
Entwickler sind verrückt nach den seltsamsten Dingen. Wir alle ziehen es vor, uns als überrationale Wesen zu betrachten, aber wenn es um die Auswahl einer bestimmten Technologie geht, geraten wir in eine Art Wahnsinn, springen von einem Kommentar zu HackerNews zu einem Beitrag in einem Blog und sind jetzt, als wären wir in Vergessenheit geraten, hilflos Wir segeln auf die hellste Lichtquelle zu und verneigen uns gehorsam davor, nachdem wir völlig vergessen haben, wonach wir ursprünglich gesucht haben.
So treffen rationale Menschen überhaupt keine Entscheidungen. Genau deshalb entscheiden sich die Entwickler beispielsweise für MapReduce.
Wie Joe Hellerstein in seinem Vortrag über Datenbanken für Studenten (in der 54. Minute) feststellte:
Tatsache ist, dass es weltweit ungefähr 5 Unternehmen gibt, die solch ehrgeizige Aufgaben ausführen. Was alle anderen betrifft ... sie geben unglaubliche Ressourcen aus, um ein fehlertolerantes System bereitzustellen, das sie wirklich nicht benötigen. Die Leute hatten in den 2000er Jahren eine Art "googeln": "Wir werden alles genau so machen wie Google, weil wir auch den größten Datenverarbeitungsdienst der Welt verwalten ..." [ironischerweise schüttelt er den Kopf und wartet auf das Lachen des Publikums]

Wie viele Stockwerke im Gebäude Ihres Rechenzentrums? Google hat beschlossen, zumindest in diesem speziellen Rechenzentrum in Mays County, Oklahoma, um vier Uhr zu bleiben.
Ja, Ihr System ist widerstandsfähiger als Sie es benötigen, aber überlegen Sie, was es kosten könnte. Der Punkt ist nicht nur die Notwendigkeit, große Datenmengen zu verarbeiten. Sie tauschen wahrscheinlich ein komplettes System - mit Transaktionen, Indizes und Abfrageoptimierung - gegen etwas relativ Schwaches aus. Dies ist ein bedeutender Rückschritt. Wie viele Hadoop-Benutzer tun dies bewusst? Wie viele von ihnen treffen eine wirklich ausgewogene Entscheidung?
MapReduce / Hadoop ist ein sehr einfaches Beispiel. Selbst die Anhänger des Frachtkultes erkannten bereits, dass die Flugzeuge nicht alle ihre Probleme lösen würden. Mit MapReduce können Sie jedoch eine wichtige Verallgemeinerung vornehmen: Wenn Sie Technologien verwenden, die für ein großes Unternehmen entwickelt wurden, aber gleichzeitig kleine Probleme lösen, können Sie gedankenlos handeln. Nicht einmal, es ist sehr wahrscheinlich, dass Sie sich von mystischen Ideen leiten lassen, dass Sie, wenn Sie Giganten wie Google und Amazon imitieren, die gleichen Höhen erreichen.

Ja, dieser Artikel ist ein weiterer Gegner des Frachtkultes. Aber warten Sie, ich habe eine nützliche Checkliste für Sie, mit der Sie fundiertere Entscheidungen treffen können.
Cooles Framework: UNPHAT
Wenn Sie das nächste Mal eine neue coole Technik zum (Um-) Formen Ihres Systems googeln, fordere ich Sie auf, anzuhalten und nur das UNPHAT- Framework zu verwenden:
- Versuchen Sie nicht einmal, über mögliche Lösungen nachzudenken, bevor Sie das (Verständnis-) Problem verstanden haben. Ihr Hauptziel ist es, das Problem in Bezug auf das Problem zu „lösen“, nicht in Bezug auf Lösungen.
- Listen Sie (eNumerate) mehrere mögliche Lösungen auf. Sie müssen nicht sofort mit dem Finger auf Ihre Lieblingsoption zeigen.
- Ziehen Sie eine separate Lösung in Betracht und lesen Sie gegebenenfalls die Dokumentation (Papier) .
- Definieren Sie den historischen Kontext, in dem diese Lösung erstellt wurde.
- Übereinstimmende Vorteile mit Fehlern. Analysieren Sie, was die Entscheidungsträger opfern mussten, um ihr Ziel zu erreichen.
- Denken Sie (denken Sie) ! Überlegen Sie nüchtern und ruhig, wie gut diese Lösung für Ihre Anforderungen geeignet ist. Was genau muss sich ändern, damit Sie Ihre Meinung ändern können? Wie viel weniger Daten sollten beispielsweise vorhanden sein, damit Sie Hadoop nicht verwenden?
Du bist nicht Amazon
Die Verwendung von UNPHAT ist einfach. Erinnern Sie sich an mein jüngstes Gespräch mit einem Unternehmen, das sich hastig entschlossen hat, Cassandra für einen intensiven Prozess des Lesens von nachts heruntergeladenen Daten zu verwenden.
Da ich bereits mit der Dynamo-Dokumentation vertraut war und wusste, dass Cassandra ein abgeleitetes System ist, verstand ich, dass in diesen Datenbanken das Hauptaugenmerk auf der Fähigkeit zur Aufzeichnung lag (Amazon musste die Aktion "In den Warenkorb" niemals ausführen nicht gescheitert). Ich wusste auch zu schätzen, dass die Entwickler die Datenintegrität geopfert haben - und in der Tat alle Funktionen, die dem traditionellen RDBMS eigen sind. Aber schließlich hatte die Firma, mit der ich gesprochen habe, bei der Firma, mit der ich gesprochen habe, keine Priorität. Ehrlich gesagt bedeutete das Projekt, einen großen Rekord pro Tag zu schaffen.

Amazon verkauft viel von allem. Wenn die Funktion "In den Warenkorb" plötzlich nicht mehr funktioniert, verlieren sie viel Geld. Haben Sie ein Problem in der gleichen Reihenfolge?
Diese Firma entschied sich für Cassandra, da es einige Minuten dauerte, bis die betreffende PostgreSQL-Abfrage abgeschlossen war, und sie entschied, dass dies technische Einschränkungen seitens ihrer Hardware waren. Nachdem wir einige Punkte geklärt hatten, stellten wir fest, dass die Tabelle aus ungefähr 50 Millionen Zeilen mit jeweils 80 Bytes bestand. Es würde ungefähr 5 Sekunden dauern, um es von der SSD zu lesen, wenn Sie es vollständig durchgehen müssten. Dies ist langsam, aber immer noch zwei Größenordnungen schneller als die Ausführungsgeschwindigkeit der Abfrage zu diesem Zeitpunkt.
Zu diesem Zeitpunkt hatte ich viele Fragen (U = verstehen, das Problem verstehen!) Und ich begann ungefähr 5 verschiedene Strategien abzuwägen, die das ursprüngliche Problem lösen könnten (N = eNumerieren, einige mögliche Lösungen auflisten!), Aber auf jeden Fall Es war bereits im Moment klar, dass die Verwendung von Cassandra grundsätzlich die falsche Entscheidung war. Alles, was sie brauchten, war ein wenig Geduld beim Einrichten, wahrscheinlich ein neues Design für die Datenbank und möglicherweise (wenn auch unwahrscheinlich) die Wahl einer anderen Technologie ... Aber definitiv kein Schlüsselwertspeicher mit intensiver Aufzeichnung dass Amazon für ihren Warenkorb erstellt!
Sie sind nicht LinkedIn
Ich war sehr überrascht, dass ein Studenten-Startup beschlossen hat, seine Architektur um Kafka herum aufzubauen. Das war unglaublich. Soweit ich das beurteilen konnte, wurden in ihrem Geschäft nur wenige Dutzend sehr große Operationen pro Tag durchgeführt. Vielleicht ein paar hundert an den erfolgreichsten Tagen. Mit dieser Bandbreite könnte das Haupt-Data-Warehouse handschriftliche Einträge in einem normalen Buch sein.
Denken Sie zum Vergleich daran, dass Kafka für alle Analyseereignisse auf LinkedIn erstellt wurde. Dies ist nur eine enorme Datenmenge. Noch vor ein paar Jahren waren es täglich etwa 1 Billion Ereignisse mit einer Spitzenlast von 10 Millionen Nachrichten pro Sekunde. Natürlich verstehe ich, dass Kafka verwendet werden kann, um mit geringeren Lasten zu arbeiten, aber bis zu 10 Bestellungen weniger?

Die Sonne ist ein sehr massives Objekt und nur 6 Größenordnungen schwerer als die Erde.
Vielleicht haben die Entwickler sogar eine bewusste Entscheidung getroffen, basierend auf den erwarteten Bedürfnissen und einem guten Verständnis des Zwecks von Kafka. Aber ich denke, dass sie eher von der (normalerweise gerechtfertigten) Begeisterung der Community für Kafka angetrieben wurden und sich fast nie gefragt haben, ob dies wirklich das Werkzeug war, das sie brauchten. Stellen Sie sich vor ... 10 Bestellungen!
Habe ich das schon gesagt Du bist nicht Amazon
Noch beliebter als das verteilte Data Warehouse von Amazon ist der Ansatz der Architekturentwicklung, der ihnen Skalierbarkeit verliehen hat: eine serviceorientierte Architektur. Wie Werner Vogels in einem Interview mit Jim Gray aus dem Jahr 2006 feststellte, stellte Amazon 2001 fest, dass sie Schwierigkeiten hatten, den Front-End-Teil zu skalieren, und dass eine serviceorientierte Architektur ihnen helfen könnte. Diese Idee infizierte einen Entwickler nach dem anderen, während Startups, die nur aus wenigen Entwicklern und fast keinen Kunden bestanden, ihre Software nicht in Nanoservices aufteilten.
Als Amazon sich entschied, auf SOA (Service-orientierte Architektur) umzusteigen, beschäftigte Amazon rund 7.800 Mitarbeiter und erzielte einen Umsatz von über 3 Milliarden US-Dollar .

Das Bill Graham Auditorium in der Konzerthalle in San Francisco bietet Platz für 7.000 Personen. Amazon hatte rund 7.800 Mitarbeiter, als sie zu SOA wechselten.
Dies bedeutet nicht, dass Sie den Übergang zu SOA verschieben sollten, bis Ihr Unternehmen das Niveau von 7800 Mitarbeitern erreicht hat. Denken Sie einfach immer mit Ihrem eigenen Kopf . Ist das wirklich die beste Lösung für Ihre Aufgabe? Was genau ist die Aufgabe vor Ihnen und gibt es andere Möglichkeiten, sie zu lösen?
Wenn Sie mir sagen, dass die Arbeit Ihrer Organisation, die aus 50 Entwicklern besteht, einfach ohne SOA endet, habe ich mich gefragt, warum so viele große Unternehmen einfach wunderbar mit einer einzigen, aber gut organisierten Anwendung arbeiten.
Auch Google ist nicht Google.
Beispiele für die Verwendung von Systemen zur Verarbeitung hoch geladener Datenströme (Hadoop oder Spark) können wirklich verwirrend sein. Sehr oft sind herkömmliche DBMS besser für die Auslastung geeignet, und manchmal ist die Datenmenge so gering, dass sogar der verfügbare Speicher für sie ausreicht. Wussten Sie, dass Sie 1 TB RAM irgendwo für 10.000 US-Dollar kaufen können? Selbst wenn Sie eine Milliarde Benutzer hätten, könnten Sie jedem von ihnen 1 KB RAM zur Verfügung stellen.
Möglicherweise reicht dies für Ihre Last nicht aus, da Sie lesen und auf die Festplatte schreiben müssen. Aber brauchen Sie wirklich mehrere tausend Festplatten zum Lesen und Schreiben? Hier ist, wie viele Daten Sie tatsächlich haben? GFS und MapReduce wurden erstellt, um Computerprobleme im Internet zu lösen, um beispielsweise den Suchindex im gesamten Internet neu zu berechnen.
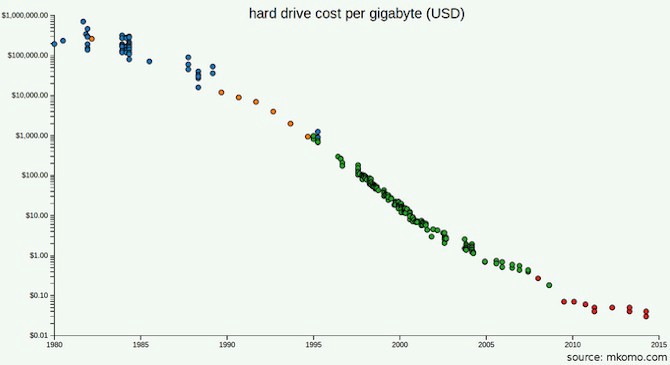
Die Preise für Festplatten sind jetzt viel niedriger als 2003, als die GFS-Dokumentation veröffentlicht wurde.
Vielleicht haben Sie die GFS- und MapReduce-Dokumentation gelesen und festgestellt, dass eines der Probleme für Google nicht die Datenmenge, sondern die Bandbreite (Verarbeitungsgeschwindigkeit) war: Sie verwendeten verteilten Speicher, da die Übertragung von Bytes von den Festplatten zu lange dauerte. Aber wie groß wird die Bandbreite der Geräte sein, die Sie in diesem Jahr verwenden werden? Wäre es besser, einfach modernere Laufwerke zu kaufen, da Sie nicht einmal so viele Geräte benötigen, wie Google benötigt? Wie viel kostet die Verwendung einer SSD?
Vielleicht möchten Sie die Skalierbarkeit im Voraus berücksichtigen. Haben Sie bereits alle notwendigen Berechnungen durchgeführt? Werden Sie Daten schneller sammeln, als die SSD-Preise sinken? Wie oft muss Ihr Unternehmen wachsen, damit nicht mehr alle verfügbaren Daten auf ein Gerät passen? Ab 2016 verarbeitete Stack Exchange 200 Millionen Abfragen pro Tag mit Unterstützung für nur 4 SQL-Server : den Haupt- Server für Stack Overflow, einen weiteren für alles andere und zwei Kopien.
Auch hier können Sie auf UNPHAT zurückgreifen und sich dennoch für Hadoop oder Spark entscheiden. Und die Entscheidung kann sogar richtig sein. Die Hauptsache ist, dass Sie wirklich die richtige Technologie verwenden, um Ihr Problem zu lösen . Dies ist übrigens bei Google bekannt: Als sie entschieden, dass MapReduce nicht für die Indizierung geeignet ist, haben sie die Verwendung eingestellt.
Das Wichtigste zuerst, verstehe das Problem
Meine Botschaft ist vielleicht nichts Neues, aber sie kann in dieser Form auf Sie antworten, oder es fällt Ihnen einfach, sich an UNPHAT zu erinnern und sie im Leben anzuwenden. Wenn nicht, können Sie Rich Hickeys Vortrag bei der Hammock Driven Development oder Pauls Buch " How to Solve it" oder Hammings "The Art of Doing Science and Engineering" sehen . Denn die Hauptsache, die wir alle fragen, ist zu denken!
Und verstehe wirklich das Problem, das du zu lösen versuchst. In den inspirierenden Worten von Paulus:
„ Es ist dumm, eine Frage zu beantworten, die Sie nicht verstehen. Es ist traurig, ein Ziel anzustreben, das Sie nicht erreichen möchten. "
Russische Übersetzung
Übersetzung: Alexander Tregubov
Herausgegeben von Alexey Ivanov (@ponchiknews)
Community: @ponchiknews
Abbildung: LucidChart Content Team