Hallo Habr! Ich präsentiere Ihnen den Beitrag, der eine
Textadaption der Leistung von
Stella Cotton auf der RailsConf 2018 und eine Übersetzung des Artikels
"Aufbau einer serviceorientierten Architektur mit Rails und Kafka" von Stella Cotton ist.
In jüngster Zeit ist der Übergang von der monolithischen Architektur zu Mikrodiensten deutlich sichtbar. In diesem Handbuch lernen wir die Grundlagen von Kafka kennen und wie ein ereignisgesteuerter Ansatz Ihre Rails-Anwendung verbessern kann. Wir werden auch über die Probleme der Überwachung und Skalierbarkeit von Diensten sprechen, die durch einen ereignisorientierten Ansatz arbeiten.
Was ist Kafka?
Ich bin sicher, dass Sie Informationen darüber haben möchten, wie Ihre Benutzer zu Ihrer Plattform gekommen sind oder welche Seiten sie besuchen, auf welche Schaltflächen sie klicken usw. Eine wirklich beliebte Anwendung kann Milliarden von Ereignissen generieren und eine große Datenmenge an Analysedienste senden, was eine ernsthafte Herausforderung für Ihre Anwendung sein kann.
Ein wesentlicher Bestandteil von Webanwendungen ist in der Regel der sogenannte
Echtzeitdatenfluss . Kafka bietet eine fehlertolerante Verbindung zwischen
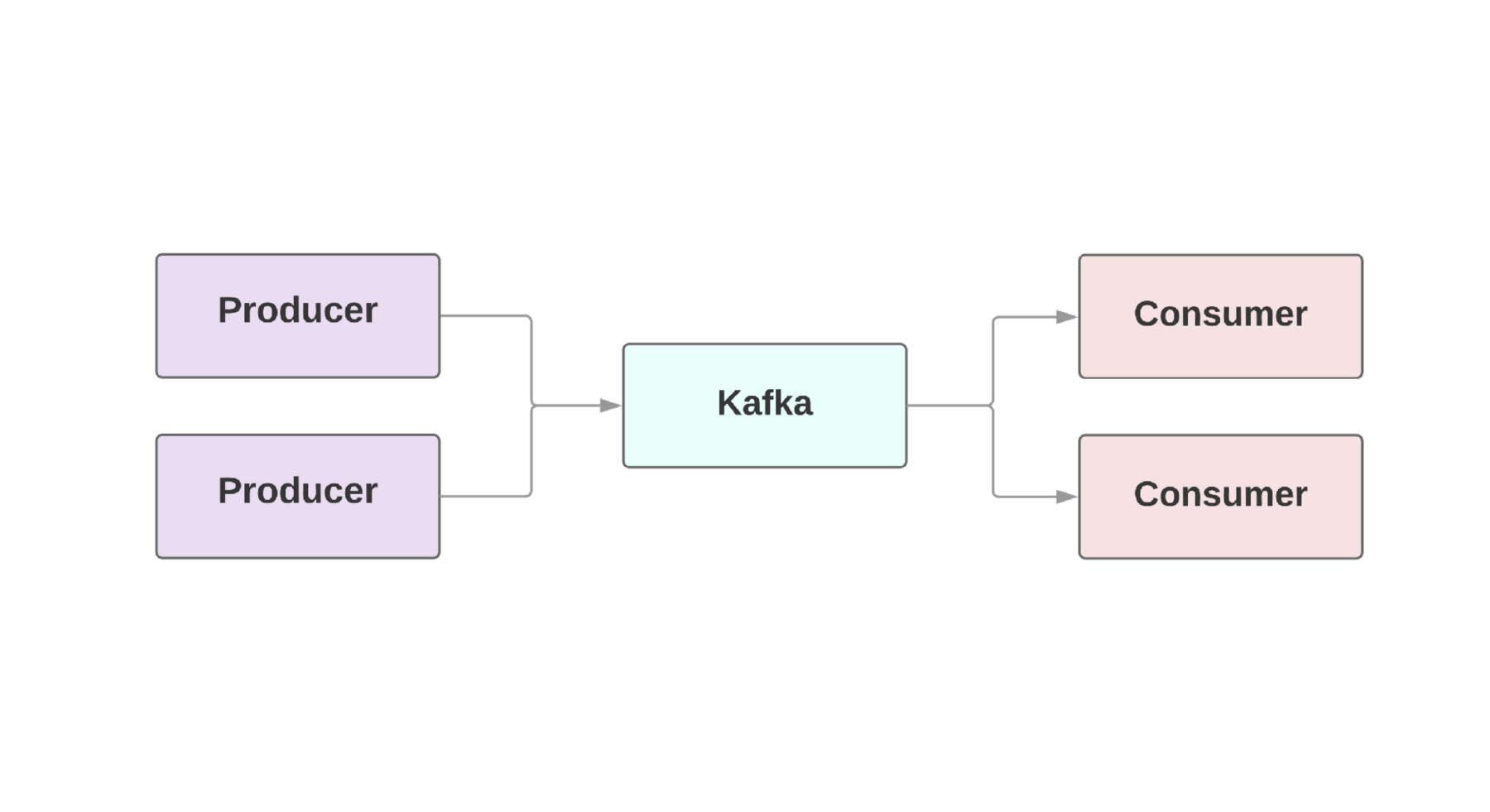
Produzenten , denen, die Ereignisse erzeugen, und
Verbrauchern , denen, die diese Ereignisse erhalten. Es kann sogar mehrere Hersteller und Verbraucher in einer Anwendung geben. In Kafka existiert jedes Ereignis für eine bestimmte Zeit, sodass mehrere Verbraucher immer wieder dasselbe Ereignis lesen können. Der Kafka-Cluster umfasst mehrere Broker, die Kafka-Instanzen sind.
Ein wesentliches Merkmal von Kafka ist die hohe Geschwindigkeit der Ereignisverarbeitung. Herkömmliche Warteschlangensysteme wie AMQP verfügen über eine Infrastruktur, die die verarbeiteten Ereignisse für jeden Verbraucher überwacht. Wenn die Anzahl der Verbraucher auf ein anständiges Niveau ansteigt, beginnt das System kaum, mit der Last fertig zu werden, da es eine zunehmende Anzahl von Bedingungen überwachen muss. Es gibt auch große Probleme mit der Konsistenz zwischen Verbraucher- und Ereignisverarbeitung. Lohnt es sich beispielsweise, eine Nachricht sofort als gesendet zu markieren, sobald sie vom System verarbeitet wird? Und wenn ein Verbraucher am anderen Ende fällt, ohne eine Nachricht zu erhalten?
Kafka hat auch eine ausfallsichere Architektur. Das System wird als Cluster auf einem oder mehreren Servern ausgeführt, die durch Hinzufügen neuer Computer horizontal skaliert werden können. Alle Daten werden auf die Festplatte geschrieben und an mehrere Broker kopiert. Um die Möglichkeiten der Skalierbarkeit zu verstehen, sollten Sie sich Unternehmen wie Netflix, LinkedIn und Microsoft ansehen. Alle senden täglich Billionen von Nachrichten über ihre Kafka-Cluster!
Kafka in Rails einrichten
Heroku bietet ein
Kafka-Cluster-Add-On , das für jede Umgebung verwendet werden kann. Für
Rubinanwendungen empfehlen wir die Verwendung des
Rubin-Kafka-Edelsteins . Die minimale Implementierung sieht ungefähr so aus:
Nach dem Konfigurieren der Konfiguration können Sie mit dem Gem Nachrichten senden. Dank des asynchronen Sendens von Ereignissen können wir Nachrichten von überall senden:
class OrdersController < ApplicationController def create @comment = Order.create!(params) $kafka_producer.produce(order.to_json, topic: "user_event", partition_key: user.id) end end
Wir werden im Folgenden über Serialisierungsformate sprechen, aber im Moment verwenden wir den guten alten JSON. Das
topic Argument bezieht sich auf das Protokoll, in das Kafka dieses Ereignis schreibt. Die Themen sind in verschiedene Abschnitte unterteilt, sodass Sie die Daten für ein bestimmtes Thema für eine bessere Skalierbarkeit und Zuverlässigkeit in verschiedene Broker aufteilen können. Und es ist wirklich eine gute Idee, zwei oder mehr Abschnitte für jedes Thema zu haben, denn wenn einer der Abschnitte fällt, werden Ihre Ereignisse trotzdem aufgezeichnet und verarbeitet. Kafka stellt sicher, dass Ereignisse in der Reihenfolge der Warteschlange innerhalb des Abschnitts, jedoch nicht innerhalb des gesamten Themas geliefert werden. Wenn die Reihenfolge der Ereignisse wichtig ist, wird durch das Senden von partition_key sichergestellt, dass alle Ereignisse eines bestimmten Typs auf derselben Partition gespeichert werden.
Kafka für Ihre Dienste
Einige der Funktionen, die Kafka zu einem nützlichen Tool machen, machen es auch zu einem Failover-RPC zwischen Diensten. Schauen Sie sich ein Beispiel für eine E-Commerce-Anwendung an:
def create_order create_order_record charge_credit_card
Wenn der Benutzer eine Bestellung
create_order , wird die Funktion
create_order . Dadurch wird eine Bestellung im System erstellt, Geld von der Karte abgezogen und eine E-Mail mit Bestätigung gesendet. Wie Sie sehen können, werden die letzten beiden Schritte in separaten Diensten ausgeführt.
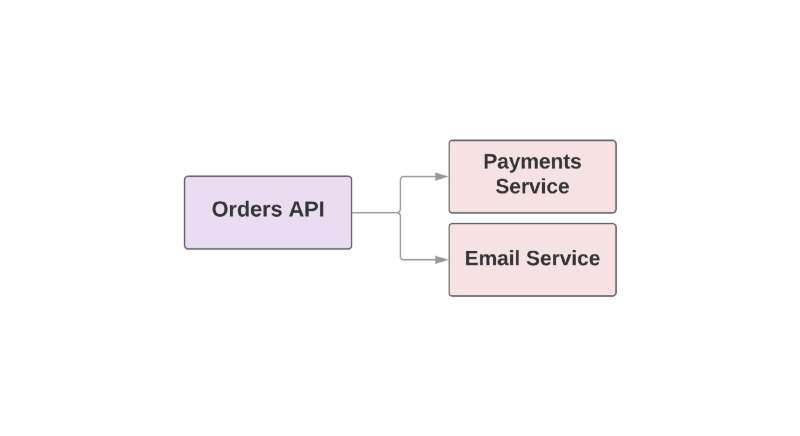
Eines der Probleme bei diesem Ansatz besteht darin, dass der übergeordnete Dienst in der Hierarchie für die Überwachung der Verfügbarkeit des nachgeschalteten Dienstes verantwortlich ist. Wenn sich herausstellte, dass der Dienst zum Versenden von Briefen ein schlechter Tag war, muss der höhere Dienst darüber Bescheid wissen. Wenn der sendende Dienst nicht verfügbar ist, müssen Sie eine Reihe von Aktionen wiederholen. Wie kann Kafka in dieser Situation helfen?
Zum Beispiel:
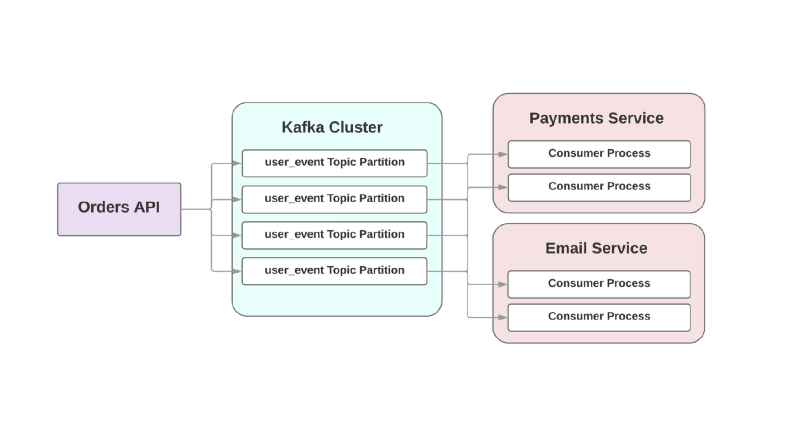
Bei diesem ereignisgesteuerten Ansatz kann ein übergeordneter Service ein Ereignis in Kafka aufzeichnen, bei dem ein Auftrag erstellt wurde. Aufgrund des sogenannten
mindestens einmaligen Ansatzes wird das Ereignis mindestens einmal in Kafka aufgezeichnet und steht den nachgeschalteten Verbrauchern zum Lesen zur Verfügung. Wenn der Dienst zum Senden von Briefen lügt, wartet das Ereignis auf der Festplatte, bis der Verbraucher aufsteht und es liest.
Ein weiteres Problem bei der RPC-orientierten Architektur besteht in schnell wachsenden Systemen: Das Hinzufügen eines neuen Downstream-Dienstes führt zu Änderungen im Upstream. Beispielsweise möchten Sie nach dem Erstellen einer Bestellung einen weiteren Schritt hinzufügen. In einer ereignisgesteuerten Welt müssen Sie einen weiteren Verbraucher hinzufügen, um einen neuen Ereignistyp zu verarbeiten.

Integration von Ereignissen in serviceorientierte Architektur
In einem Beitrag mit dem Titel „
Was meinst du mit„ ereignisgesteuert “von Martin Fowler
? “ Wird die Verwirrung um ereignisgesteuerte Anwendungen erörtert. Wenn Entwickler solche Systeme diskutieren, sprechen sie tatsächlich über eine große Anzahl verschiedener Anwendungen. Um ein allgemeines Verständnis der Natur solcher Systeme zu vermitteln, definierte Fowler mehrere Architekturmuster.
Werfen wir einen Blick auf diese Muster. Wenn Sie mehr wissen möchten, empfehle ich Ihnen, seinen
Bericht auf der GOTO Chicago 2017 zu lesen.
Ereignisbenachrichtigung
Das erste Fowler-Muster heißt
Ereignisbenachrichtigung . In diesem Szenario benachrichtigt der Produzentendienst die Verbraucher über das Ereignis mit einer Mindestmenge an Informationen:
{ "event": "order_created", "published_at": "2016-03-15T16:35:04Z" }
Wenn Verbraucher weitere Informationen über die Veranstaltung benötigen, stellen sie eine Anfrage an den Hersteller und erhalten weitere Daten.
Ereignisübertragene Zustandsübertragung
Die zweite Vorlage heißt
Event-Carried State Transfer . In diesem Szenario stellt der Hersteller zusätzliche Informationen zum Ereignis bereit, und der Verbraucher kann eine Kopie dieser Daten speichern, ohne zusätzliche Anrufe zu tätigen:
{ "event": "order_created", "order": { "order_id": 98765, "size": "medium", "color": "blue" }, "published_at": "2016-03-15T16:35:04Z" }
Event-bezogen
Fowler nannte die dritte Vorlage
Event-Sourced und sie ist eher architektonisch. Die Freigabe der Vorlage beinhaltet nicht nur die Kommunikation zwischen Ihren Diensten, sondern auch die Wahrung der Präsentation der Veranstaltung. Auf diese Weise wird sichergestellt, dass Sie den Status der Anwendung auch dann wiederherstellen können, wenn Sie die Datenbank verlieren, indem Sie einfach den gespeicherten Ereignisstrom ausführen. Mit anderen Worten, jedes Ereignis speichert einen bestimmten Status der Anwendung zu einem bestimmten Zeitpunkt.
Das große Problem bei diesem Ansatz ist, dass sich der Anwendungscode immer ändert und sich damit das Format oder die Datenmenge, die der Hersteller angibt, ändern kann. Dies macht das Wiederherstellen des Status der Anwendung problematisch.
Verantwortlichkeitstrennung für Befehlsabfragen
Die letzte Vorlage ist
Command Query Responsibility Segregation (CQRS). Die Idee ist, dass die Aktionen, die Sie auf das Objekt anwenden, z. B. Erstellen, Lesen, Aktualisieren, in verschiedene Domänen unterteilt werden sollten. Dies bedeutet, dass ein Dienst für die Erstellung, ein anderer für das Update usw. verantwortlich sein sollte. In objektorientierten Systemen wird häufig alles in einem Dienst gespeichert.
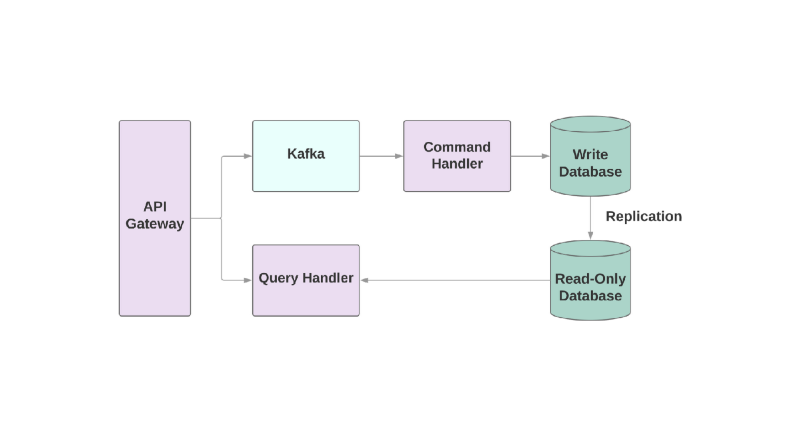
Ein Dienst, der in die Datenbank schreibt, liest den Ablauf von Ereignissen und verarbeitet Befehle. Anforderungen treten jedoch nur in der schreibgeschützten Datenbank auf. Die Aufteilung der Lese- und Schreiblogik in zwei verschiedene Dienste erhöht die Komplexität, ermöglicht es Ihnen jedoch, die Leistung für diese Systeme separat zu optimieren.
Die Probleme
Lassen Sie uns über einige Probleme sprechen, die bei der Integration von Kafka in Ihre serviceorientierte Anwendung auftreten können.
Das erste Problem könnten langsame Verbraucherprobleme sein. In einem ereignisorientierten System sollten Ihre Dienste Ereignisse sofort verarbeiten können, wenn sie von einem übergeordneten Dienst empfangen werden. Andernfalls hängen sie einfach ohne Benachrichtigungen über das Problem oder Zeitüberschreitungen. Der einzige Ort, an dem Sie Zeitüberschreitungen definieren können, ist eine Socket-Verbindung mit Kafka-Brokern. Wenn der Dienst das Ereignis nicht schnell genug verarbeitet, kann die Verbindung durch eine Zeitüberschreitung unterbrochen werden. Die Wiederherstellung des Dienstes erfordert jedoch zusätzliche Zeit, da das Erstellen solcher Sockets teuer ist.
Wie können Sie die Geschwindigkeit der Ereignisverarbeitung erhöhen, wenn der Verbraucher langsam ist? In Kafka können Sie die Anzahl der Verbraucher in einer Gruppe erhöhen, sodass mehr Ereignisse parallel verarbeitet werden können. Für einen Service sind jedoch mindestens 2 Verbraucher erforderlich: Im Falle eines Sturzes können beschädigte Abschnitte neu zugewiesen werden.
Es ist auch sehr wichtig, Metriken und Warnungen zu haben, um die Geschwindigkeit der Ereignisverarbeitung zu überwachen.
ruby-kafka kann mit ActiveSupport-Warnungen arbeiten und verfügt außerdem über StatsD- und Datadog-Module, die standardmäßig aktiviert sind. Darüber hinaus enthält das Juwel eine
Liste empfohlener Metriken für die Überwachung.
Ein weiterer wichtiger Aspekt beim Bauen von Systemen mit Kafka ist das Design von Verbrauchern, die in der Lage sind, Fehler zu behandeln. Kafka wird garantiert mindestens einmal eine Veranstaltung senden. schloss den Fall aus, dass die Nachricht überhaupt nicht gesendet wurde. Es ist jedoch wichtig, dass die Verbraucher auf wiederkehrende Ereignisse vorbereitet sind. Eine Möglichkeit, dies zu tun, besteht darin, immer
UPSERT zu verwenden, um der Datenbank neue Datensätze hinzuzufügen. Wenn der Datensatz bereits mit denselben Attributen vorhanden ist, ist der Aufruf im Wesentlichen inaktiv. Darüber hinaus können Sie jedem Ereignis eine eindeutige Kennung hinzufügen und Ereignisse, die bereits zuvor verarbeitet wurden, einfach überspringen.
Datenformate
Eine der Überraschungen bei der Arbeit mit Kafka ist möglicherweise die einfache Einstellung zum Datenformat. Sie können alles in Bytes senden und die Daten werden ohne Überprüfung an den Verbraucher gesendet. Einerseits bietet es Flexibilität und ermöglicht es Ihnen, sich nicht um das Datenformat zu kümmern. Wenn der Hersteller hingegen beschließt, die gesendeten Daten zu ändern, besteht die Möglichkeit, dass ein Verbraucher irgendwann kaputt geht.
Wählen Sie vor dem Erstellen einer ereignisorientierten Architektur ein Datenformat aus und analysieren Sie, wie es in Zukunft helfen wird, Schemata zu registrieren und zu entwickeln.
Eines der zur Verwendung empfohlenen Formate ist natürlich JSON. Dieses Format ist für Menschen lesbar und wird von allen bekannten Programmiersprachen unterstützt. Aber es gibt Fallstricke. Beispielsweise kann die Größe der endgültigen Daten in JSON erschreckend groß werden. Das Format ist erforderlich, um Schlüssel-Wert-Paare zu speichern, was flexibel genug ist, aber die Daten werden bei jedem Ereignis dupliziert. Das Ändern des Schemas ist ebenfalls eine schwierige Aufgabe, da es keine integrierte Unterstützung für das Überlagern eines Schlüssels mit einem anderen gibt, wenn Sie das Feld umbenennen müssen.
Das Team, das Kafka erstellt hat, berät
Avro als Serialisierungssystem. Daten werden in binärer Form gesendet, und dies ist nicht das am besten lesbare Format, aber im Inneren gibt es eine zuverlässigere Unterstützung für Schaltkreise. Die letzte Entität in Avro enthält sowohl Schema als auch Daten. Avro unterstützt sowohl einfache Typen wie Zahlen als auch komplexe Typen: Datumsangaben, Arrays usw. Darüber hinaus können Sie Dokumentation in das Schema aufnehmen, wodurch Sie den Zweck eines bestimmten Felds im System verstehen und viele andere integrierte Tools für die Arbeit mit dem Schema enthalten.
avro-builder ist ein Juwel von Salsify, das ein rubinartiges DSL zum Erstellen von Schemas bietet. Weitere
Informationen zu Avro finden Sie in
diesem Artikel .
Weitere Informationen
Wenn Sie daran interessiert sind, wie Kafka gehostet wird oder wie es in Heroku verwendet wird, gibt es mehrere Berichte, die für Sie von Interesse sein können.
Jeff Chao bei DataEngConf SF '17 „
Jenseits von 50.000 Partitionen: Wie Heroku arbeitet und die Grenzen von Kafka im Maßstab überschreitet“
Pavel Pravosud auf der Dreamforce '16
-Konferenz „
Dogfooding Kafka: Wie wir Herokus Echtzeit-Plattform-Event-Stream aufgebaut haben “
Schöne Aussicht!