Wir setzen das Thema der maschinellen Lernwettbewerbe auf dem Habré fort und möchten den Lesern zwei weitere Plattformen vorstellen. Sie sind sicherlich nicht so groß wie Kaggle, aber sie verdienen definitiv Aufmerksamkeit.

Persönlich mag ich Kaggle aus mehreren Gründen nicht so sehr:
- Erstens dauern die dortigen Wettbewerbe oft mehrere Monate, und für die aktive Teilnahme sind große Anstrengungen erforderlich.
- zweitens öffentliche Kernel (öffentliche Lösungen). Die Anhänger der Kaggle raten ihnen, ruhig mit den tibetischen Mönchen umzugehen, aber in Wirklichkeit ist es eine Schande, wenn sich herausstellt, dass das, was Sie ein oder zwei Monate lang besucht haben, plötzlich für alle auf einer Platte liegt.
Glücklicherweise werden maschinelle Lernwettbewerbe auf anderen Plattformen abgehalten, und einige dieser Wettbewerbe werden diskutiert.
| IDAO | SNA Hackathon 2019 |
|---|
Amtssprache: Englisch,
Veranstalter: Yandex, Sberbank, HSE | Amtssprache: Russisch,
Veranstalter: Mail.ru Group |
Online-Runde: 15. Januar - 11. Februar 2019;
Vor-Ort-Finale: 4. bis 6. April 2019 | online - vom 7. Februar bis 15. März;
offline - vom 30. März bis 1. April. |
Bestimmen Sie anhand eines bestimmten Datensatzes eines Partikels in einem großen Hadronenkollider (Flugbahn, Impuls und andere recht komplexe physikalische Parameter), ob es sich um ein Myon handelt oder nicht
Von dieser Aussage wurden 2 Aufgaben unterschieden:
- In einem mussten Sie nur Ihre Vorhersage senden,
- und im anderen Fall wurden der vollständige Code und das Modell für die Vorhersage sowie recht strenge Einschränkungen für die Ausführungszeit und die Speichernutzung auferlegt | Für den SNA Hackathon-Wettbewerb wurden Protokolle für die Anzeige von Inhalten offener Gruppen in Benutzer-Newsfeeds für Februar bis März 2018 gesammelt. Das Test-Set hat die letzten anderthalb Märzwochen versteckt. Jeder Protokolleintrag enthält Informationen darüber, was und wem er angezeigt wurde und wie der Benutzer auf diesen Inhalt reagiert hat: Fügen Sie eine „Klasse“ ein, die kommentiert, ignoriert oder im Feed ausgeblendet wird.
Das Wesentliche der Aufgaben von SNA Hackathon ist es, für jeden Benutzer des sozialen Netzwerks Odnoklassniki sein Band zu arrangieren und die Beiträge, die die „Klasse“ erhalten, so hoch wie möglich zu halten.
In der Online-Phase wurde die Aufgabe in drei Teile unterteilt:
1. Beiträge aus verschiedenen Gründen der Zusammenarbeit zu bewerten
2. Ordnen Sie die Beiträge nach den darin enthaltenen Bildern
3. Beiträge nach dem darin enthaltenen Text zu ordnen |
| Eine komplexe benutzerdefinierte Metrik, ähnlich wie ROC-AUC | Durchschnittliche ROC-AUC nach Benutzern |
Preise für die erste Etappe - T-Shirts für N Plätze, Übergang zur zweiten Etappe, wo Unterkunft und Verpflegung während des Wettbewerbs bezahlt wurden
Die zweite Stufe - ??? (Aus irgendeinem Grund war ich bei der Preisverleihung nicht anwesend und konnte nicht herausfinden, was ich für die Preise erhalten habe). Versprochene Laptops an alle Mitglieder des Gewinnerteams | Preise für die erste Etappe - T-Shirts für die 100 besten Teilnehmer, Übergang zur zweiten Etappe, wo sie für die Reise nach Moskau, Unterkunft und Verpflegung während des Wettbewerbs bezahlt haben. Gegen Ende der ersten Phase wurden außerdem Preise für die besten drei Aufgaben in Phase 1 bekannt gegeben: Alle haben auf der RTX 2080 TI-Grafikkarte gewonnen!
Die zweite Stufe ist die erste des Teams, die Teams hatten 2 bis 5 Personen, Preise:
1. Platz - 300.000 Rubel
2. Platz - 200 000 Rubel
3. Platz - 100.000 Rubel
Preis der Jury - 100 000 Rubel |
| Die offizielle Gruppe im Telegramm, ~ 190 Teilnehmer, Kommunikation auf Englisch, musste ich einige Tage warten, um Fragen zu beantworten | Die offizielle Gruppe im Telegramm, ~ 1500 Teilnehmer, eine aktive Diskussion der Aufgaben zwischen Teilnehmern und Organisatoren |
| Die Organisatoren stellten zwei grundlegende Lösungen zur Verfügung, einfache und fortschrittliche. Ein einfacher benötigte weniger als 16 GB RAM, während ein fortgeschrittener von 16 nicht passte. Gleichzeitig konnten die Teilnehmer die fortschrittliche Lösung nicht wesentlich übertreffen. Es gab keine Schwierigkeiten bei der Einführung dieser Lösungen. Es ist zu beachten, dass im erweiterten Beispiel ein Kommentar mit einem Hinweis enthalten war, wo mit der Verbesserung der Lösung begonnen werden kann. | Für jede Aufgabe wurden grundlegende primitive Lösungen bereitgestellt, die von den Teilnehmern leicht übertroffen wurden. In den frühen Tagen des Wettbewerbs hatten die Teilnehmer mehrere Schwierigkeiten: Erstens wurden die Daten im Apache-Parkettformat angegeben, und nicht alle Kombinationen von Python und dem Parkettpaket funktionierten fehlerfrei. Die zweite Schwierigkeit bestand darin, Bilder aus der Mail-Cloud zu pumpen. Derzeit gibt es keine einfache Möglichkeit, eine große Datenmenge gleichzeitig herunterzuladen. Infolgedessen verzögerten diese Probleme die Teilnehmer um einige Tage. |
IDAO. Erste Stufe
Die Aufgabe bestand darin, Myon- / Nicht-Myon-Partikel nach ihren Eigenschaften zu klassifizieren. Ein wesentliches Merkmal dieser Aufgabe war das Vorhandensein einer Gewichtsspalte in den Trainingsdaten, die die Organisatoren selbst als Vertrauen in die Antwort auf diese Zeile interpretierten. Das Problem war, dass einige Zeilen negative Gewichte enthielten.
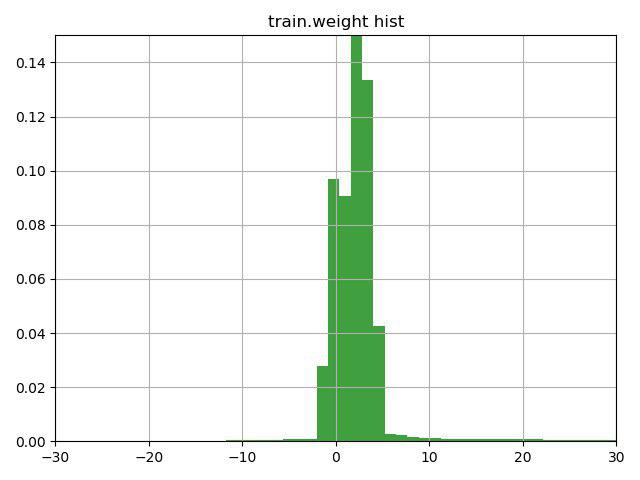
Nachdem wir einige Minuten mit einem Hinweis über die Linie nachgedacht hatten (der Hinweis machte nur auf diese Funktion der Gewichtsspalte aufmerksam) und dieses Diagramm erstellt hatten, entschieden wir uns, drei Optionen zu aktivieren:
1) Invertieren Sie das Ziel für Zeilen mit negativem Gewicht (bzw. Gewicht).
2) Verschieben Sie die Gewichte auf den Minimalwert, so dass sie bei 0 beginnen
3) Verwenden Sie keine Gewichte für Zeilen
Die dritte Option erwies sich als die schlechteste, aber die ersten beiden verbesserten das Ergebnis, die beste war Option Nr. 1, die uns in der ersten Aufgabe sofort auf den aktuellen zweiten Platz und in der zweiten auf den ersten Platz brachte.

Unser nächster Schritt bestand darin, die Daten auf fehlende Werte zu untersuchen. Die Organisatoren gaben uns bereits gekämmte Daten, bei denen einige Werte fehlten, und sie wurden durch -9999 ersetzt.
Wir fanden fehlende Werte in den Spalten MatchedHit_ {X, Y, Z} [N] und MatchedHit_D {X, Y, Z} [N] und nur dann, wenn N = 2 oder 3. Wie wir verstanden haben, flogen einige Partikel nicht durch alle 4 Detektoren und stoppte entweder bei 3 oder 4 Platte. Die Daten enthielten auch Lextra_ {X, Y} [N] -Spalten, die anscheinend dasselbe wie MatchedHit_ {X, Y, Z} [N] beschreiben, jedoch eine Art Extrapolation verwenden. Diese mageren Vermutungen deuten darauf hin, dass Sie anstelle von fehlenden Werten in MatchedHit_ {X, Y, Z} [N] Lextra_ {X, Y} [N] ersetzen können (nur für X- und Y-Koordinaten). MatchedHit_Z [N] war gut mit einem Median gefüllt. Diese Manipulationen ermöglichten es uns, für beide Aufgaben an einen Zwischenplatz zu gehen.

Da sie für den Sieg in der ersten Etappe nichts gaben, konnten wir damit aufhören, aber wir machten weiter, zeichneten einige schöne Bilder und entwickelten neue Funktionen.

Zum Beispiel haben wir festgestellt, dass, wenn wir die Schnittpunkte der Partikel aus jeder der vier Platten der Detektoren erstellen, wir sehen können, dass die Punkte auf jeder der Platten in 5 Rechtecke mit einem Seitenverhältnis von 4 zu 5 und dem Zentrum bei (0,0) und gruppiert sind Das erste Rechteck hat keine Punkte.
| Plattennummer / Rechteckabmessungen | 1 | 2 | 3 | 4 | 5 |
|---|
| Platte 1 | 500 x 625 | 1000 x 1250 | 2000 x 2500 | 4000x5000 | 8000 x 10000 |
| Platte 2 | 520 x 650 | 1040 x 1300 | 2080 x 2600 | 4160x5200 | 8320 x 10400 |
| Platte 3 | 560 x 700 | 1120 x 1400 | 2240 x 2800 | 4480 x 5600 | 8960 x 11200 |
| Platte 4 | 600 x 750 | 1200x1500 | 2400x3000 | 4800 x 6000 | 9600 x 12000 |
Nachdem wir diese Größen bestimmt hatten, fügten wir für jedes Partikel 4 neue kategoriale Merkmale hinzu - die Nummer des Rechtecks, in dem es jede Platte schneidet.
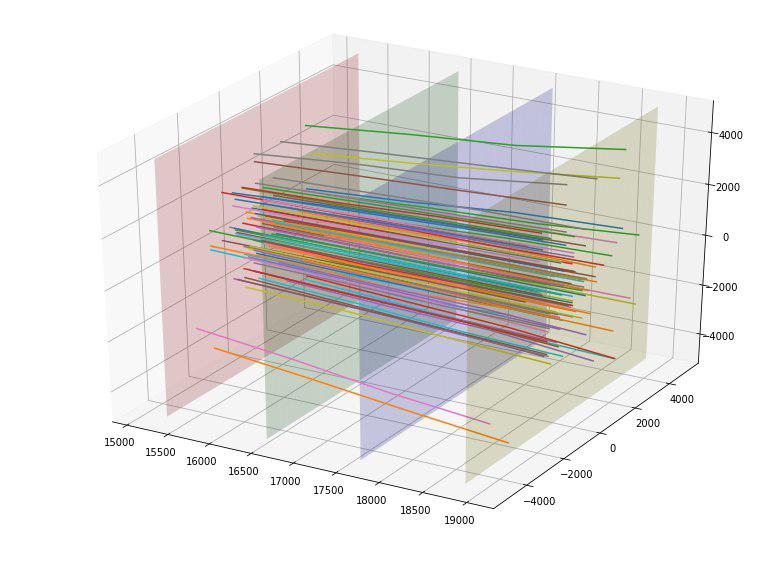
Wir bemerkten auch, dass die Partikel vom Zentrum weg zu streuen schienen und die Idee kam, die „Qualität“ dieser Streuung irgendwie zu bewerten. Im Idealfall könnte man sich je nach Eintrittspunkt eine Art „ideale“ Parabel einfallen lassen und die Abweichung davon abschätzen, aber wir haben uns auf die „ideale“ Linie beschränkt. Durch die Konstruktion solcher idealen Linien für jeden Eintrittspunkt konnten wir die mittlere quadratische Abweichung der Flugbahn jedes Partikels von dieser Linie berechnen. Da die durchschnittliche Abweichung für Ziel = 1 152 betrug und für Ziel = 0 390 betrug, haben wir diese Funktion vorläufig als gut bewertet. In der Tat traf diese Funktion sofort die Spitze der nützlichsten.
Wir waren begeistert und haben die Abweichung aller 4 Schnittpunkte für jedes Partikel von der Ideallinie als zusätzliche 4 Merkmale hinzugefügt (und sie haben auch gut funktioniert).
Die Links zu wissenschaftlichen Artikeln zum Thema des Wettbewerbs, die uns von den Organisatoren zur Verfügung gestellt wurden, deuteten darauf hin, dass wir weit davon entfernt sind, dieses Problem zu lösen, und dass es möglicherweise eine spezielle Software gibt. Nachdem wir das Repository auf Github entdeckt hatten, in dem die Methoden IsMuonSimple, IsMuon und IsMuonLoose implementiert waren, haben wir sie mit geringfügigen Änderungen an uns selbst übertragen. Die Methoden selbst waren sehr einfach: Wenn zum Beispiel die Energie unter einem Schwellenwert liegt, ist dies kein Myon, sonst ein Myon. Solche einfachen Vorzeichen konnten bei Verwendung der Gradientenverstärkung offensichtlich keinen Anstieg bewirken, daher haben wir dem Schwellenwert ein weiteres Vorzeichen "Abstand" hinzugefügt. Diese Funktionen haben sich ebenfalls etwas verbessert. Wenn man die vorhandenen Methoden gründlicher analysiert, könnte man vielleicht stärkere Methoden finden und sie den Attributen hinzufügen.
Gegen Ende des Wettbewerbs haben wir eine kleine „schnelle“ Lösung für die zweite Aufgabe gefunden, die sich in folgenden Punkten von der Grundlinie unterschied:
- In Reihen mit negativem Gewicht wurde das Ziel invertiert
- Die fehlenden Werte in MatchedHit_ {X, Y, Z} [N] wurden ausgefüllt.
- Reduzierte Tiefe auf 7
- Reduzierte Lernrate auf 0,1 (war 0,19)
Infolgedessen haben wir mehr Funktionen ausprobiert (nicht besonders erfolgreich), die Parameter ausgewählt und Catboost, Lightgbm und XGboost trainiert, verschiedene Vorhersagemischungen ausprobiert und die zweite Aufgabe vor der Eröffnung des Privat sicher gewonnen und waren in der ersten führend.
Nach der Eröffnung des Privat waren wir für 1 Aufgabe auf dem 10. Platz und für die zweite auf dem 3. Platz. Alle Führer waren durcheinander, und die Geschwindigkeit im Privaten war höher als im Liberboard. Es scheint, dass die Daten schlecht geschichtet waren (oder es gab zum Beispiel keine Linien mit negativen Gewichten im privaten Bereich) und dies war ein wenig frustrierend.
SNA Hackathon 2019 - Texte. Erste Stufe
Die Aufgabe bestand darin, die Beiträge des Benutzers im sozialen Netzwerk von Odnoklassniki nach dem darin enthaltenen Text zu ordnen. Zusätzlich zum Text gab es einige weitere Merkmale des Beitrags (Sprache, Eigentümer, Erstellungsdatum und -zeit, Anzeigedatum und -zeit).
Als klassische Ansätze für die Arbeit mit Text möchte ich zwei Optionen herausgreifen:
- Die Abbildung jedes Wortes in einen n-dimensionalen Vektorraum, so dass ähnliche Wörter ähnliche Vektoren haben (weitere Details finden Sie in unserem Artikel ), dann entweder das mittlere Wort für den Text finden oder Mechanismen verwenden, die die relative Position der Wörter berücksichtigen (CNN, LSTM / GRU) .
- Verwenden von Modellen, die sofort mit ganzen Sätzen arbeiten können. Zum Beispiel Bert. Theoretisch sollte dieser Ansatz besser funktionieren.
Da dies meine erste Erfahrung mit Texten war, wäre es falsch, jemanden zu unterrichten, also werde ich mich selbst unterrichten. Dies sind die Tipps, die ich mir zu Beginn des Wettbewerbs geben würde:
- Bevor Sie etwas lernen, schauen Sie sich die Daten an! Zusätzlich zu den Texten selbst gab es mehrere Spalten in den Daten, und es konnte viel mehr aus ihnen herausgedrückt werden als ich. Am einfachsten ist es, die Zielcodierung für einen Teil der Spalten durchzuführen.
- Lernen Sie nicht aus allen Daten! Es gab viele Daten (ungefähr 17 Millionen Zeilen) und es war völlig optional, alle zum Testen von Hypothesen zu verwenden. Training und Vorverarbeitung waren sehr langsam, und ich hätte eindeutig Zeit, um interessantere Hypothesen zu testen.
- < Umstrittener Rat > Sie müssen nicht nach einem Killermodell suchen. Ich habe mich lange mit Elmo und Bert beschäftigt, in der Hoffnung, dass sie mich sofort zu einem hohen Platz führen würden, und als Ergebnis habe ich vorab trainierte FastText-Einbettungen für die russische Sprache verwendet. Mit Elmo war es nicht möglich, eine bessere Geschwindigkeit zu erreichen, aber mit Bert konnte ich es nicht herausfinden.
- < Kontroverse Ratschläge > Suchen Sie nicht nach einer Killer-Funktion. Beim Betrachten der Daten habe ich festgestellt, dass im Bereich von 1 Prozent der Texte tatsächlich keinen Text enthalten! Aber dann gab es Links zu einigen Ressourcen, und ich schrieb einen einfachen Parser, der die Site öffnete und den Namen und die Beschreibung herausholte. Es scheint eine gute Idee zu sein, aber dann wurde ich mitgerissen, entschied mich, alle Links für alle Texte zu analysieren und verlor wieder viel Zeit. All dies führte zu keiner signifikanten Verbesserung des Endergebnisses (obwohl ich es zum Beispiel mit Stemming herausgefunden habe).
- Klassische Funktionen funktionieren. Google zum Beispiel "Text Features kaggle", lesen und fügen Sie alles hinzu. TF-IDF ergab eine Verbesserung, statistische Merkmale, wie die Länge des Textes, das Wort, die Menge der Interpunktion auch.
- Wenn DateTime-Spalten vorhanden sind, sollten Sie diese in mehrere separate Funktionen (Stunden, Wochentage usw.) analysieren. Welche Funktionen hervorgehoben werden sollen, sollte mit Grafiken / einigen Metriken analysiert werden. Hier habe ich alles richtig gemacht und die notwendigen Funktionen ausgewählt, aber eine normale Analyse würde nicht schaden (zum Beispiel wie im Finale).
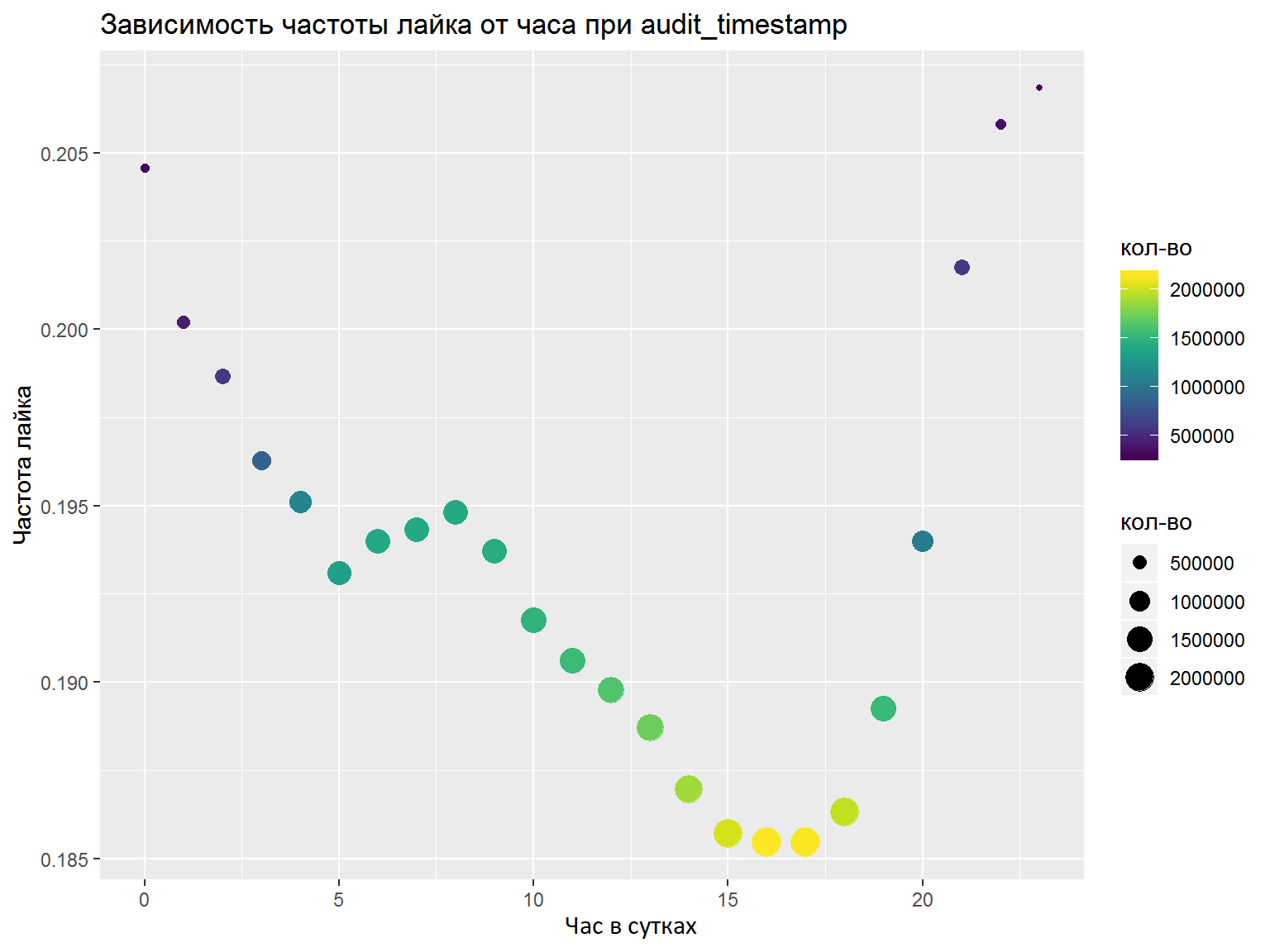
Als Ergebnis des Wettbewerbs trainierte ich ein Keras-Modell mit Faltung gemäß den Worten und ein anderes basierend auf LSTM und GRU. Sowohl dort als auch dort wurden vorab trainierte FastText-Einbettungen für die russische Sprache verwendet (ich habe eine Reihe anderer Einbettungen ausprobiert, aber diese funktionierten am besten). Nachdem ich die Vorhersagen gemittelt hatte, belegte ich unter 76 Teilnehmern den siebten Platz.
Bereits nach der ersten Phase wurde ein Artikel von Nikolai Anokhin veröffentlicht , der den zweiten Platz belegte (er nahm am Wettbewerb teil), und seine Entscheidung wurde bis zu einem bestimmten Zeitpunkt wiederholt, aber er ging aufgrund des Aufmerksamkeitsmechanismus für den Abfrageschlüsselwert weiter.
Zweite Stufe OK & IDAO
Die zweiten Phasen der Wettbewerbe fanden fast hintereinander statt, daher habe ich beschlossen, sie gemeinsam zu prüfen.
Zunächst landete ich mit dem neu gewonnenen Team im beeindruckenden Büro von Mail.ru, wo es unsere Aufgabe war, die Modelle der drei Tracks aus der ersten Phase zu kombinieren - Text, Bilder und Zusammenarbeit. Dafür wurden etwas mehr als 2 Tage eingeplant, was sich als sehr klein herausstellte. Tatsächlich konnten wir unsere Ergebnisse der ersten Stufe nur wiederholen, ohne einen Gewinn von der Vereinigung zu erhalten. Infolgedessen haben wir den 5. Platz belegt, aber das Textmodell konnte nicht verwendet werden. Wenn man sich die Entscheidungen anderer Teilnehmer ansieht, scheint es sich gelohnt zu haben, die Texte zu gruppieren und dem Kollaborationsmodell hinzuzufügen. Ein Nebeneffekt dieser Phase waren neue Eindrücke, Bekanntschaften und Kommunikation mit coolen Teilnehmern und Organisatoren sowie schwerer Schlafmangel, der das Ergebnis der IDAO-Endphase beeinflusst haben könnte.
Die Aufgabe in der persönlichen Phase des IDAO 2019-Finales bestand darin, die Wartezeit für eine Bestellung von Yandex-Taxifahrern am Flughafen vorherzusagen. In Phase 2 wurden 3 Aufgaben = 3 Flughäfen zugewiesen. Für jeden Flughafen werden pro Minute Daten zur Anzahl der Taxibestellungen für sechs Monate angegeben. Die Bestelldaten für den nächsten Monat und pro Minute für die letzten 2 Wochen wurden als Testdaten angegeben. Es gab nicht genug Zeit (1,5 Tage), die Aufgabe war ziemlich spezifisch, nur eine Person kam vom Team zum Wettbewerb - und infolgedessen war der traurige Ort näher am Ende. Von den interessanten Ideen gab es Versuche, externe Daten zu verwenden: Wetter, Staus und Statistiken zu Yandex-Taxibestellungen. Obwohl die Organisatoren nicht sagten, was die Flughäfen waren, schlugen viele Teilnehmer vor, Sheremetyevo, Domodedovo und Vnukovo zu sein. Obwohl diese Annahme nach dem Wettbewerb widerlegt wurde, verbesserten Merkmale, beispielsweise aus den Wetterdaten von Moskau, das Ergebnis sowohl bei der Validierung als auch in der Rangliste.
Fazit
- ML-Wettbewerbe sind cool und interessant! Es gibt eine Anwendung für Fähigkeiten in der Datenanalyse sowie in listigen Modellen und Techniken, und nur gesunder Menschenverstand ist willkommen.
- ML ist bereits eine riesige Wissensschicht, die exponentiell zu wachsen scheint. Ich habe mir zum Ziel gesetzt, verschiedene Bereiche (Signale, Bilder, Tabellen, Text) kennenzulernen und habe bereits erkannt, wie viel ich lernen muss. Nach diesen Wettbewerben habe ich mich beispielsweise entschlossen, Folgendes zu untersuchen: Clustering-Algorithmen, fortgeschrittene Techniken für die Arbeit mit Bibliotheken zur Erhöhung des Gradienten (insbesondere die Arbeit mit CatBoost auf der GPU), Kapselnetzwerke und den Aufmerksamkeitsmechanismus für Abfrageschlüsselwerte.
- Kein einziges Kaggle! Es gibt viele andere Wettbewerbe, bei denen es zumindest einfacher ist, ein T-Shirt zu bekommen, und es gibt mehr Chancen für andere Preise.
- Chat! Im Bereich des maschinellen Lernens und der Datenanalyse gibt es bereits eine große Community, es gibt thematische Gruppen in Telegramm-, Slack- und Serious-Bereichen von Mail.ru, Yandex und anderen Unternehmen, die Fragen beantworten und Anfängern helfen und ihre Reise in diesem Wissensbereich fortsetzen.
- Ich rate jedem, der vom vorherigen Absatz durchdrungen ist, das Datenfest zu besuchen - eine große kostenlose Konferenz in Moskau, die vom 10. bis 11. Mai stattfinden wird.