Es gibt verschiedene Ansätze zum Verständnis einer umgangssprachlichen Sprachmaschine: den klassischen Dreikomponentenansatz (der eine Spracherkennungskomponente, eine Komponente zum Verständnis natürlicher Sprache und eine Komponente enthält, die für eine bestimmte Geschäftslogik verantwortlich ist) und einen End2End-Ansatz, der vier Implementierungsmodelle umfasst: direkt, kollaborativ, mehrstufig und multitasking . Lassen Sie uns alle Vor- und Nachteile dieser Ansätze betrachten, einschließlich derer, die auf Googles Experimenten basieren, und im Detail analysieren, warum der End2End-Ansatz die Probleme des klassischen Ansatzes löst.

Wir geben dem führenden Entwickler des AI MTS-Zentrums Nikita Semenov das Wort.
Hallo! Als Vorwort möchte ich die bekannten Wissenschaftler Jan Lekun, Joshua Benjio und Jeffrey Hinton zitieren - dies sind drei Pioniere der künstlichen Intelligenz, die kürzlich eine der renommiertesten Auszeichnungen auf dem Gebiet der Informationstechnologie erhalten haben - den Turing Award. In einer der Ausgaben des Nature-Magazins im Jahr 2015 veröffentlichten sie einen sehr interessanten Artikel „Deep Learning“, in dem es einen interessanten Satz gab: „Deep Learning versprach die Fähigkeit, mit Rohsignalen umzugehen, ohne dass handgefertigte Funktionen erforderlich sind.“ Es ist schwierig, es richtig zu übersetzen, aber die Bedeutung ist ungefähr so: "Deep Learning war mit dem Versprechen verbunden, mit Rohsignalen umgehen zu können, ohne dass manuelle Zeichen erstellt werden müssen." Meiner Meinung nach ist dies für Entwickler der Hauptmotivator aller vorhandenen.
Klassischer Ansatz
Beginnen wir also mit dem klassischen Ansatz. Wenn wir über das Verstehen des Sprechens mit einer Maschine sprechen, meinen wir, dass wir eine bestimmte Person haben, die einige Dienste mit ihrer Stimme steuern möchte oder das Bedürfnis hat, dass ein System auf seine Sprachbefehle mit einer gewissen Logik reagiert.
Wie wird dieses Problem gelöst? In der klassischen Version wird ein System verwendet, das, wie oben erwähnt, aus drei großen Komponenten besteht: einer Spracherkennungskomponente, einer Komponente zum Verstehen einer natürlichen Sprache und einer Komponente, die für eine bestimmte Geschäftslogik verantwortlich ist. Es ist klar, dass der Benutzer zunächst ein bestimmtes Tonsignal erzeugt, das auf die Spracherkennungskomponente fällt und vom Ton zum Text wechselt. Dann fällt der Text in die Komponente des Verstehens der natürlichen Sprache, aus der eine bestimmte semantische Struktur herausgezogen wird, die für die für die Geschäftslogik verantwortliche Komponente erforderlich ist.
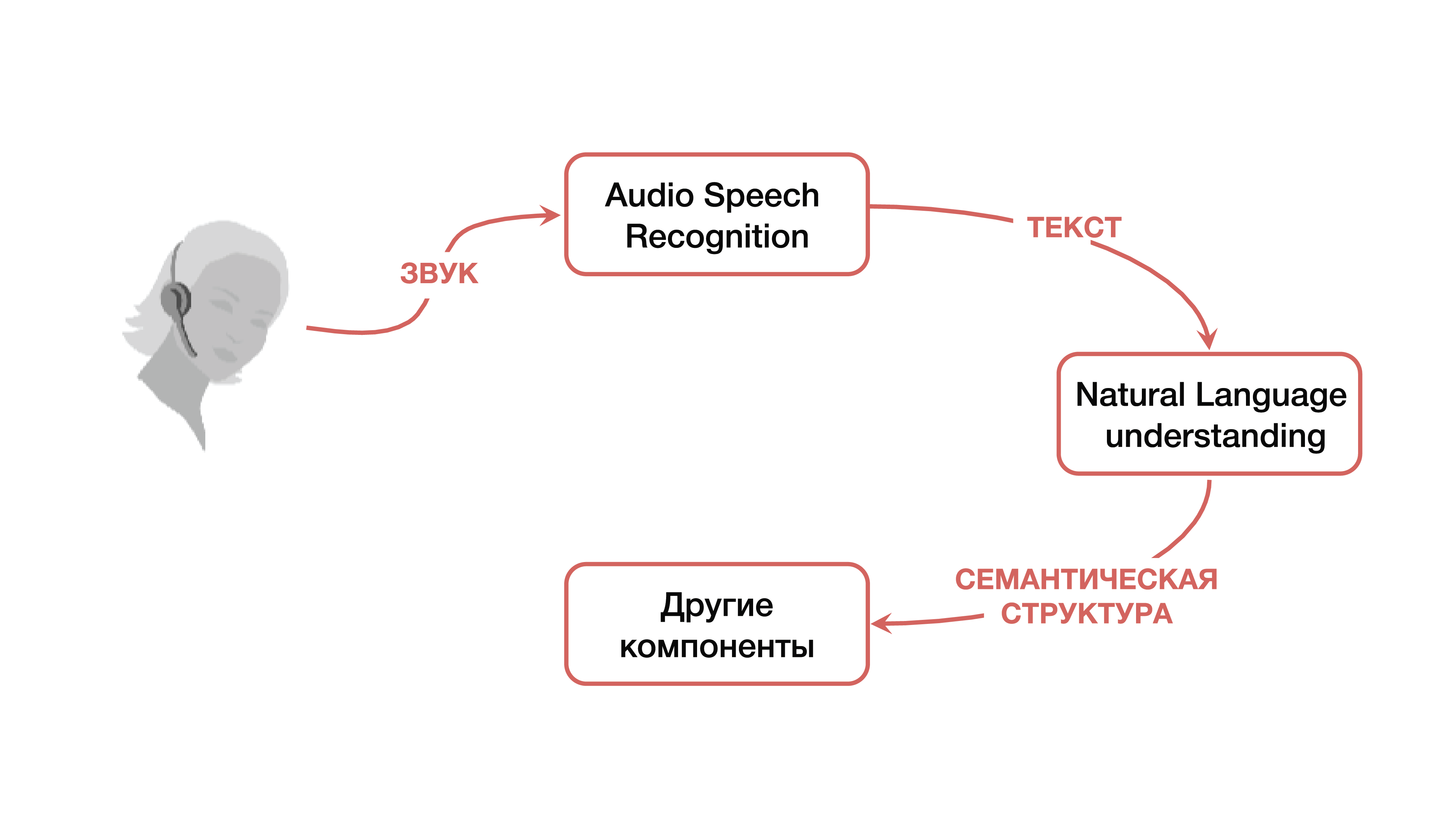
Was ist eine semantische Struktur? Dies ist eine Art Verallgemeinerung / Aggregation mehrerer Aufgaben zu einer - zum leichteren Verständnis. Die Struktur umfasst drei wichtige Teile: die Klassifizierung der Domäne (eine bestimmte Definition des Themas), die Klassifizierung der Absicht (Verständnis, was zu tun ist) und die Zuweisung benannter Entitäten zum Ausfüllen von Karten, die für bestimmte Geschäftsaufgaben in der nächsten Phase erforderlich sind. Um zu verstehen, was eine semantische Struktur ist, können Sie ein einfaches Beispiel betrachten, das Google am häufigsten zitiert. Wir haben eine einfache Anfrage: "Bitte spielen Sie ein Lied eines Künstlers."

Die Domäne und der Gegenstand dieser Anfrage ist Musik; Absicht - ein Lied spielen; Attribute der Karte „Ein Lied spielen“ - welche Art von Lied, welche Art von Künstler. Eine solche Struktur ist das Ergebnis des Verständnisses einer natürlichen Sprache.
Wenn wir über die Lösung eines komplexen und mehrstufigen Problems des Verstehens der Umgangssprache sprechen, besteht es, wie gesagt, aus zwei Stufen: Die erste ist die Spracherkennung, die zweite ist das Verstehen der natürlichen Sprache. Der klassische Ansatz beinhaltet eine vollständige Trennung dieser Stufen. In einem ersten Schritt haben wir ein bestimmtes Modell, das am Eingang ein akustisches Signal empfängt und am Ausgang mithilfe von Sprach- und Akustikmodellen und einem Lexikon die wahrscheinlichste verbale Hypothese aus diesem akustischen Signal ermittelt. Dies ist eine völlig probabilistische Geschichte - sie kann gemäß der bekannten Bayes-Formel zerlegt werden und eine Formel erhalten, mit der Sie die Wahrscheinlichkeitsfunktion der Stichprobe schreiben und die Maximum-Likelihood-Methode verwenden können. Wir haben eine bedingte Wahrscheinlichkeit des Signals X, vorausgesetzt, die Wortfolge W wird mit der Wahrscheinlichkeit dieser Wortfolge multipliziert.

Die erste Phase, die wir durchlaufen haben - wir haben eine verbale Hypothese aus dem Tonsignal erhalten. Als nächstes kommt die zweite Komponente, die diese sehr verbale Hypothese aufgreift und versucht, die oben beschriebene semantische Struktur herauszuholen.
Wir haben die Wahrscheinlichkeit der semantischen Struktur S, vorausgesetzt, die verbale Sequenz W befindet sich am Eingang.

Was ist das Schlechte an dem klassischen Ansatz, der aus diesen beiden Elementen / Schritten besteht, die getrennt unterrichtet werden (d. H. Wir trainieren zuerst das Modell des ersten Elements und dann das Modell des zweiten Elements)?
- Die Komponente zum Verständnis der natürlichen Sprache arbeitet mit den von ASR generierten verbalen Hypothesen auf hoher Ebene. Dies ist ein großes Problem, da die erste Komponente (ASR selbst) mit Rohdaten auf niedriger Ebene arbeitet und eine verbale Hypothese auf hoher Ebene generiert. Die zweite Komponente verwendet die Hypothese als Eingabe - nicht die Rohdaten aus der Primärquelle, sondern die Hypothese, die das erste Modell liefert - und erstellt ihre Hypothese über die Hypothese der ersten Stufe. Dies ist eine ziemlich problematische Geschichte, weil sie zu "bedingt" wird.
- Das nächste Problem: Wir können keinen Zusammenhang zwischen der Bedeutung von Wörtern herstellen, die zum Aufbau der sehr semantischen Struktur erforderlich sind, und dem, was die erste Komponente bevorzugt, indem wir eine eigene verbale Hypothese aufbauen. Das heißt, wenn Sie umformulieren, erhalten wir, dass die Hypothese bereits erstellt wurde. Es basiert, wie gesagt, auf drei Komponenten: dem akustischen Teil (der in die Eingabe kam und irgendwie modelliert ist), dem Sprachteil (modelliert alle Sprachgramme vollständig - die Wahrscheinlichkeit der Sprache) und dem Lexikon (Aussprache von Wörtern). Dies sind drei große Teile, die kombiniert werden müssen, und einige darin enthaltene Hypothesen. Es gibt jedoch keine Möglichkeit, die Wahl derselben Hypothese zu beeinflussen, so dass diese Hypothese für die nächste Stufe wichtig ist (was im Prinzip der Punkt ist, an dem sie vollständig getrennt lernen und sich in keiner Weise gegenseitig beeinflussen).
End2End-Ansatz
Wir haben verstanden, was der klassische Ansatz ist, welche Probleme er hat. Versuchen wir, diese Probleme mit dem End2End-Ansatz zu lösen.
Mit End2End meinen wir ein Modell, das die verschiedenen Komponenten zu einer einzigen Komponente kombiniert. Wir werden mit Modellen modellieren, die aus einer Encoder-Decoder-Architektur bestehen, die Module der Aufmerksamkeit (Aufmerksamkeit) enthält. Solche Architekturen werden häufig bei Spracherkennungsproblemen und bei Aufgaben im Zusammenhang mit der Verarbeitung einer natürlichen Sprache, insbesondere der maschinellen Übersetzung, verwendet.
Es gibt vier Möglichkeiten für die Implementierung solcher Ansätze, die das vor uns liegende Problem des klassischen Ansatzes lösen könnten: direkte, kollaborative, mehrstufige und multitasking-Modelle.
Direktes Modell
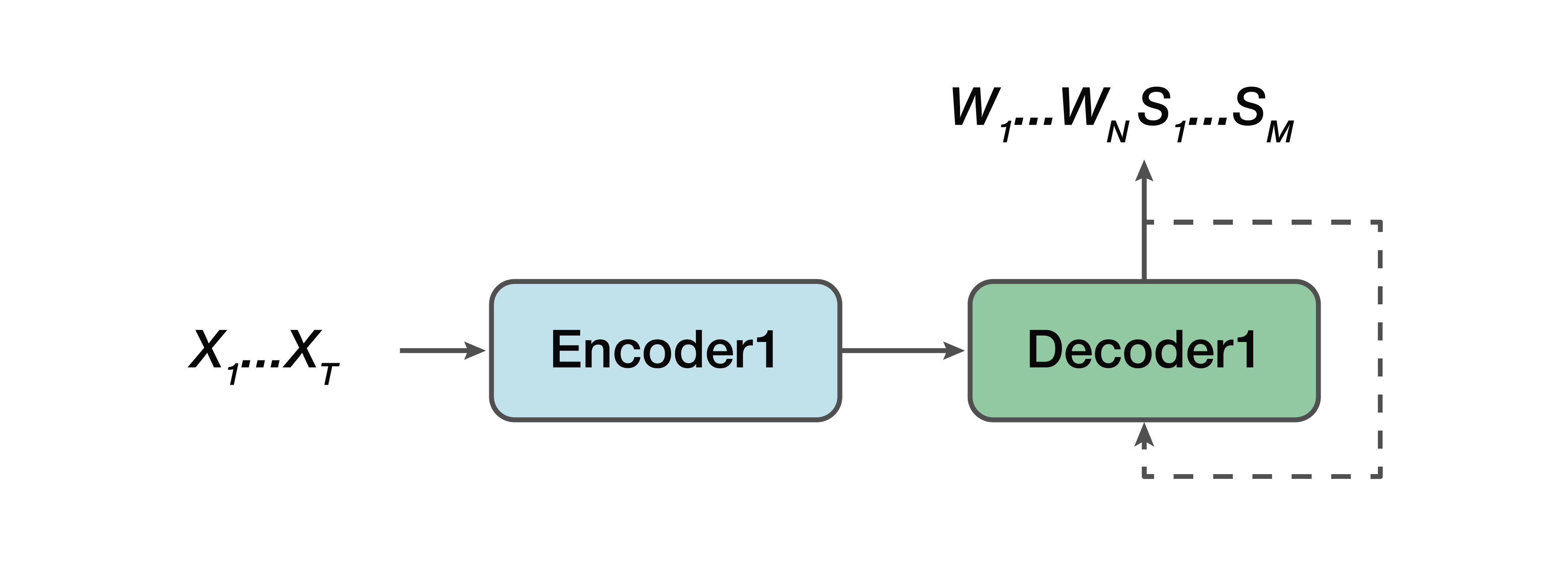
Das direkte Modell übernimmt die eingegebenen Rohattribute auf niedriger Ebene, d.h. Low-Level-Audiosignal, und am Ausgang erhalten wir sofort eine semantische Struktur. Das heißt, wir erhalten ein Modul - die Eingabe des ersten Moduls aus dem klassischen Ansatz und die Ausgabe des zweiten Moduls aus demselben klassischen Ansatz. Nur so eine "Black Box". Von hier aus gibt es einige Vor- und Nachteile. Das Modell lernt nicht, das Eingangssignal vollständig zu transkribieren - dies ist ein klares Plus, da wir kein großes, großes Markup sammeln müssen, nicht viel Audiosignal sammeln müssen und es dann den Accessoren zum Markup geben müssen. Wir brauchen nur dieses Audiosignal und die entsprechende semantische Struktur. Und alle. Dies reduziert den Arbeitsaufwand für das Markieren von Daten um ein Vielfaches. Das wahrscheinlich größte Minus dieses Ansatzes ist, dass die Aufgabe für eine solche "Black Box" zu kompliziert ist, die versucht, zwei Probleme sofort und bedingt zu lösen. Zuerst versucht er in sich selbst, eine Art Transkription aufzubauen, und dann enthüllt er aus dieser Transkription die sehr semantische Struktur. Dies wirft eine ziemlich schwierige Aufgabe auf - zu lernen, Teile der Transkription zu ignorieren. Und es ist sehr schwierig. Dieser Faktor ist ein ziemlich großes und kolossales Minus dieses Ansatzes.
Wenn wir über Wahrscheinlichkeiten sprechen, löst dieses Modell das Problem, die wahrscheinlichste semantische Struktur S aus dem akustischen Signal X mit den Modellparametern θ zu finden.
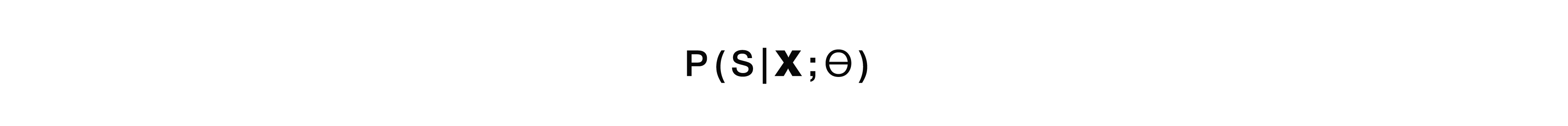
Gemeinsames Modell
Was ist die Alternative? Dies ist ein kollaboratives Modell. Das heißt, einige Modelle sind einer geraden Linie sehr ähnlich, aber mit einer Ausnahme: Die Ausgabe besteht für uns bereits aus verbalen Sequenzen und eine semantische Struktur wird einfach mit ihnen verknüpft. Das heißt, am Eingang haben wir ein Tonsignal und ein neuronales Netzwerkmodell, das am Ausgang bereits sowohl verbale Transkription als auch semantische Struktur liefert.
Von den Profis: Wir haben immer noch einen einfachen Encoder, einen einfachen Decoder. Das Lernen wird erleichtert, da das Modell nicht versucht, zwei Probleme gleichzeitig zu lösen, wie im Fall des direkten Modells. Ein weiterer Vorteil besteht darin, dass diese Abhängigkeit der semantischen Struktur von Low-Level-Sound-Attributen weiterhin besteht. Denn wieder ein Encoder, ein Decoder. Dementsprechend kann eines der Pluspunkte festgestellt werden, dass die Vorhersage dieser sehr semantischen Struktur und ihres Einflusses direkt von der Transkription selbst abhängt - was uns im klassischen Ansatz nicht zusagte.
Wieder müssen wir die wahrscheinlichste Folge von Wörtern W und die entsprechenden semantischen Strukturen S aus dem akustischen Signal X mit den Parametern θ finden.
Multitasking-Modell
Der nächste Ansatz ist ein Multitasking-Modell. Wieder der Encoder-Decoder-Ansatz, aber mit einer Ausnahme.
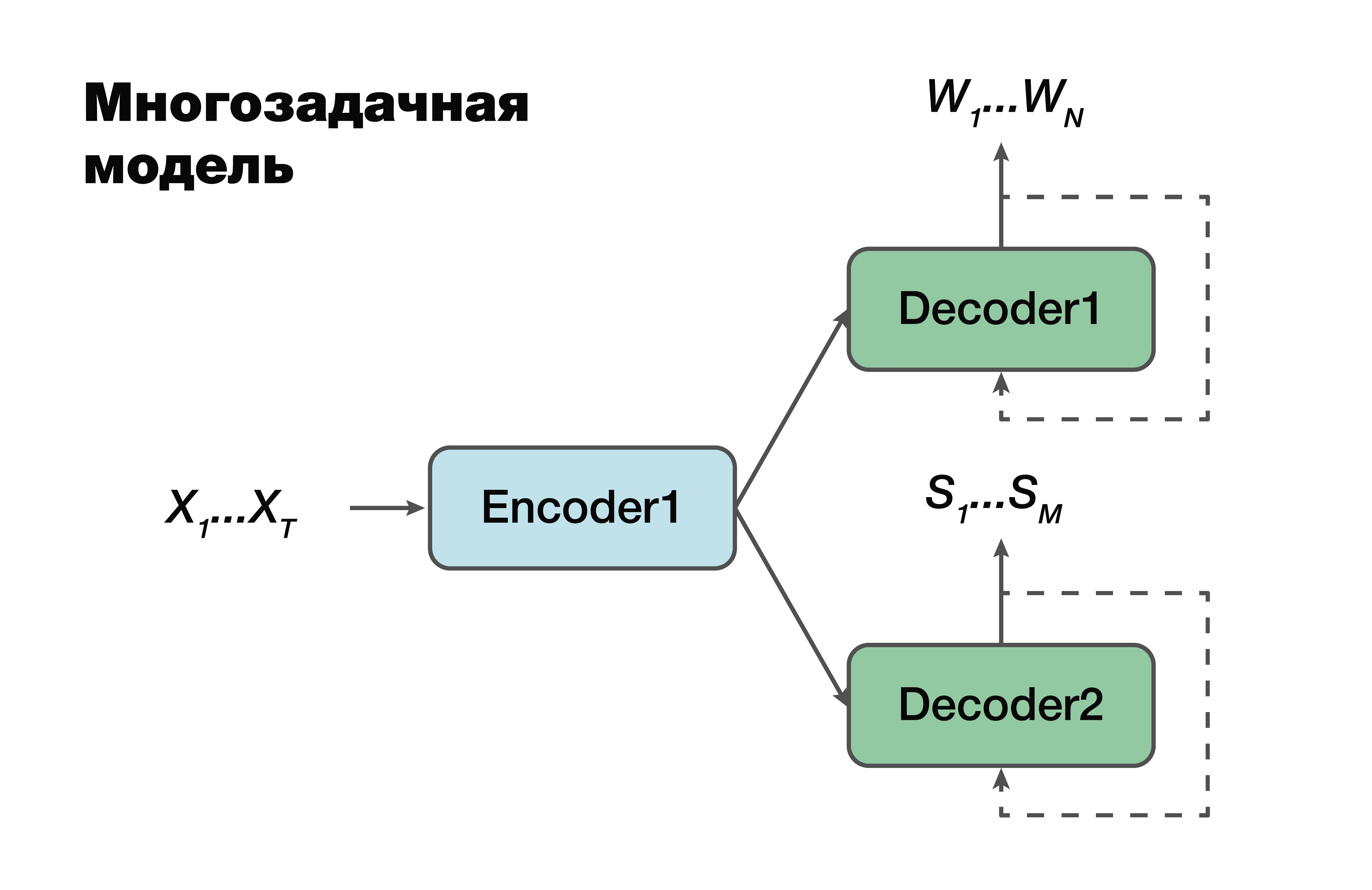
Für jede Aufgabe, dh zum Erstellen einer verbalen Sequenz, zum Erstellen einer semantischen Struktur, haben wir einen eigenen Decoder, der eine gemeinsame versteckte Darstellung verwendet, die einen einzelnen Encoder generiert. Ein sehr berühmter Trick beim maschinellen Lernen, der sehr oft in der Arbeit angewendet wird. Das gleichzeitige Lösen von zwei verschiedenen Problemen hilft dabei, Abhängigkeiten in den Quelldaten viel besser zu suchen. Und als Folge davon - die beste Verallgemeinerungsfähigkeit, da der optimale Parameter für mehrere Aufgaben gleichzeitig ausgewählt wird. Dieser Ansatz eignet sich am besten für Aufgaben mit weniger Daten. Und Decoder verwenden einen verborgenen Vektorraum, in den ihr Encoder erstellt.

Es ist wichtig zu beachten, dass bereits wahrscheinlich eine Abhängigkeit von den Parametern der Codierer- und Decodierermodelle besteht. Und diese Parameter sind wichtig.
Mehrstufiges Modell
Wir wenden uns meiner Meinung nach dem interessantesten Ansatz zu: einem mehrstufigen Modell. Wenn Sie genau hinschauen, können Sie sehen, dass dies mit einer Ausnahme tatsächlich der gleiche klassische Zweikomponentenansatz ist.
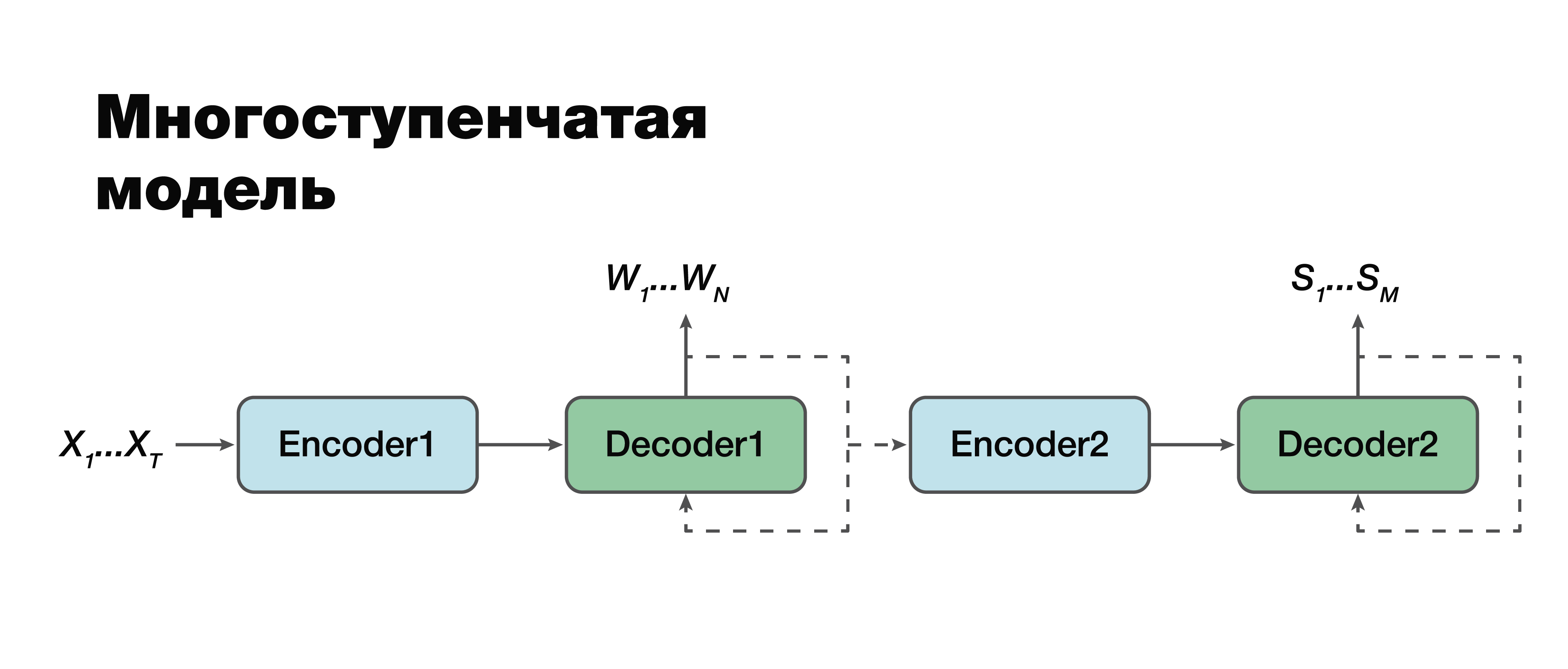
Hier ist es möglich, eine Verbindung zwischen den Modulen herzustellen und sie zu einem Modul zu machen. Daher wird die semantische Struktur als bedingt abhängig von der Transkription angesehen. Es gibt zwei Möglichkeiten, mit diesem Modell zu arbeiten. Wir können diese beiden Mini-Blöcke einzeln trainieren: den ersten und den zweiten Encoder-Decoder. Oder kombinieren Sie sie und trainieren Sie beide Aufgaben gleichzeitig.
Im ersten Fall hängen die Parameter für die beiden Aufgaben nicht zusammen (wir können mit unterschiedlichen Daten trainieren). Angenommen, wir haben einen großen Klangkörper und die entsprechenden verbalen Sequenzen und Transkriptionen. Wir "fahren" sie, wir trainieren nur den ersten Teil. Wir bekommen eine gute Transkriptionssimulation. Dann nehmen wir den zweiten Teil, wir trainieren an einem anderen Fall. Wir verbinden uns und erhalten eine Lösung, die in diesem Ansatz zu 100% mit dem klassischen Ansatz übereinstimmt, da wir den ersten Teil und den zweiten Teil getrennt genommen und trainiert haben. Und dann trainieren wir das verbundene Modell für den Fall, der bereits drei Daten enthält: ein Audiosignal, die entsprechende Transkription und die entsprechende semantische Struktur. Wenn wir ein solches Gebäude haben, können wir das Modell, das individuell an großen Gebäuden trainiert wurde, für unsere spezifische kleine Aufgabe trainieren und auf solch knifflige Weise den maximalen Genauigkeitsgewinn erzielen. Dieser Ansatz ermöglicht es uns, die Bedeutung verschiedener Teile der Transkription und ihren Einfluss auf die Vorhersage der semantischen Struktur
zu berücksichtigen, indem
wir die Fehler der zweiten Stufe in der ersten
berücksichtigen .
Es ist wichtig anzumerken, dass die endgültige Aufgabe dem klassischen Ansatz mit nur einem großen Unterschied sehr ähnlich ist: dem zweiten Term unserer Funktion, dem Logarithmus der Wahrscheinlichkeit der semantischen Struktur, vorausgesetzt, das akustische Eingangssignal X hängt auch von den Parametern des
Modells der ersten Stufe ab .

Hierbei ist auch zu beachten, dass die zweite Komponente von den Parametern des ersten und zweiten Modells abhängt.
Methodik zur Bewertung der Genauigkeit von Ansätzen
Nun lohnt es sich, die Methode zur Bewertung der Genauigkeit festzulegen. Wie kann man diese Genauigkeit tatsächlich messen, um Merkmale zu berücksichtigen, die im klassischen Ansatz nicht zu uns passen? Es gibt klassische Bezeichnungen für diese separaten Aufgaben. Um Spracherkennungskomponenten zu bewerten, können wir die klassische WER-Metrik verwenden. Dies ist eine Wortfehlerrate. Wir betrachten nach einer nicht sehr komplizierten Formel die Anzahl der Einfügungen, Substitutionen, Permutationen des Wortes und dividieren sie durch die Anzahl aller Wörter. Und wir erhalten ein bestimmtes geschätztes Merkmal für die Qualität unserer Anerkennung. Für eine semantische Struktur können wir komponentenweise einfach die F1-Punktzahl betrachten. Dies ist auch eine klassische Metrik für das Klassifizierungsproblem. Hier ist alles Plus oder Minus klar. Es gibt Fülle, es gibt Genauigkeit. Und das ist nur ein harmonisches Mittel zwischen ihnen.
Es stellt sich jedoch die Frage, wie die Genauigkeit gemessen werden kann, wenn die Eingabetranskription und das Ausgabeargument nicht übereinstimmen oder wenn die Ausgabe Audiodaten sind. Google hat eine Metrik vorgeschlagen, die die Bedeutung der Vorhersage der ersten Komponente der Spracherkennung berücksichtigt, indem die Auswirkung dieser Erkennung auf die zweite Komponente selbst bewertet wird. Sie nannten es Arg WER, das heißt, es wiegt WER über den semantischen Strukturentitäten.
Nehmen Sie die Anfrage entgegen: "Stellen Sie den Alarm für 5 Stunden ein." Diese semantische Struktur enthält ein Argument wie "fünf Stunden", ein Argument vom Typ "Datum Uhrzeit". Es ist wichtig zu verstehen, dass, wenn die Spracherkennungskomponente dieses Argument erzeugt, die Fehlermetrik dieses Arguments, dh WER, 0% beträgt. Wenn dieser Wert nicht fünf Stunden entspricht, hat die Metrik 100% WER. Daher betrachten wir einfach den gewichteten Durchschnittswert für alle Argumente und erhalten im Allgemeinen eine bestimmte aggregierte Metrik, die die Bedeutung von Transkriptionsfehlern schätzt, die die Spracherkennungskomponente erzeugen.
Lassen Sie mich ein Beispiel für die Experimente von Google geben, die es in einer seiner Studien zu diesem Thema durchgeführt hat. Sie verwendeten Daten aus fünf Domänen, fünf Themen: Medien, Media_Control, Produktivität, Freude, Keine - mit der entsprechenden Verteilung von Daten auf Trainingstestdatensätzen. Es ist wichtig zu beachten, dass alle Modelle von Grund auf neu trainiert wurden. Cross_entropy wurde verwendet, der Strahlensuchparameter war 8, der Optimierer, den sie verwendeten, natürlich Adam. Betrachtet natürlich auf einer großen Wolke ihrer TPU. Was ist das Ergebnis? Das sind interessante Zahlen:
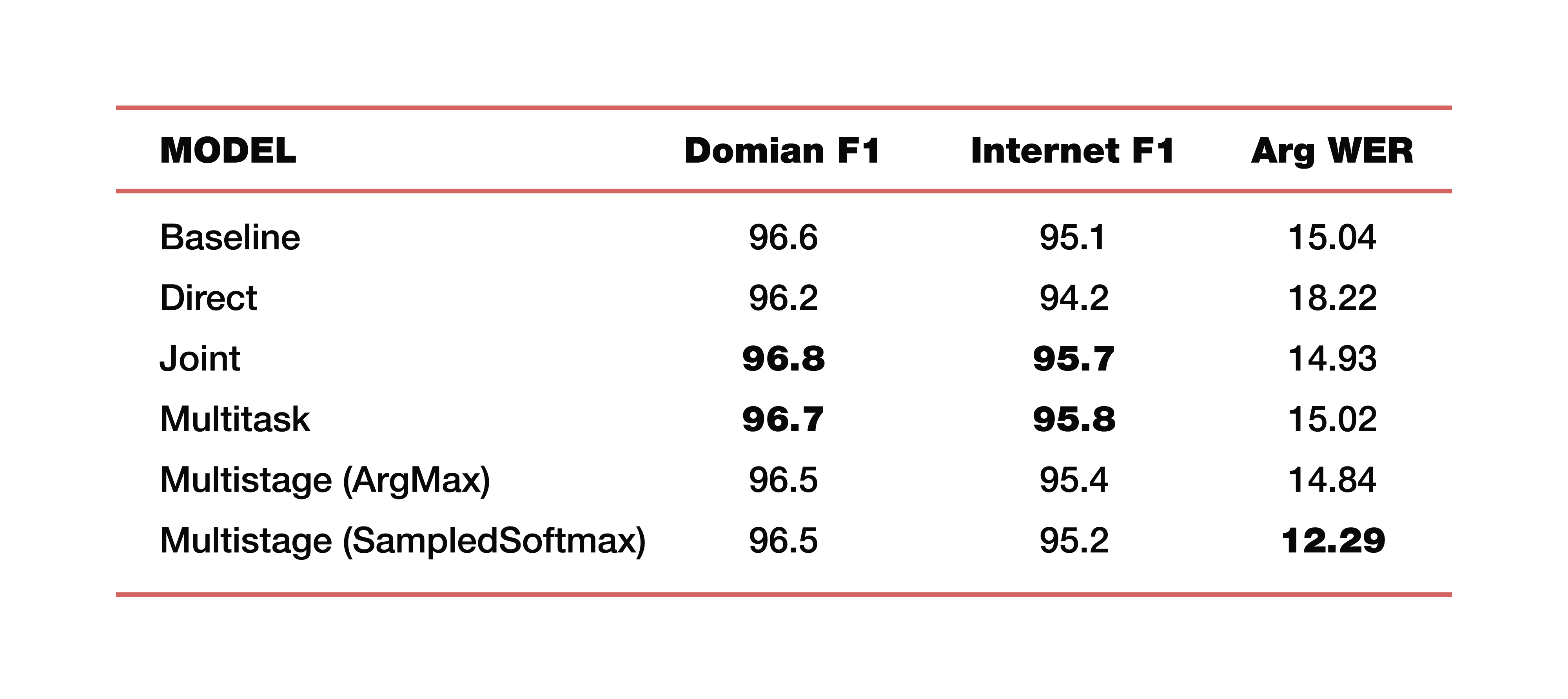
Zum Verständnis ist Baseline ein klassischer Ansatz, der, wie eingangs erwähnt, aus zwei Komponenten besteht. Im Folgenden finden Sie Beispiele für direkte, verbundene, Multitask- und mehrstufige Modelle.
Was kosten zwei mehrstufige Modelle? Gerade an der Verbindungsstelle des ersten und zweiten Teils wurden verschiedene Schichten verwendet. Im ersten Fall ist dies ArgMax, im zweiten Fall SampedSoftmax.
Worauf sollte man achten? Der klassische Ansatz verliert in allen drei Metriken, die eine Schätzung der direkten Zusammenarbeit dieser beiden Komponenten darstellen. Ja, wir sind nicht daran interessiert, wie gut die Transkription dort durchgeführt wird, wir sind nur daran interessiert, wie gut das Element, das die semantische Struktur vorhersagt, funktioniert. Es wird anhand von drei Metriken ausgewertet: F1 - nach Thema, F1 - nach Absicht und ArgWer-Metrik, die von den Argumenten von Entitäten berücksichtigt wird. F1 wird als gewichteter Durchschnitt zwischen Genauigkeit und Vollständigkeit angesehen. Das heißt, der Standard ist 100. ArgWer ist im Gegenteil kein Erfolg, es ist ein Fehler, das heißt, hier ist der Standard 0.
Es ist erwähnenswert, dass unsere gekoppelten und Multitasking-Modelle alle Klassifizierungsmodelle für Themen und Absichten vollständig übertreffen. Und das mehrstufige Modell weist einen sehr starken Anstieg des gesamten ArgWer auf. Warum ist das wichtig? Denn bei den Aufgaben, die mit dem Verstehen der Umgangssprache verbunden sind, ist die letzte Aktion wichtig, die in der für die Geschäftslogik verantwortlichen Komponente ausgeführt wird. Dies hängt nicht direkt von den von ASR erstellten Transkriptionen ab, sondern von der Qualität der ASR- und NLU-Komponenten, die zusammenarbeiten. Daher ist eine Differenz von fast drei Punkten in der argWER-Metrik ein sehr cooler Indikator, der den Erfolg dieses Ansatzes anzeigt. Es ist auch erwähnenswert, dass alle Ansätze durch Definition von Themen und Absichten vergleichbare Werte haben.
Ich werde einige Beispiele für die Verwendung solcher Algorithmen zum Verständnis der Konversationssprache geben. Wenn Google über die Aufgaben des Verstehens von Konversationssprache spricht, stellt es in erster Linie die Mensch-Computer-Schnittstellen fest, dh alle Arten von virtuellen Assistenten wie Google Assistant, Apple Siri, Amazon Alexa usw. Als zweites Beispiel ist ein Aufgabenpool wie Interactive Voice Response zu erwähnen. Das heißt, dies ist eine bestimmte Geschichte, die sich mit der Automatisierung von Call Centern befasst.
Daher untersuchten wir Ansätze mit der Möglichkeit der gemeinsamen Optimierung, um das Modell auf Fehler zu konzentrieren, die für SLUs wichtiger sind. Diese Herangehensweise an die Aufgabe, die gesprochene Sprache zu verstehen, vereinfacht die Gesamtkomplexität erheblich.
Wir haben die Möglichkeit, eine logische Schlussfolgerung zu ziehen, dh eine Art Ergebnis zu erzielen, ohne dass zusätzliche Ressourcen wie das Lexikon, Sprachmodelle, Analysatoren usw. erforderlich sind (d. H. Dies sind alles Faktoren, die dem klassischen Ansatz inhärent sind). Die Aufgabe wird „direkt“ gelöst.
In der Tat kann man dort nicht aufhören. Und wenn wir jetzt die beiden Ansätze, die beiden Komponenten einer gemeinsamen Struktur, kombiniert haben, können wir mehr anstreben. Kombinieren Sie sowohl die drei als auch die vier Komponenten - kombinieren Sie diese logische Kette einfach weiter und setzen Sie die Wichtigkeit von Fehlern angesichts der bereits vorhandenen Kritikalität auf ein niedrigeres Niveau durch. Dadurch können wir die Genauigkeit der Problemlösung erhöhen.