Wenn Sie die Zeitreihendatenbank (timeseries db,
wiki ) als Haupt-Repository für eine Site mit Statistiken verwenden, können Sie anstelle der Lösung des Problems große Kopfschmerzen bekommen. Ich arbeite an einem Projekt, bei dem eine solche Basis verwendet wird, und manchmal brachte InfluxDB, über das diskutiert wird, unerwartete Überraschungen.
Haftungsausschluss : Diese Probleme betreffen InfluxDB 1.7.4.
Warum Zeitreihen?
Das Projekt besteht darin, Transaktionen in verschiedenen Blockchains zu verfolgen und Statistiken anzuzeigen. Insbesondere betrachten wir die Emission und das Verbrennen von stabilen Münzen (
Wiki ). Basierend auf diesen Transaktionen müssen Sie Diagramme erstellen und Pivot-Tabellen anzeigen.
Bei der Analyse von Transaktionen kam die Idee auf, die InfluxDB-Zeitreihendatenbank als Hauptspeicher zu verwenden. Transaktionen sind Zeitpunkte und passen gut in das Zeitreihenmodell.
Außerdem sahen die Aggregationsfunktionen sehr praktisch aus - sie sind ideal für die Verarbeitung von Diagrammen mit einem langen Zeitraum. Der Benutzer benötigt ein Diagramm für das Jahr, und die Datenbank enthält einen Datensatz mit einem Zeitrahmen von fünf Minuten. Es ist sinnlos, ihm hunderttausend Punkte zu senden - außer bei langer Verarbeitung passen sie nicht auf den Bildschirm. Sie können Ihre eigene Implementierung zum Erhöhen des Zeitrahmens schreiben oder die in Influx integrierten Aggregationsfunktionen verwenden. Mit ihrer Hilfe können Sie Daten nach Tag gruppieren und die gewünschten 365 Punkte senden.
Es war ein wenig peinlich, dass solche Datenbanken normalerweise zum Sammeln von Metriken verwendet werden. Überwachen von Servern, iot-Geräten, von denen alle Millionen Punkte der Form "pour": [<Zeit> - <Metrikwert>]. Aber wenn die Datenbank mit einem großen Datenfluss gut funktioniert, warum sollte dann eine kleine Menge Probleme verursachen? In diesem Sinne haben sie InfluxDB zur Arbeit gebracht.
Was ist sonst noch bequem in InfluxDB
Neben den genannten Aggregationsfunktionen gibt es noch eine weitere großartige Sache -
kontinuierliche Abfragen (
doc ). Dies ist ein in die Datenbank integrierter Scheduler, der Daten nach einem Zeitplan verarbeiten kann. Sie können beispielsweise alle Datensätze für einen Tag alle 24 Stunden gruppieren, den Durchschnitt berechnen und einen neuen Punkt in eine andere Tabelle schreiben, ohne Ihre eigenen Fahrräder zu schreiben.
Es gibt auch
Aufbewahrungsrichtlinien (
doc ), mit denen das Löschen von Daten nach einem bestimmten Zeitraum eingerichtet wird. Dies ist nützlich, wenn Sie beispielsweise die Last auf der CPU eine Woche lang mit Messungen einmal pro Sekunde speichern müssen, diese Genauigkeit jedoch in einem Abstand von einigen Monaten nicht erforderlich ist. In dieser Situation können Sie Folgendes tun:
- Erstellen Sie eine fortlaufende Abfrage, um Daten in einer anderen Tabelle zusammenzufassen.
- Definieren Sie für die erste Tabelle eine Richtlinie zum Löschen von Metriken, die älter als diese Woche sind.
Und Influx reduziert unabhängig die Größe der Daten und löscht unnötige Daten.
Informationen zu gespeicherten Daten
Es werden nicht viele Daten gespeichert: etwa 70.000 Transaktionen und eine weitere Million Punkte mit Marktinformationen. Hinzufügen neuer Einträge - nicht mehr als 3000 Punkte pro Tag. Es gibt auch Metriken auf der Website, aber es gibt dort nur wenige Daten, und gemäß den Aufbewahrungsrichtlinien werden sie nicht länger als einen Monat gespeichert.
Die Probleme
Während der Entwicklung und des anschließenden Testens des Dienstes traten während des Betriebs von InfluxDB immer kritischere Probleme auf.
1. Löschen von Daten
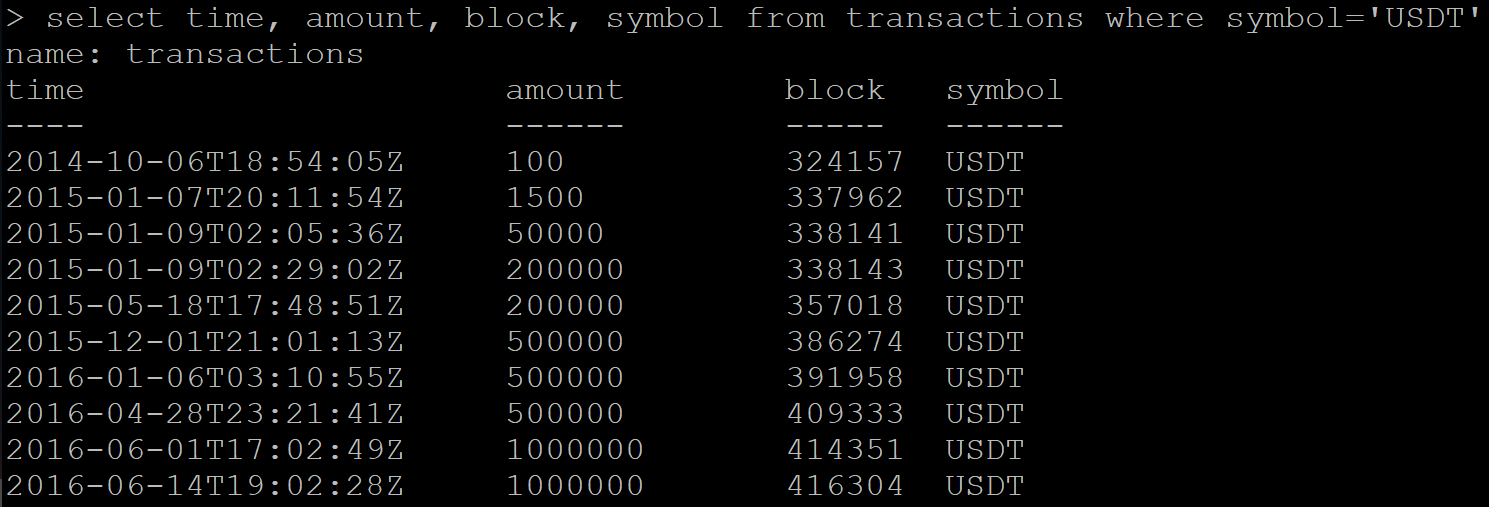
Es gibt eine Reihe von Daten mit Transaktionen:
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'
Ergebnis:
Ich sende einen Befehl zum Löschen von Daten:
DELETE FROM transactions WHERE symbol='USDT'
Als nächstes fordere ich an, bereits gelöschte Daten zu erhalten. Und Influx gibt anstelle einer leeren Antwort einen Teil der Daten zurück, die gelöscht werden sollen.
Ich versuche die ganze Tabelle zu löschen:
DROP MEASUREMENT transactions
Ich überprüfe das Löschen der Tabelle:
SHOW MEASUREMENTS
Ich sehe mir die Tabelle in der Liste nicht an, aber eine neue Datenanforderung gibt immer noch die gleichen Transaktionen zurück.
Das Problem ist mir nur einmal aufgetreten, da der Löschfall ein Einzelfall ist. Dieses Verhalten der Datenbank passt jedoch eindeutig nicht in den Rahmen "korrekter" Arbeit. Später fand ich vor fast einem Jahr ein offenes
Ticket zu diesem Thema.
Infolgedessen half das Entfernen und anschließende Wiederherstellen der gesamten Datenbank.
2. Gleitkommazahlen
Mathematische Berechnungen mit den in InfluxDB integrierten Funktionen ergeben Genauigkeitsfehler. Nicht dass es etwas Ungewöhnliches gewesen wäre, aber unangenehm.
In meinem Fall haben die Daten eine finanzielle Komponente und ich möchte sie mit hoher Genauigkeit verarbeiten. Aus diesem Grund ist geplant, fortlaufende Abfragen aufzugeben.
3. Kontinuierliche Abfragen können nicht an verschiedene Zeitzonen angepasst werden
Der Dienst verfügt über eine Tabelle mit täglichen Statistiken zu Transaktionen. Für jeden Tag müssen Sie alle Transaktionen für diesen Tag gruppieren. Der Tag für jeden Benutzer beginnt jedoch zu einer anderen Zeit, daher ist die Anzahl der Transaktionen unterschiedlich. UTC verfügt über
37 Verschiebungsoptionen
, für die Sie Daten aggregieren müssen.
Bei der Gruppierung nach Zeit in InfluxDB können Sie zusätzlich eine Verschiebung angeben, z. B. für die Moskauer Zeit (UTC + 3):
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)
Das Abfrageergebnis ist jedoch falsch. Aus irgendeinem Grund beginnen die nach Tag gruppierten Daten bereits 1677 (InfluxDB unterstützt offiziell den Zeitraum ab diesem Jahr):
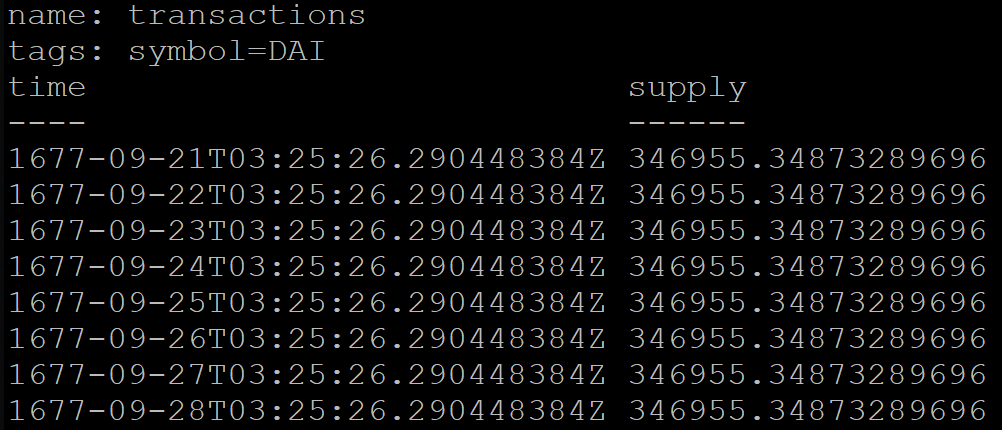
Um dieses Problem zu umgehen, wurde der Dienst vorübergehend auf UTC + 0 übertragen.
4. Leistung
Im Internet gibt es viele Benchmarks mit Vergleichen von InfluxDB und anderen Datenbanken. Bei der ersten Bekanntschaft sahen sie aus wie Marketingmaterialien, aber jetzt denke ich, dass sie etwas Wahres enthalten.
Ich werde Ihnen meinen Fall erzählen.
Der Dienst bietet eine API-Methode, die Statistiken für den letzten Tag zurückgibt. Während der Berechnungen fragt die Methode die Datenbank dreimal mit den folgenden Abfragen ab:
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1
SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1
SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESC
Erklärung
- In der ersten Abfrage erhalten wir die letzten Punkte für jede Münze mit Marktdaten. Acht Punkte für acht Münzen in meinem Fall.
- Die zweite Anfrage erhält einen der neuesten Punkte.
- Der dritte fordert eine Liste von Transaktionen für den letzten Tag an, es können mehrere hundert sein.
Ich werde klarstellen, dass in InfluxDB ein Index automatisch nach Tags und nach Zeit erstellt wird, wodurch Abfragen beschleunigt werden. In der ersten Abfrage ist das
Symbol das Tag.
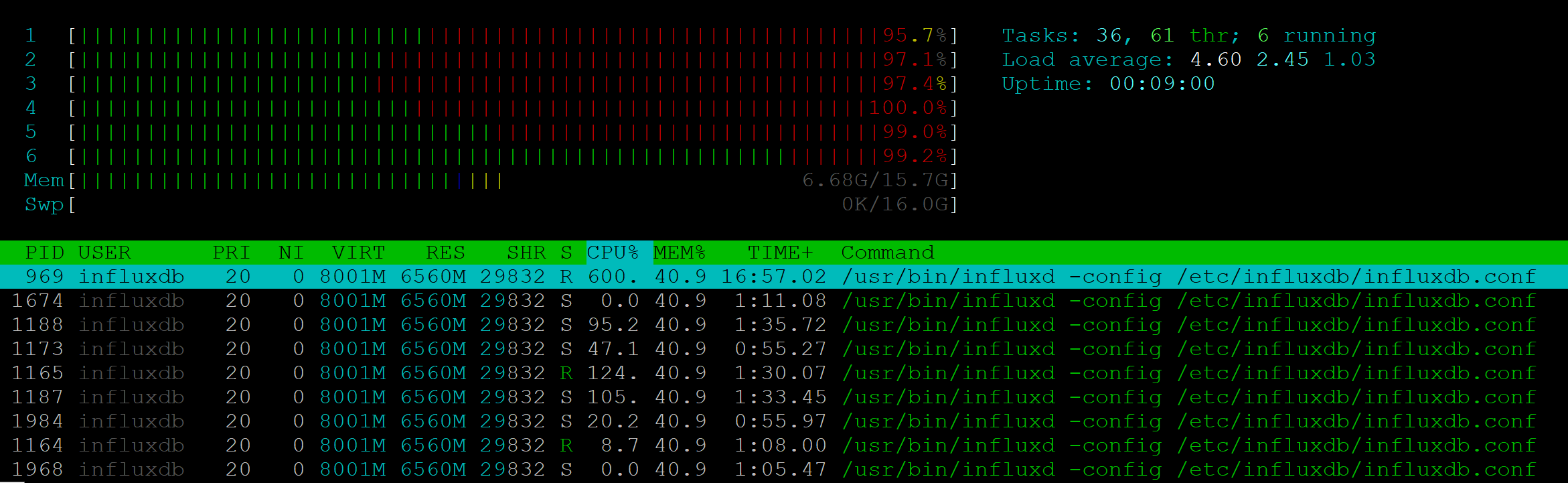
Ich habe einen Stresstest für diese API-Methode durchgeführt. Bei 25 RPS zeigte der Server eine volle Auslastung von sechs CPUs:
Gleichzeitig hat der NodeJs-Prozess überhaupt keine Last gegeben.
Die Ausführungsgeschwindigkeit hat sich bereits um 7-10 RPS verschlechtert: Wenn ein Client in 200 ms eine Antwort erhalten könnte, sollten 10 Clients eine Sekunde warten. 25 RPS - die Grenze, an der die Stabilität litt, 500 Fehler wurden an die Kunden zurückgegeben.
Mit einer solchen Leistung ist es unmöglich, Influx in unserem Projekt zu verwenden. Darüber hinaus: In einem Projekt, in dem Sie vielen Clients die Überwachung demonstrieren müssen, können ähnliche Probleme auftreten und der Metrikserver wird überlastet.
Fazit
Die wichtigste Schlussfolgerung aus den gewonnenen Erfahrungen ist, dass Sie eine unbekannte Technologie ohne ausreichende Analyse nicht in das Projekt einbeziehen können. Eine einfache Überprüfung offener Tickets auf Github könnte Informationen liefern, um InfluxDB nicht als Hauptdatenlager zu verwenden.
InfluxDB hätte gut zu den Aufgaben meines Projekts passen sollen, aber wie die Praxis gezeigt hat, erfüllt diese Datenbank nicht die Anforderungen und bringt viel durcheinander.
Sie finden Version 2.0.0-beta bereits im Projekt-Repository. Es ist zu hoffen, dass es in der zweiten Version signifikante Verbesserungen geben wird. In der Zwischenzeit werde ich die TimescaleDB-Dokumentation studieren.