
Am 8. April wurde auf der
Saint HighLoad ++ 2019- Konferenz im Rahmen des Abschnitts DevOps and Operations ein Bericht mit dem Titel „Erweitern und Ergänzen von Kubernetes“ erstellt, der von drei Mitarbeitern von Flant erstellt wurde. Darin sprechen wir über zahlreiche Situationen, in denen wir die Fähigkeiten von Kubernetes erweitern und ergänzen wollten, für die wir jedoch keine fertige und einfache Lösung gefunden haben. Die notwendigen Lösungen wurden in Form von Open Source-Projekten veröffentlicht, und diese Präsentation ist auch diesen gewidmet.
Aus Tradition freuen wir uns, ein
Video mit einem Bericht (50 Minuten, viel informativer als der Artikel) und dem Hauptdruck in Textform zu präsentieren. Lass uns gehen!
K8s Kernel und Add-Ons
Kubernetes verändert einen seit langem etablierten Branchen- und Verwaltungsansatz:
- Dank seiner Abstraktionen arbeiten wir nicht mehr mit Konzepten wie dem Konfigurieren einer Konfiguration oder dem Ausführen eines Befehls (Chef, Ansible ...), sondern verwenden die Gruppierung von Containern, Diensten usw.
- Wir können Anwendungen vorbereiten, ohne über die Nuancen der spezifischen Plattform nachzudenken, auf der sie gestartet werden sollen: Bare Metal, die Cloud eines der Anbieter usw.
- Mit K8s sind die Best Practices für die Organisation der Infrastruktur zugänglicher denn je: Skalierung, Selbstheilung, Fehlertoleranz usw.
Natürlich ist nicht alles so reibungslos: Mit Kubernetes kamen ihre eigenen - neuen - Herausforderungen.
Kubernetes ist
kein Mähdrescher, der alle Probleme aller Benutzer löst.
Der Kubernetes-
Kern ist nur für den Satz der minimal erforderlichen Funktionen verantwortlich, die in
jedem Cluster vorhanden sind:
Im Kern von Kubernetes wird ein grundlegender Satz von Grundelementen definiert - zum Gruppieren von Containern, Verwalten des Datenverkehrs usw. Wir haben
vor 2 Jahren in einem
Bericht ausführlicher darüber gesprochen.
Auf der anderen Seite bietet K8s großartige Möglichkeiten, die verfügbaren Funktionen zu erweitern, um andere -
spezifische - Benutzeranforderungen zu erfüllen. Clusteradministratoren sind für die Ergänzungen zu Kubernetes verantwortlich, die alles Notwendige installieren und konfigurieren müssen, damit ihr Cluster "die richtige Form findet" [um ihre spezifischen Probleme zu lösen]. Was für Ergänzungen sind das? Schauen wir uns einige Beispiele an.
Beispiele für Ergänzungen
Nach der Installation von Kubernetes können wir überrascht sein, dass das Netzwerk, das für die Interaktion von Pods sowohl innerhalb des Knotens als auch zwischen Knoten erforderlich ist, nicht von selbst funktioniert. Der Kubernetes-Kern garantiert nicht die erforderlichen Verbindungen, sondern definiert eine Netzwerkschnittstelle (
CNI ) für Add-Ons von Drittanbietern. Wir müssen eine dieser Ergänzungen installieren, die für die Netzwerkkonfiguration verantwortlich ist.

Ein nahes Beispiel sind Datenspeicherlösungen (lokale Festplatte, Netzwerkblockgerät, Ceph ...). Anfangs befanden sie sich im Kernel, aber mit dem Aufkommen von
CSI ändert sich
die Situation zu einer ähnlichen, die bereits beschrieben wurde: In Kubernetes die Schnittstelle und ihre Implementierung in Modulen von Drittanbietern.
Unter anderen Beispielen:
- Ingress Controller (eine Übersicht finden Sie in unserem aktuellen Artikel ) .
- Zertifikatsmanager :

- Operatoren sind eine ganze Klasse von Add-Ons (einschließlich des genannten Zertifizierungsmanagers). Sie definieren die Grundelemente und Controller. Die Logik ihrer Arbeit ist nur durch unsere Vorstellungskraft begrenzt und ermöglicht es uns, vorgefertigte Infrastrukturkomponenten (z. B. DBMS) in Grundelemente umzuwandeln, mit denen viel einfacher zu arbeiten ist (als mit einer Reihe von Containern und ihren Einstellungen). Eine große Anzahl von Betreibern wurde geschrieben - obwohl viele von ihnen noch nicht für die Produktion bereit sind, ist dies nur eine Frage der Zeit:
- Metrics ist ein weiteres Beispiel dafür, wie Kubernetes die Schnittstelle (Metrics API) von ihrer Implementierung getrennt hat (Add-Ons von Drittanbietern wie Prometheus-Adapter, Datadog-Cluster-Agent ...).
- Für Überwachung und Statistik , wo in der Praxis nicht nur Prometheus und Grafana benötigt werden , sondern auch Kube-State-Metriken, Node-Exporter usw.
Und dies ist keine vollständige Liste der Add-Ons ... Beispielsweise installieren wir bei Flant heute
29 Add-Ons für jeden Kubernetes-Cluster (alle erstellen insgesamt 249 Kubernetes-Objekte). Einfach ausgedrückt, wir sehen das Leben eines Clusters nicht ohne Ergänzungen.
Automatisierung
Die Bediener sind darauf ausgelegt, Routinevorgänge zu automatisieren, mit denen wir täglich konfrontiert sind. Hier sind Lebensbeispiele, die sich hervorragend zum Schreiben eines Operators eignen:
- Es gibt eine private (d. H. Anmeldungspflichtige) Registrierung mit Bildern für die Anwendung. Es wird davon ausgegangen, dass jeder Pod an ein spezielles Geheimnis gebunden ist, das die Authentifizierung in der Registrierung ermöglicht. Unsere Aufgabe ist es, sicherzustellen, dass dieses Geheimnis im Namespace gefunden wird, damit Pods Bilder herunterladen können. Es kann viele Anwendungen geben (von denen jede ein Geheimnis benötigt), und es ist nützlich, die Geheimnisse regelmäßig selbst zu aktualisieren, damit die Option, die Geheimnisse mit Ihren Händen aufzudecken, verschwindet. Hier kommt der Operator zur Rettung: Wir erstellen einen Controller, der darauf wartet, dass der Namespace angezeigt wird, und dem Namespace für dieses Ereignis ein Geheimnis hinzufügt.
- Angenommen, der Zugriff von den Pods auf das Internet ist standardmäßig verboten. Manchmal kann es jedoch erforderlich sein: Es ist logisch, dass der Zugriffsberechtigungsmechanismus einfach funktioniert, ohne dass bestimmte Fähigkeiten erforderlich sind, z. B. durch das Vorhandensein eines bestimmten Labels im Namespace. Wie hilft uns der Betreiber hier? Es wird ein Controller erstellt, der erwartet, dass die Bezeichnung im Namespace angezeigt wird, und die entsprechende Richtlinie für den Zugriff auf das Internet hinzufügt.
- Eine ähnliche Situation: Lassen Sie uns dem Knoten einen bestimmten Makel hinzufügen, wenn er eine ähnliche Bezeichnung hat (mit einer Art Präfix). Aktionen mit dem Bediener sind offensichtlich ...
In jedem Cluster ist es notwendig, Routineaufgaben zu lösen und dies
korrekt zu tun - mithilfe von Operatoren.
Zusammenfassend kamen wir zu dem Schluss, dass
für eine komfortable Arbeit in Kubernetes Folgendes erforderlich ist : a)
Installation von Add-Ons , b)
Entwicklung von Operatoren (zur Lösung alltäglicher Verwaltungsaufgaben).
Wie schreibe ich eine Erklärung für Kubernetes?
Im Allgemeinen ist das Schema einfach:
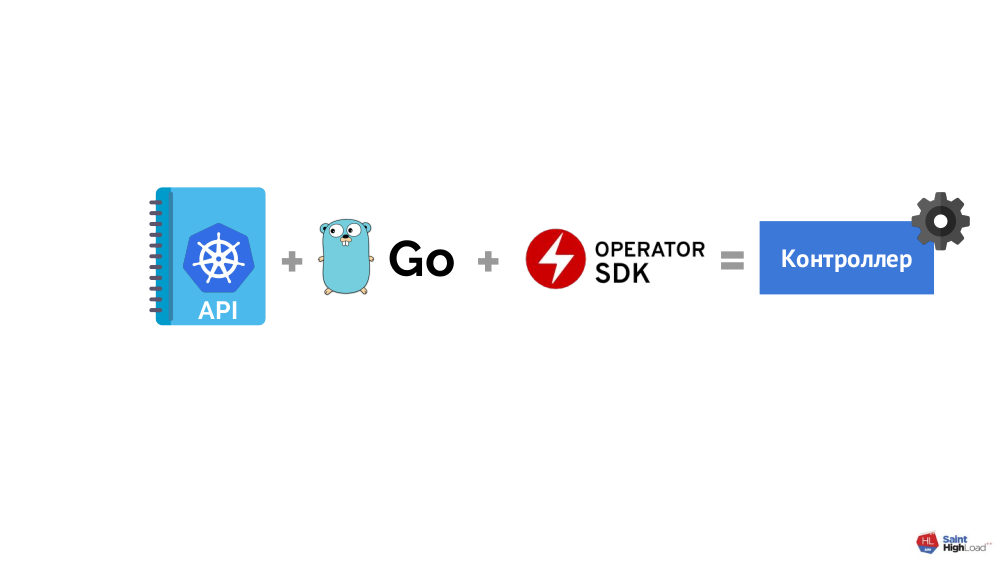
... aber es stellt sich heraus, dass:
- Die Kubernetes-API ist eine nicht triviale Sache, deren Beherrschung viel Zeit erfordert.
- Programmierung ist auch nicht jedermanns Sache (Go wird als bevorzugte Sprache gewählt, da es dafür einen speziellen Rahmen gibt - Operator SDK );
- mit dem Rahmen als solchem eine ähnliche Situation.
Fazit:
Um einen Controller (Operator)
zu schreiben , müssen Sie
erhebliche Ressourcen aufwenden, um Material zu studieren. Dies wäre für die "großen" Operatoren gerechtfertigt - beispielsweise für das MySQL-DBMS. Wenn wir uns jedoch an die oben beschriebenen Beispiele erinnern (Geheimnisse enthüllen, Zugriff auf Pods auf das Internet ...), die wir auch korrekt ausführen möchten, werden wir verstehen, dass die aufgewendeten Anstrengungen das jetzt erforderliche Ergebnis überwiegen werden:

Im Allgemeinen entsteht ein Dilemma: Verwenden Sie viele Ressourcen und finden Sie das richtige Werkzeug, um Aussagen zu schreiben oder "auf die alte Art" zu handeln (aber schnell). Um es zu lösen - um einen Kompromiss zwischen diesen Extremen zu finden - haben wir unser eigenes Projekt erstellt:
Shell-Operator (siehe auch seine jüngste Ankündigung auf dem Hub) .
Shell-Operator
Wie arbeitet er? Im Cluster befindet sich ein Pod, in dem die Go-Binärdatei mit Shell-Operator liegt.
Daneben befindet sich eine Reihe von
Haken (weitere Einzelheiten dazu siehe unten) . Der Shell-Operator selbst abonniert bestimmte
Ereignisse in der Kubernetes-API, bei denen er die entsprechenden Hooks startet.
Wie versteht der Shell-Operator, welche Hooks unter welchen Ereignissen ausgelöst werden sollen? Diese Informationen werden von den Hooks selbst an den Shell-Operator weitergegeben und machen es sehr einfach.
Ein Hook ist ein Bash-Skript oder eine andere ausführbare Datei, die ein einzelnes Argument
--config und als Antwort JSON zurückgibt. Letzterer bestimmt, welche Objekte ihn interessieren und welche Ereignisse (für diese Objekte) reagiert werden sollen:

Ich werde die Shell-Operator-Implementierung eines unserer Beispiele veranschaulichen - Geheimnisse für den Zugriff auf eine private Registrierung mit Anwendungsabbildern enthüllen. Es besteht aus zwei Stufen.
Übung: 1. Einen Haken schreiben
Der erste Schritt im Hook ist die Verarbeitung von
--config , was darauf hinweist, dass wir am Namespace interessiert sind, und insbesondere an dem Moment ihrer Erstellung:
[[ $1 == "--config" ]] ; then cat << EOF { "onKubernetesEvent": [ { "kind": "namespace", "event": ["add"] } ] } EOF …
Wie wird die Logik aussehen? Ziemlich einfach auch:
… else createdNamespace=$(jq -r '.[0].resourceName' $BINDING_CONTEXT_PATH) kubectl create -n ${createdNamespace} -f - << EOF Kind: Secret ... EOF fi
Der erste Schritt besteht darin, herauszufinden, welcher Namespace erstellt wurde, und der zweite Schritt besteht darin, über
kubectl ein Geheimnis für diesen Namespace zu
kubectl .
Übung: 2. Ein Bild zusammenstellen
Der verbleibende Hook muss noch an den Shell-Operator übertragen werden - wie geht das? Der Shell-Operator selbst wird als Docker-Image geliefert. Daher besteht unsere Aufgabe darin, einem speziellen Verzeichnis in diesem Image einen Hook hinzuzufügen:
FROM flant/shell-operator:v1.0.0-beta.1 ADD my-handler.sh /hooks
Es bleibt zu sammeln und Push'nut:
$ docker build -t registry.example.com/my-operator:v1 . $ docker push registry.example.com/my-operator:v1
Der letzte Schliff besteht darin, das Bild in einen Cluster einzubetten. Schreiben Sie dazu
Deployment :
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: my-operator spec: template: spec: containers: - name: my-operator image: registry.example.com/my-operator:v1 # 1 serviceAccountName: my-operator # 2
Darin müssen Sie zwei Punkte beachten:
- Anzeige des gerade erstellten Bildes;
- Dies ist eine Systemkomponente, die (mindestens) Rechte benötigt, um Ereignisse in Kubernetes zu abonnieren und Geheimnisse nach Namespace preiszugeben. Daher erstellen wir ein ServiceAccount (und eine Reihe von Regeln) für den Hook.
Das Ergebnis: Wir haben unser Problem auf eine für Kubernetes
native Weise gelöst und einen Operator zum Aufdecken von Geheimnissen erstellt.
Andere Shell-Operator-Funktionen
Um die Objekte des Typs Ihrer Wahl, mit dem der Hook arbeiten soll,
matchExpressions , können
Sie sie filtern, indem Sie nach bestimmten Beschriftungen
filtern (oder
matchExpressions ):
"onKubernetesEvent": [ { "selector": { "matchLabels": { "foo": "bar", }, "matchExpressions": [ { "key": "allow", "operation": "In", "values": ["wan", "warehouse"], }, ], } … } ]
Es wird ein
Deduplizierungsmechanismus bereitgestellt, mit dem Sie mithilfe eines JQ-Filters große JSONs von Objekten in kleine konvertieren können, wobei nur die Parameter übrig bleiben, mit denen wir die Änderung überwachen möchten.
Wenn der Hook aufgerufen wird, übergibt der Shell-Operator ihm
Daten über das Objekt , die für alle Anforderungen verwendet werden können.
Ereignisse, bei denen Hooks ausgelöst werden, sind nicht auf Kubernetes-Ereignisse beschränkt: Der Shell-Operator bietet Unterstützung für
das rechtzeitige Aufrufen von Hooks (ähnlich wie bei crontab im herkömmlichen Scheduler) sowie ein spezielles
onStartup- Ereignis. Alle diese Ereignisse können kombiniert und demselben Hook zugewiesen werden.
Und zwei weitere Funktionen des Shell-Operators:
- Es funktioniert asynchron . Seit dem Kubernetes-Ereignis (z. B. dem Erstellen eines Objekts) können andere Ereignisse (z. B. das Entfernen desselben Objekts) im Cluster auftreten, die in Hooks berücksichtigt werden müssen. Wenn der Hook fehlgeschlagen ist, wird er standardmäßig bis zum erfolgreichen Abschluss erneut aufgerufen (dieses Verhalten kann geändert werden).
- Es exportiert Metriken für Prometheus, mit denen Sie verstehen können, ob der Shell-Operator arbeitet, die Anzahl der Fehler für jeden Hook und die aktuelle Größe der Warteschlange ermitteln.
Um diesen Teil des Berichts zusammenzufassen:

Installation von Add-Ons
Für eine komfortable Arbeit mit Kubernetes wurde auch die Notwendigkeit der Installation von Add-Ons erwähnt. Ich werde am Beispiel der Art und Weise, wie unser Unternehmen ist, darüber sprechen, wie wir es jetzt tun.
Wir haben angefangen, mit Kubernetes mit mehreren Clustern zu arbeiten, deren einzige Ergänzung Ingress war. Es war notwendig, es in jedem Cluster anders zu platzieren, und wir haben mehrere YAML-Konfigurationen für verschiedene Umgebungen vorgenommen: Bare Metal, AWS ...
Es gab mehr Cluster - mehr Konfigurationen. Darüber hinaus haben wir diese Konfigurationen selbst verbessert, wodurch sie ziemlich heterogen wurden:
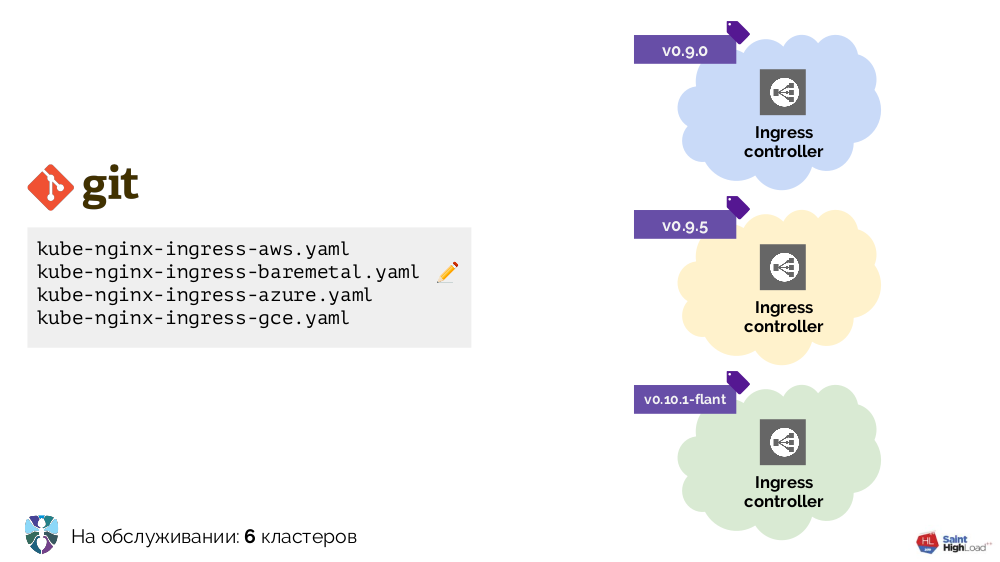
Um alles in Ordnung zu bringen, haben wir mit einem Skript (
install-ingress.sh ) begonnen, das den zu implementierenden Clustertyp als Argument verwendet, die gewünschte YAML-Konfiguration generiert und auf Kubernetes übertragen hat.
Kurz gesagt, unser weiterer Weg und die damit verbundenen Argumente waren wie folgt:
- Für die Arbeit mit YAML-Konfigurationen ist eine Template-Engine erforderlich (in den ersten Schritten handelt es sich um eine einfache Sedierung).
- Mit zunehmender Anzahl von Clustern wurden automatische Updates benötigt (die früheste Lösung besteht darin, ein Skript in Git einzufügen, es per Cron zu aktualisieren und auszuführen).
- Für Prometheus (
install-prometheus.sh ) war ein ähnliches Skript erforderlich. Es ist jedoch install-prometheus.sh bemerkenswert, als es viel mehr Eingabedaten sowie deren Speicherung (in guter Weise zentralisiert und im Cluster) erfordert und einige Daten (Kennwörter) automatisch generiert werden könnten ::

- Das Risiko, etwas Falsches in eine wachsende Anzahl von Clustern zu rollen, nahm ständig zu, sodass wir feststellten, dass die Installer (d. h. zwei Skripte: für Ingress und Prometheus) eine Bühneneinrichtung benötigten (mehrere Zweige in Git, mehrere Cron's, um sie in den entsprechenden zu aktualisieren: stabile oder Testcluster);
- Es wurde schwierig, mit
kubectl apply , da es nicht deklarativ ist und nur Objekte erstellen kann, aber keine Entscheidungen über ihren Status treffen / sie löschen kann. - Es fehlten einige Funktionen, die wir damals nicht realisierten:
- volle Kontrolle über das Ergebnis von Cluster-Updates,
- automatische Bestimmung einiger Parameter (Eingabe für Installationsskripte) basierend auf Daten, die vom Cluster abgerufen werden können (Erkennung),
- seine logische Entwicklung in Form einer kontinuierlichen Entdeckung.
All diese gesammelten Erfahrungen haben wir im Rahmen unseres anderen Projekts -
Addon-Operator - realisiert .
Addon-Operator
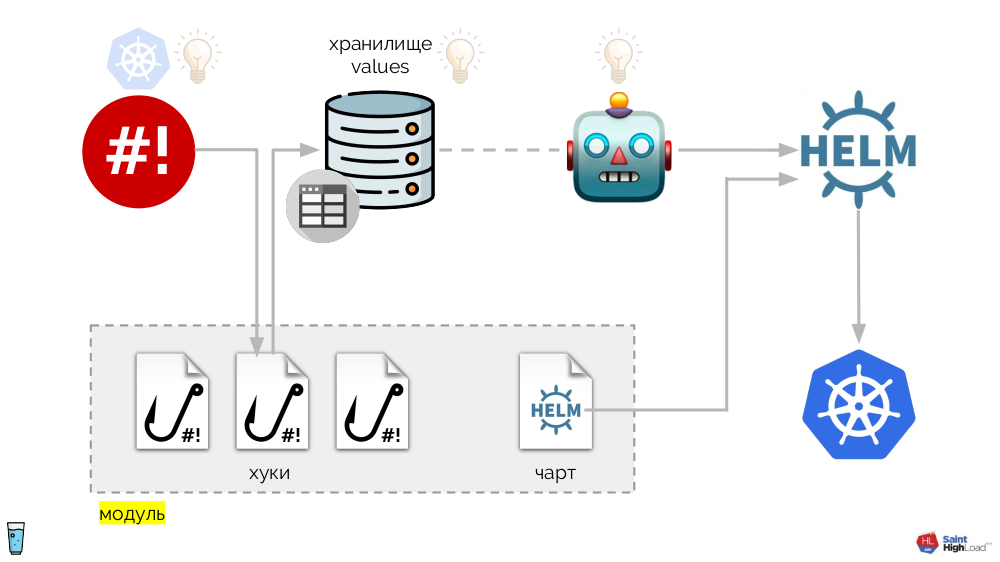
Es basiert auf dem bereits erwähnten Shell-Operator. Das ganze System ist wie folgt:
Zu Shell-Operator-Hooks werden hinzugefügt:
- Wertespeicherung
- Helmkarte
- Die Komponente, die das Werte-Repository überwacht und - im Falle von Änderungen - Helm auffordert, das Diagramm erneut zu rollen.

Auf diese Weise können wir auf ein Ereignis in Kubernetes reagieren, einen Hook starten und von diesem Hook aus Änderungen am Repository vornehmen. Danach wird das Diagramm erneut gepumpt. Im resultierenden Schema wählen wir eine Reihe von Hooks und ein Diagramm in einer Komponente aus, die wir als
Modul bezeichnen :
Es kann viele Module geben, und wir fügen ihnen globale Hooks, einen Speicher für globale Werte und eine Komponente hinzu, die diesen globalen Speicher überwacht.
Jetzt, da in Kubernetes etwas passiert, können wir darauf mit einem globalen Hook reagieren und etwas im globalen Repository ändern. Diese Änderung wird bemerkt und führt zu einem Rollback aller Module im Cluster:
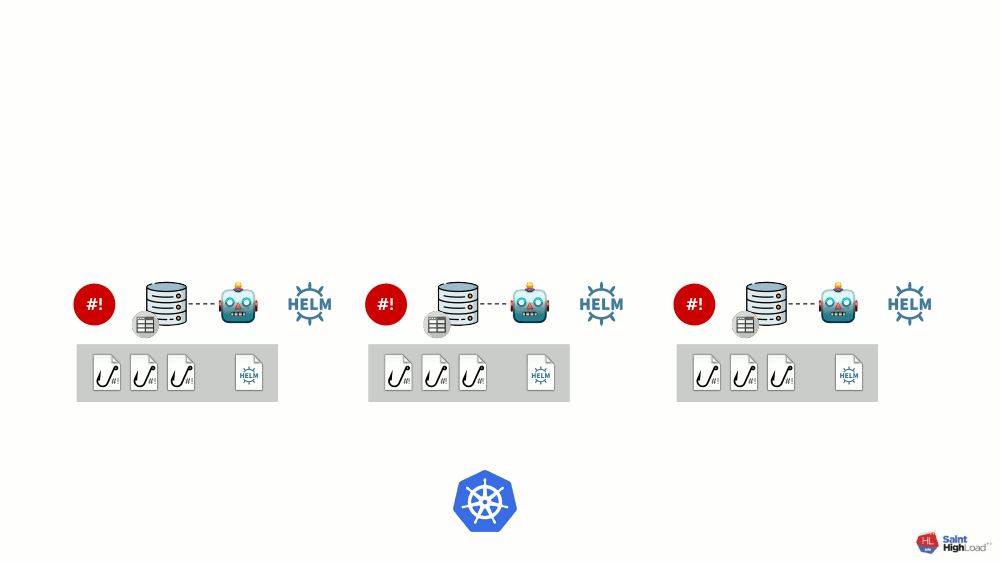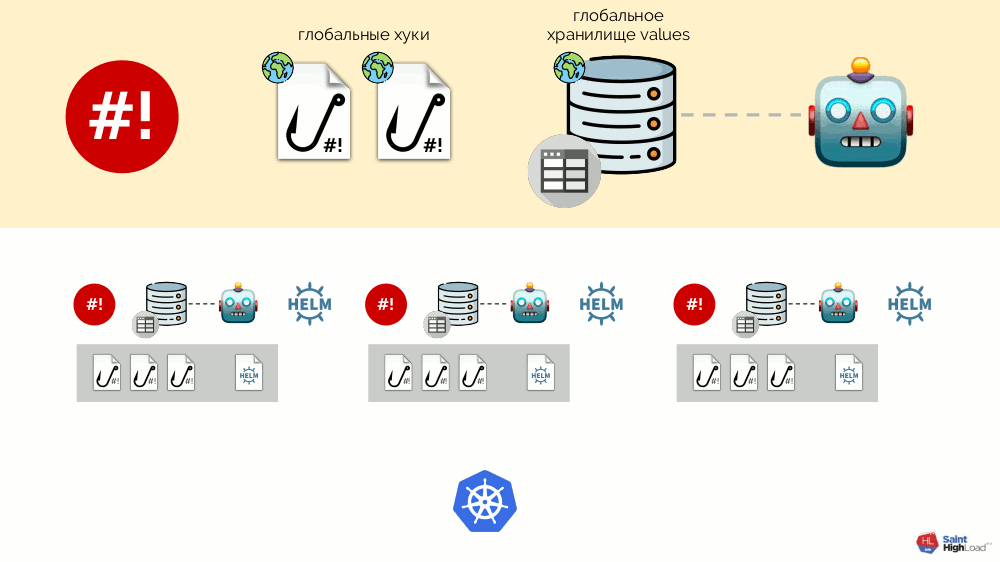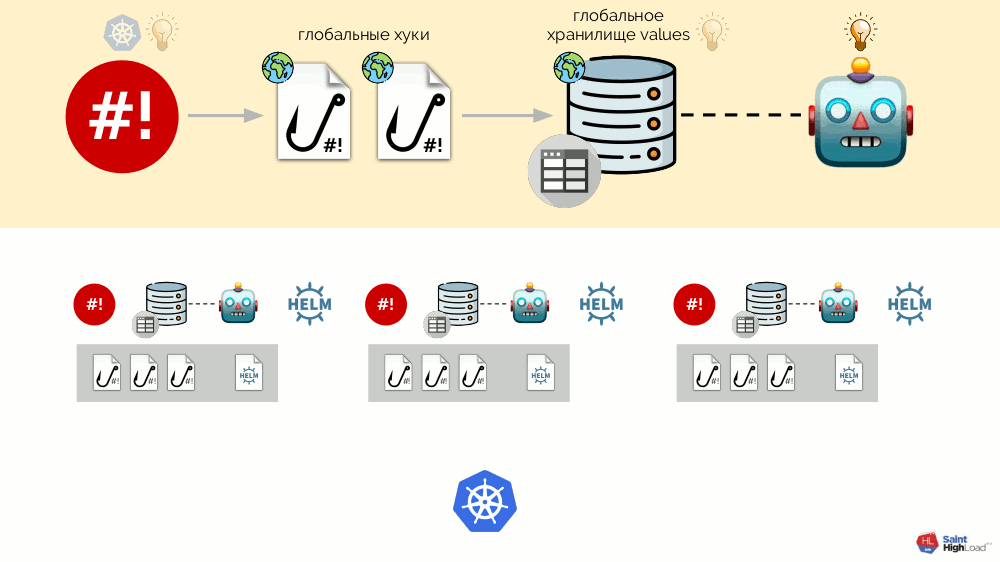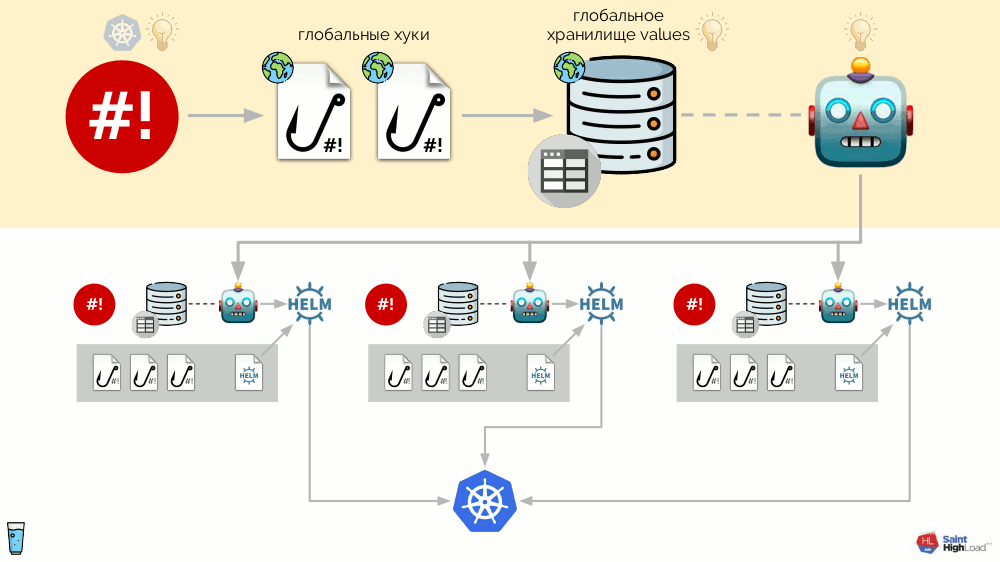
Dieses Schema erfüllt alle oben angekündigten Anforderungen für die Installation von Add-Ons:
- Helm ist verantwortlich für die Standardisierung und Deklarativität.
- Das Problem der automatischen Aktualisierung wurde mithilfe eines globalen Hooks behoben, der nach einem Zeitplan an die Registrierung gesendet wird. Wenn dort ein neues Image des Systems angezeigt wird, wird es erneut gerollt (dh "selbst").
- Die Speicherung der Einstellungen im Cluster wird mithilfe von ConfigMap implementiert, in dem Primärdaten für Speicher aufgezeichnet werden (beim Start werden sie in Speicher geladen).
- Die Probleme der Kennworterzeugung, -erkennung und der kontinuierlichen Erkennung werden mithilfe von Hooks gelöst.
- Die Bereitstellung erfolgt dank der Tags, die Docker sofort unterstützt.
- Das Ergebnis wird mithilfe von Metriken überwacht, anhand derer wir den Status verstehen können.
Dieses gesamte System ist als einzelne Binärdatei auf Go implementiert, die als Addon-Operator bezeichnet wurde. Dank dessen sieht das Schema einfacher aus:

Die Hauptkomponente in diesem Diagramm ist eine Reihe von Modulen
(unten abgeblendet) . Jetzt können wir mit ein wenig Aufwand ein Modul für das gewünschte Add-On schreiben und sicherstellen, dass es in jedem Cluster installiert wird, aktualisiert wird und auf die Ereignisse reagiert, die im Cluster benötigt werden.
Flant verwendet
Addon-Operator für mehr als 70 Kubernetes-Cluster. Aktueller Status ist
Alpha-Version . Jetzt bereiten wir die Dokumentation für die Beta-Version vor. Derzeit sind jedoch
Beispiele im Repository
verfügbar , auf deren Grundlage Sie Ihr Addon erstellen können.
Woher bekommen Sie die Addon-Operator-Module selbst? Die Veröffentlichung unserer Bibliothek ist für uns die nächste Etappe, wir planen dies im Sommer.
Videos und Folien
Video von der Aufführung (~ 50 Minuten):
Präsentation des Berichts:
PS
Weitere Berichte in unserem Blog:
Sie könnten auch an folgenden Veröffentlichungen interessiert sein: