Beim Übergang von einer monolithischen Anwendung zu einer Microservice-Architektur stehen wir vor neuen Problemen.
In einer monolithischen Anwendung ist es normalerweise recht einfach zu bestimmen, in welchem Teil des Systems ein Fehler aufgetreten ist. Das Problem liegt höchstwahrscheinlich im Code des Monolithen selbst oder in der Datenbank. Wenn wir jedoch nach einem Problem in der Microservice-Architektur suchen, ist nicht alles so offensichtlich. Sie müssen den gesamten Pfad finden, den die Anforderung von Anfang bis Ende durchlaufen hat, um sie aus Hunderten von Microservices auszuwählen. Darüber hinaus verfügen viele von ihnen über eigene Repositorys, in denen auch logische Fehler sowie Leistungs- und Fehlertoleranzprobleme auftreten können.

Ich habe lange nach einem Tool gesucht, das bei der Bewältigung solcher Probleme hilft (ich habe darüber in Habré geschrieben: 1 , 2 ), aber am Ende habe ich meine eigene Open-Source-Lösung entwickelt. In dem Artikel spreche ich über die Vorteile des Service-Mesh-Ansatzes und teile ein neues Tool für dessen Implementierung.
Die verteilte Ablaufverfolgung ist eine häufige Lösung für das Problem, Fehler in verteilten Systemen zu finden. Was aber, wenn das System einen solchen Ansatz zum Sammeln von Informationen über Netzwerkinteraktionen noch nicht implementiert hat oder, schlimmer noch, in dem Teil des Systems, in dem es bereits ordnungsgemäß funktioniert, und in dem Teil, in dem dies nicht der Fall ist, da es nicht zu den alten Diensten hinzugefügt wird? Um die genaue Grundursache des Problems zu ermitteln, müssen Sie ein vollständiges Bild davon haben, was im System geschieht. Es ist besonders wichtig zu verstehen, welche Microservices an den wichtigsten geschäftskritischen Pfaden beteiligt sind.
Hier kann uns ein Service-Mesh-Ansatz zu Hilfe kommen, der sich mit allen Maschinen zum Sammeln von Netzwerkinformationen auf einer Ebene befasst, die niedriger ist als die der Services selbst. Dieser Ansatz ermöglicht es uns, den gesamten Verkehr abzufangen und im laufenden Betrieb zu analysieren. Darüber hinaus sollten Anwendungen darüber nicht einmal etwas wissen.
Service-Mesh-Ansatz
Die Hauptidee des Service-Mesh-Ansatzes besteht darin, eine weitere Infrastrukturschicht über das Netzwerk hinzuzufügen, die es uns ermöglicht, alle Dinge mit dienstübergreifender Interaktion zu tun. Die meisten Implementierungen funktionieren wie folgt: Jedem Mikrodienst wird ein zusätzlicher Beiwagencontainer mit einem transparenten Proxy hinzugefügt, über den der gesamte eingehende und ausgehende Dienstverkehr geleitet wird. Und hier können wir den Kundenausgleich durchführen, Sicherheitsrichtlinien anwenden, die Anzahl der Anforderungen einschränken und wichtige Informationen über das Zusammenspiel von Diensten in der Produktion sammeln.
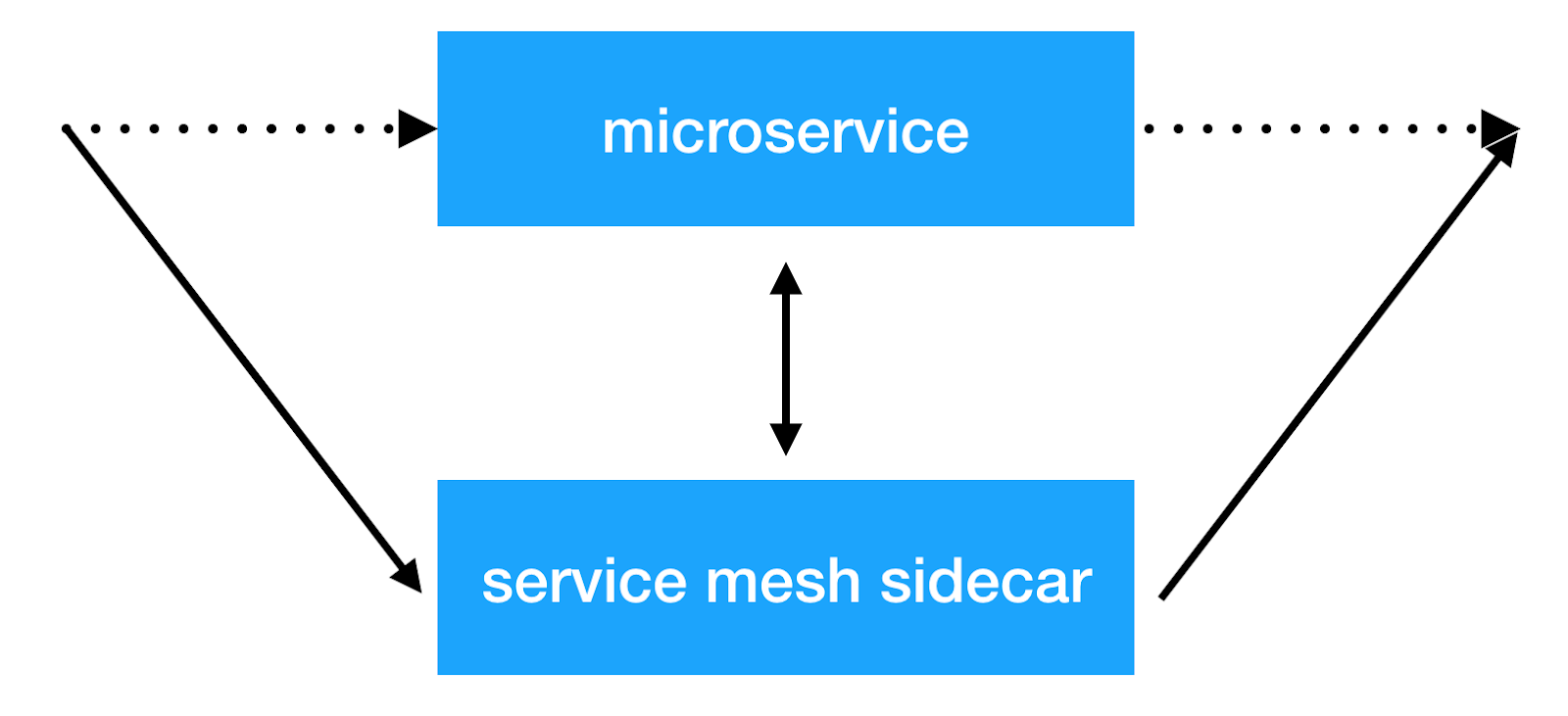
Lösungen
Es gibt bereits mehrere Implementierungen dieses Ansatzes: Istio und linkerd2 . Sie bieten viele sofort einsatzbereite Funktionen. Gleichzeitig entsteht ein großer Aufwand für die Ressourcen. Je größer der Cluster ist, in dem ein solches System funktioniert, desto mehr Ressourcen werden für die Wartung der neuen Infrastruktur benötigt. In Avito betreiben wir Kubernetes-Cluster mit Tausenden von Service-Instanzen (und ihre Anzahl wächst weiterhin schnell). In der aktuellen Implementierung verbraucht Istio ~ 300 MB RAM pro Dienstinstanz. Aufgrund der großen Anzahl von Funktionen wirkt sich ein transparenter Ausgleich auch auf die Gesamtantwortzeit von Diensten aus (bis zu 10 ms).
Infolgedessen haben wir uns genau angesehen, welche Funktionen wir gerade benötigen, und festgestellt, dass der Hauptgrund für die Implementierung solcher Lösungen die Möglichkeit war, Ablaufverfolgungsinformationen vom gesamten System transparent zu erfassen. Wir wollten auch die Kontrolle über die Interaktion von Diensten haben und verschiedene Manipulationen mit den Headern vornehmen, die zwischen Diensten übertragen werden.
Am Ende kamen wir zu unserer Entscheidung: Netramesh .
Netramesh
Netramesh ist eine leichte Service-Mesh-Lösung mit unendlicher Skalierbarkeit, unabhängig von der Anzahl der Services im System.
Die Hauptziele der neuen Lösung waren ein geringer Ressourcenaufwand und eine hohe Leistung. Von den Hauptfunktionen wollten wir sofort in der Lage sein, Ablaufverfolgungsbereiche transparent an unser Jaeger-System zu senden.
Heute sind die meisten Cloud-Lösungen auf Golang implementiert. Und dafür gibt es natürlich Gründe. Das Schreiben von Golang-Netzwerkanwendungen, die asynchron mit E / A arbeiten und nach Bedarf auf Kernel skaliert werden, ist bequem und recht einfach. Und was auch sehr wichtig ist, die Leistung reicht aus, um dieses Problem zu lösen. Deshalb haben wir uns auch für Golang entschieden.
Leistung
Wir haben uns darauf konzentriert, maximale Leistung zu erzielen. Für eine Lösung, die neben jeder Instanz des Dienstes bereitgestellt wird, ist ein geringer RAM- und Prozessorverbrauch erforderlich. Und natürlich sollte auch die Verzögerung bei der Beantwortung gering sein.
Mal sehen, was die Ergebnisse sind.
RAM
Netramesh verbraucht ~ 10 MB ohne Datenverkehr und maximal 50 MB mit einer Last von bis zu 10.000 RPS pro Instanz.
Der Istio Envoy Proxy verbraucht in unseren Clustern mit Tausenden von Instanzen immer ~ 300 MB. Auf diese Weise können Sie es nicht auf den gesamten Cluster skalieren.
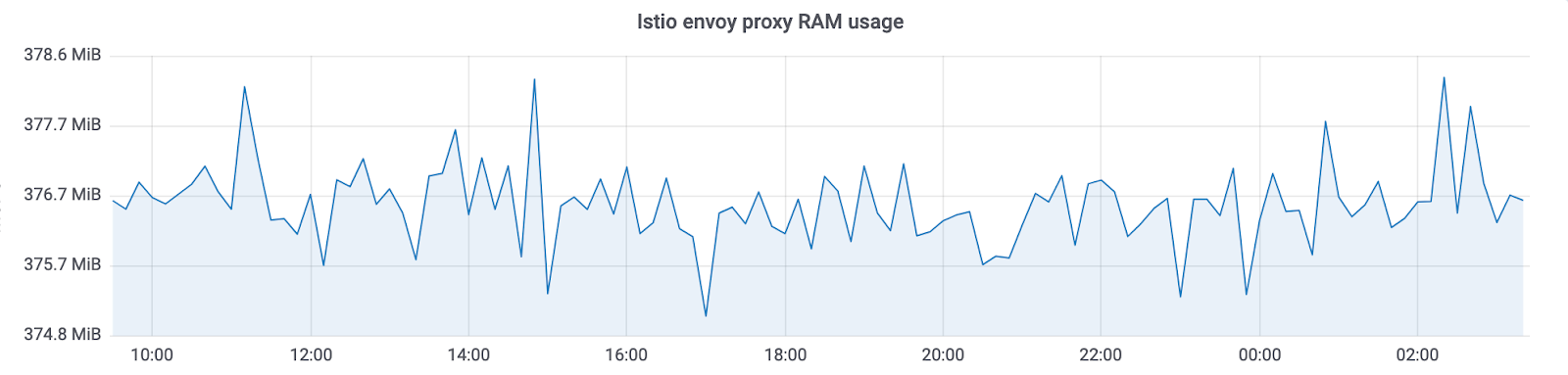

Mit Netramesh haben wir ~ 10-mal weniger Speicherverbrauch.
CPU
Die CPU-Auslastung ist unter Last relativ gleich. Dies hängt von der Anzahl der Anfragen pro Zeiteinheit an den Beiwagen ab. Werte bei 3000 Anfragen pro Sekunde in der Spitze:


Es gibt noch einen weiteren wichtigen Punkt: Netramesh - eine Lösung ohne Steuerebene und ohne Last verbraucht keine CPU-Zeit. Mit Istio aktualisieren die Beiwagen immer die Service-Endpunkte. Als Ergebnis können wir ein solches Bild ohne Last sehen:

Wir verwenden HTTP / 1, um zwischen Diensten zu kommunizieren. Die Verlängerung der Antwortzeit für Istio beim Proxen durch den Gesandten betrug bis zu 5-10 ms, was für Dienste, die in einer Millisekunde bereit sind, zu antworten, ziemlich viel ist. Mit Netramesh verringerte sich diese Zeit auf 0,5 bis 2 ms.
Skalierbarkeit
Eine geringe Menge an Ressourcen, die von jedem Proxy ausgegeben wird, ermöglicht es, ihn neben jedem Dienst zu platzieren. Netramesh wurde absichtlich ohne eine Steuerebenenkomponente entwickelt, um einfach die Leichtigkeit jedes Beiwagens aufrechtzuerhalten. In Service-Mesh-Lösungen verteilt die Steuerebene häufig Service-Discovery-Informationen an jeden Beiwagen. Dazu kommen Informationen zu Zeitüberschreitungen und Ausgleichseinstellungen. All dies ermöglicht es Ihnen, viele nützliche Dinge zu tun, aber leider vergrößert sich die Seitenwagengröße.
Serviceerkennung

Netramesh fügt keine zusätzlichen Mechanismen für die Serviceerkennung hinzu. Der gesamte Verkehr wird transparent über den netra-Beiwagen übertragen.
Netramesh unterstützt das HTTP / 1-Anwendungsprotokoll. Eine konfigurierbare Liste von Ports wird verwendet, um dies zu bestimmen. In der Regel gibt es mehrere Ports auf einem System, die über HTTP kommunizieren. Beispielsweise verwenden wir 80, 8890, 8080 für die Interaktion von Diensten und externen Anforderungen. In diesem Fall können sie mithilfe der Umgebungsvariablen NETRA_HTTP_PORTS .
Wenn Sie Kubernetes als Orchester und seinen Mechanismus von Service-Entitäten für die Intracluster-Interaktion zwischen Services verwenden, bleibt der Mechanismus genau derselbe. Zunächst erhält der Microservice die Service-IP-Adresse mit kube-dns und stellt eine neue Verbindung her. Diese Verbindung wird zuerst mit dem lokalen Netra-Sidecar hergestellt, und alle TCP-Pakete kommen zunächst in Netra an. Als nächstes stellt netra-sidecar eine Verbindung zum ursprünglichen Ziel her. NAT auf dem Pod IP auf dem Knoten bleibt genau das gleiche wie ohne Netra.
Verteilte Ablaufverfolgung und Kontext-Scrolling
Netramesh bietet die Funktionalität, die zum Senden von Ablaufverfolgungsbereichen für HTTP-Interaktionen erforderlich ist. Netra-Sidecar analysiert das HTTP-Protokoll, misst Anforderungsverzögerungen und ruft die erforderlichen Informationen aus HTTP-Headern ab. Letztendlich erhalten wir alle Spuren in einem einzigen Jaeger-System. Zur Feinabstimmung können Sie auch die Umgebungsvariablen verwenden, die von der offiziellen Jaeger Go-Bibliothek bereitgestellt werden .


Aber es gibt ein Problem. Solange die Dienste keinen speziellen Uber-Header generieren und weiterleiten, werden die verbundenen Ablaufverfolgungsbereiche im System nicht angezeigt. Und das ist es, was wir brauchen, um schnell die Ursache der Probleme zu finden. Hier hat Netramesh wieder eine Lösung. Proxies lesen HTTP-Header und generieren sie, wenn sie keine übergeordnete Trace-ID haben. Netramesh speichert auch Informationen zu eingehenden und ausgehenden Anforderungen im Beiwagen und vergleicht diese, indem die erforderlichen Header ausgehender Anforderungen angereichert werden. In den Diensten muss lediglich ein X-Request-Id NETRA_HTTP_REQUEST_ID_HEADER_NAME X-Request-Id Header NETRA_HTTP_REQUEST_ID_HEADER_NAME werden, der mit der Umgebungsvariablen NETRA_HTTP_REQUEST_ID_HEADER_NAME konfiguriert werden NETRA_HTTP_REQUEST_ID_HEADER_NAME . Um die Größe des Kontexts in Netramesh zu steuern, können Sie die folgenden Umgebungsvariablen NETRA_TRACING_CONTEXT_EXPIRATION_MILLISECONDS : NETRA_TRACING_CONTEXT_EXPIRATION_MILLISECONDS (die Zeit, in der der Kontext gespeichert wird) und NETRA_TRACING_CONTEXT_CLEANUP_INTERVAL (Periodizität der Kontextbereinigung).
Es ist auch möglich, mehrere Pfade in Ihrem System zu kombinieren, indem Sie sie mit einem speziellen Sitzungsmarker markieren. Mit Netra können Sie HTTP_HEADER_TAG_MAP , um HTTP-Header in geeignete Tracing-Span-Tags HTTP_HEADER_TAG_MAP . Dies kann besonders zum Testen nützlich sein. Nach dem Bestehen des Funktionstests können Sie sehen, welcher Teil des Systems durch Filtern nach dem entsprechenden Sitzungsschlüssel betroffen ist.
Ermitteln der Quelle der Anforderung
Um festzustellen, woher die Anforderung stammt, können Sie mit der Funktion automatisch einen Header mit einer Quelle hinzufügen. Mit der Umgebungsvariablen NETRA_HTTP_X_SOURCE_HEADER_NAME können Sie den Namen des Headers angeben, der automatisch festgelegt wird. Mit NETRA_HTTP_X_SOURCE_VALUE Sie den Wert festlegen, in dem der X-Source-Header für alle ausgehenden Anforderungen festgelegt wird.
Auf diese Weise können Sie das gesamte Netzwerk einheitlich verteilen, um die Verteilung dieses nützlichen Headers vorzunehmen. Dann können Sie es bereits in Diensten verwenden und zu Protokollen und Metriken hinzufügen.
Netramesh-Verkehr und internes Routing
Netramesh besteht aus zwei Hauptkomponenten. Der erste, netra-init, legt Netzwerkregeln zum Abfangen von Datenverkehr fest. Es verwendet Umleitungsregeln für iptables , um den gesamten oder einen Teil des Datenverkehrs auf dem Beiwagen abzufangen, der die zweite Hauptkomponente von Netramesh darstellt. Sie können konfigurieren, welche Ports Sie für eingehende und ausgehende TCP-Sitzungen INBOUND_INTERCEPT_PORTS, OUTBOUND_INTERCEPT_PORTS : INBOUND_INTERCEPT_PORTS, OUTBOUND_INTERCEPT_PORTS .
Das Tool hat auch eine interessante Funktion - probabilistisches Routing. Wenn Sie Netramesh ausschließlich zum Sammeln von Ablaufverfolgungsbereichen verwenden, können Sie in einer Produktionsumgebung Ressourcen sparen und das probabilistische Routing mithilfe der Variablen NETRA_INBOUND_PROBABILITY und NETRA_OUTBOUND_PROBABILITY (von 0 bis 1) NETRA_OUTBOUND_PROBABILITY . Der Standardwert ist 1 (der gesamte Datenverkehr wird abgefangen).
Nach einem erfolgreichen Abfangen akzeptiert netra sidecar eine neue Verbindung und verwendet die Socket-Option SO_ORIGINAL_DST , um das ursprüngliche Ziel SO_ORIGINAL_DST . Netra stellt dann eine neue Verbindung zur ursprünglichen IP-Adresse her und stellt eine bidirektionale TCP-Kommunikation zwischen den Parteien her, wobei der gesamte durchgelassene Datenverkehr abgehört wird. Wenn der Port als HTTP definiert ist, versucht Netra, ihn zu analysieren und weiterzuleiten. Wenn die HTTP-Analyse nicht erfolgreich ist, greift Netra auf TCP und transparente Proxy-Bytes zurück.
Erstellen eines Abhängigkeitsdiagramms
Nachdem ich in Jaeger viele Informationen zur Ablaufverfolgung erhalten habe, möchte ich ein vollständiges Diagramm der Interaktionen im System erhalten. Wenn Ihr System jedoch ausreichend ausgelastet ist und sich täglich Milliarden von Ablaufverfolgungsbereichen ansammeln, wird die Aggregation nicht so einfach. Es gibt einen offiziellen Weg, dies zu tun: Funkenabhängigkeiten . Es wird jedoch Stunden dauern, bis das vollständige Diagramm erstellt und der gesamte Datensatz in den letzten 24 Stunden von Jaeger heruntergeladen wurde.
Wenn Sie Elasticsearch zum Speichern von Ablaufverfolgungsbereichen verwenden, können Sie ein einfaches Dienstprogramm für Golang verwenden , mit dem mithilfe der Funktionen und Fähigkeiten von Elasticsearch in wenigen Minuten dasselbe Diagramm erstellt wird.
Wie man Netramesh benutzt
Netra kann einfach zu jedem Dienst hinzugefügt werden, auf dem ein beliebiger Orchestrator ausgeführt wird. Hier sehen Sie ein Beispiel.
Derzeit ist Netra nicht in der Lage, Sidecar automatisch für Services bereitzustellen, es gibt jedoch Pläne für die Implementierung.
Zukünftiger Netramesh
Das Hauptziel von Netramesh besteht darin, minimale Ressourcenkosten und eine hohe Leistung zu erzielen und die Hauptmöglichkeiten für die Beobachtbarkeit und Kontrolle der Interaktion zwischen Diensten bereitzustellen .
In Zukunft wird Netramesh Unterstützung für andere Protokolle auf Anwendungsebene als HTTP erhalten. In naher Zukunft wird es die Möglichkeit des L7-Routings geben.
Verwenden Sie Netramesh, wenn Sie auf ähnliche Probleme stoßen, und schreiben Sie uns Fragen und Vorschläge.