Unser Team hat in kurzer Zeit die Entfernung von einem Dutzend Mitarbeitern zu einer ganzen Einheit von fast 200 Mitarbeitern zurückgelegt, und wir möchten einige Meilensteine auf diesem Weg teilen. Außerdem werden wir diskutieren, wer genau in Big Data gerade benötigt wird und wie hoch die tatsächliche Eintrittsschwelle ist.

Erfolgsrezept in einem neuen Bereich
Die Arbeit mit Big Data ist ein relativ neuer Technologiebereich, der wie alles den Zyklus des Erwachsenwerdens durchläuft, während er sich entwickelt.
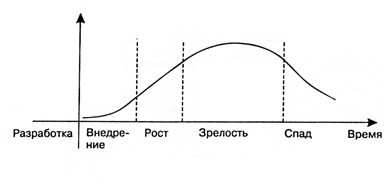
Aus Sicht eines bestimmten Spezialisten hat die Arbeit im technologischen Bereich in jeder Phase dieses Zyklus ihre Vor- und Nachteile.
Phase 1. ImplementierungIn der ersten Phase ist dies die Idee von F & E-Einheiten, die immer noch keinen wirklichen Gewinn erzielen.
Von den Profis: Es wird viel Geld investiert. Mit den Investitionen wachsen auch die Hoffnungen, bisher unzugängliche Aufgaben zu lösen und Investitionen zurückzuzahlen.
Nachteile: Jede Technologie, egal wie vielversprechend sie am Anfang aussehen mag, hat ihre eigenen Einschränkungen: Sie kann nicht verwendet werden, um alle vorhandenen Probleme zu beseitigen. Diese Grenzen werden bei der Durchführung von Experimenten mit einer neuen Idee aufgedeckt, was zu einer Abkühlung des Interesses an Technologie nach dem sogenannten „Höhepunkt hoher Erwartungen“ führt.
Stufe 2. WachstumDer eigentliche Start erfolgt nur für Technologien, die die nachfolgende Enttäuschung aufgrund ihrer tatsächlichen Fähigkeiten und nicht des Marketinglärms überwinden.
Vorteile: In dieser Phase zieht die Technologie langfristige Investitionen an: nicht nur Geld, sondern auch die Zeit der Spezialisten auf dem Arbeitsmarkt. Wenn klar wird, dass dies nicht nur ein Hype, sondern ein neuer Ansatz oder sogar ein Marktsegment ist, ist es Zeit für Spezialisten, sich in den „Trend“ zu integrieren. Dies ist ein idealer Moment, um vielversprechende Technologien im Hinblick auf den Karrierestart zu beherrschen.
Nachteile: Zu diesem Zeitpunkt ist die Technologie noch schlecht dokumentiert.
Stufe 3. ReifeAusgereifte Technologie ist das eigentliche Arbeitstier des Marktes.
Vorteile: Wenn Sie älter werden, steigt das Volumen der gesammelten Dokumentation, es erscheinen Schulungen und Kurse, und der Einstieg in die Technologie wird einfacher.
Nachteile: Gleichzeitig wächst der Wettbewerb auf dem Arbeitsmarkt.
Stufe 4. RezessionDas Stadium des Niedergangs (Sonnenuntergang) tritt bei allen Technologien auf, obwohl sie weiterhin funktionieren.
Vorteile: Zu diesem Zeitpunkt ist die Technologie bereits vollständig beschrieben, die Grenzen sind klar, eine große Menge an Dokumentation, Kurse sind verfügbar.
Nachteile: Unter dem Gesichtspunkt des Erwerbs neuer Kenntnisse und Perspektiven ist es nicht mehr so attraktiv. In der Tat ist dies eine Begleitung.
Die Wachstumsphase ist am attraktivsten für alle, die in einem neuen technologischen Bereich arbeiten möchten: sowohl für junge Berufstätige als auch für bereits etablierte Fachkräfte aus verwandten Segmenten.
Die Entwicklung von Big Data befindet sich gerade in diesem Stadium. Hohe Erwartungen blieben zurück. Das Geschäft hat bereits bewiesen, dass Big Data Gewinne erzielen kann, und daher liegt ein Produktivitätsplateau vor uns. Dieser Moment bietet Fachleuten auf dem Arbeitsmarkt eine hervorragende Chance.
Unsere Geschichte Big DataDie Einführung von Technologie in einem einzelnen Unternehmen wiederholt im Wesentlichen den allgemeinen Zyklus des Erwachsenwerdens. Und unsere Erfahrung hier ist ziemlich typisch.
Wir haben vor anderthalb Jahren mit dem Aufbau unseres Big-Data-Teams in X5 begonnen. Damals war es nur eine kleine Gruppe von Schlüsselspezialisten, und jetzt sind es fast 200 von uns.
Unsere Projektteams durchliefen mehrere Evolutionsphasen, in denen wir ein tieferes Verständnis für die Rollen und Aufgaben erhielten. Als Ergebnis haben wir unser eigenes Teamformat. Wir haben uns für den agilen Ansatz entschieden. Die Hauptidee ist, dass das Team über alle Kompetenzen verfügt, um das Problem zu lösen, und wie genau sie unter den Spezialisten verteilt sind, ist nicht so wichtig. Auf dieser Grundlage wurde die Zusammensetzung der Rollen der Teams schrittweise festgelegt, einschließlich der Berücksichtigung des technologischen Wachstums. Und jetzt haben wir:
- Product Owner (Product Owner) - hat ein Verständnis für den Themenbereich, formuliert eine allgemeine Geschäftsidee und sagt voraus, wie diese monetarisiert werden kann.
- Business Analyst (Business Analyst) - arbeitet an dieser Aufgabe.
- Datenqualität (Datenqualitätsspezialist) - prüft, ob vorhandene Daten zur Lösung des Problems verwendet werden können.
- Direkt Data Science / Data Analyst (Datenwissenschaftler / Datenanalyst) - Erstellt mathematische Modelle (es gibt verschiedene Unterarten, einschließlich solcher, die nur mit Tabellenkalkulationen funktionieren).
- Testmanager.
- Entwickler
In unserem Fall werden die Infrastruktur und die Daten von allen Teams verwendet, und die folgenden Rollen werden für Teams als Dienste implementiert: - Infrastruktur
- ETL (Datenladebefehl).
 Wie sind wir zum Dream Team gekommen?
Wie sind wir zum Dream Team gekommen?
Traum-nicht-Traum, aber wie gesagt, die Zusammensetzung der Teams hat sich aufgrund der Reife der Big-Data-Analyse und ihres Eindringens in das tägliche Leben von X5 und unseren Vertriebsnetzwerken geändert.
"Schnellstart" - minimale Rollen, maximale Geschwindigkeit
Das erste Team umfasste nur zwei Rollen:
- Der Product Owner schlug ein Modell vor und gab Empfehlungen ab.
- Data Analyst - gesammelte Statistiken basierend auf vorhandenen Daten.
Alles wurde schnell geplant und manuell im Geschäft implementiert.
"Denken wir so?" - Wir haben gelernt, das Geschäft zu verstehen und das nützlichste Ergebnis zu erzielen
Für die Interaktion mit dem Geschäft sind neue Rollen erschienen:
- Business Analyst - Beschriebene Prozessanforderungen.
- Datenqualität - Überprüfung der Datenkonsistenz.
- Abhängig von der Aufgabe analysierte Data Analyst / Data Scientist Datenstatistiken und führte Modellberechnungen auf der lokalen Workstation durch.
„Benötigen Sie mehr Ressourcen“ - lokale Berechnungsaufgaben wurden in den Cluster verschoben und begannen, externe Systeme zu berühren
Zur Unterstützung der erforderlichen Skalierung:
- Die Infrastruktur, die den HADOOP-Server ausgelöst hat.
- Entwickler - Sie haben die Integration in externe IT-Systeme implementiert und die Benutzeroberflächen zu diesem Zeitpunkt selbst überprüft.
Jetzt könnte Data Analyst / Data Scientist verschiedene Optionen für die Berechnung des Modells im Cluster prüfen, obwohl die manuelle Implementierung im Unternehmen weiterhin erhalten bleibt.
„Die Lasten wachsen weiter“ - neue Daten werden angezeigt, neue Kapazitäten sind erforderlich, um sie zu verarbeiten
Diese Änderungen konnten nicht im Team widergespiegelt werden:
- Infrastructure entwickelte den HADOOP-Cluster unter wachsender Last.
- Das ETL-Team begann mit dem regelmäßigen Herunterladen und Aktualisieren von Daten.
- Funktionstests sind erschienen.
"Automatisierung in allem" - die Technologie hat Wurzeln geschlagen, es ist Zeit, die Implementierung des Geschäfts zu automatisieren
Zu diesem Zeitpunkt erschien DevOps im Team, das die automatische Montage, Prüfung und Installation von Funktionen einrichtete.
Schlüsselgedanken zur Teambildung1. Es ist keine Tatsache, dass alles klappen würde, wenn wir nicht von Anfang an die richtigen Spezialisten gehabt hätten, um die wir ein Team aufbauen könnten. Dies ist das Skelett, auf dem die Muskeln zu wachsen begannen.
2. Der Big-Data-Markt ist vollständig grün, daher gibt es nicht genügend „fertige“ Spezialisten für jede der Rollen. Natürlich wäre es sehr praktisch, eine ganze Abteilung von Senioren zu rekrutieren, aber offensichtlich können solche „Star“ -Teams nicht viel aufgebaut werden. Wir haben uns entschieden, nicht nur „fertiges“ Personal zu jagen. Wie bereits erwähnt, sollten wir uns bei der Einhaltung der Agilität nur darum kümmern, dass das gesamte Team über die Kompetenzen verfügt, um ein bestimmtes Problem zu lösen. Mit anderen Worten, wir können Profis und Anfänger mit einer bestimmten technischen und mathematischen Basis in ein Team aufnehmen (und aufnehmen), so dass sie zusammen eine Reihe von Kompetenzen bilden, die erforderlich sind, um die gewünschten Ergebnisse zu erzielen.
3. Jede der Rollen setzt ein Verständnis der Prinzipien der Arbeit mit Big Data voraus, erfordert jedoch die Tiefe dieses Verständnisses. Die größte Variabilität von Rollen, die direkte Analogien in der klassischen Entwicklung aufweisen - Tester, Analysten usw. Für sie gibt es Aufgaben, bei denen die Zugehörigkeit zu Big Data fast unsichtbar ist, und Aufgaben, bei denen Sie etwas tiefer eintauchen müssen. Auf die eine oder andere Weise reicht es aus, eine Karriere zu beginnen, eine bestimmte Erfahrung, ein Verständnis für IT, einen Lernwillen und theoretisches Wissen über die verwendeten Tools (die durch Lesen der Artikel erworben werden können).
4. Die Praxis hat gezeigt, dass trotz der Tatsache, dass die Technologie bekannt ist und viele dies gerne tun würden, nicht jeder Spezialist, der für den Start einer Karriere in Big Data geeignet wäre (und im Herzen dort arbeiten möchte), wirklich versucht, hierher zu kommen .
Viele hervorragende Kandidaten glauben, dass die Arbeit in BigData-Teams ausschließlich Data Science ist. Was ist eine grundlegende Änderung der Aktivität mit einer hohen Eintrittsschwelle? Sie unterschätzen jedoch ihre Kompetenzen oder wissen einfach nicht, dass Menschen mit unterschiedlichen Profilen in Big Data gefragt sind, und es wäre einfacher, eine Karriere in einer alternativen Rolle zu beginnen - einer der oben genannten.
a. Um in einem gemischten Team in vielen Rollen zu arbeiten, benötigen Sie keine enge Fachausbildung im Bereich Big Data.
b. Wir haben das Team aktiv erweitert und uns an die Idee gehalten, gemischte Struktureinheiten zu bauen. Und das Interessanteste ist, dass Menschen, die zu unseren Aufgaben kamen und noch nie zuvor mit Big Data gearbeitet hatten, perfekt im Unternehmen Fuß gefasst haben, nachdem sie die Aufgaben bewältigt hatten. Sie konnten schnell die Praxis von Big Data erlernen.
5. Ohne viel Erfahrung können Sie tiefer eintauchen, die erforderlichen Sprachen und Werkzeuge lernen und motiviert sein, in diesem Segment zu wachsen, um strategischere Aufgaben innerhalb des Projekts zu bewältigen. Die gesammelten Erfahrungen helfen dabei, zu den Rollen zu wechseln, in denen Kenntnisse in Big Data erforderlich sind, und die Logik dieser Richtung zu verstehen. Übrigens hilft in diesem Sinne ein gemischtes Team sehr, die Entwicklung zu beschleunigen.
Wie komme ich zu BigData?
In unserem Fall hat sich die Idee ausgewogener Teams von Spezialisten verschiedener Ebenen „durchgesetzt“ - die Gruppe hat bereits mehr als ein internes Projekt umgesetzt. Es scheint mir, dass mit einem Mangel an vorgefertigtem Personal und einem Anstieg des Geschäftsbedarfs für solche Teams andere Unternehmen zum gleichen Szenario kommen werden.
Wenn Sie sich ernsthaft für diese Richtung entscheiden möchten, hilft Ihnen das Eintauchen in Data Sciense - Kaggle, ODS und andere spezialisierte Ressourcen. Wenn Sie sich in naher Zukunft nicht als Data Scientist sehen, aber an der Richtung an sich interessiert sind, werden Sie weiterhin in Big Data benötigt!
So steigern Sie Ihren Wert:
- Aktualisieren Sie Ihre mathematischen Kenntnisse. Um gewöhnliche Probleme mit Big Data zu lösen, ist keine Promotion erforderlich, aber Grundkenntnisse in höherer Mathematik sind noch erforderlich. Wenn Sie die Mechanismen verstehen, die den Statistiken zugrunde liegen, können Sie sich der Prozesse leichter bewusst werden.
- Wählen Sie die Rollen aus, die Ihrer aktuellen Spezialität am nächsten kommen. Finden Sie heraus, welchen Herausforderungen Sie in dieser Rolle gegenüberstehen (und in einem bestimmten Unternehmen, wohin Sie möchten). Und wenn Sie ähnliche Probleme bereits gelöst haben, sollten Sie diese im Lebenslauf hervorheben.
- Tools, die für die ausgewählte Rolle spezifisch sind, sind sehr wichtig, auch wenn dies für Big Data nicht relevant zu sein scheint. Bei der Entwicklung unserer internen Lösung stellte sich beispielsweise heraus, dass wir viele Front-End-Entwickler benötigen, die mit komplexen Schnittstellen arbeiten.
- Denken Sie daran, dass sich der Markt aktiv entwickelt. Jemand baut und pumpt Teams im Inneren, während jemand erwartet, fertige Spezialisten auf dem Arbeitsmarkt zu finden. Wenn Sie ein Anfänger sind, versuchen Sie, in ein starkes Team einzusteigen, in dem Sie zusätzliches Wissen erwerben können.
PS Übrigens wachsen wir derzeit weiter aktiv und suchen einen
Dateningenieur ,
Testspezialisten ,
React-Entwickler und
UI / UX-Spezialisten . Am 10. und 11. Mai werden wir mit allen an unserem Stand auf dem
DataFest über die Arbeit in # bigdatax5
sprechen .