, Zeichen in den Editor einzugeben. Sie müssten mehr als 10 Sekunden warten, da eine andere Aufgabe vom Prozessor belegt wird. Das ist nicht sehr angenehm.
Wir stehen also vor einem anderen Problem: Wie können wir einen Scheduler erstellen, der empfindlich auf die Antwortzeit reagiert?
Round Robin
Um dieses Problem zu lösen, wurde der
Round Robin (RR) -Algorithmus entwickelt. Die Grundidee ist ganz einfach: Anstatt Aufgaben bis zum Abschluss zu starten, starten wir die Aufgabe für einen bestimmten Zeitraum (als Zeitquant bezeichnet) und wechseln dann aus der Warteschlange zu einer anderen Aufgabe. Der Algorithmus wiederholt seine Arbeit, bis alle Aufgaben abgeschlossen sind. In diesem Fall muss die Programmlaufzeit ein Vielfaches der Zeit sein, nach der der Timer den Prozess unterbricht. Wenn der Timer beispielsweise den Prozess alle x = 10 ms unterbricht, sollte die Größe des Prozessausführungsfensters ein Vielfaches von 10 und 10,20 oder x * 10 sein.
Schauen wir uns ein Beispiel an: Aufgaben von ABV kommen gleichzeitig im System an und jeder von ihnen möchte 5 Sekunden lang arbeiten. Der SJF-Algorithmus führt jede Aufgabe bis zum Ende aus, bevor eine andere gestartet wird. Im Gegensatz dazu durchläuft der RR-Algorithmus mit dem Startfenster = 1s die Aufgaben wie folgt (Abb. 4.3):
(SJF erneut (schlecht für die Reaktionszeit)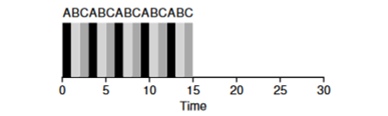 (Round Robin (gut für die Reaktionszeit)
(Round Robin (gut für die Reaktionszeit)Die durchschnittliche Antwortzeit für den Algorithmus beträgt RR (0 + 1 + 2) / 3 = 1, während für SJF (0 + 5 + 10) / 3 = 5.
Es ist logisch anzunehmen, dass das Zeitfenster ein sehr wichtiger Parameter für RR ist. Je kleiner es ist, desto höher ist die Antwortzeit. Sie können es jedoch nicht zu klein machen, da die Zeit zum Wechseln des Kontexts auch eine Rolle für die Gesamtleistung spielt. Daher wird der Zeitpunkt des Ausführungsfensters vom Betriebssystemarchitekten festgelegt und hängt von den Aufgaben ab, deren Ausführung darin geplant ist. Das Wechseln des Kontexts ist nicht der einzige Dienstvorgang, der Zeit in Anspruch nimmt. Das laufende Programm arbeitet mit viel mehr, z. B. verschiedenen Caches, und jedes Mal muss diese Umgebung gespeichert und wiederhergestellt werden, was ebenfalls viel Zeit in Anspruch nehmen kann.
RR ist ein großartiger Planer, wenn es nur eine Antwortzeitmetrik war. Aber wie verhält sich die Metrik der Bearbeitungszeit der Aufgabe mit diesem Algorithmus? Betrachten Sie das obige Beispiel, wenn die Betriebszeit A, B, C = 5s ist und zur gleichen Zeit ankommt. Aufgabe A endet um 13 Uhr, B um 14 Uhr, C um 15 Uhr und die durchschnittliche Bearbeitungszeit beträgt 14 Sekunden. Somit ist RR der schlechteste Algorithmus für Umsatzmetriken.
Im Allgemeinen ist jeder Algorithmus wie RR ehrlich und teilt die für die CPU aufgewendete Zeit gleichmäßig auf alle Prozesse auf. Und so stehen diese Metriken ständig in Konflikt miteinander.
Wir haben also mehrere entgegengesetzte Algorithmen und gleichzeitig bleiben einige Annahmen bestehen - dass die Taskzeit bekannt ist und dass die Task nur die CPU verwendet.
Mischen mit E / A.
Zunächst entfernen wir die Annahme 4, dass der Prozess nur die CPU verwendet, dies ist natürlich nicht der Fall, und die Prozesse können sich an andere Geräte wenden.
Sobald ein Prozess eine E / A-Operation anfordert, wird der Prozess blockiert und wartet auf den Abschluss der E / A. Wenn E / A an die Festplatte gesendet wird, kann ein solcher Vorgang bis zu mehreren ms oder länger dauern, und der Prozessor ist in diesem Moment inaktiv. Zu diesem Zeitpunkt kann der Scheduler den Prozessor durch einen anderen Prozess übernehmen. Die nächste Entscheidung, die der Scheduler treffen muss, ist, wenn der Prozess seine E / A abgeschlossen hat. In diesem Fall tritt ein Interrupt auf und das Betriebssystem versetzt den E / A-Aufrufprozess in den Bereitschaftszustand.
Betrachten Sie ein Beispiel für mehrere Aufgaben. Jeder von ihnen benötigt 50 ms Prozessorzeit. Der erste greift jedoch alle 10 ms auf E / A zu (was auch für 10 ms ausgeführt wird). Und Prozess B verwendet einfach einen 50-ms-Prozessor ohne E / A.
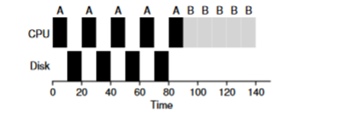
In diesem Beispiel verwenden wir den STCF-Scheduler. Wie verhält sich der Scheduler, wenn Sie einen Prozess wie A darauf ausführen? Er wird wie folgt vorgehen - zuerst A vollständig verarbeiten und dann B verarbeiten.

Der traditionelle Ansatz zur Lösung dieses Problems besteht darin, jede 10-ms-Unteraufgabe von Prozess A als separate Aufgabe zu interpretieren. Wenn mit dem STJF-Algorithmus begonnen wird, ist die Wahl zwischen einer 50-ms-Aufgabe und einer 10-ms-Aufgabe offensichtlich. Wenn die Unteraufgabe A abgeschlossen ist, werden Prozess B und E / A gestartet. Nach Abschluss der E / A ist es üblich, den 10-ms-Prozess A anstelle von Prozess B erneut zu starten. Somit ist es möglich, eine Überlappung zu realisieren, wenn die CPU von einem anderen Prozess verwendet wird, während der erste auf E / A wartet. Dadurch wird das System besser genutzt - in dem Moment, in dem interaktive Prozesse auf E / A warten, können andere Prozesse auf dem Prozessor ausgeführt werden.
Oracle ist nicht mehr
Versuchen wir nun, die Annahme loszuwerden, dass der Zeitpunkt der Aufgabe bekannt ist. Dies ist im Allgemeinen die schlechteste und unrealistischste Annahme aus der gesamten Liste. In durchschnittlichen Standardbetriebssystemen weiß das Betriebssystem selbst normalerweise nur sehr wenig über die Zeit, die zum Ausführen von Aufgaben benötigt wird. Wie können Sie also einen Scheduler erstellen, ohne zu wissen, wie lange die Aufgabe dauern wird? Vielleicht könnten wir einige der Prinzipien von RR verwenden, um dieses Problem zu lösen?
Zusammenfassung
Wir haben die Grundideen der Aufgabenplanung untersucht und 2 Planerfamilien überprüft. Die erste startet die kürzeste Aufgabe am Anfang und erhöht somit die Bearbeitungszeit, die zweite wird zwischen allen Aufgaben gleichermaßen hin- und hergerissen, wodurch sich die Reaktionszeit erhöht. Beide Algorithmen sind schlecht, während andere Familienalgorithmen gut sind. Wir haben auch untersucht, wie die parallele Verwendung von CPU und E / A die Leistung verbessern kann, haben jedoch das Problem mit der Hellsichtigkeit des Betriebssystems nicht gelöst. Und in der nächsten Lektion werden wir einen Planer betrachten, der in die nahe Vergangenheit schaut und versucht, die Zukunft vorherzusagen. Und es wird als mehrstufige Feedback-Warteschlange bezeichnet.