Vorwort
Neben meinem jüngsten Artikel möchte ich auch über das Thema MU ( M ulti U ser) MIMO sprechen. Ich habe bereits Professor Haardts einen sehr berühmten Artikel erwähnt , in dem er zusammen mit seinen Kollegen einen Algorithmus zur Trennung von Benutzern in einem Downlink (Downlink) vorschlägt, der auf linearen Methoden basiert, nämlich die Blockdiagonalisierung eines Kanals. Der Artikel hat eine beeindruckende Anzahl von Zitaten und ist auch der Eckpfeiler für eine der Prüfungsaufgaben. Warum also nicht die Grundlagen des vorgeschlagenen Algorithmus herausfinden?
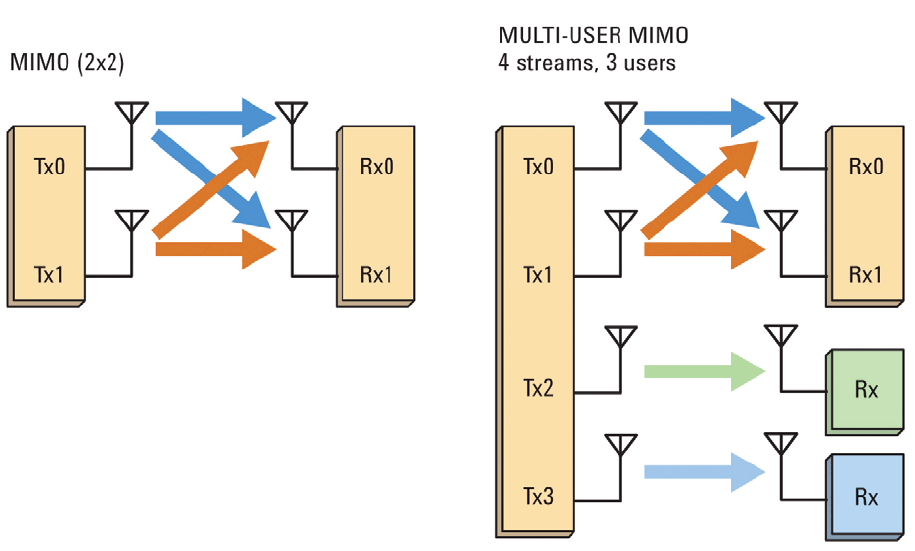
Erklärung des Problems
Lassen Sie uns zunächst entscheiden, in welchem Bereich des MIMO-Themas wir jetzt arbeiten werden.
Herkömmlicherweise können alle Übertragungsmethoden im Rahmen der MIMO-Technologie in zwei Hauptgruppen unterteilt werden:
Das Hauptziel besteht darin, die Störfestigkeit des Getriebes zu erhöhen. Wenn räumliche Kanäle vereinfacht werden, duplizieren sie sich gegenseitig, wodurch wir die beste Übertragungsqualität erhalten.
Beispiele:
- Blockcodes (zum Beispiel das Alamuti-Schema );
- Codes basierend auf dem Viterbi-Algorithmus.
Das Hauptziel ist die Erhöhung der Übertragungsgeschwindigkeit. Wir haben bereits in einem früheren Artikel besprochen, dass der MIMO-Kanal unter bestimmten Bedingungen als eine Reihe paralleler SISO-Kanäle betrachtet werden kann. Tatsächlich ist dies die zentrale Idee des räumlichen Multiplexens: die maximale Anzahl unabhängiger Informationsflüsse zu erreichen. Das Hauptproblem in diesem Fall ist die Unterdrückung von Inter-Channel-Interferenzen (Inter-Channel-Interferenzen) , für die es mehrere Klassen von Lösungen gibt:
- horizontale Kanaltrennung;
- vertikal (zum Beispiel der V-BLAST-Algorithmus);
- Diagonale (zum Beispiel der D-BLAST-Algorithmus).
Aber das ist natürlich nicht alles.
Die Idee des räumlichen Multiplexens kann erweitert werden: Nicht nur Kanäle, sondern auch Benutzer zu teilen (SDMA - Space Division Multiple Access).
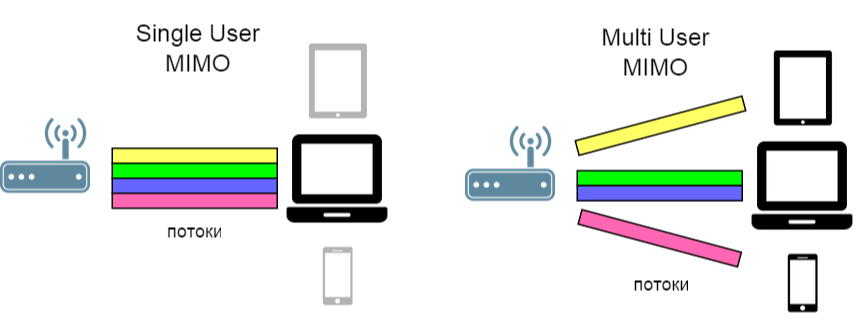
( Link zur Quelle der Illustration )
Folglich ist es in diesem Fall bereits erforderlich, gegen Interferenzen zwischen Benutzern zu kämpfen . Zu diesem Zweck wurde ein Algorithmus namens Blockdiagonalisierung Zero-Forcing vorgeschlagen , den wir heute betrachten.
Mathematische Beschreibung
Beginnen wir nach wie vor mit dem empfangenen Signalmodell. Genauer gesagt zeigen wir auf dem Diagramm, woher und was kommt:

Die Kanalmatrix hat in diesem Fall die Form:
mit der Gesamtzahl der Sendeantennen  und die Gesamtzahl der Empfangsantennen
und die Gesamtzahl der Empfangsantennen  .
.
Wichtig :
Dieser Algorithmus kann nur angewendet werden, wenn die Anzahl der Sendeantennen größer oder gleich der Gesamtzahl der Empfangsantennen ist:
Diese Bedingung wirkt sich direkt auf die Eigenschaften der Diagonalisierung aus.
Das Modell der empfangenen Symbole (Signale) kann also in Vektorform geschrieben werden als:
Interessanter ist es jedoch, die Formel für einen bestimmten Benutzer zu betrachten:
In der Tat:
 - additives Rauschen.
- additives Rauschen.
Wir kommen also zur Formulierung der Hauptaufgabe:
Sie können solche Matrizen finden  so dass der Interferenzteil auf Null geht!
so dass der Interferenzteil auf Null geht!
Das werden wir tun.
Beschreibung des Algorithmus
Wir werden die Beschreibung anhand eines Beispiels durchführen, und zur Veranschaulichung werde ich Screenshots aus erster Hand geben und sie ein wenig kommentieren.
Betrachten Sie den ersten Benutzer:

Lassen Sie uns über die Hauptschritte sprechen:
- Wir machen eine Matrix
 von Kanalmatrizen aller anderen Benutzer.
von Kanalmatrizen aller anderen Benutzer.
Gehen Sie voran:

Daher wird dieser Vorgang für jeden Benutzer wiederholt. Ist das nicht die Magie der Mathematik: Mit den Methoden der linearen Algebra lösen wir vollständig technische Probleme!
Beachten Sie, dass in der Praxis nicht nur die erhaltenen Vorcodierungsmatrizen verwendet werden, sondern auch die Nachbearbeitungsmatrizen und die Matrix der Singularwerte (siehe Folien ). Letzteres zum Beispiel zum Ausgleich der Leistung nach dem bereits bekannten Wassergießalgorithmus .
Wir modellieren den Algorithmus
Ich denke, es wird nicht überflüssig sein, eine kleine Simulation durchzuführen, um das Ergebnis zu konsolidieren. Dazu verwenden wir Python 3, nämlich:
import numpy as np
für grundlegende Berechnungen und:
import pandas as pd
um das Ergebnis anzuzeigen.
Um mich nicht zu häufen, werde ich die Quelle hier einfügen class ZeroForcingBD: def __init__(self, H, Mrs_arr): Mr, Mt = np.shape(H) self.Mr = Mr self.Mt = Mt self.H = H self.Mrs_arr = Mrs_arr def __routines(self, H, mr, shift):
Angenommen, wir haben 8 Sendeantennen und 3 Benutzer mit 3, 2 und 3 Empfangsantennen:
Mrs_arr = [3,2,3]
Wir initialisieren unsere Klasse und wenden die entsprechenden Methoden an:
BD = ZeroForcingBD(H, Mrs_arr) F, D, Hs = BD.process() FF = BD.obtain_matrices()
Wir bringen zu einer lesbaren Form:
df = pd.DataFrame(np.dot(H, FF)) df[abs(df).lt(1e-14)] = 0
Und lassen Sie uns aus Gründen der Klarheit ein wenig heben (obwohl Sie darauf verzichten können):
print(pd.DataFrame(np.round(np.real(df),100)))
Sie sollten so etwas bekommen:

Eigentlich sind sie hier Blöcke, hier ist es und Diagonalisierung. Und Minimierung von Störungen.
Solche Dinge.
Literatur
- Spencer, Quentin H., A. Lee Swindlehurst und Martin Haardt. "Zero-Forcing-Methoden für das räumliche Downlink-Multiplexing in Mehrbenutzer-MIMO-Kanälen." IEEE-Transaktionen zur Signalverarbeitung 52.2 (2004): 461-471.
- Martin Haard " Robuste Übertragungsverarbeitung für Mehrbenutzer-MIMO-Systeme "
PS
Dem Lehrpersonal und der Studentengemeinschaft meines Heimatberufs sage ich Hallo!