
Ich lebe in einer guten Stadt. Aber wie bei vielen anderen wird die Suche nach einem Parkplatz immer zum Test. Freie Plätze sind schnell besetzt, und selbst wenn Sie eigene haben, wird es für Freunde schwierig sein, Sie anzurufen, da sie nirgendwo parken können.
Also habe ich beschlossen, die Kamera aus dem Fenster zu richten und Deep Learning zu verwenden, damit mein Computer mir sagt, wann der Platz verfügbar ist:

Es mag kompliziert klingen, aber tatsächlich ist das Schreiben eines funktionierenden Prototyps mit tiefem Lernen schnell und einfach. Alle notwendigen Komponenten sind bereits vorhanden - Sie müssen nur wissen, wo Sie sie finden und wie Sie sie zusammensetzen können.
Also lasst uns Spaß haben und ein genaues kostenloses Parkbenachrichtigungssystem mit Python und Deep Learning schreiben
Aufgabe zerlegen
Wenn wir eine schwierige Aufgabe haben, die wir mit maschinellem Lernen lösen möchten, besteht der erste Schritt darin, sie in eine Folge einfacher Aufgaben aufzuteilen. Dann können wir verschiedene Werkzeuge verwenden, um jedes von ihnen zu lösen. Durch die Kombination mehrerer einfacher Lösungen erhalten wir ein System, das zu etwas Komplexem fähig ist.
So habe ich meine Aufgabe gebrochen:

Der auf das Fenster gerichtete Videostream von der Webcam wird in die Förderereingabe eingegeben:

Über die Pipeline übertragen wir jedes Bild des Videos einzeln.
Der erste Schritt besteht darin, alle möglichen Parkplätze im Rahmen zu erkennen. Bevor wir nach unbesetzten Plätzen suchen können, müssen wir natürlich verstehen, in welchen Teilen des Bildes sich Parkplätze befinden.
Dann müssen Sie auf jedem Rahmen alle Autos finden. Auf diese Weise können wir die Bewegung jeder Maschine von Bild zu Bild verfolgen.
Der dritte Schritt besteht darin, festzustellen, welche Plätze von Maschinen belegt sind und welche nicht. Kombinieren Sie dazu die Ergebnisse der ersten beiden Schritte.
Schließlich sollte das Programm eine Warnung senden, wenn der Parkplatz frei wird. Dies wird durch Änderungen der Position der Maschinen zwischen den Bildern des Videos bestimmt.
Jeder dieser Schritte kann auf unterschiedliche Weise mit unterschiedlichen Technologien ausgeführt werden. Es gibt keinen einzigen richtigen oder falschen Weg, um diesen Förderer zusammenzusetzen, verschiedene Ansätze haben ihre Vor- und Nachteile. Lassen Sie uns jeden Schritt genauer behandeln.
Wir erkennen Parkplätze
Folgendes sieht unsere Kamera:

Wir müssen dieses Bild irgendwie scannen und eine Liste der Parkplätze erhalten:

Die Lösung „in der Stirn“ wäre, die Positionen aller Parkplätze einfach manuell fest zu codieren, anstatt sie automatisch zu erkennen. In diesem Fall müssen wir den gesamten Vorgang erneut ausführen, wenn wir die Kamera bewegen oder nach Parkplätzen in einer anderen Straße suchen möchten. Es klingt so lala, also suchen wir nach einer automatischen Methode, um Parkplätze zu erkennen.
Alternativ können Sie im Bild nach Parkuhren suchen und davon ausgehen, dass sich neben jeder Parkuhr ein Parkplatz befindet:

Bei diesem Ansatz ist jedoch nicht alles so reibungslos. Erstens hat nicht jeder Parkplatz eine Parkuhr, und tatsächlich sind wir mehr daran interessiert, Parkplätze zu finden, für die Sie nicht bezahlen müssen. Zweitens sagt uns die Position der Parkuhr nichts darüber aus, wo sich der Parkplatz befindet, sondern lässt uns nur eine Annahme treffen.
Eine andere Idee besteht darin, ein Objekterkennungsmodell zu erstellen, das nach auf der Straße gezeichneten Parkmarkierungen sucht:

Aber dieser Ansatz ist so lala. Erstens sind in meiner Stadt alle diese Markierungen sehr klein und aus der Ferne schwer zu erkennen, so dass es schwierig sein wird, sie mit einem Computer zu erkennen. Zweitens ist die Straße voller allerlei anderer Linien und Markierungen. Es wird schwierig sein, Parkmarken von Fahrspurtrennern und Fußgängerüberwegen zu trennen.
Wenn Sie auf ein Problem stoßen, das auf den ersten Blick schwierig erscheint, nehmen Sie sich ein paar Minuten Zeit, um einen anderen Lösungsansatz zu finden, mit dem Sie einige technische Probleme umgehen können. Was gibt es einen Parkplatz? Dies ist nur ein Ort, an dem ein Auto lange Zeit geparkt ist. Vielleicht müssen wir Parkplätze überhaupt nicht erkennen. Warum erkennen wir nicht einfach die Autos, die lange still stehen und gehen nicht davon aus, dass sie auf dem Parkplatz stehen?
Mit anderen Worten, Parkplätze befinden sich dort, wo Autos lange stehen:

Wenn wir also die Autos erkennen und herausfinden können, welche sich nicht zwischen den Rahmen bewegen, können wir erraten, wo sich die Parkplätze befinden. So einfach ist das - gehen Sie zur Maschinenerkennung!
Autos erkennen
Das Erkennen von Autos auf einem Videorahmen ist eine klassische Objekterkennungsaufgabe. Es gibt viele Ansätze des maschinellen Lernens, die wir zur Erkennung verwenden könnten. Hier sind einige davon in der Reihenfolge von der "alten Schule" zur "neuen Schule":
- Sie können den Detektor basierend auf HOG (Histogramm orientierter Gradienten, Histogramme gerichteter Gradienten) trainieren und ihn durch das gesamte Bild führen, um alle Autos zu finden. Dieser alte Ansatz, bei dem kein tiefes Lernen verwendet wird, funktioniert relativ schnell, kommt jedoch mit Maschinen, die sich auf unterschiedliche Weise befinden, nicht sehr gut zurecht.
- Sie können den CNN-basierten Detektor (Convolutional Neural Network, ein Convolutional Neural Network) trainieren und ihn durch das gesamte Bild führen, bis wir alle Maschinen gefunden haben. Dieser Ansatz funktioniert genau, aber nicht so effizient, da wir das Bild mehrmals mit CNN scannen müssen, um alle Maschinen zu finden. Und obwohl wir Maschinen auf unterschiedliche Weise finden können, benötigen wir viel mehr Trainingsdaten als für einen HOG-Detektor.
- Sie können einen neuen Ansatz mit Deep Learning wie Mask R-CNN, Faster R-CNN oder YOLO verwenden, der die Genauigkeit von CNN und eine Reihe technischer Tricks kombiniert, die die Erkennungsgeschwindigkeit erheblich erhöhen. Solche Modelle funktionieren relativ schnell (auf der GPU), wenn wir viele Daten haben, um das Modell zu trainieren.
Im allgemeinen Fall benötigen wir die einfachste Lösung, die ordnungsgemäß funktioniert und die geringste Menge an Trainingsdaten erfordert. Dies muss nicht der neueste und schnellste Algorithmus sein. Insbesondere in unserem Fall ist Mask R-CNN jedoch eine vernünftige Wahl, obwohl es recht neu und schnell ist.
Die R-CNN-Architektur der Maske ist so konzipiert, dass sie Objekte im gesamten Bild erkennt, Ressourcen effektiv verbraucht und nicht den Schiebefensteransatz verwendet. Mit anderen Worten, es funktioniert ziemlich schnell. Mit einer modernen GPU können wir Objekte in Videos in hoher Auflösung mit einer Geschwindigkeit von mehreren Bildern pro Sekunde erkennen. Für unser Projekt sollte dies ausreichen.
Darüber hinaus bietet Mask R-CNN viele Informationen zu jedem erkannten Objekt. Die meisten Erkennungsalgorithmen geben für jedes Objekt nur einen Begrenzungsrahmen zurück. Die Maske R-CNN gibt uns jedoch nicht nur die Position jedes Objekts, sondern auch dessen Umriss (Maske):

Um Mask R-CNN zu trainieren, benötigen wir viele Bilder von Objekten, die wir erkennen möchten. Wir könnten nach draußen gehen, Fotos von Autos machen und sie auf Fotos markieren, was mehrere Arbeitstage erfordern würde. Glücklicherweise gehören Autos zu den Objekten, die Menschen häufig erkennen möchten. Daher existieren bereits mehrere öffentliche Datensätze mit Bildern von Autos.
Eines davon ist das beliebte SOCO-
Dataset (kurz für Common Objects In Context), dessen Bilder mit Objektmasken versehen sind. Dieser Datensatz enthält über 12.000 Bilder mit bereits gekennzeichneten Maschinen. Hier ist ein Beispielbild aus dem Datensatz:

Solche Daten eignen sich hervorragend zum Trainieren eines auf Mask R-CNN basierenden Modells.
Aber halt die Pferde, es gibt noch bessere Neuigkeiten! Wir sind nicht die ersten, die ihr Modell anhand des COCO-Datensatzes trainieren wollten - viele Menschen haben dies bereits vor uns getan und ihre Ergebnisse geteilt. Anstatt unser Modell zu trainieren, können wir daher ein fertiges Modell nehmen, das bereits Autos erkennt. Für unser Projekt werden wir das
Open-Source-Modell von Matterport verwenden.Wenn wir dem Eingang dieses Modells ein Bild von der Kamera geben, erhalten wir dies bereits „out of the box“:

Das Modell erkannte nicht nur Autos, sondern auch Objekte wie Ampeln und Personen. Es ist lustig, dass sie den Baum als Zimmerpflanze erkannte.
Für jedes erkannte Objekt gibt das Mask R-CNN-Modell 4 Dinge zurück:
- Art des erkannten Objekts (Ganzzahl). Das vorgefertigte COCO-Modell kann 80 verschiedene gemeinsame Objekte wie Autos und Lastwagen erkennen. Eine vollständige Liste finden Sie hier.
- Der Grad des Vertrauens in die Erkennungsergebnisse. Je höher die Zahl, desto stärker ist das Modell von der Erkennung des Objekts überzeugt.
- Ein Begrenzungsrahmen für ein Objekt in Form von XY-Koordinaten von Pixeln im Bild.
- Eine „Maske“, die anzeigt, welche Pixel innerhalb des Begrenzungsrahmens Teil des Objekts sind. Mithilfe der Maskendaten können Sie den Umriss des Objekts ermitteln.
Unten finden Sie den Python-Code zum Erkennen des Begrenzungsrahmens für Maschinen mithilfe der vorab trainierten Modelle Mask R-CNN und OpenCV:
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path
Nach dem Ausführen dieses Skripts wird auf dem Bildschirm ein Bild mit einem Rahmen um jeden erkannten Computer angezeigt:

Außerdem werden die Koordinaten jeder Maschine in der Konsole angezeigt:
Cars found in frame of video: Car: [492 871 551 961] Car: [450 819 509 913] Car: [411 774 470 856]
So haben wir gelernt, Autos im Bild zu erkennen.
Wir erkennen leere Parkplätze
Wir kennen die Pixelkoordinaten jeder Maschine. Wenn wir mehrere aufeinanderfolgende Frames durchsehen, können wir leicht feststellen, welches der Autos sich nicht bewegt hat, und davon ausgehen, dass es Parkplätze gibt. Aber wie kann man verstehen, dass das Auto den Parkplatz verlassen hat?
Das Problem ist, dass sich die Rahmen der Maschinen teilweise überlappen:

Wenn Sie sich also vorstellen, dass jeder Rahmen einen Parkplatz darstellt, kann sich herausstellen, dass er teilweise von der Maschine belegt ist, obwohl er tatsächlich leer ist. Wir müssen einen Weg finden, um den Schnittgrad zweier Objekte zu messen, um nur nach den „leersten“ Frames zu suchen.
Wir werden ein Maß namens Intersection Over Union (Verhältnis von Schnittfläche zu Gesamtfläche) oder IoU verwenden. IoU kann ermittelt werden, indem die Anzahl der Pixel berechnet wird, an denen sich zwei Objekte schneiden, und durch die Anzahl der von diesen Objekten belegten Pixel dividiert wird:
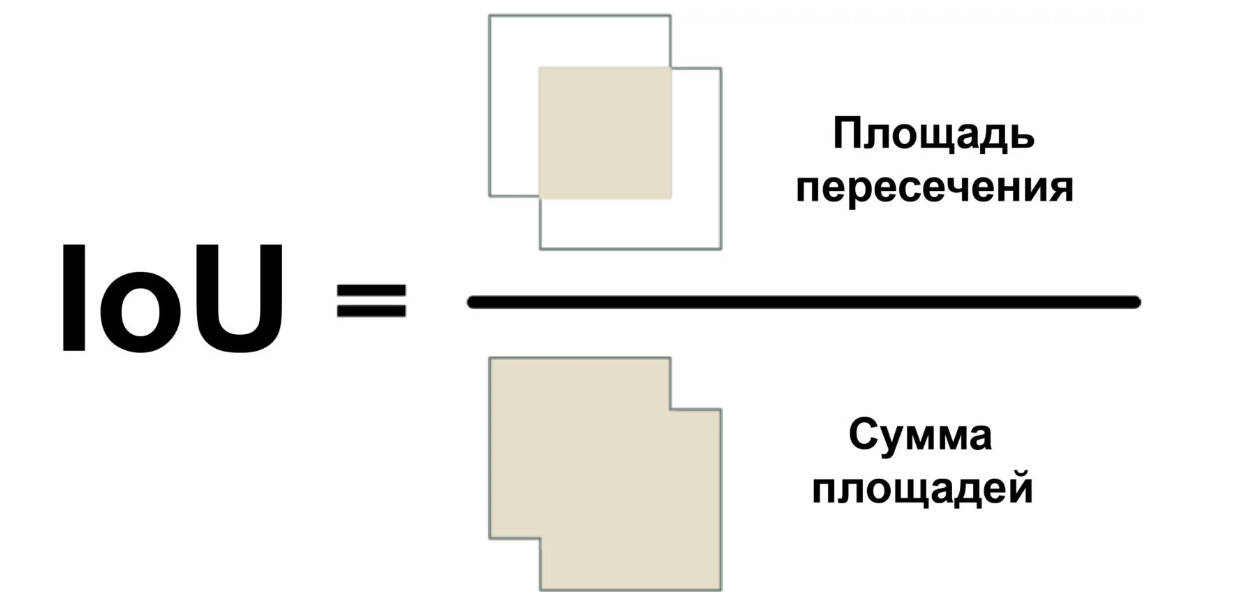
So können wir verstehen, wie sich der sehr begrenzende Rahmen des Autos mit dem Rahmen des Parkplatzes schneidet. Auf diese Weise können Sie leicht feststellen, ob das Parken kostenlos ist. Wenn der IoU-Wert niedrig ist, wie z. B. 0,15, nimmt das Auto einen kleinen Teil des Parkplatzes ein. Und wenn es hoch ist, wie 0,6, bedeutet dies, dass das Auto den größten Teil des Platzes einnimmt und Sie dort nicht parken können.
Da IoU in der Bildverarbeitung häufig verwendet wird, ist es sehr wahrscheinlich, dass die entsprechenden Bibliotheken diese Maßnahme implementieren. In unserer Bibliothek Mask R-CNN ist sie als Funktion mrcnn.utils.compute_overlaps () implementiert.
Wenn wir eine Liste von Begrenzungsrahmen für Parkplätze haben, können Sie eine Überprüfung auf das Vorhandensein von Autos in diesem Rahmen hinzufügen, indem Sie eine oder zwei ganze Codezeilen hinzufügen:
Das Ergebnis sollte ungefähr so aussehen:
[ [1. 0.07040032 0. 0.] [0.07040032 1. 0.07673165 0.] [0. 0. 0.02332112 0.] ]
In diesem zweidimensionalen Array spiegelt jede Zeile einen Rahmen des Parkplatzes wider. Und jede Spalte gibt an, wie stark sich jeder Ort mit einer der erkannten Maschinen schneidet. Ein Ergebnis von 1,0 bedeutet, dass der gesamte Platz vollständig vom Auto belegt ist, und ein niedriger Wert wie 0,02 zeigt an, dass das Auto ein wenig an seinen Platz geklettert ist, aber Sie können trotzdem darauf parken.
Um nicht belegte Plätze zu finden, müssen Sie nur jede Zeile in diesem Array überprüfen. Wenn alle Zahlen nahe Null sind, ist der Platz höchstwahrscheinlich frei!
Beachten Sie jedoch, dass die Objekterkennung bei Echtzeitvideos nicht immer perfekt funktioniert. Obwohl das auf Mask R-CNN basierende Modell ziemlich genau ist, kann es von Zeit zu Zeit ein oder zwei Autos in einem Frame des Videos vermissen. Bevor Sie behaupten, dass der Platz frei ist, müssen Sie daher sicherstellen, dass dies auch für die nächsten 5 bis 10 nächsten Videobilder der Fall ist. Auf diese Weise können wir Situationen vermeiden, in denen das System fälschlicherweise einen leeren Platz aufgrund eines Fehlers in einem Bild des Videos markiert. Sobald wir sicherstellen, dass der Platz für mehrere Frames frei bleibt, können Sie eine Nachricht senden!
SMS senden
Der letzte Teil unseres Förderers sendet SMS-Benachrichtigungen, wenn ein freier Parkplatz angezeigt wird.
Das Senden einer Nachricht von Python ist sehr einfach, wenn Sie Twilio verwenden. Twilio ist eine beliebte API, mit der Sie SMS aus nahezu jeder Programmiersprache mit nur wenigen Codezeilen senden können. Wenn Sie einen anderen Dienst bevorzugen, können Sie ihn natürlich nutzen. Ich habe nichts mit Twilio zu tun, es ist nur das erste, was mir in den Sinn kommt.
Um Twilio zu verwenden, melden Sie sich für ein Testkonto an, erstellen Sie eine Twilio-Telefonnummer und erhalten Sie Informationen zur Kontoauthentifizierung. Installieren Sie dann die Client-Bibliothek:
$ pip3 install twilio
Verwenden Sie danach den folgenden Code, um die Nachricht zu senden:
from twilio.rest import Client
Kopieren Sie diesen Code einfach dorthin, um die Möglichkeit zum Senden von Nachrichten an unser Skript hinzuzufügen. Sie müssen jedoch sicherstellen, dass die Nachricht nicht in jedem Frame gesendet wird, in dem Sie den freien Speicherplatz sehen können. Daher haben wir ein Flag, das im installierten Zustand das Senden von Nachrichten für einige Zeit oder bis ein anderer Ort frei ist, nicht zulässt.
Alles zusammenfügen
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path from twilio.rest import Client
Um diesen Code auszuführen, müssen Sie zuerst Python 3.6+,
Matterport Mask R-CNN und
OpenCV installieren.
Ich habe den Code speziell so einfach wie möglich geschrieben. Wenn er zum Beispiel im ersten Frame ein Auto sieht, kommt er zu dem Schluss, dass alle geparkt sind. Versuchen Sie, damit zu experimentieren, und prüfen Sie, ob Sie die Zuverlässigkeit verbessern können.
Durch einfaches Ändern der Bezeichner der Objekte, nach denen das Modell sucht, können Sie den Code in etwas völlig anderes verwandeln. Stellen Sie sich zum Beispiel vor, Sie arbeiten in einem Skigebiet. Nach einigen Änderungen können Sie dieses Skript in ein System verwandeln, das Snowboarder, die von einer Rampe springen, automatisch erkennt und Videos mit coolen Sprüngen aufzeichnet. Wenn Sie in einem Naturschutzgebiet arbeiten, können Sie auch ein System erstellen, das Zebras zählt. Sie sind nur durch Ihre Vorstellungskraft begrenzt.
Weitere solche Artikel finden Sie im Telegrammkanal
Neuron (@neurondata)
Link zur alternativen Übersetzung:
tproger.ru/translations/parking-searching/Alles Wissen. Experimentieren Sie!