Die heutige KI ist technisch „schwach“ - sie ist jedoch komplex und kann die Gesellschaft erheblich beeinflussen
 Sie müssen nicht Cyrus Dully sein, um zu wissen, wie furchterregend eine intelligente Intelligenz werden kann [ein amerikanischer Schauspieler, der die Rolle des Astronauten Dave Bowman in dem Film "Space Odyssey 2001" / ca. perev.]
Sie müssen nicht Cyrus Dully sein, um zu wissen, wie furchterregend eine intelligente Intelligenz werden kann [ein amerikanischer Schauspieler, der die Rolle des Astronauten Dave Bowman in dem Film "Space Odyssey 2001" / ca. perev.]KI oder künstliche Intelligenz ist heute einer der wichtigsten Wissensbereiche. "Unlösbare" Probleme werden gelöst, Milliarden von Dollar werden investiert, und Microsoft
beauftragt Common sogar, uns in poetischer Ruhe zu sagen, was für eine wunderbare Sache das ist - KI. Das stimmt.
Und wie bei jeder neuen Technologie kann es schwierig sein, diesen ganzen Hype zu überstehen. Ich forsche seit Jahren auf dem Gebiet der Drohnen und KI, aber selbst es kann schwierig für mich sein, mit all dem Schritt zu halten. In den letzten Jahren habe ich viel Zeit damit verbracht, nach Antworten auf die einfachsten Fragen zu suchen, wie zum Beispiel:
- Was meinen die Leute mit "KI"?
- Was ist der Unterschied zwischen KI, maschinellem Lernen und tiefem Lernen?
- Was ist so toll an Deep Learning?
- Welche früheren schwierigen Aufgaben sind jetzt leicht zu lösen und was ist noch schwierig?
Ich weiß, dass sich niemand für solche Dinge interessiert. Wenn Sie sich also dafür interessieren, was all diese Begeisterung für KI auf der einfachsten Ebene miteinander verbindet, ist es Zeit, hinter die Kulissen zu schauen. Wenn Sie ein KI-Experte sind und zum Spaß Berichte von der Konferenz über neurologische Informationsverarbeitung (NIPS) lesen, ist der Artikel für Sie nichts Neues. Wir erwarten jedoch Klarstellungen und Korrekturen von Ihnen in den Kommentaren.
Was ist KI?
In der Informatik gibt es einen so alten Witz: Was ist der Unterschied zwischen KI und Automatisierung? Automatisierung kann mit einem Computer durchgeführt werden, und KI möchten wir gerne tun. Sobald wir lernen, wie man etwas macht, wechselt es vom Bereich der KI in die Kategorie der Automatisierung.
Dieser Witz ist heute gültig, da die KI nicht klar genug definiert ist. Künstliche Intelligenz ist einfach kein Fachbegriff. Wenn Sie in Wikipedia einsteigen, heißt es, dass KI "die Intelligenz ist, die von Maschinen demonstriert wird, im Gegensatz zu der natürlichen Intelligenz, die von Menschen und anderen Tieren demonstriert wird". Sie können nicht weniger klar sagen.
Im Allgemeinen gibt es zwei Arten von KI: stark und schwach. Die meisten Menschen stellen sich eine starke KI vor, wenn sie von KI hören - es ist eine Art gottähnlicher allwissender Intellekt wie Skynet oder Hal 9000, der in der Lage ist zu argumentieren und mit dem Menschen vergleichbar ist, während er seine Fähigkeiten übertrifft.
Schwache AIs sind hochspezialisierte Algorithmen zur Beantwortung spezifischer nützlicher Fragen in eng definierten Bereichen. Zum Beispiel fällt ein sehr gutes Schachprogramm in diese Kategorie. Gleiches gilt für Software, die Versicherungszahlungen sehr genau anpasst. Auf ihrem Gebiet erzielen solche AIs beeindruckende Ergebnisse, sind jedoch im Allgemeinen sehr begrenzt.
Mit Ausnahme von Hollywood-Opussen sind wir heute noch nicht einmal einer starken KI nahe gekommen. Bisher ist jede KI schwach, und die meisten Forscher in diesem Bereich sind sich einig, dass die Techniken, die wir erfunden haben, um große schwache KI zu erzeugen, uns der Schaffung einer starken KI wahrscheinlich nicht näher bringen werden.
Die heutige KI ist also eher ein Marketingbegriff als ein technischer. Der Grund, warum Unternehmen ihre KI anstelle von Automatisierung bewerben, liegt darin, dass sie Hollywood-KI in die Öffentlichkeit bringen möchten. Das ist jedoch nicht so schlimm. Wenn dies nicht zu streng genommen wird, wollen die Unternehmen nur sagen, dass die schwache KI von heute, obwohl wir noch sehr weit von einer starken KI entfernt sind, viel leistungsfähiger ist als vor einigen Jahren.
Und wenn Sie vom Marketing ablenken, dann ist es so. In bestimmten Bereichen haben die Fähigkeiten von Maschinen dramatisch zugenommen, und zwar hauptsächlich dank zweier weiterer Sätze, die heute in Mode sind: maschinelles Lernen und tiefes Lernen.
 Aufgenommen aus einem kurzen Video von Facebook-Ingenieuren, das zeigt, wie Echtzeit-KI Katzen erkennt (eine Aufgabe, die auch als heiliger Gral des Internets bekannt ist).
Aufgenommen aus einem kurzen Video von Facebook-Ingenieuren, das zeigt, wie Echtzeit-KI Katzen erkennt (eine Aufgabe, die auch als heiliger Gral des Internets bekannt ist).Maschinelles Lernen
MO ist eine spezielle Methode, um Maschinenintelligenz zu erstellen. Angenommen, Sie möchten eine Rakete starten und vorhersagen, wohin sie fliegen wird. Im Allgemeinen ist es nicht so schwierig: Die Schwerkraft ist ziemlich gut untersucht. Sie können die Gleichungen aufschreiben und anhand verschiedener Variablen - wie Geschwindigkeit und Ausgangsposition - berechnen, wohin sie gehen wird.
Dieser Ansatz wird jedoch umständlich, wenn wir uns einem Bereich zuwenden, dessen Regeln nicht so bekannt und klar sind. Angenommen, der Computer möchte Ihnen mitteilen, ob auf einigen Bildern Katzen vorhanden sind. Wie werden Sie die Regeln aufschreiben, die die Ansicht unter allen möglichen Gesichtspunkten für alle möglichen Kombinationen von Schnurrbart und Ohren beschreiben?
Heutzutage ist der MO-Ansatz bekannt: Anstatt zu versuchen, alle Regeln aufzuschreiben, erstellen Sie ein System, das nach dem Studium einer Vielzahl von Beispielen unabhängig voneinander eine Reihe interner Regeln ableiten kann. Anstatt Katzen zu beschreiben, zeigen Sie Ihrer KI einfach ein paar Fotos von Katzen und lassen ihn selbst verstehen, was eine Katze ist und was nicht.
Und heute ist es der perfekte Ansatz. Ein auf Daten basierendes selbstlernendes System kann einfach durch Hinzufügen von Daten verbessert werden. Und wenn unsere Spezies etwas sehr gut kann, ist es, Daten zu generieren, zu speichern und zu verwalten. Möchten Sie lernen, wie Sie Katzen besser erkennen können? Das Internet generiert in dieser Minute Millionen von Beispielen.
Der ständig wachsende Datenfluss ist einer der Gründe für das explosive Wachstum von MO-Algorithmen in jüngster Zeit. Andere Gründe hängen mit der Verwendung dieser Daten zusammen.
Zusätzlich zu den Daten gibt es zwei weitere Probleme im Zusammenhang mit der Region Moskau:
- Wie erinnere ich mich an das, was ich gelernt habe? Wie speichere und präsentiere ich die Kommunikationen und Regeln, die ich aus den Daten abgeleitet habe, auf dem Computer?
- Wie lerne ich? Wie kann man die gespeicherte Darstellung als Reaktion auf neue Beispiele ändern und verbessern?
Mit anderen Worten, was genau wird auf der Grundlage all dieser Daten trainiert?
In MO ist die rechnerische Darstellung des von uns gespeicherten Trainings ein Modell. Die Art des verwendeten Modells ist sehr wichtig: Es bestimmt, wie Ihre KI lernt, aus welchen Daten sie lernen kann und welche Fragen Sie ihr stellen können.
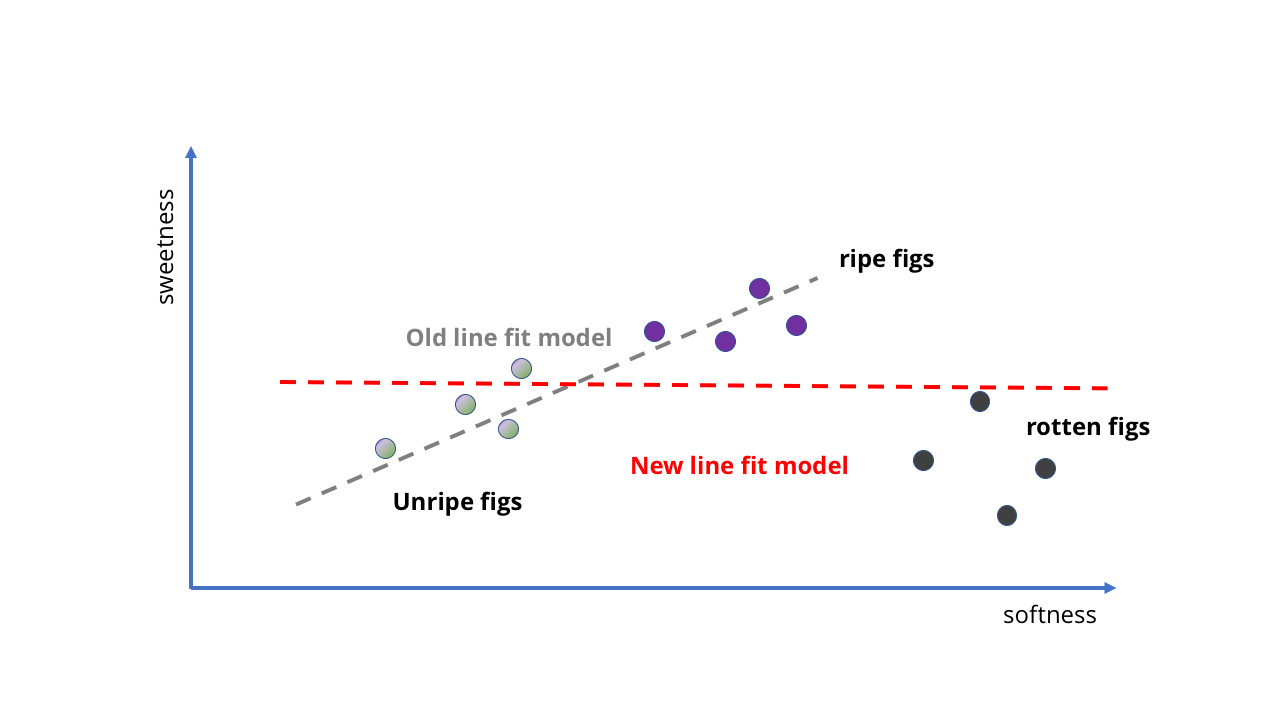
Schauen wir uns ein sehr einfaches Beispiel an. Angenommen, wir kaufen Feigen in einem Lebensmittelgeschäft und möchten mit dem MO eine KI erstellen, die uns sagt, ob sie reif ist. Dies sollte einfach zu bewerkstelligen sein, da bei Feigen je süßer, desto süßer.
Wir können mehrere Proben von reifen und unreifen Feigen nehmen, sehen, wie süß sie sind, und sie dann auf die Karte legen und die gerade Linie dafür anpassen. Diese Linie wird unser Modell sein.
 Embryo AI in Form von "je weicher desto süßer"
Embryo AI in Form von "je weicher desto süßer" Durch das Hinzufügen neuer Daten wird die Aufgabe komplizierter.
Durch das Hinzufügen neuer Daten wird die Aufgabe komplizierter.Schau mal! Die gerade Linie folgt implizit der Idee, dass "je weicher sie sind, desto süßer", und wir mussten nicht einmal etwas aufschreiben. Unser KI-Fötus weiß nichts über den Zuckergehalt oder die Reifung von Früchten, kann jedoch die Süße einer Frucht vorhersagen, indem er sie zusammendrückt.
Wie trainiere ich ein Modell, um es besser zu machen? Wir können noch mehr Proben sammeln und eine weitere gerade Linie zeichnen, um genauere Vorhersagen zu erhalten (wie im zweiten Bild oben). Die Probleme werden jedoch sofort offensichtlich. Bisher haben wir unsere Feigen-KI auf Qualitätsbeeren trainiert - was ist, wenn wir Daten aus dem Obstgarten entnehmen? Plötzlich haben wir nicht nur reife, sondern auch faule Früchte. Sie sind sehr weich, aber definitiv nicht zum Essen geeignet.
Was sollen wir tun? Nun, da dies ein MO-Modell ist, können wir ihr einfach mehr Daten geben, oder?
Wie das erste Bild unten zeigt, erhalten wir in diesem Fall völlig bedeutungslose Ergebnisse. Die Linie ist einfach nicht geeignet, um zu beschreiben, was passiert, wenn die Frucht zu reif wird. Unser Modell passt nicht mehr in die Datenstruktur.
Stattdessen müssen wir es ändern und ein besseres und komplexeres Modell verwenden - vielleicht eine Parabel oder ähnliches. Diese Änderung erschwert das Lernen, da das Zeichnen von Kurven eine komplexere Mathematik erfordert als das Zeichnen einer geraden Linie.
 Okay, wahrscheinlich war die Idee, eine gerade Linie für eine komplexe KI zu verwenden, nicht sehr erfolgreich
Okay, wahrscheinlich war die Idee, eine gerade Linie für eine komplexe KI zu verwenden, nicht sehr erfolgreich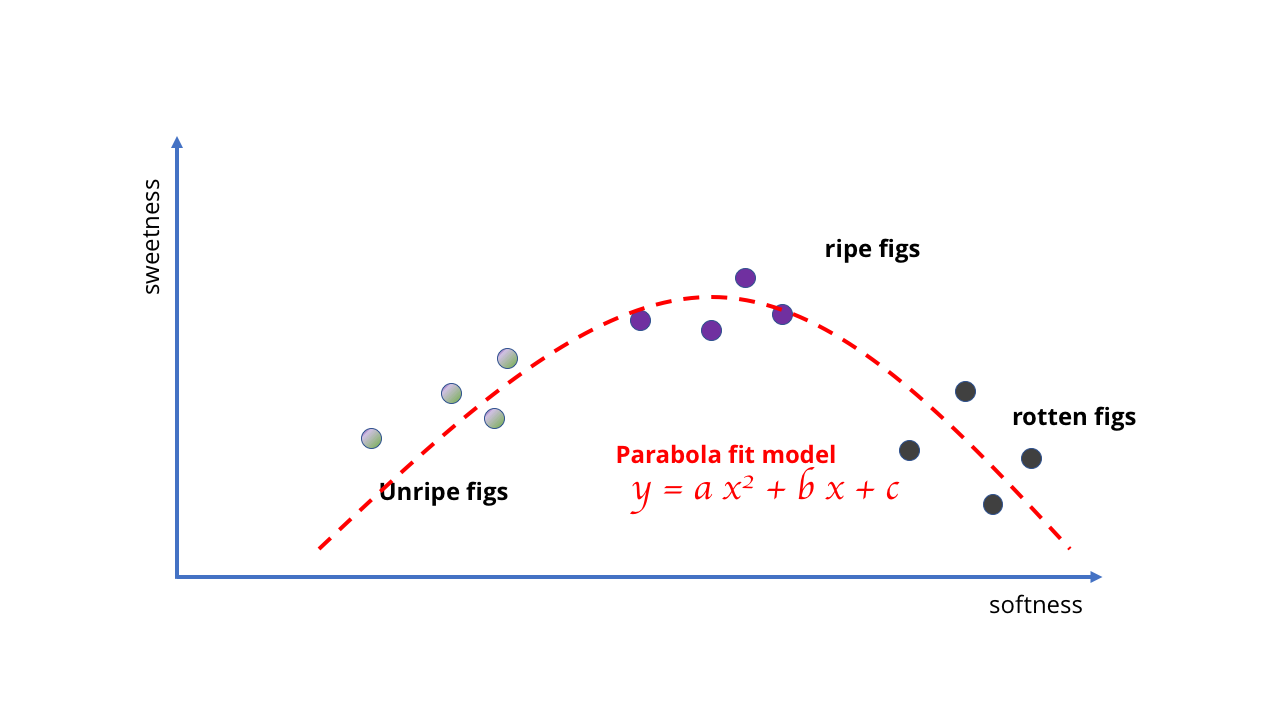 Kompliziertere Mathematik erforderlich
Kompliziertere Mathematik erforderlichDas Beispiel ist ziemlich dumm, aber es zeigt, dass die Wahl des Modells die Lernmöglichkeiten bestimmt. Im Fall von Feigen sind die Daten einfach und die Modelle können einfach sein. Wenn Sie jedoch versuchen, etwas Komplexeres zu lernen, sind komplexere Modelle erforderlich. So wie keine Datenmenge ein lineares Modell das Verhalten fauler Beeren widerspiegeln lässt, ist es unmöglich, eine einfache Kurve auszuwählen, die einer Reihe von Bildern entspricht, um einen Computer-Vision-Algorithmus zu erstellen.
Daher besteht die Schwierigkeit für das MO darin, die richtigen Modelle für die entsprechenden Aufgaben zu erstellen und auszuwählen. Wir brauchen ein Modell, das komplex genug ist, um die wirklich komplexen Beziehungen und Strukturen zu beschreiben, aber einfach genug, damit Sie damit arbeiten und es trainieren können. Obwohl das Internet, Smartphones usw. unglaubliche Datenberge geschaffen haben, aus denen wir lernen können, benötigen wir immer noch die richtigen Modelle, um diese Daten nutzen zu können.
Hier kommt Deep Learning ins Spiel.

Tiefes Lernen
Deep Learning ist maschinelles Lernen, das einen bestimmten Modelltyp verwendet: Deep Neural Networks.
Neuronale Netze sind eine Art MO-Modell, das für Berechnungen und Vorhersagen eine Struktur verwendet, die Neuronen im Gehirn ähnelt. Neuronen in neuronalen Netzen sind in Schichten organisiert: Jede Schicht führt eine Reihe einfacher Berechnungen durch und gibt die Antwort an die nächste weiter.
Das Schichtmodell ermöglicht komplexere Berechnungen. Ein einfaches Netzwerk mit einer kleinen Anzahl von Neuronenschichten reicht aus, um die oben verwendete gerade Linie oder Parabel zu reproduzieren. Tiefe neuronale Netze sind neuronale Netze mit einer großen Anzahl von Schichten, mit Dutzenden oder sogar Hunderten; daher ihr Name. Mit so vielen Ebenen können Sie unglaublich leistungsstarke Modelle erstellen.
Diese Gelegenheit ist einer der Hauptgründe für die große Beliebtheit tiefer neuronaler Netze in jüngster Zeit. Sie können verschiedene komplexe Dinge lernen, ohne einen menschlichen Forscher zu zwingen, Regeln zu definieren, und dies ermöglichte es uns, Algorithmen zu erstellen, die eine Vielzahl von Problemen lösen können, die Computer zuvor nicht angehen konnten.
Ein weiterer Aspekt trug jedoch zum Erfolg neuronaler Netze bei: das Training.
Der „Speicher“ eines Modells besteht aus einer Reihe numerischer Parameter, die bestimmen, wie Antworten auf gestellte Fragen gegeben werden. Ein Modell zu trainieren bedeutet, diese Parameter so zu optimieren, dass das Modell die bestmöglichen Antworten liefert.
In unserem Modell mit Feigen haben wir nach der Gleichung der Linie gesucht. Dies ist eine einfache Regressionsaufgabe, und es gibt Formeln, mit denen Sie die Antwort in einem Schritt erhalten.
 Einfaches neuronales Netzwerk und tiefes neuronales Netzwerk
Einfaches neuronales Netzwerk und tiefes neuronales NetzwerkBei komplexeren Modellen sind die Dinge nicht so einfach. Eine gerade Linie und eine Parabel können leicht durch mehrere Zahlen dargestellt werden, aber ein tiefes neuronales Netzwerk kann Millionen von Parametern haben, und der Datensatz für sein Training kann auch aus Millionen von Beispielen bestehen. Eine analytische Lösung in einem Schritt existiert nicht.
Glücklicherweise gibt es einen seltsamen Trick: Sie können mit einem schlechten neuronalen Netzwerk beginnen und es dann mit schrittweisen Optimierungen verbessern.
Das Erlernen des MO-Modells auf diese Weise ähnelt dem Testen eines Schülers mithilfe von Tests. Jedes Mal erhalten wir eine Bewertung, indem wir vergleichen, welche Antworten nach Meinung des Modells mit den „richtigen“ Antworten in den Trainingsdaten sein sollten. Dann machen wir eine Verbesserung und führen den Test erneut durch.
Woher wissen wir, welche Parameter wie viel angepasst werden müssen? Neuronale Netze haben eine so coole Funktion, dass Sie für viele Trainingsarten nicht nur eine Bewertung im Test erhalten, sondern auch berechnen können, wie stark sich diese als Reaktion auf eine Änderung der einzelnen Parameter ändert. In mathematischen Begriffen ist eine Schätzung eine Funktion des Wertes, und für die meisten dieser Funktionen können wir den Gradienten dieser Funktion in Bezug auf den Parameterraum leicht berechnen.
Jetzt wissen wir genau, auf welche Weise wir die Parameter anpassen müssen, um die Punktzahl zu erhöhen, und wir können das Netzwerk durch aufeinanderfolgende Schritte in die besten und besten „Richtungen“ anpassen, bis Sie einen Punkt erreichen, an dem nichts verbessert werden kann. Dies wird oft als Bergsteigen bezeichnet, weil es wirklich so ist, als würde man einen Hügel hinaufsteigen: Wenn man sich ständig hinaufbewegt, landet man oben.
 Hast du gesehen Top!
Hast du gesehen Top!Dank dessen ist es einfach, das neuronale Netzwerk zu verbessern. Wenn Ihr Netzwerk eine gute Struktur hat und neue Daten erhalten hat, müssen Sie nicht bei Null anfangen. Sie können mit den verfügbaren Parametern beginnen und aus den neuen Daten erneut lernen. Ihr Netzwerk wird sich allmählich verbessern. Die bekanntesten AIs von heute - von der Erkennung von Katzen auf Facebook bis zu Technologien, die Amazon (wahrscheinlich) in Geschäften ohne Verkäufer einsetzt - basieren auf dieser einfachen Tatsache.
Dies ist der Schlüssel zu einem weiteren Grund, warum sich der Zivilschutz so schnell und so weit verbreitet hat: Wenn Sie auf einen Hügel klettern, können Sie ein neuronales Netzwerk, das für eine bestimmte Aufgabe trainiert wurde, neu trainieren, um ein anderes, aber ähnliches auszuführen. Wenn Sie KI trainiert haben, um Katzen gut zu erkennen, können Sie mit diesem Netzwerk KI trainieren, die Hunde oder Giraffen erkennt, ohne von vorne anfangen zu müssen. Beginnen Sie mit der KI für Katzen, bewerten Sie sie anhand der Qualität der Hundeerkennung und erklimmen Sie dann den Hügel, um das Netzwerk zu verbessern!
Daher haben sich in den letzten 5 bis 6 Jahren die Fähigkeiten der KI stark verbessert. Einige Teile des Puzzles kamen auf synergistische Weise zusammen: Das Internet erzeugte eine große Menge an Daten, aus denen man lernen konnte. Berechnungen, insbesondere parallele Berechnungen auf GPUs, ermöglichten die Verarbeitung dieser riesigen Mengen. Schließlich ermöglichten tiefe neuronale Netze die Nutzung dieser Kits und die Erstellung unglaublich leistungsfähiger MO-Modelle.
Und all dies bedeutet, dass einige Dinge, die zuvor extrem schwierig waren, jetzt sehr einfach zu erledigen sind.
Und was können wir jetzt tun? Mustererkennung
Vielleicht der tiefste (Entschuldigung für das Wortspiel) und früheste Einfluss, den Deep Learning auf das Gebiet der Computer Vision hatte - insbesondere auf die Erkennung von Objekten in Fotografien. Vor einigen Jahren hat dieser xkcd-Comic den neuesten Stand der Informatik perfekt beschrieben:

Das Erkennen von Vögeln und sogar bestimmten Vogelarten ist heute eine triviale Aufgabe, die ein richtig motivierter Schüler lösen kann. Was hat sich geändert?
Die Idee der visuellen Erkennung von Objekten ist leicht zu beschreiben, aber schwer zu implementieren: Komplexe Objekte bestehen aus Mengen einfacherer Objekte, die wiederum aus einfacheren Formen und Linien bestehen. Gesichter bestehen aus Augen, Nasen und Mündern, und diese bestehen aus Kreisen und Linien und so weiter.
Daher wird die Gesichtserkennung zu einer Frage des Erkennens von Mustern, in denen sich Augen und Mund befinden, was möglicherweise das Erkennen der Form von Auge und Mund anhand von Linien und Kreisen erfordert.
Diese Muster werden als Merkmale bezeichnet, und vor dem gründlichen Lernen zur Erkennung mussten alle Merkmale manuell beschrieben und der Computer so programmiert werden, dass sie gefunden werden. Zum Beispiel gibt es den berühmten
Viola-Jones- Gesichtserkennungsalgorithmus, der auf der Tatsache basiert, dass Augenbrauen und Nase normalerweise heller sind als die Augenhöhlen, sodass sie eine helle T-Form mit zwei dunklen Punkten bilden. Der Algorithmus sucht tatsächlich nach ähnlichen T-Formen.
Die Viola-Jones-Methode funktioniert gut und ist überraschend schnell und dient als Grundlage für die Gesichtserkennung in billigen Kameras usw. Aber offensichtlich eignet sich nicht jedes Objekt, das Sie erkennen müssen, für eine solche Vereinfachung, und die Leute haben sich immer komplexere Muster auf niedriger Ebene ausgedacht. Damit die Algorithmen richtig funktionieren, war ein Team von Ärzten der Wissenschaften erforderlich, die sehr empfindlich und fehleranfällig waren.
Der große Durchbruch gelang dank des Zivilschutzes und insbesondere eines bestimmten neuronalen Netzwerks, das als Faltungs-Neuronales Netzwerk bezeichnet wird. Faltungs-Neuronale Netze, SNS, sind tiefe Netze mit einer bestimmten Struktur, die von der Struktur des visuellen Kortex des Gehirns von Säugetieren inspiriert ist. Diese Struktur ermöglicht es dem SNA, die Hierarchie von Linien und Mustern zum Erkennen von Objekten unabhängig zu lernen, anstatt darauf zu warten, dass Ärzte jahrelang nachforschen, welche Merkmale dafür am besten geeignet sind.
Zum Beispiel lernt der auf Gesicht trainierte SNA seine eigene interne Darstellung von Linien und Kreisen, die sich in Augen, Ohren und Nasen usw. bilden.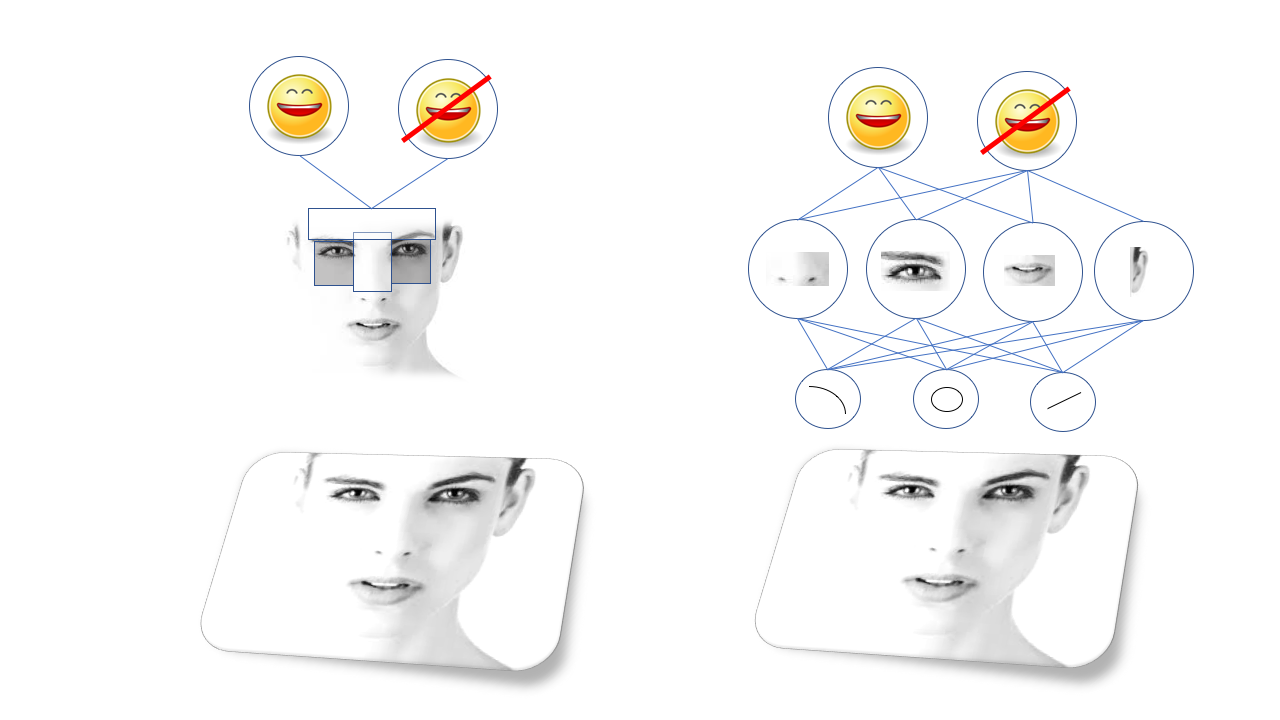 Alte visuelle Algorithmen (Viola-Jones-Methode links) stützen sich auf manuell ausgewählte Merkmale, und tiefe neuronale Netze (rechts) auf ihre eigene Hierarchie komplexerer Merkmale, die aus einfacherenSNAs bestehen, waren erstaunlich gut für die Bildverarbeitung, und bald konnten die Forscher sie für die Leistung trainieren Alle Arten von Aufgaben zur visuellen Erkennung, von der Suche nach Katzen auf dem Foto bis zur Identifizierung von Fußgängern, die in der Kamera eines Robomobils gefangen sind.Das ist alles wunderbar, aber es gibt noch einen weiteren Grund für die schnelle und weit verbreitete Verbreitung der SNA - so leicht passen sie sich an. Erinnerst du dich daran, einen Hügel bestiegen zu haben? Wenn unser Schüler einen bestimmten Vogel erkennen möchte, kann er eines der vielen visuellen Netzwerke mit Open Source-Code verwenden und ihn in seinem eigenen Datensatz trainieren, ohne zu verstehen, wie die zugrunde liegende Mathematik funktioniert.Dies kann natürlich noch weiter ausgebaut werden.
Alte visuelle Algorithmen (Viola-Jones-Methode links) stützen sich auf manuell ausgewählte Merkmale, und tiefe neuronale Netze (rechts) auf ihre eigene Hierarchie komplexerer Merkmale, die aus einfacherenSNAs bestehen, waren erstaunlich gut für die Bildverarbeitung, und bald konnten die Forscher sie für die Leistung trainieren Alle Arten von Aufgaben zur visuellen Erkennung, von der Suche nach Katzen auf dem Foto bis zur Identifizierung von Fußgängern, die in der Kamera eines Robomobils gefangen sind.Das ist alles wunderbar, aber es gibt noch einen weiteren Grund für die schnelle und weit verbreitete Verbreitung der SNA - so leicht passen sie sich an. Erinnerst du dich daran, einen Hügel bestiegen zu haben? Wenn unser Schüler einen bestimmten Vogel erkennen möchte, kann er eines der vielen visuellen Netzwerke mit Open Source-Code verwenden und ihn in seinem eigenen Datensatz trainieren, ohne zu verstehen, wie die zugrunde liegende Mathematik funktioniert.Dies kann natürlich noch weiter ausgebaut werden.Wer ist da? (Gesichtserkennung)
Angenommen, Sie möchten ein Netzwerk trainieren, das nicht nur Gesichter, sondern ein bestimmtes Gesicht erkennt. Sie können das Netzwerk trainieren, um eine bestimmte Person, dann eine andere Person usw. zu erkennen. Es braucht jedoch Zeit, um Netzwerke zu trainieren, und das würde bedeuten, dass für jede neue Person das Netzwerk neu geschult werden müsste. Nein, wirklich.Stattdessen können wir mit einem Netzwerk beginnen, das darauf trainiert ist, Gesichter im Allgemeinen zu erkennen. Ihre Neuronen sind so konfiguriert, dass sie alle Gesichtsstrukturen erkennen: Augen, Ohren, Münder und so weiter. Dann ändern Sie einfach die Ausgabe: Anstatt sie zu zwingen, bestimmte Gesichter zu erkennen, befehlen Sie ihr, eine Gesichtsbeschreibung in Form von Hunderten von Zahlen auszugeben, die die Krümmung der Nase oder die Form der Augen beschreiben, und so weiter. Das Netzwerk kann dies tun, weil es bereits „weiß“, aus welchen Komponenten das Gesicht besteht.Natürlich definieren Sie das alles nicht direkt. Stattdessen trainieren Sie das Netzwerk, indem Sie ihm eine Reihe von Gesichtern anzeigen und dann die Ausgabe vergleichen. Sie bringen ihr auch bei, dass sie Beschreibungen derselben Person ähnlich und sehr unterschiedliche Beschreibungen verschiedener Personen gibt. Mathematisch gesehen trainieren Sie ein Netzwerk, um eine Entsprechung zu den Bildern von Gesichtern eines Punkts in einem Raum von Merkmalen zu erstellen, wobei der kartesische Abstand zwischen Punkten verwendet werden kann, um deren Ähnlichkeit zu bestimmen. Das Ändern des neuronalen Netzwerks von der Gesichtserkennung (links) zur Beschreibung von Gesichtern (rechts) erfordert nur das Ändern des Formats der Ausgabedaten, ohne deren Basis zu ändern.
Das Ändern des neuronalen Netzwerks von der Gesichtserkennung (links) zur Beschreibung von Gesichtern (rechts) erfordert nur das Ändern des Formats der Ausgabedaten, ohne deren Basis zu ändern. Jetzt können Sie Gesichter erkennen, indem Sie die Beschreibungen der vom neuronalen Netzwerk erstellten Gesichter vergleichenNachdem Sie das Netzwerk trainiert haben, können Sie Gesichter leicht erkennen. Sie nehmen die ursprüngliche Person und erhalten ihre Beschreibung. Nehmen Sie dann ein neues Gesicht und vergleichen Sie die vom Netzwerk bereitgestellte Beschreibung mit Ihrem Original. Wenn sie nahe genug sind, sagen Sie, dass es ein und dieselbe Person ist. Und jetzt sind Sie von einem Netzwerk, das ein Gesicht erkennen kann, zu einem Netzwerk übergegangen, mit dem jedes Gesicht erkannt werden kann!Diese strukturelle Flexibilität ist ein weiterer Grund für die Nützlichkeit tiefer neuronaler Netze. Eine große Anzahl verschiedener MO-Modelle für Computer Vision wurde bereits entwickelt, und obwohl sie sich in sehr unterschiedliche Richtungen entwickeln, basiert die Grundstruktur vieler von ihnen auf so frühen SNAs wie Alexnet und Resnet.Ich habe sogar Geschichten über Menschen gehört, die visuelle neuronale Netze verwenden, um mit Zeitreihendaten oder Sensormessungen zu arbeiten. Anstatt ein spezielles Netzwerk zur Analyse des Datenflusses zu erstellen, trainierten sie ein Open-Source-neuronales Netzwerk, das für Computer Vision entwickelt wurde, um die Formen von Liniendiagrammen buchstäblich zu betrachten.Eine solche Flexibilität ist eine gute Sache, aber nicht unendlich. Um einige andere Probleme zu lösen, müssen Sie andere Netzwerktypen verwenden.
Jetzt können Sie Gesichter erkennen, indem Sie die Beschreibungen der vom neuronalen Netzwerk erstellten Gesichter vergleichenNachdem Sie das Netzwerk trainiert haben, können Sie Gesichter leicht erkennen. Sie nehmen die ursprüngliche Person und erhalten ihre Beschreibung. Nehmen Sie dann ein neues Gesicht und vergleichen Sie die vom Netzwerk bereitgestellte Beschreibung mit Ihrem Original. Wenn sie nahe genug sind, sagen Sie, dass es ein und dieselbe Person ist. Und jetzt sind Sie von einem Netzwerk, das ein Gesicht erkennen kann, zu einem Netzwerk übergegangen, mit dem jedes Gesicht erkannt werden kann!Diese strukturelle Flexibilität ist ein weiterer Grund für die Nützlichkeit tiefer neuronaler Netze. Eine große Anzahl verschiedener MO-Modelle für Computer Vision wurde bereits entwickelt, und obwohl sie sich in sehr unterschiedliche Richtungen entwickeln, basiert die Grundstruktur vieler von ihnen auf so frühen SNAs wie Alexnet und Resnet.Ich habe sogar Geschichten über Menschen gehört, die visuelle neuronale Netze verwenden, um mit Zeitreihendaten oder Sensormessungen zu arbeiten. Anstatt ein spezielles Netzwerk zur Analyse des Datenflusses zu erstellen, trainierten sie ein Open-Source-neuronales Netzwerk, das für Computer Vision entwickelt wurde, um die Formen von Liniendiagrammen buchstäblich zu betrachten.Eine solche Flexibilität ist eine gute Sache, aber nicht unendlich. Um einige andere Probleme zu lösen, müssen Sie andere Netzwerktypen verwenden. Und bis zu diesem Punkt haben virtuelle Assistenten sehr lange gebraucht
Und bis zu diesem Punkt haben virtuelle Assistenten sehr lange gebrauchtWas hast du gesagt? (Spracherkennung)
Bildkatalogisierung und Computer Vision sind nicht die einzigen Bereiche, in denen die KI wieder aufleben kann. Ein weiterer Bereich, in dem Computer sehr weit gekommen sind, ist die Spracherkennung, insbesondere bei der Übersetzung von Sprache in Schrift.Die Grundidee der Spracherkennung ist dem Prinzip des Computer Vision sehr ähnlich: Komplexe Dinge in Form von einfacheren zu erkennen. Im Fall von Sprache basiert die Erkennung von Sätzen und Phrasen auf der Erkennung von Wörtern, die auf der Erkennung von Silben oder genauer gesagt von Phonemen basiert. Wenn also jemand „Bond, James Bond“ sagt, hören wir tatsächlich BON + DUH + JAY + MMS + BON + DUH.In der Vision sind Merkmale räumlich organisiert, und der SNA verarbeitet diese Struktur. Gerüchten zufolge sind diese Funktionen zeitlich organisiert. Menschen können schnell oder langsam sprechen, ohne einen klaren Anfang und ein klares Ende der Rede. Wir brauchen ein Modell, das Geräusche wahrnimmt, wenn sie als Person ankommen, anstatt zu warten und nach vollständigen Sätzen in ihnen zu suchen. Wir können nicht wie in der Physik sagen, dass Raum und Zeit ein und dasselbe sind.Das Erkennen einzelner Silben ist ziemlich einfach, aber schwer zu isolieren. Zum Beispiel kann "Hallo" wie "Hölle, nein, sie sind" klingen. Für jede Folge von Tönen gibt es normalerweise mehrere Kombinationen von tatsächlich gesprochenen Silben.Um all dies zu verstehen, brauchen wir die Möglichkeit, die Sequenz in einem bestimmten Kontext zu studieren. Wenn ich ein Geräusch höre, ist es wahrscheinlicher, dass die Person "Hallo, Schatz" oder "Hölle, nein, sie sind Hirsche" sagte. Auch hier hilft maschinelles Lernen. Mit einer ausreichend großen Anzahl von Mustern gesprochener Wörter können Sie die wahrscheinlichsten Sätze lernen. Und je mehr Beispiele Sie haben, desto besser wird es.Zu diesem Zweck verwenden Menschen wiederkehrende neuronale Netze, RNS. In den meisten Arten von neuronalen Netzen, wie dem SNA, das am Computer Vision beteiligt ist, arbeiten die Verbindungen zwischen Neuronen von der Eingabe bis zur Ausgabe in einer Richtung (mathematisch gesehen handelt es sich dabei um gerichtete azyklische Graphen). In RNS kann die Ausgabe von Neuronen zu Neuronen derselben Ebene, zu sich selbst oder sogar noch weiter zurückgeleitet werden. Dadurch kann der RNS über einen eigenen Speicher verfügen (wenn Sie mit der binären Logik vertraut sind, ähnelt diese Situation der Funktionsweise von Triggern).SNA arbeitet für einen Ansatz: Wir geben ihr ein Bild und sie gibt eine Beschreibung heraus. Das RNS behält das interne Gedächtnis dessen bei, was ihr zuvor gegeben wurde, und gibt Antworten basierend auf dem, was sie bereits gesehen hat und was sie jetzt sieht.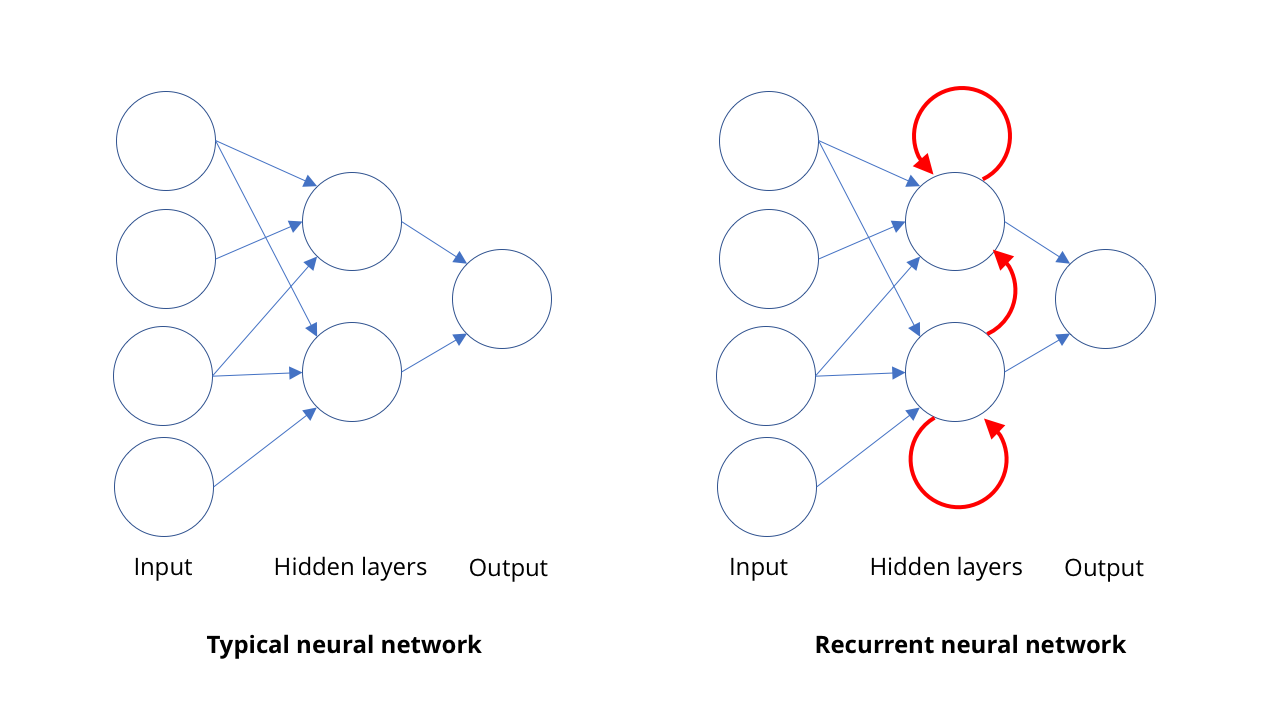 Diese Eigenschaft des Gedächtnisses im RNS ermöglicht es ihnen, nicht nur die Silben zu „hören“, die nacheinander dazu kommen. Auf diese Weise kann das Netzwerk lernen, welche Silben zu einem Wort zusammenpassen und wie wahrscheinlich bestimmte Sequenzen sind.Mit RNS ist es möglich, eine sehr gute Transkription der menschlichen Sprache zu erzielen - in einem solchen Ausmaß, dass Computer bei einigen Messungen der Transkriptionsgenauigkeit den Menschen jetzt übertreffen können. Natürlich sind Sounds nicht der einzige Bereich, in dem Sequenzen auftreten. Heute wird RNS auch verwendet, um Bewegungsabläufe zum Erkennen von Aktionen auf Video zu bestimmen.
Diese Eigenschaft des Gedächtnisses im RNS ermöglicht es ihnen, nicht nur die Silben zu „hören“, die nacheinander dazu kommen. Auf diese Weise kann das Netzwerk lernen, welche Silben zu einem Wort zusammenpassen und wie wahrscheinlich bestimmte Sequenzen sind.Mit RNS ist es möglich, eine sehr gute Transkription der menschlichen Sprache zu erzielen - in einem solchen Ausmaß, dass Computer bei einigen Messungen der Transkriptionsgenauigkeit den Menschen jetzt übertreffen können. Natürlich sind Sounds nicht der einzige Bereich, in dem Sequenzen auftreten. Heute wird RNS auch verwendet, um Bewegungsabläufe zum Erkennen von Aktionen auf Video zu bestimmen.Zeigen Sie mir, wie Sie sich bewegen können (tiefe Fälschungen und generative Netzwerke)
Bisher haben wir über MO-Modelle gesprochen, die für die Erkennung entwickelt wurden: Sagen Sie mir, was auf dem Bild gezeigt wird, und sagen Sie mir, was die Person gesagt hat. Diese Modelle können jedoch mehr - die heutigen GO-Modelle können auch zum Erstellen von Inhalten verwendet werden.Dies ist, wenn die Leute über Deepfake sprechen - unglaublich realistische gefälschte Videos und Bilder, die mit GO erstellt wurden. Vor einiger Zeit provozierte ein deutscher Fernsehbeamter eine umfangreiche politische Diskussion, indem er ein gefälschtes Video erstelltein dem der griechische Finanzminister Deutschland den Mittelfinger zeigte. Um dieses Video zu erstellen, brauchten wir ein Team von Redakteuren, die an der Erstellung einer TV-Show arbeiteten. In der modernen Welt kann dies jedoch in wenigen Minuten von jedem erledigt werden, der Zugang zu einem mittelgroßen Spielecomputer hat.Das alles ist ziemlich traurig, aber in diesem Bereich nicht so düster - mein Lieblingsvideo zum Thema dieser Technologie wird oben gezeigt.Dieses Team hat ein Modell erstellt, das in der Lage ist, ein Video mit den Tanzbewegungen einer Person zu verarbeiten und ein Video mit einer anderen Person zu erstellen, das diese Bewegungen wiederholt und sie auf Expertenebene magisch ausführt. Interessant ist auch die begleitende wissenschaftliche Arbeit .Man kann sich vorstellen, dass es mit allen von uns diskutierten Techniken möglich ist, ein Netzwerk zu trainieren, das das Bild eines Tänzers empfängt und sagt, wo sich seine Arme und Beine befinden. Und in diesem Fall hat das Netzwerk offensichtlich auf einer bestimmten Ebene gelernt, wie man die Pixel im Bild mit der Position der menschlichen Gliedmaßen verbindet. Da es sich bei einem neuronalen Netzwerk nur um Daten handelt, die auf einem Computer gespeichert sind, nicht um ein biologisches Gehirn, sollte es möglich sein, diese Daten in die entgegengesetzte Richtung zu übertragen, um Pixel zu erhalten, die der Position der Gliedmaßen entsprechen.Beginnen Sie mit einem Netzwerk, das Posen aus Bildern von Personen extrahiert.
MO-Modelle, die dies können, werden als generative Modelle bezeichnet. generieren - generieren, produzieren, erstellen / ca. übersetzt.]. Alle bisherigen Modelle, die wir in Betracht gezogen haben, werden als diskriminierend bezeichnet. unterscheiden - unterscheiden / ca. übersetzt.]. Der Unterschied zwischen ihnen kann wie folgt vorgestellt werden: Ein diskriminierendes Modell für Katzen betrachtet Fotos und unterscheidet zwischen Fotos, die Katzen enthalten, und Fotos, auf denen sie nicht sind. Das generative Modell erstellt Bilder von Katzen, die beispielsweise auf einer Beschreibung basieren, wie eine Katze aussehen sollte. Generative Modelle, die Bilder von Objekten „zeichnen“, werden mit denselben SNA-Strukturen erstellt wie die Modelle, mit denen diese Objekte erkannt werden. Und diese Modelle können auf die gleiche Weise wie andere MO-Modelle trainiert werden.Der Trick besteht jedoch darin, eine „Bewertung“ für ihr Training zu erstellen. Beim Training eines diskriminierenden Modells gibt es eine einfache Möglichkeit, die Richtigkeit und Unrichtigkeit der Antwort zu bewerten - beispielsweise, ob das Netzwerk den Hund korrekt von der Katze unterschieden hat. Wie kann man jedoch die Qualität des resultierenden Katzenbildes oder seine Genauigkeit bewerten?Und hier für eine Person, die Verschwörungstheorien liebt und glaubt, dass wir alle zum Scheitern verurteilt sind, wird die Situation ein wenig beängstigend. Sie sehen, der beste Weg, den wir zum Lernen generativer Netzwerke erfunden haben, besteht darin, es nicht selbst zu tun. Dafür verwenden wir einfach ein anderes neuronales Netzwerk.Diese Technologie wird als generatives gegnerisches Netzwerk oder GSS bezeichnet. Sie zwingen zwei neuronale Netze, miteinander zu konkurrieren: Ein Netz versucht, Fälschungen zu erzeugen, indem es beispielsweise einen neuen Tänzer basierend auf den alten Haltungen zeichnet. Ein anderes Netzwerk ist darauf trainiert, anhand einer Reihe von Beispielen für echte Tänzer den Unterschied zwischen echten und gefälschten Beispielen zu ermitteln.Und diese beiden Netzwerke spielen ein wettbewerbsfähiges Spiel. Daher das Wort "Widersacher" im Titel. Das generative Netzwerk versucht, überzeugende Fälschungen zu machen, und das diskriminierende Netzwerk versucht zu verstehen, wo die Fälschung ist und wo die reale Sache ist.Bei einem Video mit einem Tänzer wurde während des Trainings ein separates diskriminierendes Netzwerk erstellt, das einfache Ja / Nein-Antworten gibt. Sie betrachtete das Bild der Person und die Beschreibung der Position ihrer Gliedmaßen und entschied, ob es sich bei dem Bild um ein echtes Foto oder um ein Bild handelte, das von einem generativen Modell gezeichnet wurde.
Generative Modelle, die Bilder von Objekten „zeichnen“, werden mit denselben SNA-Strukturen erstellt wie die Modelle, mit denen diese Objekte erkannt werden. Und diese Modelle können auf die gleiche Weise wie andere MO-Modelle trainiert werden.Der Trick besteht jedoch darin, eine „Bewertung“ für ihr Training zu erstellen. Beim Training eines diskriminierenden Modells gibt es eine einfache Möglichkeit, die Richtigkeit und Unrichtigkeit der Antwort zu bewerten - beispielsweise, ob das Netzwerk den Hund korrekt von der Katze unterschieden hat. Wie kann man jedoch die Qualität des resultierenden Katzenbildes oder seine Genauigkeit bewerten?Und hier für eine Person, die Verschwörungstheorien liebt und glaubt, dass wir alle zum Scheitern verurteilt sind, wird die Situation ein wenig beängstigend. Sie sehen, der beste Weg, den wir zum Lernen generativer Netzwerke erfunden haben, besteht darin, es nicht selbst zu tun. Dafür verwenden wir einfach ein anderes neuronales Netzwerk.Diese Technologie wird als generatives gegnerisches Netzwerk oder GSS bezeichnet. Sie zwingen zwei neuronale Netze, miteinander zu konkurrieren: Ein Netz versucht, Fälschungen zu erzeugen, indem es beispielsweise einen neuen Tänzer basierend auf den alten Haltungen zeichnet. Ein anderes Netzwerk ist darauf trainiert, anhand einer Reihe von Beispielen für echte Tänzer den Unterschied zwischen echten und gefälschten Beispielen zu ermitteln.Und diese beiden Netzwerke spielen ein wettbewerbsfähiges Spiel. Daher das Wort "Widersacher" im Titel. Das generative Netzwerk versucht, überzeugende Fälschungen zu machen, und das diskriminierende Netzwerk versucht zu verstehen, wo die Fälschung ist und wo die reale Sache ist.Bei einem Video mit einem Tänzer wurde während des Trainings ein separates diskriminierendes Netzwerk erstellt, das einfache Ja / Nein-Antworten gibt. Sie betrachtete das Bild der Person und die Beschreibung der Position ihrer Gliedmaßen und entschied, ob es sich bei dem Bild um ein echtes Foto oder um ein Bild handelte, das von einem generativen Modell gezeichnet wurde. GSS zwingt zwei Netzwerke, miteinander zu konkurrieren: eines erzeugt Fälschungen und das andere versucht, Fälschungen vom Original zu unterscheiden.
GSS zwingt zwei Netzwerke, miteinander zu konkurrieren: eines erzeugt Fälschungen und das andere versucht, Fälschungen vom Original zu unterscheiden.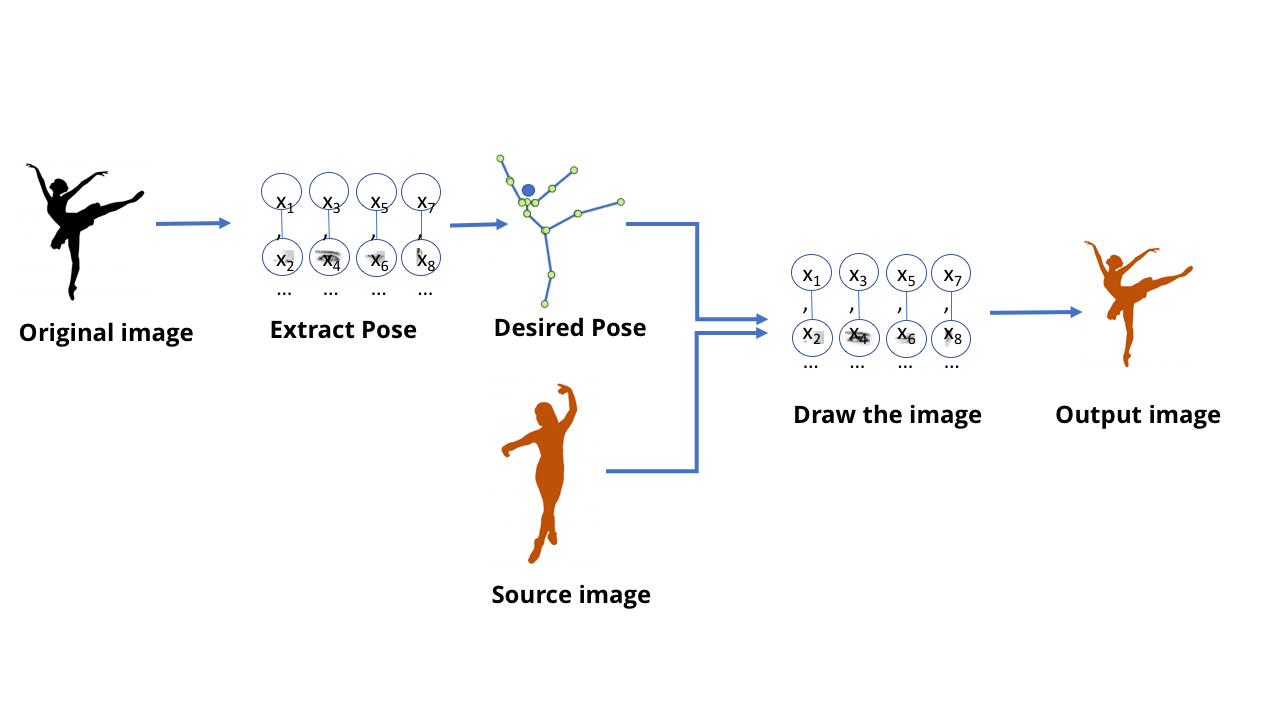 Im endgültigen Workflow wird nur ein generatives Modell verwendet, das die erforderlichen Bilder erstelltWährend der wiederholten Trainingsrunden wurden die Modelle immer besser. Dies ähnelt einem Wettbewerb zwischen einem Schmuckexperten und einem Bewertungsexperten - im Wettbewerb mit einem starken Gegner wird jeder von ihnen stärker und klüger. Wenn die Modelle gut genug funktionieren, können Sie ein generatives Modell nehmen und es separat verwenden.Generative Modelle nach dem Training können sehr nützlich sein, um Inhalte zu erstellen. Sie können beispielsweise Bilder von Gesichtern (mit denen Gesichtserkennungsprogramme trainiert werden können) oder Hintergründe für Videospiele generieren.Damit dies alles richtig funktioniert, ist viel Arbeit an Anpassungen und Korrekturen erforderlich, aber im Wesentlichen fungiert die Person hier als Schiedsrichter. Es ist die KI, die gegeneinander arbeitet und wesentliche Verbesserungen vornimmt.
Im endgültigen Workflow wird nur ein generatives Modell verwendet, das die erforderlichen Bilder erstelltWährend der wiederholten Trainingsrunden wurden die Modelle immer besser. Dies ähnelt einem Wettbewerb zwischen einem Schmuckexperten und einem Bewertungsexperten - im Wettbewerb mit einem starken Gegner wird jeder von ihnen stärker und klüger. Wenn die Modelle gut genug funktionieren, können Sie ein generatives Modell nehmen und es separat verwenden.Generative Modelle nach dem Training können sehr nützlich sein, um Inhalte zu erstellen. Sie können beispielsweise Bilder von Gesichtern (mit denen Gesichtserkennungsprogramme trainiert werden können) oder Hintergründe für Videospiele generieren.Damit dies alles richtig funktioniert, ist viel Arbeit an Anpassungen und Korrekturen erforderlich, aber im Wesentlichen fungiert die Person hier als Schiedsrichter. Es ist die KI, die gegeneinander arbeitet und wesentliche Verbesserungen vornimmt., Skynet Hal 9000?
In jedem Dokumentarfilm über die Natur am Ende gibt es eine Episode, in der die Autoren darüber sprechen, wie all diese grandiose Schönheit aufgrund der schrecklichen Menschen bald verschwinden wird. Ich denke, dass im gleichen Sinne jede verantwortungsvolle Diskussion über KI einen Abschnitt über ihre Grenzen und sozialen Konsequenzen enthalten sollte.
Lassen Sie uns zunächst noch einmal die aktuellen Einschränkungen der KI hervorheben: Die Hauptidee, die Sie hoffentlich durch das Lesen dieses Artikels gelernt haben, ist, dass der Erfolg der MO oder KI in hohem Maße von den von uns gewählten Trainingsmodellen abhängt. Wenn die Leute das Netzwerk nicht gut organisieren oder ungeeignete Materialien für das Training verwenden, können diese Verzerrungen für alle sehr offensichtlich sein.
Tiefe neuronale Netze sind unglaublich flexibel und leistungsfähig, haben aber keine magischen Eigenschaften. Trotz der Tatsache, dass Sie tiefe neuronale Netze für RNS und SNA verwenden, ist ihre Struktur sehr unterschiedlich, und daher sollten die Leute sie trotzdem bestimmen. Selbst wenn Sie den SNA für Autos verwenden und ihn für die Vogelerkennung neu trainieren können, können Sie dieses Modell nicht für die Spracherkennung neu trainieren.
Wenn wir es in menschlichen Begriffen beschreiben, sieht alles so aus, als hätten wir verstanden, wie der visuelle Kortex und der auditive Kortex funktionieren, aber wir haben keine Ahnung, wie der zerebrale Kortex funktioniert und wo wir anfangen können, uns ihm zu nähern.
Dies bedeutet, dass wir in naher Zukunft die gottähnliche KI Hollywoods wahrscheinlich nicht sehen werden. Dies bedeutet jedoch nicht, dass die KI in ihrer gegenwärtigen Form keine ernsthaften Auswirkungen auf die Gesellschaft haben kann.
Wir stellen uns oft vor, wie KI uns „ersetzt“, dh wie Roboter unsere Arbeit buchstäblich erledigen, aber in Wirklichkeit wird dies nicht passieren. Schauen Sie sich zum Beispiel die Radiologie an: Manchmal sagen Menschen, die den Erfolg des Computer Vision betrachten, dass KI Radiologen ersetzen wird. Vielleicht werden wir nicht den Punkt erreichen, an dem wir überhaupt keinen einzigen menschlichen Radiologen haben werden. Aber eine Zukunft ist durchaus möglich, in der für hundert der heutigen Radiologen die KI fünf bis zehn von ihnen erlauben wird, die Arbeit aller anderen zu erledigen. Wenn ein solches Szenario realisiert wird, wohin gehen die verbleibenden 90 Ärzte?
Auch wenn die moderne Generation der KI den Hoffnungen ihrer optimistischsten Unterstützer nicht gerecht wird, wird dies dennoch zu sehr weitreichenden Konsequenzen führen. Und wir müssen diese Probleme lösen, daher wird es wahrscheinlich ein guter Anfang sein, die Grundlagen dieses Bereichs zu beherrschen.