
Jeder nimmt Texte einzigartig wahr, unabhängig davon, ob diese Person Nachrichten im Internet oder weltbekannte klassische Romane liest. Dies gilt auch für eine Vielzahl von Algorithmen und Techniken des maschinellen Lernens, die Texte auf mathematischere Weise verstehen, nämlich unter Verwendung eines hochdimensionalen Vektorraums.
Dieser Artikel befasst sich mit der Visualisierung hochdimensionaler Word2Vec-Worteinbettungen mit t-SNE. Die Visualisierung kann hilfreich sein, um zu verstehen, wie Word2Vec funktioniert und wie Beziehungen zwischen Vektoren interpretiert werden, die aus Ihren Texten erfasst wurden, bevor sie in neuronalen Netzen oder anderen Algorithmen für maschinelles Lernen verwendet werden. Als Trainingsdaten verwenden wir Artikel aus Google News und klassischen literarischen Werken von Leo Tolstoi, dem russischen Schriftsteller, der als einer der größten Autoren aller Zeiten gilt.
Wir gehen die kurze Übersicht über den t-SNE-Algorithmus durch, gehen dann zur Berechnung der Worteinbettungen mit Word2Vec über und fahren schließlich mit der Visualisierung von Wortvektoren mit t-SNE im 2D- und 3D-Raum fort. Wir werden unsere Skripte in Python mit Jupyter Notebook schreiben.
T-verteilte stochastische Nachbareinbettung
T-SNE ist ein Algorithmus für maschinelles Lernen zur Datenvisualisierung, der auf einer nichtlinearen Dimensionsreduktionstechnik basiert. Die Grundidee von t-SNE besteht darin, den Dimensionsraum zu reduzieren und den relativen paarweisen Abstand zwischen Punkten einzuhalten. Mit anderen Worten, der Algorithmus ordnet mehrdimensionale Daten zwei oder mehr Dimensionen zu, wobei Punkte, die anfangs weit voneinander entfernt waren, ebenfalls weit entfernt sind und nahe Punkte ebenfalls in nahe Punkte umgewandelt werden. Es kann gesagt werden, dass t-SNE nach einer neuen Datendarstellung sucht, bei der die Nachbarschaftsbeziehungen erhalten bleiben. Die detaillierte Beschreibung der gesamten t-SNE-Logik finden Sie im Originalartikel [1].
Das Word2Vec-Modell
Zunächst sollten wir Vektordarstellungen von Wörtern erhalten. Zu diesem Zweck habe ich Word2vec [2] ausgewählt, dh ein rechnerisch effizientes Vorhersagemodell zum Lernen mehrdimensionaler Worteinbettungen aus Rohtextdaten. Das Schlüsselkonzept von Word2Vec besteht darin, Wörter, die im Trainingskorpus gemeinsame Kontexte haben, im Vergleich zu anderen in unmittelbarer Nähe im Vektorraum zu lokalisieren.
Als Eingabedaten für die Visualisierung verwenden wir Artikel aus Google News und einige Romane von Leo Tolstoi. Vorab trainierte Vektoren, die auf einem Teil des Google News-Datensatzes (ca. 100 Milliarden Wörter) trainiert wurden, wurden von Google auf
der offiziellen Seite veröffentlicht , daher werden wir sie verwenden.
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Zusätzlich zu dem vorgefertigten Modell werden wir ein weiteres Modell zu Tolstois Romanen unter Verwendung der Gensim [3] -Bibliothek trainieren. Word2Vec verwendet Sätze als Eingabedaten und erzeugt Wortvektoren als Ausgabe. Zunächst muss ein vorab trainierter Punkt-Satz-Tokenizer heruntergeladen werden, der einen Text in eine Liste von Sätzen unterteilt, wobei Abkürzungswörter, Kollokationen und Wörter berücksichtigt werden, die wahrscheinlich einen Anfang oder ein Ende von Sätzen angeben. Standardmäßig enthält das NLTK-Datenpaket keinen vorab geschulten Punkt-Tokenizer für Russisch. Daher verwenden wir Modelle von Drittanbietern von
github.com/mhq/train_punkt .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
In der Word2Vec-Trainingsphase wurden die folgenden Hyperparameter verwendet:
- Die Dimensionalität des Merkmalsvektors beträgt 200.
- Der maximale Abstand zwischen analysierten Wörtern innerhalb eines Satzes beträgt 5.
- Ignoriert alle Wörter mit einer Gesamtfrequenz von weniger als 5 pro Korpus.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualisierung von Worteinbettungen mit t-SNE
T-SNE ist sehr nützlich, wenn es notwendig ist, die Ähnlichkeit zwischen Objekten zu visualisieren, die sich im mehrdimensionalen Raum befinden. Bei einem großen Datensatz wird es immer schwieriger, ein einfach zu lesendes t-SNE-Diagramm zu erstellen. Daher ist es üblich, Gruppen der ähnlichsten Wörter zu visualisieren.
Lassen Sie uns einige Wörter aus dem Vokabular des vorgefertigten Google News-Modells auswählen und Wortvektoren für die Visualisierung vorbereiten.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
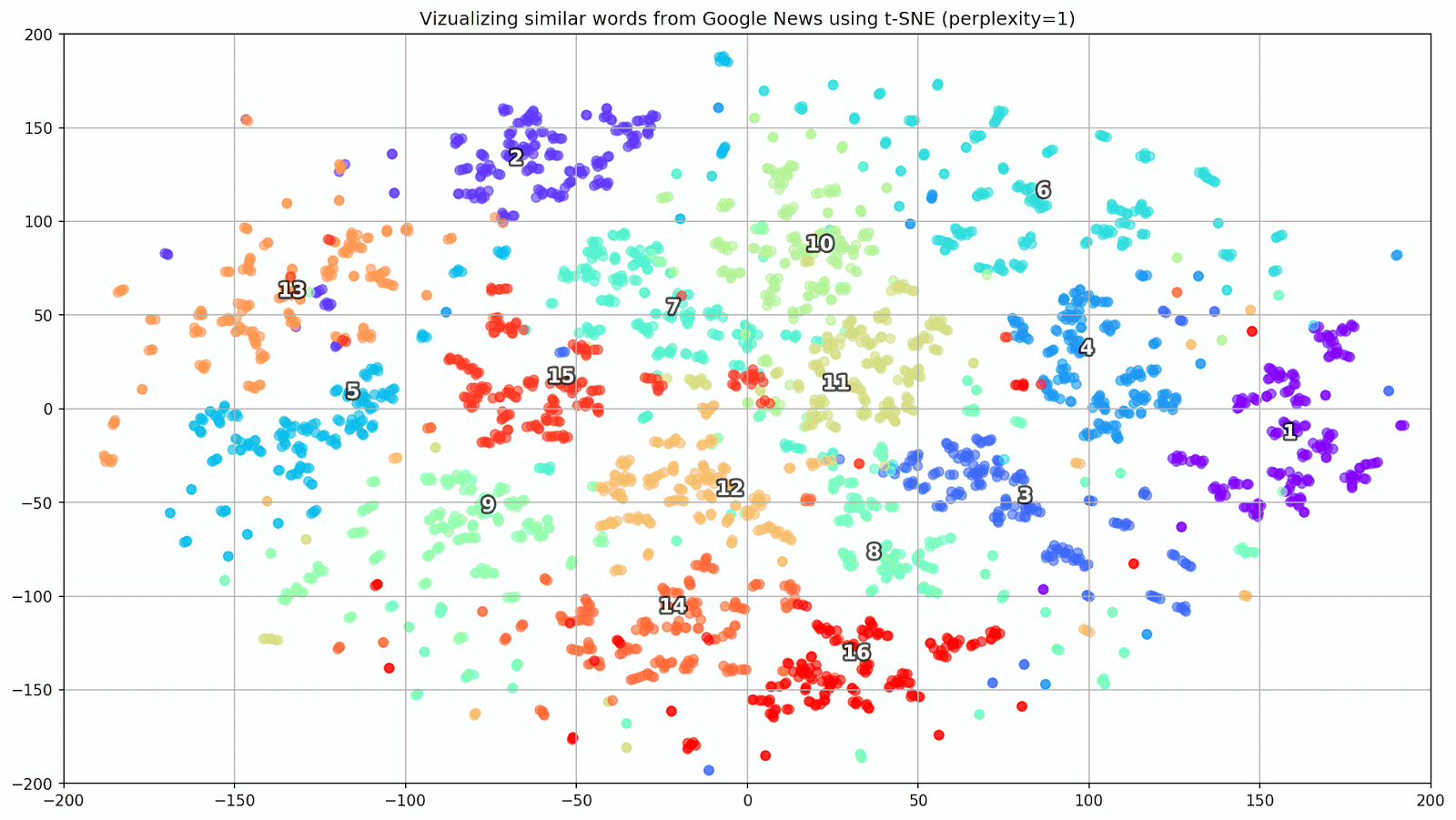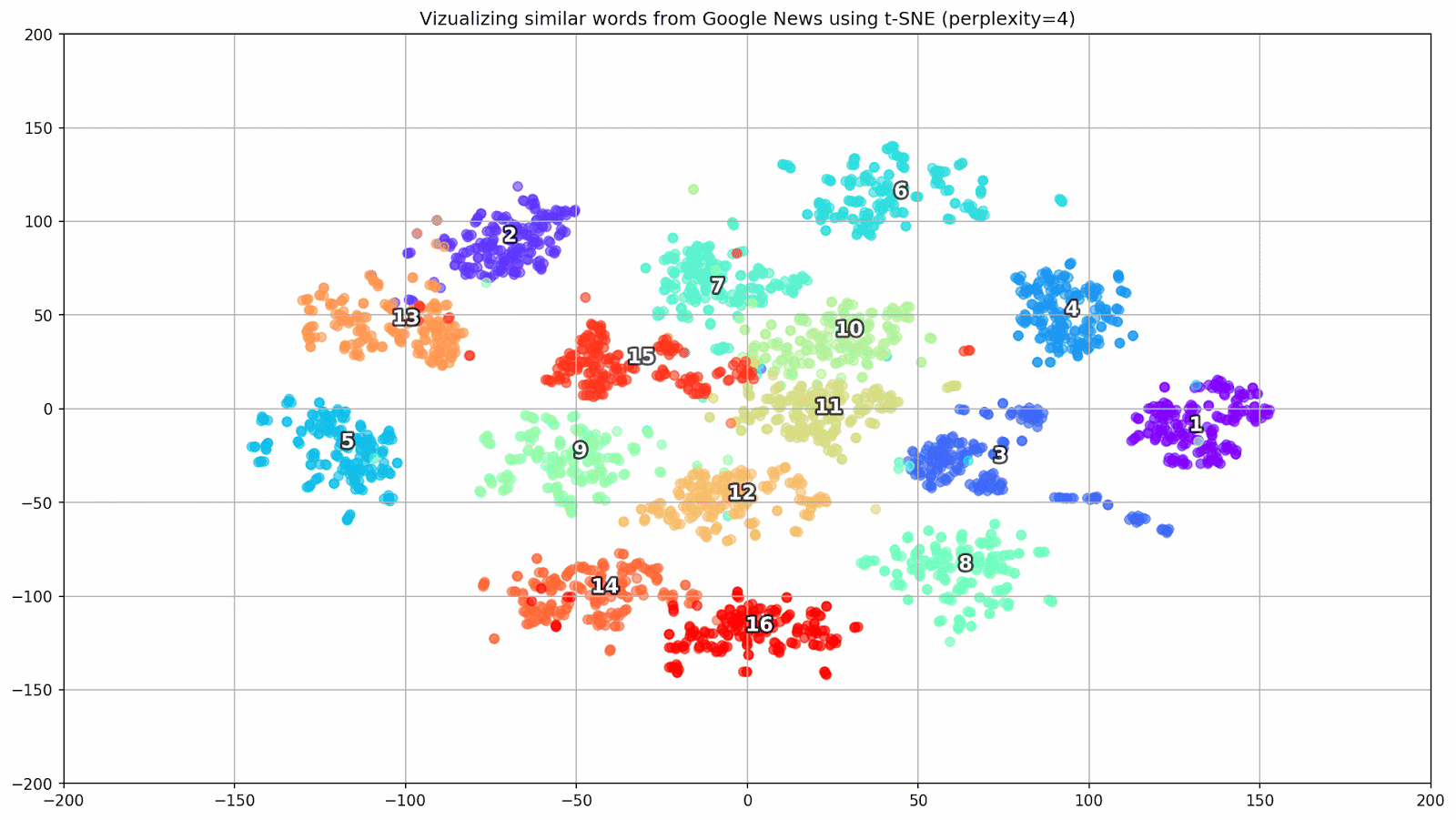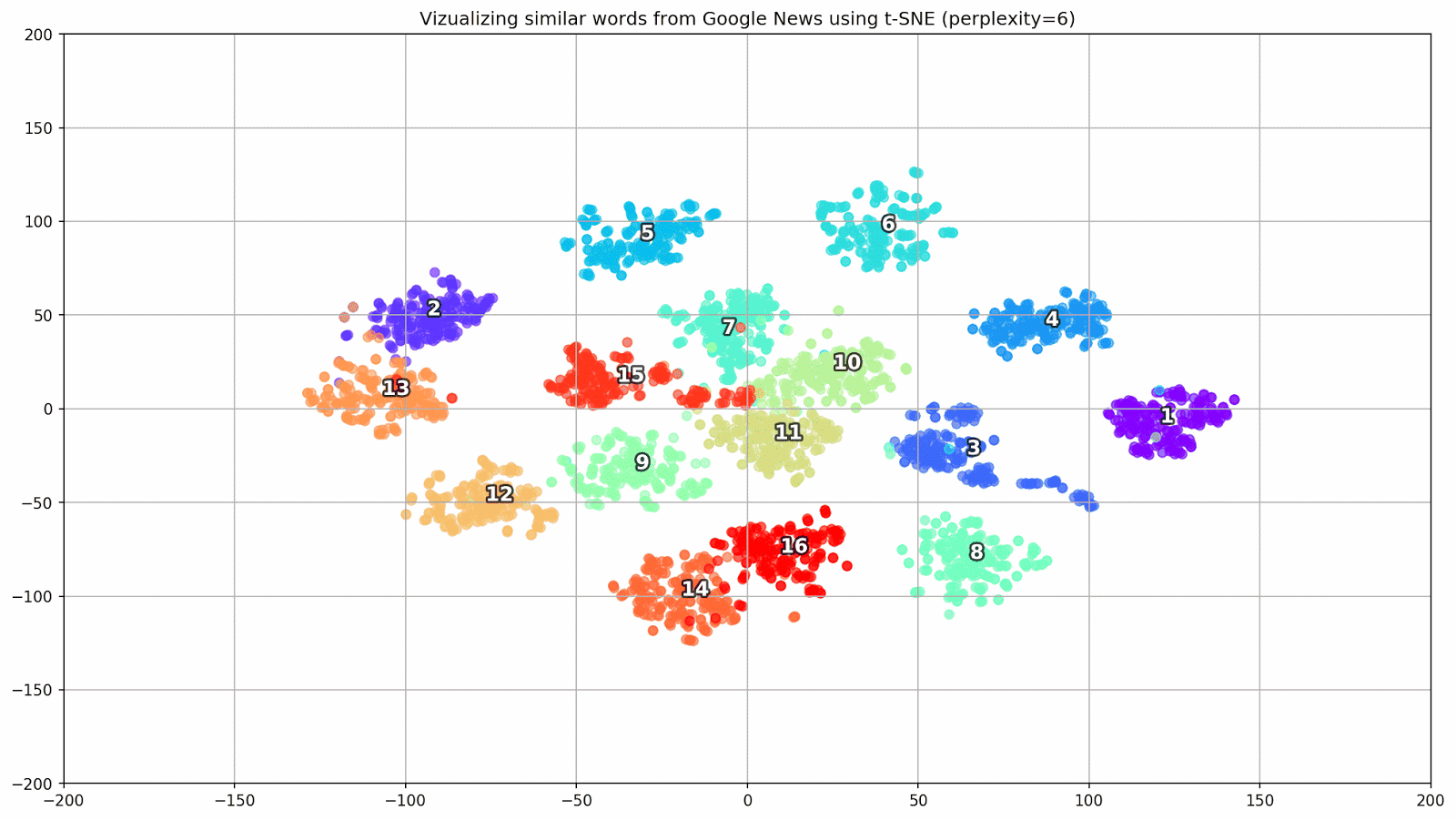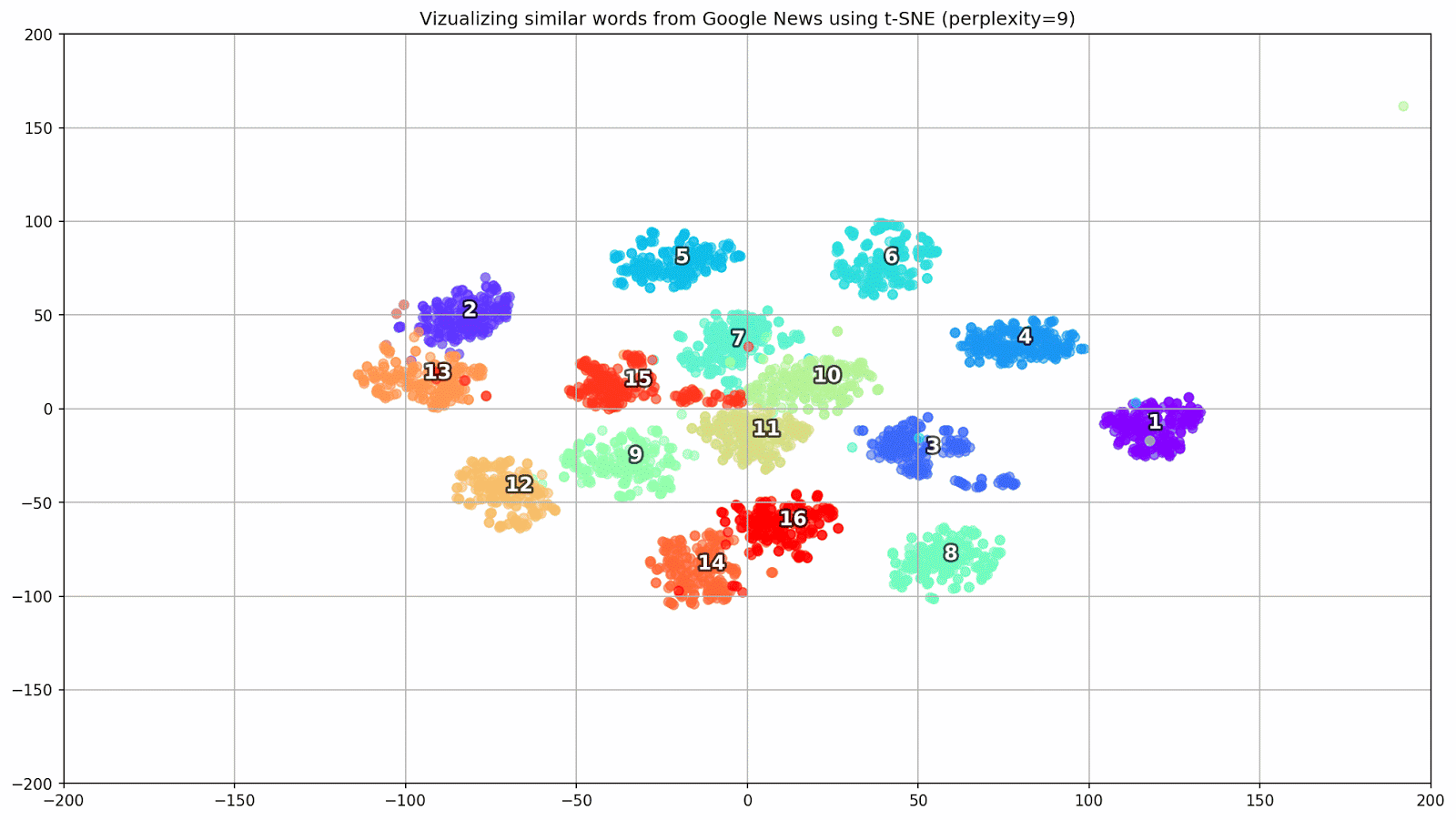 Abb. 1. Die Auswirkung verschiedener Verwirrungswerte auf die Form von Wortclustern.
Abb. 1. Die Auswirkung verschiedener Verwirrungswerte auf die Form von Wortclustern.Als nächstes gehen wir zum faszinierenden Teil dieses Papiers über, der Konfiguration von t-SNE. In diesem Abschnitt sollten wir uns auf die folgenden Hyperparameter konzentrieren.
- Die Anzahl der Komponenten , dh die Dimension des Ausgaberaums.
- Der Ratlosigkeitswert , der im Zusammenhang mit t-SNE als glattes Maß für die effektive Anzahl von Nachbarn angesehen werden kann. Dies hängt mit der Anzahl der nächsten Nachbarn zusammen, die bei vielen anderen vielfältigen Lernenden beschäftigt sind (siehe Abbildung oben). Nach [1] wird empfohlen, einen Wert zwischen 5 und 50 zu wählen.
- Die Art der anfänglichen Initialisierung für Einbettungen.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Es sollte erwähnt werden, dass t-SNE eine nicht konvexe Zielfunktion hat, die durch eine Gradientenabstiegsoptimierung mit zufälliger Initiierung minimiert wird, sodass unterschiedliche Läufe leicht unterschiedliche Ergebnisse liefern.
Im Folgenden finden Sie ein Skript zum Erstellen eines 2D-Streudiagramms mit Matplotlib, einer der beliebtesten Bibliotheken für die Datenvisualisierung in Python.
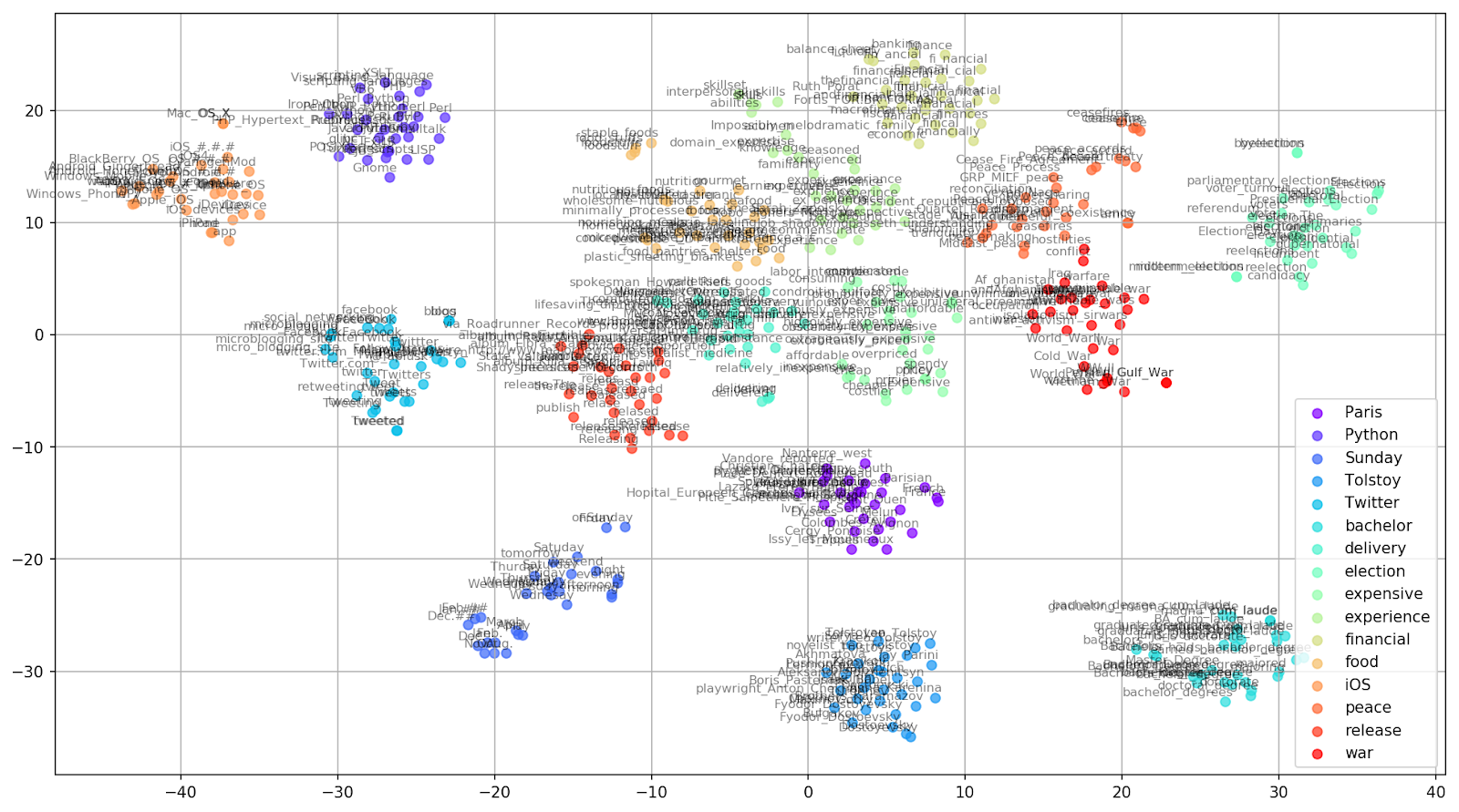 Abb. 2. Cluster ähnlicher Wörter aus Google News (Präplexität = 15).
Abb. 2. Cluster ähnlicher Wörter aus Google News (Präplexität = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
In einigen Fällen kann es nützlich sein, alle Wortvektoren gleichzeitig zu zeichnen, um das gesamte Bild zu sehen. Lassen Sie uns nun Anna Karenina analysieren, einen epischen Roman aus Leidenschaft, Intrigen, Tragödien und Erlösung.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
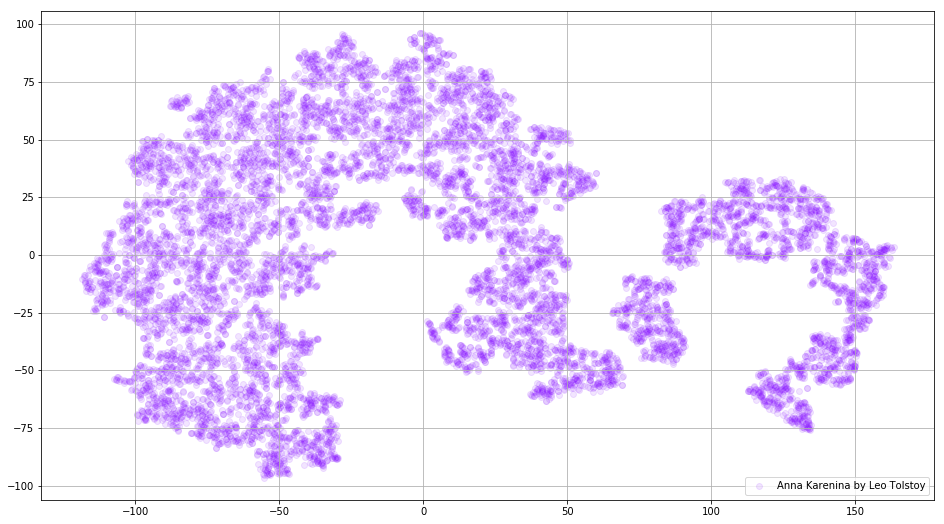
 Abb. 3. Visualisierung des auf Anna Karenina trainierten Word2Vec-Modells.
Abb. 3. Visualisierung des auf Anna Karenina trainierten Word2Vec-Modells.Das gesamte Bild kann noch informativer sein, wenn wir anfängliche Einbettungen im 3D-Raum abbilden. In dieser Zeit werfen wir einen Blick auf Krieg und Frieden, einen der wichtigsten Romane der Weltliteratur und eine der größten literarischen Errungenschaften Tolstois.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
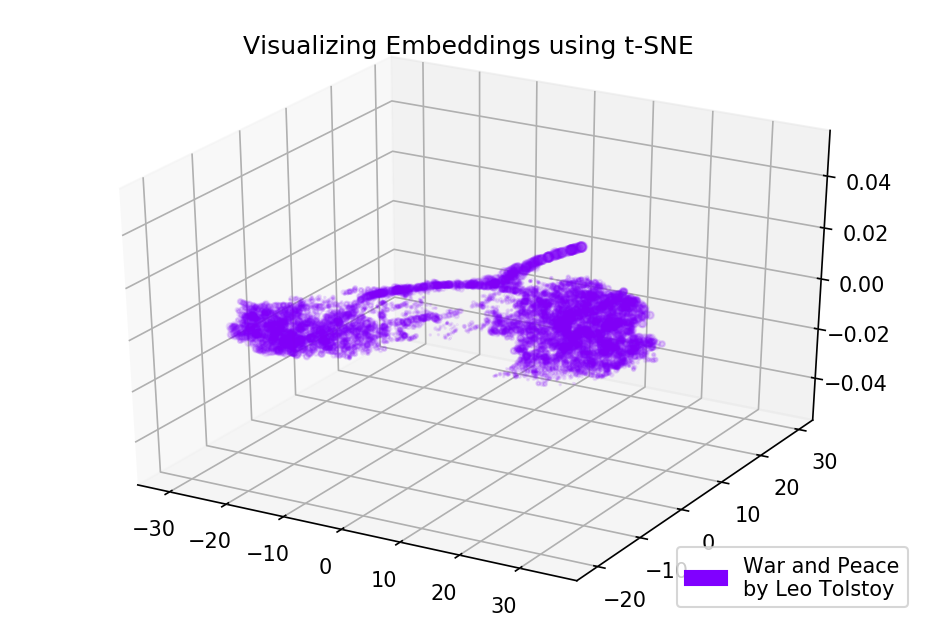 Abb. 4. Visualisierung des auf Krieg und Frieden trainierten Word2Vec-Modells.
Abb. 4. Visualisierung des auf Krieg und Frieden trainierten Word2Vec-Modells.Die Ergebnisse
So sehen Texte aus der Perspektive von Word2Vec und t-SNE aus. Wir haben ein recht informatives Diagramm für ähnliche Wörter aus Google News und zwei Diagramme für Tolstois Romane erstellt. Noch eine Sache, GIFs! GIFs sind fantastisch, aber das Plotten von GIFs entspricht fast dem Plotten normaler Diagramme. Deshalb habe ich beschlossen, sie im Artikel nicht zu erwähnen, aber den Code für die Generierung von Animationen finden Sie in den Quellen.
Der Quellcode ist bei
Github erhältlich .
Der Artikel wurde ursprünglich in
Towards Data Science veröffentlicht .
Referenzen
- L. Maate und G. Hinton, "Visualisierung von Daten mit t-SNE", Journal of Machine Learning Research, vol. 9, pp. 2579-2605, 2008.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado und J. Dean, „Verteilte Darstellungen von Wörtern und Phrasen und ihre Zusammensetzung“, Advances in Neural Information Processing Systems, pp. 3111-3119, 2013.
- R. Rehurek und P. Sojka, „Software-Framework für die Themenmodellierung mit großen Korpora“, Proceedings des LREC 2010-Workshops zu neuen Herausforderungen für NLP-Frameworks, 2010.