
Technologien und Modelle für unser zukünftiges Computer-Vision-System wurden in verschiedenen Projekten unseres Unternehmens schrittweise entwickelt und verbessert - in den Bereichen Mail, Cloud und Suche. Gereift wie guter Käse oder Cognac. Als wir feststellten, dass unsere neuronalen Netze hervorragende Erkennungsergebnisse zeigten, beschlossen wir, sie in ein einziges B2B-Produkt - Vision - zu integrieren, das wir jetzt selbst verwenden und anbieten, Sie zu verwenden.
Heute funktioniert unsere Computer-Vision-Technologie auf der Mail.Ru Cloud Solutions-Plattform erfolgreich und löst sehr komplexe praktische Probleme. Es basiert auf einer Reihe von neuronalen Netzen, die auf unseren Datensätzen trainiert sind und sich auf die Lösung angewandter Probleme spezialisiert haben. Alle Dienste drehen sich um unsere Serverkapazitäten. Sie können die öffentliche Vision-API in Ihre Anwendungen integrieren, über die alle Funktionen des Dienstes verfügbar sind. Die API ist schnell - dank Server-GPUs beträgt die durchschnittliche Antwortzeit in unserem Netzwerk 100 ms.
Kommen Sie unter den Schnitt, es gibt eine detaillierte Geschichte und viele Beispiele für Vision.
Als Beispiel für einen Dienst, bei dem wir selbst die oben genannten Gesichtserkennungstechnologien verwenden, können wir
Ereignisse anführen. Eine seiner Komponenten sind die Vision-Fotoständer, die wir auf verschiedenen Konferenzen installieren. Wenn Sie zu einem solchen Fotostand gehen, ein Bild mit der eingebauten Kamera aufnehmen und Ihre E-Mail-Adresse eingeben, findet das System sofort unter den Fotos diejenigen, von denen die regulären Konferenzfotografen Sie aufgenommen haben, und sendet Ihnen die gefundenen Fotos auf Wunsch per Post. Und es geht nicht um inszenierte Porträtaufnahmen - Vision erkennt Sie auch im Hintergrund in der Menge der Besucher. Natürlich werden sie von den Fotoständen selbst nicht erkannt, sondern sind nur Tablets in schönen Untersetzern, die Gäste einfach mit ihren eingebauten Kameras fotografieren und Informationen an Server übertragen, auf denen die ganze Magie der Erkennung stattfindet. Und wir haben wiederholt beobachtet, wie überraschend die Effektivität der Technologie selbst unter Spezialisten für Bilderkennung ist. Im Folgenden werden einige Beispiele aufgeführt.
1. Unser Gesichtserkennungsmodell
1.1. Neuronales Netz und Verarbeitungsgeschwindigkeit
Zur Erkennung verwenden wir eine Modifikation des neuronalen Netzwerkmodells ResNet 101. Das durchschnittliche Pooling am Ende wird durch eine vollständig verbundene Ebene ersetzt, ähnlich wie in ArcFace. Die Größe der Vektordarstellungen beträgt jedoch 128 und nicht 512. Unser Trainingsset enthält etwa 10 Millionen Fotos von 273.593 Personen.
Das Modell arbeitet dank einer sorgfältig ausgewählten Serverkonfigurationsarchitektur und GPU-Computing sehr schnell. Es dauert 100 ms, um eine Antwort von der API in unseren internen Netzwerken zu erhalten. Dies umfasst die Gesichtserkennung (Gesichtserkennung auf dem Foto), die Erkennung und die Rückgabe der PersonID in der API-Antwort. Bei großen Mengen eingehender Daten - Fotos und Videos - dauert es viel länger, Daten an den Dienst zu übertragen und eine Antwort zu erhalten.
1.2. Bewertung der Wirksamkeit des Modells
Die Bestimmung der Effizienz neuronaler Netze ist jedoch eine sehr gemischte Aufgabe. Die Qualität ihrer Arbeit hängt davon ab, auf welchen Datensätzen die Modelle trainiert wurden und ob sie für die Arbeit mit bestimmten Daten optimiert wurden.
Wir haben begonnen, die Genauigkeit unseres Modells mit dem beliebten LFW-Verifikationstest zu bewerten, aber es ist zu klein und einfach. Nach Erreichen einer Genauigkeit von 99,8% ist es nicht mehr nützlich. Es gibt einen guten Wettbewerb für die Bewertung von Erkennungsmodellen - Megaface erreichte allmählich 82% Rang 1. Der Megaface-Test besteht aus einer Million Fotos - Distraktoren - und das Modell sollte in der Lage sein, mehrere tausend Fotos von Prominenten aus dem Facescrub-Datensatz gut von Distraktoren zu unterscheiden. Nachdem wir den Megaface-Test auf Fehler überprüft hatten, stellten wir fest, dass wir bei der bereinigten Version eine Genauigkeit von 98% Rang 1 erreichen (Promi-Fotos sind im Allgemeinen recht spezifisch). Aus diesem Grund haben sie einen separaten Identifikationstest erstellt, ähnlich wie Megaface, jedoch mit Fotos von „normalen“ Menschen. Die Erkennungsgenauigkeit ihrer Datensätze wurde weiter verbessert und ging weit voran. Zusätzlich verwenden wir den Clustering-Qualitätstest, der aus mehreren tausend Fotos besteht. Es simuliert das Markup von Gesichtern in der Cloud des Benutzers. In diesem Fall sind Cluster Gruppen ähnlicher Personen, eine Gruppe für jede erkennbare Person. Wir haben die Qualität der Arbeit an realen Gruppen überprüft (wahr).
Natürlich hat jedes Modell Erkennungsfehler. Solche Situationen werden jedoch häufig durch Feinabstimmung der Schwellenwerte für bestimmte Bedingungen gelöst (für alle Konferenzen verwenden wir dieselben Schwellenwerte, und beispielsweise müssen wir für ACS die Schwellenwerte erheblich erhöhen, damit weniger Fehlalarme auftreten). Die überwiegende Mehrheit der Konferenzteilnehmer wurde von unseren Vision-Fotoständen korrekt erkannt. Manchmal schaute jemand auf die zugeschnittene Vorschau und sagte: "Ihr System war falsch, ich bin es nicht." Dann haben wir das gesamte Foto geöffnet und es stellte sich heraus, dass dieser Besucher wirklich auf dem Foto war, nur dass er es nicht aufgenommen hat, sondern dass jemand anderes, nur ein Mann, versehentlich im Hintergrund in der Unschärfezone aufgetaucht ist. Darüber hinaus erkennt das neuronale Netzwerk häufig korrekt, selbst wenn ein Teil des Gesichts nicht sichtbar ist oder eine Person im Profil oder sogar im Halbgesicht steht. Das System kann eine Person erkennen, selbst wenn die Person beispielsweise beim Aufnehmen mit einem Weitwinkelobjektiv in das Feld der optischen Verzerrung gefallen ist.
1.3. Testbeispiele in schwierigen Situationen
Nachfolgend finden Sie Beispiele für den Betrieb unseres neuronalen Netzwerks. Am Eingang werden Fotos eingereicht, die sie mit PersonID markieren muss - eine eindeutige Kennung für die Person. Wenn zwei oder mehr Bilder dieselbe Kennung haben, zeigen diese Fotos je nach Modell eine Person.
Wir stellen sofort fest, dass wir während des Testens Zugriff auf verschiedene Parameter und Schwellenwerte von Modellen haben, die wir konfigurieren können, um ein bestimmtes Ergebnis zu erzielen. Die öffentliche API ist für maximale Genauigkeit in häufigen Fällen optimiert.
Beginnen wir mit dem Einfachsten, mit der Gesichtserkennung im Gesicht.

Das war zu einfach. Wir erschweren die Aufgabe, fügen einen Bart und eine Handvoll Jahre hinzu.

Jemand wird sagen, dass dies nicht zu schwierig war, da in beiden Fällen das Gesicht in seiner Gesamtheit sichtbar ist und der Algorithmus viele Informationen über das Gesicht enthält. Okay, dreh Tom Hardy im Profil. Diese Aufgabe ist viel komplizierter, und wir haben viel Aufwand für die erfolgreiche Lösung bei gleichzeitig geringem Fehleraufwand betrieben: Wir haben ein Trainingsmuster ausgewählt, über die Architektur des neuronalen Netzwerks nachgedacht, die Verlustfunktionen verbessert und die vorläufige Verarbeitung von Fotos verbessert.
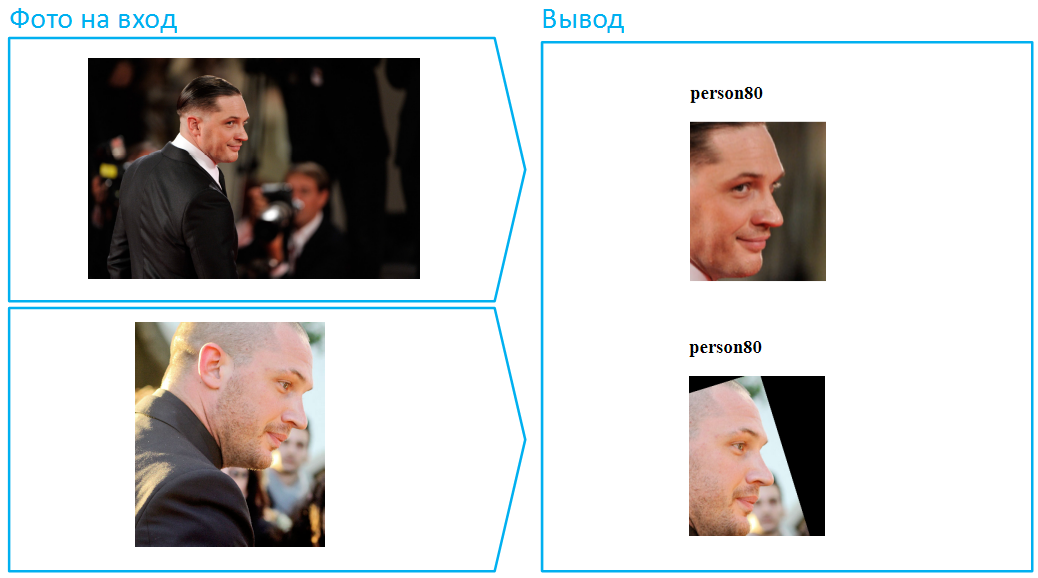
Setzen wir einen Hut auf ihn:

Dies ist übrigens ein Beispiel für eine besonders schwierige Situation, da das Gesicht hier sehr bedeckt ist und im unteren Bild auch ein tiefer Schatten die Augen verbirgt. Im wirklichen Leben ändern Menschen ihr Aussehen sehr oft mit Hilfe einer dunklen Brille. Mach dasselbe mit Tom.

Lassen Sie uns versuchen, Fotos aus verschiedenen Altersgruppen hochzuladen, und dieses Mal werden wir Erfahrungen mit einem anderen Schauspieler machen. Nehmen wir ein viel komplexeres Beispiel, wenn altersbedingte Veränderungen besonders ausgeprägt sind. Die Situation ist nicht weit hergeholt, es passiert immer wieder, wenn Sie ein Foto in Ihrem Reisepass mit dem Gesicht des Inhabers vergleichen müssen. Immerhin steckt das erste Foto im Pass, wenn der Besitzer 20 Jahre alt ist, und von 45 Personen kann sich sehr viel ändern:

Denken Sie, dass sich das Hauptspecial für unmögliche Missionen mit dem Alter nicht wesentlich geändert hat? Ich denke, dass sogar ein paar Leute die oberen und unteren Fotos kombinieren würden, der Junge hat sich im Laufe der Jahre so sehr verändert.

Neuronale Netze sind viel häufiger mit Veränderungen im Erscheinungsbild konfrontiert. Zum Beispiel können Frauen manchmal ihr Image mithilfe von Kosmetika stark verändern:

Lassen Sie uns die Aufgabe jetzt noch komplizierter machen: Lassen Sie verschiedene Teile des Gesichts mit verschiedenen Fotos bedecken. In solchen Fällen kann der Algorithmus nicht die gesamten Stichproben vergleichen. Vision geht jedoch gut mit solchen Situationen um.
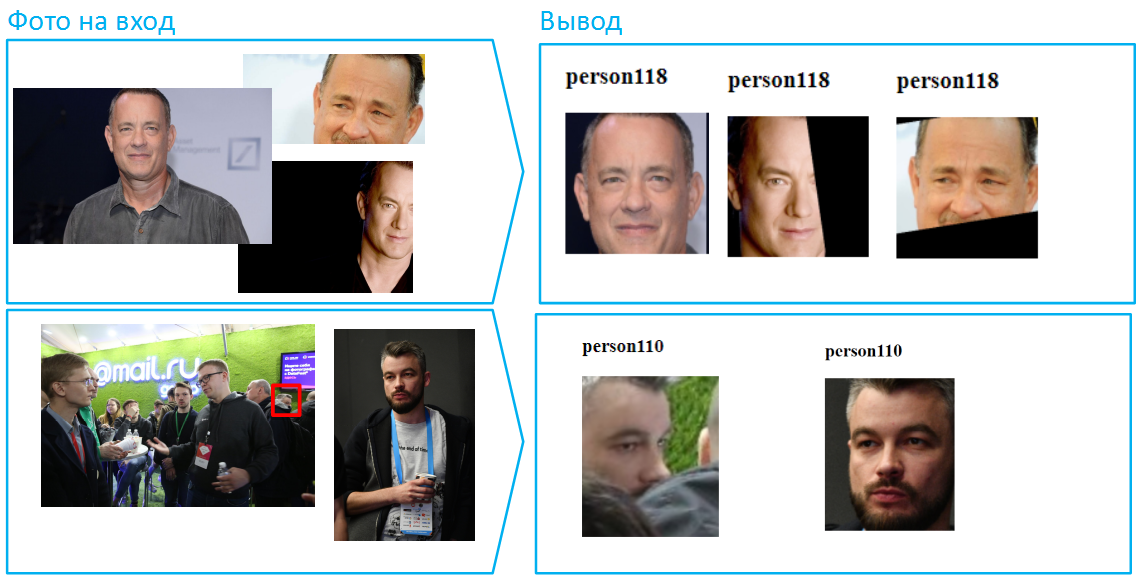
Übrigens sind auf Fotos viele Gesichter zu sehen, zum Beispiel können mehr als 100 Personen in ein gemeinsames Bild der Halle passen. Dies ist eine schwierige Situation für neuronale Netze, da viele Gesichter unterschiedlich beleuchtet werden können, jemand außerhalb der Schärfezone. Wenn das Foto jedoch mit ausreichender Auflösung und Qualität aufgenommen wurde (mindestens 75 Pixel pro Quadrat, das das Gesicht bedeckt), kann Vision es identifizieren und erkennen.

Die Besonderheit bei der Meldung von Fotos und Bildern von Überwachungskameras besteht darin, dass Menschen häufig verschwommen sind, weil sie sich außerhalb des Schärfebereichs befanden oder sich in diesem Moment bewegten:

Auch die Beleuchtungsstärke kann von Bild zu Bild stark variieren. Dies wird auch oft zu einem Stolperstein. Viele Algorithmen haben große Schwierigkeiten, Bilder, die zu dunkel und zu hell sind, korrekt zu verarbeiten, ganz zu schweigen vom genauen Vergleich. Ich möchte Sie daran erinnern, dass Sie, um ein solches Ergebnis zu erzielen, Schwellenwerte auf eine bestimmte Weise festlegen müssen. Diese Möglichkeit ist noch nicht öffentlich verfügbar. Für alle Clients verwenden wir dasselbe neuronale Netzwerk mit Schwellenwerten, die für die meisten praktischen Aufgaben geeignet sind.

Kürzlich haben wir eine neue Version des Modells eingeführt, die asiatische Gesichter mit hoher Genauigkeit erkennt. Zuvor war dies ein großes Problem, das sogar als "Rassismus beim maschinellen Lernen" (oder "neuronale Netze") bezeichnet wurde. Europäische und amerikanische neuronale Netze erkannten europoidische Gesichter gut, und bei mongoloiden und negroiden war es viel schlimmer. Wahrscheinlich im selben China war die Situation genau umgekehrt. Es geht um Trainingsdatensätze, die die dominierenden Arten von Menschen in einem bestimmten Land widerspiegeln. Die Situation ändert sich jedoch, heute ist dieses Problem alles andere als akut. Das Sehen hat keine Schwierigkeiten mit Vertretern verschiedener Rassen.

Gesichtserkennung ist nur eine von vielen Anwendungen unserer Technologie. Vision kann gelehrt werden, alles zu erkennen. Zum Beispiel Fahrzeugnummern, auch unter schwierigen Bedingungen für Algorithmen: in scharfen Winkeln, schmutzige und schwer lesbare Zahlen.

2. Praktische Anwendungsfälle
2.1. Physische Zugangskontrolle: Wenn zwei den gleichen Pass haben
Mit Hilfe von Vision ist es möglich, Buchhaltungssysteme für die An- und Abreise von Mitarbeitern zu implementieren. Ein traditionelles System, das auf elektronischen Ausweisen basiert, hat offensichtliche Nachteile. Sie können beispielsweise zwei Ausweise zusammen durchlaufen. Wenn das Zugangskontrollsystem (ACS) durch Vision ergänzt wird, wird ehrlich aufgezeichnet, wer wann kam und ging.
2.2. Zeiterfassung
Dieser Anwendungsfall für Vision ist eng mit dem vorherigen verwandt. Wenn wir das Zugangskontrollsystem durch unseren Gesichtserkennungsdienst ergänzen, kann es nicht nur Verstöße gegen die Zugangskontrolle feststellen, sondern auch den tatsächlichen Aufenthalt der Mitarbeiter im Gebäude oder in der Einrichtung aufzeichnen. Mit anderen Worten, Vision wird helfen, ehrlich zu überlegen, wer und wie viel zur Arbeit gekommen ist und mit ihr gegangen ist und wer sogar übersprungen hat, selbst wenn seine Kollegen ihn vor seinen Vorgesetzten gedeckt haben.
2.3. Videoanalyse: Personenverfolgung und Sicherheit
Indem Sie Personen mit Vision verfolgen, können Sie die tatsächliche Durchgängigkeit von Einkaufsbereichen, Bahnhöfen, Kreuzungen, Straßen und vielen anderen öffentlichen Orten genau einschätzen. Unsere Nachverfolgung kann auch eine große Hilfe bei der Kontrolle des Zugriffs sein, beispielsweise auf ein Lager oder andere wichtige Büroräume. Das Verfolgen von Personen und Gesichtern hilft natürlich bei der Lösung von Sicherheitsproblemen. Jemanden erwischt, der aus Ihrem Geschäft gestohlen hat? Fügen Sie es in die PersonID, die Vision zurückgegeben hat, in die schwarze Liste Ihrer Videoanalyse-Software ein, und das nächste Mal benachrichtigt das System die Sicherheit sofort, wenn dieser Typ erneut angezeigt wird.
2.4. Im Handel
Einzelhandel und verschiedene Dienstleistungsunternehmen sind an der Erkennung von Warteschlangen interessiert. Mit Vision können Sie erkennen, dass es sich nicht um eine zufällige Personenmenge handelt, sondern um eine Warteschlange, und deren Länge bestimmen. Und dann informiert das System die Verantwortlichen der Warteschlange, um die Situation zu verstehen: Entweder handelt es sich um einen Zustrom von Besuchern, und es müssen zusätzliche Mitarbeiter angerufen werden, oder jemand hackt mit seiner Arbeitsverantwortung.
Eine weitere interessante Aufgabe ist die Trennung der Mitarbeiter des Unternehmens in der Halle von den Besuchern. In der Regel lernt das System, Objekte in bestimmten Kleidungsstücken (Kleiderordnung) oder mit bestimmten Unterscheidungsmerkmalen (Unterschriftenschal, Abzeichen auf der Brust usw.) zu trennen. Dies hilft, die Anwesenheit genauer zu bewerten (damit die Mitarbeiter allein die Statistiken der Personen in der Halle nicht „aufwickeln“).
Mithilfe der Gesichtserkennung können Sie Ihr Publikum bewerten: Wie hoch ist die Loyalität der Besucher, dh wie viele Personen kehren mit welcher Häufigkeit zu Ihrer Einrichtung zurück? Berechnen Sie, wie viele eindeutige Besucher pro Monat zu Ihnen kommen. Um die Kosten für die Gewinnung und Bindung zu optimieren, können Sie die Besucherzahlen je nach Wochentag und sogar Tageszeit ermitteln und ändern.
Franchisegeber und Netzwerkunternehmen können anhand von Fotos eine Bewertung der Markenqualität verschiedener Einzelhandelsgeschäfte anordnen: das Vorhandensein von Logos, Schildern, Postern, Bannern usw.
2.5. Beim Transport
Ein weiteres Beispiel für Sicherheit durch Videoanalyse ist die Identifizierung von Gegenständen, die in Flughafen- oder Bahnhofshallen zurückgelassen wurden. Das Sehen kann trainiert werden, um Objekte aus Hunderten von Klassen zu erkennen: Möbel, Taschen, Koffer, Regenschirme, verschiedene Arten von Kleidung, Flaschen und so weiter. Wenn Ihr Videoanalysesystem ein Objekt ohne Eigentümer erkennt und es mit Vision erkennt, sendet es ein Signal an den Sicherheitsdienst. Eine ähnliche Aufgabe betrifft die automatische Erkennung von nicht standardmäßigen Situationen an öffentlichen Orten: Jemand wurde krank oder jemand rauchte am falschen Ort oder die Person fiel auf die Schienen und so weiter - all diese Muster des Videoanalysesystems können durch die API Vision erkannt werden.
2.6. Workflow
Eine weitere interessante zukünftige Anwendung von Vision, die wir derzeit entwickeln, ist die Erkennung von Dokumenten und deren automatische Analyse in Datenbanken. Anstatt endlose Serien, Nummern, Ausgabedaten, Kontonummern, Bankdaten, Geburtsdaten und -orte sowie viele andere formalisierte Daten manuell einzugeben (oder noch schlimmer einzugeben), können Sie Dokumente scannen und automatisch über einen sicheren Kanal über die API senden In der Cloud, in der das System im laufenden Betrieb ist, werden diese Dokumente erkannt, analysiert und eine Antwort mit Daten im gewünschten Format für den automatischen Eintrag in die Datenbank zurückgegeben. Vision weiß bereits heute, wie man Dokumente klassifiziert (auch als PDF) - es unterscheidet Pässe, SNILS, TIN, Geburtsurkunden, Heiratsurkunden und andere.
Natürlich kann das neuronale Netzwerk all diese Situationen nicht sofort bewältigen. In jedem Fall wird ein neues Modell für einen bestimmten Kunden erstellt, viele Faktoren, Nuancen und Anforderungen werden berücksichtigt, Datensätze werden ausgewählt, Einstellungen für Trainingstests werden wiederholt.
3. API-Arbeitsschema
Das „Eingangstor“ von Vision für Benutzer ist die REST-API. Am Eingang kann er Fotos, Videodateien und Sendungen von Netzwerkkameras (RTSP-Streams) aufnehmen.
Um Vision verwenden zu können, müssen Sie
sich bei Mail.ru Cloud Solutions
registrieren und Zugriffstoken (client_id + client_secret) erhalten. Die Benutzerauthentifizierung wird mithilfe des OAuth-Protokolls durchgeführt. Die Quelldaten in den Hauptteilen der POST-Anforderungen werden an die API gesendet. Als Antwort erhält der Client das Erkennungsergebnis von der API im JSON-Format, und die Antwort ist strukturiert: Sie enthält Informationen zu den gefundenen Objekten und ihren Koordinaten.

Antwortbeispiel{ "status":200, "body":{ "objects":[ { "status":0, "name":"file_0" }, { "status":0, "name":"file_2", "persons":[ { "tag":"person9" "coord":[149,60,234,181], "confidence":0.9999, "awesomeness":0.45 }, { "tag":"person10" "coord":[159,70,224,171], "confidence":0.9998, "awesomeness":0.32 } ] } { "status":0, "name":"file_3", "persons":[ { "tag":"person11", "coord":[157,60,232,111], "aliases":["person12", "person13"] "confidence":0.9998, "awesomeness":0.32 } ] }, { "status":0, "name":"file_4", "persons":[ { "tag":"undefined" "coord":[147,50,222,121], "confidence":0.9997, "awesomeness":0.26 } ] } ], "aliases_changed":false }, "htmlencoded":false, "last_modified":0 }
Die Antwort hat einen interessanten Parameter - dies ist die bedingte „Kühle“ des Gesichts auf dem Foto. Damit wählen wir die beste Gesichtsaufnahme aus der Sequenz aus. Wir haben das neuronale Netzwerk trainiert, um die Wahrscheinlichkeit vorherzusagen, mit der das Bild in sozialen Netzwerken aussehen wird. Je besser das Bild und je glatter das Gesicht, desto größer die Ehrfurcht.
Die Vision-API verwendet ein Konzept wie Space. Dies ist ein Werkzeug zum Erstellen verschiedener Sätze von Gesichtern. Beispiele für Leerzeichen sind Schwarzweißlisten, Listen von Besuchern, Mitarbeitern, Kunden usw. Für jedes Token in Vision können Sie bis zu 10 Leerzeichen erstellen. In jedem Leerzeichen können bis zu 50.000 Personen-IDs vorhanden sein, dh bis zu 500.000 für ein Token . Darüber hinaus ist die Anzahl der Token pro Konto nicht begrenzt.
Heute unterstützt die API die folgenden Erkennungs- und Erkennungsmethoden:
- Erkennen / Setzen - Definition und Erkennung von Gesichtern. Weist jedem eindeutigen Gesicht automatisch eine PersonID zu, gibt die PersonID und die Koordinaten der gefundenen Gesichter zurück.
- Löschen - Löscht eine bestimmte PersonID aus der Personendatenbank.
- Abschneiden - Löscht den gesamten Speicherplatz von PersonID. Dies ist nützlich, wenn er als Test verwendet wurde und Sie die Basis für die Produktion zurücksetzen müssen.
- Erkennen - Definition von Objekten, Szenen, Nummernschildern, Attraktionen, Warteschlangen usw. Gibt die Klasse der gefundenen Objekte und ihre Koordinaten zurück
- Nach Dokumenten suchen - Erkennt bestimmte Arten von Dokumenten der Russischen Föderation (unterscheidet Pass, Snls, Gasthaus usw.).
Außerdem werden wir in Kürze die Arbeit an Methoden für die OCR beenden, Geschlecht, Alter und Emotionen bestimmen sowie Merchandising-Aufgaben lösen, dh die Anzeige von Waren in Geschäften automatisch steuern. Die vollständige API-Dokumentation finden Sie hier:
https://mcs.mail.ru/help/vision-api4. Fazit
Über die öffentliche API können Sie jetzt auf die Gesichtserkennung in Fotos und Videos zugreifen. Sie unterstützt die Definition verschiedener Objekte, Fahrzeugnummern, Attraktionen, Dokumente und ganzer Szenen. Anwendungsszenarien - Meer. Kommen Sie, testen Sie unseren Service und stellen Sie die schwierigsten Aufgaben dafür. Die ersten 5.000 Transaktionen sind kostenlos. Es kann die „fehlende Zutat“ für Ihre Projekte sein.
Der Zugriff auf die API kann sofort bei der Registrierung und Verbindung mit
Vision erfolgen . Alle Habra-Benutzer - ein Aktionscode für zusätzliche Transaktionen. Schreiben Sie eine persönliche E-Mail-Adresse, unter der das Konto registriert wurde!