Ein guter Taxibuchungsservice sollte sicher, zuverlässig und schnell sein. Der Benutzer wird nicht auf Details eingehen: Es ist wichtig, dass er auf die Schaltfläche Bestellen klickt und so schnell wie möglich ein Auto erhält, das ihn von Punkt A nach Punkt B bringt. Wenn sich keine Autos in der Nähe befinden, sollte der Dienst dies unverzüglich mitteilen, damit der Kunde dies nicht tut entwickelte falsche Erwartungen. Wenn das Schild „Keine Autos“ zu oft angezeigt wird, ist es logisch, dass eine Person diesen Dienst einfach nicht mehr nutzt und zu einem Konkurrenten geht.
In diesem Artikel möchte ich darüber sprechen, wie wir mit Hilfe des maschinellen Lernens das Problem gelöst haben, Autos in einem Gebiet mit geringer Dichte zu finden (mit anderen Worten, wo es auf den ersten Blick keine Autos gibt). Und was kam daraus?
Hintergrund
Um ein Taxi zu rufen, macht der Benutzer ein paar einfache Schritte, und was passiert in den Eingeweiden des Dienstes?
Über
ETA im Pin haben wir bereits die
Berechnung des Preises und die
Wahl des am besten geeigneten Fahrers geschrieben . Und dies ist eine Geschichte über das Finden von Fahrern. Wenn eine Bestellung erstellt wird, erfolgt die Suche zweimal: auf der PIN und auf der Bestellung. Die Suche nach der Bestellung erfolgt in zwei Schritten: Rekrutierung von Kandidaten und Ranking. Erstens gibt es freie Kandidaten, die entlang des Straßengraphen kommen. Dann werden Boni und Filter angewendet. Die verbleibenden Kandidaten werden eingestuft und der Gewinner erhält ein Angebot der Bestellung. Wenn er zustimmt, wird er der Bestellung zugeordnet und geht zum Lieferort. Wenn er sich weigert, kommt das Angebot zum nächsten. Wenn keine Kandidaten mehr vorhanden sind, wird die Suche erneut gestartet. Dies dauert nicht länger als drei Minuten. Danach wird die Bestellung storniert - ausgebrannt.
Die Suche auf der PIN ähnelt der Suche auf der Bestellung, nur die Bestellung wird nicht erstellt und die Suche selbst wird nur einmal durchgeführt. Außerdem werden vereinfachte Einstellungen für die Anzahl der Kandidaten und den Radius der Suche verwendet. Solche Vereinfachungen sind erforderlich, da es eine Größenordnung mehr Stifte als Ordnungen gibt und die Suche eine ziemlich schwierige Operation ist.
Der entscheidende Moment für unsere Geschichte: Wenn es bei der vorläufigen Suche auf der Stecknadel keine geeigneten Kandidaten gab, erlauben wir keine Bestellung. Zumindest war es früher so.
Folgendes hat der Benutzer in der Anwendung gesehen:
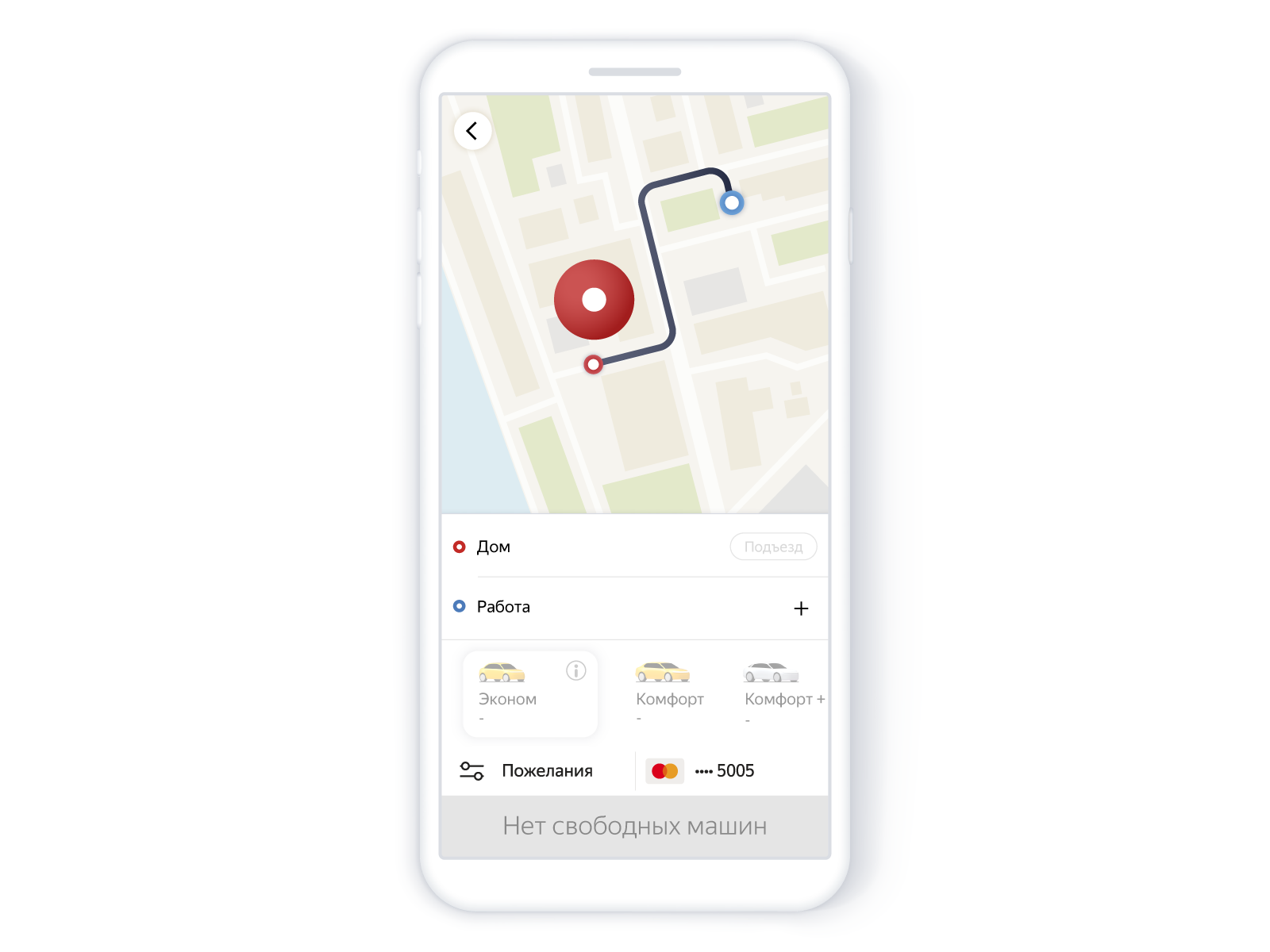
Suche nach Autos ohne Autos
Sobald wir eine Hypothese hatten: Vielleicht kann die Bestellung in einigen Fällen noch abgeschlossen werden, selbst wenn keine Autos auf dem Stift waren. In der Tat vergeht einige Zeit zwischen der PIN und der Bestellung, und die Suche in der Bestellung ist vollständiger und wird manchmal mehrmals wiederholt: Während dieser Zeit werden möglicherweise freie Treiber angezeigt. Wir wussten auch das Gegenteil: Wenn Fahrer an einer Stecknadel gefunden wurden, ist es keine Tatsache, dass sie bei der Bestellung gefunden werden. Manchmal verschwinden sie oder alle lehnen die Bestellung ab.
Um diese Hypothese zu testen, haben wir ein Experiment gestartet: Wir haben aufgehört, während einer PIN-Suche nach einer Testgruppe von Benutzern auf das Vorhandensein von Maschinen zu prüfen, dh sie hatten die Möglichkeit, eine „Bestellung ohne Maschinen“ aufzugeben. Das Ergebnis war ziemlich unerwartet:
Wenn das Auto nicht auf dem Stift stand, war es in 29% der Fälle später - bei der Suche nach einer Bestellung! Darüber hinaus unterschieden sich Bestellungen ohne Autos in Bezug auf Stornierungsraten, Bewertungen und andere Qualitätsindikatoren nicht wesentlich von den üblichen. Die Anzahl der Bestellungen ohne Auto betrug 5% aller Bestellungen, aber etwas mehr als 1% aller erfolgreichen Reisen.
Um zu verstehen, woher die Ausführenden dieser Befehle kommen, schauen wir uns ihren Status während der Suche auf der PIN an:
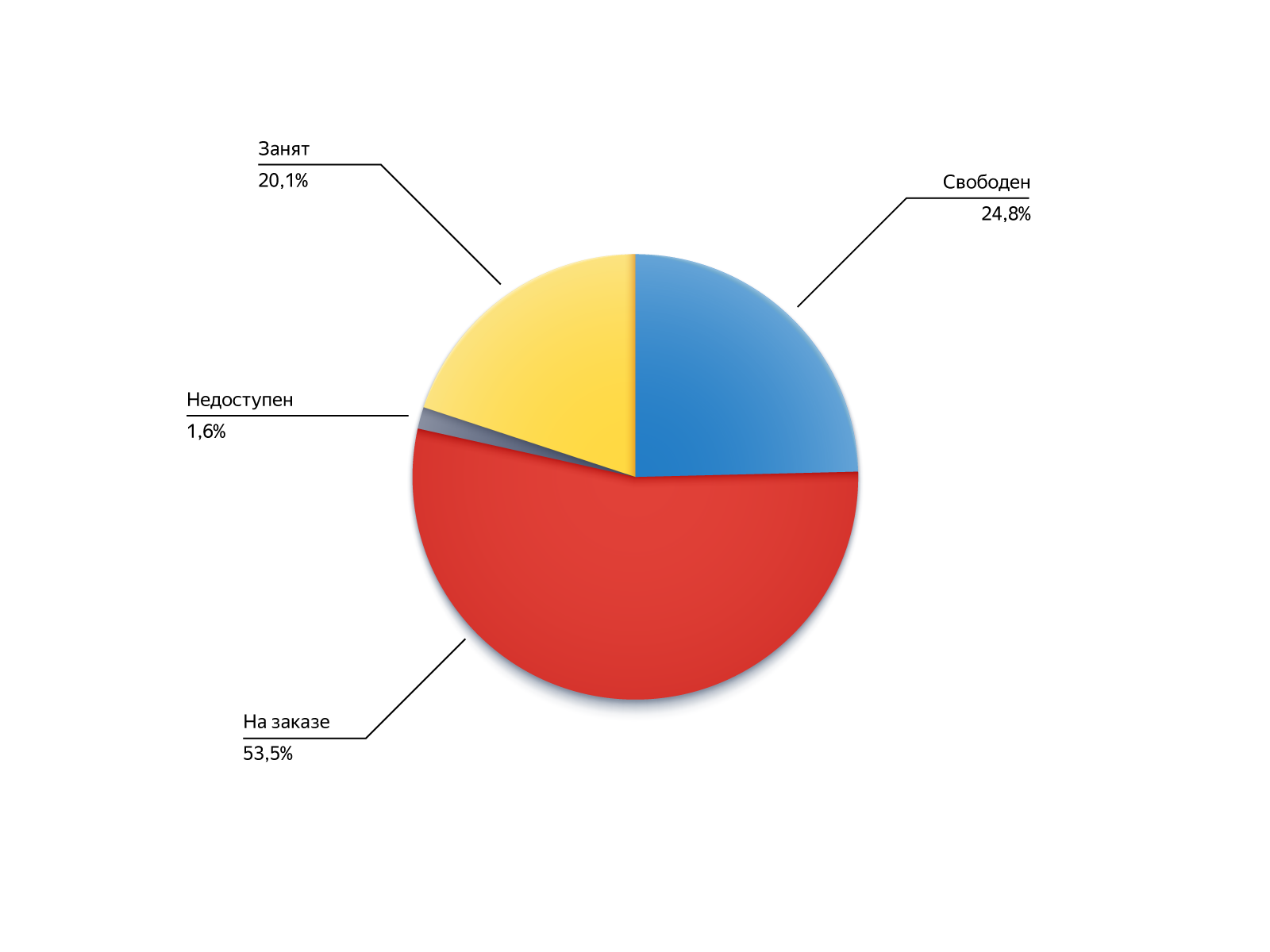
- Kostenlos: war verfügbar, kam aber aus irgendeinem Grund nicht in die Kandidaten, war zum Beispiel zu weit weg;
- Auf Bestellung: Er war beschäftigt, konnte sich aber befreien oder für Bestellungen entlang der Kette verfügbar werden.
- Besetzt: Die Möglichkeit, Bestellungen entgegenzunehmen, war deaktiviert, aber der Fahrer kehrte zur Leitung zurück.
- Nicht verfügbar: Der Fahrer war nicht online, aber er erschien.
Fügen Sie Zuverlässigkeit hinzu
Zusätzliche Bestellungen sind großartig, aber 29% der erfolgreichen Suchanfragen bedeuten, dass der Benutzer in 71% der Fälle lange gewartet hat und daher nirgendwo abgereist ist. Unter dem Gesichtspunkt der Systemeffizienz ist dies zwar nicht schrecklich, aber tatsächlich erhält der Benutzer falsche Hoffnung und verbringt Zeit, woraufhin er verärgert ist und (möglicherweise) die Nutzung des Dienstes einstellt. Um dieses Problem zu lösen, haben wir gelernt, die Wahrscheinlichkeit vorherzusagen, mit der eine Maschine in der Bestellung gefunden wird.
Das Schema ist wie folgt:
- Der Benutzer steckt eine Stecknadel.
- Suche auf dem Pin.
- Wenn es keine Autos gibt, sagen wir voraus: Vielleicht erscheinen sie.
- Und je nach Wahrscheinlichkeit geben wir einen Befehl oder geben ihn nicht, aber wir warnen, dass die Dichte der Autos in diesem Bereich derzeit gering ist.
In der Anwendung sah es so aus:
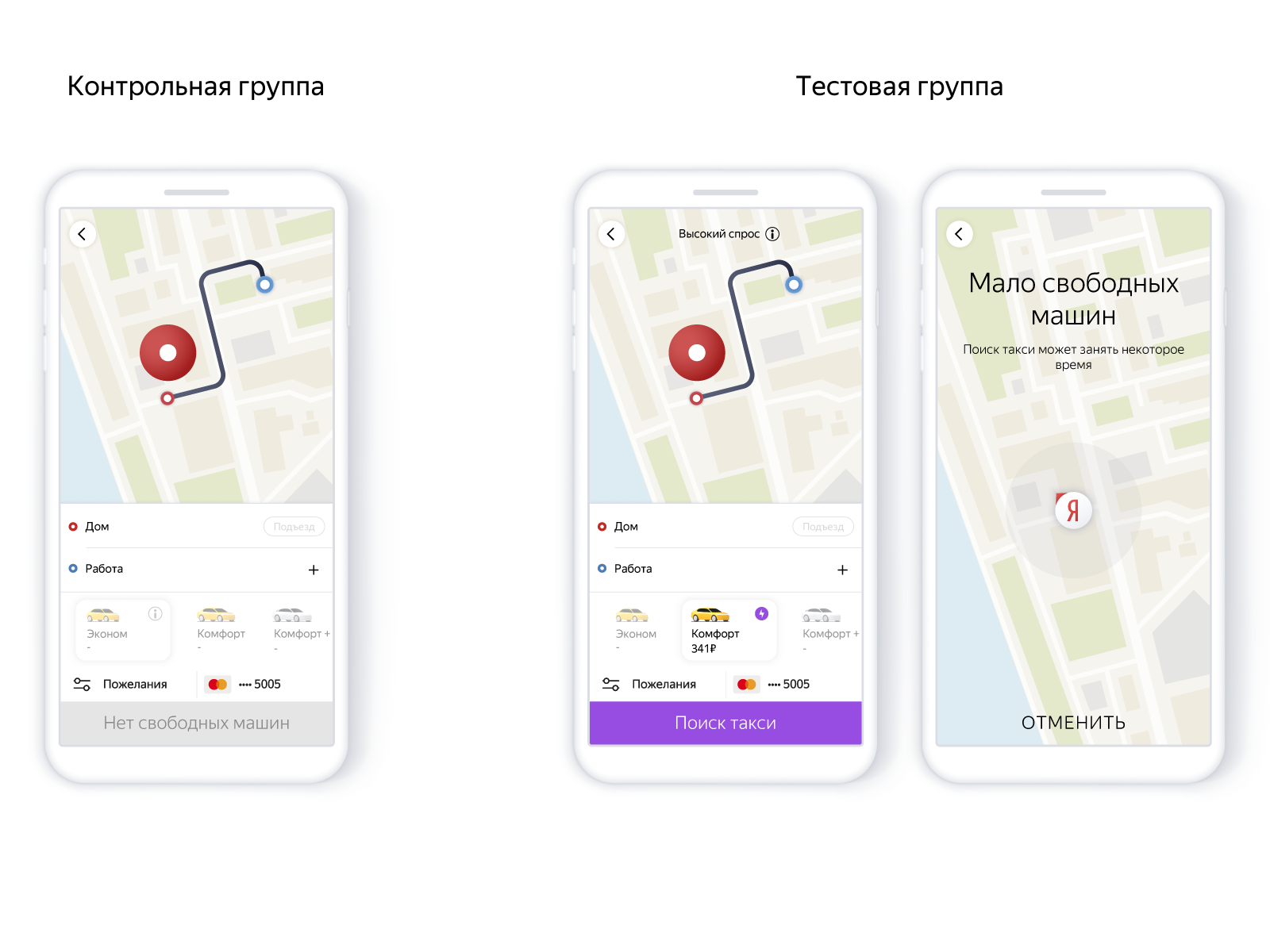
Mit dem Modell können Sie sorgfältig neue Aufträge erstellen und eine Person nicht umsonst beruhigen. Das heißt, das Verhältnis von Zuverlässigkeit und Anzahl der Bestellungen ohne Maschinen mithilfe des Präzisionsrückrufmodells anzupassen. Die Zuverlässigkeit des Dienstes beeinflusst den Wunsch, das Produkt weiterhin zu verwenden, d. H. Letztendlich kommt es auf die Anzahl der Fahrten an.
Ein bisschen über PräzisionsrückrufEine der grundlegenden Aufgaben beim maschinellen Lernen ist das Klassifizierungsproblem: Ordnen Sie ein Objekt einer von zwei Klassen zu. In diesem Fall wird das Ergebnis der Operation des Algorithmus für maschinelles Lernen häufig zu einer numerischen Schätzung der Zugehörigkeit zu einer der Klassen, beispielsweise einer Wahrscheinlichkeitsschätzung. Die ausgeführten Aktionen sind jedoch normalerweise binär: Wenn wir ein Auto haben, geben wir es auf Bestellung, und wenn nicht, dann nein. Der Bestimmtheit halber nennen wir das Modell einen Algorithmus, der eine numerische Schätzung erzeugt, und den Klassifikator - eine Regel, die sich auf eine von zwei Klassen bezieht (1 oder –1). Um einen Klassifikator basierend auf der Bewertung des Modells zu erstellen, müssen Sie einen Bewertungsschwellenwert auswählen. Wie genau - hängt stark von der Aufgabe ab.
Angenommen, wir führen einen Test (Klassifikator) für eine seltene und gefährliche Krankheit durch. Basierend auf den Testergebnissen schicken wir den Patienten entweder zu einer detaillierteren Untersuchung oder sagen: „Gesund, geh nach Hause.“ Für uns ist es viel schlimmer, eine kranke Person nach Hause zu schicken, als eine gesunde Person vergeblich zu untersuchen. Das heißt, wir möchten, dass der Test für so viele wirklich kranke Menschen wie möglich funktioniert. Dieser Wert wird als Rückruf = bezeichnet
. Der ideale Klassifikatorrückruf ist 100%. Eine entartete Situation besteht darin, alle zur Untersuchung zu schicken, dann beträgt der Rückruf ebenfalls 100%.
Es passiert und umgekehrt. Zum Beispiel stellen wir ein Testsystem für Schüler her, das über einen Betrugsdetektor verfügt. Wenn eine Überprüfung in einigen Fällen von Betrug plötzlich nicht mehr funktioniert, ist dies unangenehm, aber nicht kritisch. Andererseits ist es äußerst schlimm, die Schüler zu Unrecht für das zu beschuldigen, was sie nicht getan haben. Das heißt, es ist für uns wichtig, dass es unter den positiven Antworten des Klassifikators so viele richtige wie möglich gibt, möglicherweise zum Nachteil ihrer Anzahl. Sie müssen also die Präzision maximieren =
. Wenn Operationen an allen Objekten beginnen, entspricht die Genauigkeit der Häufigkeit der bestimmten Klasse in der Stichprobe.
Wenn der Algorithmus einen numerischen Wahrscheinlichkeitswert angibt, können Sie durch Auswahl unterschiedlicher Schwellenwerte unterschiedliche Werte für den Präzisionsrückruf erzielen.
In unserer Aufgabe ist die Situation wie folgt. Rückruf ist die Anzahl der Bestellungen, die wir anbieten können. Präzision ist die Zuverlässigkeit dieser Bestellungen. Hier ist die Präzisionsrückrufkurve unseres Modells:
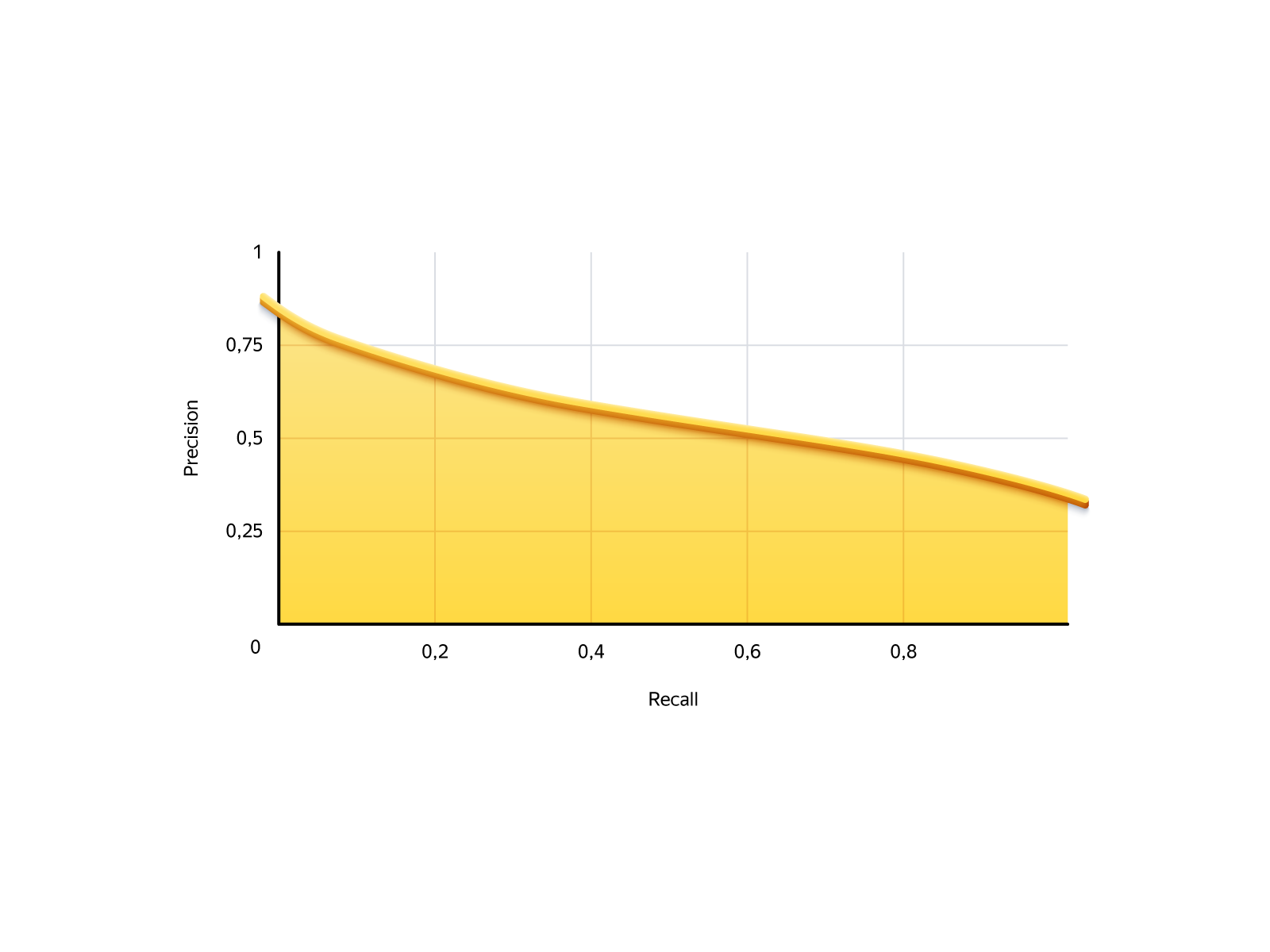
Es gibt zwei extreme Fälle: Lassen Sie niemanden bestellen und lassen Sie jeden bestellen. Wenn Sie niemandem erlauben, ist der Rückruf 0: Wir erstellen keine Aufträge, aber keiner von ihnen schlägt fehl. Wenn Sie alle zulassen, beträgt der Rückruf 100% (wir erhalten alle möglichen Bestellungen) und die Genauigkeit 29%, d. H. 71% der Bestellungen werden sich als schlecht herausstellen.
Als Zeichen haben wir verschiedene Parameter des Ausgangspunkts verwendet:
- Zeit / Ort.
- Systemstatus (Anzahl der belegten Autos aller Tarife und Pins in der Nähe).
- Suchparameter (Radius, Anzahl der Kandidaten, Einschränkungen).
Details zu den Symptomen
Konzeptionell wollen wir zwischen zwei Situationen unterscheiden:
- "Toter Wald" - derzeit gibt es hier keine Autos.
- "Pech" - es gibt Autos, aber es gab keine geeigneten bei der Suche.
Ein Beispiel für „Pech“ ist, wenn am Freitagabend im Zentrum eine hohe Nachfrage besteht. Es gibt viele Aufträge, es gibt viele, die viel wollen, es gibt überhaupt nicht genug Fahrer. Dies kann folgendermaßen geschehen: Der Pin enthält keine geeigneten Treiber. Aber buchstäblich in Sekunden erscheinen sie, denn zu diesem Zeitpunkt gibt es an diesem Ort viele Fahrer und ihr Status ändert sich ständig.
Daher erwiesen sich verschiedene Merkmale des Systems in der Nähe von Punkt A als gute Merkmale:
- Die Gesamtzahl der Autos.
- Die Anzahl der bestellten Autos.
- Die Anzahl der Maschinen, die im Status "Besetzt" nicht für Bestellungen verfügbar sind.
- Die Anzahl der Benutzer.
Denn je mehr Autos in der Nähe sind, desto wahrscheinlicher ist es, dass eines von ihnen verfügbar wird.
Tatsächlich ist es für uns wichtig, nicht nur Autos zu haben, sondern auch erfolgreiche Reisen zu unternehmen. Daher war es möglich, die Wahrscheinlichkeit einer erfolgreichen Reise vorherzusagen. Wir haben uns jedoch dagegen entschieden, da dieser Wert stark vom Benutzer und Treiber abhängt.
CatBoost wurde als Modelllernalgorithmus verwendet. Für das Training verwendeten wir Daten aus dem Experiment. Nach der Implementierung war es notwendig, Trainingsdaten zu sammeln, damit manchmal eine kleine Anzahl von Benutzern eine Bestellung aufgeben konnte, die der Entscheidung des Modells widersprach.
Zusammenfassung
Die Ergebnisse des Experiments erwiesen sich als zu erwarten: Die Verwendung des Modells ermöglicht es, die Anzahl erfolgreicher Fahrten aufgrund von Bestellungen ohne Autos erheblich zu erhöhen und gleichzeitig die Zuverlässigkeit nicht zu beeinträchtigen.
Derzeit wird der Mechanismus in allen Städten und Ländern eingeführt, und damit finden etwa 1% der erfolgreichen Reisen statt. Darüber hinaus erreicht in einigen Städten mit einer geringen Autodichte der Anteil solcher Fahrten 15%.
Andere Taxi-Technologie-Beiträge