Nun, wir wissen bereits alles, was Sie zum Programmieren von UDB benötigen. Aber es ist eine Sache zu wissen und eine ganz andere, in der Lage zu sein. Deshalb werden wir heute diskutieren, wo und wie wir uns inspirieren lassen können, um unsere eigenen Fähigkeiten zu verbessern und Erfahrungen zu sammeln. Wie aus der
Übersetzung der Dokumentation hervorgeht , gibt es trockenes Wissen, das nicht immer an die reale Praxis gebunden ist (ich habe in einer ziemlich langen Notiz darauf hingewiesen, bis zur letzten Übersetzung bis heute). Tatsächlich zeigt die Statistik der Artikelansichten, dass immer weniger Menschen Übersetzungen lesen. Es gab sogar einen Vorschlag, diesen Zyklus als uninteressant zu unterbrechen, aber es blieben nur zwei Teile übrig, weshalb am Ende einfach beschlossen wurde, das Tempo ihrer Vorbereitung zu verkürzen. Im Allgemeinen ist die Dokumentation für den Controller eine notwendige Sache, aber nicht autark. Wo sonst kann man sich inspirieren lassen?

Zunächst kann ich das hervorragende Dokument
AN82156 Entwerfen von PSoC Creator-Komponenten mit UDB-Datenpfaden empfehlen . Darin finden Sie typische Lösungen sowie mehrere Standardprojekte. Darüber hinaus wird die Entwicklung zu Beginn des Dokuments mit dem UDB-Editor und gegen Ende mit dem Datapath Config Tool ausgeführt, dh das Dokument deckt alle Aspekte der Entwicklung ab. Wenn ich jedoch den Preis eines einzelnen PSoC-Chips betrachte, würde ich sagen, dass der Controller stark überbewertet ist, wenn er nur die in diesem Dokument beschriebenen Probleme lösen kann. PWMs und serielle Standardanschlüsse können ohne PSoC ausgeführt werden. Glücklicherweise ist das Spektrum der PSoC-Aufgaben viel breiter. Nachdem wir AN82156 gelesen haben, suchen wir nach anderen Inspirationsquellen.
Die nächste nützliche Quelle sind die Beispiele, die mit PSoC Creator geliefert werden. Ich habe sie bereits in einem Hinweis auf einen der Teile der Übersetzung der Unternehmensdokumentation erwähnt (siehe
hier ). Sie werden ungefähr hier gespeichert (die Festplatte kann abweichen):
E: \ Programme (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ psoc \ content \ CyComponentLibrary.
Sie sollten nach * .v-Dateien suchen, dh nach Verilog-Texten oder * .vhd, da die Syntax der VHDL-Sprache etwas ausführlicher beschrieben werden muss. In dieser Sprache finden Sie manchmal interessante Nuancen, die den Augen des Programmierers bei Verilog verborgen bleiben. Das Problem ist, dass dies keine Beispiele sind, sondern vorgefertigte Lösungen. Das ist wunderbar, sie sind perfekt getestet, aber wir, einfache Programmierer, haben mit den Cypress-Programmierern unterschiedliche Ziele. Unsere Aufgabe ist es, in kurzer Zeit etwas Hilfreiches zu tun. Danach beginnen wir, es in unseren Projekten zu verwenden, für die wir die meiste Zeit aufwenden werden. Es sollte idealerweise die uns heute zugewiesenen Aufgaben lösen, und wenn wir morgen denselben Code in ein anderes Projekt einfügen möchten, in dem alles etwas anders sein wird, werden wir es morgen in dieser Situation beenden. Für Cypress-Entwickler ist die Komponente das Endprodukt, sodass sie die meiste Zeit damit verbringen können. Und sie müssen für alles sorgen. Als ich mir diese Texte ansah, war ich traurig. Sie sind zu komplex für jemanden, der gerade angefangen hat, nach Inspirationsquellen für seine ersten Entwicklungen zu suchen. Aber als Referenz sind diese Texte durchaus geeignet. Es gibt viele wertvolle Designs, die benötigt werden, um Ihre eigenen Dinge zu erstellen.
Auch gibt es sehr interessante Ecken. Zum Beispiel gibt es, jetzt sage ich im Stil von "Butteröl", Modelle für die Modellierung (vor langer Zeit hat mich ein strenger Lehrer davon abgehalten, Simulationen auf andere Weise als "Modellieren" zu übersetzen). Sie finden sie im Katalog.
E: \ Programme (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim.
Das interessanteste Verzeichnis für den Programmierer auf Verilogue ist:
E: \ Programme (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim \ presynth \ vlg.
Die Beschreibung der Komponenten in der Dokumentation ist gut. Hier werden jedoch Verhaltensmodelle für alle Standardkomponenten beschrieben. Manchmal ist dies besser als die Dokumentation (die in einer schweren Sprache verfasst ist und einige wesentliche Details weggelassen werden). Wenn das Verhalten dieser oder jener Komponente nicht klar ist, sollten Sie versuchen, es genau zu verstehen, indem Sie Dateien aus diesem Verzeichnis anzeigen. Zuerst habe ich versucht, auf Google zu suchen, aber sehr oft habe ich in den gefundenen Foren nur Argumente und keine Einzelheiten getroffen. Hier sind genau die Einzelheiten.
Trotzdem ist das Nachschlagewerk wunderbar, aber wo kann man nach einem Lehrbuch suchen, woraus kann man lernen? Ehrlich gesagt gibt es nichts Besonderes. Es gibt nicht viele gute fertige Beispiele für den UDB-Editor. Ich hatte großes Glück, dass ich, als ich mich plötzlich entschied, RGB-LEDs zu spielen, unter dem UDB-Editor auf ein schönes Beispiel stieß (darüber schrieb ich in dem
Artikel , der den gesamten Zyklus startete). Wenn Sie jedoch viel mit einer Suchmaschine arbeiten, gibt es immer noch Beispiele für das Datapath-Konfigurationstool. Deshalb habe ich den
vorherigen Artikel erstellt, damit jeder versteht, wie dieses Tool verwendet wird. Und hier befindet sich eine wunderbare Seite, auf der viele Beispiele gesammelt
werden .
Auf dieser Seite finden Sie Entwicklungen von Drittentwicklern, die jedoch von Cypress überprüft wurden. Das ist genau das, was wir brauchen: Wir sind auch Entwickler von Drittanbietern, aber wir möchten aus etwas lernen, das genau verifiziert ist. Schauen wir uns ein Beispiel an, in dem ich diese Seite gefunden habe - einen Hardware-Rechner mit Quadratwurzel. Endbenutzer nehmen es in den Signalverarbeitungspfad auf und werfen eine Komponente auf die Schaltung. In diesem Beispiel werden wir trainieren, um einen ähnlichen Code zu analysieren, und dann kann jeder unabhängig schwimmen. Das erforderliche Beispiel kann also über den
Link heruntergeladen werden.
Wir untersuchen es. Es gibt Beispiele (die jeder unabhängig betrachten wird) und Bibliotheken im Verzeichnis \ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib.
Für jeden Typ (Ganzzahl oder Festpunkt) und für jedes Bit gibt es eine Lösung. Dies sollte beachtet werden. Vielseitigkeit ist gut, wenn Sie im UDB-Editor entwickeln, aber wie Sie sehen, werden Menschen bei der Entwicklung mit dem Datenpfad-Bearbeitungstool wie folgt gequält. Haben Sie keine Angst, wenn Sie es nicht universell machen können (aber wenn es besser funktioniert).
Auf der obersten Ebene (Schaltung) werde ich nicht aufhören, wir studieren nicht mit PSoC, sondern mit UDB. Schauen wir uns eine Option mittlerer Komplexität an - 16 Bit, aber ganzzahlig. Es befindet sich im Verzeichnis CJCU_B_Isqrt16_v1_0.
Als erstes müssen Sie das Übergangsdiagramm der Firmware erweitern. Ohne sie werden wir nicht einmal erraten, welche Art von Quadratwurzel-Algorithmus angewendet wurde, da Google eine Auswahl mehrerer grundlegend unterschiedlicher Algorithmen anbietet.
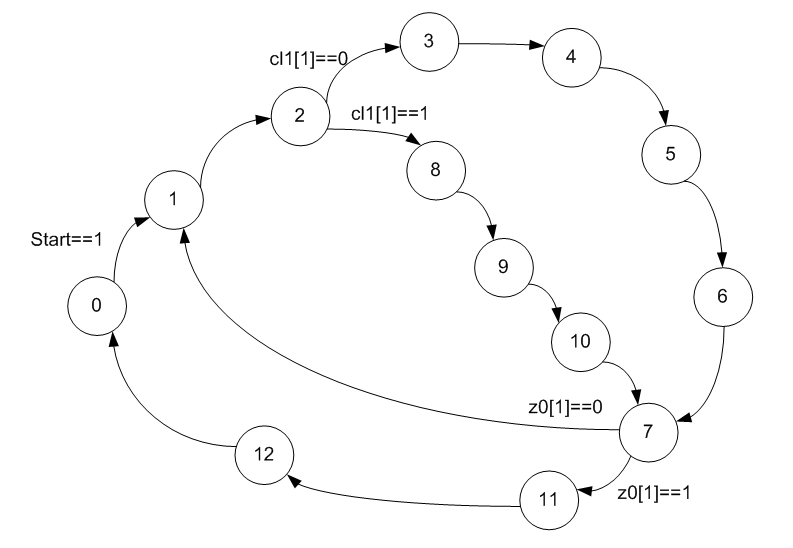
Bisher ist nichts klar, aber es ist vorhersehbar. Müssen weitere Informationen hinzufügen. Wir betrachten die Zustandscodierung. Es fällt auf, dass sie nicht im üblichen inkrementellen Binärcode codiert sind.

Ich habe diesen Ansatz bereits in meinen Artikeln erwähnt, konnte ihn jedoch in bestimmten Beispielen nie verwenden. Ich möchte Sie daran erinnern, dass die dynamische Konfiguration der RAM ALU nur drei Adresseneingänge hat. Das heißt, ALU kann eine von acht Operationen ausführen. Wenn der Automat mehr Zustände hat, wird die Regel "Jeder Zustand hat seine eigene Operation" unmöglich. Daher werden Zustände ausgewählt, in denen die Operationen für die ALU identisch sind, sie haben drei Bits, die an die RAM-Adresse der dynamischen Konfiguration geliefert werden (normalerweise niederwertige), sie werden auf die gleiche Weise codiert und der Rest auf verschiedene Arten. Wie man einen solchen Solitaire addiert, ist bereits ein Entwicklerproblem. Die Entwickler des untersuchten Codes haben genau wie oben gezeigt gefaltet.
Fügen Sie diese Informationen zum Diagramm hinzu und färben Sie die Zustände, die dieselbe Funktion in ALU ausführen, in ähnlichen Farben.
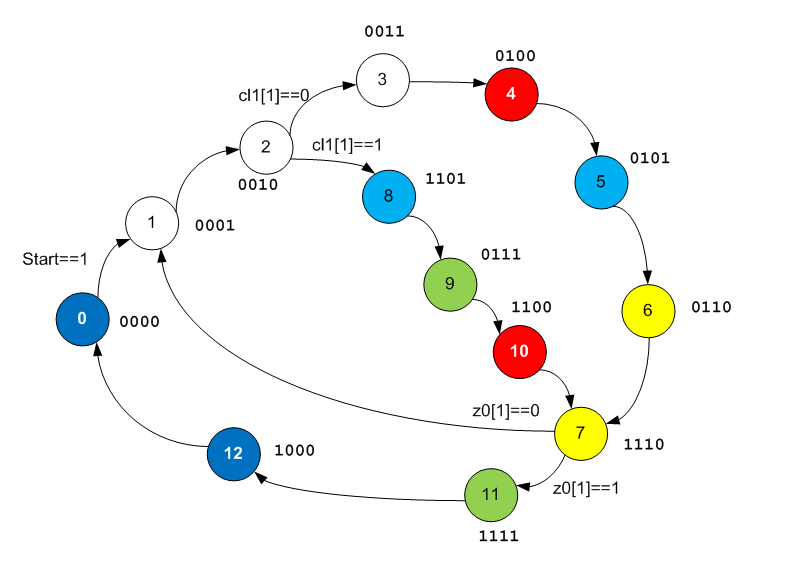
Es wurden noch keine Muster manifestiert, aber wir öffnen das Diagramm weiterhin. Wir öffnen das Datapath Edit Tool und studieren bereits die darin enthaltene Logik.
Bitte beachten Sie, dass zwei Datenpfadblöcke in einer Kette verbunden sind. Wenn wir etwas Eigenes tun, benötigen wir möglicherweise auch Folgendes (das Datenpfad-Bearbeitungstool kann jedoch Blöcke erstellen, die bereits in einer Kette verknüpft sind, sodass dies nicht beängstigend ist):
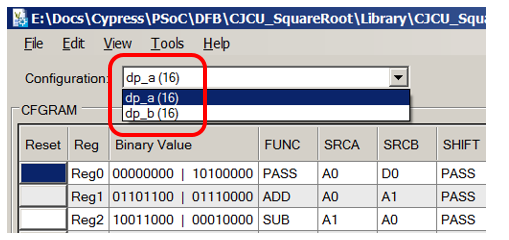
Beim Lesen (und Ausfüllen) des ALU entsprechenden Diagramms öffnen wir immer ein Dokument mit der folgenden Abbildung:

Die Entwickler dieses Beispiels haben sich um uns gekümmert und die Kommentarfelder ausgefüllt. Jetzt können wir sie verwenden, um zu verstehen, wofür konfiguriert ist. Gleichzeitig stellen wir für uns selbst fest, dass das Schreiben von Kommentaren immer nützlich ist, sowohl für diejenigen, die den Code begleiten, als auch für uns, wenn wir in sechs Monaten alles darüber vergessen werden.
Wir betrachten den X000-Code, der den Zuständen 0 und 12 entspricht:

Aus dem Kommentar geht bereits hervor, was dort passiert (der Inhalt von Register D0 wird in Register A0 und der Inhalt von D1 in Register A1 kopiert. Da wir dies wissen, trainieren wir unsere Intuition für die Zukunft und finden einen ähnlichen Eintrag in den Einstellungsfeldern:

Dort sehen wir, dass die ALU im
PASS- Modus arbeitet, das Schieberegister ist ebenfalls
PASS , so dass keine anderen Aktionen wirklich ausgeführt werden.
Unterwegs schauen wir uns den Text in Verilog an und sehen, wo der Wert der Register D0 und D1 gleich ist:

Falls gewünscht, können Sie dasselbe im Datenpfad-Konfigurationstool anzeigen, indem Sie Ansicht-> Anfangsregisterwerte wählen:
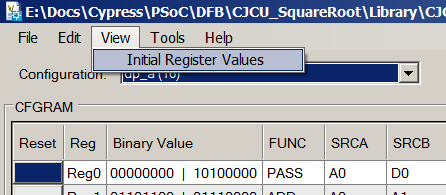
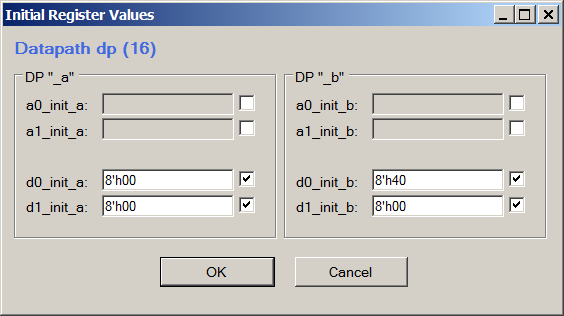
Für die Anzeige ist es bequemer, Verilog-Code direkt zu analysieren und eine eigene Version zu erstellen. Arbeiten Sie den Editor ab, um die Syntax nicht zu berücksichtigen.
In ähnlicher Weise analysieren wir (zunächst in den Kommentaren) alle anderen Funktionen von ALU:
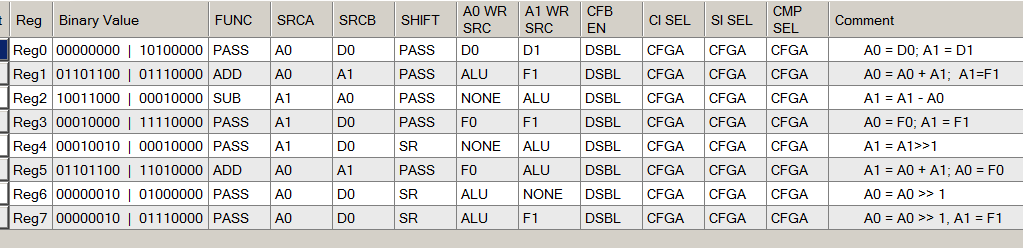
Wir wiederholen den Übergangsgraphen des Automaten unter Berücksichtigung neuer Erkenntnisse:

Es zeichnet sich bereits etwas ab, aber bisher kann ich keinen der von Google in dieser Grafik gefundenen Algorithmen mit Sicherheit festlegen. Über einige kann man eher zuversichtlich sagen, dass es nicht sie sind, aber selbst für die Glaubwürdigen kann ich immer noch keine sichere Antwort geben, dass sie es sind. Verwirrt die aktive Verwendung der Register FIFO F0 und F1. Im Allgemeinen in der Datei
\ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib \ CJCU_Isqrt_v1_0 \ API \ CJCU_Isqrt.c
Es ist ersichtlich, dass F1 verwendet wird, um das Argument zu übergeben und das Ergebnis zurückzugeben:

Gleicher Text:void `$INSTANCE_NAME`_ComputeIsqrtAsync(uint`$regWidth` square) { /* Set up FIFOs, start the computation. */ CY_SET_REG`$dpWidth`(`$INSTANCE_NAME`_F1, square); CY_SET_REG8(`$INSTANCE_NAME`_CTL, 0x01); } … uint`$resultWidth` `$INSTANCE_NAME`_ReadIsqrtAsync() { /* Read back result. */ return CY_GET_REG`$dpWidth`(`$INSTANCE_NAME`_F1); }
Aber ein Argument und ein Ergebnis. Und warum gibt es im Laufe der Arbeit so viele Anrufe beim FIFO? Und was hat FIFO0 damit zu tun? Schneiden Sie mich in Stücke, aber es scheint, dass die Autoren den Modus ausnutzten, der bei Übersetzungen der Dokumentation auftrat, als dieser Block anstelle eines vollwertigen FIFO als ein einziges Register fungierte. Angenommen, die Autoren haben beschlossen, den Registersatz zu erweitern. Wenn ja, dann ist ihre Methodik für uns in unserer praktischen Arbeit nützlich. Lassen Sie uns die Details untersuchen. In der Dokumentation werden verschiedene Ansätze für die Arbeit mit FIFO beschrieben. Sie können - so können Sie - so, aber Sie können - irgendwie. Und keine Einzelheiten. Wir haben wieder die Möglichkeit, uns über die besten internationalen Praktiken zu informieren. Was machen Autoren mit FIFO?
Erstens sind dies die Signalzuweisungen:
wire f0_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_4); wire f1_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_3 || state == B_SQRT_STATE_9 || state == B_SQRT_STATE_11); wire fifo_dyn = (state == B_SQRT_STATE_0 || state == B_SQRT_STATE_12);
Zweitens ist hier eine Verbindung zu Datapath:
/* input */ .f0_load(f0_load), /* input */ .f1_load(f1_load), /* input */ .d0_load(1'b0), /* input */ .d1_load(fifo_dyn),
Aus der Beschreibung der Steuerung geht nicht besonders hervor, was dies alles bedeutet. Aber aus Application Note habe ich herausgefunden, dass diese Einstellung für alles verantwortlich ist:

Gerade wegen dieser Einstellung kann dieser Block übrigens nicht mit dem UDB-Editor beschrieben werden. Wenn sich diese Steuerbits im
EIN- Zustand befinden, kann FIFO an verschiedenen Quellen und Empfängern arbeiten. Wenn
Dx_LOAD gleich eins ist, tauscht
Fx mit dem Systembus aus, wenn Null, dann mit dem hier ausgewählten Register:

Es stellt sich heraus, dass F0 in den Zuständen 12 und 0 immer mit dem Register A0 und F1 mit dem Systembus (um das Ergebnis hochzuladen und das Argument zu laden), in anderen Zuständen - mit A1 austauscht.
Ferner haben wir aus dem Verilog-Code herausgefunden, dass in F0 die Daten in den Zuständen 1 und 4 und in F1 - in den Zuständen 1, 3, 9, 11 geladen werden.
Fügen Sie das erworbene Wissen zum Diagramm hinzu. Um Verwirrung während der Abfolge der Operationen zu vermeiden, war es auch an der Zeit, die Zuweisungsmarke „a la UDB Editor“ durch Verilogovs Pfeile zu ersetzen, um hervorzuheben, dass die Quelle der Wert des Signals ist, das es vor dem Betreten des Blocks hatte.

Aus Sicht der Analyse des Algorithmus ist bereits alles klar. Vor uns liegt eine Modifikation eines solchen Algorithmus:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 30; // The second-to-top bit is set: use 1u << 14 for uint16_t type; use 1uL<<30 for uint32_t type // "one" starts at the highest power of four <= than the argument. while (one > op) { one >>= 2; } while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Nur in Bezug auf unser System wird es eher so aussehen:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 14; // The second-to-top bit is set while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Die Zustände 4 und 10 codieren die Zeichenfolge explizit:
res >>= 1;
für verschiedene Branchen.
Die Zeile lautet:
one >>= 2;
Es wird explizit entweder durch ein Paar von Zuständen 6 und 7 oder durch ein Paar von Zuständen 9 und 7 codiert. Im Moment möchte ich ausrufen: „Nun, die Erfinder sind dieselben Autoren!“, aber sehr bald wird klar, warum es bei zwei Zweigen eine solche Schwierigkeit gibt (im C-Code gibt es einen Zweig und Problemumgehung).
Zustand 2 codiert einen bedingten Zweig. Zustand 7 codiert eine Schleifenanweisung. Die Vergleichsoperation in Schritt 2 ist sehr teuer. Im Allgemeinen enthält das Register A0 in den meisten Schritten die Variable Eins. In Schritt 1 wird jedoch die Variable Eins auf F0 entladen, und stattdessen wird der Wert
res + eins geladen. In Schritt 2 wird die Subtraktion zum Vergleich durchgeführt, und in den Schritten 3 und 8 wird der Wert
Eins wiederhergestellt. Warum in Schritt 4 A0 erneut nach F0 kopiert wird, habe ich nicht verstanden. Vielleicht ist das eine Art Rudiment.
Es bleibt herauszufinden, wer
res und wer
op ist . Wir wissen, dass die Bedingung op und res + one vergleicht. In Zustand 1 werden A0 (
eins ) und A1 hinzugefügt. Da ist also A1
res . Es stellt sich heraus, dass in Zustand 11 A1 auch
res ist , und er ist es, der in F1 gelangt, der dem Ausgang der Funktion zugeführt wird. F1 in Zustand 1 ist eindeutig
op . Ich schlage vor, die Farbdifferenzierung der
Hosen der Variablen einzuführen. Wir bezeichnen
res als rot,
op als grün und
eins als braun (nicht ganz kontrastiert, aber die anderen Farben sind noch weniger kontrastiert).
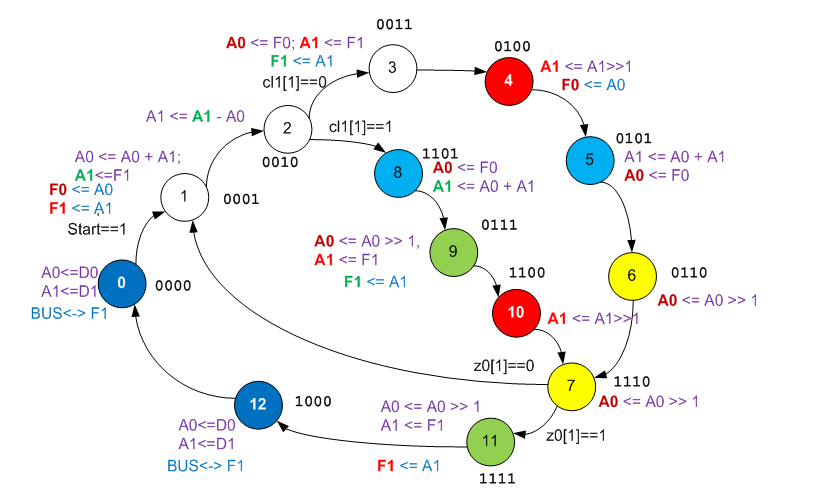
Tatsächlich wird die ganze Wahrheit offenbart. Wir sehen, wie sich A1 zum Vergleich und für Berechnungen vorübergehend von F1 ändert, wie derselbe Unterschied sowohl zum Vergleich (tatsächlich zur Erzeugung von Bit C) als auch zur Teilnahme an der Formel verwendet wird. Wir sehen sogar, warum der leere Raum (Bypass) im C-Algorithmus durch einen langen Zweig des Übergangsgraphen des Automaten codiert wird (in diesem Zweig werden die Register identisch mit dem Austausch ausgetauscht, der im Hauptcodezweig stattfindet). Wir sehen alles.
Die einzige Frage, die mich immer wieder quält, ist, wie die Autoren FIFO in den Einzelbyte-Modus geschaltet haben. In der Dokumentation heißt es, dass Sie dazu die CLR-Bits im Auxiliary Control-Register in eine Einheit heben müssen, aber ich sehe nicht, dass die API über solche Datensätze verfügt. Vielleicht wird jemand dies verstehen und in die Kommentare schreiben.
Nun, und etwas Eigenes zu entwickeln - in umgekehrter Reihenfolge mit den erworbenen Fähigkeiten.
Fazit
Um die Fähigkeiten zur Entwicklung von „Firmware“ auf Basis von UDB zu entwickeln, ist es nützlich, nicht nur die Dokumentation zu lesen, sondern sich auch von den Designs anderer inspirieren zu lassen. Der mit dem PSoC Creator gelieferte Code kann als Referenz hilfreich sein. Die im Compiler enthaltenen Verhaltensmodelle helfen Ihnen dabei, besser zu verstehen, was in der Dokumentation gemeint war. Der Artikel enthält auch einen Link zu einer Reihe von Beispielen von Drittherstellern und zeigt, wie eines dieser Beispiele analysiert wird.
In diesem Zusammenhang kann der Zyklus von Copyright-Artikeln zur Arbeit mit UDB als abgeschlossen betrachtet werden. Ich würde mich freuen, wenn er jemandem helfen würde, Wissen zu erlangen, das in der Praxis nützlich ist. Es liegen einige Übersetzungen der Dokumentation vor uns, aber Statistiken zeigen, dass fast niemand sie liest. Sie sind sauber geplant, um das Thema nicht auf den Punkt zu bringen.