Ich habe mit Dutzenden von QS-Ingenieuren aus verschiedenen Unternehmen gesprochen, und jeder von ihnen hat darüber gesprochen, dass sie unterschiedliche Systeme und Tools für die Fehlerverfolgung verwenden. Wir haben auch einige davon ausprobiert, und ich habe beschlossen, die Lösung, zu der wir gekommen sind, zu teilen.

Intro
Ich werde banal sein. Fehler treten auf und werden in verschiedenen Phasen des Entwicklungsprozesses erkannt. Daher können Sie die Fehler abhängig von der Zeit, zu der sie erkannt wurden, in Kategorien einteilen:
- Mängel . Dies sind die Fehler, die die Entwickler beim Sägen neuer Funktionen gemacht haben. Solche Fehler werden bei Recherchen oder Abnahmetests neuer Funktionen an Entwicklungsständen von Teams festgestellt.
- Fehler in der Regression . Hierbei handelt es sich um Fehler, bei denen manuelle Regressionstests oder automatische UI- und API-Tests auf dem Stand für Code-Integration gefunden werden.
- Bugs mit einem Verkauf . Dies sind Probleme, die Mitarbeiter oder Kunden beim technischen Support gefunden und kontaktiert haben.
Wo haben wir angefangen oder Jira
Vor zwei Jahren hatten wir ein engagiertes Team von Testern, die das Produkt manuell testeten, nachdem sie den Code aller Teams integriert hatten. Bis zu diesem Punkt wurde der Code von Entwicklern an Entwicklerständen getestet. Fehler, die die Tester gefunden haben, wurden im Backlog in Jira aufgezeichnet. Fehler wurden in einem gemeinsamen Rückstand gespeichert und mit anderen Aufgaben von Sprint zu Sprint verschoben. Jeder Sprint bekam zwei oder drei Fehler und wurde repariert, aber die meisten blieben am Ende des Rückstands:
- Einer der Gründe, warum sich Fehler im Backlog ansammeln, ist, dass sie die Benutzer nicht stören. Solche Fehler haben eine niedrige Priorität und werden nicht behoben.
- Wenn das Unternehmen keine klaren und verständlichen Regeln zum Feststellen von Fehlern hat, können Tester dasselbe Problem mehrmals hinzufügen, da sie den bereits hinzugefügten Fehlerbericht in dieser Liste nicht finden konnten.
- Ein weiterer Grund kann sein, dass unerfahrene Tester an dem Projekt beteiligt sind. Es ist ein Fehler für Anfänger, in die Fehlerverfolgung alle während des Betriebs gefundenen Fehler einzutragen. Unerfahrene Tester sind der Ansicht, dass der Zweck des Testens darin besteht, nach Fehlern zu suchen, anstatt Informationen über die Qualität des Produkts bereitzustellen und das Auftreten von Fehlern zu verhindern.
Ich werde ein einfaches Beispiel geben. Beim Erstellen von Berichten in den Datumseingabefeldern wird das Datum standardmäßig ersetzt. Wenn Sie das Datum im Popup ändern, können Sie heute erneut auswählen und das Datumseingabefeld wird gelöscht.
Ich habe den Verdacht, dass während des gesamten Lebens unseres Netzwerks niemand außer Testern diesen Fehler nicht reproduziert hat. Solche Fehler machen die meisten Fehler aus, die nicht behoben wurden.
Wenn bei diesem Ansatz alle gefundenen Fehler eingegeben werden, werden einige von ihnen dupliziert und die meisten dieser Fehler werden nicht repariert. Probleme treten auf:
- Tester sind demotiviert, da die gefundenen Fehler von den Entwicklern nicht behoben werden. Man hat das Gefühl, dass die Arbeit keinen Sinn ergibt.
- Für den Produktbesitzer ist es schwierig, einen Rückstand mit vielen Fehlern zu verwalten.
Auf Wiedersehen Jira, es lebe Kaiten
Im Frühjahr 2018 verließen wir Jira und zogen nach Kaiten. Der Werkzeugwechsel wurde durch Gründe verursacht, über die Andrei Arefiev in dem Artikel
„Warum Dodo Pizza Kaiten anstelle von Trello und Jira verwendete“ schrieb. Nach dem Umzug nach Kaiten hat sich unser Ansatz zur Arbeit mit Fehlern nicht geändert:
- Unvollkommenheiten wurden auf den Befehlstafeln aufgezeichnet und die Entwickler entschieden unabhängig voneinander, ob sie repariert werden sollten oder nicht.
- Die Fehler, die in der Regression gefunden wurden (sie wurde von einem speziellen Testerteam ausgeführt), wurden im Release-Zweig repariert und gaben den Code erst frei, nachdem alle Probleme behoben waren. Wir haben beschlossen, dass es logischer ist, Informationen über diese Probleme im Testerkanal in Slack zu speichern und zu sammeln. Die Tester schrieben eine Nachricht, die eine Legende, eine Liste von Fehlern mit Protokollen und die Namen der Entwickler enthielt, die die Aufgabe übernommen hatten. Mit Hilfe von Emoji haben sie den Status geändert und in Trades, die sie besprochen haben, Screenshots angewendet und synchronisiert. Dieses Format eignet sich für Tester. Einige Entwickler mochten diese Methode nicht, da im Chat parallel eine andere Korrespondenz stattfand und diese Nachricht aufging und nicht sichtbar war. Wir haben es behoben, aber es hat das Leben nicht wesentlich vereinfacht.

- Die auf dem Produkt gefundenen Fehler wurden im Backlog, Product Owner, aufgezeichnet, priorisiert und diejenigen ausgewählt, die repariert werden sollen.
Experimentierzeit oder nicht
Wir haben uns entschlossen, mit den Formaten zu experimentieren und in Kaiten ein separates Board erstellt, auf dem wir Fehler gespeichert und den Status geändert haben. Wir haben die Erstellung eines Fehlerberichts vereinfacht, um weniger Zeit zu verbringen. Beim Hinzufügen einer Karte zu Kaiten haben Tester Entwickler markiert. Eine Benachrichtigung wurde an ihre Mail darüber gesendet. Wir haben dieses Board auf einen Monitor gestellt, der im Gang in der Nähe unseres Arbeitsplatzes hing, damit Entwickler den Fortschritt sehen und der Testprozess transparent werden konnte. Diese Praxis hat auch keine Wurzeln geschlagen, da der Hauptkommunikationskanal Slack ist. Unsere Entwickler checken nicht oft E-Mails. Daher funktionierte diese Lösung schnell nicht mehr und wir kehrten zu Slack zurück.
Bring die Ameisen zurück
Nach einem fehlgeschlagenen Board-Experiment in Kaiten waren einige Entwickler immer noch gegen das Nachrichtenformat in Slack. Und wir begannen zu überlegen, wie wir Fehler in der Lücke verfolgen und Probleme lösen können, die Entwickler daran hinderten. Als Ergebnis der Suche stieß ich auf eine Anwendung für Slack, Workast, mit der die Arbeit mit Kleinkindern direkt im Messenger organisiert werden kann. Wir dachten, dass Sie mit dieser Anwendung den Prozess der Arbeit mit Fehlern flexibler verwalten können. Diese Anwendung hatte ihre Vorteile: Statusänderung und Zuweisung an Entwickler auf Knopfdruck, erledigte Aufgaben wurden ausgeblendet und die Nachricht wuchs nicht zu einer enormen Größe.
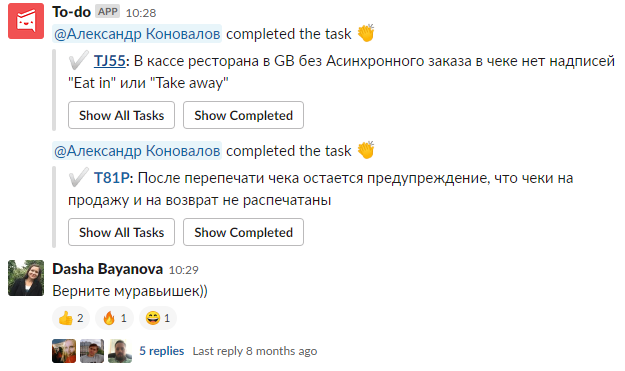
So lösten sich die gelösten Probleme in der Todo-Anwendung und forderten die Rückgabe von "Ameisen" an. Nachdem die Testphase der Workast-Anwendung beendet war, haben wir beschlossen, sie abzubrechen. Durch die Verwendung dieser Anwendung kamen wir zu dem gleichen Ergebnis wie bei der Verwendung von Jira. Es gab einige Fehler, die auf dieser Liste von Regression zu Regression wanderten. Und mit jeder Iteration gab es mehr von ihnen. Vielleicht hat es sich gelohnt, den Prozess der Arbeit mit dieser Erweiterung abzuschließen, sie zu kaufen und zu verwenden, aber wir haben es nicht getan.
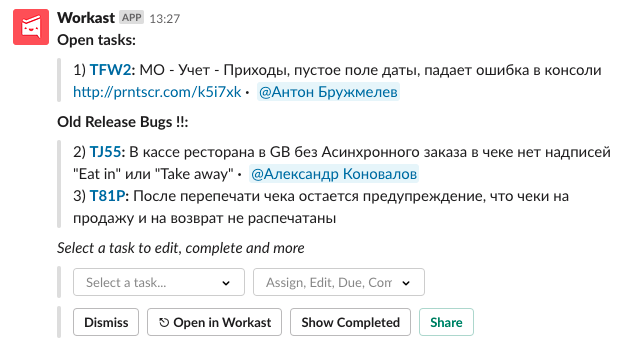
Unser perfekter Weg, um jetzt mit Fehlern umzugehen
Ende 2018 - Anfang 2019 - gab es in unserem Unternehmen eine Reihe von Änderungen, die sich auf den Prozess der Arbeit mit Fehlern auswirkten.
Erstens hatten wir kein engagiertes Testerteam. Alle Tester verteilten sich auf Entwicklungsteams, um die Kompetenz der Testteams zu stärken. Dank dessen haben wir früher vor der Integration des Befehlscodes begonnen, Fehler zu finden.
Zweitens haben wir manuelle Regressionstests zugunsten der automatischen aufgegeben.
Drittens haben wir eine „Null-Fehler-Richtlinie“ eingeführt. In dem Artikel "
#zerobugpolicy oder wie wir Fehler beheben " beschreibt
bevzuk, wie wir die Fehler auswählen, die wir beheben.
Heute ist der Prozess der Arbeit mit Fehlern wie folgt:
- Mängel . Tester melden das Problem Analysten oder Produktmanagern. Sie gehen, zeigen, reproduzieren, erklären, wie sich dies auf Kunden auswirkt, und entscheiden, ob es vor der Veröffentlichung repariert werden muss oder später repariert werden kann oder ob es sich überhaupt nicht lohnt, es zu reparieren.
- Fehler in der Regression , die bei Autotests festgestellt wurden, werden von dem Team behoben, das diesen Teil des Systems berührt hat, und wir werden diesen Code erst veröffentlichen, wenn wir das Problem gelöst haben. Tester beheben diese Fehler in einem beliebigen Format auf dem Release-Kanal in Slack.
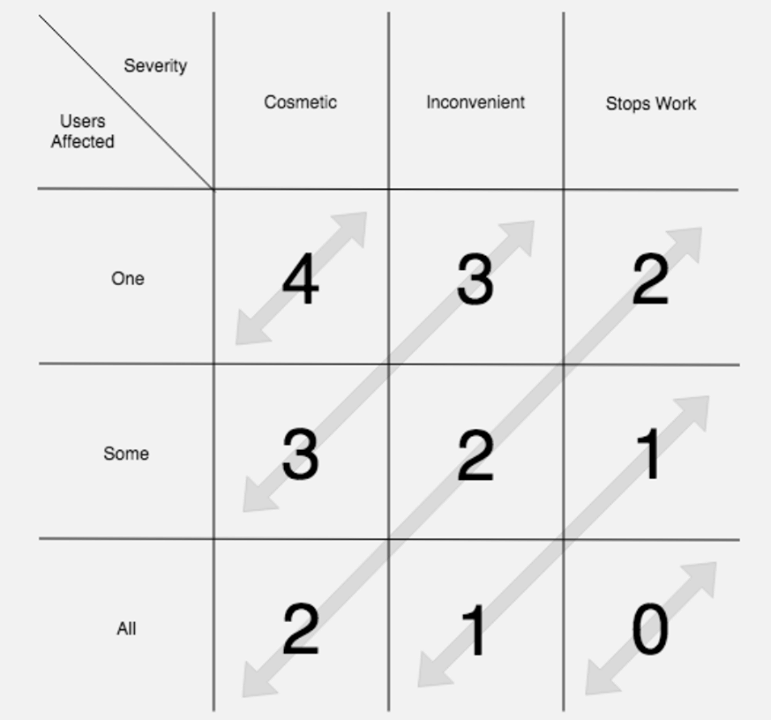
- Bugs mit einem Verkauf . Solche Fehler gehen direkt an die Aufgabenbesitzer. Analysten führen Fehler in der Prioritätsmatrix des Fehlers aus und fügen sie dem Backlog hinzu oder beheben sie selbst, indem sie Statistiken über Treffer zu diesem Problem sammeln.
Zusammenfassung
Kurz gesagt, wir haben das Bug-Tracking-System grundsätzlich aufgegeben . Mit diesem Ansatz zur Arbeit mit Fehlern haben wir verschiedene Probleme gelöst:
- Tester sind nicht verärgert, weil die Fehler, die sie bei der Fehlerverfolgung finden und auslösen, nicht behoben sind.
- Tester verbringen keine Zeit mit einer Institution und einer vollständigen Beschreibung von Fehlern, die niemand lesen wird.
- PO ist einfacher zu verwalten, wenn keine Totlast vorhanden ist.
Ich möchte nicht sagen, dass das Verfolgen von Fehlern nutzlos ist. Die Fehler, die wir zur Arbeit bringen, werden wie alle anderen Aufgaben verfolgt. Ein Bug-Tracking-System ist jedoch kein erforderliches Testattribut. Es muss nicht nur verwendet werden, weil die meisten Unternehmen es verwenden und dies in der Branche üblich ist. Sie müssen „mit dem Kopf denken“ und Werkzeuge für Ihre Prozesse und Bedürfnisse anprobieren. Es ist ideal für uns, jetzt ohne Bug-Tracking-System zu arbeiten. Während eines halben Jahres solcher Arbeit haben wir nie daran gedacht, dorthin zurückzukehren und wieder alle Fehler dort zu bekommen.
Und wie ist der Prozess der Arbeit mit Fehlern in Ihrem Unternehmen angeordnet?