Protokolle sind ein wichtiger Bestandteil des Systems, damit Sie verstehen, dass es wie erwartet funktioniert (oder nicht funktioniert). Unter den Bedingungen der Microservice-Architektur wird die Arbeit mit Protokollen zu einer separaten Disziplin einer speziellen Olympiade. Sie müssen sofort eine Reihe von Fragen lösen:
- wie man Protokolle aus der Anwendung schreibt;
- wo man Protokolle schreibt;
- wie Protokolle zur Speicherung und Verarbeitung geliefert werden;
- wie man Protokolle verarbeitet und speichert.
Durch die Verwendung der heute beliebten Containerisierungstechnologien wird dem Feld der Optionen zur Lösung des Problems Sand auf dem Rechen hinzugefügt.
Gerade über diese Entschlüsselung des Berichts von Yuri Bushmelev "Kartenrechen auf dem Gebiet der Sammlung und Lieferung von Protokollen"
Wen kümmert es bitte unter der Katze.
Ich heiße Yuri Bushmelev. Ich arbeite bei Lazada. Heute werde ich darüber sprechen, wie wir unsere Protokolle erstellt haben, wie wir sie gesammelt haben und was wir dort schreiben.

Woher kommen wir? Wer sind wir Lazada ist der Online-Shop Nr. 1 in sechs Ländern Südostasiens. Alle diese Länder werden von Rechenzentren verteilt. Es gibt jetzt 4 Rechenzentren. Warum ist das wichtig? Denn einige Entscheidungen waren darauf zurückzuführen, dass zwischen den Zentren eine sehr schwache Verbindung besteht. Wir haben eine Microservice-Architektur. Ich war überrascht, dass wir bereits 80 Microservices haben. Als ich die Aufgabe mit Protokollen begann, waren es nur 20. Außerdem gibt es ein ziemlich großes Stück PHP-Erbe, mit dem man auch leben und sich abfinden muss. All dies generiert derzeit mehr als 6 Millionen Nachrichten pro Minute im gesamten System. Weiter werde ich zeigen, wie wir versuchen, damit zu leben und warum dies so ist.

Wir müssen irgendwie mit diesen 6 Millionen Nachrichten leben. Was sollen wir mit ihnen machen? 6 Millionen Nachrichten, die Sie benötigen:
- von der Bewerbung senden
- zur Lieferung annehmen
- zur Analyse und Lagerung liefern.
- zu analysieren
- irgendwie speichern.

Als drei Millionen Nachrichten erschienen, sah ich ungefähr gleich aus. Weil wir mit ein paar Cent angefangen haben. Es ist klar, dass dort Anwendungsprotokolle geschrieben sind. Zum Beispiel konnte ich keine Verbindung zur Datenbank herstellen, ich konnte eine Verbindung zur Datenbank herstellen, aber ich konnte nichts lesen. Darüber hinaus schreibt jeder unserer Microservices auch ein Zugriffsprotokoll. Jede Anfrage, die bei einem Microservice eintrifft, fällt in das Protokoll. Warum machen wir das? Entwickler möchten in der Lage sein, zu verfolgen. In jedem Zugriffsprotokoll befindet sich ein Traceid-Feld, entlang dessen eine spezielle Schnittstelle die gesamte Kette weiter abwickelt und den Trace wunderschön anzeigt. Trace zeigt, wie die Anfrage gelaufen ist, und dies hilft unseren Entwicklern, schnell mit nicht identifiziertem Müll umzugehen.

Wie kann man damit leben? Jetzt werde ich kurz das Feld der Optionen beschreiben - wie dieses Problem im Allgemeinen gelöst wird. So lösen Sie das Problem des Sammelns, Übertragens und Speicherns von Protokollen.

Wie schreibe ich aus der Anwendung? Es ist klar, dass es verschiedene Wege gibt. Insbesondere gibt es bewährte Verfahren, wie modische Genossen uns sagen. Es gibt eine alte Schule in zwei Formen, wie die Großväter sagten. Es gibt andere Möglichkeiten.

Mit der Sammlung von Protokollen über die gleiche Situation. Es gibt nicht viele Möglichkeiten, diesen bestimmten Teil zu lösen. Es gibt schon mehr, aber nicht so viele.

Aber mit der Lieferung und der anschließenden Analyse beginnt die Anzahl der Variationen zu explodieren. Ich werde jetzt nicht jede Option beschreiben. Ich denke, die Hauptoptionen werden von jedem gehört, der sich für das Thema interessiert hat.

Ich werde zeigen, wie wir es in Lazada gemacht haben und wie eigentlich alles begann.

Vor einem Jahr kam ich nach Lazada und sie schickten mich zu einem Projekt über Protokolle. Es war so. Das Protokoll der Anwendung wurde in stdout und stderr geschrieben. Sie haben alles auf modische Weise gemacht. Aber dann haben die Entwickler es aus den Standardabläufen geworfen, und dann werden die Infrastrukturspezialisten es irgendwie klären. Zwischen Infrastrukturspezialisten und Entwicklern gibt es auch Auslöser, die sagten: "Äh ... okay, lasst sie uns einfach in eine Datei mit einer Shell einwickeln, das ist alles." Und da sich das alles im Container befindet, haben sie es direkt in den Container selbst eingewickelt, den Katalog heruntergeladen und dort abgelegt. Ich denke, dass es für jeden ungefähr offensichtlich ist, was daraus wurde.

Mal sehen, etwas weiter weg. Wie liefern wir diese Protokolle? Jemand hat sich für td-agent entschieden, das eigentlich fließend, aber nicht ganz fließend ist. Ich habe die Beziehung dieser beiden Projekte immer noch nicht verstanden, aber sie scheinen ungefähr dasselbe zu sein. Und dieser in Ruby geschriebene Fluss liest Protokolldateien und analysiert sie für einige regelmäßige Zeiträume in JSON. Dann schickte er sie nach Kafka. Und in Kafka hatten wir für jede API 4 separate Themen. Warum 4? Weil es live gibt, gibt es Inszenierung und weil es stdout und stderr gibt. Entwickler bringen sie zur Welt, und Infrastrukturingenieure müssen sie in Kafka erstellen. Darüber hinaus wurde Kafka von einer anderen Abteilung kontrolliert. Daher war es notwendig, ein Ticket zu erstellen, damit dort 4 Themen für jede API erstellt werden. Jeder hat es vergessen. Im Allgemeinen gab es Müll und Dämpfe.
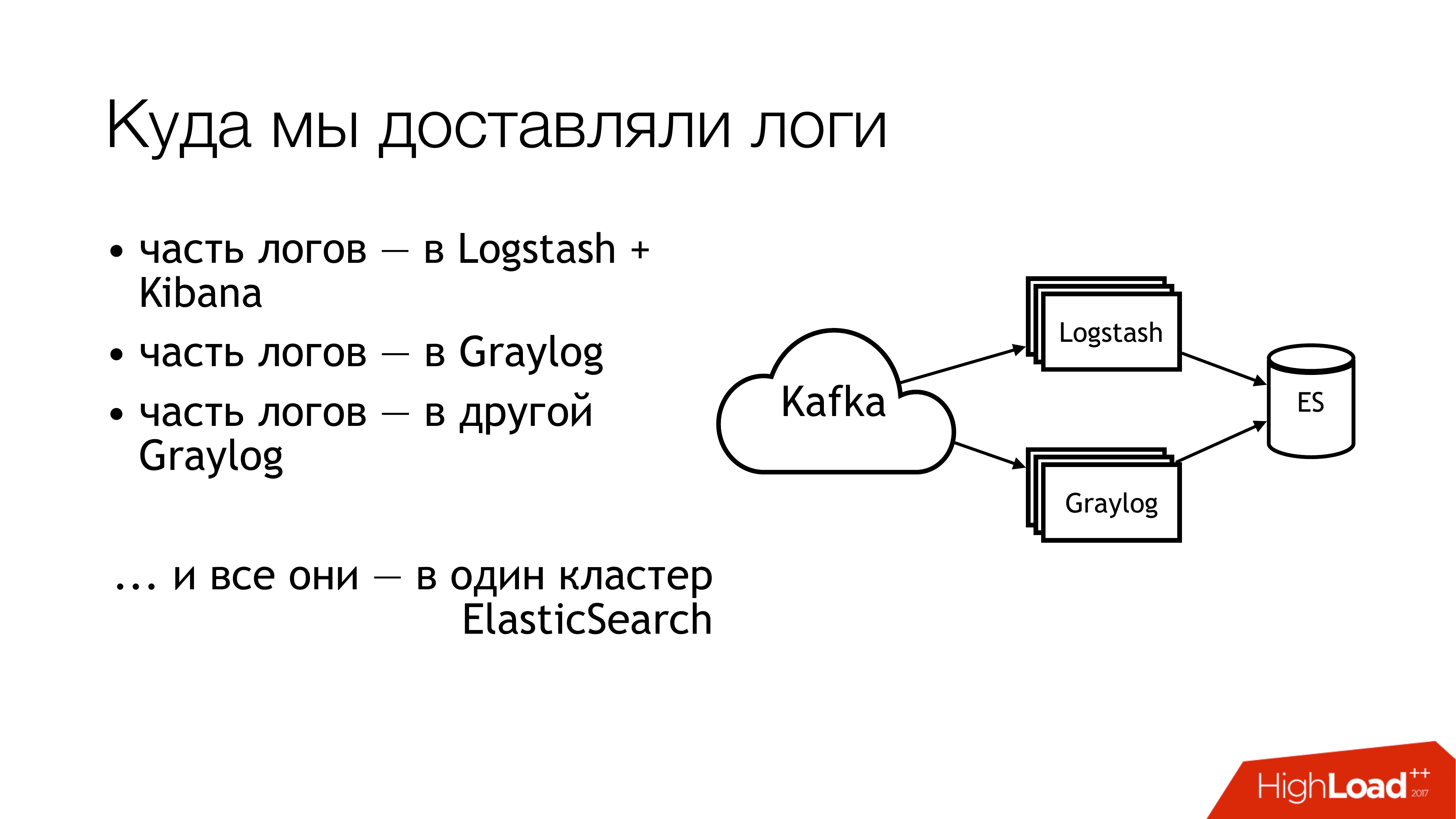
Was haben wir als nächstes damit gemacht? Wir haben es an Kafka geschickt. Weiter von Kafka flog die Hälfte der Baumstämme nach Logstash. Die andere Hälfte der Protokolle wurde freigegeben. Ein Teil flog in ein Graylog, ein Teil - in ein anderes Graylog. Infolgedessen flog all dies in einen Elasticsearch-Cluster. Das heißt, dieses ganze Durcheinander fiel schließlich dort hin. Sie müssen das nicht tun!

So sieht es aus, wenn Sie von oben aus der Ferne schauen. Tu das nicht! Hier geben die Zahlen sofort die Problembereiche an. Es gibt tatsächlich mehr davon, aber 6 sind wirklich ziemlich problematisch, mit denen Sie etwas tun müssen. Ich werde jetzt separat darüber sprechen.

Hier (1,2,3) schreiben wir Dateien und dementsprechend sind hier drei Rechen gleichzeitig.
Das erste (1) ist, dass wir sie irgendwo schreiben müssen. Ich möchte der API nicht immer die Möglichkeit geben, direkt in eine Datei zu schreiben. Es ist wünschenswert, dass die API im Container isoliert und noch besser schreibgeschützt ist. Ich bin ein Systemadministrator, daher habe ich eine etwas alternative Sicht auf diese Dinge.
Der zweite Punkt (2,3) - Wir haben viele Anfragen an die API. Die API schreibt viele Daten in eine Datei. Dateien wachsen. Wir müssen sie drehen. Denn sonst gibt es keine Möglichkeit, Discs zu bekommen. Das Drehen ist schlecht, da sie über die Shell in ein Verzeichnis umgeleitet werden. Wir können es in keiner Weise bewegen. Eine Anwendung kann nicht angewiesen werden, Deskriptoren neu zu entdecken. Weil die Entwickler Sie wie einen Narren ansehen werden: „Was sind die Deskriptoren? Wir schreiben in der Regel an stdout. “ Infrastrukturingenieure haben Copytruncate in Logrotate erstellt, wodurch nur eine Kopie der Datei erstellt und das Original übertragen wird. Dementsprechend endet zwischen diesen Kopiervorgängen normalerweise der Speicherplatz.
(4) Wir hatten verschiedene Formate und waren in verschiedenen APIs. Sie waren etwas anders, aber Regexp musste anders geschrieben werden. Da dies alles von Puppet kontrolliert wurde, gab es ein großes Bündel von Klassen mit ihren Kakerlaken. Außerdem konnte td-agent die meiste Zeit Gedächtnis essen, dumm, es konnte nur so tun, als ob es funktioniert, und nichts tun. Draußen war es unmöglich zu verstehen, dass er nichts tat. Bestenfalls wird er fallen und jemand wird ihn später abholen. Genauer gesagt, der Alarm wird eintreffen und jemand wird mit seinen Händen hinübergehen.

(6) Und der meiste Müll und Abfall - es war Elasticsearch. Weil es eine alte Version war. Weil wir zu dieser Zeit keine engagierten Meister hatten. Wir hatten heterogene Protokolle, in denen sich die Felder schneiden konnten. Verschiedene Protokolle verschiedener Anwendungen können mit denselben Feldnamen geschrieben werden, aber gleichzeitig können sich unterschiedliche Daten darin befinden. Das heißt, ein Protokoll enthält eine Ganzzahl im Feld, z. B. Ebene. Ein weiteres Protokoll enthält String im Feld Ebene. In Abwesenheit einer statischen Abbildung wird so etwas Wunderbares erhalten. Wenn nach der Indexrotation in elasticsearch die erste Nachricht mit einer Zeichenfolge eingetroffen ist, leben wir normal. Und wenn es zuerst mit Integer angekommen ist, werden alle nachfolgenden Nachrichten, die mit String angekommen sind, einfach verworfen. Weil der Feldtyp nicht übereinstimmt.

Wir begannen diese Fragen zu stellen. Wir beschlossen, die Schuldigen nicht zu suchen.

Aber es muss etwas getan werden! Das Offensichtliche ist, Standards zu setzen. Wir hatten bereits einige Standards. Einige haben wir etwas später bekommen. Glücklicherweise wurde zu diesem Zeitpunkt bereits ein einheitliches Protokollformat für alle APIs genehmigt. Es wird direkt in die Standards für das Zusammenspiel von Diensten geschrieben. Dementsprechend sollten diejenigen, die Protokolle erhalten möchten, diese in diesem Format schreiben. Wenn jemand keine Protokolle in diesem Format schreibt, übernehmen wir keine Garantie.
Darüber hinaus möchte ich einen einheitlichen Standard für die Methoden zur Aufzeichnung, Zustellung und Sammlung von Protokollen festlegen. Eigentlich, wo man sie schreibt und wie man sie liefert. Die ideale Situation ist, wenn die Projekte dieselbe Bibliothek verwenden. Hier ist eine separate Protokollierungsbibliothek für Go, es gibt eine separate Bibliothek für PHP. Jeder, den wir haben - jeder sollte sie benutzen. Im Moment würde ich sagen, dass wir es um 80 Prozent bekommen. Aber einige essen weiterhin Kakteen.
Und dort (auf der Folie) erschien kaum „SLA for Log Delivery“. Er ist noch nicht da, aber wir arbeiten daran. Weil es sehr praktisch ist, wenn in der Infra angegeben wird, dass wir dort wahrscheinlich so und so liefern, wenn Sie in einem solchen Format an einen solchen Ort und nicht mehr als N Nachrichten pro Sekunde schreiben. Dies lindert eine Reihe von Kopfschmerzen. Wenn es eine SLA gibt, dann ist das einfach wunderbar!

Wie haben wir angefangen, das Problem zu lösen? Der Hauptrechen war mit td-agent. Es war nicht klar, wohin die Protokolle gingen. Werden sie geliefert? Werden sie gehen? Wo sind sie überhaupt? Daher wurde beschlossen, als erstes Element td-agent zu ersetzen. Ich skizzierte kurz die Optionen, durch die es ersetzt werden soll.
Fließend Erstens bin ich ihm bei einem früheren Job begegnet, und er ist auch regelmäßig dort hingefallen. Zweitens ist dies nur im Profil dasselbe.
Filebeat. Wie war es für uns bequem? Die Tatsache, dass er unterwegs ist und wir viel Fachwissen in Go haben. Wenn das so wäre, könnten wir es irgendwie für uns selbst hinzufügen. Deshalb haben wir es nicht genommen. Damit auch keine Versuchung bestand, es für sich selbst neu zu schreiben.
Die offensichtliche Lösung für den Sysadmin sind alle Syslogs in dieser Menge (syslog-ng / rsyslog / nxlog).
Oder schreiben Sie etwas Eigenes, aber wir haben es fallen lassen, genau wie Filebeat. Wenn Sie etwas schreiben, ist es besser, etwas Nützliches für das Geschäft zu schreiben. Für die Lieferung von Protokollen ist es besser, etwas fertig zu nehmen.
Daher kam es tatsächlich auf die Wahl zwischen syslog-ng und rsyslog an. Er beugte sich zu rsyslog, einfach weil wir bereits Klassen für rsyslog in Puppet hatten und ich keinen offensichtlichen Unterschied zwischen ihnen fand. Was ist Syslog, was ist Syslog? Ja, jemand hat schlechtere Unterlagen, jemand hat bessere. Er weiß wie und er - auf eine andere Art und Weise.

Und ein bisschen über rsyslog. Zunächst einmal ist es cool, weil es viele Module hat. Es verfügt über von Menschen lesbares RainerScript (eine moderne Konfigurationssprache). Ein großartiger Bonus ist, dass wir das Verhalten von td-agent mit seinen regulären Mitteln emulieren können und sich für Anwendungen nichts geändert hat. Das heißt, wir ändern td-agent in rsyslog, aber wir berühren nicht alles andere. Und sofort bekommen wir eine funktionierende Lieferung. Als nächstes ist mmnormalize eine großartige Sache in rsyslog. Sie können Protokolle analysieren, jedoch nicht Grok und Regexp verwenden. Sie erstellt einen abstrakten Syntaxbaum. Es analysiert Protokolle ungefähr, während der Compiler Quellcodes analysiert. Auf diese Weise können Sie sehr schnell arbeiten, wenig CPU verbrauchen und im Allgemeinen ist es eine sehr coole Sache. Es gibt Unmengen anderer Boni. Ich werde nicht aufhören.

Rsyslog hat immer noch eine Reihe von Fehlern. Sie sind ungefähr gleich Boni. Die Hauptprobleme - Sie müssen in der Lage sein, es zu kochen, und Sie müssen die Version auswählen.
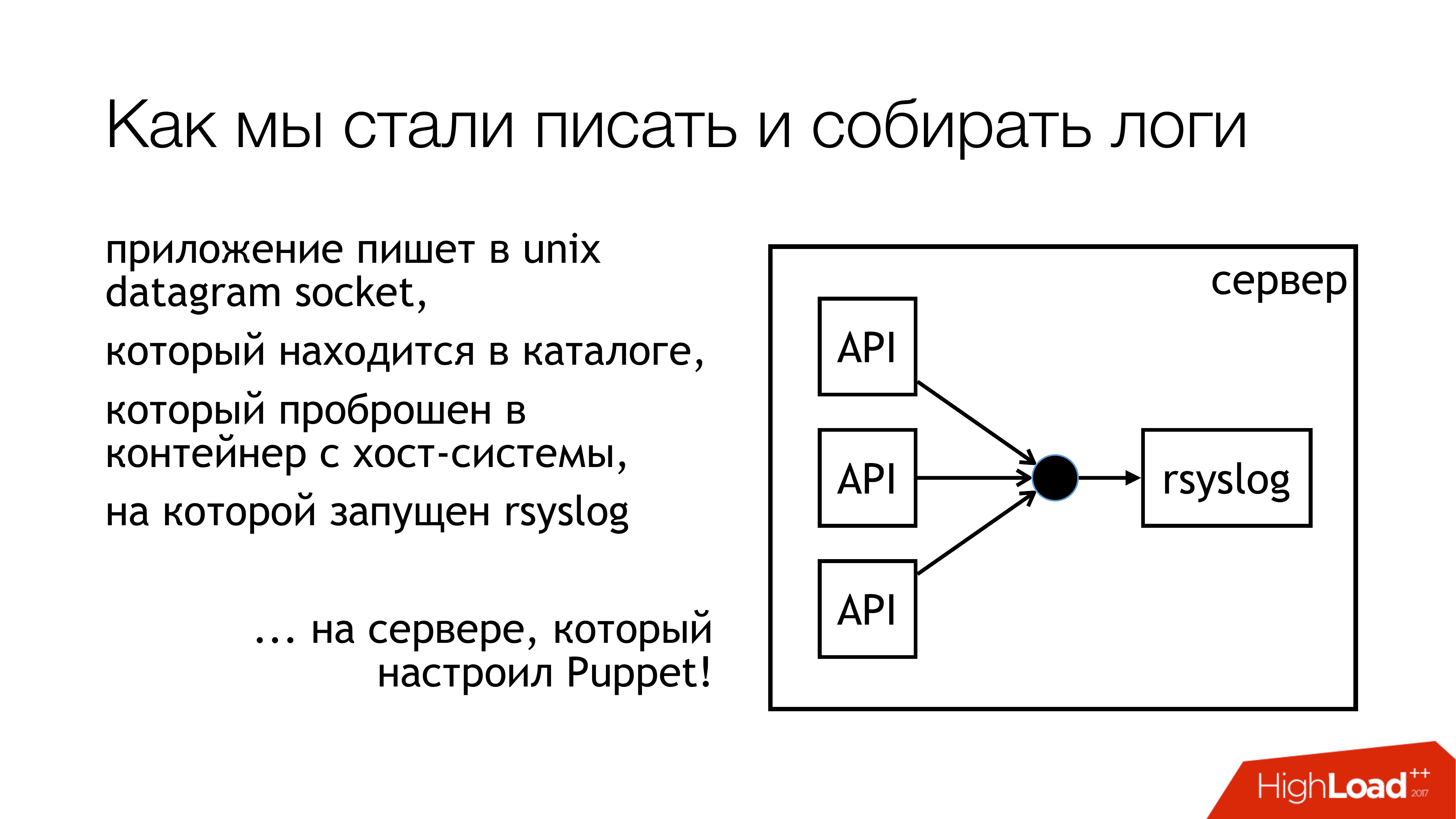
Wir beschlossen, Protokolle in den Unix-Socket zu schreiben. Und nicht in / dev / log, da dort Brei aus den Systemprotokollen vorhanden ist, befindet sich in dieser Pipeline ein Journal. Schreiben wir also in einen benutzerdefinierten Socket. Wir hängen es an einen separaten Regelsatz an. Wir werden uns nicht einmischen. Alles wird transparent und klar sein. Also haben wir es tatsächlich getan. Das Verzeichnis mit diesen Sockets ist standardisiert und wird an alle Container weitergeleitet. Container können den benötigten Socket sehen, öffnen und schreiben.
Warum nicht eine Datei? Weil jeder einen Artikel über Badushechka gelesen hat, der versucht hat, die Datei an Docker weiterzuleiten, und sich herausstellte, dass sich der Dateideskriptor nach dem Neustart von rsyslog ändert und Docker diese Datei verliert. Er hält etwas anderes offen, aber nicht die gleiche Buchse, in der sie schreiben. Wir haben beschlossen, dieses Problem zu umgehen und gleichzeitig das Blockierungsproblem zu umgehen.

Rsyslog führt die auf der Folie angegebenen Aktionen aus und sendet die Protokolle entweder an das Relais oder an Kafka. Kafka passt zum alten Weg. Relay - Ich habe versucht, reines rsyslog zu verwenden, um Protokolle zu liefern. Ohne Message Queue Standard-Rsyslog-Tools. Grundsätzlich funktioniert es.

Aber es gibt Nuancen, wie man sie später in diesen Teil stopft (Logstash / Graylog / ES). Dieser Teil (rsyslog-rsyslog) wird zwischen Rechenzentren verwendet. Hier ist ein komprimierter TCP-Link, mit dem Sie Bandbreite sparen und dementsprechend die Wahrscheinlichkeit erhöhen können, dass wir unter Bedingungen, in denen der Kanal voll ist, Protokolle von einem anderen Rechenzentrum erhalten. Weil wir Indonesien haben, in dem alles schlecht ist. Hier liegt dieses ständige Problem.

Wir haben darüber nachgedacht, wie wir tatsächlich überwachen und mit welcher Wahrscheinlichkeit die von der Anwendung aufgezeichneten Protokolle dieses Ziel erreichen. Wir haben uns entschlossen, die Metriken zu erhalten. Rsyslog verfügt über ein eigenes Statistiksammlungsmodul, das über eine Art Zähler verfügt. Beispielsweise kann es Ihnen die Größe der Warteschlange anzeigen oder wie viele Nachrichten in einer solchen Aktion eingegangen sind. Ihnen kann schon etwas weggenommen werden. Außerdem verfügt es über benutzerdefinierte Leistungsindikatoren, die konfiguriert werden können, und zeigt beispielsweise die Anzahl der Nachrichten an, die von einer API geschrieben wurden. Als nächstes habe ich rsyslog_exporter in Python geschrieben, und wir haben alles an Prometheus gesendet und geplottet. Graylog-Metriken wollten wirklich, aber bisher hatten wir keine Zeit, sie zu konfigurieren.

Was sind die Probleme? Probleme traten mit der Tatsache auf, dass wir (PLÖTZLICH!) Entdeckten, dass unsere Live-APIs 50.000 Nachrichten pro Sekunde schreiben. Dies ist nur eine Live-API ohne Staging. Und Graylog zeigt uns nur 12.000 Nachrichten pro Sekunde. Und es stellte sich eine vernünftige Frage, aber wo sind die Reste? Daraus folgerten wir, dass Graylog einfach nicht zurechtkommt. Sie sahen aus, und tatsächlich beherrschte Graylog mit Elasticsearch diesen Stream nicht.
Weitere Entdeckungen, die wir dabei gemacht haben.
Write to Socket sind blockiert. Wie ist das passiert? Als ich rsyslog für die Zustellung verwendete, brach irgendwann unser Kanal zwischen den Rechenzentren. Die Lieferung erfolgte an einem Ort, die Lieferung an einem anderen Ort. All dies ist auf einem Computer mit APIs angekommen, die in den rsyslog-Socket schreiben. Es gab eine Warteschlange. Dann wurde die Warteschlange zum Schreiben in den Unix-Socket gefüllt, die standardmäßig 128 Pakete enthält. Und das nächste write () in der Anwendung wird blockiert. Als wir uns die Bibliothek angesehen haben, die wir in Anwendungen auf Go verwenden, wurde dort geschrieben, dass das Schreiben in den Socket im nicht blockierenden Modus erfolgt. Wir waren uns sicher, dass nichts blockiert. Weil wir einen Artikel über Badushechka gelesen haben, der darüber geschrieben hat. Aber es gibt einen Moment. Um diesen Anruf herum gab es immer noch einen endlosen Zyklus, in dem ständig versucht wurde, die Nachricht in die Steckdose zu schieben. Wir haben es nicht bemerkt. Ich musste die Bibliothek neu schreiben. Seitdem hat es sich mehrmals geändert, aber jetzt haben wir Sperren in allen Subsystemen beseitigt. Daher können Sie rsyslog stoppen und nichts wird fallen.
Es ist notwendig, die Größe der Warteschlangen zu überwachen, um nicht auf diesen Rechen zu treten. Erstens können wir überwachen, wann wir anfangen, Nachrichten zu verlieren. Zweitens können wir überwachen, dass wir im Prinzip Lieferprobleme haben.
Und ein weiterer unangenehmer Moment - 10-fache Verstärkung in der Microservice-Architektur - ist sehr einfach. Wir haben nicht viele eingehende Anfragen, aber aufgrund des Diagramms, in dem diese Nachrichten ausgeführt werden, und aufgrund von Zugriffsprotokollen erhöhen wir die Belastung der Protokolle tatsächlich um das Zehnfache. Leider hatte ich keine Zeit, die genauen Zahlen zu berechnen, aber Microservices - das sind sie. Dies muss berücksichtigt werden. Es stellt sich heraus, dass das Protokollsammlungssubsystem derzeit in Lazada am meisten geladen ist.

Wie löse ich das Elasticsearch-Problem? Wenn Sie die Protokolle schnell an einem Ort abrufen müssen, um nicht auf allen Computern ausgeführt zu werden und sie dort nicht zu sammeln, verwenden Sie den Dateispeicher. Dies funktioniert garantiert. Es wird von jedem Server gemacht. Sie müssen nur die Festplatten dort kleben und syslog setzen. Danach haben Sie garantiert alle Protokolle an einem Ort. Weiterhin wird es bereits möglich sein, Elasticsearch, Graylog, etwas anderes langsam einzustellen. Sie haben jedoch bereits alle Protokolle und können diese außerdem so weit speichern, wie genügend Festplatten-Arrays vorhanden sind.

Zum Zeitpunkt meines Berichts sah die Schaltung so aus. Wir haben praktisch aufgehört, in die Datei zu schreiben. Jetzt werden wir höchstwahrscheinlich die Reste ausschalten. Auf lokalen Computern, auf denen die API ausgeführt wird, wird das Schreiben in Dateien beendet. Erstens gibt es einen Dateispeicher, der sehr gut funktioniert. Zweitens ist der Platz auf diesen Maschinen ständig leer, es ist notwendig, ihn ständig zu überwachen.
Dieser Teil mit Logstash und Graylog steigt wirklich an. Deshalb müssen wir es loswerden. Sie müssen eine Sache wählen.

Wir beschlossen, Logstash und Kibana zu werfen. Weil wir eine Sicherheitsabteilung haben. Was ist die Verbindung? Die Verbindung besteht darin, dass Kibana ohne X-Pack und ohne Shield keine Differenzierung der Zugriffsrechte auf Protokolle zulässt. Deshalb nahmen sie Graylog. Er hat alles. Ich mag ihn nicht, aber es funktioniert. Wir kauften neues Eisen, legten dort frisches Graylog ab und verschoben alle Protokolle mit strengen Formaten in ein separates Graylog. Wir haben das Problem mit verschiedenen Arten identischer Felder organisatorisch gelöst.

Was genau ist im neuen Graylog enthalten? Wir haben gerade alles im Docker aufgezeichnet. Wir haben eine Reihe von Servern genommen, drei Kafka-Instanzen ausgerollt, 7 Graylog-Server Version 2.3 (weil ich Elasticsearch Version 5 wollte). All dies bei Überfällen von der Festplatte ausgelöst. Wir haben eine Indexierungsrate von bis zu 100.000 Nachrichten pro Sekunde gesehen. Wir haben die Zahl von 140 Terabyte Daten pro Woche gesehen.

Und wieder ein Rechen! Zwei Verkäufe kommen. Wir sind für 6 Millionen Nachrichten umgezogen. Bei uns hat Graylog keine Zeit zum Kauen. Irgendwie müssen wir wieder überleben.

Wir haben so überlebt. Wir haben ein paar weitere Server und SSDs hinzugefügt. Im Moment leben wir so. Jetzt kauen wir bereits 160.000 Nachrichten pro Sekunde. Wir haben das Limit noch nicht erreicht, daher ist noch nicht klar, wie viel wir wirklich daraus machen können.

Das sind unsere Pläne für die Zukunft. Das wichtigste davon ist wahrscheinlich die hohe Verfügbarkeit. Wir haben es noch nicht. Mehrere Autos sind gleich konfiguriert, aber bisher läuft alles durch ein Auto. , failover .
Graylog.
rate limit , API, bandwidth .
, - SLA c , . , .
.

, , . -, . -, syslog — . -, rsyslog , . .
.
: - … (filebeat?)
: . . API , , . pipe. : « , , »? , , : « , ».
: HDFS?
: . , , , , long term solution.
: .
: . "" .
: rsyslog. TCP, UDP. UDP, ?
: . , , . , : « , - , - », «! , , , .» . , ? , ? best effort. , 100% . . .
: API - , , ? - .
: , . . , . , API . rsyslog . API , , timestamp . Graylog, timestamp. .
: Timestamp .
: Timestamp API. , , . NTP. API timestamp . rsyslog .
: . , . ? ?
: . - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. . , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . . Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
Frage : Verwenden Sie Kafka, weil Sie es hatten? Nicht für andere Zwecke verwendet?
Antwort : Kafka, das vom Data Sience-Team verwendet wurde. Dies ist ein völlig eigenständiges Projekt, zu dem ich leider nichts sagen kann. Ich weiß es nicht Sie wurde vom Data Science-Team geleitet. Als die Protokolle gestartet wurden, entschieden sie sich, sie zu verwenden, um keine eigenen zu erstellen. Jetzt haben wir Graylog aktualisiert und die Kompatibilität verloren, da es eine alte Version von Kafka gibt. Wir mussten unsere eigenen bekommen. Gleichzeitig haben wir diese vier Themen für jede API entfernt. Wir haben ein breites Thema für alle live gemacht, ein breites Thema für alle Inszenierungen und einfach alles dort aufgeschlüsselt. Graylog harkt das alles parallel.
Frage : Warum ist dieser Schamanismus mit Sockeln notwendig? Haben Sie versucht, den Syslog-Protokolltreiber für Container zu verwenden?
Antwort : In dem Moment, als wir diese Frage stellten, hatten wir eine angespannte Beziehung zum Hafenarbeiter. Es war Docker 1.0 oder 0.9. Docker selbst war komisch. Zweitens, wenn Sie auch die Protokolle hineinschieben ... Ich habe den unbestätigten Verdacht, dass er alle Protokolle durch den Docker-Daemon durch sich selbst weiterleitet. Wenn eine API verrückt wird, stecken die restlichen APIs in der Tatsache fest, dass sie nicht stdout und stderr senden können. Ich weiß nicht, wohin das führen wird. Ich habe den Verdacht, dass Sie den Docker-Syslog-Treiber an dieser Stelle nicht verwenden müssen. Unsere Abteilung für Funktionstests verfügt über einen eigenen Graylog-Cluster mit Protokollen. Sie verwenden Docker-Log-Treiber und dort scheint alles in Ordnung zu sein. Aber sie schreiben sofort GELF an Graylog. Wir in dem Moment, als das alles so war, brauchten wir es, um einfach zu funktionieren. Vielleicht werden wir es später versuchen, wenn jemand kommt und sagt, dass es seit hundert Jahren normal funktioniert.
Frage : Sie liefern zwischen Rechenzentren auf rsyslog. Warum nicht bei Kafka?
Antwort : Wir machen beides, und das in Wirklichkeit. Aus zwei Gründen. Wenn der Kanal vollständig tot ist, haben wir alle Protokolle, auch in komprimierter Form, werden nicht durch ihn kriechen. Und mit Kafka können sie einfach verloren gehen. Auf diese Weise können wir diese Protokolle nicht mehr kleben. Wir verwenden Kafka in diesem Fall nur direkt. Wenn wir einen guten Kanal haben und ihn freigeben möchten, verwenden wir deren rsyslog. Tatsächlich können Sie es jedoch so konfigurieren, dass er selbst das fallen lässt, was nicht gekrochen ist. Im Moment verwenden wir rsyslog direkt irgendwo, irgendwo in Kafka.