Guten Tag. Mein Name ist Ibadov Ilkin, ich bin Student der Ural Federal University.
In diesem Artikel möchte ich über meine Erfahrungen mit der automatisierten Lösung für Googles Captcha "reCAPTCHA" sprechen. Ich möchte den Leser im Voraus warnen, dass der Prototyp zum Zeitpunkt des Schreibens des Artikels nicht so effizient funktioniert, wie es aus dem Titel hervorgeht. Das Ergebnis zeigt jedoch, dass der implementierte Ansatz das Problem lösen kann.
Wahrscheinlich ist jeder in seinem Leben auf ein Captcha gestoßen: Geben Sie Text aus einem Bild ein, lösen Sie einen einfachen Ausdruck oder eine komplizierte Gleichung, wählen Sie Autos, Hydranten, Fußgängerüberwege ... Der Schutz von Ressourcen vor automatisierten Systemen ist notwendig und spielt eine wichtige Rolle für die Sicherheit: Captcha schützt vor DDoS-Angriffen , automatische Registrierungen und Buchungen, Parsen, verhindert die Auswahl von Spam und Passwort für Konten.
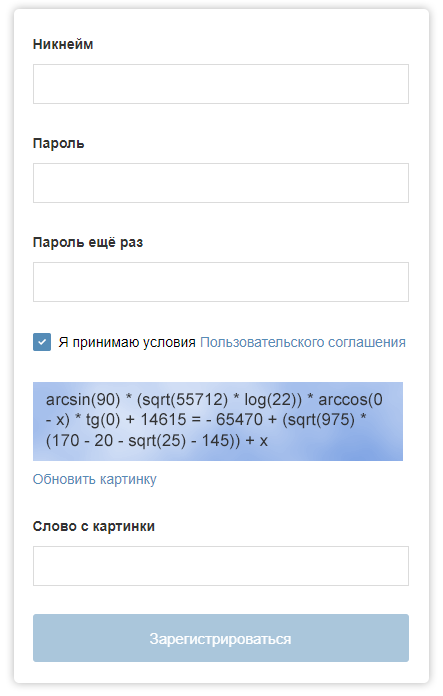 Das Anmeldeformular auf "Habré" könnte mit einem solchen Captcha versehen sein.
Das Anmeldeformular auf "Habré" könnte mit einem solchen Captcha versehen sein.Mit der Entwicklung von Technologien für maschinelles Lernen kann die Leistung von Captcha gefährdet sein. In diesem Artikel beschreibe ich die wichtigsten Punkte eines Programms, mit denen das Problem der manuellen Auswahl von Bildern in Google reCAPTCHA gelöst werden kann (zum Glück bisher nicht immer).
Um durch Captcha zu kommen, müssen folgende Probleme gelöst werden: Bestimmen der erforderlichen Captcha-Klasse, Erkennen und Klassifizieren von Objekten, Erkennen von Captcha-Zellen, Simulieren menschlicher Aktivitäten beim Lösen von Captcha (Cursorbewegung, Klicken).
Um nach Objekten in einem Bild zu suchen, werden trainierte neuronale Netze verwendet, die auf einen Computer heruntergeladen werden können und Objekte in Bildern oder Videos erkennen. Um das Captcha zu lösen, reicht es jedoch nicht aus, nur Objekte zu erkennen: Sie müssen die Position der Zellen bestimmen und herausfinden, welche Zellen Sie auswählen möchten (oder überhaupt nicht). Hierfür werden Computer Vision Tools verwendet: In dieser Arbeit ist dies die berühmte
OpenCV-Bibliothek .
Um Objekte im Bild zu finden, wird zunächst das Bild selbst benötigt. Ich erhalte einen Screenshot eines Teils des Bildschirms mit dem
PyAutoGUI- Modul mit Abmessungen, die zum Erkennen von Objekten ausreichen. Im Rest des Bildschirms zeige ich Fenster zum Debuggen und Überwachen von Programmprozessen an.
Objekterkennung
Das Erkennen und Klassifizieren von Objekten ist das, was das neuronale Netzwerk tut. Die Bibliothek, mit der wir mit neuronalen Netzen arbeiten können, heißt "
Tensorflow " (entwickelt von Google). Heutzutage
stehen Ihnen
viele verschiedene trainierte Modelle für unterschiedliche Daten zur Verfügung , was bedeutet, dass alle ein unterschiedliches Erkennungsergebnis
liefern können: Einige Modelle erkennen Objekte besser, andere schlechter.
In diesem Artikel verwende ich das Modell ssd_mobilenet_v1_coco. Das ausgewählte Modell wurde anhand des
COCO- Datensatzes trainiert, der 90 verschiedene Klassen hervorhebt (von Personen und Autos bis hin zu Zahnbürsten und Kämmen). Jetzt gibt es andere Modelle, die mit denselben Daten trainiert werden, jedoch mit unterschiedlichen Parametern. Darüber hinaus verfügt dieses Modell über optimale Leistungs- und Genauigkeitsparameter, was für einen Desktop-Computer wichtig ist. Die Quelle sagt, dass die Verarbeitungszeit für ein Bild von 300 x 300 Pixel 30 Millisekunden beträgt. Auf der "Nvidia GeForce GTX TITAN X".
Das Ergebnis des neuronalen Netzwerks ist eine Reihe von Arrays:
- mit einer Liste von Klassen erkannter Objekte (deren Kennungen);
- mit einer Liste von Bewertungen erkannter Objekte (in Prozent);
- mit einer Liste von Koordinaten erkannter Objekte ("Kästchen").
Die Indizes der Elemente in diesen Arrays entsprechen einander, dh: Das dritte Element im Array der Objektklassen entspricht dem dritten Element im Array der "Kästchen" der erkannten Objekte und dem dritten Element im Array der Objektbewertungen.
 Mit dem ausgewählten Modell können Sie Objekte aus 90 Klassen in Echtzeit erkennen.
Mit dem ausgewählten Modell können Sie Objekte aus 90 Klassen in Echtzeit erkennen.Zellerkennung
"OpenCV" bietet uns die Möglichkeit, mit Entitäten zu arbeiten, die als "
Schaltkreise " bezeichnet werden: Sie können nur von der Funktion "findContours ()" aus der Bibliothek "OpenCV" erkannt werden. Es ist notwendig, ein Binärbild an die Eingabe einer solchen Funktion zu senden, das
durch die Schwellentransformationsfunktion erhalten werden kann :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
Nachdem wir die Extremwerte der Parameter der Schwellentransformationsfunktion eingestellt haben, werden auch verschiedene Arten von Rauschen beseitigt. Um die Menge an unnötigen kleinen Elementen und Rauschen zu minimieren, können
morphologische Transformationen angewendet werden: Erosions- (Komprimierungs-) und Aufbaufunktionen (Expansionsfunktionen). Diese Funktionen sind auch Teil von OpenCV. Nach den Transformationen werden die Konturen ausgewählt, deren Anzahl der Eckpunkte vier beträgt (nachdem zuvor die
Approximationsfunktion für die Konturen ausgeführt wurde).
 Im ersten Fenster das Ergebnis der Schwellenwerttransformation. Das zweite ist ein Beispiel für eine morphologische Transformation. Im dritten Fenster sind die Zellen und die Captcha-Kappe bereits ausgewählt: programmgesteuert farblich hervorgehoben.
Im ersten Fenster das Ergebnis der Schwellenwerttransformation. Das zweite ist ein Beispiel für eine morphologische Transformation. Im dritten Fenster sind die Zellen und die Captcha-Kappe bereits ausgewählt: programmgesteuert farblich hervorgehoben.Nach all den Transformationen fallen die Konturen, die keine Zellen sind, immer noch in das endgültige Array mit Zellen. Um unnötige Geräusche herauszufiltern, wähle ich nach den Werten der Länge (Umfang) und der Fläche der Konturen.
Es wurde experimentell gezeigt, dass die Werte der interessierenden Schaltungen im Bereich von 360 bis 900 Einheiten liegen. Dieser Wert wird auf dem Bildschirm mit einer Diagonale von 15,6 Zoll und einer Auflösung von 1366 x 768 Pixel ausgewählt. Ferner können die angegebenen Werte der Konturen in Abhängigkeit von der Größe des Benutzerbildschirms berechnet werden, es gibt jedoch keine solche Verknüpfung in dem zu erstellenden Prototyp.
Der Hauptvorteil des gewählten Ansatzes zur Erkennung von Zellen besteht darin, dass es uns egal ist, wie das Raster aussieht und wie viele Zellen auf der Captcha-Seite angezeigt werden: 8, 9 oder 16.
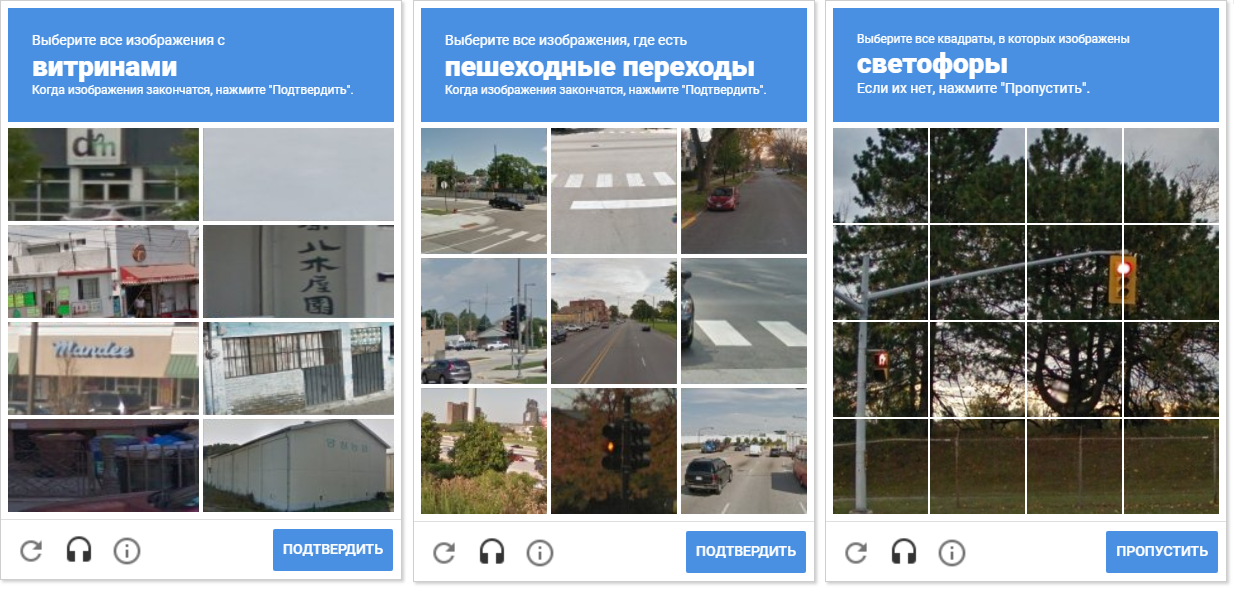 Das Bild zeigt eine Vielzahl von Captcha-Netzen. Bitte beachten Sie, dass der Abstand zwischen den Zellen unterschiedlich ist. Das Trennen von Zellen voneinander ermöglicht eine morphologische Kompression.
Das Bild zeigt eine Vielzahl von Captcha-Netzen. Bitte beachten Sie, dass der Abstand zwischen den Zellen unterschiedlich ist. Das Trennen von Zellen voneinander ermöglicht eine morphologische Kompression.Ein zusätzlicher Vorteil der Erkennung von Konturen besteht darin, dass wir mit OpenCV ihre Zentren erkennen können (sie werden benötigt, um die Bewegungskoordinaten und den Mausklick zu bestimmen).
Auswählen von Zellen zur Auswahl
Mit einem Array mit sauberen Konturen von CAPTCHA-Zellen ohne unnötige Rauschkreise können wir jede CAPTCHA-Zelle durchlaufen („Schaltung“ in der Terminologie „OpenCV“) und prüfen, ob sie sich mit der erkannten „Box“ des vom neuronalen Netzwerk empfangenen Objekts schneidet.
Um diese Tatsache festzustellen, wurde die Übertragung der erfassten "Box" auf eine Schaltung ähnlich den Zellen verwendet. Dieser Ansatz stellte sich jedoch als falsch heraus, da der Fall, in dem sich das Objekt innerhalb der Zelle befindet, nicht als Schnittpunkt betrachtet wird. Natürlich stachen solche Zellen im Captcha nicht hervor.
Das Problem wurde gelöst, indem der Umriss jeder Zelle (mit weißer Füllung) auf ein schwarzes Blatt neu gezeichnet wurde. In ähnlicher Weise wurde ein Binärbild eines Rahmens mit einem Objekt erhalten. Es stellt sich die Frage, wie nun die Tatsache des Schnittpunkts der Zelle mit dem schattierten Rahmen des Objekts festgestellt werden kann. Bei jeder Iteration eines Arrays mit Zellen wird eine Disjunktionsoperation (logisch oder) für zwei Binärbilder ausgeführt. Als Ergebnis erhalten wir ein neues Binärbild, in dem geschnittene Bereiche hervorgehoben werden. Das heißt, wenn es solche Bereiche gibt, schneiden sich die Zelle und der Rahmen des Objekts. Programmatisch kann eine solche Prüfung mit der Methode "
.any () " durchgeführt werden: Sie gibt "True" zurück, wenn das Array mindestens ein Element gleich eins hat, oder "False", wenn keine Einheiten vorhanden sind.
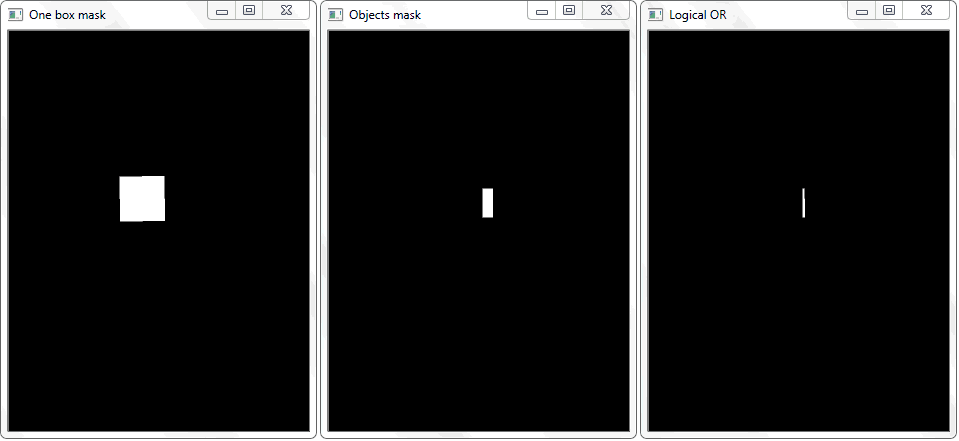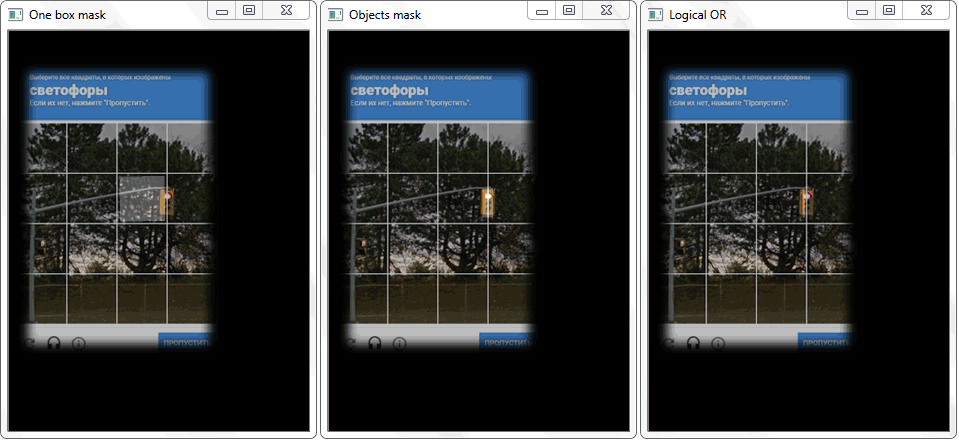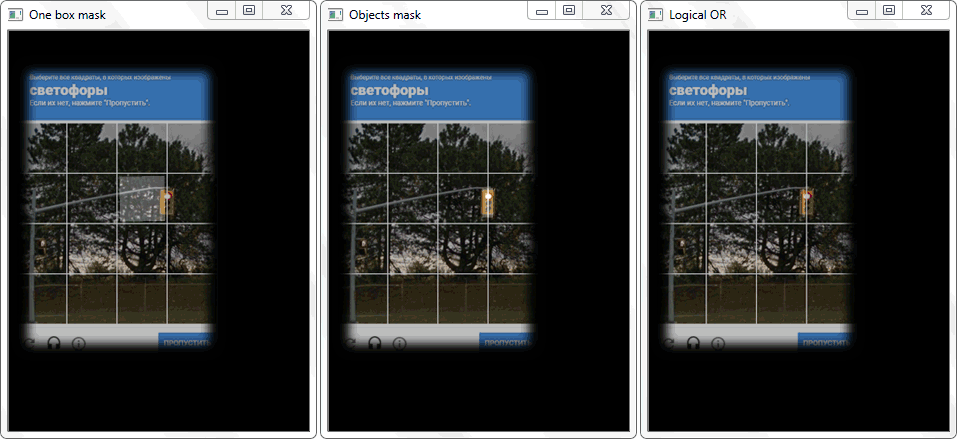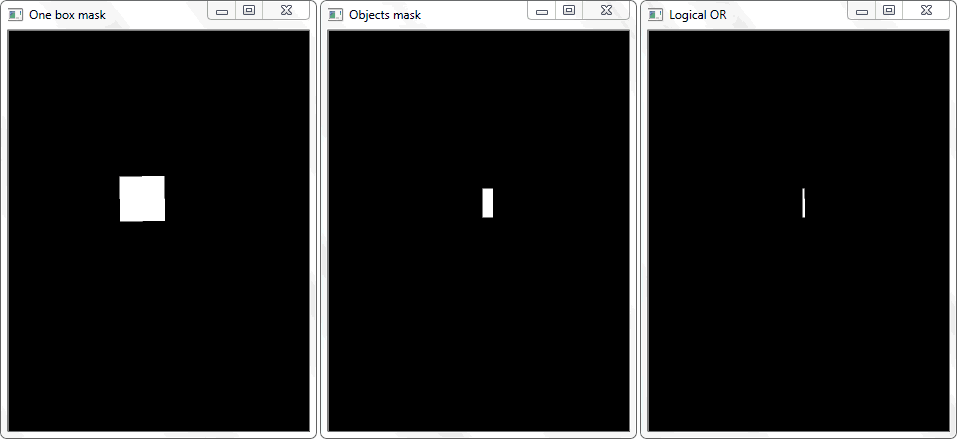 Die Funktion "any ()" für das Bild "Logical OR" gibt in diesem Fall true zurück und stellt dadurch die Tatsache des Schnittpunkts der Zelle mit dem Rahmenbereich des erkannten Objekts fest.
Die Funktion "any ()" für das Bild "Logical OR" gibt in diesem Fall true zurück und stellt dadurch die Tatsache des Schnittpunkts der Zelle mit dem Rahmenbereich des erkannten Objekts fest.Management
Die Cursorsteuerung in „Python“ wird dank des Moduls „win32api“ zur Verfügung gestellt (später stellte sich jedoch heraus, dass die bereits in das Projekt importierte „PyAutoGUI“ auch weiß, wie das geht). Das Drücken und Loslassen der linken Maustaste sowie das Bewegen des Cursors auf die gewünschten Koordinaten wird von den entsprechenden Funktionen des win32api-Moduls ausgeführt. Im Prototyp wurden sie jedoch in benutzerdefinierte Funktionen eingeschlossen, um eine visuelle Beobachtung der Cursorbewegung zu ermöglichen. Dies wirkt sich negativ auf die Leistung aus und wurde ausschließlich zu Demonstrationszwecken implementiert.
Während des Entwicklungsprozesses entstand die Idee, Zellen in zufälliger Reihenfolge auszuwählen. Es ist möglich, dass dies keinen praktischen Sinn ergibt (aus offensichtlichen Gründen gibt Google uns keine Kommentare und Beschreibungen der Mechanismen der Captcha-Operation), aber das Bewegen des Cursors auf chaotische Weise durch die Zellen macht mehr Spaß.
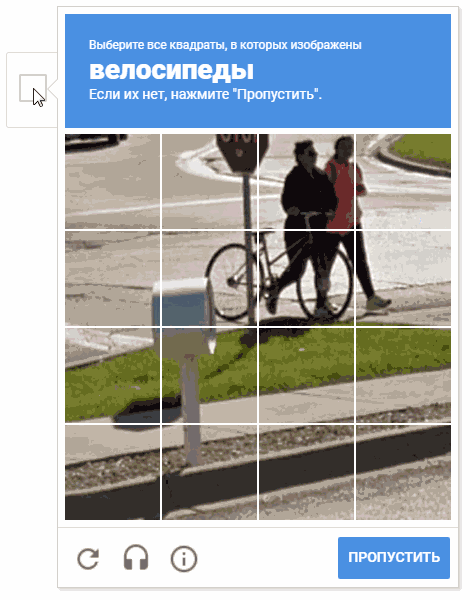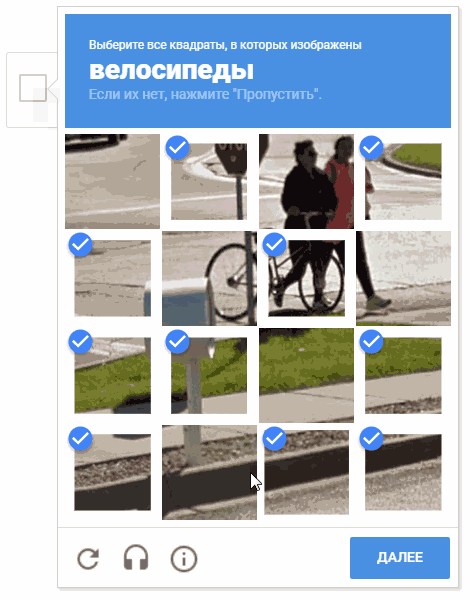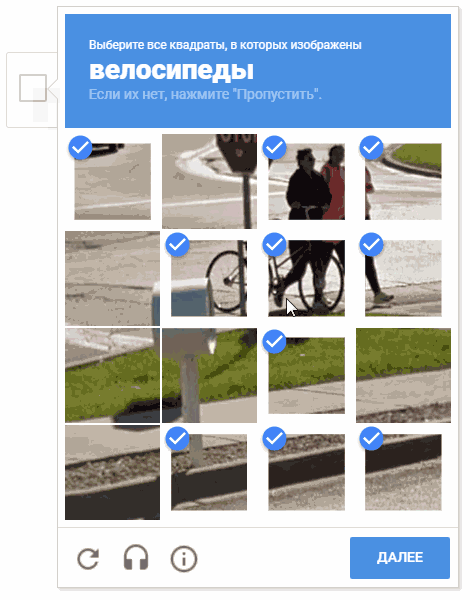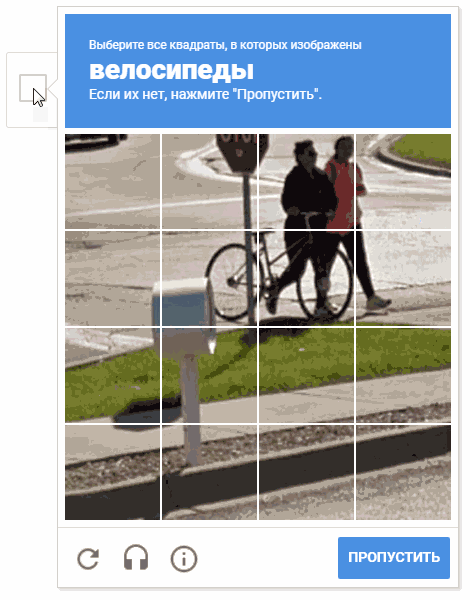 In der Animation lautet das Ergebnis "random.shuffle (boxsForSelect)".
In der Animation lautet das Ergebnis "random.shuffle (boxsForSelect)".Texterkennung
Um alle verfügbaren Entwicklungen zu einem Ganzen zusammenzufassen, ist eine weitere Verknüpfung erforderlich: eine Erkennungseinheit für die vom Captcha geforderte Klasse. Wir wissen bereits, wie verschiedene Objekte im Bild erkannt und unterschieden werden. Wir können auf beliebige Captcha-Zellen klicken, wissen jedoch nicht, auf welche Zellen wir klicken sollen. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, Text aus der Captcha-Überschrift zu erkennen. Zunächst habe ich versucht, die Texterkennung mit dem optischen Zeichenerkennungswerkzeug "
Tesseract-OCR " zu implementieren.
In den neuesten Versionen ist es möglich, Sprachpakete direkt im Installationsfenster zu installieren (zuvor wurde dies manuell durchgeführt). Nach der Installation und dem Import von Tesseract-OCR in mein Projekt habe ich versucht, den Text aus dem Captcha-Header zu erkennen.
Das Ergebnis hat mich leider überhaupt nicht beeindruckt. Ich entschied, dass der Text in der Kopfzeile fett hervorgehoben und aus einem bestimmten Grund zusammengeführt wurde, und versuchte daher, verschiedene Transformationen auf das Bild anzuwenden: Binärisierung, Verengung, Erweiterung, Unschärfe, Verzerrung und Größenänderung. Leider ergab dies kein gutes Ergebnis: Im besten Fall wurde nur ein Teil der Klassenbuchstaben bestimmt, und wenn das Ergebnis zufriedenstellend war, habe ich dieselben Transformationen angewendet, jedoch für andere Großbuchstaben (mit unterschiedlichem Text), und das Ergebnis stellte sich erneut als schlecht heraus.
 Das Erkennen der Tesseract-OCR-Kappen führte normalerweise zu unbefriedigenden Ergebnissen.
Das Erkennen der Tesseract-OCR-Kappen führte normalerweise zu unbefriedigenden Ergebnissen.Es ist unmöglich eindeutig zu sagen, dass „Tesseract-OCR“ Text nicht gut erkennt. Dies ist nicht der Fall: Das Tool kann mit anderen Bildern (nicht mit Captcha-Großbuchstaben) viel besser umgehen.
Ich habe mich für einen Drittanbieter entschieden, der eine API für die kostenlose Arbeit damit anbietet (Registrierung und Erhalt eines Schlüssels für eine E-Mail-Adresse sind erforderlich). Der Service hat ein Limit von 500 Erkennungen pro Tag, aber während des gesamten Entwicklungszeitraums sind keine Probleme mit Einschränkungen aufgetreten. Im Gegenteil: Ich habe das Originalbild des Headers beim Service eingereicht (ohne absolut irgendwelche Transformationen anzuwenden) und das Ergebnis hat mich angenehm beeindruckt.
Wörter aus dem Dienst wurden praktisch fehlerfrei zurückgegeben (normalerweise sogar solche, die in Kleinbuchstaben geschrieben wurden). Darüber hinaus kehrten sie in einem sehr praktischen Format zurück - unterbrochen durch Zeilenumbruchzeichen. In allen Bildern war ich nur an der zweiten Zeile interessiert, also habe ich direkt darauf zugegriffen. Dies konnte sich nur freuen, da ein solches Format mich von der Notwendigkeit befreite, eine Zeile vorzubereiten: Ich musste weder den Anfang noch das Ende des gesamten Textes abschneiden, „schneiden“, ersetzen, mit regulären Ausdrücken arbeiten und andere Operationen an der Zeile ausführen, um ein Wort hervorzuheben (und manchmal zwei!) - ein schöner Bonus!
text = serviceResponse['ParsedResults'][0]['ParsedText']
Ein Dienst, der Text erkannte, machte fast nie einen Fehler mit dem Klassennamen, aber ich entschied mich trotzdem, einen Teil des Klassennamens für einen möglichen Fehler zu belassen. Dies ist optional, aber ich habe festgestellt, dass „Tesseract-OCR“ in einigen Fällen das Ende eines Wortes ab der Mitte falsch erkannt hat. Darüber hinaus beseitigt dieser Ansatz den Anwendungsfehler bei einem langen Klassennamen oder einem Namen mit zwei Wörtern (in diesem Fall gibt der Dienst nicht 3, sondern 4 Zeilen zurück, und ich kann den vollständigen Namen der Klasse in der zweiten Zeile nicht finden).
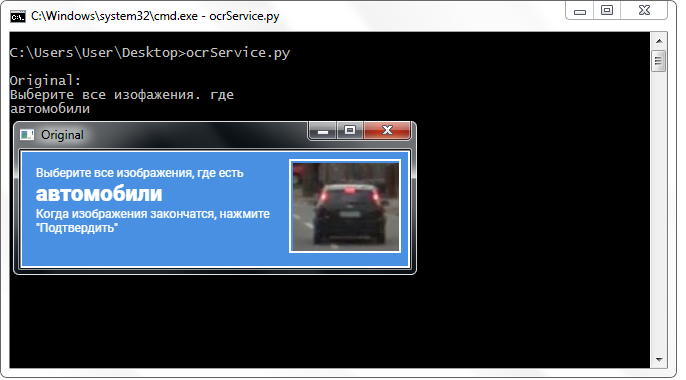 Ein Drittanbieter erkennt den Klassennamen gut, ohne das Image zu verändern.
Ein Drittanbieter erkennt den Klassennamen gut, ohne das Image zu verändern.Fusion
Das Abrufen von Text aus der Kopfzeile reicht nicht aus. Es muss mit den Bezeichnern der verfügbaren Modellklassen verglichen werden, da das neuronale Netzwerk im Klassenarray genau den Klassenbezeichner und nicht dessen Namen zurückgibt, wie es scheint. Beim Training des Modells wird in der Regel eine Datei erstellt, in der Klassennamen und deren Bezeichner verglichen werden (auch als „Label Map“ bezeichnet). Ich habe beschlossen, es einfacher zu machen und die Klassenkennungen manuell anzugeben, da für Captcha weiterhin Klassen in Russisch erforderlich sind (dies kann übrigens geändert werden):
if "" in query:
Alles, was oben beschrieben wurde, wird im Hauptzyklus des Programms reproduziert: Die Rahmen des Objekts, die Zelle, ihre Schnittpunkte werden bestimmt, der Cursor bewegt sich und klickt. Wenn ein Header erkannt wird, wird die Texterkennung durchgeführt. Wenn das neuronale Netzwerk die erforderliche Klasse nicht erkennen kann, wird eine willkürliche Verschiebung des Bildes bis zu fünfmal durchgeführt (dh die Eingabe in das neuronale Netzwerk wird geändert), und wenn die Erkennung immer noch nicht erfolgt, wird auf die Schaltfläche „Überspringen / Bestätigen“ geklickt (seine Position wird ähnlich erkannt Zellen und Kappen erkennen).
Wenn Sie das Captcha häufig lösen, können Sie das Bild beobachten, wenn die ausgewählte Zelle verschwindet und langsam und langsam eine neue an ihrer Stelle erscheint. Da der Prototyp so programmiert ist, dass er nach Auswahl aller Zellen sofort zur nächsten Seite wechselt, habe ich beschlossen, 3 Sekunden Pause einzulegen, um das Klicken auf die Schaltfläche „Weiter“ auszuschließen, ohne Objekte in der langsam erscheinenden Zelle zu erkennen.
Der Artikel wäre nicht vollständig, wenn er keine Beschreibung des Wichtigsten enthalten würde - ein Häkchen für die erfolgreiche Übergabe von Captcha. Ich entschied, dass ein einfacher
Vorlagenvergleich dies tun könnte. Es ist erwähnenswert, dass der Mustervergleich bei weitem nicht der beste Weg ist, Objekte zu erkennen. Zum Beispiel musste ich die Erkennungsempfindlichkeit auf „0,01“ einstellen, damit die Funktion keine Zecken mehr in allen sehen konnte, sondern sie sah, wenn es wirklich eine Zecke gab. Ebenso habe ich mit einem leeren Kontrollkästchen gehandelt, das den Benutzer trifft und von dem aus das Captcha startet (es gab keine Probleme mit der Empfindlichkeit).
Ergebnis
Das Ergebnis aller beschriebenen Aktionen war eine Anwendung, deren Leistung ich auf dem "
Toaster " getestet habe:
Es ist erwähnenswert, dass das Video nicht beim ersten Versuch aufgenommen wurde, da ich häufig mit der Notwendigkeit konfrontiert war, Klassen auszuwählen, die nicht im Modell enthalten sind (z. B. Fußgängerüberwege, Treppen oder Schaufenster).
"Google reCAPTCHA" gibt einen bestimmten Wert an die Site zurück und zeigt, wie "Sie sind ein Roboter", und Site-Administratoren können wiederum einen Schwellenwert für das Übergeben dieses Werts festlegen. Möglicherweise wurde am Toaster ein relativ niedriger Captcha-Schwellenwert festgelegt. Dies erklärt die ziemlich einfache Passage des Captcha durch das Programm, obwohl es zweimal falsch war und die Ampel auf der ersten Seite und der Hydrant auf der vierten Seite des Captcha nicht zu sehen waren.
Zusätzlich zum Toaster wurden Experimente auf der offiziellen
reCAPTCHA-Demoseite durchgeführt . Infolgedessen wurde festgestellt, dass es nach mehreren fehlerhaften Erkennungen (und Nichterkennungen) selbst für eine Person äußerst schwierig wird, ein Captcha zu erhalten: Neue Klassen sind erforderlich (wie Traktoren und Palmen), Zellen ohne Objekte erscheinen in den Proben (fast eintönige Farben) und die Anzahl der Seiten nimmt dramatisch zu. durchgehen.
Dies machte sich besonders bemerkbar, als ich mich entschied, auf zufällige Zellen zu klicken, falls Objekte nicht erkannt wurden (aufgrund ihrer Abwesenheit im Modell). Daher können wir mit Sicherheit sagen, dass zufällige Klicks nicht zu einer Lösung des Problems führen. Um eine solche „Blockierung“ durch den Prüfer zu beseitigen, haben wir die Internetverbindung wieder hergestellt und die Browserdaten gelöscht, da es unmöglich wurde, einen solchen Test zu bestehen - es war fast endlos!
 Wenn Sie an Ihrer Menschlichkeit zweifeln, ist ein solches Ergebnis möglich.
Wenn Sie an Ihrer Menschlichkeit zweifeln, ist ein solches Ergebnis möglich.Entwicklung
Wenn der Artikel und die Anwendung das Interesse des Lesers wecken, werde ich die Implementierung, Tests und die weitere Beschreibung gerne in einer detaillierteren Form fortsetzen.
Es geht darum, Klassen zu finden, die nicht Teil des aktuellen Netzwerks sind. Dies wird die Effizienz der Anwendung erheblich verbessern. Im Moment ist es dringend erforderlich, zumindest Klassen wie Fußgängerüberwege, Schaufenster und Schornsteine zu erkennen - ich werde Ihnen sagen, wie Sie das Modell umschulten. Während der Entwicklung habe ich eine kurze Liste der häufigsten Klassen erstellt:
- Fußgängerüberwege;
- Hydranten;
- Schaufenster
- Schornsteine;
- Autos;
- Busse
- Ampeln;
- Fahrräder
- Verkehrsmittel;
- Treppen
- Zeichen.
Durch die gleichzeitige Verwendung mehrerer Modelle kann die Qualität der Objekterkennung verbessert werden. Dies kann die Leistung beeinträchtigen, aber die Genauigkeit erhöhen.
Eine andere Möglichkeit, die Qualität der Erkennung von Objekten zu verbessern, besteht darin, die Bildeingabe in das neuronale Netzwerk zu ändern: Im Video können Sie sehen, dass ich, wenn Objekte nicht erkannt werden, mehrmals eine willkürliche Bildverschiebung durchführe (innerhalb von 10 Pixeln horizontal und vertikal). Mit dieser Operation können Sie häufig Objekte anzeigen, die zuvor vorhanden waren wurden nicht erkannt.
Eine Vergrößerung des Bildes von einem kleinen auf ein großes Quadrat (bis zu 300 x 300 Pixel) führt auch zur Erkennung nicht erkannter Objekte.
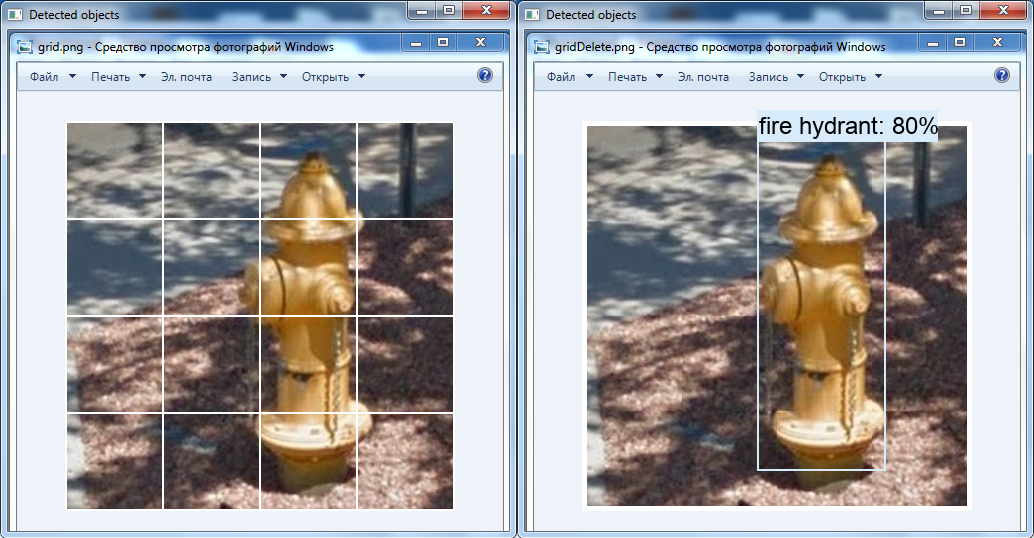
 Links wurden keine Objekte gefunden: Originalquadrat mit 100 Pixel Seite. Rechts wird ein Bus erkannt: ein vergrößertes Quadrat mit einer Größe von bis zu 300 x 300 Pixel.
Links wurden keine Objekte gefunden: Originalquadrat mit 100 Pixel Seite. Rechts wird ein Bus erkannt: ein vergrößertes Quadrat mit einer Größe von bis zu 300 x 300 Pixel.Eine weitere interessante Transformation ist das Entfernen des weißen Gitters über dem Bild mit OpenCV-Tools: Möglicherweise wurde der Hydrant aus diesem Grund im Video nicht erkannt (diese Klasse ist im neuronalen Netzwerk vorhanden).
 Links ist das Originalbild und rechts das Bild, das im Grafikeditor geändert wurde: Das Raster wird gelöscht, die Zellen werden ineinander verschoben.
Links ist das Originalbild und rechts das Bild, das im Grafikeditor geändert wurde: Das Raster wird gelöscht, die Zellen werden ineinander verschoben.Zusammenfassung
Mit diesem Artikel wollte ich Ihnen sagen, dass Captcha wahrscheinlich nicht der beste Schutz gegen Bots ist, und es ist durchaus möglich, dass in naher Zukunft neue Schutzmaßnahmen gegen automatisierte Systeme erforderlich sein werden.
Der entwickelte Prototyp zeigt, dass es mit den erforderlichen Klassen im neuronalen Netzwerkmodell und der Anwendung von Transformationen über Bilder möglich ist, einen Prozess zu automatisieren, der nicht automatisiert werden sollte, selbst wenn er sich noch in einem unfertigen Zustand befindet.
Ich möchte Google auch darauf aufmerksam machen, dass es neben der in diesem Artikel beschriebenen Methode zur Umgehung von Captcha auch eine
andere Möglichkeit gibt , ein Audio-Sample zu
transkribieren . Meiner Meinung nach ist es jetzt notwendig, Maßnahmen zur Verbesserung der Qualität von Softwareprodukten und Algorithmen gegen Roboter zu ergreifen.
Aus dem Inhalt und dem Wesen des Materials geht hervor, dass ich Google und insbesondere reCAPTCHA nicht mag, aber dies ist weit davon entfernt, und wenn es eine nächste Implementierung gibt, werde ich Ihnen sagen, warum.
Entwickelt und demonstriert, um die Bildung zu verbessern und Methoden zur Gewährleistung der Informationssicherheit zu verbessern.
Vielen Dank für Ihre Aufmerksamkeit.