Hallo an alle. Die neuronale Netzwerkbibliothek ist in meinem letzten
Artikel beschrieben . Hier habe ich mich entschlossen zu zeigen, wie Sie das trainierte Netzwerk von TF (Tensorflow) bei Ihrer Entscheidung verwenden können und ob es sich lohnt.
Unter dem Schnitt ein Vergleich mit der ursprünglichen Implementierung von TF, einer Demo-Anwendung zum Erkennen von Bildern, na ja ... Schlussfolgerungen. Wen interessiert das bitte?
Hier erfahren Sie beispielsweise, wie ResNet funktioniert.
Hier ist die Netzwerkstruktur in Zahlen:
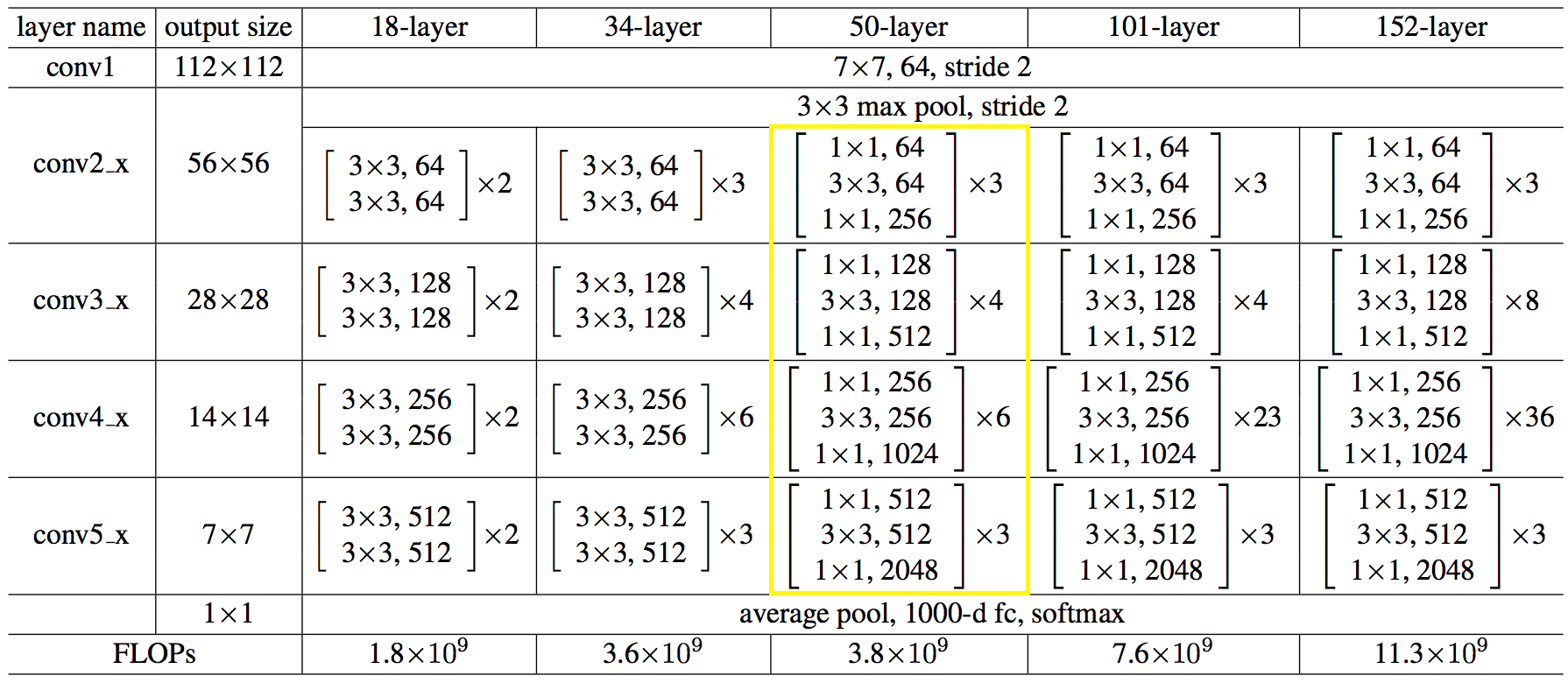
Der Code erwies sich als nicht einfacher und nicht komplizierter als Python.
C ++ - Code zum Erstellen eines Netzwerks:auto net = sn::Net(); net.addNode("In", sn::Input(), "conv1") .addNode("conv1", sn::Convolution(64, 7, 3, 2, sn::batchNormType::beforeActive, sn::active::none, mode), "pool1_pad") .addNode("pool1_pad", sn::Pooling(3, 2, sn::poolType::max, mode), "res2a_branch1 res2a_branch2a"); convBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, 1, "res2a_branch", "res2b_branch2a res2b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, "res2b_branch", "res2c_branch2a res2c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256}, 3, "res2c_branch", "res3a_branch1 res3a_branch2a", mode); convBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, 2, "res3a_branch", "res3b_branch2a res3b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3b_branch", "res3c_branch2a res3c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3c_branch", "res3d_branch2a res3d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3d_branch", "res4a_branch1 res4a_branch2a", mode); convBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, 2, "res4a_branch", "res4b_branch2a res4b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4b_branch", "res4c_branch2a res4c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4c_branch", "res4d_branch2a res4d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4d_branch", "res4e_branch2a res4e_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4e_branch", "res4f_branch2a res4f_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4f_branch", "res5a_branch1 res5a_branch2a", mode); convBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, 2, "res5a_branch", "res5b_branch2a res5b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5b_branch", "res5c_branch2a res5c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5c_branch", "avg_pool", mode); net.addNode("avg_pool", sn::Pooling(7, 7, sn::poolType::avg, mode), "fc1000") .addNode("fc1000", sn::FullyConnected(1000, sn::active::none, mode), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
→ Den vollständigen Code finden Sie
hierSie können es einfacher machen, die Netzwerkarchitektur und Gewichte aus Dateien laden,
so: string archPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Struct.json", weightPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Weights.dat"; std::ifstream ifs; ifs.open(archPath, std::ifstream::in); if (!ifs.good()){ cout << "error open file : " + archPath << endl; system("pause"); return false; } ifs.seekg(0, ifs.end); size_t length = ifs.tellg(); ifs.seekg(0, ifs.beg); string jnArch; jnArch.resize(length); ifs.read((char*)jnArch.data(), length);
Antrag auf Interesse gestellt. Sie können
von hier herunterladen. Das Volumen ist aufgrund der Netzwerkgewichte groß. Quellen sind da, die Sie als Beispiel verwenden können.
Die Anwendung wurde nur für den Artikel erstellt und wird nicht unterstützt. Daher wurde sie nicht in das Projekt-Repository aufgenommen.

Nun, was ist im Vergleich zu TF passiert?
Anzeigen nach durchschnittlich 100 Bildern. Maschine: i5-2400, GF1050, Win7, MSVC12.
Die Werte der Erkennungsergebnisse stimmen mit dem 3. Zeichen überein.
→
TestcodeIn der Tat ist natürlich alles bedauerlich.
Für die CPU habe ich mich entschieden, MKL-DNN nicht zu verwenden. Ich selbst dachte daran, es zu beenden: Verteilte den Speicher für sequentielles Lesen neu, lud die Vektorregister auf das Maximum. Vielleicht war es notwendig, zur Matrixmultiplikation und / oder zu anderen Hacks zu führen. Hier ausgeruht, war es zunächst schlimmer, es wäre richtiger, MKL trotzdem zu verwenden.
Auf der GPU wird Zeit für das Kopieren des Speichers vom / in den Speicher der Grafikkarte aufgewendet, und nicht alle Vorgänge werden auf der GPU ausgeführt.
Welche Schlussfolgerungen können aus all dieser Aufregung gezogen werden:
- nicht um anzugeben, sondern um bekannte bewährte Lösungen zu verwenden, sind sie schon mehr oder weniger in den Sinn gekommen. Er saß selbst einmal auf mxnet und arbeitete mit einheimischem Gebrauch, mehr dazu weiter unten;
- Versuchen Sie nicht, die native C-Schnittstelle von ML-Frameworks zu verwenden. Und verwenden Sie sie in der Sprache, auf die sich die Entwickler konzentriert haben, dh Python.
Eine einfache Möglichkeit, die ML-Funktionalität in Ihrer Sprache zu nutzen, besteht darin, einen Serviceprozess für Python durchzuführen und Bilder an den Socket zu senden. Sie erhalten eine Aufteilung der Verantwortung und das Fehlen von schwerem Code.
Vielleicht alles. Der Artikel war kurz, aber die Schlussfolgerungen sind meiner Meinung nach wertvoll und gelten nicht nur für ML.
Vielen Dank.
PS:
Wenn jemand den Wunsch und die Kraft hat, zu versuchen, TF noch einzuholen,
willkommen !)
PS2:
senkte früh die Hände. Er machte eine Rauchpause, nahm sie wieder und alles klappte.
Für die CPU hat das Casting auf Matrixmultiplikation geholfen, wie ich dachte.
Für die GPU habe ich alle Operationen in einer separaten Bibliothek ausgewählt, so dass ohne Kopieren auf die CPU und umgekehrt das einzige Minus dieses Ansatzes darin bestand, dass ich alle Operatoren neu schreiben (duplizieren) musste, obwohl einige Dinge übereinstimmten, aber sie nicht verbanden.
Im Allgemeinen ist hier wie jetzt:
Das heißt, zumindest fiel die Schlussfolgerung noch schneller aus als bei TF.
Der Testcode hat sich nicht geändert.