Fehler und Software gingen seit Beginn der Ära der Computerprogrammierung Hand in Hand. Im Laufe der Zeit haben Entwickler eine Reihe von Methoden zum Testen und Debuggen von Programmen entwickelt, bevor diese bereitgestellt werden. Diese Methoden eignen sich jedoch nicht mehr für moderne Systeme mit tiefem Lernen. Heutzutage kann die Hauptpraxis im Bereich des maschinellen Lernens als Training für einen bestimmten Datensatz bezeichnet werden, gefolgt von einer Überprüfung für einen anderen Datensatz. Auf diese Weise können Sie den durchschnittlichen Wirkungsgrad der Modelle berechnen. Es ist jedoch auch wichtig, die Zuverlässigkeit zu gewährleisten, dh im schlimmsten Fall einen akzeptablen Wirkungsgrad. In diesem Artikel beschreiben wir drei Ansätze zur genauen Identifizierung und Beseitigung von Fehlern in trainierten Vorhersagemodellen: kontradiktorische Tests, robustes Lernen und
formale Verifizierung .
Systeme mit MOs sind per Definition nicht stabil. Selbst Systeme, die gegen eine Person in einem bestimmten Bereich gewinnen, sind möglicherweise nicht in der Lage, die Lösung einfacher Probleme zu bewältigen, wenn subtile Unterschiede vorgenommen werden. Betrachten Sie zum Beispiel das Problem der Bildstörung: Ein neuronales Netzwerk, das Bilder besser klassifizieren kann als Menschen, kann leicht zu der Annahme gebracht werden, dass es sich bei dem Faultier um einen Rennwagen handelt, der dem Bild einen kleinen Teil des sorgfältig berechneten Rauschens hinzufügt.
 Konkurrierende Eingaben, wenn sie einem normalen Bild überlagert werden, können die KI verwirren. Zwei extreme Bilder unterscheiden sich für jedes Pixel um nicht mehr als 0,0078. Die erste wird mit einer Wahrscheinlichkeit von 99% als Faultier eingestuft. Der zweite ist wie ein Rennwagen mit einer Wahrscheinlichkeit von 99%.
Konkurrierende Eingaben, wenn sie einem normalen Bild überlagert werden, können die KI verwirren. Zwei extreme Bilder unterscheiden sich für jedes Pixel um nicht mehr als 0,0078. Die erste wird mit einer Wahrscheinlichkeit von 99% als Faultier eingestuft. Der zweite ist wie ein Rennwagen mit einer Wahrscheinlichkeit von 99%.Dieses Problem ist nicht neu. Programme hatten immer Fehler. Seit Jahrzehnten verfügen Programmierer über eine beeindruckende Reihe von Techniken, von Unit-Tests bis hin zur formalen Verifizierung. Bei herkömmlichen Programmen funktionieren diese Methoden gut, aber die Anpassung dieser Ansätze für strenge Tests von MO-Modellen ist aufgrund des Maßstabs und der fehlenden Struktur in Modellen, die Hunderte von Millionen von Parametern enthalten können, äußerst schwierig. Dies legt die Notwendigkeit nahe, neue Ansätze zu entwickeln, um die Zuverlässigkeit von MO-Systemen sicherzustellen.
Aus Sicht des Programmierers ist ein Fehler jedes Verhalten, das nicht der Spezifikation entspricht, dh der geplanten Funktionalität des Systems. Im Rahmen unserer KI-Forschung untersuchen wir Techniken, um zu bewerten, ob MO-Systeme die Anforderungen nicht nur an die Trainings- und Testsätze, sondern auch an die Liste der Spezifikationen erfüllen, die die gewünschten Eigenschaften des Systems beschreiben. Unter diesen Eigenschaften kann es Beständigkeit gegen ausreichend kleine Änderungen der Eingabedaten, Sicherheitsbeschränkungen, die katastrophale Ausfälle verhindern, oder die Einhaltung von Vorhersagen mit den Gesetzen der Physik geben.
In diesem Artikel werden drei wichtige technische Probleme erörtert, mit denen die MO-Community konfrontiert ist, wenn es darum geht, die MO-Systeme robust zu machen und zuverlässig den gewünschten Spezifikationen zu entsprechen:
- Effektive Überprüfung der Einhaltung der Spezifikationen. Wir untersuchen effektive Methoden, um zu überprüfen, ob MO-Systeme ihren Eigenschaften entsprechen (z. B. Stabilität und Invarianz), die vom Entwickler und den Benutzern von ihnen verlangt werden. Ein Ansatz, um Fälle zu finden, in denen sich ein Modell von diesen Eigenschaften entfernen kann, besteht darin, systematisch nach den schlechtesten Arbeitsergebnissen zu suchen.
- Schulung von MO-Modellen gemäß den Spezifikationen. Selbst wenn eine ausreichend große Menge an Trainingsdaten vorhanden ist, können Standard-MO-Algorithmen Vorhersagemodelle erzeugen, deren Betrieb nicht den gewünschten Spezifikationen entspricht. Wir müssen die Trainingsalgorithmen so überarbeiten, dass sie nicht nur gut mit den Trainingsdaten funktionieren, sondern auch die gewünschten Spezifikationen erfüllen.
- Formaler Nachweis der Konformität von MO-Modellen mit den gewünschten Spezifikationen. Es müssen Algorithmen entwickelt werden, um zu bestätigen, dass das Modell die gewünschten Spezifikationen für alle möglichen Eingabedaten erfüllt. Obwohl das Gebiet der formalen Verifikation solche Algorithmen trotz seiner beeindruckenden Fortschritte seit mehreren Jahrzehnten untersucht, sind diese Ansätze nicht einfach auf moderne MO-Systeme zu skalieren.
Überprüfen Sie die Modellkonformität mit den gewünschten Spezifikationen
Der Widerstand gegen Wettbewerbsbeispiele ist ein ziemlich gut untersuchtes Problem des Zivilschutzes. Eine der wichtigsten Schlussfolgerungen ist die Bedeutung der Bewertung der Aktionen des Netzwerks als Ergebnis starker Angriffe und die Entwicklung transparenter Modelle, die sehr effektiv analysiert werden können. Wir haben zusammen mit anderen Forschern festgestellt, dass sich viele Modelle als resistent gegen schwache, wettbewerbsfähige Beispiele erweisen. Sie bieten jedoch eine Genauigkeit von fast 0% für stärkere Wettbewerbsbeispiele (
Athalye et al., 2018 ,
Uesato et al., 2018 ,
Carlini und Wagner, 2017 ).
Obwohl sich die meisten Arbeiten auf seltene Fehler im Kontext des Unterrichts mit einem Lehrer konzentrieren (und dies ist hauptsächlich eine Klassifizierung von Bildern), besteht die Notwendigkeit, die Anwendung dieser Ideen auf andere Bereiche auszudehnen. In einer kürzlich durchgeführten Arbeit mit einem wettbewerbsorientierten Ansatz zur Aufdeckung katastrophaler Ausfälle wenden wir diese Ideen auf Testnetzwerke an, die mit Verstärkung geschult und für den Einsatz an Orten mit hohen Sicherheitsanforderungen ausgelegt sind. Eine der Herausforderungen bei der Entwicklung autonomer Systeme besteht darin, dass, da ein Fehler schwerwiegende Folgen haben kann, selbst eine geringe Ausfallwahrscheinlichkeit nicht als akzeptabel angesehen wird.
Unser Ziel ist es, einen „Rivalen“ zu entwickeln, der hilft, solche Fehler im Voraus zu erkennen (in einer kontrollierten Umgebung). Wenn ein Gegner die schlechtesten Eingabedaten für ein bestimmtes Modell effektiv ermitteln kann, können wir seltene Fehlerfälle erkennen, bevor wir es bereitstellen. Wie bei Bildklassifizierern vermittelt die Bewertung der Arbeit mit einem schwachen Gegner ein falsches Sicherheitsgefühl während der Bereitstellung. Dieser Ansatz ähnelt der Softwareentwicklung mit Hilfe des „roten Teams“ (Red-Teaming), an dem ein Drittanbieter-Entwicklungsteam beteiligt ist, das die Rolle von Angreifern übernimmt, um Schwachstellen zu erkennen. transl.] geht jedoch über die Suche nach durch Eindringlinge verursachten Fehlern hinaus und umfasst auch Fehler, die natürlich auftreten, beispielsweise aufgrund unzureichender Verallgemeinerung.
Wir haben zwei komplementäre Ansätze für Wettbewerbstests von verstärkten Lernnetzwerken entwickelt. Im ersten Fall verwenden wir die derivatfreie Optimierung, um die erwartete Belohnung direkt zu minimieren. Im zweiten Teil lernen wir eine Funktion des gegnerischen Werts, die erfahrungsgemäß vorhersagt, in welchen Situationen das Netzwerk ausfallen kann. Dann verwenden wir diese erlernte Funktion zur Optimierung und konzentrieren uns auf die Auswertung der problematischsten Eingabedaten. Diese Ansätze machen nur einen kleinen Teil des reichen und wachsenden Raums potenzieller Algorithmen aus, und wir sind sehr an der zukünftigen Entwicklung dieses Bereichs interessiert.
Beide Ansätze zeigen bereits signifikante Verbesserungen gegenüber zufälligen Tests. Mit unserer Methode können in wenigen Minuten Fehler
erkannt werden, nach denen zuvor den ganzen Tag gesucht werden musste oder die möglicherweise gar nicht gefunden wurden (
Uesato et al., 2018b ). Wir fanden auch heraus, dass Wettbewerbstests ein qualitativ anderes Verhalten von Netzwerken aufzeigen können als das, was von einer Bewertung eines zufälligen Testsatzes erwartet werden könnte. Insbesondere haben wir mit unserer Methode festgestellt, dass Netzwerke, die die Orientierungsaufgabe auf einer dreidimensionalen Karte ausgeführt haben und dies normalerweise auf menschlicher Ebene bewältigen, das Ziel in unerwartet einfachen Labyrinthen nicht finden können (
Ruderman et al., 2018 ). Unsere Arbeit betont auch die Notwendigkeit, Systeme zu entwickeln, die vor natürlichen Fehlern geschützt sind und nicht nur Konkurrenten.
 Bei Tests mit Zufallsstichproben sehen wir fast nie Karten mit einer hohen Ausfallwahrscheinlichkeit, aber Wettbewerbstests zeigen die Existenz solcher Karten. Die Ausfallwahrscheinlichkeit bleibt auch nach dem Entfernen vieler Wände hoch, dh der Vereinfachung der Karten im Vergleich zu den ursprünglichen.
Bei Tests mit Zufallsstichproben sehen wir fast nie Karten mit einer hohen Ausfallwahrscheinlichkeit, aber Wettbewerbstests zeigen die Existenz solcher Karten. Die Ausfallwahrscheinlichkeit bleibt auch nach dem Entfernen vieler Wände hoch, dh der Vereinfachung der Karten im Vergleich zu den ursprünglichen.Spec Model Training
Wettbewerbstests versuchen, ein Gegenbeispiel zu finden, das gegen Spezifikationen verstößt. Oft wird die Konsistenz von Modellen mit diesen Spezifikationen überschätzt. Aus mathematischer Sicht ist die Spezifikation eine Art Beziehung, die zwischen den Eingabe- und Ausgabedaten des Netzwerks aufrechterhalten werden muss. Dies kann in Form einer oberen und unteren Grenze oder einiger wichtiger Eingabe- und Ausgabeparameter erfolgen.
Inspiriert von dieser Beobachtung haben mehrere Forscher (
Raghunathan et al., 2018 ;
Wong et al., 2018 ;
Mirman et al., 2018 ;
Wang et al., 2018 ), darunter unser Team von DeepMind (
Dvijotham et al., 2018 ;
Gowal et al., 2018 ) arbeiteten an Algorithmen, die für Wettbewerbstests unveränderlich sind. Dies kann geometrisch beschrieben werden - wir können die schlimmste Spezifikationsverletzung begrenzen (
Ehlers 2017 ,
Katz et al. 2017 ,
Mirman et al., 2018 ) und den Ausgabedatenraum basierend auf einer Reihe von Eingaben begrenzen. Wenn diese Grenze durch Netzwerkparameter differenzierbar ist und schnell berechnet werden kann, kann sie während des Trainings verwendet werden. Dann kann sich die ursprüngliche Grenze durch jede Schicht des Netzwerks ausbreiten.
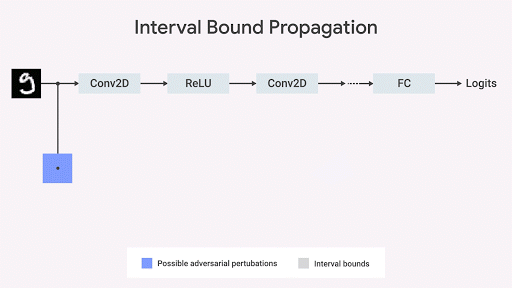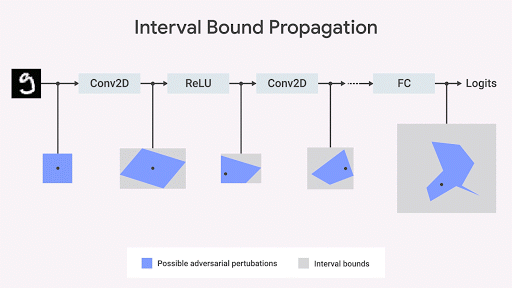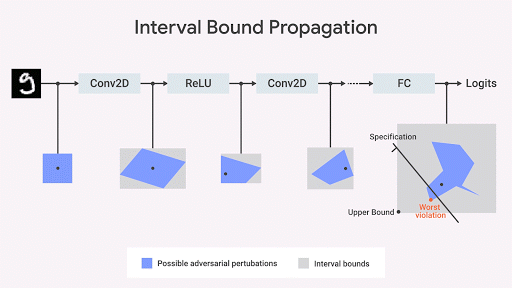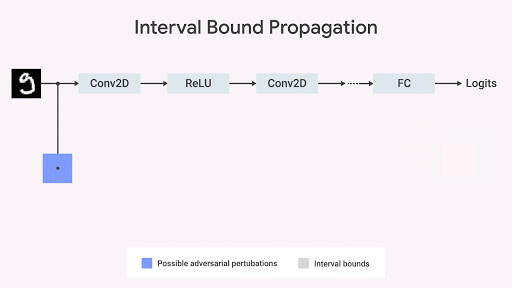
Wir zeigen, dass die Ausbreitung der Grenze des Intervalls schnell und effizient ist und - anders als bisher angenommen - gute Ergebnisse liefert (
Gowal et al., 2018 ). Insbesondere zeigen wir, dass es nachweislich die Anzahl von Fehlern (d. H. Die maximale Anzahl von Fehlern, die jeder Gegner verursachen kann) im Vergleich zu den fortschrittlichsten Bildklassifizierern auf Sätzen aus den MNIST- und CIFAR-10-Datenbanken reduzieren kann.
Das nächste Ziel wird darin bestehen, die richtigen geometrischen Abstraktionen zu untersuchen, um übermäßige Annäherungen an den Ausgaberaum zu berechnen. Wir möchten Netzwerke auch so trainieren, dass sie zuverlässig mit komplexeren Spezifikationen arbeiten, die das gewünschte Verhalten beschreiben, wie z. B. die zuvor erwähnte Invarianz und die Einhaltung physikalischer Gesetze.
Formale Überprüfung
Gründliche Tests und Schulungen können bei der Erstellung zuverlässiger MO-Systeme eine große Hilfe sein. Formell willkürlich umfangreiche Tests können jedoch nicht garantieren, dass das Verhalten des Systems unseren Wünschen entspricht. In großen Modellen scheint es aufgrund der astronomischen Anzahl möglicher Bildänderungen schwierig zu sein, alle möglichen Ausgabeoptionen für einen bestimmten Satz von Eingaben (z. B. geringfügige Bildänderungen) aufzulisten. Wie im Fall des Trainings kann man jedoch effektivere Ansätze finden, um geometrische Einschränkungen für den Satz von Ausgabedaten festzulegen. Die formale Überprüfung ist Gegenstand laufender Forschung bei DeepMind.
Die MO-Community hat einige interessante Ideen zur Berechnung der genauen geometrischen Grenzen des Netzwerkausgaberaums entwickelt (Katz et al. 2017,
Weng et al., 2018 ;
Singh et al., 2018 ). Unser Ansatz (
Dvijotham et al., 2018 ), der auf Optimierung und Dualität basiert, besteht darin, das Verifizierungsproblem in Bezug auf die Optimierung zu formulieren, wobei versucht wird, die größte Verletzung der getesteten Eigenschaft zu finden. Die Aufgabe wird berechenbar, wenn bei der Optimierung Ideen aus der Dualität verwendet werden. Als Ergebnis erhalten wir zusätzliche Einschränkungen, die die Grenzen angeben, die beim Verschieben der Intervallgrenze [Intervallgrenzenausbreitung] unter Verwendung der sogenannten Schnittebenen berechnet werden. Dies ist ein zuverlässiger, aber unvollständiger Ansatz: Es kann Fälle geben, in denen die für uns interessante Eigenschaft erfüllt ist, die von diesem Algorithmus berechnete Grenze jedoch nicht streng genug ist, um das Vorhandensein dieser Eigenschaft formal nachzuweisen. Nach Erhalt der Grenze erhalten wir jedoch eine formelle Garantie für das Fehlen von Verstößen gegen diese Eigenschaft. In Abb. Im Folgenden wird dieser Ansatz grafisch dargestellt.

Dieser Ansatz ermöglicht es uns, die Anwendbarkeit von Verifizierungsalgorithmen auf allgemeinere Netzwerke (Aktivatorfunktionen, Architekturen), allgemeine Spezifikationen und komplexere GO-Modelle (generative Modelle, neuronale Prozesse usw.) und Spezifikationen zu erweitern, die über die Wettbewerbszuverlässigkeit (
Qin ) hinausgehen
, 2018 ).
Perspektiven
Der Einsatz von MOs in Situationen mit hohem Risiko hat seine eigenen Herausforderungen und Schwierigkeiten. Dies erfordert die Entwicklung von Bewertungstechnologien, die garantiert unwahrscheinliche Fehler erkennen. Wir glauben, dass eine konsistente Schulung zu Spezifikationen die Leistung im Vergleich zu Fällen, in denen Spezifikationen implizit aus Schulungsdaten resultieren, erheblich verbessern kann. Wir freuen uns auf die Ergebnisse laufender Wettbewerbsbewertungsstudien, robuster Trainingsmodelle und die Überprüfung formaler Spezifikationen.
Es wird viel mehr Arbeit erforderlich sein, damit wir automatisierte Tools erstellen können, die gewährleisten, dass KI-Systeme in der realen Welt "alles richtig machen". Insbesondere freuen wir uns sehr über Fortschritte in folgenden Bereichen:
- Schulung zur Wettbewerbsbewertung und -verifizierung. Mit der Skalierung und Weiterentwicklung von KI-Systemen wird es immer schwieriger, wettbewerbsfähige Bewertungs- und Verifizierungsalgorithmen zu entwickeln, die ausreichend an das KI-Modell angepasst sind. Wenn wir die volle Leistung der KI zur Bewertung und Verifizierung nutzen können, kann dieser Prozess skaliert werden.
- Entwicklung öffentlich verfügbarer Tools für die Bewertung und Verifizierung des Wettbewerbs: Es ist wichtig, Ingenieuren und anderen KI-Nutzern benutzerfreundliche Tools zur Verfügung zu stellen, die Aufschluss über mögliche Ausfallarten des KI-Systems geben, bevor dieser Ausfall zu erheblichen negativen Folgen führt. Dies erfordert eine gewisse Standardisierung der Wettbewerbsbewertungen und Verifizierungsalgorithmen.
- Erweiterung des Spektrums wettbewerbsfähiger Beispiele. Bisher konzentrierte sich ein Großteil der Arbeit an Wettbewerbsbeispielen auf die Stabilität von Modellen gegenüber kleinen Änderungen, normalerweise im Bildbereich. Dies ist ein hervorragendes Testfeld für die Entwicklung von Ansätzen für Wettbewerbsbewertungen, zuverlässige Schulungen und Verifizierungen. Wir haben begonnen, verschiedene Spezifikationen für Eigenschaften zu untersuchen, die in direktem Zusammenhang mit der realen Welt stehen, und freuen uns auf die Ergebnisse zukünftiger Forschungen in dieser Richtung.
- Schulungsspezifikationen. Spezifikationen, die das „richtige“ Verhalten von KI-Systemen beschreiben, sind oft schwer genau zu formulieren. Da wir immer intelligentere Systeme erstellen, die zu komplexem Verhalten fähig sind und in einer unstrukturierten Umgebung arbeiten, müssen wir lernen, wie Systeme erstellt werden, die teilweise formulierte Spezifikationen verwenden können, und weitere Spezifikationen aus dem Feedback erhalten.
DeepMind setzt sich für positive Auswirkungen auf die Gesellschaft durch die verantwortungsvolle Entwicklung und Bereitstellung von MO-Systemen ein. Um sicherzustellen, dass der Beitrag der Entwickler garantiert positiv ist, müssen wir uns mit vielen technischen Hindernissen befassen. Wir beabsichtigen, einen Beitrag zu diesem Bereich zu leisten, und arbeiten gerne mit der Community zusammen, um diese Probleme zu lösen.