Aus dem Bericht des leitenden Entwicklers Sergey Murylyov erfahren Sie mehr über den assoziativen Multithread-Container für die Standardbibliothek, die im Rahmen von WG21 entwickelt wird. Sergey sprach über die Vor- und Nachteile populärer Lösungen für dieses Problem und den von den Entwicklern gewählten Weg.
- Sie haben wahrscheinlich bereits aus dem Titel erraten, dass der heutige Bericht darüber handeln wird, wie wir im Rahmen der Arbeitsgruppe 21 unseren Container ähnlich wie std :: unordered_map erstellt haben, jedoch für eine Multithread-Umgebung.
In vielen Programmiersprachen - Java, C #, Python - existiert dies bereits und ist weit verbreitet. In unserem geliebten, schnellsten und produktivsten C ++ ist dies jedoch nicht geschehen. Aber wir haben uns beraten und beschlossen, so etwas zu tun.

Bevor Sie dem Standard etwas hinzufügen, müssen Sie sich überlegen, wie die Benutzer ihn verwenden werden. Dann, um eine korrektere Schnittstelle zu schaffen, die höchstwahrscheinlich vom Ausschuss angenommen wird - vorzugsweise ohne Änderungen. Und damit es am Ende nicht so war, dass sie eine Sache taten, aber es stellte sich heraus, dass eine andere.
Die bekannteste und am weitesten verbreitete Option ist das Zwischenspeichern großer schwerer Computer. Es gibt einen ziemlich bekannten Memcached-Dienst, der Webserver-Antworten einfach im Speicher zwischenspeichert. Es ist klar, dass Sie auf der Seite Ihrer Anwendung ungefähr dasselbe tun können, wenn Sie über einen wettbewerbsfähigen assoziativen Container verfügen. Beide Ansätze haben ihre Vor- und Nachteile. Wenn Sie jedoch keinen solchen Container haben, müssen Sie entweder Ihr eigenes Fahrrad bauen oder eine Art Memcached verwenden.
Ein weiterer beliebter Anwendungsfall ist die Ereignis-Deduplizierung. Ich denke, viele in diesem Raum schreiben alle Arten von verteilten Systemen und wissen, dass häufig verteilte Warteschlangen für die Kommunikation zwischen Komponenten wie Apache Kafka und Amazon Kinesis verwendet werden. Sie zeichnen sich dadurch aus, dass sie eine Nachricht mehrmals an einen Verbraucher senden können. Dies wird als mindestens einmalige Lieferung bezeichnet, was eine mindestens einmalige Liefergarantie bedeutet: Mehr ist möglich, weniger nicht.
Betrachten Sie dies im Hinblick auf das wirkliche Leben. Stellen Sie sich vor, wir haben ein Backend eines Chatrooms oder eines sozialen Netzwerks, in dem Messaging stattfindet. Dies kann dazu führen, dass jemand eine Nachricht geschrieben hat und später mehrmals eine Push-Benachrichtigung auf seinem Mobiltelefon erhalten hat. Es ist klar, dass Benutzer, die dies sehen, nicht glücklich darüber sind. Es wird argumentiert, dass dieses Problem mit einem so wunderbaren Multithread-Container gelöst werden kann.
Der nächste, weniger häufig verwendete Fall ist, wenn wir nur irgendwo auf der Serverseite etwas speichern müssen, einige Metadaten für den Benutzer. Zum Beispiel können wir die Zeit speichern, in der sich der Benutzer zuletzt authentifiziert hat, um zu verstehen, wann er das nächste Mal nach seinem Benutzernamen und Passwort gefragt werden sollte.
Die letzte Option auf dieser Folie ist die Statistik. Aus realen Anwendungen kann ein Beispiel für die Verwendung in einer virtuellen Maschine von Facebook gegeben werden. Sie haben eine ganze virtuelle Maschine erstellt, um PHP zu optimieren, und in ihrer virtuellen Maschine versuchen sie, die Argumente, mit denen sie aufgerufen wurden, in eine Multithread-Hash-Tabelle für alle integrierten Funktionen zu schreiben. Und wenn sie ein Ergebnis im Cache haben, versuchen sie, es einfach sofort weiterzugeben und nichts zu zählen.

Das Hinzufügen von etwas Großem und Kompliziertem zum Standard ist nicht einfach und nicht schnell. Wenn etwas Großes hinzugefügt wird, durchläuft es in der Regel die technische Spezifikation. Derzeit bewegt sich der Standard stark, um die Multithreading-Unterstützung in der Standardbibliothek zu erweitern. Und speziell der Vorschlag P0260R3 über Multithread-Warteschlangen geht gerade dahin. Bei diesem Vorschlag handelt es sich um eine Datenstruktur, die uns sehr ähnlich ist, und unsere Entwurfsentscheidungen sind in vielerlei Hinsicht sehr ähnlich.
Tatsächlich ist eines der Grundkonzepte ihres Designs, dass sich ihre Schnittstelle von der Standard-std :: queue unterscheidet. Was ist der Punkt? Wenn Sie sich die Standardwarteschlange ansehen, müssen Sie zwei Operationen ausführen, um ein Element daraus zu extrahieren. Sie müssen eine Front-Operation ausführen, um zu zählen, und eine Pop-Operation, um zu löschen. Wenn wir unter Multithreading-Bedingungen arbeiten, haben wir möglicherweise eine Operation in der Warteschlange zwischen diesen beiden Aufrufen, und es kann vorkommen, dass wir ein Element betrachten und ein anderes löschen, was konzeptionell falsch erscheint. Daher wurden diese beiden Aufrufe dort durch einen ersetzt, und einige weitere Aufrufe aus der Kategorie Try Push und Try Pop wurden hinzugefügt. Die allgemeine Idee ist jedoch, dass ein Multithread-Container nicht mit einer normalen Schnittstelle identisch ist.
Multithread-Warteschlangen haben auch viele verschiedene Implementierungen, die verschiedene Aufgaben lösen. Die häufigste Aufgabe ist die Aufgabe von Produzenten und Verbrauchern, wenn wir einige Threads haben, die einige Aufgaben produzieren, und es einige Threads gibt, die Aufgaben aus der Warteschlange nehmen und verarbeiten.
Der zweite Fall ist, wenn wir nur eine Art synchronisierte Warteschlange benötigen. Bei Herstellern und Verbrauchern erhalten wir eine Warteschlange, die auf den oberen und unteren Bereich beschränkt ist. Wenn wir relativ gesehen versuchen, aus einer leeren Warteschlange zu extrahieren, geraten wir in einen Wartezustand. Und das Gleiche passiert ungefähr, wenn wir versuchen, etwas hinzuzufügen, das nicht in die Größe der Warteschlange passt.
Auch in diesem Vorschlag wird beschrieben, dass wir eine separat erstellte Schnittstelle haben, mit der wir unterscheiden können, welche Implementierung wir in der Sperre haben oder welche frei ist. Die Tatsache, dass hier überall im Vorschlag sperrenfrei geschrieben ist, wird in Büchern tatsächlich als wartungsfrei geschrieben. Dies bedeutet, dass unser Algorithmus für eine feste Anzahl von Operationen funktioniert. Frei sperren bedeutet dort etwas anderes, aber das ist nicht der Punkt.
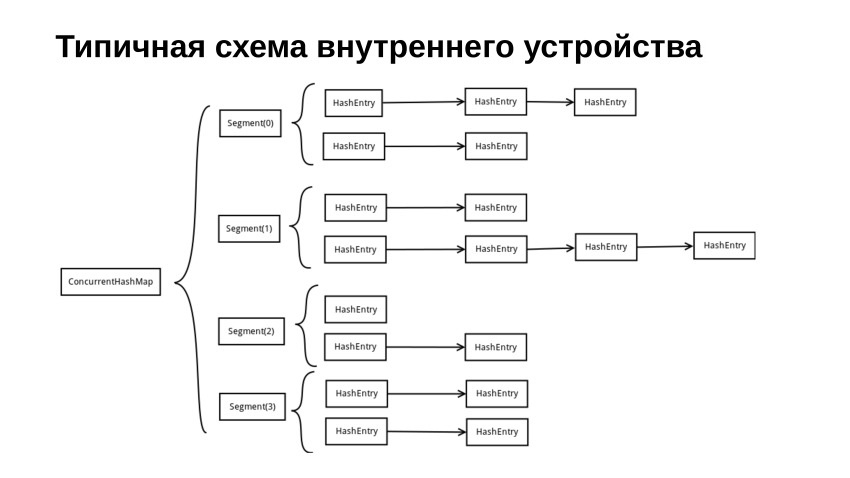
Schauen wir uns ein typisches Diagramm an, wie die Implementierung unserer Hash-Tabelle aussehen könnte, wenn sie blockiert ist. Wir haben es in mehrere Segmente unterteilt. Jedes Segment enthält in der Regel eine Art Sperre wie Mutex, Spinlock oder etwas noch Schwierigeres. Zusätzlich zu Mutex oder Spinlock enthält es auch die übliche Hash-Tabelle, die von diesem Unternehmen geschützt wird.
In diesem Bild haben wir eine Hash-Tabelle, die auf den Listen erstellt wird. Tatsächlich haben wir in unserer Referenzimplementierung aus Leistungsgründen eine Hash-Tabelle mit offener Adressierung geschrieben. Leistungsüberlegungen sind im Grunde die gleichen, warum std :: vector schneller als std :: list ist, da Vektor relativ gesehen sequentiell im Speicher gespeichert wird. Wenn wir damit weitermachen, haben wir sequentiellen Zugriff, der gut zwischengespeichert ist. Wenn wir eine Art Blatt verwenden, werden wir alle möglichen Sprünge zwischen verschiedenen Speicherabschnitten haben. Und das Ganze endet in der Regel damit, dass wir an Produktivität verlieren.
Ganz am Anfang, wenn wir etwas in dieser Hash-Tabelle finden wollen, nehmen wir den Hash-Code vom Schlüssel. Sie können es modulo nehmen und etwas anderes damit machen, damit wir die Segmentnummer erhalten, und in dem Segment, das wir suchen, wie in einer regulären Hash-Tabelle, aber gleichzeitig nehmen wir natürlich die Sperre.

Die Hauptideen unseres Designs. Natürlich haben wir auch eine Schnittstelle erstellt, die nicht mit std :: unordered_map übereinstimmt. Der Grund ist dies. Zum Beispiel haben wir in gewöhnlicher std :: unordered_map so etwas Wunderbares wie Iteratoren. Erstens können nicht alle Implementierungen sie normal unterstützen. Und diejenigen, die in der Regel unterstützen können, sind eine Art sperrfreie Implementierungen, die entweder eine Garbage Collection oder eine Art intelligenter Zeiger erfordern, die den dahinter liegenden Speicher bereinigen.
Darüber hinaus gibt es mehrere andere Arten von Operationen, die wir durchgeführt haben. In der Tat, Iteratoren, sind sie an vielen Orten. Zum Beispiel sind sie in Java. Aber seltsamerweise synchronisieren sie sich dort in der Regel nicht. Und wenn Sie versuchen, etwas aus verschiedenen Threads mit ihnen zu tun, können sie leicht in einen ungültigen Zustand übergehen, und Sie können eine Ausnahme in Java erhalten. Wenn Sie dies in die Pluspunkte schreiben, ist dies höchstwahrscheinlich ein undefiniertes Verhalten, das noch schlimmer ist . Übrigens zum Thema undefiniertes Verhalten: Meiner Meinung nach haben Genossen von Facebook in ihrer Bibliotheks-Torheit, die in Open Source auf GitHub veröffentlicht ist, genau das getan. Ich habe gerade die Schnittstelle mit Java kopiert und so wundervolle Iteratoren bekommen.
Wir haben auch keine Speicherbeschwerde. Wenn wir also etwas zum Container hinzugefügt und Speicher dafür verwendet haben, geben wir es nicht zurück, selbst wenn wir alles löschen. Eine weitere Voraussetzung für diese Entscheidung war, dass wir eine Hash-Tabelle mit offener Adressierung haben. Es arbeitet mit einer linearen Datenstruktur, die wie ein Vektor keinen Speicher zurückgibt.
Der nächste konzeptionelle Moment ist, dass wir unter keinen Umständen irgendjemanden nach außen verlinken und auf interne Objekte verweisen werden. Dies wurde genau getan, um die Notwendigkeit einer Speicherbereinigung zu verhindern und keine intelligenten Zeiger zu erzwingen. Es ist klar, dass es unrentabel ist, Objekte nach Wert zu speichern, wenn sie ausreichend groß sind. In diesem Fall können wir sie jedoch immer in intelligente Zeiger unserer Wahl einwickeln. Und wenn wir zum Beispiel eine Art Synchronisation für die Werte durchführen möchten, können wir sie in eine Art boost :: synchronized_value einschließen.
Wir haben uns die Tatsache angesehen, dass vor einiger Zeit die shared_ptr-Klasse aus der Methode entfernt wurde, die die Anzahl der aktiven Links zu diesem Objekt zurückgegeben hat. Und wir kamen zu dem Schluss, dass wir auch mehrere Funktionen wegwerfen müssen, nämlich size, count, empty, buckets_count, denn sobald wir diesen Wert von der Funktion zurückgeben, ist er sofort nicht mehr gültig, weil jemand dies kann ändere den gleichen Moment.
Bei einem unserer vorherigen Meetings haben sie uns gebeten, eine Art Modus hinzuzufügen, damit wir im Single-Thread-Modus auf unseren Container zugreifen können, wie bei einer regulären std :: unordered_map. Diese Semantik ermöglicht es uns, klar zu unterscheiden, wo wir im Multithread-Modus arbeiten und wo nicht. Und um einige unangenehme Situationen zu vermeiden, in denen Leute einen Multithread-Container nehmen, erwarten Sie, dass alles in Ordnung mit ihnen ist, nehmen Sie Iteratoren und dann stellt sich plötzlich heraus, dass alles schlecht ist.

Bei diesem Treffen in Hawaii wurde ein ganzer Vorschlag gegen uns geschrieben. :) Uns wurde gesagt, dass solche Dinge keinen Platz im Standard haben, weil es viele Möglichkeiten gibt, Ihren assoziativen Multithread-Container zu erstellen.
Jeder hat seine Vor- und Nachteile - und es ist nicht klar, wie wir das nutzen sollen, was uns letztendlich gelingt. In der Regel wird es verwendet, wenn Sie eine extreme Leistung benötigen. Und es scheint, dass unsere Box-Lösung nicht geeignet ist, es ist notwendig, für jeden spezifischen Fall zu optimieren.
Der zweite Punkt dieses Vorschlags war, dass unsere Benutzeroberfläche nicht mit der Tatsache kompatibel ist, dass Facebook auf GitHub aus seiner Standardbibliothek gepostet hat.
Tatsächlich gab es dort keine besonderen Probleme. Es gab einfach eine Frage aus der Kategorie "Ich habe nicht gelesen, aber verurteilt". Sie haben nur geschaut - die Benutzeroberfläche ist anders, was bedeutet, dass sie nicht kompatibel ist.
Die Idee des Vorschlags war auch, dass solche Aufgaben mit Hilfe des sogenannten richtlinienbasierten Entwurfs gelöst werden sollten, wenn ein zusätzlicher Vorlagenparameter erstellt werden muss, in dem Sie eine Bitmaske übergeben können, mit welchen Funktionen wir aktivieren und welche deaktivieren möchten. In der Tat klingt dies ein wenig wild und führt dazu, dass wir ungefähr 2 ^ n Implementierungen erhalten, wobei n die Anzahl der verschiedenen Merkmale ist.

Im Code sieht es ungefähr so aus. Wir haben eine Art Parameter und eine Anzahl vordefinierter Konstanten, die dort übergeben werden können. Seltsamerweise wurde dieser Vorschlag abgelehnt.

Tatsächlich hat das Komitee bereits die Position vertreten, dass solche Dinge sein sollten, wenn die Multithread-Warteschlange SG1 durchlief. Es gab nicht einmal eine Abstimmung zu diesem Thema. Es wurden jedoch zwei Fragen zur Abstimmung gestellt.
Erster. Viele Leute wollten, dass wir auf der Seite unserer Referenzimplementierung das Lesen unterstützen, ohne Sperren zu nehmen. Damit haben wir eine völlig unblockierende Lesung. Es macht wirklich Sinn: In der Regel ist das Zwischenspeichern der beliebteste Benutzerfall. Und es ist sehr vorteilhaft für uns, schnell zu lesen.
Zweiter Moment. Jeder hörte viel von dem vorherigen Freund, der über politikbasiertes Design sprach. Jeder hatte eine Idee - aber was, lassen Sie mich auch über meine Idee sprechen! Und alle stimmten für ein politikbasiertes Design. Obwohl ich sagen muss, geht diese ganze Geschichte schon eine ganze Weile weiter, und vor uns haben dies unsere Kollegen von Intel, Arch Robinson und Anton Malakhov getan. Und sie hatten bereits mehrere Vorschläge zu diesem Thema. Sie haben nur angeboten, eine
sperrfreie Implementierung hinzuzufügen, die auf dem
SeepOrderedList- Algorithmus basiert. Und sie hatten auch ein richtlinienbasiertes Design mit der Speicherbeschwerde.
Und diesem Vorschlag gefiel die Library Evolution Working Group nicht. Es wurde mit dem Grund abgeschlossen, dass wir einfach eine unbegrenzte Erhöhung der Anzahl von Wörtern im Standard haben werden. Es wird einfach unmöglich sein, eine angemessene Vorschau anzuzeigen und einfach in Code zu implementieren.
Wir haben keine Kommentare zu den Ideen selbst. Wir haben zum größten Teil Kommentare zur Referenzimplementierung. Und natürlich haben wir einige Ideen, die eingeführt werden können, um es klarer zu machen. Aber im Wesentlichen werden wir das nächste Mal denselben Vorschlag machen. Wir hoffen aufrichtig, dass wir nicht wie bei den Modulen fünf Aufrufe mit demselben Vorschlag erhalten. Wir glauben aufrichtig an uns selbst und dass wir zum nächsten Aufruf übergehen dürfen und dass die Arbeitsgruppe für Bibliotheksentwicklung dennoch auf unserer Meinung bestehen und es uns nicht erlauben wird, politikbasiertes Design durchzusetzen. Weil unser Gegner nicht aufhört. Er beschloss, allen zu beweisen, dass es notwendig war. Aber wie sie sagen, wird die Zeit es zeigen. Ich habe alles, danke für Ihre Aufmerksamkeit.