Hallo Habr!
Wir erinnern Sie daran, dass wir nach dem Buch über
Kafka eine ebenso interessante Arbeit über die
Kafka Streams API- Bibliothek veröffentlicht haben.

Bisher versteht die Community nur die Grenzen dieses mächtigen Werkzeugs. Daher wurde kürzlich ein Artikel veröffentlicht, dessen Übersetzung wir Ihnen vorstellen möchten. Aus eigener Erfahrung erklärt der Autor, wie aus Kafka Streams ein verteiltes Data Warehouse erstellt wird. Viel Spaß beim Lesen!
Die Apache
Kafka Streams- Bibliothek weltweit wird in Unternehmen für die verteilte Streaming-Verarbeitung zusätzlich zu Apache Kafka verwendet. Einer der unterschätzten Aspekte dieses Frameworks ist, dass Sie damit einen lokalen Status basierend auf der Streaming-Verarbeitung speichern können.
In diesem Artikel werde ich Ihnen erläutern, wie unser Unternehmen diese Gelegenheit erfolgreich genutzt hat, um ein Produkt für die Sicherheit von Cloud-Anwendungen zu entwickeln. Mit Kafka Streams haben wir Shared-Service-Microservices erstellt, die jeweils als fehlertolerante und leicht zugängliche Quelle für zuverlässige Informationen über den Status von Objekten im System dienen. Für uns ist dies ein Fortschritt in Bezug auf Zuverlässigkeit und einfache Unterstützung.
Wenn Sie an einem alternativen Ansatz interessiert sind, mit dem Sie eine einzige zentrale Datenbank verwenden können, um den formalen Status Ihrer Objekte zu unterstützen - lesen Sie, es wird interessant sein ...
Warum wir dachten, es sei Zeit, unsere Herangehensweisen an die Arbeit mit dem gemeinsamen Staat zu ändernWir mussten den Status verschiedener Objekte basierend auf Agentenberichten beibehalten (zum Beispiel: Wurde die Site angegriffen)? Vor dem Wechsel zu Kafka Streams haben wir uns häufig auf eine einzige zentrale Datenbank (+ Service-API) verlassen, um unseren Status zu verwalten. Dieser Ansatz hat seine Nachteile: In
datenintensiven Situationen wird die Unterstützung für Konsistenz und Synchronisation zu einer echten Herausforderung. Die Datenbank kann zu einem Engpass werden oder sich in
einem Rennzustand befinden und unter Unvorhersehbarkeit leiden.
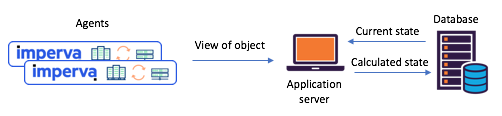 Abbildung 1: Ein typisches Split-State-Szenario vor dem Übergang zu
Abbildung 1: Ein typisches Split-State-Szenario vor dem Übergang zu
Kafka- und Kafka-Streams: Agenten kommunizieren ihre Übermittlungen über die API. Der aktualisierte Status wird über eine zentrale Datenbank berechnetLernen Sie Kafka Streams kennen - jetzt ist es einfach, Microservices mit gemeinsamem Status zu erstellenVor etwa einem Jahr haben wir beschlossen, unsere gemeinsamen Zustandsszenarien gründlich zu überprüfen, um solche Probleme zu lösen. Wir haben uns sofort für Kafka Streams entschieden - wir wissen, wie skalierbar, leicht zugänglich und fehlertolerant es ist, wie umfangreich seine Streaming-Funktionalität ist (Transformationen, einschließlich Stateful-Transformationen). Genau das, was wir brauchten, ganz zu schweigen davon, wie ausgereift und zuverlässig das Messaging-System bei Kafka war.
Jeder der von uns erstellten zustandserhaltenden Mikrodienste wurde auf der Grundlage der Kafka Streams-Instanz mit einer relativ einfachen Topologie erstellt. Es bestand aus 1) einer Quelle 2) einem Prozessor mit einer permanenten Speicherung von Schlüsseln und Werten 3) Drain:
 Abbildung 2: Die Standardtopologie unserer Streaming-Instanzen für Stateful Microservices. Bitte beachten Sie, dass es auch ein Repository gibt, das Planungsmetadaten enthält.
Abbildung 2: Die Standardtopologie unserer Streaming-Instanzen für Stateful Microservices. Bitte beachten Sie, dass es auch ein Repository gibt, das Planungsmetadaten enthält.Mit diesem neuen Ansatz verfassen Agenten Nachrichten, die an das ursprüngliche Thema übermittelt wurden, und Verbraucher - beispielsweise ein E-Mail-Benachrichtigungsdienst - akzeptieren den berechneten gemeinsamen Status über den Bestand (Ausgabethema).
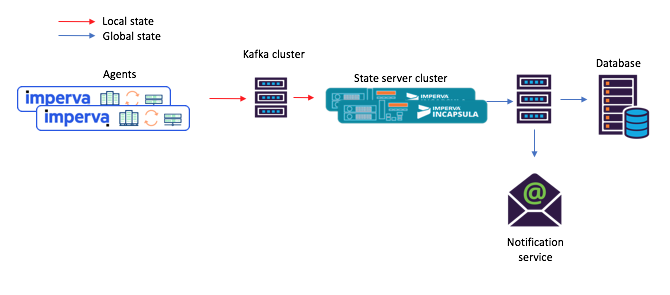 Abbildung 3: Ein neues Beispiel für einen Taskflow für ein Szenario mit gemeinsam genutzten Microservices: 1) Der Agent generiert eine Nachricht, die im ursprünglichen Kafka-Thema eingeht. 2) ein Mikrodienst mit einem gemeinsam genutzten Status (unter Verwendung von Kafka-Streams) verarbeitet ihn und schreibt den berechneten Status in das endgültige Kafka-Thema; Danach 3) akzeptieren die Verbraucher den neuen StaatHey, dieses eingebaute Repository mit Schlüsseln und Werten ist tatsächlich sehr nützlich!
Abbildung 3: Ein neues Beispiel für einen Taskflow für ein Szenario mit gemeinsam genutzten Microservices: 1) Der Agent generiert eine Nachricht, die im ursprünglichen Kafka-Thema eingeht. 2) ein Mikrodienst mit einem gemeinsam genutzten Status (unter Verwendung von Kafka-Streams) verarbeitet ihn und schreibt den berechneten Status in das endgültige Kafka-Thema; Danach 3) akzeptieren die Verbraucher den neuen StaatHey, dieses eingebaute Repository mit Schlüsseln und Werten ist tatsächlich sehr nützlich!Wie oben erwähnt, enthält unsere Shared-State-Topologie einen Speicher mit Schlüsseln und Werten. Wir haben verschiedene Optionen für die Verwendung gefunden, von denen zwei im Folgenden beschrieben werden.
Option 1: Verwenden des Schlüsselspeichers und des Wertspeichers für BerechnungenUnser erstes Repository mit Schlüsseln und Werten enthielt Zusatzdaten, die wir für Berechnungen benötigten. In einigen Fällen wurde beispielsweise der geteilte Staat auf der Grundlage eines Mehrheitsentscheidungsprinzips bestimmt. Im Repository konnten die neuesten Agentenberichte zum Status eines bestimmten Objekts gespeichert werden. Wenn wir dann einen neuen Bericht von einem Agenten erhalten, können wir ihn speichern, Berichte von allen anderen Agenten über den Status desselben Objekts aus dem Repository extrahieren und die Berechnung wiederholen.
Abbildung 4 unten zeigt, wie wir den Zugriff auf den Schlüssel- und Wertspeicher für die Verarbeitungsmethode des Prozessors geöffnet haben, damit wir die neue Nachricht verarbeiten können.
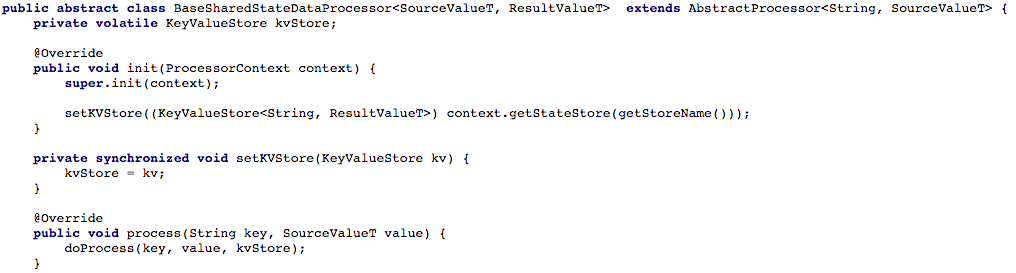 Abbildung 4: Wir öffnen den Zugriff auf die Speicherung von Schlüsseln und Werten für die Verarbeitungsmethode des Prozessors (danach müssen Sie in jedem Skript, das mit einem gemeinsam genutzten Status arbeitet, die
Abbildung 4: Wir öffnen den Zugriff auf die Speicherung von Schlüsseln und Werten für die Verarbeitungsmethode des Prozessors (danach müssen Sie in jedem Skript, das mit einem gemeinsam genutzten Status arbeitet, die doProcess Methode implementieren).Option 2: Erstellen einer CRUD-API über Kafka StreamsNachdem wir unseren grundlegenden Aufgabenfluss angepasst hatten, versuchten wir, eine RESTful CRUD-API für unsere Shared-Service-Microservices zu schreiben. Wir wollten in der Lage sein, den Status einiger oder aller Objekte zu extrahieren sowie den Status des Objekts festzulegen oder zu löschen (dies ist nützlich, wenn die Serverseite dies unterstützt).
Um alle Get State-APIs zu unterstützen, haben wir den Status immer dann, wenn wir ihn während der Verarbeitung neu berechnen mussten, für lange Zeit in das integrierte Repository mit Schlüsseln und Werten gestellt. In diesem Fall wird es recht einfach, eine solche API mit einer einzelnen Instanz von Kafka Streams zu implementieren, wie in der folgenden Liste gezeigt:
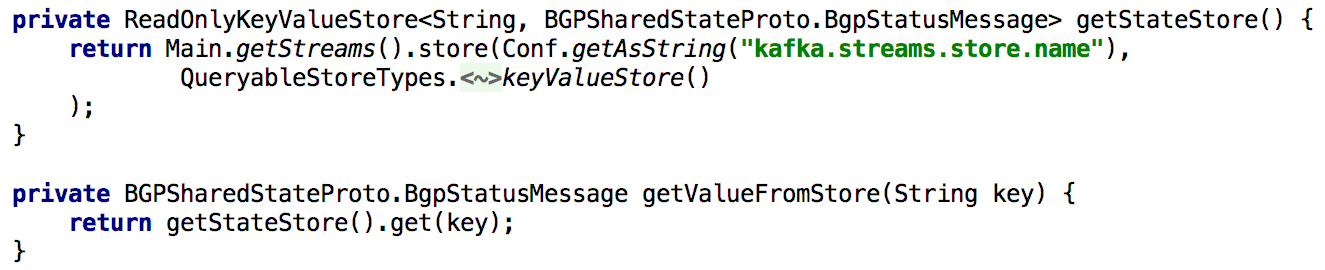 Abbildung 5: Verwenden der integrierten Speicherung von Schlüsseln und Werten, um den vorberechneten Status eines Objekts zu erhalten
Abbildung 5: Verwenden der integrierten Speicherung von Schlüsseln und Werten, um den vorberechneten Status eines Objekts zu erhaltenDas Aktualisieren des Status eines Objekts über die API ist ebenfalls einfach zu implementieren. Im Prinzip müssen Sie dafür nur einen Produzenten Kafka erstellen und mit dessen Hilfe eine Aufzeichnung erstellen, in der ein neuer Zustand hergestellt wird. Dies stellt sicher, dass alle über die API generierten Nachrichten auf die gleiche Weise verarbeitet werden, wie sie von anderen Herstellern (z. B. Agenten) empfangen wurden.
 Abbildung 6: Sie können den Status eines Objekts mit dem Produzenten Kafka festlegenEine kleine Komplikation: Kafka hat viele Partitionen.
Abbildung 6: Sie können den Status eines Objekts mit dem Produzenten Kafka festlegenEine kleine Komplikation: Kafka hat viele Partitionen.Als Nächstes wollten wir die Verarbeitungslast verteilen und die Verfügbarkeit verbessern, indem wir für jedes Szenario einen Microservice-Cluster mit gemeinsamem Dienst bereitstellen. Das Setup wurde uns so einfach wie möglich gegeben: Nachdem wir alle Instanzen so konfiguriert hatten, dass sie mit derselben Anwendungs-ID (und mit denselben Boot-Servern) arbeiteten, wurde fast alles andere automatisch erledigt. Wir legen außerdem fest, dass jedes Quellthema aus mehreren Partitionen besteht, sodass jeder Instanz eine Teilmenge solcher Partitionen zugewiesen werden kann.
Ich möchte auch erwähnen, dass es normal ist, eine Sicherungskopie des Statusspeichers zu erstellen, damit diese Kopie beispielsweise im Falle einer Wiederherstellung nach einem Fehler auf eine andere Instanz übertragen wird. Für jeden Statusspeicher in Kafka Streams wird ein repliziertes Thema mit einem Änderungsprotokoll erstellt (in dem lokale Aktualisierungen verfolgt werden). So sichert Kafka ständig den Staatsladen. Daher kann im Falle eines Ausfalls der einen oder anderen Kafka Streams-Instanz der Statusspeicher schnell in einer anderen Instanz wiederhergestellt werden, in die die entsprechenden Partitionen verschoben werden. Unsere Tests haben gezeigt, dass dies in Sekundenschnelle erledigt werden kann, selbst wenn sich Millionen von Datensätzen im Repository befinden.
Beim Wechsel von einem Shared-Service-Microservice zu einem Cluster von Microservices ist die Implementierung der Get State-API weniger trivial. In der neuen Situation enthält das Status-Repository jedes Mikrodienstes nur einen Teil des Gesamtbilds (die Objekte, deren Schlüssel einer bestimmten Partition zugeordnet wurden). Wir mussten feststellen, in welcher Instanz der Status des benötigten Objekts enthalten war, und dies basierend auf den Flussmetadaten, wie unten gezeigt:
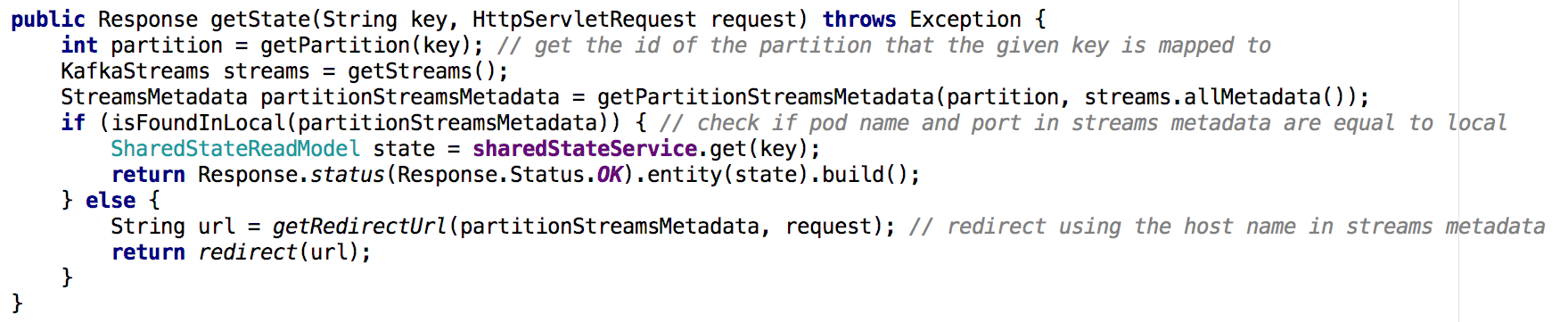 Abbildung 7: Mithilfe von Flussmetadaten bestimmen wir, von welcher Instanz der Status des gewünschten Objekts angefordert werden soll. Ein ähnlicher Ansatz wurde mit der GET ALL-API verwendetWichtigste Ergebnisse
Abbildung 7: Mithilfe von Flussmetadaten bestimmen wir, von welcher Instanz der Status des gewünschten Objekts angefordert werden soll. Ein ähnlicher Ansatz wurde mit der GET ALL-API verwendetWichtigste ErgebnisseStaatliche Geschäfte in Kafka Streams können de facto als verteilte Datenbank dienen.
- kontinuierlich in kafka repliziert
- Auf einem solchen System kann leicht eine CRUD-API erstellt werden
- Das Verarbeiten mehrerer Partitionen ist etwas komplizierter
- Es ist auch möglich, der Stream-Topologie einen oder mehrere Statusspeicher zum Speichern von Hilfsdaten hinzuzufügen. Diese Option kann verwendet werden für:
- Langzeitspeicherung von Daten, die für Berechnungen in der Streaming-Verarbeitung benötigt werden
- Langzeitspeicherung von Daten, die bei der nächsten Initialisierung der Stream-Instanz hilfreich sein können
- viel mehr ...
Dank dieser und anderer Vorteile eignet sich Kafka Streams hervorragend zur Unterstützung des globalen Status in einem verteilten System wie dem unseren. Kafka Streams hat sich in der Produktion als sehr zuverlässig erwiesen (vom Zeitpunkt der Bereitstellung an haben wir praktisch keine Nachrichten verloren), und wir sind sicher, dass dies nicht auf seine Funktionen beschränkt ist!