
Mit dem Aufkommen hochwertiger Kameras in Mobiltelefonen fotografieren wir immer häufiger und drehen Videos der hellen und wichtigen Momente unseres Lebens. Viele von uns haben Fotoarchive aus zig Jahren und Tausende von Fotos, in denen die Navigation immer schwieriger wird. Denken Sie daran, wie oft es vor einigen Jahren oft gedauert hat, das richtige Foto zu finden.
Eines der Ziele von Mail.ru Cloud ist es, den bequemsten Zugriff und die bequemste Suche in Ihrem Foto- und Videoarchiv zu ermöglichen. Zu diesem Zweck haben wir, das Mail.ru-Bildverarbeitungsteam, intelligente Fotoverarbeitungssysteme entwickelt und implementiert: Suche nach Objekten, Szenen, Gesichtern usw. Eine weitere auffällige Technologie ist das Erkennen von Attraktionen. Und heute werde ich darüber sprechen, wie wir dieses Problem mithilfe von Deep Learning gelöst haben.
Stellen Sie sich die Situation vor: Sie sind in den Urlaub gefahren und haben ein paar Fotos mitgebracht. Und in einem Gespräch mit Freunden haben sie dich gebeten zu zeigen, wie du einen Palast, eine Burg, eine Pyramide, einen Tempel, einen See, einen Wasserfall, einen Berg usw. besucht hast. Sie scrollen verzweifelt mit Fotos durch den Ordner und versuchen, den richtigen zu finden. Höchstwahrscheinlich finden Sie es nicht unter Hunderten von Bildern und sagen, dass Sie es später zeigen werden.
Wir lösen dieses Problem, indem wir benutzerdefinierte Fotos in Alben gruppieren. So finden Sie mit wenigen Klicks ganz einfach die richtigen Bilder. Jetzt haben wir Alben auf Gesichtern, auf Objekten und Szenen sowie auf Attraktionen.
Fotos mit Sehenswürdigkeiten sind wichtig, da sie oft wichtige Momente unseres Lebens zeigen (z. B. Reisen). Dies können Fotografien im Hintergrund einer architektonischen Struktur oder eine vom Menschen unberührte Ecke der Natur sein. Daher müssen wir diese Fotos finden und den Benutzern einen einfachen und schnellen Zugriff darauf ermöglichen.
Funktionserkennung
Aber es gibt eine Nuance: Sie können nicht einfach ein Modell nehmen und trainieren, um die Sehenswürdigkeiten zu erkennen, es gibt viele Schwierigkeiten.
- Erstens können wir nicht klar beschreiben, was ein „Wahrzeichen“ ist. Wir können nicht sagen, warum ein Gebäude ein Wahrzeichen ist und daneben nicht. Dies ist kein formalisiertes Konzept, das die Formulierung des Erkennungsproblems erschwert.
- Zweitens sind die Sehenswürdigkeiten äußerst vielfältig. Es können historische oder kulturelle Gebäude sein - Tempel, Paläste, Burgen. Dies können die verschiedensten Denkmäler sein. Es können natürliche Objekte sein - Seen, Schluchten, Wasserfälle. Und ein Modell muss in der Lage sein, all diese Attraktionen zu finden.
- Drittens gibt es nur sehr wenige Bilder mit Sehenswürdigkeiten. Nach unseren Berechnungen sind sie nur in 1-3% der Benutzerfotos zu finden. Daher können wir uns keine Fehler bei der Erkennung erlauben, denn wenn wir einer Person ein Foto ohne einen Punkt von Interesse zeigen, wird es sofort wahrgenommen und führt zu Verwirrung und negativen Reaktionen. Im Gegenteil, wir haben der Person ein Foto mit einem Wahrzeichen in New York gezeigt, und sie war noch nie in Amerika gewesen. Das Erkennungsmodell muss also einen niedrigen FPR (False Positive Rate) aufweisen.
- Viertens deaktivieren etwa 50% der Benutzer oder sogar mehr die Speicherung von Geoinformationen beim Fotografieren. Wir müssen dies berücksichtigen und den Ort ausschließlich anhand des Bildes bestimmen. Die meisten Dienste, die es heute irgendwie schaffen, mit Sehenswürdigkeiten zu arbeiten, tun dies dank Geodaten. Unsere anfänglichen Anforderungen waren härter.
Ich werde jetzt mit Beispielen zeigen.
Hier sind ähnliche Objekte, drei französisch-gotische Kathedralen. Links ist die Amiens Kathedrale, in der Mitte der Reims Kathedrale, rechts ist Notre Dame de Paris.

Sogar eine Person braucht einige Zeit, um sie anzusehen und zu verstehen, dass es sich um verschiedene Kathedralen handelt, und die Maschine muss auch in der Lage sein, damit umzugehen, und zwar schneller als eine Person.
Und hier ist ein Beispiel für eine andere Schwierigkeit: Die drei Fotos auf der Folie sind Notre Dame de Paris, aufgenommen aus verschiedenen Blickwinkeln. Die Fotos erwiesen sich als sehr unterschiedlich, aber sie müssen alle erkannt und gefunden werden.

Natürliche Objekte unterscheiden sich grundlegend von architektonischen. Links ist Caesarea in Israel, rechts der English Park in München.

Auf diesen Fotos gibt es nur sehr wenige charakteristische Details, für die sich das Modell „durchsetzen“ kann.
Unsere Methode
Unsere Methode basiert vollständig auf tiefen Faltungs-Neuronalen Netzen. Als Lernansatz wählten sie das sogenannte Curriculum-Lernen - Lernen in mehreren Stufen. Um sowohl bei Vorhandensein als auch bei Fehlen von Geodaten effizienter arbeiten zu können, haben wir eine besondere Schlussfolgerung gezogen (Schlussfolgerung). Ich werde Ihnen die einzelnen Phasen genauer erläutern.
Datacet
Der Treibstoff für maschinelles Lernen sind Daten. Und zuerst mussten wir einen Datensatz für das Modelltraining sammeln.
Wir haben die Welt in 4 Regionen unterteilt, von denen jede in verschiedenen Ausbildungsstufen verwendet wird. Dann wurden Länder in jeder Region aufgenommen, für jedes Land wurde eine Liste von Städten zusammengestellt und eine Datenbank mit Fotos ihrer Attraktionen erstellt. Beispiele für Daten sind unten dargestellt.

Zuerst haben wir versucht, unser Modell auf der resultierenden Basis zu trainieren. Die Ergebnisse waren schlecht. Sie begannen zu analysieren und es stellte sich heraus, dass die Daten sehr "schmutzig" sind. Jede Attraktion hatte eine große Menge Müll. Was zu tun ist? Das manuelle Überprüfen der gesamten großen Datenmenge ist teuer, trostlos und nicht sehr intelligent. Aus diesem Grund haben wir eine automatische Reinigung der Basis durchgeführt, bei der die manuelle Verarbeitung nur in einem Schritt durchgeführt wird: Für jede Attraktion haben wir manuell 3-5 Referenzfotos ausgewählt, die die gewünschte Attraktion in einer mehr oder weniger korrekten Perspektive genau enthalten. Es stellt sich ziemlich schnell heraus, da das Volumen solcher Referenzdaten im Verhältnis zur gesamten Datenbank gering ist. Dann wird bereits eine automatische Reinigung basierend auf tiefen Faltungs-Neuronalen Netzen durchgeführt.
Weiterhin werde ich den Begriff "Einbetten" verwenden, unter dem ich Folgendes verstehen werde. Wir haben ein Faltungs-Neuronales Netzwerk, wir haben es für die Klassifizierung trainiert, die letzte Klassifizierungsschicht abgeschnitten, einige Bilder aufgenommen, sind durch das Netzwerk gefahren und haben einen numerischen Vektor am Ausgang erhalten. Ich werde es Einbettung nennen.
Wie gesagt, unsere Schulung wurde in mehreren Phasen durchgeführt, die Teilen unserer Datenbank entsprachen. Daher nehmen wir zuerst entweder ein neuronales Netzwerk aus der vorherigen Stufe oder ein Initialisierungsnetzwerk.
Wir werden die Fotos der Sehenswürdigkeiten über das Netzwerk laufen lassen und mehrere Einbettungen erhalten. Jetzt können Sie die Basis reinigen. Wir nehmen alle Bilder aus dem Datensatz für diese Attraktion auf und fahren jedes Bild durch das Netzwerk. Wir bekommen eine Reihe von Einbettungen und für jede von ihnen berücksichtigen wir die Entfernungen zur Einbettung von Standards. Dann berechnen wir die durchschnittliche Entfernung, und wenn sie mehr als einen bestimmten Schwellenwert beträgt, der der Parameter des Algorithmus ist, betrachten wir dies als keine Touristenattraktion. Wenn die durchschnittliche Entfernung unter dem Schwellenwert liegt, verlassen wir dieses Foto.
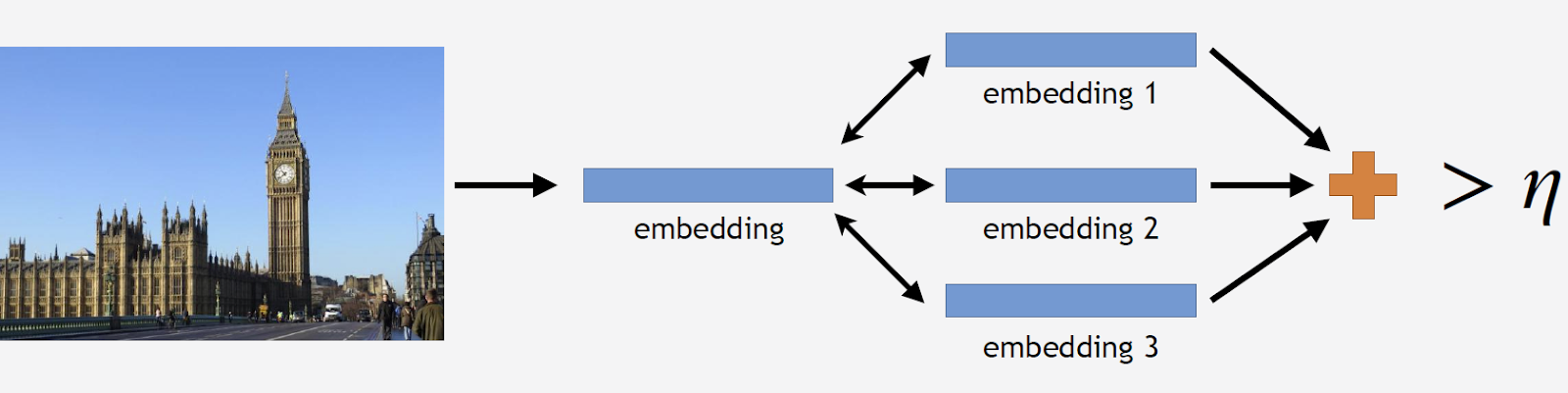
Als Ergebnis haben wir eine Datenbank erhalten, die mehr als 11.000 Attraktionen aus mehr als 500 Städten in 70 Ländern der Welt enthält - über 2,3 Millionen Fotos. Jetzt ist es an der Zeit, sich daran zu erinnern, dass die meisten Fotos überhaupt keine Attraktionen enthalten. Diese Informationen müssen irgendwie mit unseren Modellen geteilt werden. Aus diesem Grund haben wir unserer Datenbank 900.000 Fotos ohne Sehenswürdigkeiten hinzugefügt und unser Modell auf den resultierenden Datensatz trainiert.
Um die Qualität des Trainings zu messen, haben wir einen Offline-Test eingeführt. Basierend auf der Tatsache, dass Sehenswürdigkeiten nur in etwa 1-3% der Fotos zu finden sind, haben wir manuell einen Satz von 290 Fotos zusammengestellt, die Sehenswürdigkeiten zeigen. Dies sind verschiedene, recht komplexe Fotografien mit einer großen Anzahl von Objekten, die aus verschiedenen Winkeln aufgenommen wurden, damit der Test für das Modell so schwierig wie möglich ist. Nach dem gleichen Prinzip haben wir 11.000 Fotos ohne Sehenswürdigkeiten ausgewählt, die ebenfalls recht komplex sind, und wir haben versucht, Objekte zu finden, die den in unserer Datenbank verfügbaren Sehenswürdigkeiten sehr ähnlich sind.
Um die Qualität des Trainings zu beurteilen, messen wir die Genauigkeit unseres Modells anhand von Fotos mit und ohne Visier. Dies sind unsere beiden Hauptmetriken.
Bestehende Ansätze
In der wissenschaftlichen Literatur gibt es relativ wenig Informationen zur Seherkennung. Die meisten Lösungen basieren auf lokalen Funktionen. Die Idee ist, dass wir ein bestimmtes Anforderungsbild und ein Bild aus der Datenbank haben. In diesen Bildern finden wir lokale Zeichen - Schlüsselpunkte, und vergleichen sie. Wenn die Anzahl der Übereinstimmungen groß genug ist, haben wir unserer Meinung nach einen Punkt von Interesse gefunden.
Bisher ist die beste Methode die von Google vorgeschlagene Methode DELF (Deep Local Features), bei der ein Vergleich lokaler Features mit Deep Learning kombiniert wird. Wenn wir das Eingabebild durch das Faltungsnetzwerk laufen lassen, erhalten wir einige DELF-Zeichen.

Wie ist die Anerkennung von Attraktionen? Wir haben eine Datenbank mit Fotos und ein Eingabebild und möchten verstehen, ob sich dort eine Touristenattraktion befindet oder nicht. Wir lassen alle Bilder durch DELF laufen, wir erhalten die entsprechenden Zeichen für die Basis und für das Eingabebild. Dann führen wir eine Suche nach der Methode der nächsten Nachbarn durch und erhalten am Ausgang Kandidatenbilder mit Vorzeichen. Wir vergleichen diese Zeichen mit Hilfe der geometrischen Verifikation: Wenn sie erfolgreich bestanden werden, glauben wir, dass das Bild einen Punkt von Interesse enthält.
Faltungs-Neuronales Netz
Für Deep Learning ist das Pre-Training von entscheidender Bedeutung. Deshalb haben wir die Basis der Szenen genommen und darauf unser neuronales Netzwerk vorab trainiert. Warum so? Eine Szene ist ein komplexes Objekt, das eine große Anzahl anderer Objekte enthält. Und die Attraktion ist ein Sonderfall der Szene. Auf dieser Grundlage können wir dem Modell eine Vorstellung von einigen Funktionen auf niedriger Ebene geben, die dann für die erfolgreiche Erkennung von Attraktionen verallgemeinert werden können.
Als Modell haben wir ein neuronales Netzwerk aus der Residual-Netzwerkfamilie verwendet. Ihr Hauptmerkmal ist, dass sie einen Restblock verwenden, der eine Sprungverbindung enthält, die es dem Signal ermöglicht, frei zu passieren, ohne in Schichten mit Gewichten zu gelangen. Mit dieser Architektur können Sie tiefe Netzwerke qualitativ trainieren und mit dem Effekt der Gradientenunschärfe umgehen, der beim Lernen sehr wichtig ist.
Unser Modell ist Wide ResNet 50-2, eine Modifikation von ResNet 50, bei der die Anzahl der Windungen im internen Engpassblock verdoppelt wird.

Das Netzwerk ist sehr effizient. Wir haben Tests in unserer Szenendatenbank durchgeführt und Folgendes erhalten:
Wide ResNet erwies sich als fast doppelt so schnell wie das ziemlich große ResNet 200-Netzwerk. Die Betriebsgeschwindigkeit ist für den Betrieb sehr wichtig. Aufgrund der Gesamtheit dieser Umstände haben wir Wide ResNet 50-2 als unser wichtigstes neuronales Netzwerk verwendet.
Schulung
Um das Netzwerk zu trainieren, brauchen wir Verlust (Verlustfunktion). Um es auszuwählen, haben wir uns für den metrischen Lernansatz entschieden: Ein neuronales Netzwerk wird so trainiert, dass Vertreter derselben Klasse in einem Cluster zusammengefasst werden. Gleichzeitig sollten Cluster für verschiedene Klassen so weit wie möglich voneinander entfernt sein. Für Attraktionen haben wir den Center-Verlust verwendet, der Punkte derselben Klasse zu einem bestimmten Center zusammenführt. Ein wichtiges Merkmal dieses Ansatzes ist, dass keine negative Stichprobe erforderlich ist, was in den späteren Phasen des Trainings ein ziemlich schwieriges Verfahren ist.
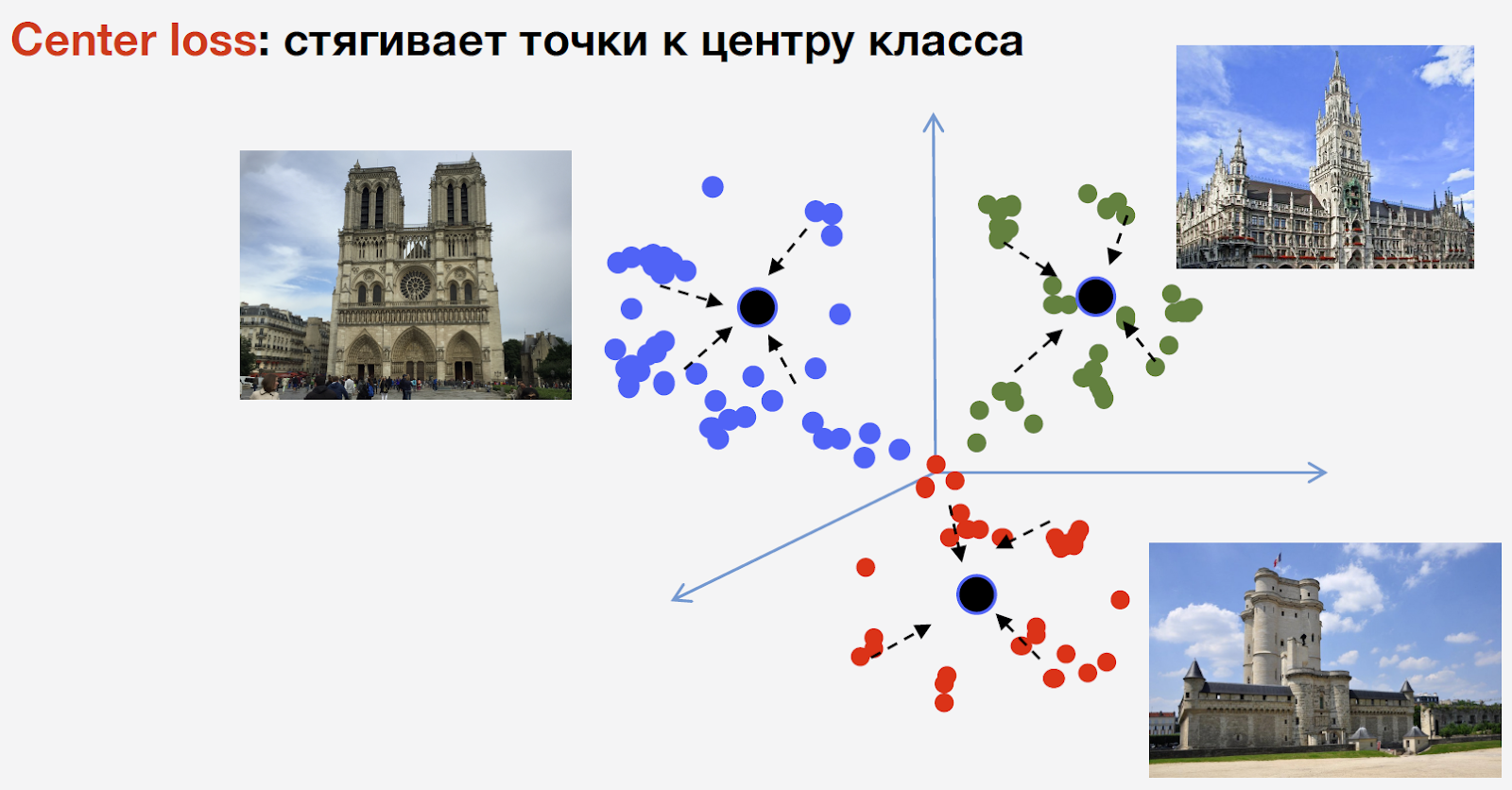
Ich möchte Sie daran erinnern, dass wir n Klassen von Attraktionen und eine andere Klasse von „Nicht-Attraktionen“ haben. Der Center-Verlust wird dafür nicht verwendet. Wir meinen, dass ein Orientierungspunkt ein und dasselbe Objekt ist und eine Struktur darin ist. Daher ist es ratsam, ein Zentrum dafür in Betracht zu ziehen. Aber keine Touristenattraktion kann etwas sein, und das Zentrum für ihn zu betrachten, ist unvernünftig.
Dann haben wir alles zusammengestellt und ein Modell für das Training bekommen. Es besteht aus drei Hauptteilen:
- Faltungsneurales Netzwerk Wide ResNet 50-2, auf der Grundlage von Szenen vorab trainiert;
- Teile der Einbettung, bestehend aus einer vollständig verbundenen Schicht und einer Chargennormschicht;
- Ein Klassifikator, bei dem es sich um eine vollständig verbundene Schicht handelt, gefolgt von einem Paar Softmax-Verlust und Center-Verlust.

Wie Sie sich erinnern, ist unsere Basis nach Regionen der Welt in 4 Teile unterteilt. Wir verwenden diese 4 Teile als Teil des Lehrplan-Lernparadigmas. In jeder Phase haben wir den aktuellen Datensatz, fügen einen weiteren Teil der Welt hinzu und erhalten einen neuen Trainingsdatensatz.
Das Modell besteht aus drei Teilen, und für jeden von ihnen verwenden wir unsere eigene Lernrate im Training. Dies ist erforderlich, damit das Netzwerk nicht nur die Sehenswürdigkeiten aus dem neuen Teil des Datensatzes lernen kann, den wir hinzugefügt haben, sondern auch die bereits gelernten Daten nicht vergisst. Nach vielen Experimenten erwies sich dieser Ansatz als der effektivste.
Also haben wir das Modell trainiert. Sie müssen verstehen, wie es funktioniert. Verwenden wir die Klassenaktivierungskarte, um zu sehen, welcher Teil des Bildes am besten auf unser neuronales Netzwerk reagiert. Im Bild unten in der ersten Zeile die Eingabebilder und in der zweiten Zeile die Klassenaktivierungskarte aus dem Raster, das wir im vorherigen Schritt trainiert haben.

Die Heatmap zeigt, welchen Teilen des Bildes das Netzwerk mehr Aufmerksamkeit schenkt. Aus der Klassenaktivierungskarte ist ersichtlich, dass unser neuronales Netzwerk das Konzept der Anziehung erfolgreich gelernt hat.
Folgerung
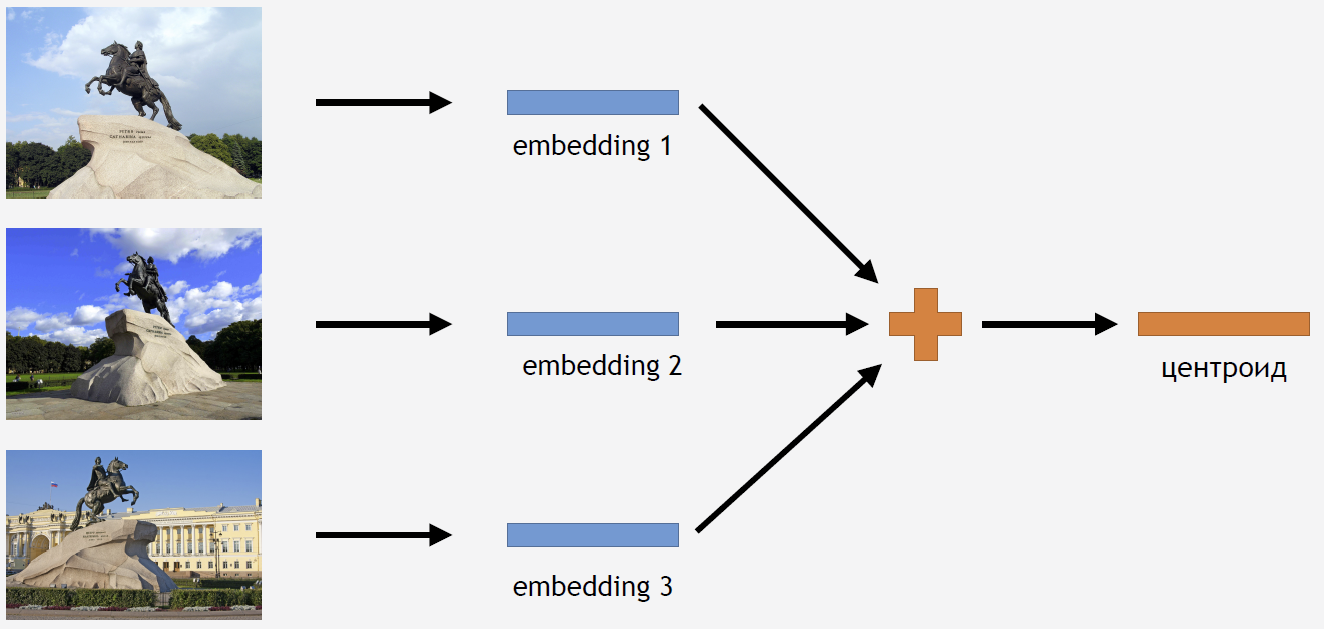
Jetzt müssen Sie dieses Wissen irgendwie nutzen, um das Ergebnis zu erhalten. Da wir den Center-Verlust für das Training verwendet haben, erscheint es ziemlich logisch, auch den Tserotoid für Attraktionen zu berechnen.
Dazu nehmen wir einen Teil der Bilder aus dem Trainingsset für eine Art Attraktion, zum Beispiel für den Bronze Horseman. Wir führen sie durch das Netzwerk, erhalten Einbettungen, Durchschnittswerte und erhalten einen Schwerpunkt.
Es stellt sich jedoch die Frage: Wie viele Zentroide für eine Attraktion sind sinnvoll zu berechnen? Die Antwort erscheint zunächst klar und logisch: ein Schwerpunkt. Dies stellte sich jedoch als nicht ganz so heraus. Zuerst haben wir uns auch für einen Schwerpunkt entschieden und ein ziemlich gutes Ergebnis erzielt. Warum müssen Sie ein paar Zentroide nehmen?
Erstens sind unsere Daten nicht ganz sauber. Obwohl wir den Datensatz bereinigt haben, haben wir nur den Müll entfernt. Und wir könnten Bilder haben, die nicht als Müll betrachtet werden können, aber das Ergebnis verschlechtern.
Zum Beispiel habe ich eine Wahrzeichenklasse im Winterpalast. Ich möchte einen Schwerpunkt für ihn zählen. Das Set enthielt jedoch eine Reihe von Fotografien mit dem Palastplatz und dem Bogen des Generalstabs. Wenn wir den Schwerpunkt in allen Bildern berücksichtigen, wird er nicht zu stabil sein. Es ist notwendig, ihre Einbettungen, die aus dem üblichen Raster erhalten werden, irgendwie zu gruppieren, nur den Schwerpunkt zu nehmen, der für den Winterpalast verantwortlich ist, und den Durchschnitt anhand dieser Daten zu berechnen.

Zweitens können Fotos aus verschiedenen Blickwinkeln aufgenommen werden.
Ich werde den Glockenturm von Belfort in Brügge als Beispiel für dieses Verhalten anführen. Zwei Zentroide werden für sie gezählt. In der oberen Reihe des Bildes befinden sich die Fotos, die näher am ersten Schwerpunkt liegen, und in der zweiten Reihe die Fotos, die näher am zweiten Schwerpunkt liegen:

Der erste Schwerpunkt ist für die „intelligenteren“ Nahaufnahmen vom Brügger Marktplatz verantwortlich. Und der zweite Schwerpunkt ist für Fotos verantwortlich, die aus der Ferne von angrenzenden Straßen aufgenommen wurden.
Es stellt sich heraus, dass wir durch Berechnung mehrerer Zentroide pro Klasse eines interessierenden Punktes verschiedene Winkel dieses interessierenden Punktes in der Inferenz anzeigen können.
Wie finden wir diese Mengen, um Schwerpunkte zu berechnen? Wir wenden hierarchische Clusterbildung auf die Datensätze für jeden Punkt von Interesse an - vollständige Verknüpfung. Mit seiner Hilfe finden wir gültige Cluster, anhand derer wir Zentroide berechnen. Mit gültigen Clustern meinen wir diejenigen, die aufgrund von Clustering mindestens 50 Fotos enthalten. Die verbleibenden Cluster werden verworfen. Als Ergebnis stellte sich heraus, dass etwa 20% der Sehenswürdigkeiten mehr als einen Schwerpunkt haben.
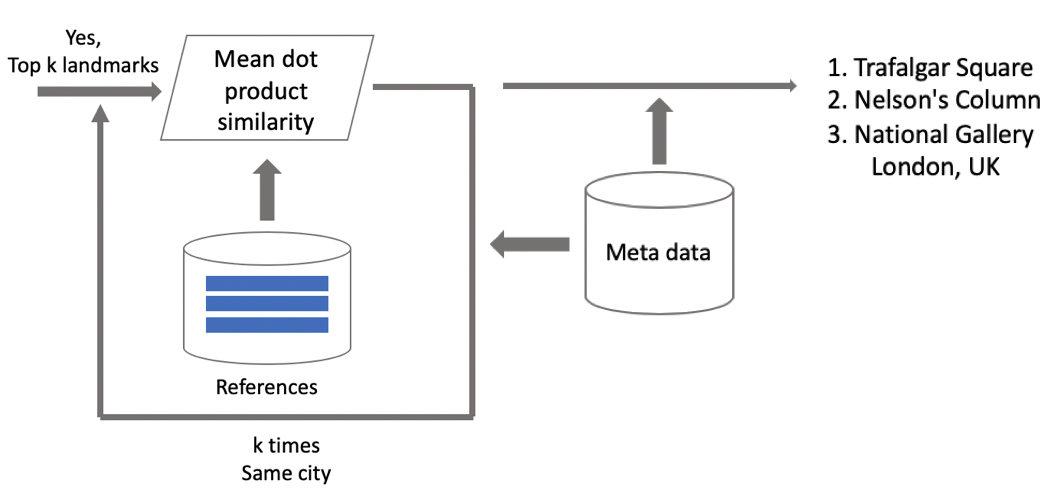
Nun Schlussfolgerung. Wir berechnen es in zwei Schritten: Zuerst führen wir das Eingabebild durch unser Faltungsnetzwerk und erhalten die Einbettung. Anschließend verwenden wir das Skalarprodukt, das wir mit den Einbettungen vergleichen. Wenn die Bilder Geodaten enthalten, beschränken wir die Suche auf Schwerpunkte, die sich auf die Attraktionen beziehen, die sich auf einem Quadrat von 1 pro 1 km vom Aufnahmeort befinden. Auf diese Weise können Sie genauer suchen und einen niedrigeren Schwellenwert für den nachfolgenden Vergleich auswählen. Wenn der erhaltene Abstand größer als der Schwellenwert ist, der ein Parameter des Algorithmus ist, sagen wir, dass auf dem Foto ein Punkt von Interesse mit dem Maximalwert des Skalarprodukts vorhanden ist. Wenn weniger, dann ist dies keine Touristenattraktion.
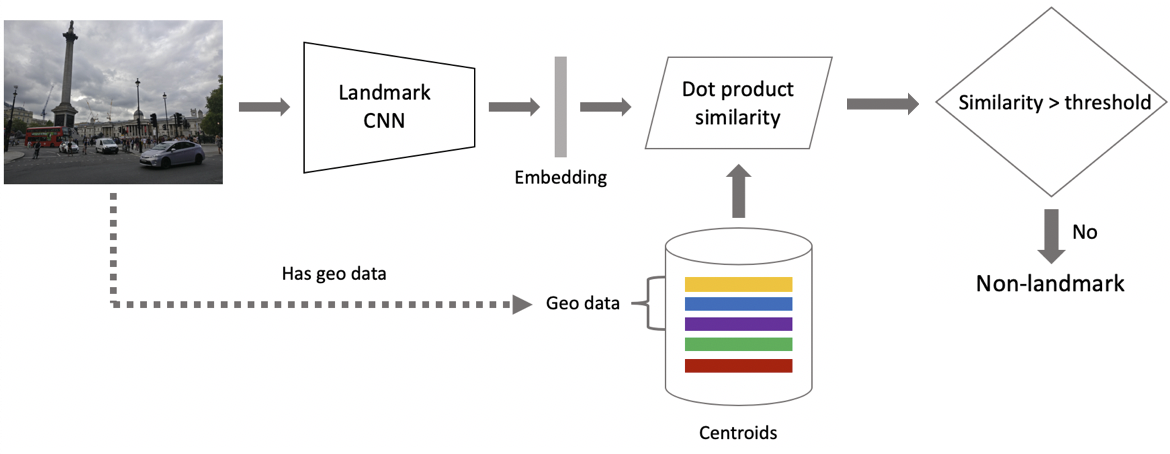
Angenommen, das Foto enthält eine Landmarke. Wenn wir Geodaten haben, verwenden wir diese und zeigen die Antwort an. Wenn keine Geodaten vorhanden sind, führen Sie eine zusätzliche Überprüfung durch. Als wir den Datensatz bereinigten, erstellten wir eine Reihe von Referenzbildern für jede Klasse von Attraktionen. Für sie können wir die Einbettungen zählen und dann den durchschnittlichen Abstand von ihnen zur Einbettung des Anforderungsbildes berechnen. Wenn der Schwellenwert überschritten wird, wird die Überprüfung bestanden. Wir fügen Metadaten hinzu und zeigen das Ergebnis an. Es ist wichtig zu beachten, dass wir ein solches Verfahren für mehrere Attraktionen durchführen können, die im Bild gefunden wurden.
Testergebnisse
Wir haben unser Modell mit DELF verglichen, für das wir die Parameter verwendet haben, bei denen es die besten Ergebnisse bei unserem Test zeigte. Die Ergebnisse waren fast gleich.
: ( 100 ), 87 % , . : 85,3 %. 46 %, — .
/B- . 10 %, 3 %, 13 %.
DELF. GPU DELF 7 , 7 , 1 . CPU DELF . CPU 15 . , .
:
. .
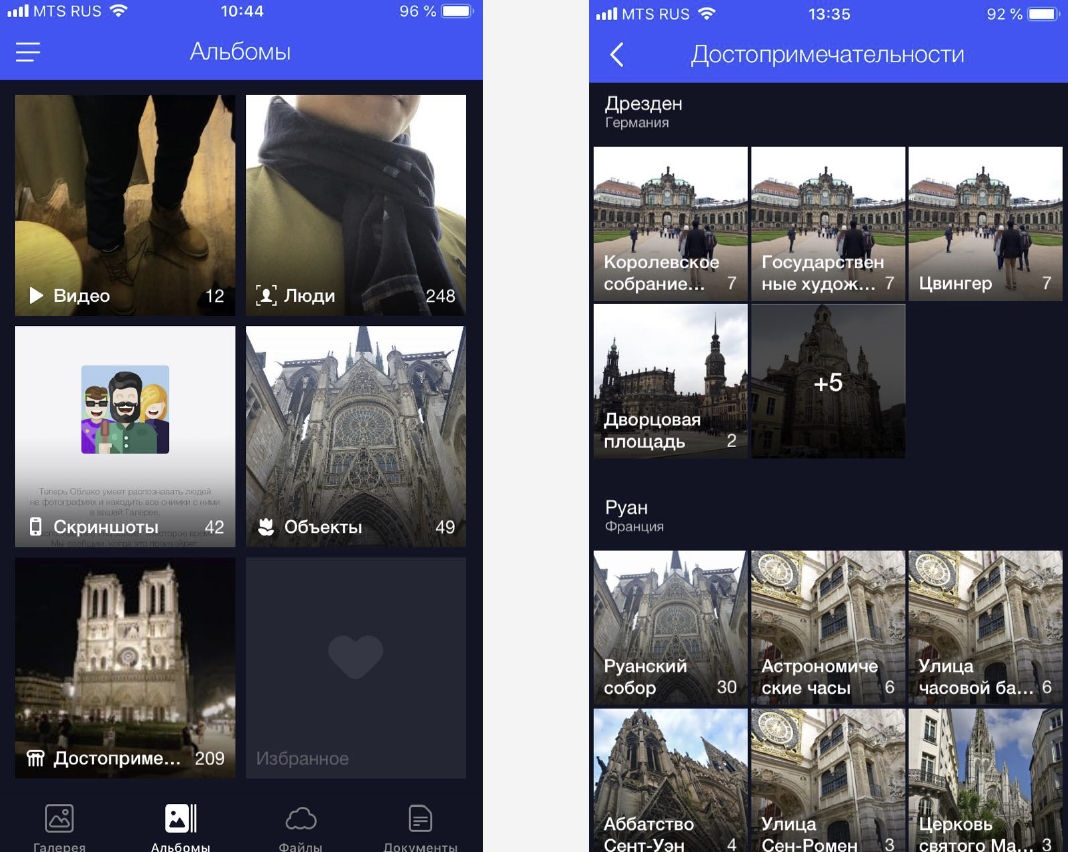
, . «», «», «». , . , .
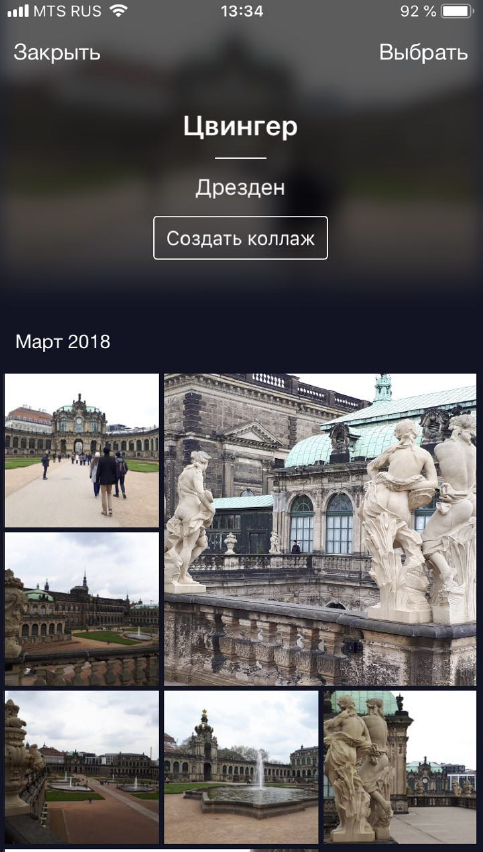
: , , . Instagram , , — .
Zusammenfassung
.
- . , . .
- deep metric learning, .
- curriculum learning — . . inference , .
, — . , , . - . !