Wenn Sie jemals die Daten von zwei Analysetools auf derselben Site verglichen oder Analysen mit Berichten und Verkäufen verglichen haben, haben Sie wahrscheinlich festgestellt, dass diese nicht immer übereinstimmen. In diesem Artikel werde ich erklären, warum die Statistiken von Webanalyseplattformen keine Daten enthalten und wie groß diese Verluste sein können.
In diesem Artikel konzentrieren wir uns auf Google Analytics als beliebtesten Analysedienst, obwohl die meisten auf der Seite implementierten Analyseplattformen dieselben Probleme haben. Dienste, die auf Serverprotokollen basieren, vermeiden einige dieser Probleme, werden jedoch so selten verwendet, dass wir sie in diesem Artikel nicht behandeln.
Analytics-Testkonfigurationen in Destilled
Bei Distilled.net verfügen wir über eine Standardressource von Google Analtics, die mit einem HTML-Tag im Google Tag Manager funktioniert. Darüber hinaus habe ich in den letzten zwei Jahren drei zusätzliche parallele Implementierungen von Google Analytics verwendet, um Unterschiede zwischen verschiedenen Konfigurationen zu messen.
Zwei dieser zusätzlichen Implementierungen - eine in GTM und die andere auf der Seite - verwalten lokal gespeicherte, umbenannte Kopien der Google Analytics-JavaScript-Datei (www.distilled.net/static/js/au3.js anstelle von
www.google-analytics.com/). analyse.js ), um die Erkennung für Werbeblocker zu erschweren.
Ich habe auch umbenannte JavaScript-Funktionen ("tcap" und "Buffoon" anstelle des Standards "ga") und umbenannte Tracker ("FredTheUnblockable" und "AlbertTheImmutable") verwendet, um das Problem doppelter Tracker zu vermeiden (was häufig zu Problemen führen kann).
Schließlich haben wir die Konfiguration „DianaTheIndefatigable“, die einen umbenannten Tracker hat, aber Standardcode verwendet und auf Seitenebene implementiert ist.
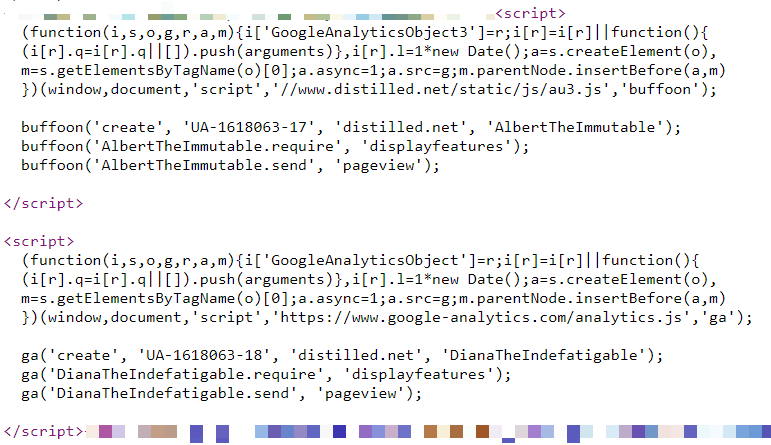
Alle unsere Konfigurationen sind in der folgenden Tabelle aufgeführt:

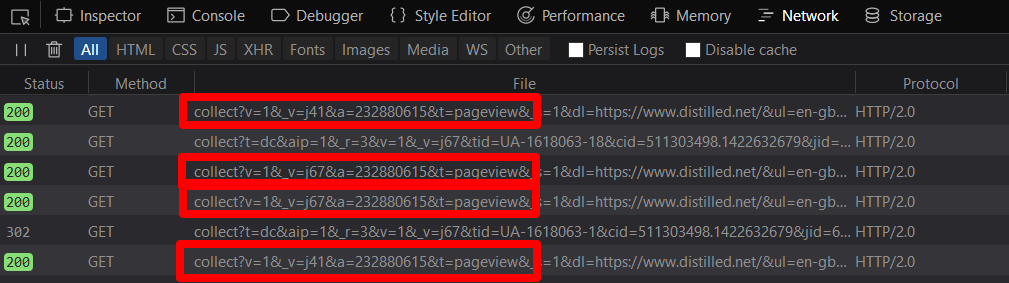
Ich habe ihre Funktionalität in verschiedenen Browsern und Werbeblockern getestet, indem ich Seitenaufrufe analysiert habe, die in Browser-Entwicklertools angezeigt werden:
Gründe für Datenverlust
1. Werbeblocker
Werbeblocker, hauptsächlich in Form von Browsererweiterungen, werden immer häufiger. Anfänglich war der Hauptgrund für ihre Verwendung die Verbesserung der Leistung und des Interaktionserlebnisses auf Websites mit einer großen Menge an Werbung. In den letzten Jahren hat der Schwerpunkt auf Datenschutz zugenommen, was auch zur Popularität von Werbeblockern beigetragen hat.
Die Wirkung von WerbeblockernEinige Werbeblocker blockieren standardmäßig Webanalyseplattformen, andere sind möglicherweise weiter konfiguriert, um diese Funktion auszuführen. Ich habe die Distilled-Website mit Adblock Plus und uBlock Origin getestet, den beiden beliebtesten Desktop-Browser-Erweiterungen für das Blockieren von Werbung. Es ist jedoch erwähnenswert, dass Werbeblocker zunehmend auch auf Smartphones verwendet werden.
Folgende Ergebnisse wurden erzielt (alle Angaben beziehen sich auf April 2018):
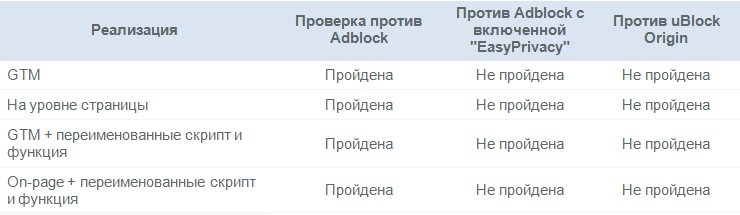
Wie aus der Tabelle ersichtlich ist, tragen die geänderten GA-Einstellungen nicht wesentlich dazu bei, Blockern zu widerstehen.
Datenverlust durch Werbeblocker: ~ 10%Die Verwendung von Werbeblockern kann je nach Region zwischen 15 und 25% liegen. Bei vielen dieser Einstellungen handelt es sich jedoch um AdBlock Plus mit Standardeinstellungen, bei denen, wie oben gesehen, das Tracking nicht blockiert wird.
Der Anteil von AdBlock Plus am Markt für Werbeblocker variiert zwischen 50 und 70%.
Nach jüngsten Schätzungen liegt diese Zahl näher bei 50%. Wenn wir daher davon ausgehen, dass nicht mehr als 50% der installierten Werbeblocker die Analyse blockieren, erhalten wir einen Datenverlust in Höhe von etwa 10%.
2. Verfolgen Sie die Funktion in Browsern nicht
Dies ist eine weitere Funktion, die durch den Schutz der Privatsphäre motiviert ist. Diesmal geht es aber nicht um das Add-On, sondern um die Funktion der Browser selbst. Die Anforderung "Nicht verfolgen" ist für Websites und Plattformen nicht erforderlich. Beispielsweise bietet Firefox eine stärkere Funktion unter denselben Parametern, die ich auch testen wollte.
Der Effekt von Nicht verfolgenDie meisten Browser bieten jetzt die Option "Nachricht nicht verfolgen" an. Ich habe die neuesten Versionen von Firefox- und Chrome-Browsern für Windows 10 getestet.
 Auch hier scheinen die geänderten Einstellungen nicht viel zu helfen.Datenverlust durch "Nicht verfolgen": <1%
Auch hier scheinen die geänderten Einstellungen nicht viel zu helfen.Datenverlust durch "Nicht verfolgen": <1%Tests haben gezeigt, dass nur die Tracking-Schutzfunktion im Firefox Quantum-Browser die Tracker betrifft. Firefox nimmt 5% des Browsermarktes ein, aber der Tracking-Schutz ist standardmäßig nicht aktiviert. Daher hatte der Start dieser Funktion keine Auswirkungen auf die Trends des Firefox-Verkehrs auf Distilled.net.
3. Filter
Filter, die Sie im Analysesystem konfigurieren, können das Volumen des empfangenen Datenverkehrs in den Berichten absichtlich oder unbeabsichtigt unterschätzen.
Beispielsweise führt ein Filter, der bestimmte Bildschirmauflösungen ausschließt, bei denen es sich um Bots oder internen Datenverkehr handeln kann, eindeutig zu einer gewissen Unterschätzung des Datenverkehrs.
Datenverlust durch Filter: N / A.
Die Auswirkungen dieses Faktors sind schwer zu bewerten, da diese Einstellung je nach Standort unterschiedlich ist. Ich empfehle jedoch dringend, eine doppelte Hauptansicht (ohne Filter) zu verwenden, damit Sie den Verlust wichtiger Informationen schnell erkennen können.
4. GTM vs On-Page vs falsch lokalisierter Code
In den letzten Jahren wurde Google Tag Manager aufgrund seiner Flexibilität und einfachen Änderungsmöglichkeiten zu einer immer beliebteren Methode zur Implementierung von Analysen. Ich habe jedoch lange bemerkt, dass diese GA-Implementierungsmethode im Vergleich zur Einstellung auf Seitenebene zu einer Unterschätzung führen kann.
Ich war auch gespannt, was passieren würde, wenn Sie die Empfehlungen von Google zum Festlegen des On-Page-Codes nicht befolgen würden.
Durch die Kombination meiner eigenen Daten mit den Daten von der
Website meines Kollegen Dom Woodman, der die Analyseerweiterung Drupal sowie GTM verwendet, konnte ich den Unterschied zwischen dem Tag-Manager und dem Code erkennen, der sich falsch auf der Seite befindet (am unteren Rand des Tags). Dann habe ich diese Daten mit meinen eigenen GTM-Daten abgeglichen, um das vollständige Bild über alle 5 Konfigurationen hinweg zu sehen.
Auswirkungen von GTM und falsch platziertem On-Page-Code
Verkehr als Prozentsatz der Basislinie (Standardimplementierung mit Tag Manager):
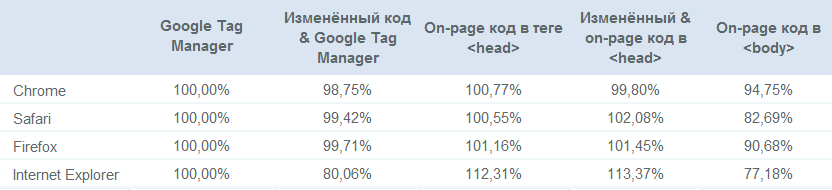
Wichtigste Ergebnisse
- On-Page-Code registriert normalerweise mehr Verkehr als GTM.
- Der geänderte Code befindet sich normalerweise innerhalb der Fehlergrenze, mit Ausnahme des geänderten GTM-Codes in Internet Explorer.
- Ein falsch lokalisierter Tracking-Code kostet Sie je nach Browser (!) Bis zu 30% Ihres Datenverkehrs im Vergleich zu korrekt implementiertem On-Page-Code.
- Benutzerdefinierte Konfigurationen, die darauf ausgelegt sind, mehr Verkehr zu erhalten, indem Werbeblocker vermieden werden, tun dies nicht.
Es ist auch erwähnenswert, dass Benutzerimplementierungen tatsächlich weniger Verkehr erhalten als Standardimplementierungen. Im Fall von On-Page-Code liegen die Verluste innerhalb der Fehlergrenze, aber im Fall von GTM gibt es eine andere Nuance, die die endgültigen Daten beeinflussen könnte.
Da ich zum Vergleich ungefilterte Profile verwendet habe, gab es im Hauptprofil eine Menge Bot-Spam, der größtenteils als Internet Explorer getarnt war.
Heutzutage ist unser Hauptprofil am meisten Spam, es wird jedoch auch als Vergleichsstufe verwendet, sodass der Unterschied zwischen dem On-Page-Code und dem Tag-Manager tatsächlich etwas größer ist.
GTM-Datenverlust: 1-5%
Mit GTM verbundene Verluste hängen davon ab, welche Browser und Geräte von Besuchern Ihrer Website verwendet werden. Auf Distilled.net beträgt der Unterschied etwa 1,7%, unser Publikum nutzt aktiv Desktops und ist technisch fortgeschritten, Internet Explorer wird selten verwendet. Je nach Vertikale können Verluste 5% erreichen.
Ich habe auch eine Aufschlüsselung nach Gerät vorgenommen:

Datenverlust aufgrund falsch lokalisierten On-Page-Codes: ~ 10%
Auf Teflsearch.com gingen etwa 7,5% der Daten aufgrund von falsch lokalisiertem Code gegen GTM verloren. Da der Tag Manager selbst die Daten unterschätzt, könnte der Gesamtverlust leicht 10% erreichen.
Bonus: Datenverlust von Kanälen
Oben haben wir Bereiche untersucht, in denen Sie im Allgemeinen Daten verlieren können. Es gibt jedoch andere Faktoren, die zu unvollständigen Daten führen. Wir werden sie kurz betrachten. Die Hauptprobleme hier sind dunkler Verkehr und Zuschreibung.
Dunkler VerkehrDunkler Verkehr ist direkter Verkehr, der nicht wirklich direkter Verkehr ist.
Und dies wird immer häufiger.
Typische Ursachen für dunklen Verkehr:
- Nicht markierte E-Mail-Marketingkampagnen;
- Nicht markierte Kampagnen in Anwendungen (insbesondere Facebook, Twitter usw.);
- Verzerrter organischer Verkehr;
- Daten, die aufgrund von Fehlern gesendet wurden, die während des Tracking-Setup-Vorgangs gemacht wurden (können auch als Selbstverweise angezeigt werden);
Erwähnenswert ist auch ein Trend in Richtung Wachstum des wirklich direkten Verkehrs, der historisch gesehen organisch war. Im Zusammenhang mit der Verbesserung der Autovervollständigungsfunktion in Browsern, der Synchronisierung des Suchverlaufs auf verschiedenen Geräten usw. scheinen die Benutzer die zuvor gesuchte URL einzugeben.
Namensnennung
Im Allgemeinen ist eine Sitzung in Google Analytics (und auf jeder anderen Plattform) ein eher willkürliches Konstrukt. Möglicherweise ist es offensichtlich, wie eine Gruppe von Anrufen zu einer oder mehreren Sitzungen zusammengefasst werden sollte. In Wirklichkeit beruht dieser Prozess jedoch auf einer Reihe eher zweifelhafter Annahmen. Insbesondere ist anzumerken, dass Google Analytics in der Regel direkten Datenverkehr (einschließlich dunklen Datenverkehrs) der vorherigen nicht direkten Quelle zuordnet, sofern eine vorhanden ist.
Fazit
Ich war etwas überrascht von einigen der Ergebnisse, die ich erhalten habe, aber ich bin sicher, dass ich nicht alles abgedeckt habe, und es gibt andere Möglichkeiten, Daten zu verlieren. Die Forschung in diesem Bereich kann also weiter fortgesetzt werden.
Weitere solche Artikel können auf meinem
Telegrammkanal (proroas) gelesen werden.