Ich schlage vor, dass Sie sich mit dem Protokoll des Berichts von Alexander Sigachev von Inventos "Der Entwicklungs- und Testprozess mit Docker + Gitlab CI" vertraut machen.
Diejenigen, die gerade erst mit der Implementierung des Entwicklungs- und Testprozesses auf Basis von Docker + Gitlab CI beginnen, stellen häufig grundlegende Fragen. Wo soll ich anfangen? Wie organisieren? Wie teste ich?
Dieser Bericht ist gut geeignet, um Sie strukturiert über den Entwicklungs- und Testprozess mit Docker und Gitlab CI zu informieren. 2017 Bericht selbst. Ich denke, dass Sie aus diesem Bericht die Grundlagen, Methoden, Ideen und Nutzungserfahrungen ziehen können.
Wen kümmert es bitte unter der Katze.
Ich heiße Alexander Sigachev. Ich arbeite für Inventos. Ich erzähle Ihnen von meinen Erfahrungen mit Docker und wie wir es schrittweise in Projekten im Unternehmen implementieren.
Thema: Entwicklungsprozess mit Docker und Gitlab CI.
Dies ist mein zweiter Vortrag über Docker. Zum Zeitpunkt des ersten Berichts haben wir Docker nur in der Entwicklung auf Entwicklungsmaschinen verwendet. Die Anzahl der Mitarbeiter, die Docker verwendeten, betrug ca. 2-3 Personen. Allmählich wurden Erfahrungen gesammelt und wir gingen etwas weiter. Link zu unserem ersten Bericht .
Was wird in diesem Bericht stehen? Wir werden unsere Erfahrungen darüber teilen, welchen Rechen wir gesammelt haben, welche Probleme wir gelöst haben. Nicht überall war es schön, aber man durfte weitermachen.
Unser Motto lautet: Dockerisieren Sie alles, was unsere Hände erreichen.
Welche Probleme lösen wir?
Wenn ein Unternehmen mehrere Teams hat, ist der Programmierer eine gemeinsam genutzte Ressource. Es gibt Phasen, in denen ein Programmierer aus einem Projekt herausgezogen und für einige Zeit einem anderen Projekt übergeben wird.
Damit der Programmierer schnell darauf eingehen kann, muss er den Quellcode des Projekts herunterladen und die Umgebung so schnell wie möglich starten, damit er die Aufgaben dieses Projekts weiter lösen kann.
Wenn Sie bei Null anfangen, reicht die Dokumentation im Projekt normalerweise nicht aus. Nur Oldtimer haben Informationen zur Einrichtung. Mitarbeiter richten ihren Arbeitsplatz in ein bis zwei Tagen selbständig ein. Um dies zu beschleunigen, haben wir Docker verwendet.
Der nächste Grund ist die Standardisierung der Einstellungen in der Entwicklung. Nach meiner Erfahrung ergreifen Entwickler immer die Initiative. In jedem fünften Fall wird eine benutzerdefinierte Domain eingegeben, z. B. vasya.dev. In der Nähe befindet sich der Nachbar Petya, dessen Domain petya.dev ist. Sie entwickeln eine Website oder eine Komponente des Systems unter Verwendung dieses Domainnamens.
Wenn das System wächst und diese Domänennamen in die Konfiguration fallen, liegt ein Konflikt zwischen den Entwicklungsumgebungen vor und der Pfad der Site wird neu geschrieben.
Das gleiche passiert mit den Datenbankeinstellungen. Jemand kümmert sich nicht um die Sicherheit und arbeitet mit einem leeren Root-Passwort. Jemand in der Installationsphase forderte MySQL ein Kennwort an, und es stellte sich heraus, dass das Kennwort eins 123 war. Es kommt häufig vor, dass sich die Datenbankkonfiguration abhängig vom Commit des Entwicklers ständig ändert. Jemand hat korrigiert, jemand hat die Konfiguration nicht korrigiert. Es gab Tricks, als wir eine Art .gitignore in .gitignore und jeder Entwickler eine Datenbank installieren musste. Dies erschwerte den Startvorgang. Unter anderem müssen Sie sich an die Datenbank erinnern. Die Datenbank muss initialisiert werden, ein Passwort muss registriert sein, ein Benutzer muss registriert sein, eine Platte muss erstellt werden und so weiter.
Ein weiteres Problem sind die verschiedenen Versionen von Bibliotheken. Es kommt oft vor, dass ein Entwickler mit verschiedenen Projekten arbeitet. Es gibt ein Legacy-Projekt, das vor fünf Jahren begann (ab 2017 - Anmerkung. Ed.). Zu Beginn haben wir mit MySQL 5.5 begonnen. Es gibt auch moderne Projekte, in denen wir versuchen, modernere Versionen von MySQL einzuführen, zum Beispiel 5.7 oder älter (2017 - Anmerkung. Ed.)
Jeder, der mit MySQL arbeitet, weiß, dass diese Bibliotheken Abhängigkeiten ziehen. Es ist ziemlich problematisch, zwei Basen zusammen zu betreiben. Zumindest ist es für alte Kunden problematisch, eine Verbindung zur neuen Datenbank herzustellen. Dies verursacht wiederum mehrere Probleme.
Das nächste Problem ist, wenn der Entwickler auf dem lokalen Computer arbeitet, lokale Ressourcen, lokale Dateien und lokalen RAM verwendet. Die gesamte Interaktion zum Zeitpunkt der Entwicklung der Lösung des Problems erfolgt im Rahmen der Tatsache, dass sie auf einer Maschine funktioniert. Ein Beispiel ist, wenn wir Backend-Server in Production 3 haben und der Entwickler die Dateien im Stammverzeichnis speichert und von dort aus nginx die Dateien verwendet, um auf die Anfrage zu antworten. Wenn ein solcher Code in die Produktion fällt, stellt sich heraus, dass die Datei auf einem der drei Server vorhanden ist.
Jetzt entwickelt sich die Richtung der Mikrodienste. Wenn wir unsere großen Anwendungen in einige kleine Komponenten aufteilen, die miteinander interagieren. Auf diese Weise können Sie die Technologie für einen bestimmten Aufgabenstapel auswählen. Außerdem können Sie die Arbeit und den Verantwortungsbereich zwischen Entwicklern teilen.
Der auf JS entwickelte Frondend-Entwickler hat praktisch keinen Einfluss auf das Backend. Der Backend-Entwickler wiederum entwickelt in unserem Fall Ruby on Rails und stört Frondend nicht. Die Interaktion erfolgt über die API.
Als Bonus konnten wir mit Docker Ressourcen für Staging nutzen. Jedes Projekt erforderte aufgrund seiner Spezifität bestimmte Einstellungen. Physisch war es notwendig, entweder einen virtuellen Server auszuwählen und separat zu konfigurieren oder eine variable Umgebung gemeinsam zu nutzen, und Projekte konnten sich je nach Version der Bibliotheken gegenseitig beeinflussen.

Werkzeuge Was benutzen wir?
- Direkt Docker selbst. Dockerfile beschreibt Abhängigkeiten einer Anwendung.
- Docker-Compose ist ein Bundle, das einige unserer Docker-Anwendungen zusammenführt.
- GitLab verwenden wir zum Speichern des Quellcodes.
- Wir verwenden GitLab-CI für die Systemintegration.

Der Bericht besteht aus zwei Teilen.
Im ersten Teil wird erläutert, wie Docker auf Entwicklungsmaschinen ausgeführt wird.
Im zweiten Teil wird erläutert, wie Sie mit GitLab interagieren, wie wir Tests ausführen und wie wir Staging einführen.
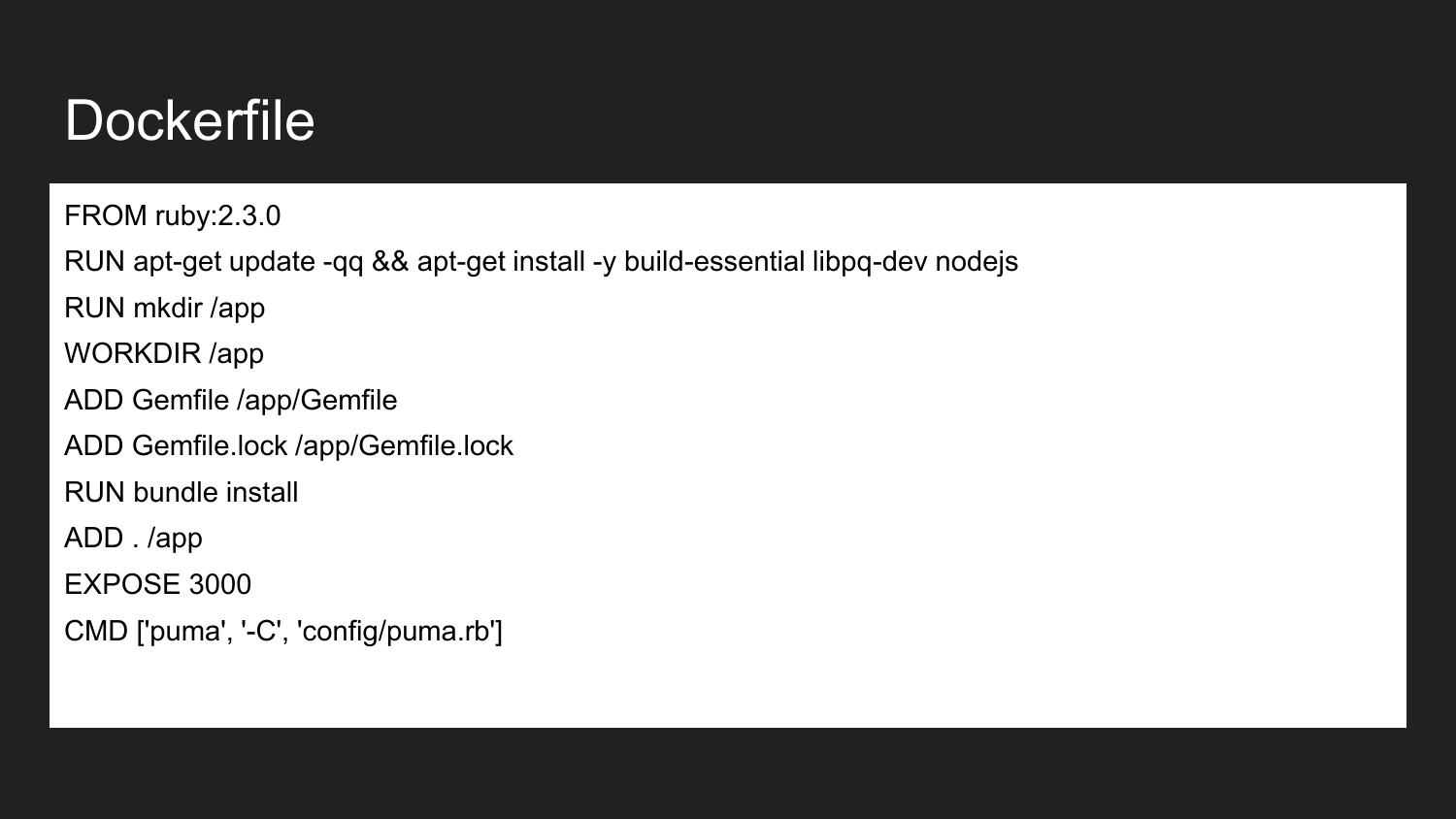
Docker ist eine Technologie, mit der (unter Verwendung eines deklarativen Ansatzes) die erforderlichen Komponenten beschrieben werden können. Dies ist ein Beispiel für eine Docker-Datei. Hier geben wir bekannt, dass wir vom offiziellen Ruby Docker-Image erben: 2.3.0. Es enthält die installierte Ruby-Version 2.3. Wir installieren die notwendigen Build-Bibliotheken und NodeJS. Wir beschreiben, dass wir das Verzeichnis /app erstellen. Weisen Sie das App-Verzeichnis dem Arbeitsverzeichnis zu. In diesem Verzeichnis platzieren wir das erforderliche Minimum Gemfile und Gemfile.lock. Dann erstellen wir die Projekte, die dieses Abhängigkeitsimage installieren. Wir geben an, dass der Container bereit ist, den externen Port 3000 abzuhören. Der letzte Befehl ist der Befehl, der unsere Anwendung direkt startet. Wenn wir den Projektstartbefehl ausführen, versucht die Anwendung, den angegebenen Befehl auszuführen und zu starten.

Dies ist ein minimales Beispiel für eine Docker-Compose-Datei. In diesem Fall zeigen wir, dass eine Verbindung zwischen den beiden Containern besteht. Dies ist direkt an den Datenbankdienst und den Webdienst. Unsere Webanwendungen erfordern in den meisten Fällen eine Datenbank als Backend zum Speichern von Daten. Da wir MySQL verwenden, ist das Beispiel MySQL - aber nichts hindert uns daran, eine Art Freundesdatenbank (PostgreSQL, Redis) zu verwenden.
Wir nehmen das MySQL 5.7.14-Image aus der offiziellen Quelle mit unverändertem Docker-Hub. Das Bild, das für unsere Webanwendung verantwortlich ist, sammeln wir aus dem aktuellen Verzeichnis. Er sammelt beim ersten Start ein Bild für uns. Dann wird der Befehl gestartet, den wir hier ausführen. Wenn wir zurückgehen, werden wir sehen, dass der Startbefehl über Puma definiert wurde. Puma ist ein in Ruby geschriebener Dienst. Im zweiten Fall definieren wir neu. Dieser Befehl kann je nach unseren Anforderungen oder Aufgaben beliebig sein.
Wir beschreiben auch, was Sie benötigen, um den Port auf unserem Host-Computer von 3000 auf 3000 Portcontainer weiterzuleiten. Dies erfolgt automatisch mithilfe von iptables und eines eigenen Mechanismus, der direkt in Docker eingebettet ist.
Der Entwickler kann nach wie vor eine beliebige verfügbare IP-Adresse anwenden, z. B. 127.0.0.1 lokale oder externe IP-Adresse des Computers.
Die letzte Zeile besagt, dass der Webcontainer vom Datenbankcontainer abhängig ist. Wenn wir den Start des Webcontainers aufrufen, startet Docker-Compose die Datenbank für uns. Bereits zu Beginn der Datenbank (tatsächlich nach dem Start des Containers! Dies garantiert nicht die Bereitschaft der Datenbank) starten wir eine Anwendung, unser Backend.
Auf diese Weise können Sie Fehler vermeiden, wenn die Datenbank nicht ausgelöst wird, und Ressourcen sparen, wenn wir den Datenbankcontainer stoppen und die Ressourcen für andere Projekte freigeben.

Was gibt uns die Verwendung der Docker-Datenbank für das Projekt. Wir alle Entwickler korrigieren die Version von MySQL. Auf diese Weise können Sie einige Fehler vermeiden, die bei unterschiedlichen Versionen auftreten können, wenn sich Syntax, Konfiguration und Standardeinstellungen ändern. Auf diese Weise können Sie einen gemeinsamen Hostnamen für die Datenbank, die Anmeldung und das Kennwort angeben. Wir entfernen uns von den Zoonamen und Konflikten in den Konfigurationsdateien, die früher waren.
Wir können eine optimalere Konfiguration für die Entwicklungsumgebung verwenden, die sich von der Standardkonfiguration unterscheidet. MySQL ist standardmäßig auf schwachen Computern konfiguriert und die sofort einsatzbereite Leistung ist sehr gering.

Mit Docker können Sie den Python-, Ruby-, NodeJS- und PHP-Interpreter der gewünschten Version verwenden. Wir müssen keinen Versionsmanager mehr verwenden. Zuvor verwendete Ruby das RPM-Paket, mit dem die Version je nach Projekt geändert werden konnte. Auf diese Weise kann der Docker-Container auch Code reibungslos migrieren und zusammen mit Abhängigkeiten versionieren. Wir haben kein Problem damit, die Version sowohl des Interpreters als auch des Codes zu verstehen. Um die Version zu aktualisieren, senken Sie den alten Container und heben Sie den neuen Container an. Wenn etwas schief gelaufen ist, können wir den neuen Container absenken und den alten Container anheben.
Nach dem Zusammenstellen des Bildes sind die Container in Entwicklung und Produktion identisch. Dies gilt insbesondere für große Installationen.
 Im Frontend verwenden wir JavaScipt und NodeJS.
Im Frontend verwenden wir JavaScipt und NodeJS.
Jetzt haben wir das neueste Projekt bei ReacJS. Der Entwickler hat den gesamten Container ausgeführt und mithilfe von Hot-Reload entwickelt.
Als nächstes wird die Aufgabe des Zusammenstellens von JavaScipt gestartet und der in der Statik gesammelte Code wird durch nginx-Speicherressourcen bereitgestellt.
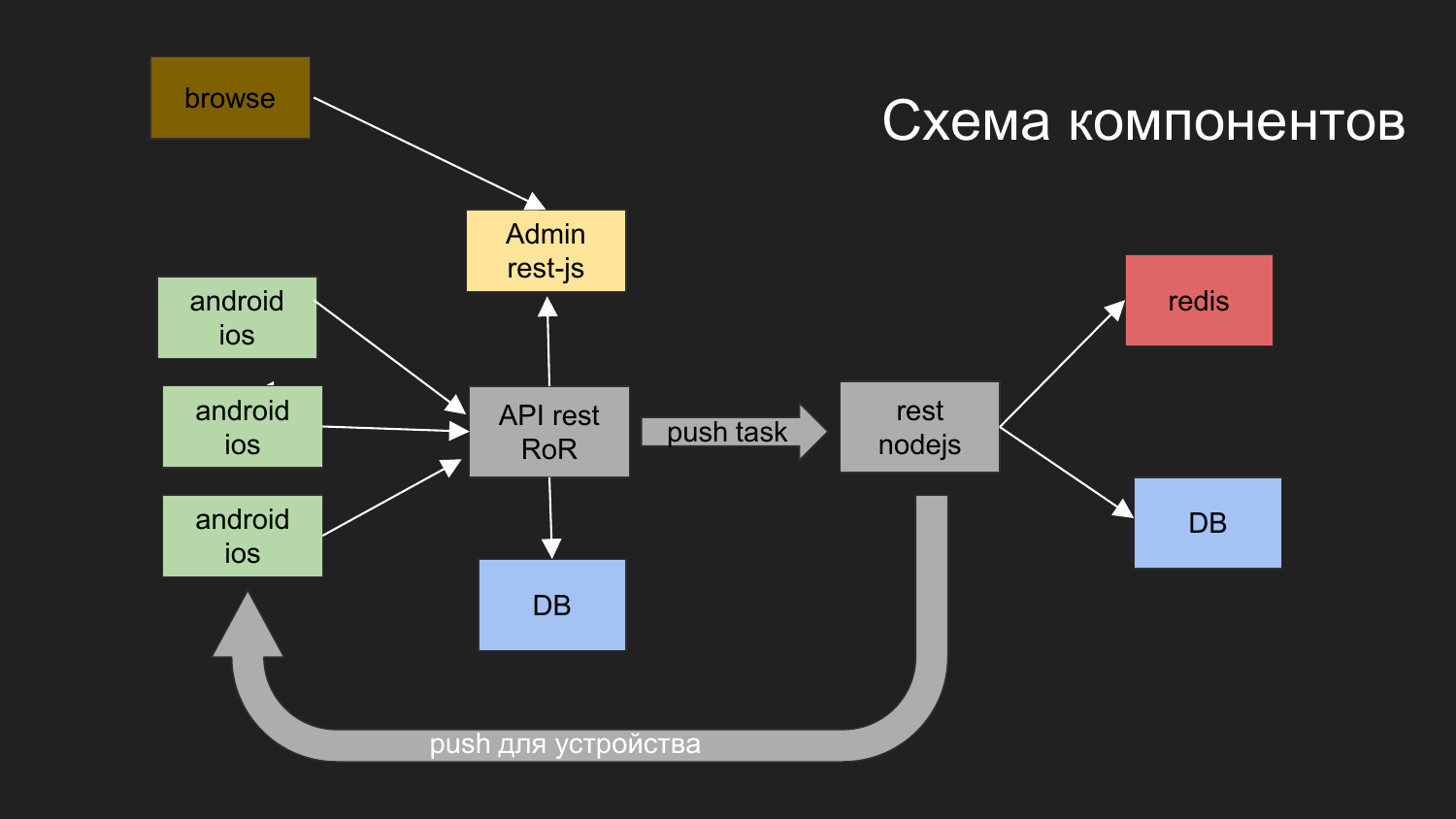
Hier habe ich ein Diagramm unseres letzten Projekts gegeben.
Welche Aufgaben haben Sie gelöst? Wir müssen ein System aufbauen, mit dem mobile Geräte interagieren. Sie bekommen Daten. Eine der Optionen besteht darin, Push-Benachrichtigungen an dieses Gerät zu senden.
Was haben wir dafür getan?
Wir haben in Anwendungskomponenten unterteilt, wie zum Beispiel: den Admin-Teil in JS, das Backend, das über die REST-Schnittstelle unter Ruby on Rails funktioniert. Das Backend interagiert mit der Datenbank. Das generierte Ergebnis wird an den Client weitergegeben. Der Administrator mit Backend und Datenbank interagiert über die REST-Schnittstelle.
Wir mussten auch Push-Benachrichtigungen senden. Zuvor hatten wir ein Projekt, in dem ein Mechanismus implementiert wurde, der für die Zustellung von Benachrichtigungen an mobile Plattformen verantwortlich ist.
Wir haben ein solches Schema entwickelt: Der Bediener des Browsers interagiert mit dem Admin-Panel, das Admin-Panel interagiert mit dem Backend, die Aufgabe besteht darin, Push-Benachrichtigungen zu senden.
Push-Benachrichtigungen interagieren mit einer anderen Komponente, die auf NodeJS implementiert ist.
Warteschlangen werden erstellt, und das Senden von Benachrichtigungen folgt einem eigenen Mechanismus.
Hier werden zwei Datenbanken gezeichnet. Derzeit verwenden wir mit Hilfe von Docker zwei unabhängige Datenbanken, die in keiner Weise mit sich selbst verbunden sind. Darüber hinaus verfügen sie über ein gemeinsames virtuelles Netzwerk, und die physischen Daten werden in verschiedenen Verzeichnissen auf dem Computer des Entwicklers gespeichert.
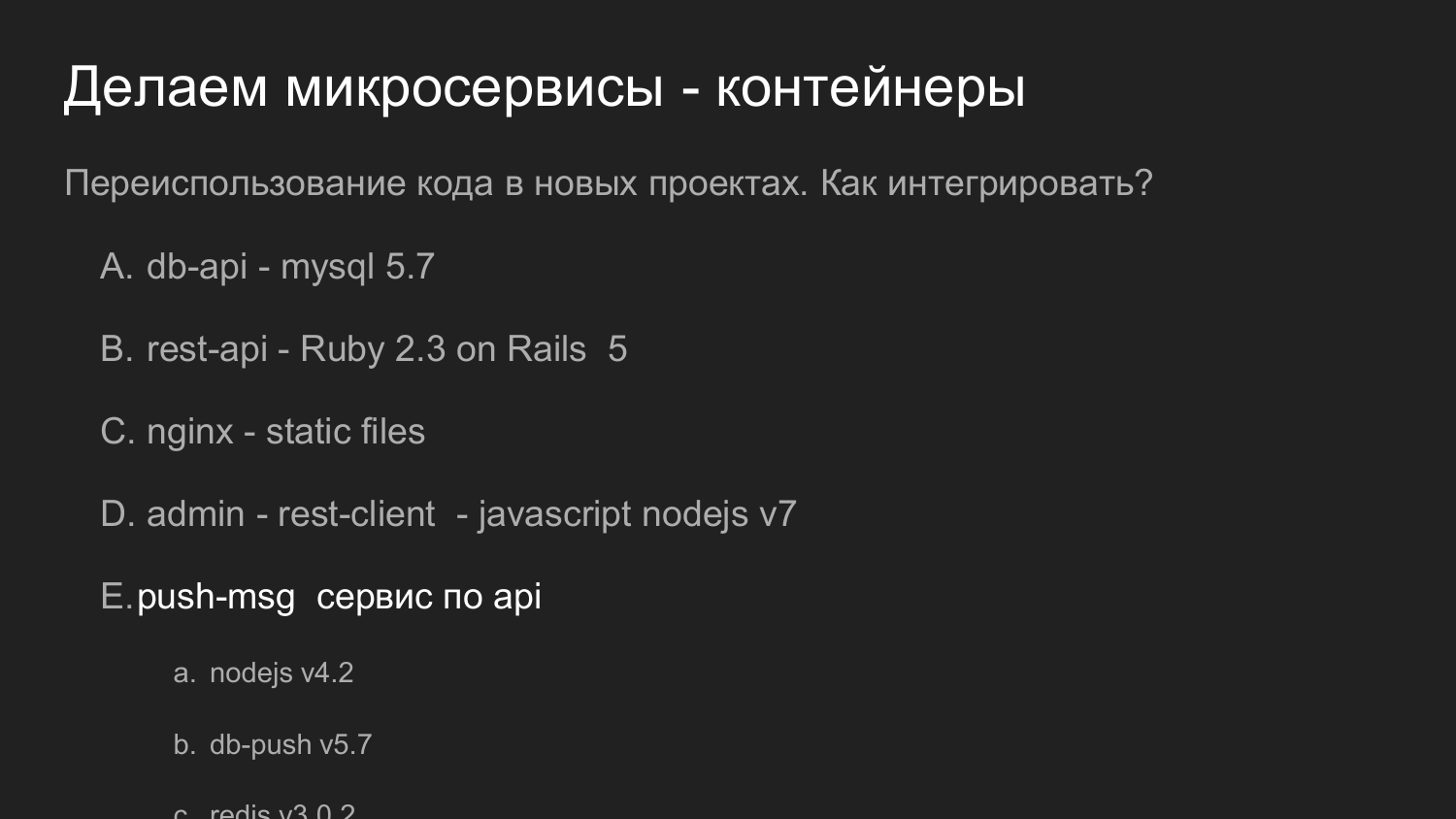
Das Gleiche, aber in Zahlen. Die Wiederverwendung von Code ist hier wichtig.
Wenn wir früher über die Wiederverwendung von Code in Form von Bibliotheken gesprochen haben, wird in diesem Beispiel unser Dienst, der auf Push-Benachrichtigungen reagiert, als vollständiger Server wiederverwendet. Es bietet eine API. Und schon mit unserer Neuentwicklung interagiert damit.
Zu diesem Zeitpunkt haben wir Version 4 von NodeJS verwendet. Jetzt (in 2017 - Anmerkung. Hrsg.) In jüngsten Entwicklungen verwenden wir Version 7 von NodeJS. Kein Problem bei neuen Komponenten, um neue Versionen von Bibliotheken anzuziehen.
Bei Bedarf können Sie die NodeJS-Version des Push-Benachrichtigungsdienstes umgestalten und aktualisieren.
Und wenn wir die API-Kompatibilität beibehalten können, können wir sie durch andere Projekte ersetzen, die zuvor verwendet wurden.

Was benötigen Sie, um Docker hinzuzufügen? Fügen Sie unserem Repository eine Docker-Datei hinzu, die die erforderlichen Abhängigkeiten beschreibt. In diesem Beispiel sind die Komponenten nach Logik unterteilt. Dies ist eine minimale Anzahl von Backend-Entwicklern.
Erstellen Sie beim Erstellen eines neuen Projekts eine Docker-Datei und beschreiben Sie das gewünschte Ökosystem (Python, Ruby, NodeJS). Das Docker-Compose beschreibt die notwendige Abhängigkeit - die Datenbank. Wir beschreiben, dass wir eine Datenbank dieser und jener Version benötigen, um die Daten dort irgendwo zu speichern.
Wir verwenden einen separaten dritten Container mit Nginx, um statisch zu rendern. Sie können Bilder hochladen. Das Backend legt sie in einem vorbereiteten Volume ab, das ebenfalls in einem Container mit Nginx montiert ist, der statisch ist.
Um die Nginx- und MySQL-Konfiguration zu speichern, haben wir den Docker-Ordner hinzugefügt, in dem wir die erforderlichen Konfigurationen speichern. Wenn ein Entwickler ein Git-Klon-Repository auf seinem Computer erstellt, bereitet er bereits ein Projekt für die lokale Entwicklung vor. Es stellt sich nicht die Frage, welcher Port oder welche Einstellungen angewendet werden sollen.

Darüber hinaus haben wir mehrere Komponenten: Admin, Inform-API, Push-Benachrichtigungen.
Um alles auszuführen, haben wir ein weiteres Repository namens dockerized-app erstellt. Derzeit verwenden wir mehrere Repositorys für jede Komponente. Sie unterscheiden sich nur logisch - in GitLab sieht es aus wie ein Ordner und auf dem Entwicklercomputer wie ein Ordner für ein bestimmtes Projekt. Eine Ebene darunter sind die Komponenten, die kombiniert werden.
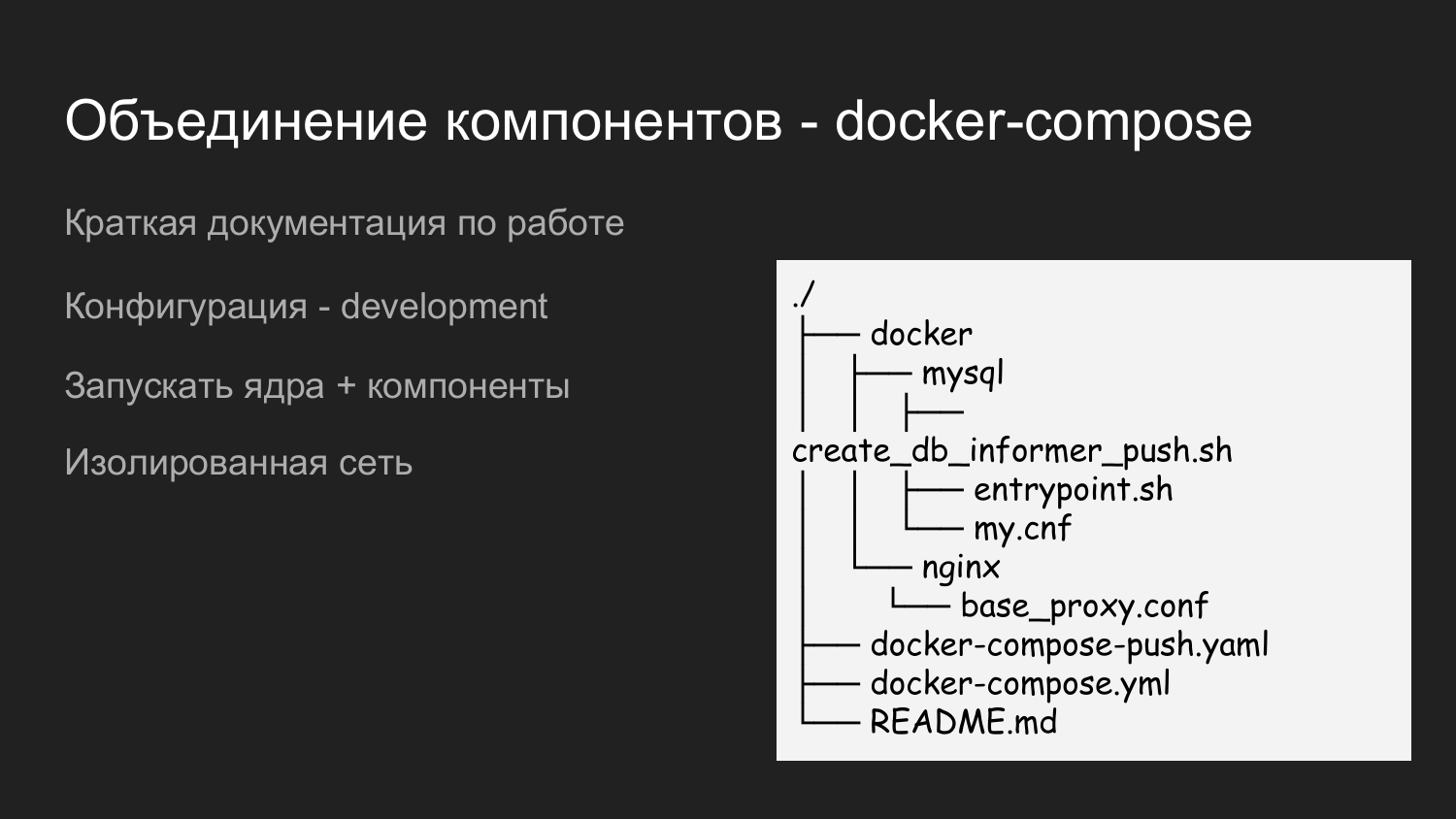
Dies ist nur ein Beispiel für den Inhalt der Docker-App. Wir bringen hier auch den Docker-Katalog mit, in dem wir die Konfigurationen eintragen, die für die Interaktion aller Komponenten erforderlich sind. Es gibt README.md, in dem kurz beschrieben wird, wie ein Projekt gestartet wird.
Hier haben wir zwei Docker-Compose-Dateien verwendet. Dies geschieht, um schrittweise ausgeführt werden zu können. Wenn ein Entwickler mit dem Kernel arbeitet, benötigt er keine Push-Benachrichtigungen. Dann startet er einfach die Docker-Compose-Datei und die Ressource wird entsprechend gespeichert.
Wenn eine Integration mit Push-Benachrichtigungen erforderlich ist, werden docker-compose.yaml und docker-compose-push.yaml gestartet.
Da sich docker-compose.yaml und docker-compose-push.yaml im Ordner befinden, wird automatisch ein einzelnes virtuelles Netzwerk erstellt.
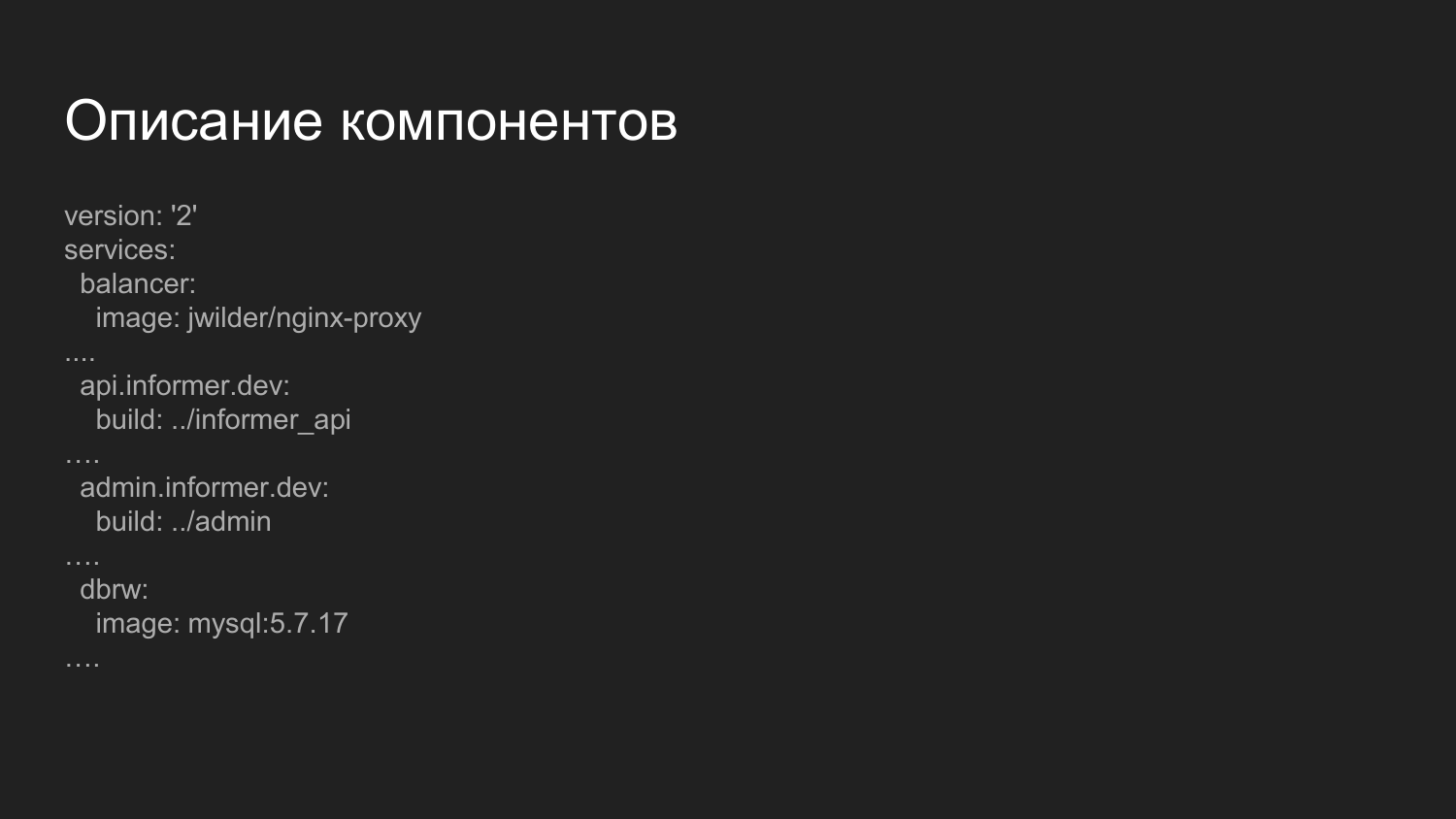
Beschreibung der Komponenten. Dies ist eine erweiterte Datei, die für das Sammeln von Komponenten verantwortlich ist. Was ist hier bemerkenswert? Hier stellen wir die Balancer-Komponente vor.
Dies ist ein vorgefertigtes Docker-Image, in dem nginx gestartet wird, und eine Anwendung, die den Docker-Socket abhört. Dynamisch, wenn Container ein- und ausgeschaltet werden, wird die nginx-Konfiguration neu generiert. Wir verteilen den Umgang mit Komponenten über Domainnamen der dritten Ebene.
Für die Entwicklungsumgebung verwenden wir die .dev-Domäne - api.informer.dev. Anwendungen mit der .dev-Domäne sind auf dem Computer des lokalen Entwicklers verfügbar.
Anschließend werden Konfigurationen auf jedes Projekt übertragen und alle Projekte gleichzeitig gestartet.
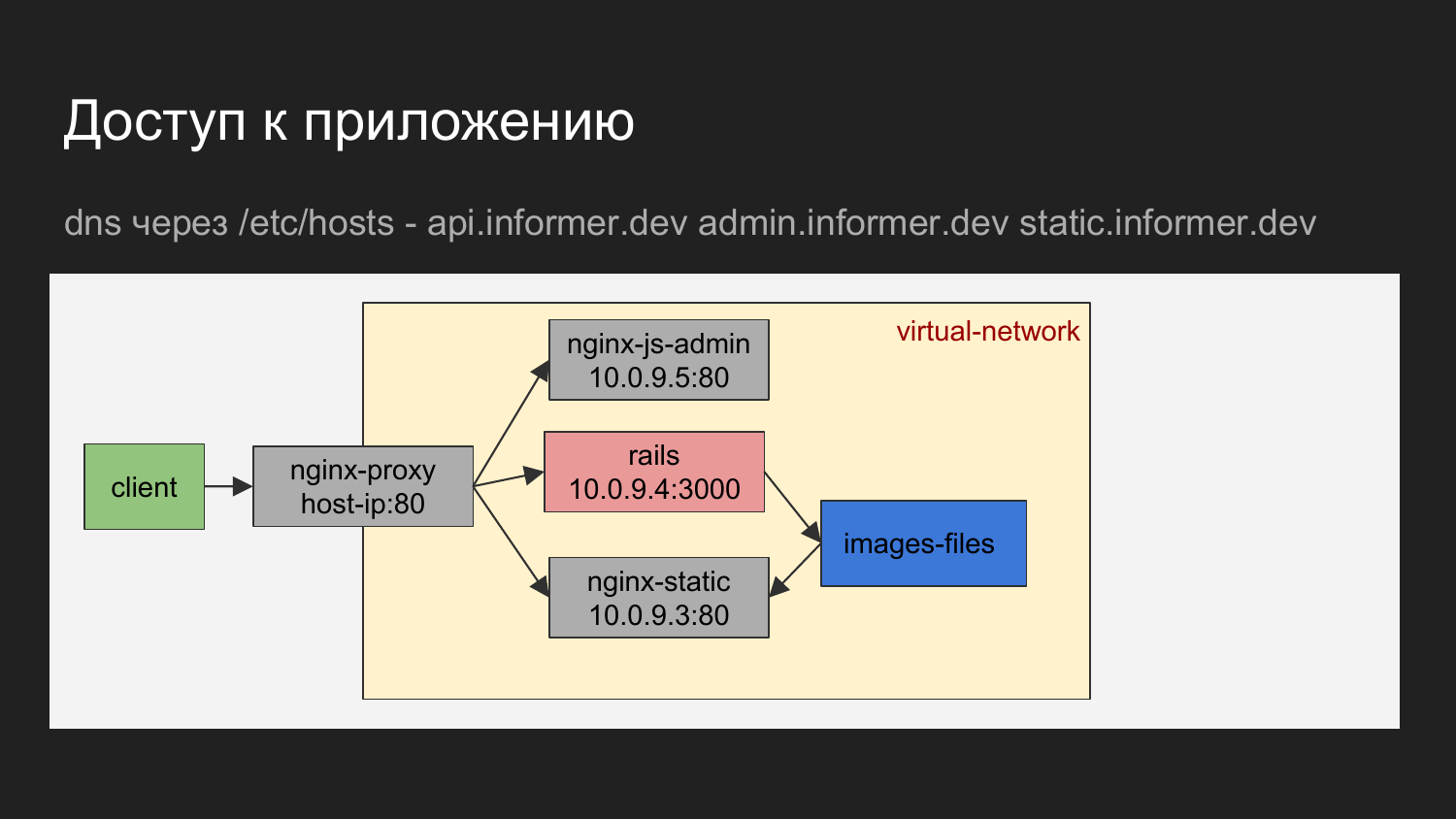
Wenn grafisch dargestellt, stellt sich heraus, dass der Client unser Browser oder ein Tool ist, mit dem wir Anforderungen für den Balancer ausführen.
Der Domain Name Balancer bestimmt, auf welchen Container zugegriffen werden soll.
Es kann Nginx sein, das den JS-Administratorbereich angibt. Dies kann nginx sein, das die API oder statische Dateien angibt, die nginx in Form von Ladebildern übergeben werden.
Das Diagramm zeigt, dass die Container über ein virtuelles Netzwerk verbunden und hinter dem Proxy versteckt sind.
Auf dem Computer des Entwicklers können Sie sich an den Container wenden, der die IP kennt, aber wir verwenden diese grundsätzlich nicht. Der Bedarf an direkter Behandlung entsteht praktisch nicht.

Welches Beispiel sollte verwendet werden, um die Anwendung anzudocken? Meiner Meinung nach ist das offizielle Docker-Image für MySQL ein gutes Beispiel.
Es ist ziemlich kompliziert. Es gibt viele Versionen. Dank seiner Funktionalität können Sie jedoch viele Anforderungen abdecken, die im Verlauf der Weiterentwicklung auftreten können. Wenn Sie Zeit verbringen und herausfinden, wie all dies zusammenwirkt, werden Sie wahrscheinlich keine Probleme bei der Selbstimplementierung haben.
In hub.docker.com gibt es normalerweise Links zu github.com, die Rohdaten direkt bereitstellen, aus denen Sie das Bild selbst zusammenstellen können.
Weiter in diesem Repository befindet sich das Skript docker-endpoint.sh, das für die Erstinitialisierung und die weitere Verarbeitung des Anwendungsstarts verantwortlich ist.
Auch in diesem Beispiel besteht die Möglichkeit der Konfiguration mithilfe von Umgebungsvariablen. Durch Definieren der Umgebungsvariablen beim Starten eines einzelnen Containers oder über Docker-Compose können wir sagen, dass wir ein leeres Kennwort für Docker für Root in MySQL festlegen müssen oder was auch immer wir wollen.
Es besteht die Möglichkeit, ein zufälliges Passwort zu erstellen. Wir sagen, wir brauchen einen Benutzer, wir müssen ein Passwort für den Benutzer festlegen und wir müssen eine Datenbank erstellen.
In unseren Projekten haben wir das Dockerfile, das für die Initialisierung verantwortlich ist, leicht vereinheitlicht. Dort haben wir unsere Anforderungen korrigiert, um nur eine Erweiterung der Benutzerrechte vorzunehmen, die die Anwendung verwendet. Dies ermöglichte es in Zukunft, einfach eine Datenbank über die Anwendungskonsole zu erstellen. Ruby-Anwendungen verfügen über einen Befehl zum Erstellen, Ändern und Löschen von Datenbanken.

Dies ist ein Beispiel dafür, wie eine bestimmte Version von MySQL auf github.com aussieht. Sie können die Docker-Datei öffnen und sehen, wie die Installation dort abläuft.
Skript docker-endpoint.sh, das für den Einstiegspunkt verantwortlich ist. Während der Erstinitialisierung sind einige Vorbereitungsschritte erforderlich, und alle diese Aktionen werden nur für das Initialisierungsskript ausgeführt.

Wir gehen zum zweiten Teil über.
Um den Quellcode zu speichern, haben wir zu gitlab gewechselt. Dies ist ein ziemlich leistungsfähiges System mit einer visuellen Oberfläche.
Eine der Komponenten von Gitlab ist Gitlab CI. Hier können Sie die Folgebefehle beschreiben, die anschließend verwendet werden, um ein Codeübermittlungssystem zu organisieren oder automatische Tests durchzuführen.
Bericht über Gitlab CI 2 https://goo.gl/uohKjI - ein Bericht des Ruby Russia Clubs - ziemlich detailliert und vielleicht wird es Sie interessieren.

Nun werden wir uns überlegen, was zur Aktivierung von Gitlab CI erforderlich ist. Um Gitlab CI zu starten, reicht es aus, die Datei .gitlab-ci.yml im Stammverzeichnis des Projekts abzulegen.
Hier beschreiben wir, dass wir eine Folge von Zuständen wie test, deploy ausführen möchten.
Wir führen Skripte aus, die Docker-Compose direkt aufrufen und die Assembly unserer Anwendung zusammenstellen. Dies ist nur ein Beispiel für ein Backend.
Als nächstes sagen wir, dass es notwendig ist, Migrationen voranzutreiben, um die Datenbank zu ändern und Tests auszuführen.
Wenn die Skripte korrekt ausgeführt werden und keinen Fehlercode zurückgeben, fährt das System dementsprechend mit der zweiten Stufe der Bereitstellung fort.
Die Bereitstellungsphase ist derzeit für die Bereitstellung implementiert. Wir haben keinen reibungslosen Neustart organisiert.
Wir löschen alle Behälter gewaltsam aus und heben dann alle Behälter wieder an, die in der ersten Phase während des Tests gesammelt wurden.
Wir führen es für die aktuelle variable Umgebung der Datenbankmigration aus, die von den Entwicklern geschrieben wurde.
Es gibt einen Hinweis, der dies nur auf den Hauptzweig anwendet.
Beim Ändern anderer Zweige wird nicht ausgeführt.
Es ist möglich, Rollouts in Filialen zu organisieren.
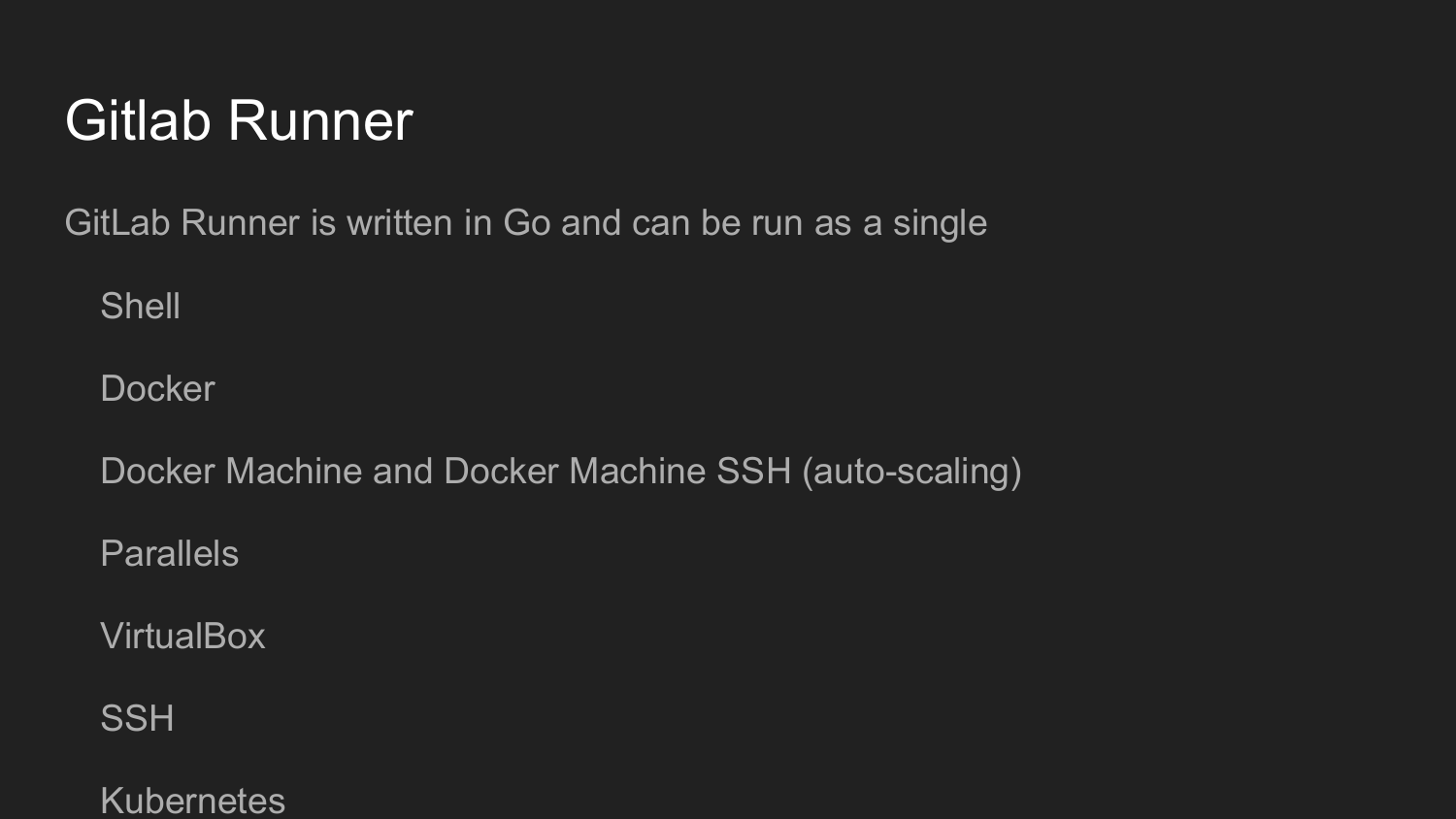
Um dies weiter zu organisieren, müssen wir Gitlab Runner installieren.
Dieses Dienstprogramm ist in Golang geschrieben. Es ist eine einzelne Datei, wie es in der Golang-Welt üblich ist, für die keine Abhängigkeiten erforderlich sind.
Beim Start registrieren wir den Gitlab Runner.
Wir bekommen den Schlüssel in der Weboberfläche von Gitlab.
Dann rufen wir den Befehl init in der Befehlszeile auf.
Konfigurieren Sie Gitlab Runner im Dialogmodus (Shell, Docker, VirtualBox, SSH).
Der Code auf Gitlab Runner wird bei jedem Commit ausgeführt, abhängig von der Einstellung .gitlab-ci.yml.
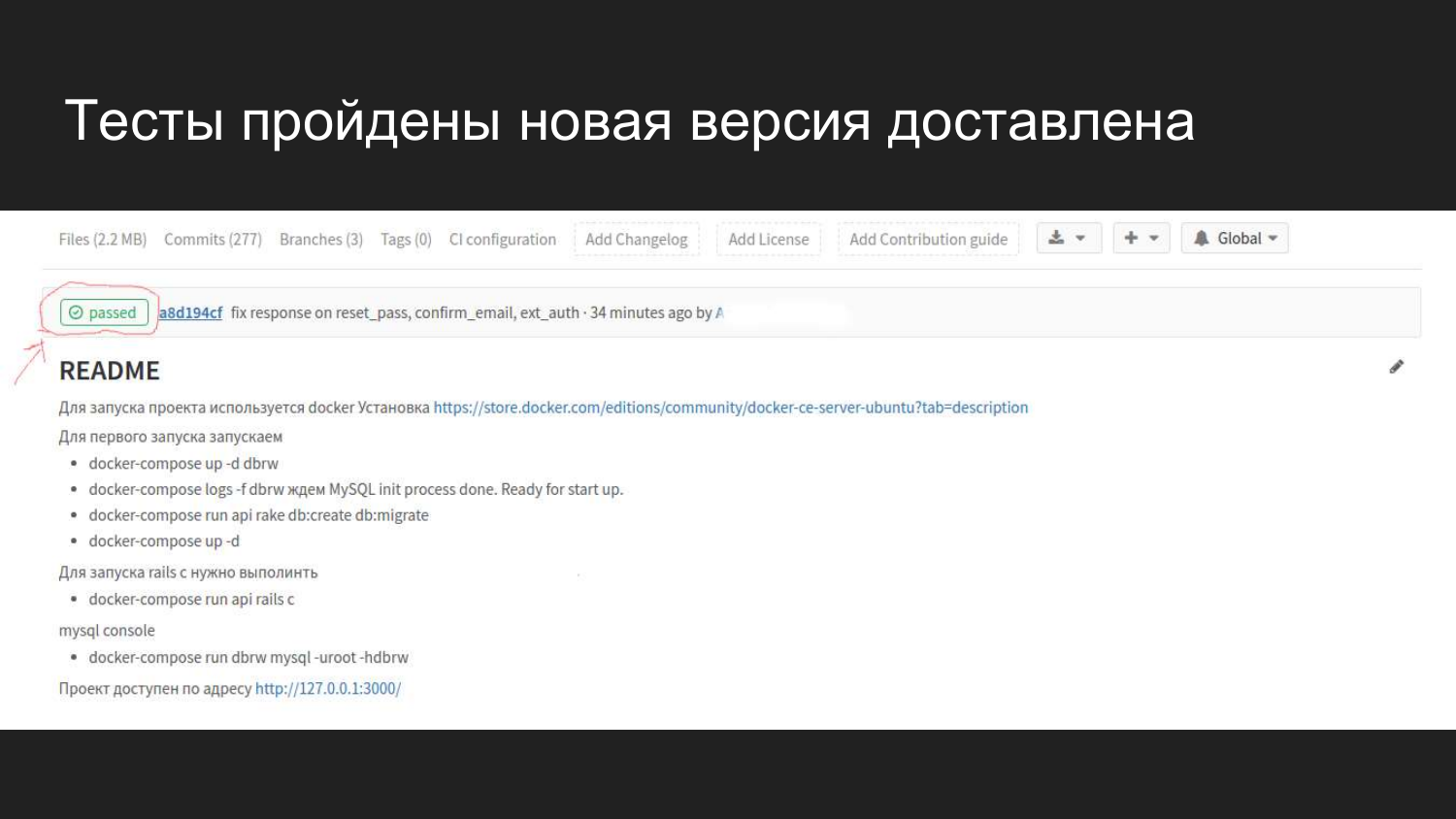
Wie es in Gitlab in einer Weboberfläche visuell aussieht. Nach dem Verbinden von GItlab CI wird ein Flag angezeigt, das den aktuellen Status des Builds anzeigt.
Wir sehen, dass vor 4 Minuten ein Commit durchgeführt wurde, das alle Tests bestanden hat und keine Probleme verursachte.
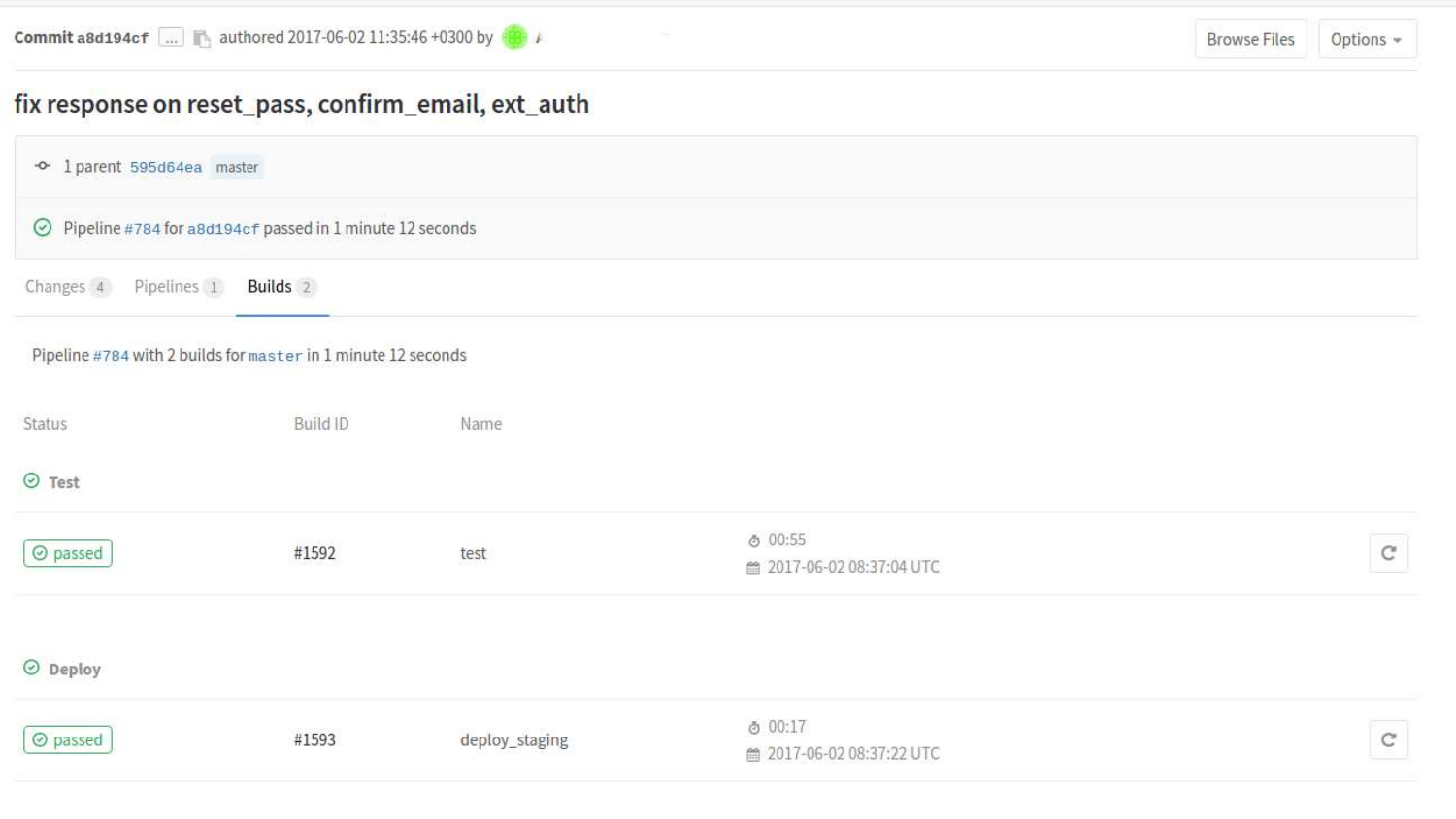
Wir können uns Builds genauer ansehen. Hier sehen wir, dass zwei Staaten bereits vergangen sind. Teststatus und Bereitstellungsstatus beim Staging.
Wenn wir auf einen bestimmten Build klicken, wird eine Konsolenausgabe der Befehle angezeigt, die im Prozess gemäß .gitlab-ci.yml gestartet wurden.
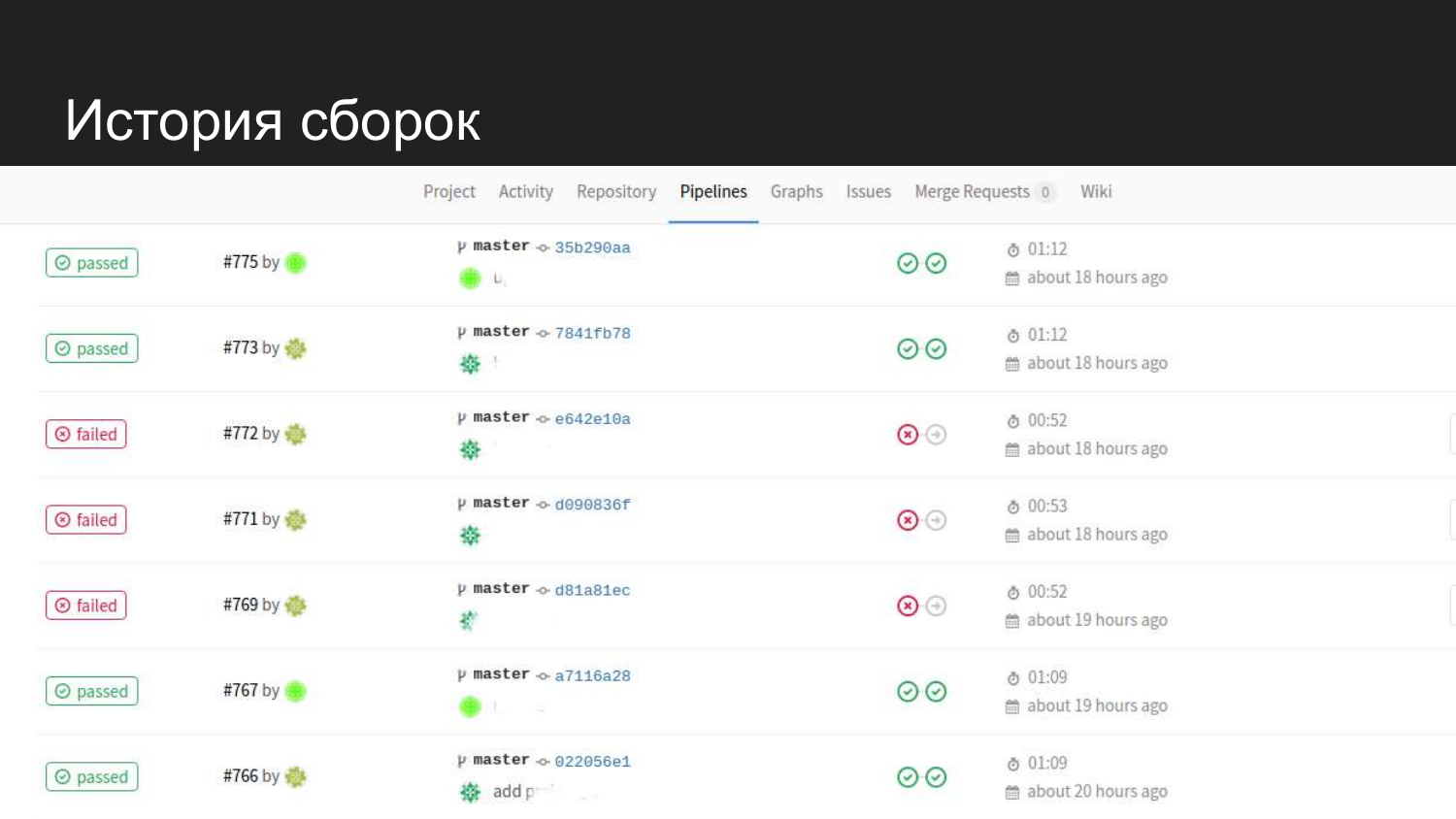
So sieht die Geschichte unseres Produkts aus. Wir sehen, dass es erfolgreiche Versuche gab. Wenn Tests eingereicht werden, wird nicht mit dem nächsten Schritt fortgefahren, und der Code für die Bereitstellung wird nicht aktualisiert.

Welche Aufgaben haben wir beim Staging gelöst, als wir Docker eingeführt haben? , , , .
.
Docker-compose .
, Docker . Docker-compose .
, .
— staging .
production 80 443 , WEB.

? Gitlab Runner .
Gitlab Gitlab Runner, - , .
Gitlab Runner, .
nginx-proxy .
, . .
80 , .

? root. root root .
, root , root.
- , , , , .
? , .
, ?
ID (UID) ID (GID).
ID 1000.
Ubuntu. Ubuntu ID 1000.
?
Docker. , . , - , .
, .
.
Docker Docker Swarm, . - Docker Swarm.
. . . web-.
