
RabbitMQ ist ein in Erlang geschriebener Nachrichtenbroker, mit dem Sie einen Failovercluster mit vollständiger Datenreplikation auf mehreren Knoten organisieren können, wobei jeder Knoten Lese- und Schreibanforderungen verarbeiten kann. Da viele Kubernetes-Cluster in der Produktion sind, unterstützen wir eine große Anzahl von RabbitMQ-Installationen und müssen Daten ohne Ausfallzeiten von einem Cluster in einen anderen migrieren.
Diese Operation war für uns in mindestens zwei Fällen notwendig:
- Übertragen von Daten von einem RabbitMQ-Cluster, der sich nicht in Kubernetes befindet, zu einem neuen Cluster, der bereits "abgestimmt" ist (dh in K8s-Pods funktioniert).
- Migration von RabbitMQ innerhalb von Kubernetes von einem Namespace in einen anderen (z. B. wenn die Pfade durch Namespaces begrenzt sind, um die Infrastruktur von einem Pfad in einen anderen zu übertragen).
Das in diesem Artikel vorgeschlagene Rezept konzentriert sich auf Situationen (ohne darauf beschränkt zu sein), in denen sich ein alter RabbitMQ-Cluster (z. B. mit 3 Knoten) befindet, der sich entweder in K8s oder auf einigen alten Servern befindet. Eine in Kubernetes gehostete Anwendung funktioniert damit (bereits dort oder in Zukunft):

... und wir stehen vor der Herausforderung, es auf eine neue Produktion in Kubernetes zu migrieren.
Zunächst wird ein allgemeiner Ansatz für die Migration selbst beschrieben und anschließend technische Details zu ihrer Implementierung.
Migrationsalgorithmus
Der erste vorbereitende Schritt vor einer Aktion besteht darin, zu überprüfen, ob der Hochverfügbarkeitsmodus (
HA ) in der alten RabbitMQ-Installation aktiviert ist. Der Grund liegt auf der Hand - wir wollen keine Daten verlieren. Um diese Prüfung durchzuführen, können Sie zum RabbitMQ-Admin-Bereich gehen und auf der Registerkarte Admin → Richtlinien sicherstellen, dass der Wert
ha-mode: all :

Der nächste Schritt besteht darin, einen neuen RabbitMQ-Cluster in Kubernetes-Pods zu erstellen (in unserem Fall beispielsweise bestehend aus 3 Knoten, deren Anzahl jedoch unterschiedlich sein kann).
Danach führen wir den alten und den neuen RabbitMQ-Cluster zusammen und erhalten einen einzelnen Cluster (mit 6 Knoten):
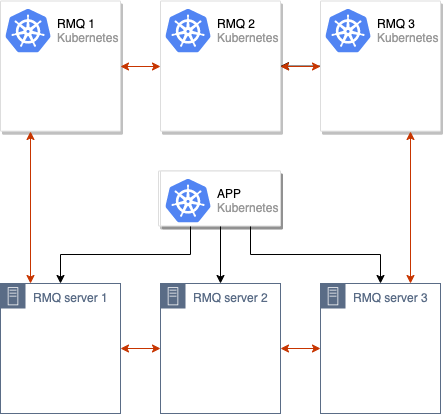
Der Prozess der Synchronisierung von Daten zwischen dem alten und dem neuen RabbitMQ-Cluster wird eingeleitet. Nachdem alle Daten zwischen allen Knoten im Cluster synchronisiert wurden, können wir die Anwendung auf die Verwendung des neuen Clusters umstellen:
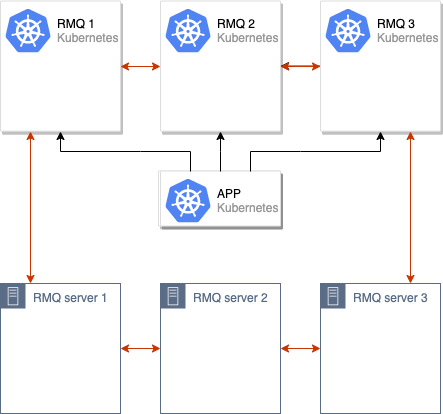
Nach diesen Vorgängen reicht es aus, die alten Knoten aus dem RabbitMQ-Cluster zu entfernen, und der Umzug kann als abgeschlossen betrachtet werden:

Wir haben dieses Schema wiederholt in unserer Produktion verwendet. Zu ihrer eigenen Bequemlichkeit haben wir es jedoch im Rahmen eines speziellen Systems implementiert, das typische RMQ-Konfigurationen auf Gruppen von Kubernetes-Clustern verteilt
(für diejenigen, die neugierig sind: Wir sprechen über den Addon-Operator , über den wir kürzlich gesprochen haben ) . Im Folgenden finden Sie individuelle Anweisungen, die jeder auf seine Installationen anwenden kann, um die vorgeschlagene Lösung in Aktion zu testen.
Wir versuchen es in der Praxis
Anforderungen
Details sind sehr einfach:
- Kubernetes Cluster (Minikube ist auch geeignet);
- RabbitMQ-Cluster (kann auf Bare-Metal-Basis bereitgestellt und als regulärer Cluster in Kubernetes aus der offiziellen Helm-Tabelle erstellt werden).
Für das unten beschriebene Beispiel habe ich RMQ für Kubernetes bereitgestellt und es
rmq-old .
Standvorbereitung
1. Laden Sie das Helm-Diagramm herunter und bearbeiten Sie es ein wenig:
helm fetch --untar stable/rabbitmq-ha
Der
ErlangCookie legen wir ein Kennwort,
ErlangCookie und die
ha-all Richtlinie fest, sodass die Warteschlangen standardmäßig zwischen allen Knoten des RMQ-Clusters synchronisiert werden:
rabbitmqPassword: guest rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we definitions: policies: |- { "name": "ha-all", "pattern": ".*", "vhost": "/", "definition": { "ha-mode": "all", "ha-sync-mode": "automatic", "ha-sync-batch-size": 81920 } }
2. Stellen Sie das Diagramm ein:
helm install . --name rmq-old --namespace rmq-old
3. Gehen Sie zum RabbitMQ-Administrationsbereich, erstellen Sie eine neue Warteschlange und fügen Sie einige Nachrichten hinzu. Sie werden benötigt, damit wir nach der Migration sicherstellen können, dass alle Daten gespeichert wurden und wir nichts verloren haben:

Der Prüfstand ist fertig: Wir haben den "alten" RabbitMQ mit den Daten, die übertragen werden müssen.
RabbitMQ-Cluster-Migration
1.
ErlangCookie den neuen RabbitMQ in einem
anderen Namespace mit
demselben ErlangCookie und Kennwort für den Benutzer
ErlangCookie . Zu diesem Zweck führen wir die oben beschriebenen Vorgänge aus und ändern den endgültigen RMQ-Installationsbefehl wie folgt:
helm install . --name rmq-new --namespace rmq-new
2. Jetzt müssen Sie den neuen Cluster mit dem alten zusammenführen. Gehen Sie dazu zu jedem der Pods des
neuen RabbitMQ und führen Sie die folgenden Befehle aus:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \ rabbitmqctl stop_app && \ rabbitmqctl join_cluster $OLD_RMQ && \ rabbitmqctl start_app
Die Variable
OLD_RMQ Adresse eines der Knoten des
alten RMQ-Clusters.
Diese Befehle stoppen den aktuellen Knoten des
neuen RMQ-Clusters, hängen ihn an den alten Cluster an und starten ihn neu.
3. Der RMQ-Cluster mit 6 Knoten ist bereit:

Sie müssen warten, bis die Nachrichten zwischen allen Knoten synchronisiert sind. Es ist leicht zu erraten, dass die Synchronisationszeit von Nachrichten von der Kapazität des Bügeleisens abhängt, auf dem der Cluster bereitgestellt wird, und von der Anzahl der Nachrichten. In dem beschriebenen Szenario gibt es nur 10 davon, sodass die Daten sofort synchronisiert wurden. Bei einer ausreichend großen Anzahl von Nachrichten kann die Synchronisierung jedoch Stunden dauern.
Also der Synchronisationsstatus:

Hier bedeutet
+5 , dass sich Nachrichten
bereits auf
weiteren 5 Knoten befinden (mit Ausnahme der
Node Feld
Node ). Somit war die Synchronisation erfolgreich.
4. Es bleibt nur, die RMQ-Adresse in der Anwendung auf den neuen Cluster umzustellen (die spezifischen Aktionen hier hängen vom verwendeten Technologie-Stack und anderen Anwendungsspezifikationen ab). Danach können Sie sich von der alten verabschieden.
Für die letzte Operation (d. H.
Nach dem Umschalten der Anwendung auf einen neuen Cluster) gehen wir zu jedem Knoten des
alten Clusters und führen die folgenden Befehle aus:
rabbitmqctl stop_app rabbitmqctl reset
Der Cluster hat die alten Knoten „vergessen“: Sie können den alten RMQ löschen, wodurch die Verschiebung abgeschlossen wird.
Hinweis : Wenn Sie RMQ mit Zertifikaten verwenden, ändert sich im Grunde nichts - der Verschiebevorgang wird genauso ausgeführt.Schlussfolgerungen
Das beschriebene Schema eignet sich für fast alle Fälle, in denen RabbitMQ übertragen oder einfach in einen neuen Cluster verschoben werden muss.
In unserem Fall traten Schwierigkeiten nur einmal auf, wenn von vielen Stellen aus auf RMQ zugegriffen wurde, und wir hatten nicht die Möglichkeit, die RMQ-Adresse überall in eine neue zu ändern. Dann haben wir ein neues RMQ im selben Namespace mit denselben Labels gestartet, sodass es unter die vorhandenen Services und Ingresss fällt. Als wir den Pod gestartet haben, haben wir die Labels mit unseren Händen manipuliert und sie zu Beginn gelöscht, sodass Anforderungen nicht auf ein leeres RMQ fielen Hinzufügen nach der Nachrichtensynchronisation.
Wir haben die gleiche Strategie angewendet, als wir RabbitMQ auf eine neue Version mit einer geänderten Konfiguration aktualisiert haben - alles funktionierte wie eine Uhr.
PS
Als logische Fortsetzung dieses Materials bereiten wir Artikel über MongoDB (Migration von einem Eisenserver zu Kubernetes) und MySQL (eine der Optionen zum "Vorbereiten" dieses DBMS in Kubernetes) vor. Sie werden in den kommenden Monaten veröffentlicht.
PPS
Lesen Sie auch in unserem Blog: