Einführung
Bereitstellung des nächsten Systems, da eine große Anzahl verschiedener Protokolle verarbeitet werden muss. Als Werkzeug ELK gewählt. In diesem Artikel werden unsere Erfahrungen mit der Optimierung dieses Stapels erläutert.
Wir setzen uns nicht das Ziel, alle Möglichkeiten zu beschreiben, sondern wollen uns genau auf die Lösung praktischer Probleme konzentrieren. Dies ist darauf zurückzuführen, dass es bei ausreichend großer Dokumentation und vorgefertigten Bildern viele Fallstricke gibt, zumindest haben wir sie gefunden.
Wir haben den Stack über Docker-Compose bereitgestellt. Außerdem hatten wir eine gut geschriebene docker-compose.yml, mit der wir den Stack fast problemlos anheben konnten. Und es schien uns, dass der Sieg bereits nahe war, jetzt werden wir uns ein bisschen drehen, um unseren Bedürfnissen zu entsprechen, und das war's.
Leider war der Versuch, das System so zu optimieren, dass Protokolle von unserer Anwendung empfangen und verarbeitet werden, nicht von Erfolg gekrönt. Aus diesem Grund haben wir beschlossen, dass es sich lohnt, jede Komponente einzeln zu untersuchen und dann zu ihren Beziehungen zurückzukehren.
Also haben wir mit logstash angefangen.
Umgebung, Bereitstellung, Starten Sie Logstash im Container
Für die Bereitstellung verwenden wir Docker-Compose. Die hier beschriebenen Experimente wurden unter MacOS und Ubuntu 18.0.4 durchgeführt.
Das Logstash-Image, das bei uns in der ursprünglichen Datei docker-compose.yml registriert wurde, lautet docker.elastic.co/logstash/logstash:6.3.2
Wir werden es für Experimente verwenden.
Um logstash auszuführen, haben wir eine separate docker-compose.yml geschrieben. Natürlich war es möglich, das Image über die Befehlszeile zu starten, aber wir haben ein bestimmtes Problem gelöst, bei dem alles von Docker-Compose gestartet wird.
Kurz über Konfigurationsdateien
Wie aus der Beschreibung hervorgeht, kann logstash sowohl für einen Kanal ausgeführt werden. In diesem Fall muss die Datei * .conf übertragen werden, oder für mehrere Kanäle. In diesem Fall muss die Datei pipelines.yml übertragen werden, die wiederum mit den Dateien verknüpft wird .conf für jeden Kanal.
Wir gingen den zweiten Weg. Es schien uns universeller und skalierbarer. Aus diesem Grund haben wir pipelines.yml erstellt und das Pipelines-Verzeichnis erstellt, in das wir die .conf-Dateien für jeden Kanal ablegen.
Im Container befindet sich eine weitere Konfigurationsdatei - logstash.yml. Wir berühren es nicht, verwenden es so wie es ist.
Also, die Struktur unserer Verzeichnisse:
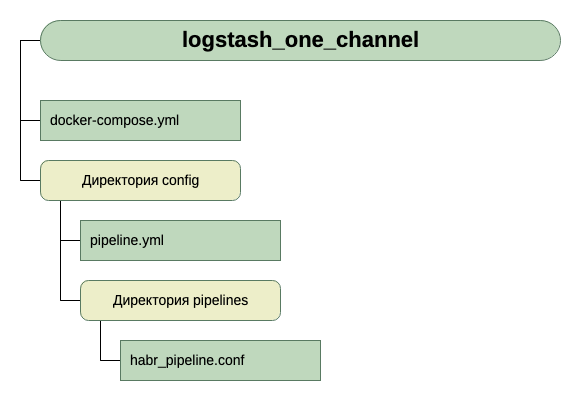
Um die Eingabe zu erhalten, glauben wir vorerst, dass es sich um TCP auf Port 5046 handelt, und für die Ausgabe verwenden wir stdout.
Hier ist eine so einfache Konfiguration für den ersten Lauf. Da ist die anfängliche Aufgabe zu starten.
Wir haben also diese docker-compose.yml
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Was sehen wir hier?
- Netzwerke und Volumes stammen aus der ursprünglichen docker-compose.yml (der, in der der gesamte Stack gestartet wird), und ich denke, dass sie das Gesamtbild hier nicht wesentlich beeinflussen.
- Wir erstellen einen Logstash-Service aus dem Image docker.elastic.co/logstash/logstash:6.3.2 und geben ihm den Namen logstash_one_channel.
- Wir leiten Port 5046 innerhalb des Containers an denselben internen Port weiter.
- Wir ordnen unsere Kanaleinstellungsdatei ./config/pipelines.yml der Datei /usr/share/logstash/config/pipelines.yml im Container zu, in der logstash sie aufnimmt und für alle Fälle schreibgeschützt macht.
- Wir zeigen das Verzeichnis ./config/pipelines, in dem sich die Kanaleinstellungsdateien befinden, im Verzeichnis / usr / share / logstash / config / pipelines an und machen es auch schreibgeschützt.
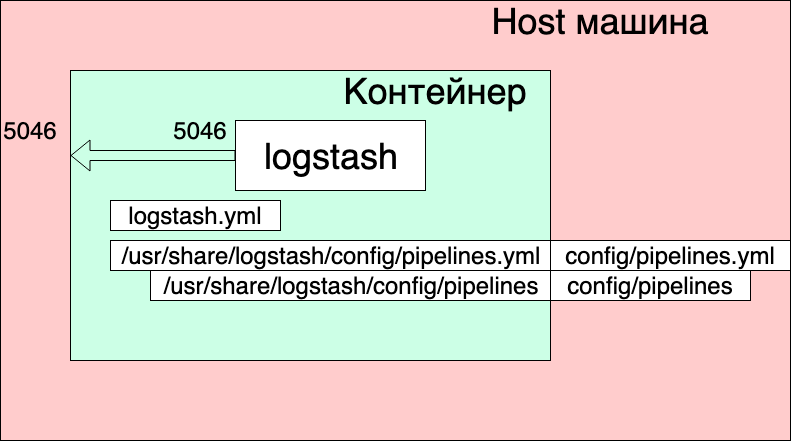
Pipelines.yml-Datei
- pipeline.id: HABR pipeline.workers: 1 pipeline.batch.size: 1 path.config: "./config/pipelines/habr_pipeline.conf"
Hier wird ein Kanal mit der HABR-Kennung und dem Pfad zu seiner Konfigurationsdatei beschrieben.
Und schließlich die Datei "./config/pipelines/habr_pipeline.conf"
input { tcp { port => "5046" } } filter { mutate { add_field => [ "habra_field", "Hello Habr" ] } } output { stdout { } }
Lassen Sie uns vorerst nicht auf seine Beschreibung eingehen, sondern versuchen zu rennen:
docker-compose up
Was sehen wir?
Der Container startete. Wir können seine Funktion überprüfen:
echo '13123123123123123123123213123213' | nc localhost 5046
Und wir sehen die Antwort in der Containerkonsole:
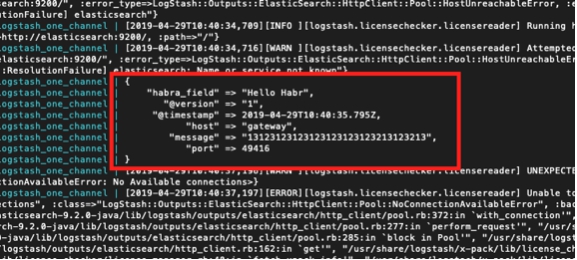
Gleichzeitig sehen wir aber auch:
logstash_one_channel | [2019-04-29T11: 28: 59,790]
[ERROR] [logstash.licensechecker.licensereader] Lizenzinformationen können nicht vom Lizenzserver abgerufen werden {: message => "Elasticsearch Nicht erreichbar: [http: // elasticsearch: 9200 /] [Manticore :: ResolutionFailure] elasticsearch ", ...
logstash_one_channel | [2019-04-29T11: 28: 59,894] [INFO] [logstash.pipeline] Die
Pipeline wurde erfolgreich gestartet. {: Pipeline_id => ". Monitoring-logstash",: thread => "# <Thread: 0x119abb86 run>"}
logstash_one_channel | [2019-04-29T11: 28: 59,988] [INFO] [logstash.agent] Pipelines werden ausgeführt {: count => 2,: running_pipelines => [: HABR,: ". Monitoring-logstash"],: non_running_pipelines => [ ]}
logstash_one_channel | [2019-04-29T11: 29: 00,015]
[ FEHLER]
[logstash.inputs.metrics] X-Pack ist auf Logstash installiert, jedoch nicht auf Elasticsearch. Bitte installieren Sie X-Pack auf Elasticsearch, um die Überwachungsfunktion zu verwenden. Andere Funktionen sind möglicherweise verfügbar.logstash_one_channel | [2019-04-29T11: 29: 00,526] [INFO] [logstash.agent] Der Logstash-API-Endpunkt {: port => 9600} wurde erfolgreich gestartet.
logstash_one_channel | [2019-04-29T11: 29: 04,478] [INFO] [logstash.outputs.elasticsearch] Ausführen der Integritätsprüfung, um festzustellen, ob eine Elasticsearch-Verbindung funktioniert {: healthcheck_url => http: // elasticsearch: 9200 /,: path => "/"}
l
ogstash_one_channel | [2019-04-29T11: 29: 04,487]
[WARN] [logstash.outputs.elasticsearch] Es wurde versucht, die Verbindung zur toten ES-Instanz wiederherzustellen, es ist jedoch ein Fehler aufgetreten. {: url => " elasticsearch : 9200 /",: error_type => LogStash :: Outputs :: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError,: error => "Elasticsearch nicht erreichbar: [http: // elasticsearch: 9200 / ] [Manticore :: ResolutionFailure] elasticsearch ”}logstash_one_channel | [2019-04-29T11: 29: 04,704] [INFO] [logstash.licensechecker.licensereader] Ausführen der Integritätsprüfung, um festzustellen, ob eine Elasticsearch-Verbindung funktioniert {: healthcheck_url => http: // elasticsearch: 9200 /,: path => "/"}
logstash_one_channel | [2019-04-29T11: 29: 04,710]
[WARN] [logstash.licensechecker.licensereader] Es wurde versucht, die Verbindung zur toten ES-Instanz wiederherzustellen, es ist jedoch ein Fehler aufgetreten. {: url => " elasticsearch : 9200 /",: error_type => LogStash :: Outputs :: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError,: error => "Elasticsearch nicht erreichbar: [http: // elasticsearch: 9200 / ] [Manticore :: ResolutionFailure] elasticsearch ”}Und unser Baumstamm schleicht sich ständig an.
Hier habe ich grün eine Meldung hervorgehoben, dass die Pipeline erfolgreich gestartet wurde, rot - eine Fehlermeldung und gelb - eine Meldung über einen Versuch,
elasticsearch zu kontaktieren: 9200.
Dies liegt daran, dass die im Bild enthaltene logstash.conf die Verfügbarkeit von Elasticsearch überprüft. Schließlich geht logstash davon aus, dass es als Teil des Elk-Stacks funktioniert, und wir haben es getrennt.
Sie können arbeiten, aber nicht bequem.
Die Lösung besteht darin, diese Prüfung über die Umgebungsvariable XPACK_MONITORING_ENABLED zu deaktivieren.
Nehmen Sie eine Änderung an docker-compose.yml vor und führen Sie sie erneut aus:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Jetzt ist alles in Ordnung. Der Behälter ist zum Experimentieren bereit.
Wir können wieder die nächste Konsole eingeben:
echo '13123123123123123123123213123213' | nc localhost 5046
Und siehe:
logstash_one_channel | { logstash_one_channel | "message" => "13123123123123123123123213123213", logstash_one_channel | "@timestamp" => 2019-04-29T11:43:44.582Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "host" => "gateway", logstash_one_channel | "port" => 49418 logstash_one_channel | }
Arbeiten Sie innerhalb eines Kanals
Also fingen wir an. Jetzt können Sie sich tatsächlich die Zeit nehmen, Logstash direkt zu konfigurieren. Wir werden die Datei pipelines.yml vorerst nicht berühren. Wir werden sehen, was Sie durch die Arbeit mit einem Kanal erreichen können.
Ich muss sagen, dass das allgemeine Prinzip der Arbeit mit der Kanalkonfigurationsdatei im offiziellen Handbuch
hier gut beschrieben
istWenn Sie auf Russisch lesen möchten, haben wir diesen
Artikel hier verwendet (aber die Abfragesyntax ist dort alt, wir müssen dies berücksichtigen).
Gehen wir nacheinander vom Abschnitt Eingabe aus. Wir haben bereits Arbeiten an TCP gesehen. Was könnte hier noch von Interesse sein?
Testen Sie Nachrichten mit Heartbeat
Es gibt eine so interessante Möglichkeit, automatische Testnachrichten zu generieren.
Dazu müssen Sie das Heartbean-Plugin in den Eingabeabschnitt aufnehmen.
input { heartbeat { message => "HeartBeat!" } }
Einschalten, einmal pro Minute starten, um zu empfangen
logstash_one_channel | { logstash_one_channel | "@timestamp" => 2019-04-29T13:52:04.567Z, logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "HeartBeat!", logstash_one_channel | "@version" => "1", logstash_one_channel | "host" => "a0667e5c57ec" logstash_one_channel | }
Wir wollen öfter bekommen, wir müssen den Intervallparameter hinzufügen.
So erhalten wir alle 10 Sekunden eine Nachricht.
input { heartbeat { message => "HeartBeat!" interval => 10 } }
Daten aus einer Datei abrufen
Wir haben uns auch für den Dateimodus entschieden. Wenn es normal mit der Datei funktioniert, ist es möglich, dass zumindest für die lokale Verwendung kein Agent benötigt wird.
Gemäß der Beschreibung sollte der Betriebsmodus dem Schwanz-f ähnlich sein, d.h. Liest neue Zeilen oder liest optional die gesamte Datei.
Also, was wir bekommen wollen:
- Wir möchten Zeilen erhalten, die an eine Protokolldatei angehängt werden.
- Wir möchten Daten empfangen, die in mehrere Protokolldateien geschrieben wurden, und gleichzeitig die Freigabe der Daten freigeben.
- Wir möchten überprüfen, ob beim Neustart von logstash diese Daten nicht erneut empfangen werden.
- Wir möchten überprüfen, ob Logstash deaktiviert ist und die Daten weiterhin in Dateien geschrieben werden. Wenn wir sie ausführen, erhalten wir diese Daten.
Fügen Sie zur Durchführung des Experiments eine weitere Zeile zu docker-compose.yml hinzu und öffnen Sie das Verzeichnis, in dem wir die Dateien ablegen.
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input
Und ändern Sie den Eingabeabschnitt in habr_pipeline.conf
input { file { path => "/usr/share/logstash/input/*.log" } }
Wir fangen an:
docker-compose up
Um Protokolldateien zu erstellen und aufzuzeichnen, verwenden wir den folgenden Befehl:
echo '1' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:53.876Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
Ja, es funktioniert!
Gleichzeitig sehen wir, dass wir das Pfadfeld automatisch hinzugefügt haben. In Zukunft können wir also Datensätze danach filtern.
Versuchen wir es noch einmal:
echo '2' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:59.906Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "2", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
Und jetzt zu einer anderen Datei:
echo '1' >> logs/number2.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:29:26.061Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log" logstash_one_channel | }
Großartig! Die Datei wurde abgeholt, der Pfad war korrekt, alles ist in Ordnung.
Stoppen Sie den Logstash und starten Sie ihn neu. Lass uns warten. Die Stille. Das heißt, Wir erhalten diese Aufzeichnungen nicht erneut.
Und jetzt das gewagteste Experiment.
Wir setzen logstash und führen aus:
echo '3' >> logs/number2.log echo '4' >> logs/number1.log
Führen Sie logstash erneut aus und sehen Sie:
logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "3", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.589Z logstash_one_channel | } logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "4", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.856Z logstash_one_channel | }
Hurra! Alles wurde abgeholt.
Wir müssen jedoch vor Folgendem warnen. Wenn der Container mit logstash gelöscht wird (Docker stoppen logstash_one_channel && Docker rm logstash_one_channel), wird nichts abgeholt. Im Container wurde die Dateiposition gespeichert, an der sie gelesen wurde. Wenn es von Grund auf neu ausgeführt wird, werden nur neue Zeilen akzeptiert.
Lesen Sie vorhandene Dateien
Angenommen, wir führen logstash zum ersten Mal aus, haben aber bereits Protokolle und möchten diese verarbeiten.
Wenn wir logstash mit dem oben verwendeten Eingabeabschnitt ausführen, erhalten wir nichts. Nur Zeilenumbrüche werden von logstash verarbeitet.
Fügen Sie dem Eingabeabschnitt eine zusätzliche Zeile hinzu, um Zeilen aus vorhandenen Dateien abzurufen:
input { file { start_position => "beginning" path => "/usr/share/logstash/input/*.log" } }
Darüber hinaus gibt es eine Nuance, die nur neue Dateien betrifft, die logstash noch nicht gesehen hat. Für die gleichen Dateien, die bereits in das Sichtfeld von logstash fielen, erinnerte er sich bereits an ihre Größe und nimmt jetzt nur noch neue Einträge in sie auf.
Lassen Sie uns auf das Studium des Eingabeabschnitts eingehen. Es gibt viel mehr Möglichkeiten, aber für uns reichen weitere Experimente vorerst aus.
Routing und Datenkonvertierung
Versuchen wir, das folgende Problem zu lösen. Nehmen wir an, wir haben Nachrichten von einem Kanal, einige davon sind informativ und teilweise eine Fehlermeldung. Unterschied im Tag. Einige INFO, andere FEHLER.
Wir müssen sie am Ausgang trennen. Das heißt, Wir schreiben Informationsnachrichten in einen Kanal und Fehlermeldungen in einen anderen.
Gehen Sie dazu vom Eingabebereich zum Filtern und Ausgeben.
Mithilfe des Filterabschnitts analysieren wir die eingehende Nachricht und erhalten daraus einen Hash (Schlüssel-Wert-Paare), mit dem Sie bereits arbeiten können, d. H. durch Bedingungen zerlegen. Und im Ausgabebereich wählen wir Nachrichten aus und senden sie jeweils an unseren Kanal.
Analysieren einer Nachricht mit grok
Um Textzeichenfolgen zu analysieren und eine Reihe von Feldern daraus abzurufen, gibt es im Filterbereich ein spezielles Plugin - grok.
Da ich hier keine detaillierte Beschreibung geben möchte (hierzu verweise ich auf die
offizielle Dokumentation ), werde ich mein einfaches Beispiel geben.
Dazu müssen Sie das Format der Eingabezeilen festlegen. Ich habe sie:
1 INFO message1
2 ERROR message2
Das heißt, Der Bezeichner kommt zuerst, dann INFO / ERROR, dann ein Wort ohne Leerzeichen.
Nicht schwer, aber genug, um zu verstehen, wie es funktioniert.
Im Filterbereich des Grok-Plugins müssen wir also ein Muster für das Parsen unserer Zeilen definieren.
Es wird so aussehen:
filter { grok { match => { "message" => ["%{INT:message_id} %{LOGLEVEL:message_type} %{WORD:message_text}"] } } }
Dies ist im Wesentlichen ein regulärer Ausdruck. Es werden vorgefertigte Muster wie INT, LOGLEVEL, WORD verwendet. Ihre Beschreibung sowie andere Muster finden Sie
hier.Wenn Sie diesen Filter durchlaufen, wird unsere Zeichenfolge in einen Hash aus drei Feldern umgewandelt: message_id, message_type, message_text.
Sie werden im Ausgabebereich angezeigt.
Weiterleiten von Nachrichten im Ausgabeabschnitt mit dem Befehl if
Wie wir uns erinnern, wollten wir im Ausgabeabschnitt die Nachrichten in zwei Streams aufteilen. Einige - welche iNFO werden wir an die Konsole ausgeben, und mit Fehlern werden wir in eine Datei ausgeben.
Wie teilen wir diese Beiträge auf? Der Zustand des Problems fordert bereits zur Lösung auf - wir haben bereits das ausgewählte Feld message_type, das nur zwei Werte INFO und ERROR annehmen kann. Für ihn werden wir mit der if-Anweisung eine Wahl treffen.
if [message_type] == "ERROR" { # } else { # stdout }
Die Beschreibung der Arbeit mit Feldern und Operatoren finden Sie in diesem Abschnitt des
offiziellen Handbuchs .
Nun zur eigentlichen Schlussfolgerung.
Bei der Ausgabe an die Konsole ist hier alles klar - stdout {}
Und hier ist die Ausgabe der Datei - denken Sie daran, dass wir alles aus dem Container ausführen und damit die Datei, in die wir das Ergebnis schreiben, von außen zugänglich ist, müssen wir dieses Verzeichnis in docker-compose.yml öffnen.
Gesamt:
Der Ausgabeabschnitt unserer Datei sieht folgendermaßen aus:
output { if [message_type] == "ERROR" { file { path => "/usr/share/logstash/output/test.log" codec => line { format => "custom format: %{message}"} } } else {stdout { } } }
Fügen Sie in docker-compose.yml ein weiteres Volume zur Ausgabe hinzu:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input - ./output:/usr/share/logstash/output
Wir beginnen, wir versuchen, wir sehen eine Aufteilung in zwei Flüsse.