
Hallo! Ich möchte im Klartext über die Mechanismen der Entstehung von Diebstahl in virtuellen Maschinen und über einige nicht offensichtliche Artefakte berichten, die wir während seiner Recherchen herausfinden konnten, in die ich als technischer Berater der Cloud-Plattform
Mail.ru Cloud Solutions eintauchen musste. Die Plattform läuft auf KVM.
Die CPU-Diebstahlzeit ist die Zeit, in der die virtuelle Maschine keine Prozessorressourcen für ihre Ausführung empfängt. Diese Zeit wird nur in Gastbetriebssystemen in Virtualisierungsumgebungen berücksichtigt. Die Gründe, aus denen diese sehr zugewiesenen Ressourcen wie im Leben verwendet werden, sind sehr vage. Aber wir haben uns entschlossen, es herauszufinden und sogar eine ganze Reihe von Experimenten durchzuführen. Nicht, dass wir jetzt alles über Stehlen wissen, aber wir werden Ihnen jetzt etwas Interessantes erzählen.
1. Was ist stehlen
Steal ist also eine Metrik, die auf einen Mangel an Prozessorzeit für Prozesse in einer virtuellen Maschine hinweist. Wie
im KVM-Kernel-Patch beschrieben , ist Steal die Zeit, zu der der Hypervisor andere Prozesse auf dem Host-Betriebssystem ausführt, obwohl er den Prozess der virtuellen Maschine zur Ausführung in die Warteschlange gestellt hat. Das heißt, Steal wird als Differenz zwischen der Zeit, zu der der Prozess zur Ausführung bereit ist, und der Zeit, zu der der Prozessor dem Prozess zugewiesen ist, betrachtet.
Der Kernel-Kernel empfängt den metrischen Diebstahl vom Hypervisor. Gleichzeitig gibt der Hypervisor nicht genau an, welche anderen Prozesse er ausführt. Er sagt lediglich: "Während ich beschäftigt bin, kann ich Ihnen keine Zeit geben." In KVM wurde die Unterstützung für das Stehlenzählen in
Patches hinzugefügt. Hier gibt es zwei wichtige Punkte:
- Die virtuelle Maschine lernt vom Hypervisor, wie man stiehlt. Das heißt, unter dem Gesichtspunkt der Verluste ist dies für Prozesse auf der virtuellen Maschine selbst eine indirekte Messung, die verschiedenen Verzerrungen unterliegen kann.
- Der Hypervisor teilt der virtuellen Maschine keine Informationen darüber mit, was er mit anderen tut. Hauptsache, er widmet ihr keine Zeit. Aus diesem Grund kann die virtuelle Maschine selbst keine Verzerrungen im Steal-Index erkennen, die durch die Art der konkurrierenden Prozesse geschätzt werden könnten.
2. Was beeinflusst stehlen
2.1. Berechnung stehlen
Tatsächlich wird Steal als ungefähr gleichbedeutend mit der normalen CPU-Auslastungszeit angesehen. Es gibt nicht viele Informationen darüber, wie die Entsorgung berücksichtigt wird. Wahrscheinlich, weil die Mehrheit diese Frage für offensichtlich hält. Aber hier gibt es auch Fallstricke. Um
sich mit diesem Prozess vertraut zu machen, lesen Sie den
Artikel von Brendann Gregg : Sie lernen eine Reihe von Nuancen bei der Berechnung der Auslastung kennen und Situationen, in denen diese Berechnung aus folgenden Gründen fehlerhaft ist:
- Überhitzung des Prozessors, während der Taktzyklen übersprungen werden.
- Schalten Sie den Turbo-Boost ein / aus, wodurch sich die Prozessortaktfrequenz ändert.
- Eine Änderung der Dauer eines Zeitquantums, die bei Verwendung energiesparender Prozessortechnologien wie SpeedStep auftritt.
- Das Problem der Berechnung des Durchschnitts: Eine Schätzung der Auslastung innerhalb einer Minute bei 80% kann einen kurzfristigen Ausbruch in 100% verbergen.
- Die zyklische Sperre (Spin Lock) führt dazu, dass der Prozessor entsorgt wird, der Benutzerprozess jedoch keinen Fortschritt bei seiner Ausführung sieht. Infolgedessen beträgt die geschätzte Prozessorauslastung durch den Prozess hundertprozentig, obwohl der Prozess keine physische Prozessorzeit verbraucht.
Ich habe keinen Artikel gefunden, der eine ähnliche Berechnung für Diebstahl beschreibt (wenn Sie wissen, teilen Sie dies in den Kommentaren mit). Nach der Quelle zu urteilen, ist der Berechnungsmechanismus jedoch der gleiche wie für die Entsorgung. Es ist nur so, dass dem Kernel direkt für den KVM-Prozess (Virtual Machine Process) ein weiterer Zähler hinzugefügt wird, der die Zeitdauer zählt, in der sich der KVM-Prozess im Standby-Zustand der Prozessorzeit befindet. Der Zähler entnimmt Informationen über den Prozessor seiner Spezifikation und prüft, ob alle seine Ticks vom virtuellen Prozess verwendet wurden. Wenn das alles ist, dann glauben wir, dass der Prozessor nur am Prozess der virtuellen Maschine beteiligt war. Ansonsten informieren wir, dass der Prozessor etwas anderes getan hat, Steal erschien.
Der Diebstahlzählprozess unterliegt denselben Problemen wie die reguläre Recyclingzählung. Um nicht zu sagen, dass solche Probleme häufig auftreten, aber sie sehen entmutigend aus.
2.2. Arten der Virtualisierung auf KVM
Im Allgemeinen gibt es drei Arten der Virtualisierung, die alle von KVM unterstützt werden. Die Art der Virtualisierung kann den Mechanismus bestimmen, durch den der Diebstahl erfolgt.
Sendung In diesem Fall erfolgt der Betrieb des Betriebssystems der virtuellen Maschine mit den physischen Geräten des Hypervisors ungefähr so:
- Das Gastbetriebssystem sendet einen Befehl an sein Gastgerät.
- Der Gastgerätetreiber akzeptiert den Befehl, generiert eine Anforderung für das Geräte-BIOS und sendet sie an den Hypervisor.
- Der Hypervisor-Prozess übersetzt einen Befehl in einen Befehl für ein physisches Gerät, wodurch es unter anderem sicherer wird.
- Der physische Gerätetreiber akzeptiert den geänderten Befehl und sendet ihn an das physische Gerät selbst.
- Die Ergebnisse der Befehlsausführung gehen auf die gleiche Weise zurück.
Der Vorteil der Übersetzung besteht darin, dass Sie jedes Gerät emulieren können und keine spezielle Vorbereitung des Kernels des Betriebssystems erforderlich ist. Aber dafür muss man vor allem schnell bezahlen.
Hardware-Virtualisierung . In diesem Fall versteht das Gerät auf Hardwareebene die Befehle des Betriebssystems. Dies ist der schnellste und beste Weg. Leider wird es nicht von allen physischen Geräten, Hypervisoren und Gastbetriebssystemen unterstützt. Derzeit sind die Hauptgeräte, die die Hardwarevirtualisierung unterstützen, Prozessoren.
Paravirtualisierung (Paravirtualisierung) . Die häufigste Version der Gerätevirtualisierung unter KVM und im Allgemeinen der häufigste Virtualisierungsmodus für Gastbetriebssysteme. Die Besonderheit besteht darin, dass die Arbeit mit einigen Subsystemen des Hypervisors (z. B. mit einem Netzwerk- oder Plattenstapel) oder die Zuweisung von Speicherseiten mithilfe der Hypervisor-API erfolgt, ohne dass Befehle auf niedriger Ebene übersetzt werden müssen. Der Nachteil dieser Virtualisierungsmethode besteht darin, dass der Kernel des Gastbetriebssystems so geändert werden muss, dass er mithilfe dieser API mit dem Hypervisor interagieren kann. In der Regel wird dies jedoch durch die Installation spezieller Treiber auf dem Gastbetriebssystem gelöst. In KVM wird diese API als
virtio-API bezeichnet .
Bei der Paravirtualisierung wird im Vergleich zur Übersetzung der Pfad zum physischen Gerät erheblich reduziert, indem Befehle direkt von der virtuellen Maschine an den Host-Hypervisor-Prozess gesendet werden. Auf diese Weise können Sie die Ausführung aller Anweisungen in der virtuellen Maschine beschleunigen. In KVM ist die virtio-API dafür verantwortlich, die nur für bestimmte Geräte wie ein Netzwerk oder einen Festplattenadapter funktioniert. Aus diesem Grund werden Virtio-Treiber in virtuellen Maschinen platziert.
Die Kehrseite dieser Beschleunigung ist, dass nicht alle Prozesse, die in einer virtuellen Maschine ausgeführt werden, in dieser verbleiben. Dadurch entstehen einige Spezialeffekte, die zum Stehlen führen können. Ich empfehle, eine detaillierte Studie zu diesem Problem mit
einer API für virtuelle E / A: virtio zu starten .
2.3. Fair Sheduling
Die Virtualisierung auf einem Hypervisor ist in der Tat ein gewöhnlicher Prozess, der den Gesetzen des Sheduling (Zuweisung von Ressourcen zwischen Prozessen) im Linux-Kernel folgt. Wir werden ihn daher genauer betrachten.
Linux verwendet den sogenannten CFS (Completely Fair Scheduler), der seit Kernel 2.6.23 zum Standard-Dispatcher geworden ist. Um diesen Algorithmus zu verstehen, können Sie die Linux-Kernel-Architektur oder -Quellen lesen. Das Wesentliche von CFS ist die Verteilung der Prozessorzeit zwischen Prozessen in Abhängigkeit von der Dauer ihrer Ausführung. Je mehr Prozessorzeit der Prozess benötigt, desto weniger Zeit erhält er. Dies garantiert die „ehrliche“ Ausführung aller Prozesse - so dass ein Prozess nicht ständig alle Prozessoren belegt und auch andere Prozesse ausgeführt werden können.
Manchmal führt dieses Paradigma zu interessanten Artefakten. Langjährige Linux-Benutzer werden sich wahrscheinlich an das Verblassen eines normalen Desktop-Texteditors erinnern, während sie anspruchsvolle compilerähnliche Anwendungen ausführen. Dies geschah, weil nicht ressourcenintensive Aufgaben von Desktopanwendungen mit Aufgaben konkurrierten, die aktiv Ressourcen verbrauchen, wie z. B. einem Compiler. CFS hält dies für unehrlich, sodass der Texteditor regelmäßig angehalten wird und der Prozessor die Compiler-Aufgaben verarbeiten kann. Dies wurde mithilfe des Mechanismus
sched_autogroup korrigiert, aber viele andere Funktionen der Verteilung der CPU-Zeit zwischen den Aufgaben blieben erhalten. In dieser Geschichte geht es nicht darum, wie schlimm die Dinge in CFS sind, sondern darum, die Aufmerksamkeit auf die Tatsache zu lenken, dass eine „ehrliche“ Verteilung der Prozessorzeit nicht die trivialste Aufgabe ist.
Ein weiterer wichtiger Punkt im Schuppen ist die Vorauszahlung. Dies ist erforderlich, um den Snickering-Prozess vom Prozessor aus zu steuern und andere arbeiten zu lassen. Der Exilprozess wird als Kontextumschaltung, Prozessorkontextumschaltung bezeichnet. In diesem Fall wird der gesamte Kontext der Aufgabe gespeichert: der Status des Stapels, der Register usw., wonach der Prozess wartet und ein anderer seinen Platz einnimmt. Dies ist eine teure Operation für das Betriebssystem und wird selten verwendet, aber tatsächlich ist daran nichts auszusetzen. Häufiges Wechseln des Kontexts kann auf ein Problem im Betriebssystem hinweisen, wird jedoch normalerweise kontinuierlich fortgesetzt und zeigt nichts Besonderes an.
Eine so lange Geschichte ist erforderlich, um eine Tatsache zu erklären: Je mehr Prozessorressourcen ein ehrlicher Linux-Sheduler zu verbrauchen versucht, desto schneller wird sie gestoppt, damit auch andere Prozesse funktionieren können. Ob dies richtig ist oder nicht, ist ein komplexes Problem, das unter verschiedenen Belastungen unterschiedlich gelöst wird. In Windows konzentrierte sich der Sheduler bis vor kurzem auf die Prioritätsverarbeitung von Desktopanwendungen, aufgrund derer Hintergrundprozesse hängen bleiben konnten. Sun Solaris hatte fünf verschiedene Klassen von Schuppen. Als sie mit der Virtualisierung begannen, fügten sie den sechsten
Fair Share Scheduler hinzu , da die vorherigen fünf nicht ausreichend mit der Virtualisierung von Solaris Zones arbeiteten. Ich empfehle, eine detaillierte Studie zu diesem Problem mit Büchern wie
Solaris Internals: Solaris 10 und OpenSolaris Kernel Architecture oder
Understanding the Linux Kernel zu beginnen .
2.4. Wie kann man den Diebstahl überwachen?
Die Überwachung des Diebstahls in einer virtuellen Maschine ist wie bei jeder anderen Prozessormetrik einfach: Sie können alle Methoden zum Entfernen von Prozessormetriken verwenden. Die Hauptsache ist, dass die virtuelle Maschine unter Linux läuft. Aus irgendeinem Grund stellt Windows seinen Benutzern solche Informationen nicht zur Verfügung. :(
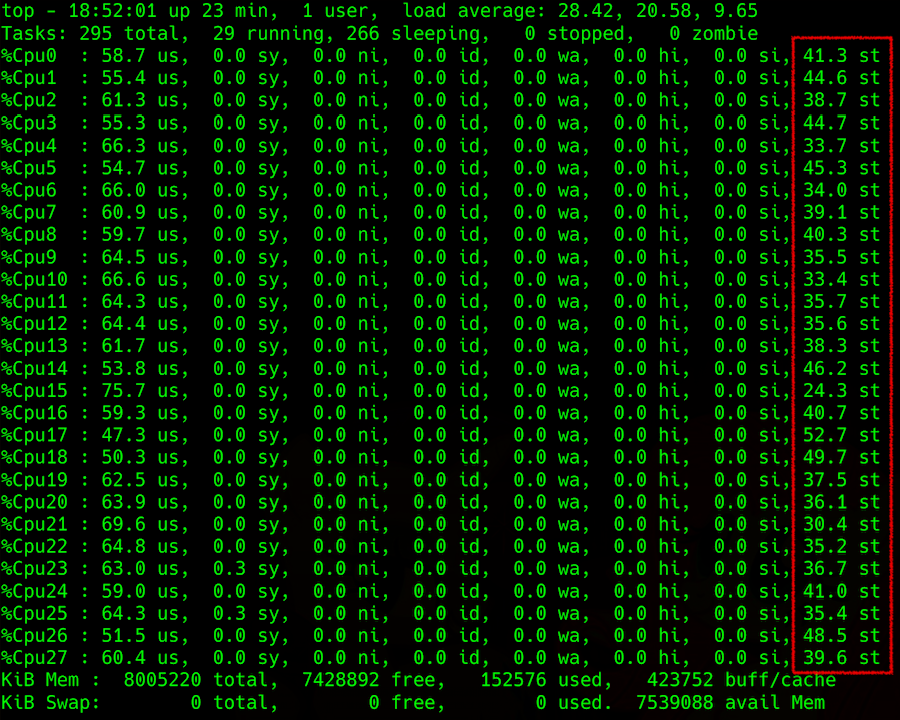 Die Ausgabe des Befehls top: Details zum Prozessorladen in der Spalte ganz rechts - stehlen
Die Ausgabe des Befehls top: Details zum Prozessorladen in der Spalte ganz rechts - stehlenDie Schwierigkeit tritt auf, wenn versucht wird, diese Informationen vom Hypervisor abzurufen. Sie können versuchen, den Diebstahl auf dem Hostcomputer vorherzusagen, indem Sie beispielsweise den Parameter Load Average (LA) verwenden - den Durchschnittswert der Anzahl der Prozesse, die in der Warteschlange auf die Ausführung warten. Die Methode zur Berechnung dieses Parameters ist nicht einfach. Wenn jedoch LA, normalisiert durch die Anzahl der Prozessorthreads, größer als 1 ist, bedeutet dies, dass der Linux-Server etwas überlastet ist.
Worauf warten all diese Prozesse? Die offensichtliche Antwort ist der Prozessor. Die Antwort ist jedoch nicht ganz richtig, da manchmal der Prozessor frei ist und LA überrollt. Denken Sie daran,
wie NFS abfällt und wie LA wächst . Dies kann bei einer Festplatte und bei anderen Eingabe- / Ausgabegeräten ungefähr gleich sein. Tatsächlich können Prozesse jedoch das Ende jeder Sperre erwarten, sowohl physisch, mit einem E / A-Gerät verknüpft, als auch logisch, z. B. mit einem Mutex. Dies umfasst auch Sperren auf Hardwareebene (dieselbe Antwort von der Festplatte) oder Logik (die sogenannten Sperrprimitive, die eine Reihe von Entitäten, Mutex Adaptive und Spin, Semaphoren, Bedingungsvariablen, RW-Sperren, IPC-Sperren ...) enthalten.
Ein weiteres Merkmal von LA ist, dass es als Durchschnittswert für das Betriebssystem betrachtet wird. Beispielsweise konkurrieren 100 Prozesse um eine Datei, und dann ist LA = 50. Ein so großer Wert scheint darauf hinzudeuten, dass das Betriebssystem schlecht ist. Bei anderem schief geschriebenem Code kann dies jedoch ein normaler Zustand sein, obwohl er nur für ihn schlecht ist und andere Prozesse im Betriebssystem nicht darunter leiden.
Aufgrund dieser Mittelung (und nicht weniger als einer Minute) ist es nicht die dankbarste Aufgabe, etwas anhand des LA-Indikators zu bestimmen, was in bestimmten Fällen zu sehr unsicheren Ergebnissen führt. Wenn Sie versuchen, es herauszufinden, werden Sie feststellen, dass nur die einfachsten Fälle in Wikipedia-Artikeln und anderen verfügbaren Ressourcen beschrieben werden, ohne eine ausführliche Erklärung des Prozesses. Ich sende alle Interessierten
hier noch einmal an Brendann Gregg - weiter
unten unter den Links. Wem Faulheit auf Englisch eine
Übersetzung seines beliebten Artikels über LA ist .
3. Spezialeffekte
Lassen Sie uns nun auf die wichtigsten Fälle von Diebstahl eingehen, auf die wir gestoßen sind. Ich werde Ihnen sagen, wie sie sich aus dem Vorstehenden ergeben und wie sie sich auf Indikatoren auf dem Hypervisor beziehen.
Recycling . Das einfachste und häufigste: Der Hypervisor wird wiederverwendet. In der Tat gibt es viele laufende virtuelle Maschinen, einen großen Prozessorverbrauch, viel Konkurrenz, die LA-Auslastung beträgt mehr als 1 (normalisiert durch Prozessorthreads). In allen Virtualoks verlangsamt sich alles. Der vom Hypervisor übertragene Diebstahl nimmt ebenfalls zu. Es ist notwendig, die Last neu zu verteilen oder jemanden auszuschalten. Im Allgemeinen ist alles logisch und verständlich.
Paravirtualisierung versus Einzelinstanzen . Es gibt eine einzige virtuelle Maschine auf dem Hypervisor, die einen kleinen Teil davon verbraucht, aber die Eingabe / Ausgabe, beispielsweise auf einer Festplatte, stark belastet. Und von irgendwo darin erscheint ein kleiner Diebstahl, bis zu 10% (wie mehrere Experimente gezeigt haben).
Der Fall ist interessant. Steal wird hier nur aufgrund von Sperren auf der Ebene paravirtualisierter Treiber angezeigt. In der virtuellen Maschine wird ein Interrupt erstellt, der vom Treiber verarbeitet wird und an den Hypervisor gesendet wird. Aufgrund der Interrupt-Verarbeitung auf dem Hypervisor für die virtuelle Maschine sieht es wie eine gesendete Anforderung aus, sie ist zur Ausführung bereit und wartet auf den Prozessor, gibt dem Prozessor jedoch keine Zeit. Virtualka glaubt, dass diese Zeit gestohlen wird.
Dies geschieht, wenn der Puffer gesendet wird, in den Kernelbereich des Hypervisors gelangt und wir beginnen, darauf zu warten. Obwohl er aus Sicht von virtualka sofort zurückkehren sollte. Daher wird diese Zeit gemäß dem Diebstahlberechnungsalgorithmus als gestohlen betrachtet. In dieser Situation gibt es höchstwahrscheinlich andere Mechanismen (z. B. die Verarbeitung einiger anderer Systemaufrufe), die jedoch nicht sehr unterschiedlich sein sollten.
Sheduler gegen stark belastete Virtualoks . Wenn eine virtuelle Maschine mehr als andere gestohlen wird, ist sie genau mit dem Sheduler verbunden. Je stärker der Prozess den Prozessor lädt, desto eher wird er vom Sheduler ausgestoßen, sodass auch die anderen arbeiten können. Wenn die virtuelle Maschine ein wenig verbraucht, sieht sie fast keinen Diebstahl: Ihr Prozess hat ehrlich gesessen und gewartet, es ist notwendig, ihm mehr Zeit zu geben. Wenn die virtuelle Maschine die maximale Belastung aller ihrer Kerne erzeugt, wird sie häufig aus dem Prozessor entfernt und versucht, nicht viel Zeit zu geben.
Schlimmer noch, wenn die Prozesse in der virtuellen Maschine versuchen, mehr Prozessor zu erhalten, weil sie die Datenverarbeitung nicht bewältigen können. Dann wird das Betriebssystem auf dem Hypervisor aufgrund einer ehrlichen Optimierung immer weniger Prozessorzeit geben. Dieser Prozess findet wie eine Lawine statt und der Diebstahl springt in den Himmel, obwohl andere virtuelle Maschinen ihn möglicherweise fast nicht bemerken. Und je mehr Kerne, desto schlimmer fiel die Maschine unter die Verteilung. Kurz gesagt, stark ausgelastete virtuelle Maschinen mit vielen Kernen leiden am meisten.
Low LA, aber es gibt ein Schnäppchen . Wenn LA ungefähr 0,7 beträgt (das heißt, der Hypervisor scheint unterlastet zu sein), aber innerhalb einzelner virtueller Maschinen ein Diebstahl beobachtet wird:
- Die oben beschriebene Option mit Paravirtualisierung. Eine virtuelle Maschine kann Metriken empfangen, die auf Diebstahl hinweisen, obwohl mit dem Hypervisor alles in Ordnung ist. Nach den Ergebnissen unserer Experimente überschreitet eine solche Steal-Option 10% nicht und sollte keinen signifikanten Einfluss auf die Anwendungsleistung innerhalb der virtuellen Maschine haben.
- Der Parameter LA wird falsch berücksichtigt. Genauer gesagt wird es in jedem bestimmten Moment als wahr angesehen, aber wenn es für eine Minute gemittelt wird, stellt sich heraus, dass es unterschätzt wird. Wenn beispielsweise eine virtuelle Maschine genau eine halbe Minute pro Drittel des Hypervisors alle ihre Prozessoren verbraucht, beträgt LA pro Minute auf dem Hypervisor 0,15. Vier solcher virtuellen Maschinen, die gleichzeitig arbeiten, ergeben 0,6. Und die Tatsache, dass es in LA jeweils eine halbe Minute lang einen wilden Diebstahl von 25% gab, kann nicht mehr herausgezogen werden.
- Wieder wegen des Schuppens, der entschied, dass jemand zu viel aß, und diesen warten ließ. In der Zwischenzeit wechsle ich den Kontext, verarbeite Interrupts und mache andere wichtige Systemaufgaben. Infolgedessen treten bei einigen virtuellen Maschinen keine Probleme auf, während bei anderen ernsthafte Leistungseinbußen auftreten.
4. Andere Verzerrungen
Es gibt weitere Millionen Gründe, die ehrliche Rückgabe der Prozessorzeit auf der virtuellen Maschine zu verzerren. Zum Beispiel erhöhen Hypertreading und NUMA die Komplexität der Berechnungen. Sie verwirren die Wahl des Kernels für die Ausführung des Prozesses völlig, da der Sheduler Koeffizienten - Gewichte verwendet, die beim Wechseln von Kontexten die Berechnung noch schwieriger machen.
Es gibt Verzerrungen aufgrund von Technologien wie Turbo-Boost oder umgekehrt dem Energiesparmodus, der bei der Berechnung der Auslastung die Frequenz oder sogar die Zeitscheibe auf dem Server künstlich erhöhen oder verringern kann. Das Einschalten des Turbo-Boosts verringert die Leistung eines Prozessorthreads aufgrund der erhöhten Leistung eines anderen. In diesem Moment werden keine Informationen über die aktuelle Prozessorfrequenz an die virtuelle Maschine übertragen, und sie glaubt, dass jemand ihre Zeit bindet (zum Beispiel hat sie 2 GHz angefordert, aber halb so viel erhalten).
Im Allgemeinen kann es viele Ursachen für Verzerrungen geben. In einem bestimmten System finden Sie möglicherweise etwas anderes. Beginnen Sie besser mit den Büchern, auf die ich oben verwiesen habe, und nehmen Sie Statistiken vom Hypervisor mit Dienstprogrammen wie perf, sysdig, systemtap, von denen es
Dutzende gibt .
5. Schlussfolgerungen
- Aufgrund der Paravirtualisierung kann ein gewisser Diebstahl auftreten, der als normal angesehen werden kann. Im Internet schreiben sie, dass dieser Wert 5-10% betragen kann. Dies hängt von den Anwendungen in der virtuellen Maschine und von der Belastung der physischen Geräte ab. Es ist wichtig zu beachten, wie sich Anwendungen in virtuellen Maschinen anfühlen.
- Das Verhältnis der Belastung des Hypervisors und des Diebstahls innerhalb der virtuellen Maschine ist nicht immer eindeutig miteinander verbunden. Beide Diebstahlschätzungen können in bestimmten Situationen bei unterschiedlichen Belastungen fehlerhaft sein.
- Scheduler mag keine Prozesse, die viel verlangen. Er versucht, denen, die mehr verlangen, weniger zu geben. Große virtuelle Maschinen sind böse.
- Ein kleiner Diebstahl kann die Norm ohne Paravirtualisierung sein (unter Berücksichtigung der Last in der virtuellen Maschine, der Merkmale der Last der Nachbarn, der Lastverteilung unter den Threads und anderer Faktoren).
- Wenn Sie herausfinden möchten, wie Sie in einem bestimmten System stehlen, müssen Sie verschiedene Optionen untersuchen, Metriken sammeln, sorgfältig analysieren und überlegen, wie Sie die Last gleichmäßig verteilen können. Abweichungen sind in jedem Fall möglich, die experimentell bestätigt oder im Kernel-Debugger angezeigt werden müssen.