Die Geschichte von VKontakte ist auf Wikipedia, wurde von Pavel selbst erzählt. Es scheint, dass jeder sie bereits kennt. Pavel
sprach bereits 2010 über das Innere, die Architektur und das Design der Website in HighLoad ++. Seitdem sind viele Server durchgesickert, daher werden wir die Informationen aktualisieren: Wir sezieren, ziehen die Innenseiten heraus, wiegen - wir betrachten das VK-Gerät aus technischer Sicht.
 Alexey Akulovich
Alexey Akulovich (
AterCattus ) ist ein Backend-Entwickler im VKontakte-Team. Das Transkript dieses Berichts ist eine kollektive Antwort auf häufig gestellte Fragen zum Betrieb der Plattform, der Infrastruktur, der Server und der Interaktion zwischen ihnen, jedoch nicht zur Entwicklung, nämlich
zur Hardware . Separat - über Datenbanken und was VK an ihrer Stelle hat, über das Sammeln von Protokollen und die Überwachung des gesamten Projekts als Ganzes. Details unter dem Schnitt.
Seit mehr als vier Jahren erledige ich alle Arten von Aufgaben im Zusammenhang mit dem Backend.
- Herunterladen, Speichern, Verarbeiten, Verteilen von Medien: Video, Live-Streaming, Audio, Fotos, Dokumente.
- Infrastruktur, Plattform, Entwicklerüberwachung, Protokolle, regionale Caches, CDN, proprietäres RPC-Protokoll.
- Integration mit externen Diensten: Push-Mailing, Analyse externer Links, RSS-Feed.
- Helfen Sie Kollegen bei verschiedenen Fragen, um Antworten zu erhalten, auf die Sie in einen unbekannten Code eintauchen müssen.
Während dieser Zeit war ich an vielen Komponenten der Website beteiligt. Ich möchte diese Erfahrung teilen.
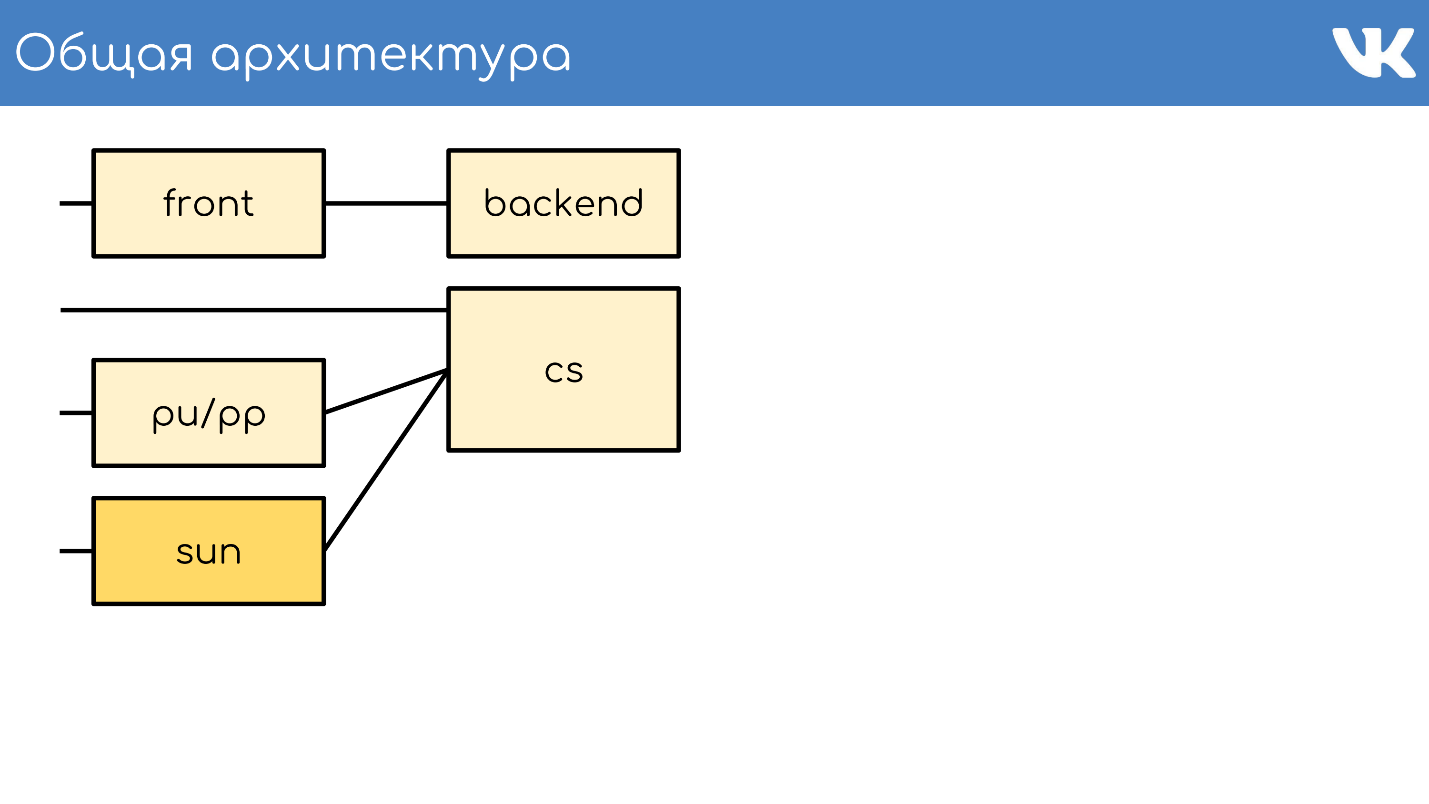
Allgemeine Architektur
Alles beginnt wie gewohnt mit einem Server oder einer Gruppe von Servern, die Anforderungen annehmen.
Frontserver
Der Frontserver akzeptiert Anforderungen über HTTPS, RTMP und WSS.
HTTPS sind Anfragen für die Haupt- und mobilen Webversionen der Website: vk.com und m.vk.com sowie für andere offizielle und inoffizielle Clients unserer API: mobile Clients, Instant Messenger. Wir haben einen Empfang von
RTMP- Verkehr für Live-Übertragungen mit separaten Frontservern und
WSS- Verbindungen für die Streaming-API.
Für HTTPS und WSS ist
nginx auf den Servern installiert. Für RTMP-Sendungen haben wir kürzlich auf unsere eigene
Kive- Lösung
umgestellt , die jedoch den Rahmen des Berichts
sprengt . Aus Gründen der Fehlertoleranz geben diese Server gemeinsame IP-Adressen bekannt und fungieren als Gruppen, damit bei einem Problem auf einem der Server Benutzeranforderungen nicht verloren gehen. Bei HTTPS und WSS verschlüsseln dieselben Server den Datenverkehr, um einen Teil der CPU-Last für sich selbst zu übernehmen.
Außerdem werden wir nicht über WSS und RTMP sprechen, sondern nur über Standard-HTTPS-Anforderungen, die normalerweise mit einem Webprojekt verbunden sind.
Backend
Hinter der Front befinden sich normalerweise die Backend-Server. Sie verarbeiten Anforderungen, die der Frontserver von Clients empfängt.
Dies sind
kPHP-Server, auf denen der HTTP-Dämon ausgeführt wird, da HTTPS bereits entschlüsselt ist. kPHP ist ein Server, der nach dem
Prefork-Modell arbeitet : Er startet den Master-Prozess, eine Reihe von
untergeordneten Prozessen, übergibt ihnen Listening-Sockets und sie verarbeiten ihre Anforderungen. Gleichzeitig werden Prozesse nicht zwischen jeder Anforderung des Benutzers neu gestartet, sondern setzen einfach ihren Status auf den anfänglichen Nullwertstatus zurück - Anforderung für Anforderung, anstatt neu zu starten.
Lastverteilung
Alle unsere Backends sind kein riesiger Pool von Maschinen, die jede Anfrage bearbeiten können. Wir
teilen sie
in separate Gruppen ein : Allgemein, Mobil, API, Video, Inszenierung ... Das Problem auf einer separaten Gruppe von Computern betrifft nicht alle anderen. Bei Problemen mit dem Video weiß der Benutzer, der Musik hört, nicht einmal über die Probleme Bescheid. An welches Backend die Anfrage gesendet werden soll, wird von nginx auf der Vorderseite in der Konfiguration gelöst.
Erfassung und Neuausrichtung von Metriken
Um zu verstehen, wie viele Autos Sie in jeder Gruppe benötigen, verlassen wir
uns nicht auf QPS . Die Backends sind unterschiedlich, sie haben unterschiedliche Anforderungen, jede Anforderung hat unterschiedliche Komplexität bei der QPS-Berechnung. Daher verwenden wir das
Konzept der Auslastung des gesamten Servers - der CPU und der Leistung .
Wir haben Tausende solcher Server. Die kPHP-Gruppe wird auf jedem physischen Server ausgeführt, um alle Kernel zu verwenden (da kPHP Single-Threaded ist).
Inhaltsserver
CS oder Content Server ist Speicher . CS ist ein Server, der Dateien speichert und auch hochgeladene Dateien verarbeitet. Dabei handelt es sich um alle Arten von synchronen Hintergrundaufgaben, die das Haupt-Web-Frontend für ihn bereitstellt.
Wir haben Zehntausende von physischen Servern, auf denen Dateien gespeichert sind. Benutzer lieben es, Dateien hochzuladen, und wir lieben es, sie zu speichern und zu teilen. Einige dieser Server werden von speziellen Pu / PP-Servern geschlossen.
pu / pp
Wenn Sie die Registerkarte Netzwerk in VK geöffnet haben, haben Sie pu / pp gesehen.

Was ist pu / pp? Wenn wir einen Server nach dem anderen schließen, gibt es zwei Möglichkeiten, eine Datei hochzuladen und auf einen Server herunterzuladen, der geschlossen wurde:
direkt über
http://cs100500.userapi.com/path oder
über einen Zwischenserver -
http://pu.vk.com/c100500/path .
Pu ist der historische Name für das Hochladen von Fotos und pp ist der Foto-Proxy . Das heißt, ein Server zum Hochladen von Fotos und ein anderer zum Geben. Jetzt werden nicht nur Fotos geladen, sondern der Name bleibt erhalten.
Diese Server
beenden HTTPS-Sitzungen , um die Prozessorlast aus dem Speicher zu entfernen. Da Benutzerdateien auf diesen Servern verarbeitet werden, ist es umso besser, je weniger vertrauliche Informationen auf diesen Computern gespeichert sind. Zum Beispiel HTTPS-Verschlüsselungsschlüssel.
Da die Maschinen von unseren anderen Maschinen geschlossen werden, können wir es uns leisten, ihnen keine „weißen“ externen IPs und keine
„grauen“ IPs zu
geben . Wir haben also im IP-Pool gespeichert und garantiert, dass die Computer vor dem Zugriff von außen geschützt sind - es gibt einfach keine IP, um darauf zuzugreifen.
Fehlertoleranz durch gemeinsam genutzte IP . In Bezug auf die Fehlertoleranz funktioniert das Schema auf die gleiche Weise: Mehrere physische Server haben eine gemeinsame physische IP, und das Eisenstück vor ihnen wählt aus, wohin die Anforderung gesendet werden soll. Später werde ich über andere Optionen sprechen.
Der umstrittene Punkt ist, dass in diesem Fall der
Client weniger Verbindungen hat . Wenn auf mehreren Computern dieselbe IP-Adresse vorhanden ist - mit demselben Host: pu.vk.com oder pp.vk.com - ist die Anzahl der gleichzeitigen Anforderungen an einen Host im Client-Browser begrenzt. Aber während des allgegenwärtigen HTTP / 2 glaube ich, dass dies nicht mehr der Fall ist.
Das offensichtliche Minus des Schemas ist, dass Sie den
gesamten Datenverkehr , der zum Speicher gelangt, über einen anderen Server
pumpen müssen . Da wir den Verkehr durch Autos pumpen, können wir noch nicht auf die gleiche Weise starken Verkehr pumpen, z. B. Video. Wir übertragen es direkt - eine separate direkte Verbindung für einzelne Repositories speziell für Video. Wir übertragen leichtere Inhalte über einen Proxy.
Vor nicht allzu langer Zeit haben wir eine verbesserte Version von Proxy. Jetzt werde ich Ihnen sagen, wie sie sich von gewöhnlichen unterscheiden und warum dies notwendig ist.
Sonne
Im September 2017 entließ Oracle, das zuvor Sun gekauft hatte,
eine große Anzahl von Sun-Mitarbeitern . Wir können sagen, dass das Unternehmen zu diesem Zeitpunkt aufgehört hat zu existieren. Unsere Administratoren wählten einen Namen für das neue System und beschlossen, diesem Unternehmen Tribut und Respekt zu zollen. Sie nannten das neue Sun-System. Unter uns nennen wir es einfach "Sonnenschein".
Pp hatte ein paar Probleme.
Eine IP pro Gruppe ist ein ineffizienter Cache . Mehrere physische Server haben eine gemeinsame IP-Adresse, und es gibt keine Möglichkeit zu steuern, an welchen Server die Anforderung gesendet wird. Wenn also verschiedene Benutzer für dieselbe Datei kommen und sich auf diesen Servern ein Cache befindet, wird die Datei im Cache jedes Servers abgelegt. Dies ist ein sehr ineffizientes Schema, aber es konnte nichts unternommen werden.
Infolgedessen können
wir keine Inhalte sharden , da wir keinen bestimmten Server für diese Gruppe auswählen können - sie haben eine gemeinsame IP. Aus internen Gründen hatten wir
auch nicht die Möglichkeit, solche Server in den Regionen zu platzieren . Sie standen nur in St. Petersburg.
Mit den Sonnen haben wir das Auswahlsystem geändert. Jetzt haben wir
Anycast-Routing : dynamisches Routing, Anycast, Self-Check-Daemon. Jeder Server hat seine eigene IP, gleichzeitig aber ein gemeinsames Subnetz. Alles ist so konfiguriert, dass bei Verlust eines Servers der Datenverkehr automatisch auf andere Server derselben Gruppe verteilt wird. Jetzt ist es möglich, einen bestimmten Server auszuwählen,
es gibt kein übermäßiges Caching und die Zuverlässigkeit wird nicht beeinträchtigt.
Gewichtsunterstützung . Jetzt können wir es uns leisten, Autos mit unterschiedlichen Kapazitäten nach Bedarf zu platzieren und auch bei vorübergehenden Problemen das Gewicht der arbeitenden „Sonnen“ zu ändern, um die Belastung für sie zu verringern, damit sie „ruhen“ und wieder arbeiten.
Sharding nach Inhalts-ID . Das Lustige am Sharding ist, dass wir normalerweise Inhalte sharden, sodass verschiedene Benutzer derselben Datei durch dieselbe „Sonne“ folgen, sodass sie einen gemeinsamen Cache haben.
Wir haben kürzlich die Clover-App gestartet. Dies ist ein Online-Live-Quiz, bei dem der Präsentator Fragen stellt und Benutzer in Echtzeit antworten, indem sie Optionen auswählen. Die Anwendung verfügt über einen Chat, in dem Benutzer überfluten können.
Mehr als 100.000 Menschen können gleichzeitig eine Verbindung zur Sendung herstellen. Sie alle schreiben Nachrichten, die an alle Teilnehmer gesendet werden, zusammen mit der Nachricht kommt ein weiterer Avatar. Wenn 100.000 Menschen für einen Avatar in einer „Sonne“ kommen, kann er manchmal über eine Wolke rollen.
Um Ausbrüchen von Anfragen aus derselben Datei standzuhalten, fügen wir für eine Art von Inhalt ein dummes Schema hinzu, das Dateien über alle verfügbaren „Sonnen“ in der Region verteilt.
Sonne drinnen
Reverse Proxy zu Nginx, Cache in RAM oder Optane / NVMe Fast Disks. Beispiel:
http://sun4-2.userapi.com/c100500/path - Link zur "Sonne", die sich in der vierten Region befindet, der zweiten Servergruppe. Es schließt die Pfaddatei, die physisch auf dem Server 100500 liegt.
Cache
Wir fügen unserem Architekturschema einen weiteren Knoten hinzu - die Caching-Umgebung.

Unten sehen Sie das Layout der
regionalen Caches , von denen es ungefähr 20 gibt. Dies sind die Orte, an denen sich genau die Caches und "Sonnen" befinden, die den Verkehr durch sich selbst zwischenspeichern können.

Dies ist das Zwischenspeichern von Multimedia-Inhalten. Benutzerdaten werden hier nicht gespeichert - nur Musik, Videos, Fotos.
Um die Region des Benutzers zu bestimmen,
erfassen wir
die in den Regionen angekündigten BGP-Netzwerkpräfixe . Im Fall eines Fallbacks haben wir immer noch eine Analyse der Geoip-Basis, wenn wir IP nicht anhand von Präfixen finden konnten.
Basierend auf der IP des Benutzers bestimmen wir die Region . Im Code können wir eine oder mehrere Regionen des Benutzers betrachten - die Punkte, denen er geografisch am nächsten ist.
Wie funktioniert es
Wir betrachten die Beliebtheit von Dateien nach Regionen . Es gibt eine regionale Cache-Nummer, in der sich der Benutzer befindet, und eine Dateikennung. Wir nehmen dieses Paar und erhöhen die Bewertung für jeden Download.
Gleichzeitig kommen von Zeit zu Zeit Dämonen - Dienste in den Regionen - zur API und sagen: "Ich habe so und so einen Cache, gib mir eine Liste der beliebtesten Dateien in meiner Region, die ich noch nicht habe." Die API gibt eine Reihe von Dateien nach Bewertung sortiert aus, der Daemon pumpt sie aus, überträgt sie in die Regionen und gibt ihnen Dateien von dort. Dies ist ein grundlegender Unterschied zwischen pu / pp und Sun gegenüber Caches: Sie geben die Datei sofort durch sich selbst weiter, auch wenn die Datei nicht im Cache vorhanden ist, und der Cache pumpt die Datei zuerst in sich selbst und beginnt dann, sie weiterzugeben.
Gleichzeitig bringen wir
Inhalte näher an die Benutzer heran und verschmieren die Netzwerklast. Beispielsweise verteilen wir nur aus dem Moskauer Cache während der Stoßzeiten mehr als 1 Tbit / s.
Es gibt jedoch Probleme -
Cache-Server sind nicht aus Gummi . Für sehr beliebte Inhalte gibt es manchmal nicht genügend Netzwerk auf einem separaten Server. Wir haben 40-50 Gbit / s-Cache-Server, aber es gibt Inhalte, die einen solchen Kanal vollständig verstopfen. Wir bemühen uns, die Speicherung von mehr als einer Kopie beliebter Dateien in der Region zu realisieren. Ich hoffe, dass wir es bis Ende des Jahres realisieren werden.
Wir haben die allgemeine Architektur untersucht.
- Frontserver, die Anforderungen annehmen.
- Backends, die Anforderungen verarbeiten.
- Tresore, die von zwei Arten von Proxys geschlossen werden.
- Regionale Caches.
Was fehlt in diesem Schema? Natürlich die Datenbanken, in denen wir Daten speichern.
Datenbanken oder Engines
Wir nennen sie keine Datenbanken, sondern Engines-Engines, weil wir im allgemein akzeptierten Sinne praktisch keine Datenbanken haben.
 Dies ist eine notwendige Maßnahme
Dies ist eine notwendige Maßnahme . Dies geschah, weil in den Jahren 2008-2009, als VK einen explosionsartigen Anstieg der Popularität verzeichnete, das Projekt vollständig auf MySQL und Memcache funktionierte und es Probleme gab. MySQL fiel gern und ruinierte Dateien, danach stieg es nicht mehr an, und Memcache verschlechterte sich allmählich in der Leistung und musste neu gestartet werden.
Es stellte sich heraus, dass es in dem Projekt, das immer beliebter wurde, einen dauerhaften Speicher gab, der die Daten beschädigte, und einen Cache, der langsamer wurde. Unter solchen Bedingungen ist es schwierig, ein wachsendes Projekt zu entwickeln. Es wurde beschlossen, die kritischen Dinge, auf denen das Projekt beruhte, auf ihren eigenen Motorrädern neu zu schreiben.
Die Lösung war erfolgreich . Die Möglichkeit dazu bestand ebenso wie ein dringender Bedarf, da zu diesem Zeitpunkt keine anderen Skalierungsmethoden existierten. Es gab keinen Haufen Basen, NoSQL gab es noch nicht, es gab nur MySQL, Memcache, PostrgreSQL - und das ist alles.
Universalbetrieb . Die Entwicklung wurde von unserem Team von C-Entwicklern geleitet, und alles wurde auf die gleiche Weise durchgeführt. Unabhängig von der Engine gab es überall ungefähr das gleiche Format der auf die Festplatte geschriebenen Dateien, die gleichen Startparameter, die Signale wurden gleich verarbeitet und verhielten sich bei Randbedingungen und Problemen gleich. Mit dem Wachstum der Engines ist es für Administratoren bequem, das System zu bedienen - es gibt keinen Zoo, der gewartet werden muss, und es muss gelernt werden, jede neue Basis von Drittanbietern erneut zu bedienen, wodurch es möglich wurde, ihre Anzahl schnell und bequem zu erhöhen.
Motortypen
Das Team hat einige Motoren geschrieben. Hier sind nur einige davon: Freund, Hinweise, Bild, IPdb, Briefe, Listen, Protokolle, Memcached, Meowdb, Nachrichten, Nostradamus, Foto, Wiedergabelisten, PMemcached, Sandbox, Suche, Speicherung, Likes, Aufgaben, ...
Für jede Aufgabe, die eine bestimmte Datenstruktur erfordert oder atypische Anforderungen verarbeitet, schreibt das C-Team eine neue Engine. Warum nicht.
Wir haben eine separate
Memcached- Engine, die der üblichen ähnelt, aber ein paar Brötchen enthält und die nicht langsamer wird. Nicht ClickHouse, funktioniert aber auch. Es gibt einen separaten
pmemcached - es handelt sich um einen
dauerhaften memcached , der Daten auch auf der Festplatte speichern kann und mehr als in den RAM gelangt, um beim Neustart keine Daten zu verlieren. Es gibt verschiedene Engines für einzelne Aufgaben: Warteschlangen, Listen, Sets - alles, was unser Projekt benötigt.
Cluster
Aus Sicht des Codes besteht keine Notwendigkeit, sich Engines oder Datenbanken als bestimmte Prozesse, Entitäten oder Instanzen vorzustellen. Der Code funktioniert speziell mit Clustern mit Gruppen von Engines -
ein Typ pro Cluster . Angenommen, es gibt einen zwischengespeicherten Cluster - es ist nur eine Gruppe von Maschinen.
Der Code muss den physischen Standort, die Größe und die Anzahl der Server nicht kennen. Er geht mit einer Kennung zum Cluster.
Damit dies funktioniert, müssen Sie eine weitere Entität hinzufügen, die sich zwischen dem Code und den Engines befindet - den
Proxy .
RPC-Proxy
Proxy - ein
Verbindungsbus , der fast den gesamten Standort betreibt. Gleichzeitig haben wir
keine Serviceerkennung - stattdessen gibt es eine Konfiguration dieses Proxys, die den Speicherort aller Cluster und aller Shards dieses Clusters kennt. Dies wird von Admins durchgeführt.
Programmierer kümmern sich im Allgemeinen nicht darum, wie viel, wo und was es kostet - sie gehen einfach zum Cluster. Das erlaubt uns viel. Nach Erhalt der Anfrage leitet der Proxy die Anfrage um und weiß, wo - er bestimmt dies.

Gleichzeitig ist Proxy ein Schutzpunkt gegen Dienstausfälle. Wenn eine Engine langsamer wird oder abstürzt, versteht der Proxy dies und reagiert dementsprechend auf die Client-Seite. Auf diese Weise können Sie das Zeitlimit entfernen. Der Code wartet nicht auf die Antwort der Engine, versteht jedoch, dass dies nicht funktioniert und Sie sich anders verhalten müssen. Der Code sollte darauf vorbereitet sein, dass die Datenbanken nicht immer funktionieren.
Spezifische Implementierungen
Manchmal wollen wir immer noch eine kundenspezifische Lösung als Motor. Gleichzeitig wurde beschlossen, nicht unseren vorgefertigten RPC-Proxy zu verwenden, der speziell für unsere Engines erstellt wurde, sondern einen separaten Proxy für die Aufgabe zu erstellen.
Für MySQL, das wir an einigen Stellen noch haben, verwenden wir db-proxy und für ClickHouse -
Kittenhouse .
Das funktioniert insgesamt so. Es gibt einen Server, auf dem kPHP, Go und Python ausgeführt werden - im Allgemeinen jeder Code, der unserem RPC-Protokoll folgen kann. Der Code wird lokal an den RPC-Proxy gesendet. Auf jedem Server, auf dem Code vorhanden ist, wird ein eigener lokaler Proxy gestartet. Auf Anfrage versteht der Proxy, wohin er gehen soll.
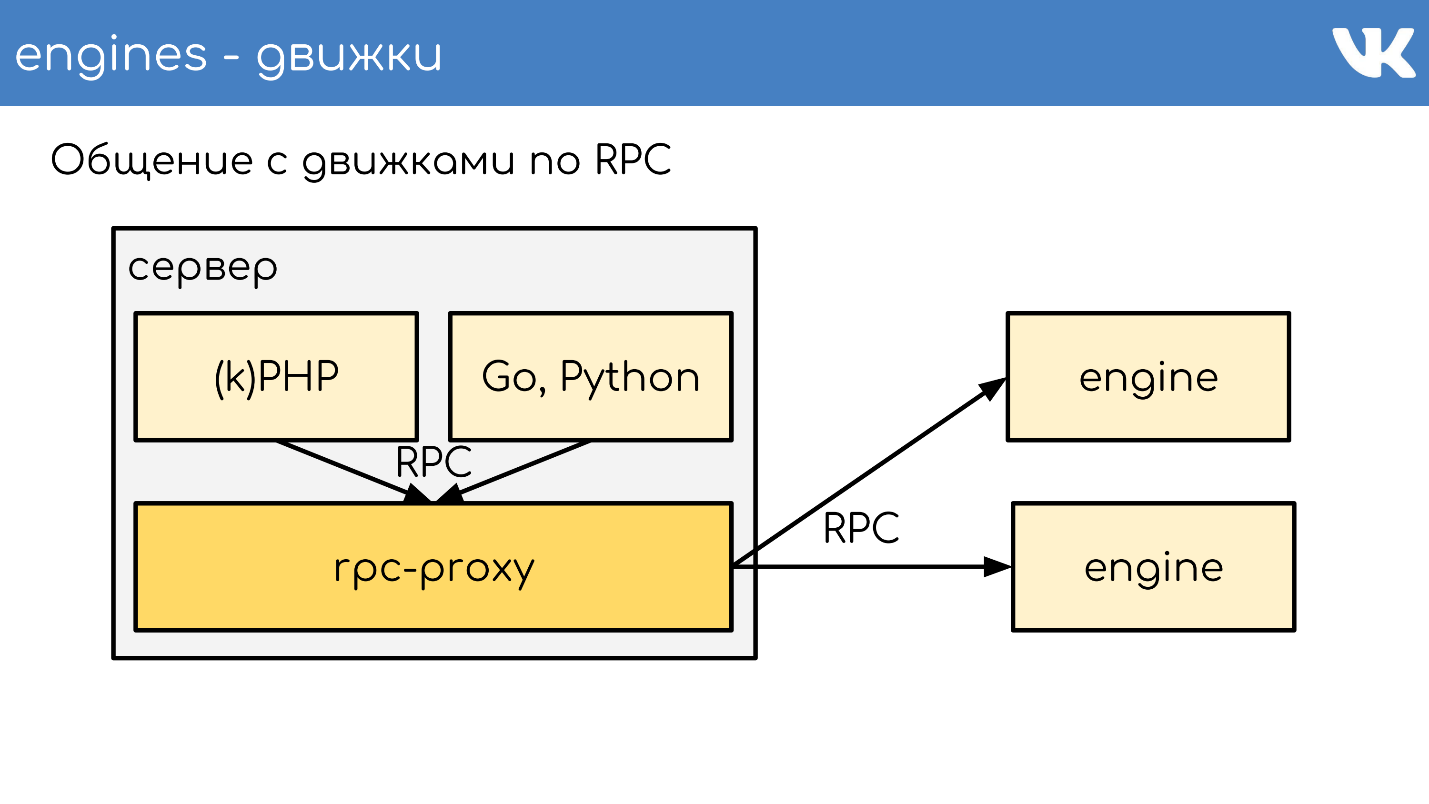
Wenn eine Engine zu einer anderen wechseln möchte, auch wenn es sich um einen Nachbarn handelt, wird ein Proxy verwendet, da sich der Nachbar in einem anderen Rechenzentrum befinden kann. Der Motor sollte nicht daran gebunden sein, den Standort von etwas anderem als sich selbst zu kennen - wir haben diese Standardlösung. Aber natürlich gibt es Ausnahmen :)
Ein Beispiel für ein TL-Schema, nach dem alle Motoren arbeiten.
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long;
Dies ist ein binäres Protokoll, dessen nächstgelegenes Analogon
protobuf ist. Das Schema beschreibt im Voraus optionale Felder, komplexe Typen - Erweiterungen integrierter Skalare und Abfragen. Alles funktioniert nach diesem Protokoll.
RPC über TL über TCP / UDP ... UDP?
Wir haben ein RPC-Protokoll zum Abfragen der Engine, das über dem TL-Schema ausgeführt wird. Dies alles funktioniert über die TCP / UDP-Verbindung. TCP - es ist klar, warum wir oft nach UDP gefragt werden.
UDP hilft,
das Problem einer großen Anzahl von Verbindungen zwischen Servern zu
vermeiden . Wenn auf jedem Server ein RPC-Proxy vorhanden ist und dieser im Allgemeinen an eine beliebige Engine gesendet werden kann, erhalten Sie Zehntausende von TCP-Verbindungen zum Server. Es gibt eine Last, aber sie ist nutzlos. Bei UDP ist dies kein Problem.
Kein redundanter TCP-Handshake . Dies ist ein typisches Problem: Wenn eine neue Engine oder ein neuer Server gestartet wird, werden viele TCP-Verbindungen gleichzeitig hergestellt. Bei kleinen, leichten Anforderungen, z. B. UDP-Nutzdaten, besteht die gesamte Kommunikation zwischen dem Code und der Engine aus
zwei UDP-Paketen: eines fliegt in die eine Richtung, das andere in die andere. Eine Hin- und Rückfahrt - und der Code erhielt eine Antwort vom Motor ohne Handschlag.
Ja, alles funktioniert nur
mit einem sehr geringen Prozentsatz des Paketverlusts . Das Protokoll unterstützt Neuübertragungen und Zeitüberschreitungen. Wenn wir jedoch viel verlieren, erhalten wir praktisch TCP, was nicht rentabel ist. Fahren Sie über die Ozeane kein UDP.
Wir haben Tausende solcher Server, und das gleiche Schema gibt es: Auf jedem physischen Server befindet sich ein Paket von Engines. Grundsätzlich sind sie Single-Threaded, um so schnell wie möglich ohne Blockierung zu arbeiten, und werden als Single-Threaded-Lösungen zerkleinert. Gleichzeitig haben wir nichts zuverlässigeres als diese Engines, und der dauerhaften Datenspeicherung wird viel Aufmerksamkeit geschenkt.
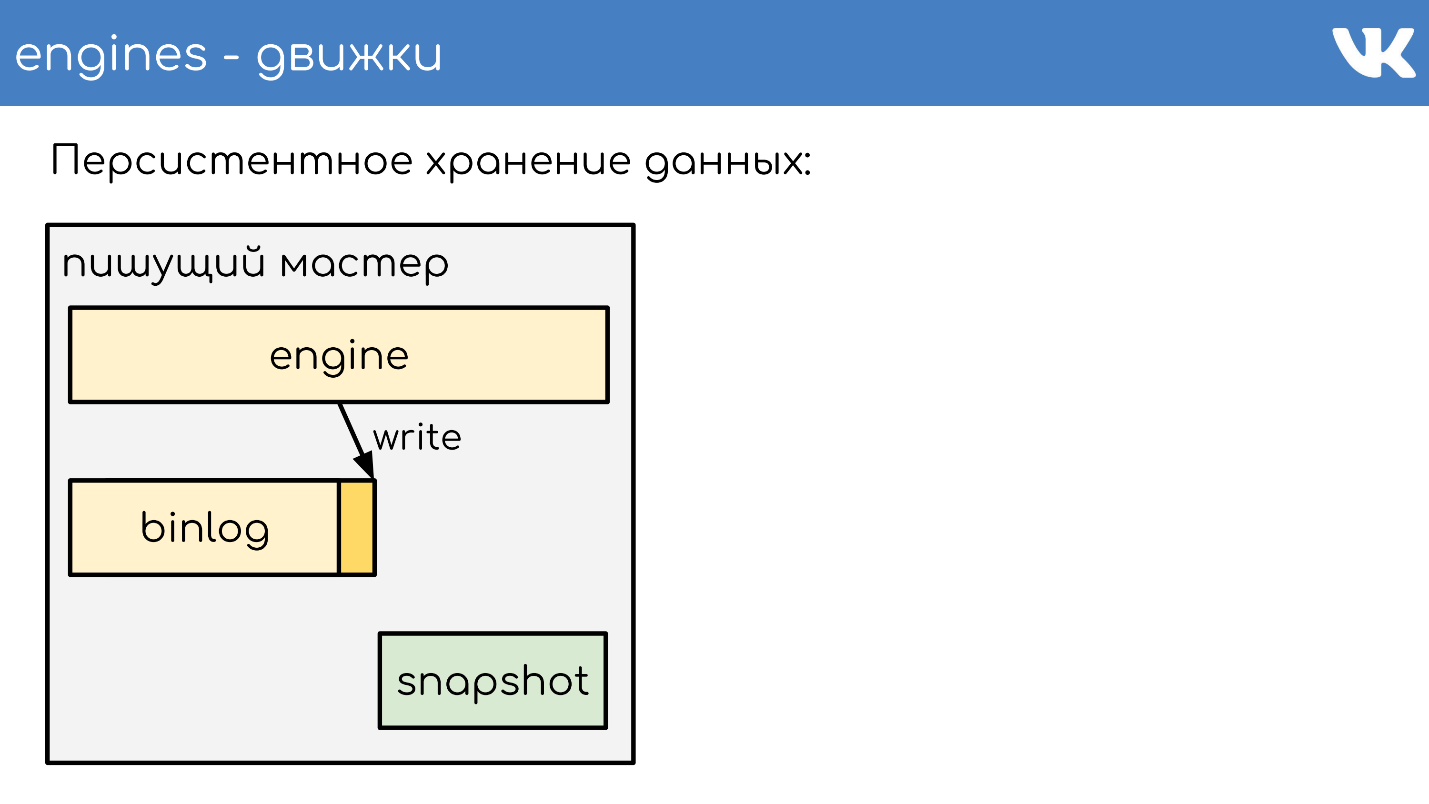
Permanente Datenspeicherung
Motoren schreiben Binlogs . Ein Binlog ist eine Datei, an deren Ende ein Ereignis hinzugefügt wird, um einen Status oder Daten zu ändern. In verschiedenen Lösungen wird es unterschiedlich genannt: Binärprotokoll,
WAL ,
AOF , aber das Prinzip ist eins.
Damit die Engine während eines Neustarts über viele Jahre nicht das gesamte Binlog erneut liest, schreiben die Engines
Snapshots - den aktuellen Status . Bei Bedarf lesen sie zuerst daraus und dann aus dem Binlog. Alle Binlogs werden im gleichen Binärformat geschrieben - gemäß dem TL-Schema, damit Administratoren sie mit ihren Tools gleichermaßen verwalten können. Schnappschüsse sind nicht erforderlich. Es gibt eine allgemeine Überschrift, die angibt, wessen Schnappschuss die Int, die Magie des Motors ist und welcher Körper für niemanden wichtig ist. Dies ist das Problem der Engine, die den Schnappschuss aufgezeichnet hat.
Ich werde kurz das Prinzip der Arbeit beschreiben. Es gibt einen Server, auf dem die Engine ausgeführt wird. Er öffnet ein neues leeres Binlog für die Aufzeichnung und schreibt ein Änderungsereignis hinein.

Irgendwann beschließt er entweder, einen Schnappschuss zu machen, oder er erhält ein Signal. Der Server erstellt eine neue Datei, schreibt ihren Status vollständig in sie, hängt die aktuelle Größe des Binlog-Offsets an das Ende der Datei an und schreibt weiter. Ein neues Binlog wird nicht erstellt.
Irgendwann, wenn die Engine neu gestartet wird, befinden sich ein Binlog und ein Snapshot auf der Festplatte. Der Motor liest den vollständigen Schnappschuss ein und erhöht seinen Zustand an einem bestimmten Punkt.

Subtrahiert die Position, die zum Zeitpunkt der Erstellung des Snapshots war, und die Größe des Binlogs.
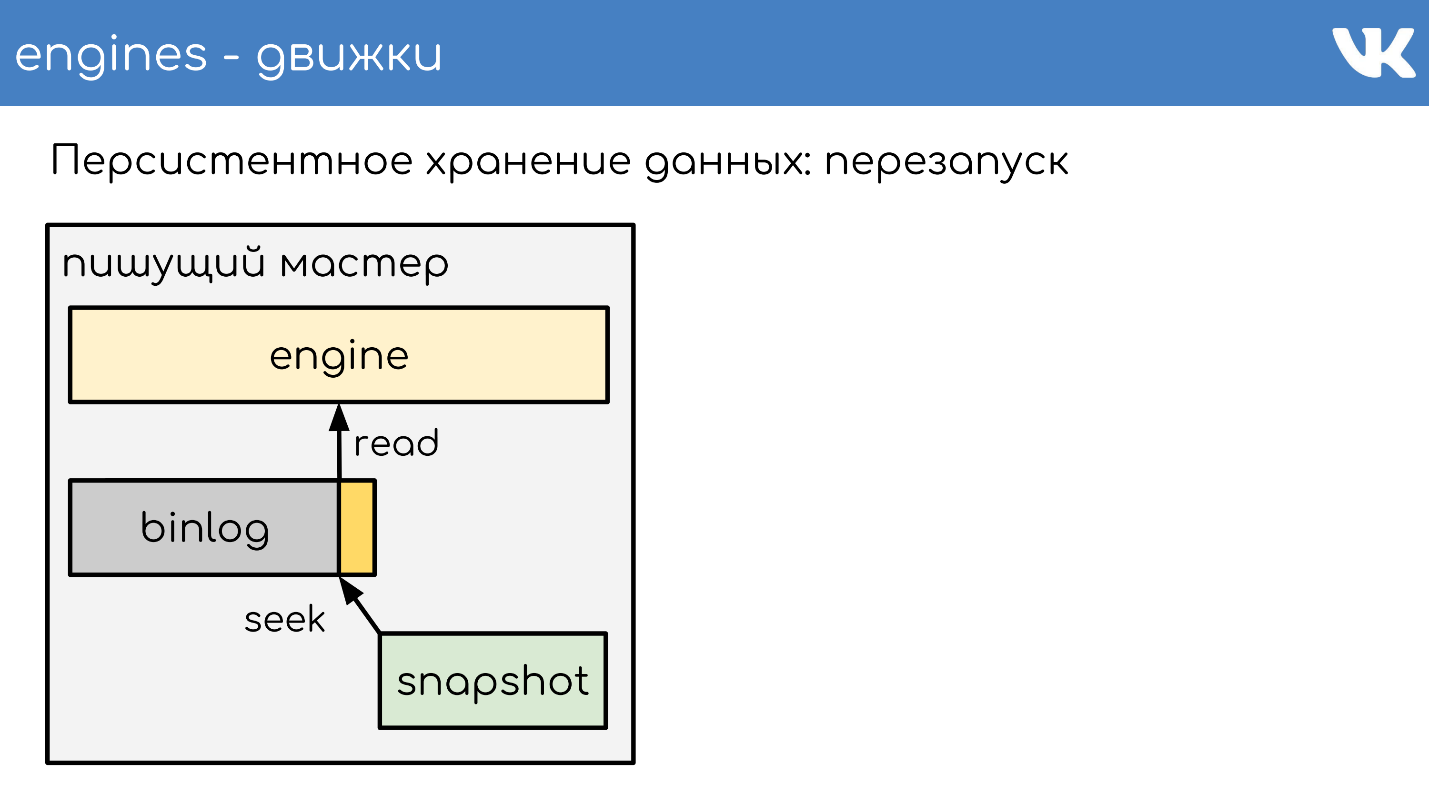
Liest das Ende des Binlogs, um den aktuellen Status abzurufen, und schreibt weitere Ereignisse. Dies ist ein einfaches Schema, an dem alle unsere Motoren arbeiten.
Datenreplikation
Infolgedessen ist die Datenreplikation anweisungsbasiert. Wir schreiben keine Seitenänderungen in das Binlog, sondern fordern
Änderungen an . Sehr ähnlich zu dem, was über das Netzwerk kommt, nur wenig verändert.
Das gleiche Schema wird nicht nur für die Replikation, sondern auch
für die Erstellung von Sicherungen verwendet . Wir haben eine Engine - einen Schreibmeister, der in ein Binlog schreibt. An jedem anderen Ort, an dem sich die Administratoren eingerichtet haben, steigt das Kopieren dieses Binlogs, und das ist alles - wir haben ein Backup.

Wenn Sie ein Lesereplikat benötigen, um die Belastung des Lesens auf der CPU zu verringern, steigt die Lese-Engine nur an, wodurch das Ende des Binlogs gelesen und diese Befehle lokal in sich selbst ausgeführt werden.
Die Verzögerung hier ist sehr gering, und es besteht die Möglichkeit herauszufinden, wie weit sich die Replik hinter dem Master befindet.
Daten-Sharding im RPC-Proxy
Wie funktioniert Sharding? Wie versteht der Proxy, an welchen Cluster-Shard gesendet werden soll? Der Code sagt nicht: "An 15 Shard senden!" - Nein, es macht einen Proxy.
Das einfachste Schema ist firstint , die erste Nummer in der Anfrage.
get(photo100_500) => 100 % N.Dies ist ein Beispiel für ein einfaches Memcached-Text-Protokoll, aber Anforderungen sind natürlich komplex und strukturiert. Das Beispiel verwendet die erste Zahl in der Abfrage und den Rest der Division durch die Clustergröße.
Dies ist nützlich, wenn wir die Datenlokalität einer Entität haben möchten. Angenommen, 100 ist eine Benutzer- oder Gruppen-ID, und wir möchten, dass sich alle Daten einer Entität für komplexe Abfragen auf demselben Shard befinden.
Wenn es uns egal ist, wie die Anforderungen über den Cluster verteilt sind, gibt es eine andere Option - das
Hashing des gesamten Shards .
hash(photo100_500) => 3539886280 % NWir bekommen auch den Hash, den Rest der Division und die Nummer der Scherbe.
Beide Optionen funktionieren nur, wenn wir darauf vorbereitet sind, dass wir den Cluster um ein Vielfaches aufteilen oder vergrößern, wenn wir ihn vergrößern. Zum Beispiel hatten wir 16 Shards, wir fehlen, wir wollen mehr - Sie können sicher 32 ohne Ausfallzeiten erhalten. Wenn wir mehrmals aufbauen wollen, kommt es zu Ausfallzeiten, da nicht alles ohne Verlust sorgfältig zerkleinert werden kann. Diese Optionen sind nützlich, aber nicht immer.
Wenn wir eine beliebige Anzahl von Servern hinzufügen oder entfernen müssen, wird
konsistentes Hashing auf dem a la Ketama-Ring verwendet . Gleichzeitig verlieren wir die Lokalität der Daten vollständig. Wir müssen eine Zusammenführungsanforderung an den Cluster senden, damit jedes Teil seine kleine Antwort zurückgibt, und die Antworten an den Proxy bereits kombinieren.
Es gibt superspezifische Abfragen. : RPC-proxy , , . , , , . proxy.

. —
memcache .
ring-buffer: prefix.idx = line— , , — . 0 1. memcache — . .
,
Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
ClickHouse
, .

, RPC RPC-proxy, , . ClickHouse, :
- - ClickHouse;
- RPC-proxy, ClickHouse, - , , RPC.
— ClickHouse.
ClickHouse,
KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse
reverse proxy , , . .

RPC- , , nginx. KittenHouse UDP.

, UDP- . RPC , UDP. .
Überwachung
: , , . :
.
Netdata ,
Graphite Carbon . ClickHouse, Whisper, . ClickHouse,
Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
statlogsCountEvent ( 'stat_name', $key1, $key2, …) statlogsUniqueCount ( 'stat_name', $uid, $key1, $key2, …) statlogsValuetEvent ( 'stat_name', $value, $key1, $key2, …) $stats = statlogsStatData($params)
, , — , Wathdogs.
, 600 1 .
, . — , . , .
,
memcache , .
stats-daemon .
logs-collectors , , .

logs-collectors.
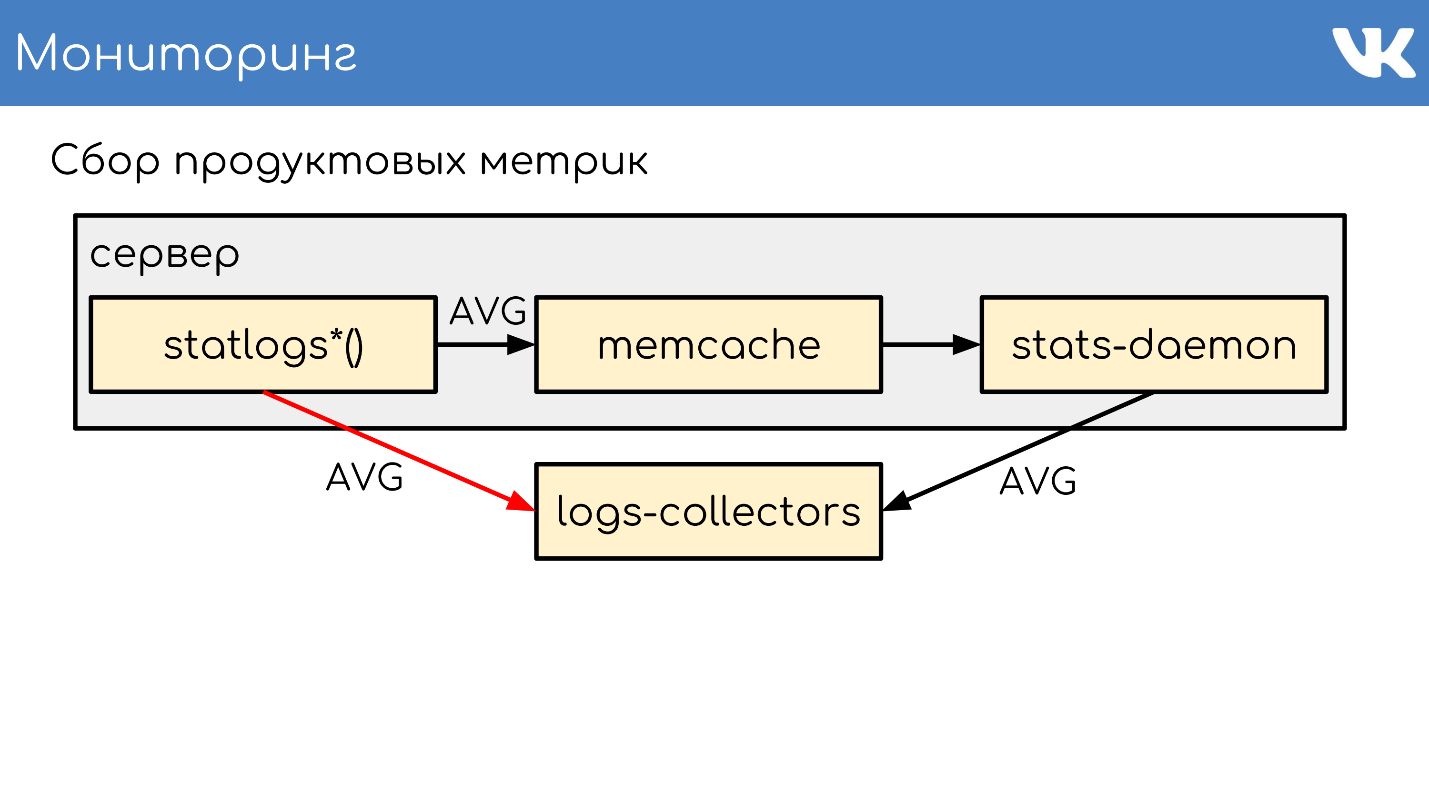
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors
meowDB — , .
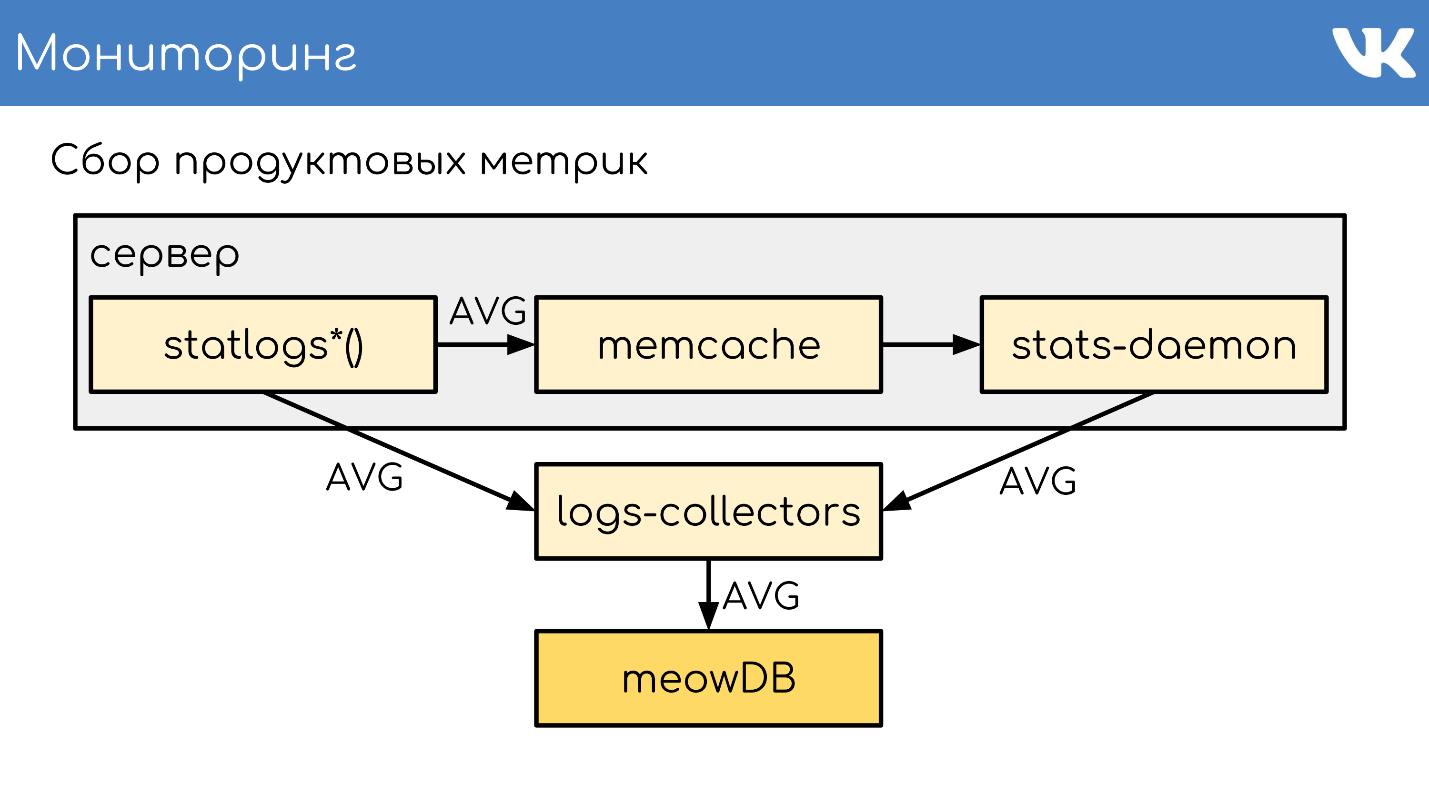
«-SQL» .

2018 , -, ClickHouse. ClickHouse — ?

, KittenHouse.
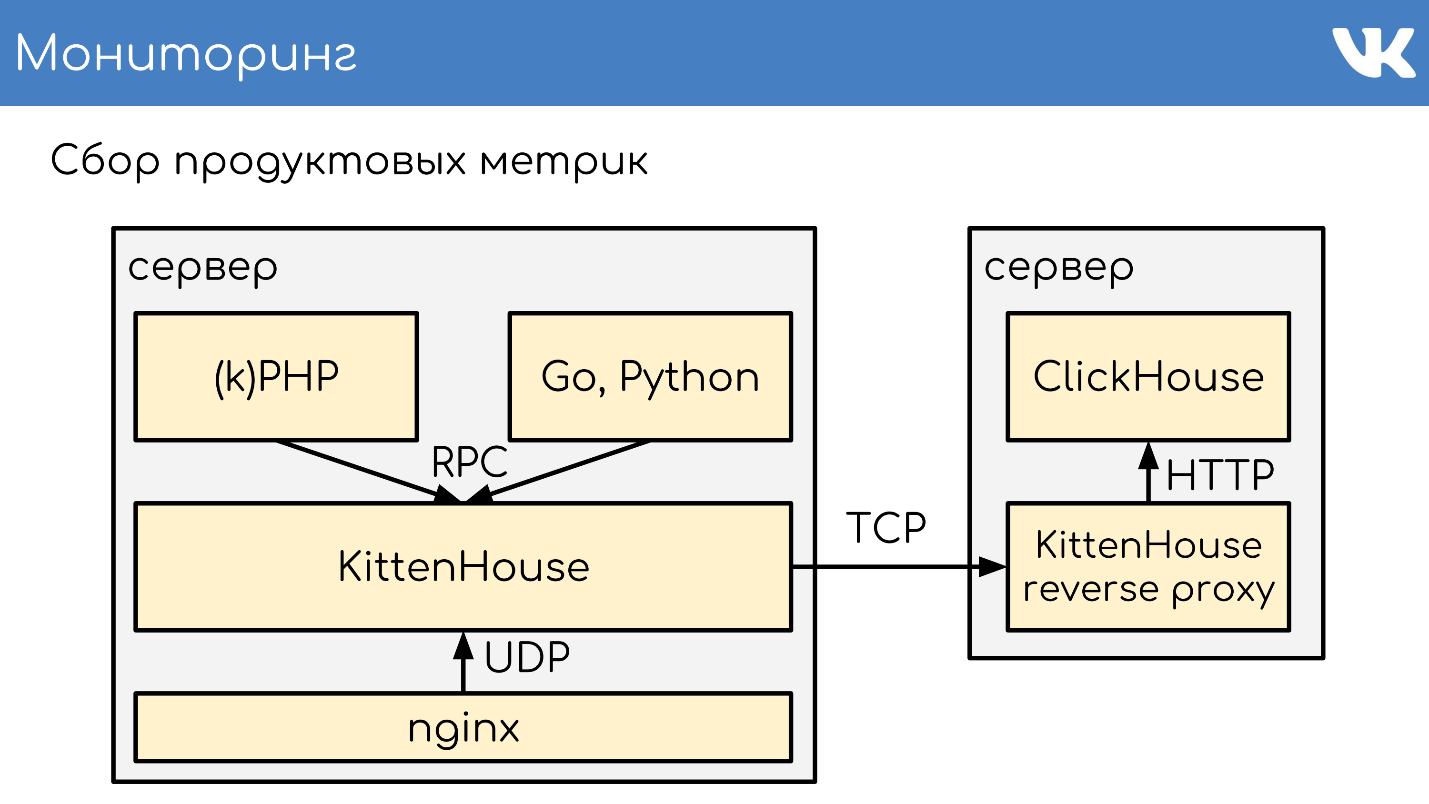 «*House»
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
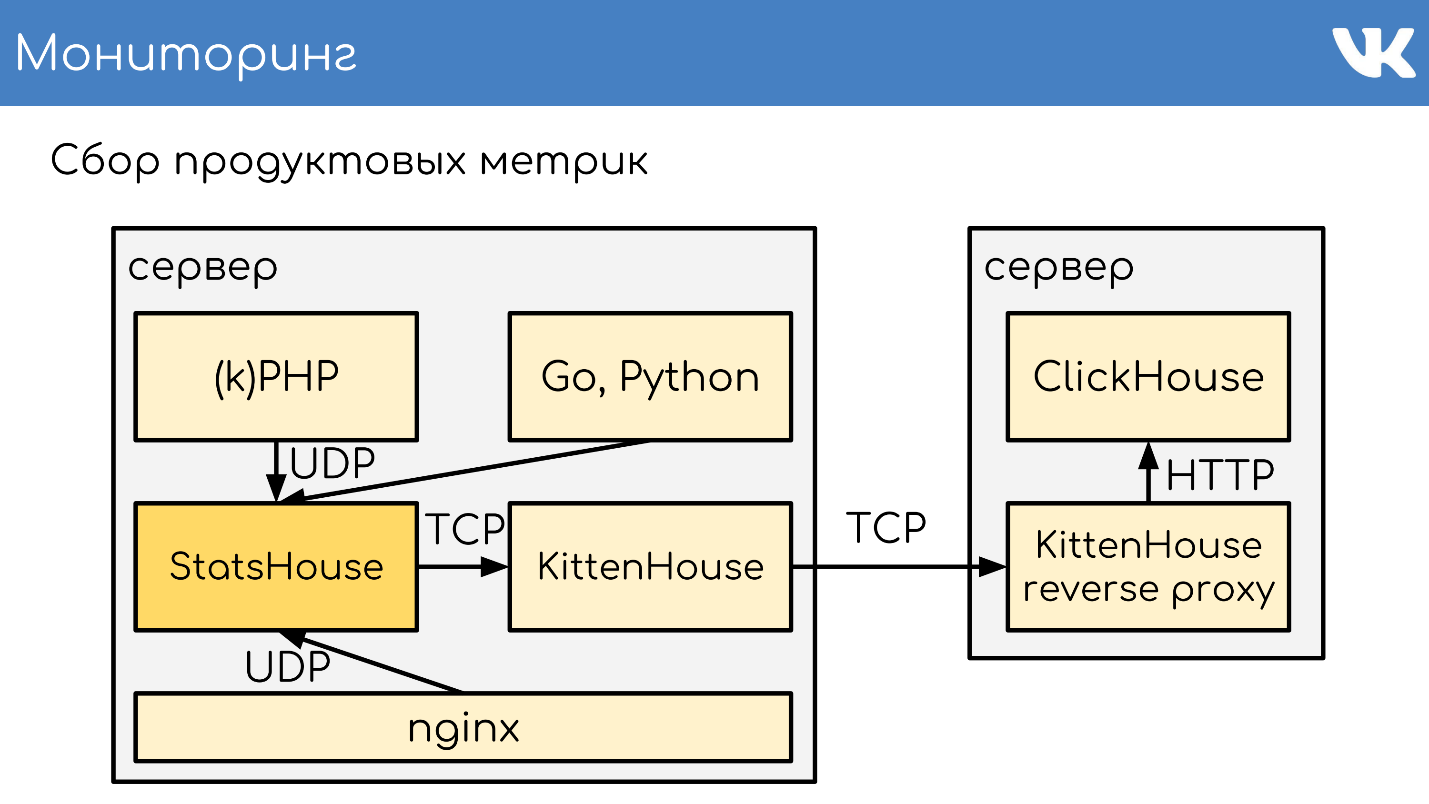
memcache, stats-daemon logs-collectors .

memcache, stats-daemon logs-collectors .
- , StatsHouse.
- StatsHouse KittenHouse UDP-, SQL-inserts, .
- KittenHouse ClickHouse.
- , StatsHouse — ClickHouse SQL.
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , .
, .
PHP.
git :
GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . ,
gossip replication , , — , . . ,
. .
kPHP
git .
HTTP- , diff — . —
binlog copyfast . , .
. copyfast' , binlog , gossip replication , -, .
graceful .
, , :
- git master branch;
- .deb ;
- binlog copyfast;
- ;
- .dep;
- dpkg -i ;
- graceful .
,
.deb ,
dpkg -i . kPHP , — dpkg? . — .
:, PHP Russia 17 PHP-. , , ( PHP!) — , PHP, .