Wenn Highroad in der Schule unterrichtet würde, hätte das Lehrbuch zu diesem Thema eine solche Aufgabe. „Das soziale Netzwerk N verfügt über 2.000 Server, auf denen 150.000 Dateien mit jeweils 900 MB PHP-Code und ein Staging-Cluster für 50 Computer gespeichert sind. Der Code wird zweimal täglich auf den Servern bereitgestellt, im Staging-Cluster wird der Code alle paar Minuten aktualisiert, und es gibt zusätzliche „Hotfixes“ - kleine Dateigruppen, die nicht auf allen oder auf dem ausgewählten Teil der Server angeordnet sind, ohne auf die vollständige Berechnung zu warten. Frage: Werden solche Bedingungen als Hochlast betrachtet und wie werden sie bereitgestellt? Schreiben Sie mindestens 5 Bereitstellungsoptionen. “ Wir können nur vom Hyload-Problembuch träumen, aber jetzt wissen wir bereits, dass
Yuri Nasretdinov (
youROCK ) dieses Problem definitiv lösen und die „Fünf“ bekommen würde.
Yuri hielt nicht bei einer einfachen Lösung an, sondern erstellte zusätzlich einen Bericht, in dem er das Konzept des „Code Deployment“ -Konzepts enthüllte, über klassische und alternative Lösungen für umfangreiche PHP-Bereitstellungen sprach, deren Leistung analysierte und das MDK-Bereitstellungssystem vorstellte.
Das Konzept des "Bereitstellen von Code"
Auf Englisch bedeutet der Begriff „Einsatz“, die Truppen in Alarmbereitschaft zu versetzen, und auf Russisch sagen wir manchmal „Füllen Sie den Code in den Kampf“, was dasselbe bedeutet. Sie nehmen den Code in der bereits kompilierten Form oder im Original, wenn es sich um PHP handelt, laden ihn auf die Server hoch, die den Benutzerverkehr bedienen, und wechseln dann auf magische Weise die Last von einer Version des Codes zu einer anderen. All dies ist im Konzept der „Code-Bereitstellung“ enthalten.
Der Bereitstellungsprozess besteht normalerweise aus mehreren Phasen.
- Abrufen des Codes aus dem Repository auf eine beliebige Weise: Klonen, Abrufen, Auschecken.
- Montage - bauen . Bei PHP-Code fehlt möglicherweise die Erstellungsphase. In unserem Fall handelt es sich in der Regel um die automatische Generierung von Übersetzungsdateien, das Hochladen statischer Dateien auf CDN und einige andere Vorgänge.
- Lieferung an Endserver - Bereitstellung.
Nachdem alles zusammengestellt ist, beginnt die Phase der sofortigen Bereitstellung - der
Code wird
auf Produktionsserver übertragen . Über diese Phase wird
Badoo diskutiert.
Altes Bereitstellungssystem in Badoo
Wenn Sie eine Datei mit einem Dateisystem-Image haben, wie können Sie diese dann bereitstellen? Unter Linux müssen Sie
ein Zwischenschleifengerät erstellen, eine Datei anhängen und danach kann dieses Blockgerät bereits gemountet werden.
Ein Loop-Gerät ist eine Krücke, die Linux benötigt, um ein Dateisystem-Image bereitzustellen. Es gibt Betriebssysteme, in denen diese Krücke nicht benötigt wird.

Wie verwendet der Bereitstellungsprozess Dateien, die wir der Einfachheit halber auch als "Schleifen" bezeichnen? Es gibt ein Verzeichnis, in dem sich der Quellcode und der automatisch generierte Inhalt befinden. Wir machen ein leeres Bild des Dateisystems - jetzt ist es EXT2, und früher haben wir ReiserFS verwendet. Wir mounten ein leeres Image des Dateisystems in einem temporären Verzeichnis und kopieren dort den gesamten Inhalt. Wenn wir nichts brauchen, um in Produktion zu gehen, kopieren wir nicht alles. Hängen Sie danach das Gerät aus und rufen Sie das Image des Dateisystems ab, in dem sich die erforderlichen Dateien befinden. Als nächstes
archivieren wir
das Image und laden es auf alle Server hoch. Dort entpacken und mounten wir es.
Andere bestehende Lösungen
Zunächst möchten wir uns bei
Richard Stallman bedanken - ohne seine Lizenz hätten die meisten von uns verwendeten Dienstprogramme nicht existiert.

Herkömmlicherweise habe ich die Methoden zum Bereitstellen von PHP-Code in vier Kategorien unterteilt.
- Basierend auf dem Versionskontrollsystem : svn up, git pull, hg up.
- Basierend auf dem Dienstprogramm rsync - in ein neues Verzeichnis oder "oben".
- Stellen Sie eine Datei bereit - egal was passiert: phar, hhbc, loop.
- Die spezielle Methode, die Rasmus Lerdorf vorgeschlagen hat, ist rsync, 2 Verzeichnisse und realpath_root .
Jede Methode hat sowohl Vor- als auch Nachteile, weshalb wir sie aufgegeben haben. Betrachten Sie diese 4 Methoden genauer.
Bereitstellung basierend auf dem Versionskontrollsystem von svn up
Ich habe SVN nicht zufällig gewählt - nach meinen Beobachtungen besteht der Einsatz in dieser Form genau im Fall von SVN. Das System ist recht
leicht und ermöglicht
eine schnelle und einfache Bereitstellung. Führen Sie einfach svn up aus, und schon sind Sie fertig.
Diese Methode hat jedoch ein großes Minus: Wenn Sie svn up ausführen und beim Aktualisieren des Quellcodes neue Anforderungen aus dem Repository eingehen, wird der Status des Dateisystems angezeigt, das im Repository nicht vorhanden war. Sie haben einen Teil der Dateien neu und einen Teil der alten - dies ist eine
nicht atomare Bereitstellungsmethode, die nicht für hohe Auslastung geeignet ist, sondern nur für kleine Projekte. Trotzdem kenne ich Projekte, die immer noch auf diese Weise bereitgestellt werden, und bis jetzt funktioniert alles für sie.
Bereitstellung basierend auf dem Dienstprogramm rsync
Hierfür gibt es zwei Möglichkeiten: Hochladen von Dateien mit dem Dienstprogramm direkt auf den Server und Hochladen von "oben" - Update.
rsync in ein neues Verzeichnis
Da Sie zuerst den gesamten Code vollständig in ein Verzeichnis gießen, das noch nicht auf dem Server vorhanden ist, und erst dann den Datenverkehr wechseln, ist diese Methode
atomar - niemand sieht einen Zwischenzustand. In unserem Fall führt das Erstellen von 150.000 Dateien und das Löschen des alten Verzeichnisses mit 150.000 Dateien zu einer
großen Belastung des Festplattensubsystems . Wir verwenden Festplatten sehr aktiv, und der Server fühlt sich nach einer solchen Operation für eine Minute nicht gut an. Da wir 2000 Server haben, müssen 900 MB 2000 Mal ausgefüllt werden.
Dieses Schema kann verbessert werden, wenn Sie zuerst eine bestimmte Anzahl von Zwischenservern hochladen, z. B. 50, und diese dann dem Rest hinzufügen. Dies löst mögliche Probleme mit dem Netzwerk, aber das Problem des Erstellens und Löschens einer großen Anzahl von Dateien verschwindet nirgendwo.
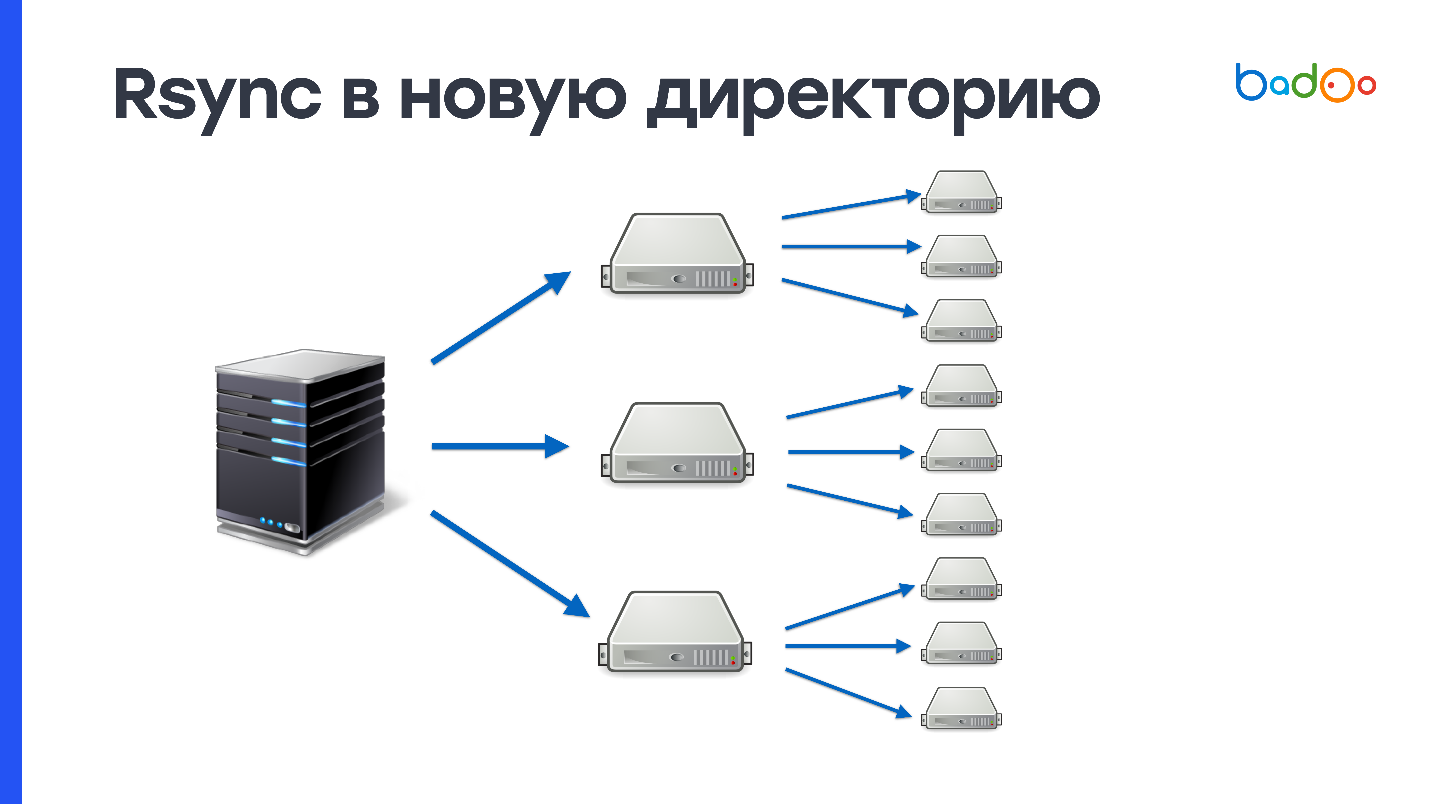
rsync oben
Wenn Sie rsync verwendet haben, wissen Sie, dass dieses Dienstprogramm nicht nur ganze Verzeichnisse füllen, sondern auch vorhandene aktualisieren kann. Nur Änderungen zu senden ist ein Plus, aber da wir die Änderungen in dasselbe Verzeichnis hochladen, in dem wir den Kampfcode bereitstellen, wird es auch eine Art Zwischenzustand geben - dies ist ein Minus.
Das Einreichen von Änderungen funktioniert folgendermaßen. Rsync erstellt Listen von Dateien auf der Serverseite, von der aus die Bereitstellung ausgeführt wird, und auf der Empfangsseite. Danach zählt es stat aus allen Dateien und sendet die gesamte Liste an die empfangende Seite. Auf dem Server, von dem aus die Bereitstellung ausgeführt wird, wird der Unterschied zwischen diesen Werten berücksichtigt und festgelegt, welche Dateien gesendet werden sollen.
Unter unseren Bedingungen benötigt dieser Prozess etwa
3 MB Datenverkehr und 1 Sekunde Prozessorzeit . Es scheint, dass dies nicht viel ist, aber wir haben 2.000 Server, und alles hat mindestens eine Minute Prozessorzeit. Dies ist keine so schnelle Methode, aber definitiv besser, als das Ganze über rsync zu senden. Es bleibt irgendwie das Problem der Atomizität zu lösen und wird fast perfekt sein.
Stellen Sie eine Datei bereit
Unabhängig davon, welche einzelne Datei Sie hochladen, ist die Verwendung von BitTorrent oder des UFTP-Dienstprogramms relativ einfach. Eine Datei ist einfacher zu entpacken, kann unter Unix atomar ersetzt werden und es ist einfach, die Integrität der auf dem Buildserver generierten und an die Zielcomputer gelieferten Datei zu überprüfen, indem die MD5- oder SHA-1-Beträge aus der Datei berechnet werden (im Fall von rsync wissen Sie nicht, was sich auf den Zielservern befindet )
Bei Festplatten ist die sequentielle Aufzeichnung ein großes Plus - eine 900-MB-Datei wird in etwa 10 Sekunden auf eine nicht belegte Festplatte geschrieben. Trotzdem müssen Sie dieselben 900 MB aufzeichnen und über das Netzwerk übertragen.
Lyrischer Exkurs über UFTP
Dieses Open Source-Dienstprogramm wurde ursprünglich erstellt, um Dateien über ein Netzwerk mit langen Verzögerungen zu übertragen, z. B. über ein satellitengestütztes Netzwerk. UFTP erwies sich jedoch als geeignet zum Hochladen von Dateien auf eine große Anzahl von Computern, da es mit dem auf Multicast basierenden UDP-Protokoll funktioniert. Eine Multicast-Adresse wird erstellt, alle Computer, die die Datei empfangen möchten, abonnieren sie, und die Switches ermöglichen die Zustellung von Kopien von Paketen an jeden Computer. Wir verlagern also die Last der Datenübertragung an das Netzwerk. Wenn Ihr Netzwerk damit umgehen kann, funktioniert diese Methode viel besser als BitTorrent.
Sie können dieses Open Source-Dienstprogramm in Ihrem Cluster ausprobieren. Trotz der Tatsache, dass es über UDP funktioniert, verfügt es über einen NACK-Mechanismus - eine negative Bestätigung, die die Weiterleitung von Paketen erzwingt, die bei der Zustellung verloren gehen.
Dies ist eine zuverlässige Methode zur Bereitstellung .
Optionen für die Bereitstellung einzelner Dateien
tar.gzEine Option, die die Nachteile beider Ansätze kombiniert. Sie müssen nicht nur nacheinander 900 MB auf die Festplatte schreiben, sondern danach die gleichen 900 MB durch zufälliges Lesen und Schreiben erneut schreiben und 150.000 Dateien erstellen. Diese Methode hat eine noch schlechtere Leistung als rsync.
pharPHP unterstützt Archive im Phar-Format (PHP-Archiv), weiß, wie man deren Inhalte angibt und Dateien einschließt. Aber nicht alle Projekte lassen sich einfach in einem Phar zusammenfassen - Sie müssen den Code anpassen. Nur weil der Code aus diesem Archiv nicht funktioniert. Außerdem können Sie nicht eine Datei im Archiv ändern (
Yuri aus der Zukunft: Theoretisch können Sie das immer noch ). Sie müssen das gesamte Archiv neu laden. Trotz der Tatsache, dass Phar-Archive mit OPCache arbeiten, muss der Cache bei der Bereitstellung verworfen werden, da sonst in OPCache Müll aus der alten Phar-Datei vorhanden ist.
hhbcDiese Methode stammt ursprünglich aus HHVM - HipHop Virtual Machine und wird von Facebook verwendet. Dies ist so etwas wie ein Phar-Archiv, enthält jedoch nicht die Quellcodes, sondern den kompilierten Bytecode der virtuellen HHVM-Maschine - dem PHP-Interpreter von Facebook. Es ist verboten, Änderungen an dieser Datei vorzunehmen: In diesem Modus können keine neuen Klassen, Funktionen und anderen dynamischen Funktionen erstellt werden. Aufgrund dieser Einschränkungen kann die virtuelle Maschine zusätzliche Optimierungen verwenden. Laut Facebook kann dies die Geschwindigkeit der Codeausführung um bis zu 30% erhöhen. Dies ist wahrscheinlich eine gute Option für sie. Es ist auch unmöglich, hier eine Datei zu ändern (
Yuri aus der Zukunft: Eigentlich ist es möglich, weil es eine SQLite-Basis ist ). Wenn Sie eine Zeile ändern möchten, müssen Sie das gesamte Archiv erneut wiederholen.
Für diese Methode ist es
verboten, eval und dynamic include zu verwenden. Das ist so, aber nicht ganz. Eval kann verwendet werden, aber wenn es keine neuen Klassen oder Funktionen erstellt und include nicht aus Verzeichnissen erstellt werden kann, die sich außerhalb dieses Archivs befinden.
SchleifeDies ist unsere alte Version und hat zwei große Vorteile. Erstens sieht es aus wie ein reguläres Verzeichnis
. Sie mounten die Schleife, und für den Code spielt es keine Rolle - sie funktioniert mit Dateien sowohl in der Entwicklungsumgebung als auch in der Produktionsumgebung. Die zweite Schleife kann im Lese- und Schreibmodus bereitgestellt werden und eine Datei ändern, wenn Sie für die Produktion noch dringend etwas ändern müssen.
Aber Schleife hat Nachteile. Erstens funktioniert es komisch mit Docker. Ich werde etwas später darüber sprechen.
Zweitens, wenn Sie Symlink in der letzten Schleife als document_root verwenden, haben Sie Probleme mit OPCache. Es ist nicht sehr gut, Symlink im Pfad zu haben, und es beginnt zu verwirren, welche Versionen der Dateien verwendet werden sollen. Daher muss OPCache bei der Bereitstellung zurückgesetzt werden.
Ein weiteres Problem besteht darin, dass
Superuser-Berechtigungen erforderlich sind , um Dateisysteme bereitzustellen. Und Sie dürfen nicht vergessen, sie beim Start / Neustart des Computers zu mounten, da sonst anstelle von Code ein leeres Verzeichnis vorhanden ist.
Probleme mit Docker
Wenn Sie einen Docker-Container erstellen und einen Ordner darin ablegen, in dem „Schleifen“ oder andere Blockgeräte bereitgestellt sind, treten zwei Probleme gleichzeitig auf: Die neuen Bereitstellungspunkte fallen nicht in den Docker-Container und die zum Zeitpunkt der Erstellung vorhandenen „Schleifen“ Ein Docker-Container
kann nicht ausgehängt werden, da er von einem Docker-Container belegt ist.
Dies ist natürlich im Allgemeinen nicht mit der Bereitstellung kompatibel, da die Anzahl der Schleifengeräte begrenzt ist und unklar ist, wie der neue Code in den Container fallen soll.
Wir haben versucht, seltsame Dinge zu tun, zum Beispiel einen lokalen
NFS-Server zu eröffnen oder ein Verzeichnis mit SSHFS bereitzustellen, aber aus verschiedenen Gründen hat sich dies nicht in uns festgesetzt. Infolgedessen haben wir in cron rsync aus der letzten "Schleife" im aktuellen Verzeichnis registriert und den Befehl einmal pro Minute ausgeführt:
rsync /var/loop/<N>/ /var/www/
Hier ist
/var/www/ das Verzeichnis, das in den Container
/var/www/ wird. Auf Computern mit Docker-Containern müssen wir jedoch nicht oft PHP-Skripte ausführen, sodass rsync nicht atomar war, was für uns geeignet war. Trotzdem ist diese Methode natürlich sehr schlecht. Ich möchte ein Bereitstellungssystem erstellen, das gut mit Docker funktioniert.
rsync, 2 Verzeichnisse und realpath_root
Diese Methode wurde von Rasmus Lerdorf, dem Autor von PHP, vorgeschlagen und er weiß, wie man sie einsetzt.
Wie kann man eine atomare Bereitstellung durchführen und auf welche Weise habe ich darüber gesprochen? Nehmen Sie symlink und registrieren Sie es als document_root. Zu jedem Zeitpunkt zeigt symlink auf eines der beiden Verzeichnisse, und Sie machen rsync in ein benachbartes Verzeichnis, dh in das Verzeichnis, auf das der Code nicht verweist.
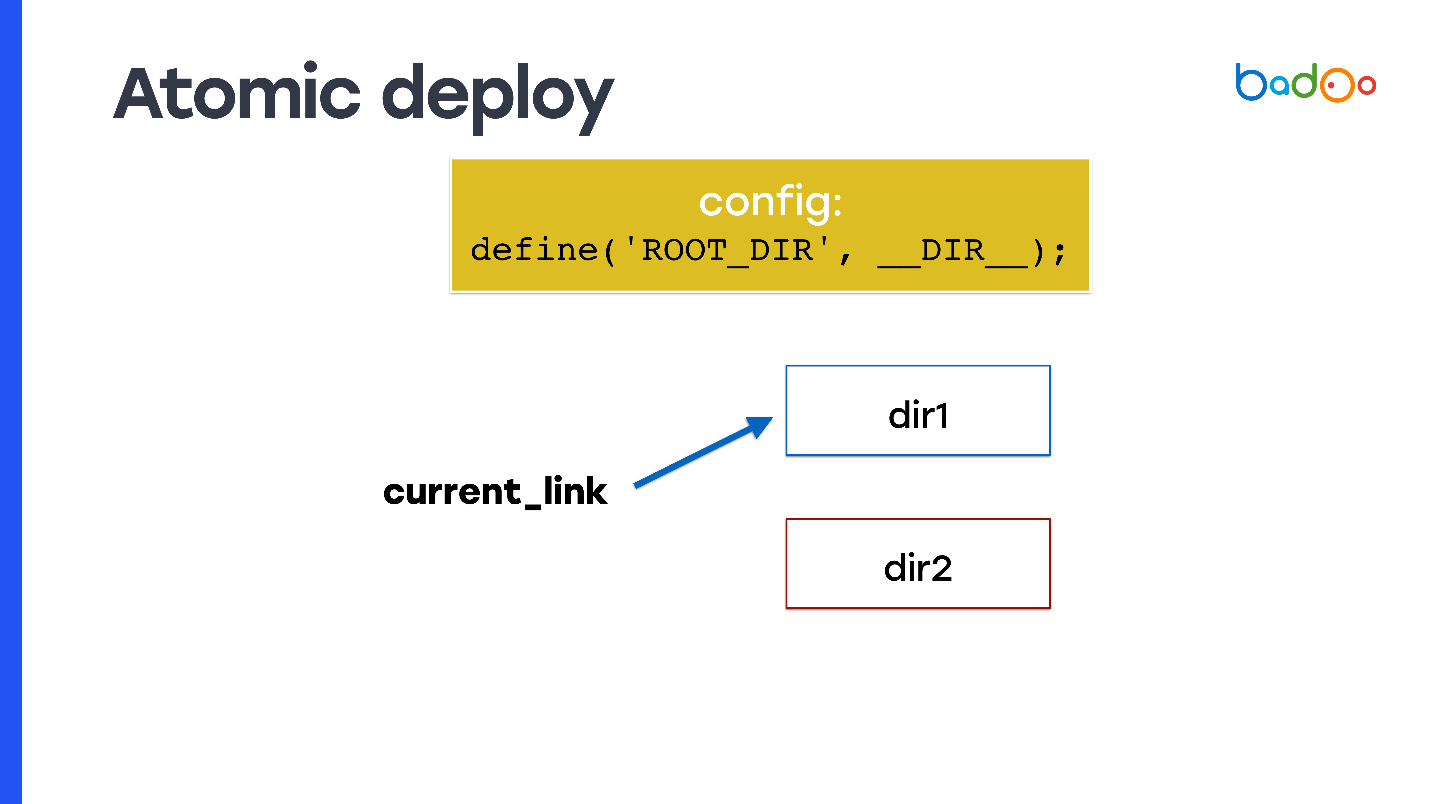
Das Problem tritt jedoch auf: Der PHP-Code weiß nicht, in welchem der Verzeichnisse er gestartet wurde. Daher müssen Sie beispielsweise eine Variable verwenden, die Sie am Anfang der Konfiguration schreiben. Sie legt fest, aus welchem Verzeichnis der Code ausgeführt wurde und aus welchen neuen Dateien aufgenommen werden soll. Auf einer Folie heißt es
ROOT_DIR .
Verwenden Sie diese Konstante, wenn Sie auf alle Dateien im Code zugreifen, den Sie in der Produktion verwenden. Sie erhalten also die Eigenschaft atomicity: Anforderungen, die vor dem Wechseln von symlink eingehen, enthalten weiterhin Dateien aus dem alten Verzeichnis, in dem Sie nichts geändert haben, und neue Anforderungen, die nach dem Wechseln von symlink eingegangen sind, funktionieren ab dem neuen Verzeichnis und werden bearbeitet neuer Code.

Dies muss jedoch im Code geschrieben werden. Nicht alle Projekte sind dafür bereit.
Rasmus-Stil
Rasmus schlägt vor, den Code nicht manuell zu ändern und Konstanten zu erstellen, um Apache leicht zu ändern oder Nginx zu verwenden.
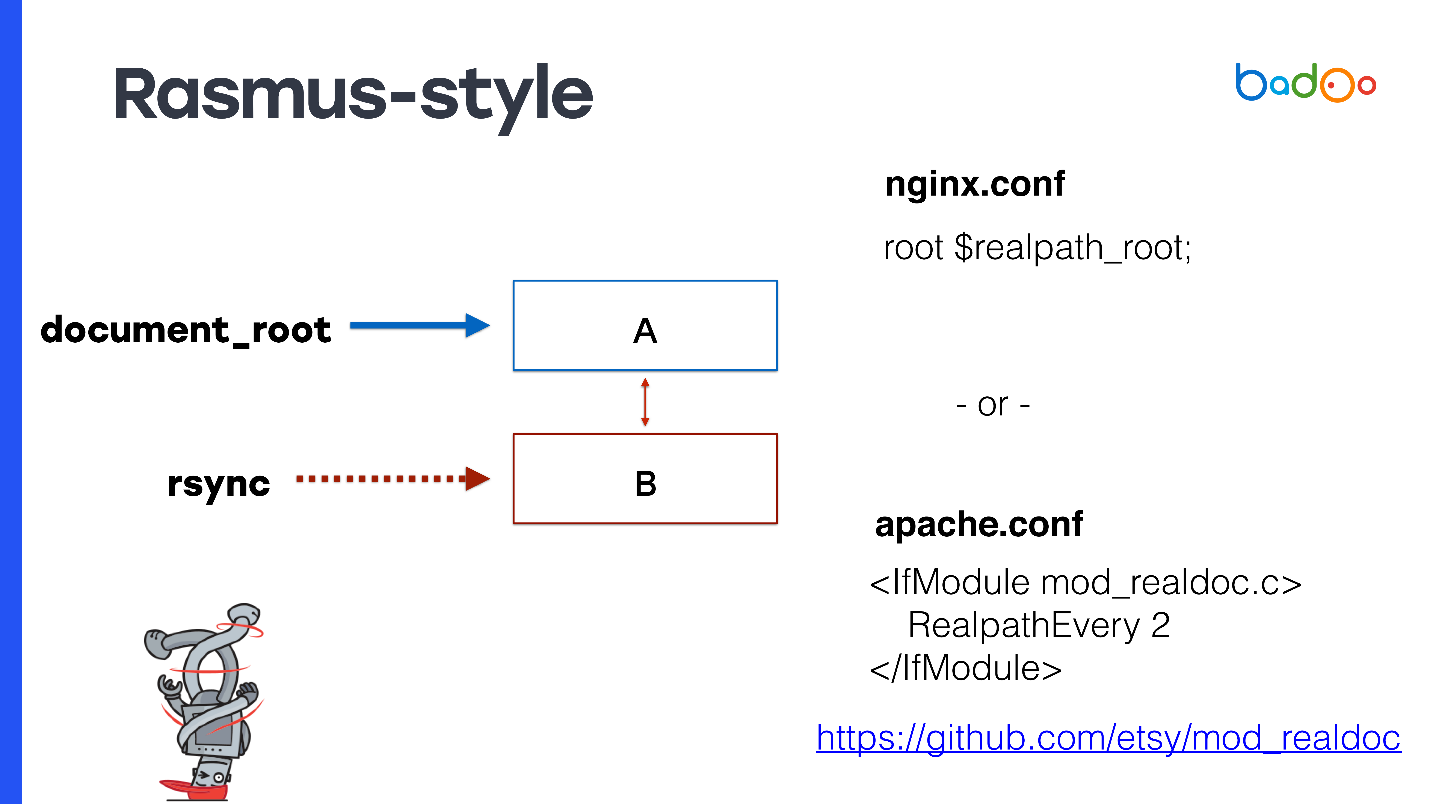
Geben Sie für document_root den Symlink zur neuesten Version an. Wenn Sie nginx haben, können Sie
root $realpath_root registrieren. Für Apache benötigen Sie ein separates Modul mit den Einstellungen, die auf der Folie
root $realpath_root . Dies funktioniert folgendermaßen: Wenn eine Anforderung eingeht, berücksichtigt nginx oder Apache von Zeit zu Zeit realpath () aus dem Pfad, speichert sie vor Symlinks und übergibt diesen Pfad als document_root. In diesem Fall verweist document_root immer auf ein reguläres Verzeichnis ohne Symlinks, und Ihr PHP-Code muss möglicherweise nicht darüber nachdenken, aus welchem Verzeichnis er aufgerufen wird.
Diese Methode hat interessante Vorteile - echte Pfade kommen zu OPCache PHP, sie enthalten keinen Symlink. Selbst die allererste Datei, zu der die Anforderung kam, ist bereits voll, und es gibt keine Probleme mit OPCache. Da document_root verwendet wird, funktioniert dies mit jedem PHP-Projekt. Sie müssen nichts anpassen.
Es ist kein erneutes Laden von fpm erforderlich. Während der Bereitstellung muss OPCache nicht zurückgesetzt werden, weshalb der Prozessorserver sehr ausgelastet ist, da alle Dateien erneut analysiert werden müssen. In meinem Experiment erhöhte das Zurücksetzen von OPCache um etwa eine halbe Minute den Prozessorverbrauch um den Faktor 2–3. Es wäre schön, es wiederzuverwenden, und diese Methode ermöglicht es Ihnen, es zu tun.
Nun die Nachteile. Da Sie OPCache nicht wiederverwenden und über zwei Verzeichnisse verfügen, müssen Sie für jedes Verzeichnis eine Kopie der Datei im Speicher speichern. Unter OPCache ist zweimal mehr Speicher erforderlich.
Es gibt eine weitere Einschränkung, die seltsam erscheinen kann:
Sie können nicht mehr als einmal pro max_execution_time bereitstellen . Andernfalls tritt das gleiche Problem auf, da während rsync in eines der Verzeichnisse wechselt, Anforderungen von diesem weiterhin verarbeitet werden können.
Wenn Sie Apache aus irgendeinem Grund verwenden, benötigen Sie ein
Drittanbieter-Modul , das Rasmus ebenfalls geschrieben hat.
Rasmus sagt, das System ist gut und ich empfehle es Ihnen auch. Für 99% der Projekte ist es sowohl für neue als auch für bestehende Projekte geeignet. Aber natürlich sind wir nicht so und haben beschlossen, unsere eigene Entscheidung zu schreiben.
Neues System - MDK
Grundsätzlich unterscheiden sich unsere Anforderungen nicht von den Anforderungen für die meisten Webprojekte. Wir wollen nur eine
schnelle Bereitstellung für Staging und Produktion,
geringen Ressourcenverbrauch , Wiederverwendung von OPCache und schnelles Rollback.
Es gibt jedoch zwei weitere Anforderungen, die sich von den anderen unterscheiden können. Zuallererst ist es die Fähigkeit,
Patches atomar anzuwenden . Wir bezeichnen Patches als Änderungen in einer oder mehreren Dateien, die etwas über die Produktion regeln. Wir wollen es schnell machen. Im Prinzip bewältigt das von Rasmus angebotene System die Patch-Aufgabe.
Wir haben auch
CLI-Skripte , die mehrere Stunden lang ausgeführt werden können und die weiterhin mit einer konsistenten Version des Codes funktionieren sollten. In diesem Fall passen die oben genannten Lösungen leider entweder nicht zu uns oder wir müssen viele Verzeichnisse haben.
Mögliche Lösungen:
- Schleife xN (-staging, -docker, -opcache);
- rsync xN (-Produktion, -opcache xN);
- SVN xN (-Produktion, -opcache xN).
Hier ist N die Anzahl der Berechnungen, die in wenigen Stunden durchgeführt werden. Wir können Dutzende davon haben, was bedeutet, dass sehr viel Platz für zusätzliche Kopien des Codes aufgewendet werden muss.
Deshalb haben wir uns ein neues System
ausgedacht und es
MDK genannt. Es steht für
Multiversion Deployment Kit , ein
Bereitstellungstool für mehrere Versionen. Wir haben es basierend auf den folgenden Annahmen gemacht.
Wir haben die Baumspeicherarchitektur von Git übernommen. Wir benötigen eine konsistente Version des Codes, in dem das Skript funktioniert, dh wir benötigen Snapshots. Snapshots werden von LVM unterstützt, dort jedoch von experimentellen Dateisystemen wie Btrfs und Git ineffizient implementiert. Wir haben die Implementierung von Snapshots von Git übernommen.
Alle Dateien wurden von file.php in file.php umbenannt. <Version>. Da alle vorhandenen Dateien einfach auf der Festplatte gespeichert sind, müssen wir der Version ein Suffix hinzufügen, wenn wir mehrere Versionen derselben Datei speichern möchten.
Ich liebe Go, also habe ich aus Geschwindigkeitsgründen ein System auf Go geschrieben.Funktionsweise des Multiversion Deployment Kit
Wir haben die Idee von Schnappschüssen von Git übernommen. Ich habe es ein wenig vereinfacht und Ihnen gesagt, wie es in MDK implementiert ist.
Es gibt zwei Arten von Dateien in MDK. Das erste sind
Karten. Die folgenden Bilder sind grün markiert und entsprechen den Verzeichnissen im Repository. Der zweite Typ sind
direkt die Dateien, die sich wie gewohnt an derselben Stelle befinden, jedoch mit einem Suffix in Form einer Dateiversion. Dateien und Karten werden basierend auf ihrem Inhalt versioniert, in unserem Fall einfach MD5.
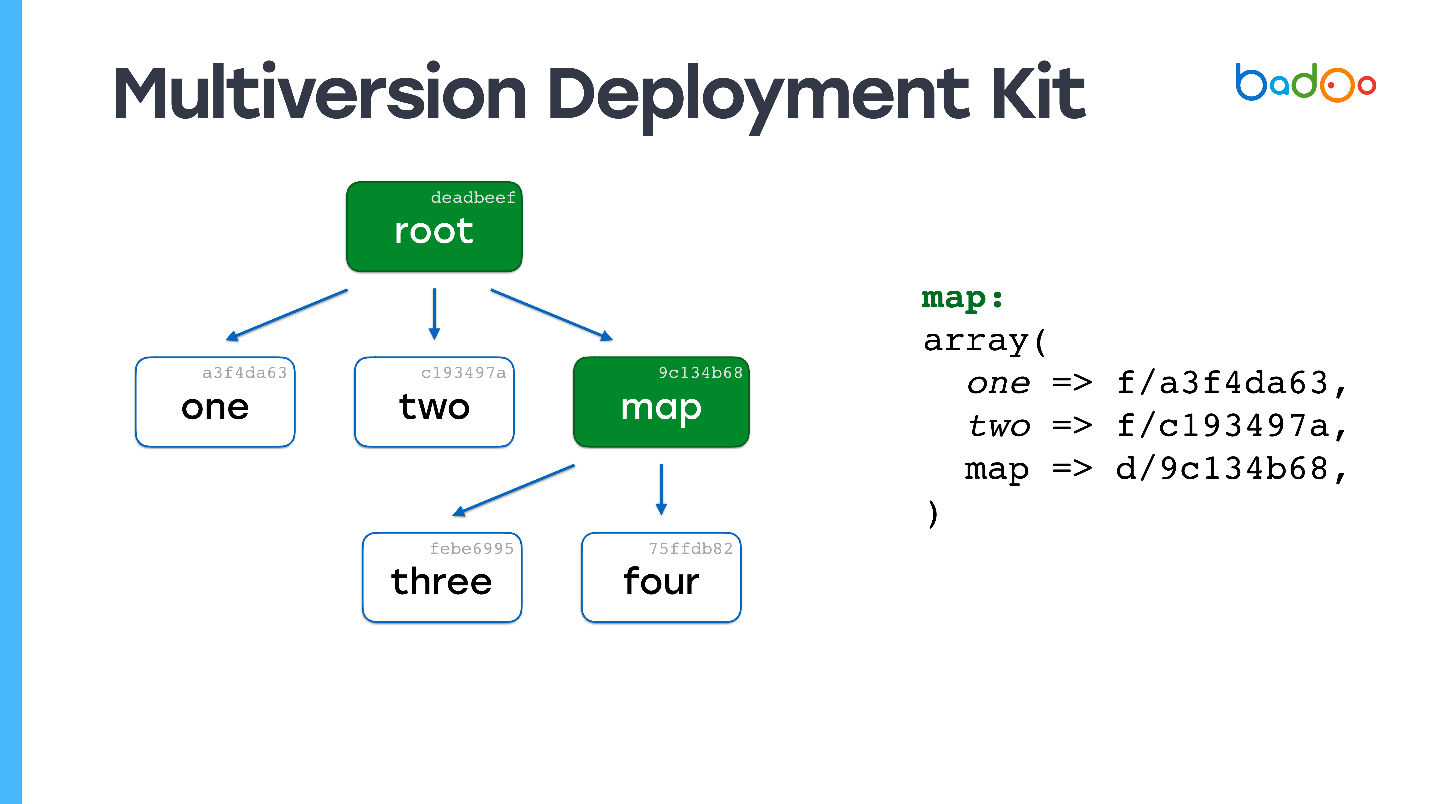
Angenommen, wir haben eine Hierarchie von Dateien, in der die
Stammzuordnung auf bestimmte Versionen von Dateien aus anderen Zuordnungen verweist , und diese wiederum auf andere Dateien und
Zuordnungen verweisen und bestimmte Versionen korrigieren. Wir wollen eine Art Datei ändern.

Vielleicht haben Sie bereits ein ähnliches Bild gesehen: Wir ändern die Datei auf der zweiten Verschachtelungsebene, und in der entsprechenden Map - Map * wird die Version der Drei * -Datei aktualisiert, ihr Inhalt wird geändert, die Version wird geändert - und die Version ändert sich auch in der Root-Map. Wenn wir etwas ändern, erhalten wir immer eine neue Root-Map, aber alle Dateien, die wir nicht geändert haben, werden wiederverwendet.
Links bleiben zu denselben Dateien wie sie waren. Dies ist die Hauptidee, Snapshots auf irgendeine Weise zu erstellen. Beispielsweise wird
ZFS in
ZFS ungefähr auf die gleiche Weise implementiert.
Wie MDK auf einer Festplatte liegt

Wir haben auf der Festplatte:
Symlink zur neuesten Root-Map - den Code, der aus dem Web bereitgestellt wird, mehrere Versionen von Root-Maps, mehrere Dateien, möglicherweise mit unterschiedlichen Versionen, und in den Unterverzeichnissen gibt es Maps für die entsprechenden Verzeichnisse.
Ich sehe die Frage voraus: "
Und wie verarbeitet dies die Webanforderung? Zu welchen Dateien kommt der Benutzercode? "
Ja, ich habe Sie getäuscht - es gibt auch Dateien ohne Versionen, denn wenn Sie eine Anfrage für index.php erhalten und diese nicht im Verzeichnis haben, funktioniert die Site nicht.

Alle PHP-Dateien haben Dateien, die wir
Stubs nennen, da sie zwei Zeilen enthalten: erfordern aus der Datei, in der die Funktion deklariert ist, die mit diesen Karten arbeitet, und erfordern aus der gewünschten Version der Datei.
<?php require_once "mdk.inc"; require mdk_resolve_path("a.php");
Dies geschieht auf diese Weise und ist nicht mit der neuesten Version
verknüpft. Wenn Sie
b.php ohne Version aus der
a.php- Datei ausschließen,
merkt sich das
System , da require_once geschrieben ist, von welcher Root-Karte es gestartet wurde, und verwendet es Holen Sie sich eine konsistente Version von Dateien.
Für den Rest der Dateien haben wir nur einen Symlink zur neuesten Version.
Bereitstellen mit MDK
Das Modell ist Git Push sehr ähnlich.
- Senden Sie den Inhalt der Root-Map.
- Auf der Empfangsseite schauen wir uns an, welche Dateien fehlen. Da die Version der Datei vom Inhalt bestimmt wird, müssen wir sie nicht ein zweites Mal herunterladen ( Yuri aus der Zukunft: außer für den Fall, dass ein verkürzter MD5 kollidiert, der noch einmal in der Produktion aufgetreten ist ).
- Fordern Sie die fehlende Datei an.
- Wir gehen zum zweiten Punkt und weiter im Kreis.
Beispiel
Angenommen, auf dem Server befindet sich eine Datei mit dem Namen "one". Senden Sie eine Root-Map.

In der Stammzuordnung zeigen gestrichelte Pfeile Links zu Dateien an, die wir nicht haben. Wir kennen ihre Namen und Versionen, weil sie auf der Karte sind. Wir fordern sie vom Server an. Der Server sendet und es stellt sich heraus, dass eine der Dateien auch eine Karte ist.
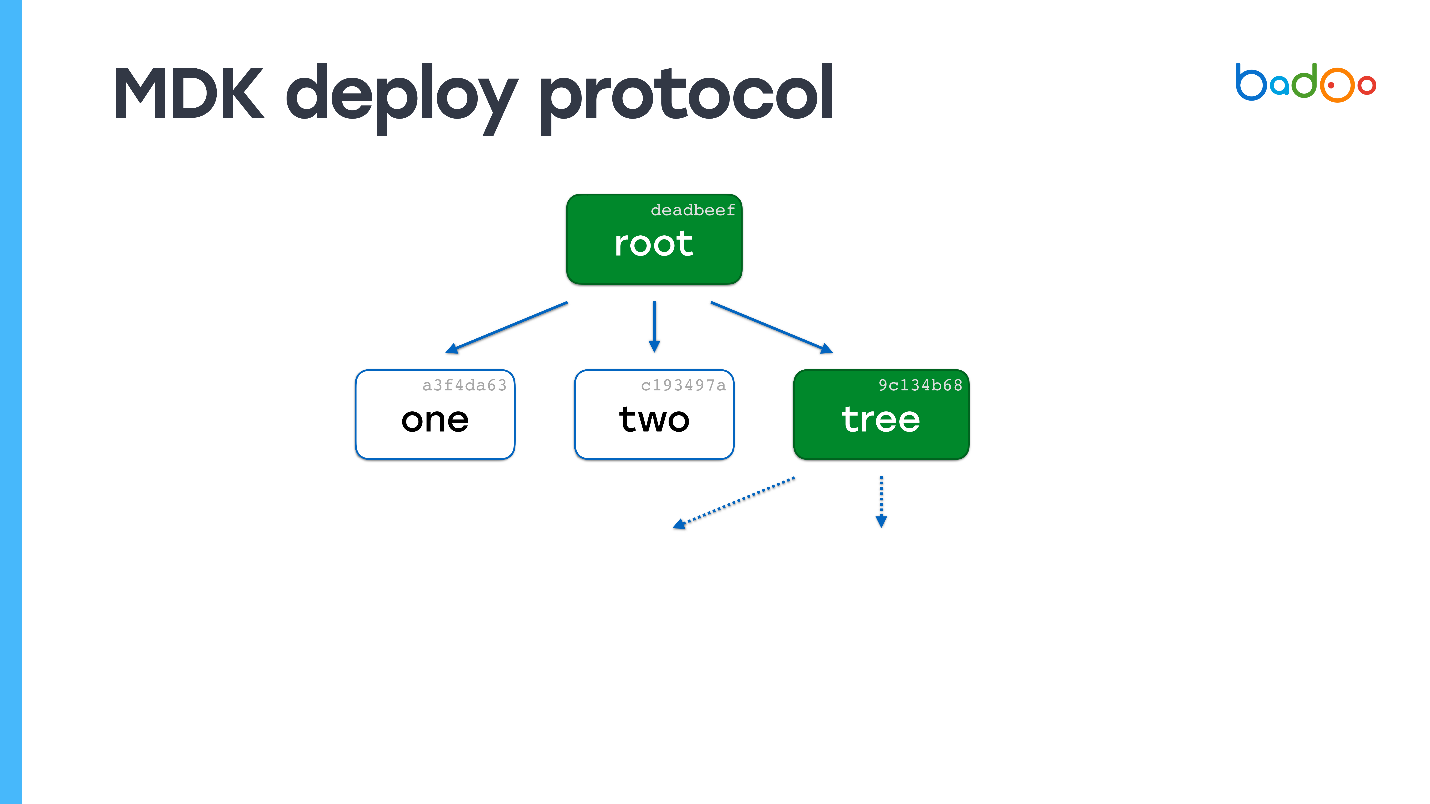
Wir schauen - wir haben überhaupt keine einzige Datei. Wieder fordern wir fehlende Dateien an. Der Server sendet sie. Es sind keine Karten mehr vorhanden - der Bereitstellungsprozess ist abgeschlossen.
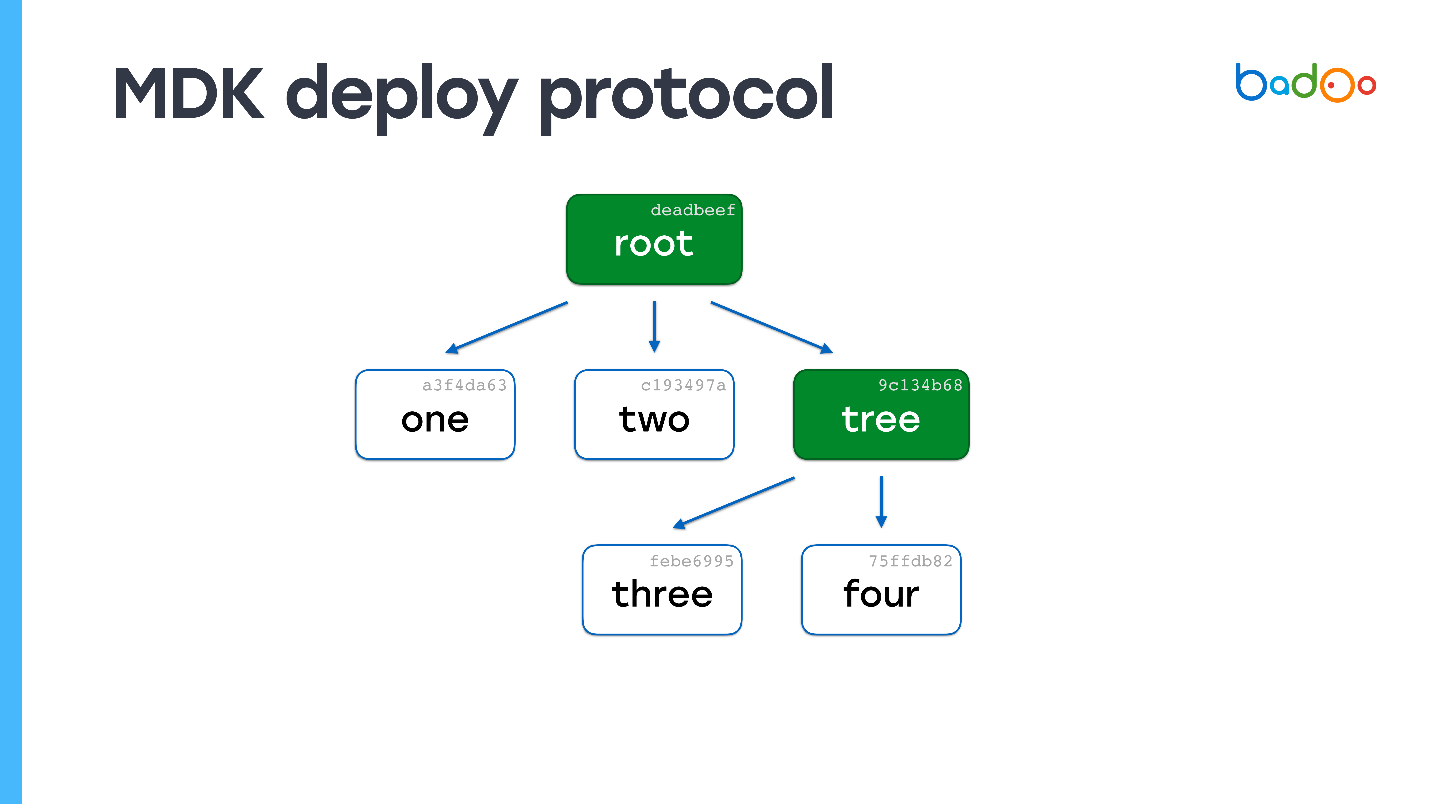
Sie können leicht erraten, was passieren wird, wenn die Dateien 150.000 sind, aber eine hat sich geändert. Wir werden in der Root-Map sehen, dass eine Map fehlt. Lassen Sie uns die Verschachtelungsebene durchgehen und eine Datei erhalten. In Bezug auf die Rechenkomplexität unterscheidet sich der Prozess fast nicht vom direkten Kopieren von Dateien, gleichzeitig bleiben jedoch die Konsistenz und die Snapshots des Codes erhalten.
MDK hat keine Nachteile :) Es ermöglicht Ihnen,
kleine Änderungen schnell und atomar bereitzustellen , und
Skripte funktionieren tagelang , da wir alle Dateien, die bereitgestellt wurden, innerhalb einer Woche belassen können. Sie werden ausreichend Platz einnehmen. Sie können OPCache auch wiederverwenden, und die CPU frisst fast nichts.
Die Überwachung ist recht schwierig, aber möglich . Alle Dateien sind nach Inhalten versioniert, und Sie können cron schreiben, das alle Dateien durchläuft und den Namen und den Inhalt überprüft. Sie können auch überprüfen, ob die Root-Map auf alle Dateien verweist und keine fehlerhaften Links enthält. Darüber hinaus wird während der Bereitstellung die Integrität überprüft.
Sie können
die Änderungen problemlos rückgängig machen , da alle alten Karten vorhanden sind. Wir können die Karte einfach werfen, alles wird sofort da sein.
Für mich bedeutet die Tatsache, dass
MDK in Go geschrieben ist , dass es schnell funktioniert.
Ich habe dich wieder getäuscht, es gibt immer noch Nachteile. Damit das Projekt mit dem System funktioniert, ist
eine wesentliche Änderung des Codes erforderlich, die jedoch einfacher ist, als es auf den ersten Blick erscheinen mag.
Das System ist sehr komplex . Ich würde die Implementierung nicht empfehlen, wenn Sie keine Anforderungen wie Badoo haben. Außerdem endet der Ort früher oder später, sodass der
Garbage Collector erforderlich ist .
Wir haben spezielle Dienstprogramme zum Bearbeiten von Dateien geschrieben - echte, keine Stubs, zum Beispiel mdk-vim. Sie geben die Datei an, sie findet die gewünschte Version und bearbeitet sie.
MDK in Zahlen
Wir haben 50 Server im Staging, auf denen wir für 3-5 s bereitstellen
. Im Vergleich zu allem außer rsync ist es sehr schnell. In der
Produktion stellen wir ca.
2 Minuten kleine Patches bereit -
5-10 s .
Wenn Sie aus irgendeinem Grund den gesamten Ordner mit dem Code auf allen Servern verloren haben (was niemals passieren sollte :)),
dauert der
Vorgang des vollständigen Hochladens etwa 40 Minuten . Es ist uns einmal passiert, wenn auch nachts mit einem Minimum an Verkehr. Daher wurde niemand verletzt. Die zweite Datei befand sich 5 Minuten lang auf zwei Servern, daher ist dies nicht erwähnenswert.
Das System ist nicht in Open Source, aber wenn Sie interessiert sind, schreiben Sie in die Kommentare - es kann angelegt sein (
Yuri aus der Zukunft: Das System ist zum Zeitpunkt dieses Schreibens noch nicht in Open Source ).
Fazit
Hör auf Rasmus, er lügt nicht . Meiner Meinung nach ist die rsync-Methode zusammen mit realpath_root die beste, obwohl Schleifen auch recht gut funktionieren.
Denken Sie mit Ihrem Kopf : Sehen Sie sich genau an, was Ihr Projekt benötigt, und versuchen Sie nicht, ein Raumschiff zu schaffen, in dem es genügend „Mais“ gibt. Wenn Sie jedoch immer noch ähnliche Anforderungen haben, ist ein MDK-ähnliches System genau das Richtige für Sie.
Wir haben uns entschlossen, zu diesem Thema zurückzukehren, das in HighLoad ++ diskutiert wurde und möglicherweise nicht die gebührende Aufmerksamkeit erhielt, da es nur einer von vielen Bausteinen war, um eine hohe Leistung zu erzielen. Aber jetzt haben wir eine separate professionelle PHP Russia- Konferenz, die sich ausschließlich mit PHP befasst. Und hier kommen wir wirklich voll zur Geltung. Wir werden gründlich über Leistung , Standards und Tools sprechen - viel darüber, einschließlich Refactoring .
Abonnieren Sie den Telegrammkanal mit Aktualisierungen des Konferenzprogramms und bis zum 17. Mai.