Vergleichende Tests von in C / C ++ implementierten Multithread-Caches und eine Beschreibung der Anordnung des LRU / MRU-Caches der O (n) Cache ** RU-Serie
Im Laufe der Jahrzehnte wurden viele Caching-Algorithmen entwickelt: LRU, MRU, ARC und andere .... Wenn jedoch ein Cache für Multithread-Arbeiten benötigt wurde, gab Google zu diesem Thema eineinhalb Optionen an, und die Frage zu StackOverflow blieb im Allgemeinen unbeantwortet. Ich habe eine Lösung von Facebook gefunden , die auf threadsicheren Containern aus dem Intel TBB-Repository basiert . Letzterer hat auch einen Multithread-LRU-Cache, der sich noch im Beta-Test befindet. Um ihn zu verwenden, müssen Sie im Projekt explizit Folgendes angeben:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
Andernfalls zeigt der Compiler einen Fehler an, da der Intel TBB-Code überprüft wird:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
Ich wollte irgendwie die Leistung von Caches vergleichen - welches soll ich wählen? Oder schreiben Sie Ihre eigenen? Früher, als ich Single-Threaded-Caches ( Link ) verglich, erhielt ich Angebote, andere Bedingungen mit anderen Schlüsseln auszuprobieren, und stellte fest, dass ein bequemer erweiterbarer Prüfstand erforderlich war. Um das Hinzufügen konkurrierender Algorithmen zu den Tests zu vereinfachen, habe ich beschlossen, sie in die Standardschnittstelle einzubinden:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
Ebenso sind die Schnittstellen verpackt: Arbeiten mit dem Betriebssystem, Abrufen von Einstellungen, Testfällen usw. Quellen werden im Repository angeordnet . Am Stand gibt es zwei Testfälle: Einfügen / Suchen von bis zu 1.000.000 Elementen mit einem Schlüssel aus zufällig generierten Zahlen und bis zu 100.000 Elementen mit einem Zeichenfolgenschlüssel (entnommen aus 10 MB Zeilen von wiki.train.tokens). Um die Ausführungszeit zu bewerten, wird jeder Testcache zuerst ohne Zeitmessungen auf das Zielvolumen erwärmt, dann entlädt das Semaphor die Flüsse aus der Kette, um Daten hinzuzufügen und zu suchen. Die Anzahl der Threads und Testfalleinstellungen wird in assets / settings.json festgelegt . Eine schrittweise Anleitung zum Kompilieren und eine Beschreibung der JSON-Einstellungen finden Sie im WiKi-Repository . Die Zeit wird vom Moment der Freigabe des Semaphors bis zum Ende des letzten Threads verfolgt. Folgendes ist passiert:
Testfall1 - ein Schlüssel in Form eines Arrays von Zufallszahlen uint64_t keyArray [3]:
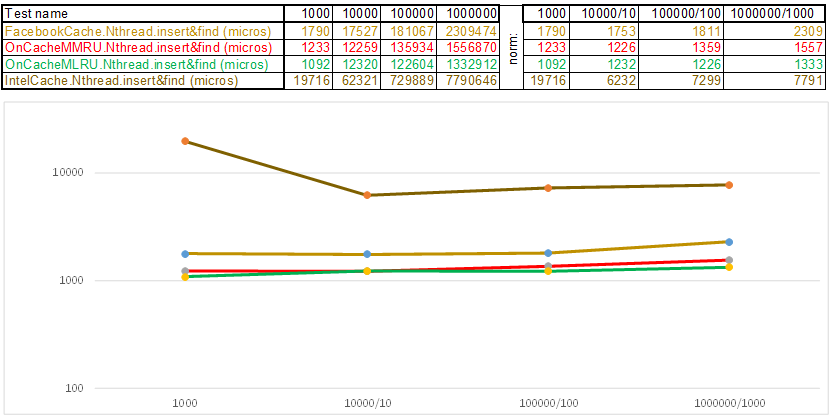
Testfall2 - Schlüssel als Zeichenfolge:
Bitte beachten Sie, dass sich das Volumen der eingefügten / gesuchten Daten in jedem Schritt des Testfalls um das Zehnfache erhöht. Dann dividiere ich die Zeit, die für die Verarbeitung des nächsten Volumens aufgewendet wurde, durch 10, 100, 1000 ... Wenn sich der Algorithmus in der Zeitkomplexität wie O (n) verhält, bleibt die Zeitachse ungefähr parallel zur X-Achse. Als nächstes werde ich heiliges Wissen offenbaren, wie ich es geschafft habe Erhalten Sie 3-5-fache Überlegenheit gegenüber dem Facebook-Cache in den Algorithmen der O (n) Cache ** RU-Serie, wenn Sie mit einem Zeichenfolgenschlüssel arbeiten:
- Anstatt jeden Buchstaben der Zeichenfolge zu lesen, setzt die Hash-Funktion einfach einen Zeiger auf die Zeichenfolgendaten auf uint64_t keyArray [3] und zählt die Summe der Ganzzahlen. Das heißt, es funktioniert wie das Programm "Errate die Melodie" - und ich denke, die Melodie besteht aus 3 Noten ... 3 * 8 = 24 Buchstaben, wenn es lateinisch ist, und dies ermöglicht es Ihnen bereits, Linien in Hash-Körben ziemlich gut zu streuen. Ja, viele Zeilen können in einem Hash-Korb gesammelt werden, und hier beginnt der Algorithmus zu beschleunigen:
- Mit der Überspringliste in jedem Korb können Sie schnell zuerst in verschiedenen Hashes springen (Korb-ID = Hash% Anzahl der Körbe, sodass in einem Korb unterschiedliche Hashes angezeigt werden können) und dann innerhalb desselben Hash entlang der Scheitelpunkte:
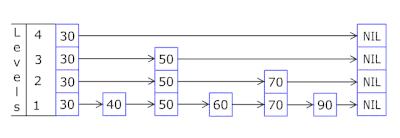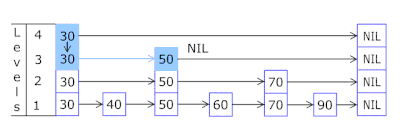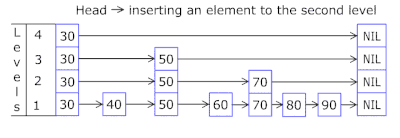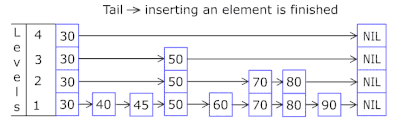
- Die Knoten, in denen die Schlüssel und Daten gespeichert sind, werden aus dem zuvor zugewiesenen Array von Knoten entnommen, wobei die Anzahl der Knoten mit der Cache-Kapazität übereinstimmt. Der Atomic-Bezeichner gibt an, welcher Knoten als nächstes verwendet werden soll. Wenn er das Ende des Knotenpools erreicht, beginnt er mit 0 =, sodass der Allokator in einem Kreis die alten Knoten überschreibt ( LRU-Cache in OnCacheMLRU ).
Für den Fall, dass die beliebtesten Elemente in Suchabfragen im Cache gespeichert werden müssen, wird die zweite OnCacheMMRU-Klasse erstellt . Der Algorithmus lautet wie folgt: Zusätzlich zur Cache-Kapazität übergibt der Klassenkonstruktor auch den zweiten Parameter uint32_t Nutzlosigkeit. Die Beliebtheit ist begrenzt, wenn die Anzahl der Suchanforderungen, die den aktuellen Knoten aus dem zyklischen Pool wünschen, geringer ist Wenn die Grenzen unbrauchbar sind, wird der Knoten für die nächste Einfügeoperation wiederverwendet (er wird entfernt). Wenn in diesem Kreis die Popularität des Knotens (std :: atomic <uint32_t> verwendet {0}) hoch ist, kann der Knoten zum Zeitpunkt der Anforderung des Allokators aus dem zyklischen Pool überleben, der Beliebtheitszähler wird jedoch auf 0 zurückgesetzt. Es wird also ein weiterer Kreis des Allokator-Durchgangs zurückgesetzt auf einem Pool von Knoten und erhalten die Chance, wieder an Popularität zu gewinnen, um weiterhin zu existieren. Das heißt, es ist eine Mischung aus den MRU-Algorithmen (bei denen die beliebtesten für immer im Cache hängen) und MQ (bei denen die Lebensdauer verfolgt wird). Der Cache wird ständig aktualisiert und funktioniert gleichzeitig sehr schnell - anstelle von 10 Servern können Sie 1 setzen.
Im Großen und Ganzen verbringt der Caching-Algorithmus Zeit mit Folgendem:
- Pflege der Cache-Infrastruktur (Container, Allokatoren, Verfolgung der Lebensdauer und Beliebtheit von Elementen)
- Hash-Berechnung und Schlüsselvergleichsoperationen beim Hinzufügen / Suchen von Daten
- Suchalgorithmen: Rot-Schwarzer Baum, Hash-Tabelle, Überspringliste, ...
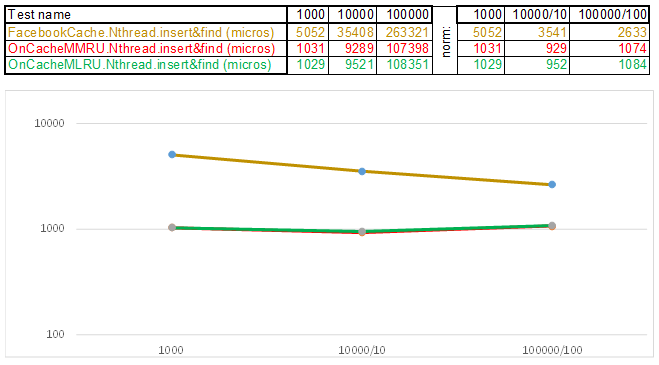
Es war lediglich notwendig, die Betriebszeit jedes dieser Elemente zu reduzieren, da der einfachste Algorithmus zeitlich komplex und häufig der effizienteste ist, da jede Logik CPU-Zyklen benötigt. Das heißt, was auch immer Sie schreiben, dies sind Operationen, die sich im Vergleich zur einfachen Aufzählungsmethode rechtzeitig auszahlen sollten: Während die nächste Funktion aufgerufen wird, muss die Aufzählung weitere hundert oder zwei Knoten durchlaufen. In diesem Licht verlieren Multithread-Caches im Single-Thread-Modus immer, da der Schutz von Körben durch std :: shared_mutex und Knoten durch std :: atomic_flag in_use nicht kostenlos ist. Daher verwende ich für die Ausgabe auf dem Server den OnCacheSMRU- Single-Threaded-Cache im Haupt-Epoll-Server-Thread (nur lange Vorgänge beim Arbeiten mit DBMS, Festplatte und Kryptografie werden in parallelen Workflows ausgeführt). Für eine vergleichende Bewertung wird eine Single-Threaded-Version von Testfällen verwendet:
Testfall1 - ein Schlüssel in Form eines Arrays von Zufallszahlen uint64_t keyArray [3]:

Testfall2 - Schlüssel als Zeichenfolge:
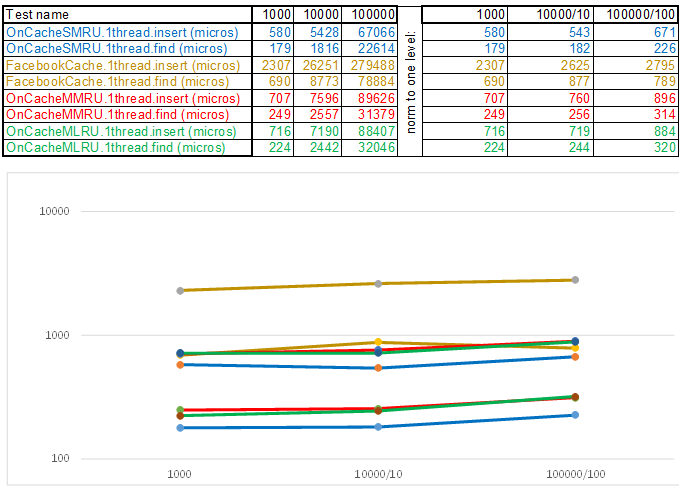
Abschließend möchte ich Ihnen sagen, was aus den Quellen des Prüfstands noch interessant zu extrahieren ist:
- Die JSON-Analysebibliothek, die aus einer einzelnen specjson.h-Datei besteht, ist ein kleiner, einfacher und schneller Algorithmus für diejenigen, die nicht einige Megabyte des Codes einer anderen Person in ihr Projekt ziehen möchten, um die Einstellungsdatei oder den eingehenden JSON eines bekannten Formats zu analysieren.
- Ein Ansatz, bei dem die Implementierung plattformspezifischer Operationen in der Form (Klasse LinuxSystem: public ISystem {...}) anstelle der herkömmlichen (#ifdef _WIN32) eingefügt wird. Es ist bequemer, beispielsweise Semaphore zu verpacken, mit dynamisch verbundenen Bibliotheken und Diensten zu arbeiten - in Klassen gibt es nur Code und Header eines bestimmten Betriebssystems. Wenn Sie ein anderes Betriebssystem benötigen, fügen Sie eine andere Implementierung ein (Klasse WindowsSystem: public ISystem {...}).
- Der Stand geht zu CMake - es ist praktisch, das Projekt CMakeLists.txt in Qt Creator oder Microsoft Visual Studio 2017 zu öffnen. Wenn Sie mit dem Projekt über CmakeLists.txt arbeiten, können Sie einige vorbereitende Vorgänge automatisieren, z. B. Testfalldateien und Konfigurationsdateien in das Installationsverzeichnis kopieren:
- Für diejenigen, die die neuen Funktionen von C ++ 17 beherrschen, ist dies ein Beispiel für die Arbeit mit std :: shared_mutex, std :: allocator <std :: shared_mutex>, statischem thread_local in Vorlagen (es gibt Nuancen - wo zuzuweisen?), Starten einer großen Anzahl von Tests in Threads auf unterschiedliche Weise mit Messung der Ausführungszeit:
- Schritt-für-Schritt-Anleitung zum Kompilieren, Konfigurieren und Ausführen dieses Prüfstands - WiKi .
Wenn Sie noch keine Schritt-für-Schritt-Anleitung für ein praktisches Betriebssystem haben, bin ich dankbar für den Beitrag zum Repository zur Implementierung von ISystem und für die schrittweise Kompilierungsanleitung (für WiKi) ... Oder schreiben Sie mir einfach - ich werde versuchen, die Zeit zum Hochfahren der virtuellen Maschine zu finden und die Schritte für die Assembly zu beschreiben.