Hallo allerseits! Ich heiße Pavel Agaletsky. Ich arbeite als Teamleiter in einem Team, das ein Lamoda-Liefersystem entwickelt. 2018 sprach ich auf der HighLoad ++ - Konferenz und möchte heute eine Abschrift meines Berichts vorstellen.
Mein Thema ist der Erfahrung unseres Unternehmens bei der Bereitstellung von Systemen und Diensten in verschiedenen Umgebungen gewidmet. Ausgehend von unserer prähistorischen Zeit, als wir alle Systeme auf regulären virtuellen Servern bereitstellten, endete dies mit einem schrittweisen Übergang von Nomad zu einer Bereitstellung auf Kubernetes. Ich werde Ihnen sagen, warum wir dies getan haben und welche Probleme wir dabei hatten.
Stellen Sie Anwendungen auf der VM bereit
Zunächst wurden vor 3 Jahren alle Systeme und Dienste des Unternehmens auf normalen virtuellen Servern bereitgestellt. Technisch war es so organisiert, dass der gesamte Code unserer Systeme mit automatischen Build-Tools unter Verwendung von Jenkins erstellt und zusammengesetzt wurde. Mit Ansible rollte er unser Versionskontrollsystem auf virtuelle Server aus. Darüber hinaus wurde jedes System in unserem Unternehmen mindestens auf zwei Servern bereitgestellt: einer davon war auf dem Kopf, der zweite auf dem Kopf. Diese beiden Systeme waren in allen Einstellungen, Leistung, Konfiguration und mehr absolut identisch. Der einzige Unterschied zwischen ihnen bestand darin, dass der Kopf Benutzerverkehr erhielt, während der Schwanz niemals Benutzerverkehr erhielt.
Warum wurde das gemacht?
Bei der Bereitstellung neuer Versionen unserer Anwendung wollten wir die Möglichkeit einer nahtlosen Einführung bieten, dh ohne erkennbare Konsequenzen für die Benutzer. Dies wurde aufgrund der Tatsache erreicht, dass die nächste zusammengebaute Version mit Ansible am Heck ausgerollt wurde. Dort konnten die an der Bereitstellung beteiligten Personen überprüfen und sicherstellen, dass alles in Ordnung war: Alle Metriken, Abschnitte und Anwendungen funktionierten. Die erforderlichen Skripte werden gestartet. Erst nachdem sie überzeugt waren, dass alles in Ordnung ist, wurde der Verkehr umgeschaltet. Er fing an, zu dem Server zu gehen, der vorher Schwanz war. Und derjenige, der vorher der Kopf war, wurde ohne Benutzerverkehr gelassen, während mit der vorherigen Version unserer Anwendung darauf.
Somit war es für Benutzer nahtlos. Weil das Umschalten gleichzeitig erfolgt, da es sich nur um ein Balancer-Umschalten handelt. Es ist sehr einfach, ein Rollback auf die vorherige Version durchzuführen, indem Sie einfach den Balancer zurückschalten. Wir konnten auch die Produktionsfähigkeit der Anwendung überprüfen, noch bevor der Benutzerverkehr zu ihr gelangt, was praktisch genug war.
Welche Vorteile haben wir dabei gesehen?
- Erstens funktioniert es ganz einfach. Jeder versteht, wie dieses Bereitstellungsschema funktioniert, da die meisten Benutzer jemals auf normalen virtuellen Servern bereitgestellt haben.
- Dies ist sehr zuverlässig , da die Bereitstellungstechnologie einfach ist und von Tausenden von Unternehmen getestet wird. Auf diese Weise werden Millionen von Servern bereitgestellt. Es ist schwer, etwas zu zerbrechen.
- Und schließlich könnten wir atomare Bereitstellungen erhalten . Bereitstellungen, die gleichzeitig für Benutzer erfolgen, ohne dass ein merklicher Wechsel zwischen der alten und der neuen Version erforderlich ist.
Dabei haben wir aber auch einige Mängel gesehen:
- Neben der Produktionsumgebung und der Entwicklungsumgebung gibt es noch andere Umgebungen. Zum Beispiel Qa und Vorproduktion. Zu dieser Zeit hatten wir viele Server und ungefähr 60 Dienste. Aus diesem Grund musste für jeden Dienst die für ihn relevante Version der virtuellen Maschine verwaltet werden. Wenn Sie Bibliotheken aktualisieren oder neue Abhängigkeiten installieren möchten, müssen Sie dies in allen Umgebungen tun. Es war auch erforderlich, die Zeit, zu der Sie die nächste neue Version Ihrer Anwendung bereitstellen wollten, mit der Zeit zu synchronisieren, zu der die Entwickler die erforderlichen Umgebungseinstellungen vorgenommen haben. In diesem Fall ist es leicht, in eine Situation zu geraten, in der sich unsere Umgebung in allen aufeinanderfolgenden Umgebungen gleichzeitig geringfügig unterscheidet. In der QS-Umgebung gibt es beispielsweise einige Versionen von Bibliotheken und in der Produktion andere, was zu Problemen führen wird.
- Schwierigkeiten beim Aktualisieren der Abhängigkeiten Ihrer Anwendung. Es hängt nicht von dir ab, sondern vom anderen Team. Nämlich aus dem Befehl devops, der den Server unterstützt. Sie müssen eine geeignete Aufgabe für sie festlegen und eine Beschreibung dessen geben, was Sie tun möchten.
- Zu dieser Zeit wollten wir auch die großen großen Monolithen, die wir hatten, in separate kleine Dienste aufteilen, da wir verstanden hatten, dass es immer mehr von ihnen geben würde. Zu diesem Zeitpunkt hatten wir bereits mehr als 100 davon. Für jeden neuen Dienst musste eine separate neue virtuelle Maschine erstellt werden, die ebenfalls gewartet und bereitgestellt werden muss. Außerdem benötigen Sie nicht ein Auto, sondern mindestens zwei. Dazu wird noch die QS-Umgebung hinzugefügt. Dies verursacht Probleme und macht das Erstellen und Starten neuer Systeme für Sie schwieriger, kostspieliger und zeitaufwändiger.
Aus diesem Grund haben wir beschlossen, dass es bequemer ist, von der Bereitstellung gewöhnlicher virtueller Maschinen zur Bereitstellung unserer Anwendungen im Docker-Container zu wechseln. Wenn Sie Docker haben, benötigen Sie ein System, das die Anwendung im Cluster ausführen kann, da Sie den Container nicht einfach anheben können. Normalerweise möchten Sie verfolgen, wie viele Container angehoben werden, damit sie automatisch ansteigen. Aus diesem Grund mussten wir ein Steuerungssystem wählen.
Wir haben lange darüber nachgedacht, welche man nehmen kann. Tatsache ist, dass zu diesem Zeitpunkt dieser Stapel von Bereitstellungen auf normalen virtuellen Servern etwas veraltet war, da es dort nicht die neuesten Versionen von Betriebssystemen gab. Irgendwann stand sogar FreeBSD da, was nicht sehr bequem zu warten war. Wir haben verstanden, dass Sie so schnell wie möglich auf Docker migrieren müssen. Unsere Entwickler haben ihre vorhandenen Erfahrungen mit verschiedenen Lösungen untersucht und sich für ein System wie Nomad entschieden.
Wechseln Sie zu Nomad
Nomad ist ein HashiCorp-Produkt. Sie sind auch für ihre anderen Entscheidungen bekannt:
 Consul
Consul ist ein Tool zur Serviceerkennung.
Terraform ist ein Serververwaltungssystem, mit dem Sie sie über eine Konfiguration konfigurieren können, die als Infrastruktur als Code bezeichnet wird.
Mit Vagrant können Sie virtuelle Maschinen lokal oder in der Cloud über bestimmte Konfigurationsdateien bereitstellen.
Nomad schien zu dieser Zeit eine ziemlich einfache Lösung zu sein, zu der Sie schnell wechseln können, ohne die gesamte Infrastruktur zu verändern. Darüber hinaus ist es recht einfach zu beherrschen. Deshalb haben wir es als unser Filtersystem für unseren Container gewählt.
Was ist erforderlich, um Ihr System vollständig für Nomad bereitzustellen?
- Zunächst benötigen Sie das Docker-Image Ihrer Anwendung. Sie müssen es erstellen und in den Docker-Image-Speicher stellen. In unserem Fall ist dies künstlich - ein solches System, mit dem Sie verschiedene Artefakte verschiedener Typen hineinschieben können. Es kann Archive, Docker-Images, PHP-Composer-Pakete, NPM-Pakete usw. speichern.
- Sie benötigen außerdem eine Konfigurationsdatei , die Nomad mitteilt, was, wo und wie viel Sie bereitstellen möchten.
Wenn wir über Nomad sprechen, wird die HCL-Sprache als Informationsdateiformat verwendet, das für
HashiCorp Configuration Language steht . Dies ist eine Obermenge von Yaml, mit der Sie Ihren Service in Bezug auf Nomad beschreiben können.

Hier können Sie angeben, wie viele Container Sie bereitstellen möchten, von welchen Images verschiedene Parameter während der Bereitstellung übertragen werden sollen. Sie füttern also diese Nomad-Datei und sie startet entsprechend die entsprechenden Container in der Produktion.
In unserem Fall haben wir festgestellt, dass es nicht sehr praktisch ist, für jeden Dienst genau die gleichen, identischen HLC-Dateien zu schreiben, da es viele Dienste gibt und Sie diese manchmal aktualisieren möchten. Es kommt vor, dass ein Dienst nicht in einer Instanz bereitgestellt wird, sondern in den unterschiedlichsten. Zum Beispiel hat eines der Systeme, die wir in der Produktion haben, mehr als 100 Instanzen in der Produktion. Sie werden von denselben Images gestartet, unterscheiden sich jedoch in den Konfigurationseinstellungen und Konfigurationsdateien.
Aus diesem Grund haben wir beschlossen, dass es für uns praktisch ist, alle Konfigurationsdateien für die Bereitstellung in einem gemeinsamen Repository zu speichern. So wurden sie beobachtbar: Sie waren leicht zu warten und es war möglich zu sehen, welche Systeme wir hatten. Bei Bedarf ist es auch einfach, etwas zu aktualisieren oder zu ändern. Das Hinzufügen eines neuen Systems ist ebenfalls nicht schwierig - geben Sie einfach die Konfigurationsdatei in das neue Verzeichnis ein. Darin befinden sich die Dateien: service.hcl, die eine Beschreibung unseres Dienstes enthalten, und einige env-Dateien, mit denen dieser Dienst, der in der Produktion bereitgestellt wird, konfiguriert werden kann.

Einige unserer Systeme werden jedoch nicht in einer Kopie, sondern in mehreren gleichzeitig im Produkt bereitgestellt. Aus diesem Grund haben wir beschlossen, dass es für uns zweckmäßig ist, Konfigurationen nicht in ihrer reinen Form, sondern in ihrer Vorlagenform zu speichern. Und als Vorlagensprache haben wir
jinja 2 gewählt . In diesem Format speichern wir sowohl die Konfigurationen des Dienstes selbst als auch die dafür benötigten env-Dateien.
Darüber hinaus haben wir im Repository eine gemeinsame Skriptbereitstellung für alle Projekte bereitgestellt, mit der Sie Ihren Service in der Produktion, in der richtigen Umgebung und am richtigen Ziel starten und bereitstellen können. In dem Fall, als wir unsere HCL-Konfiguration in eine Vorlage verwandelten, sah die HCL-Datei, die zuvor eine reguläre Nomad-Konfiguration war, in diesem Fall etwas anders aus.
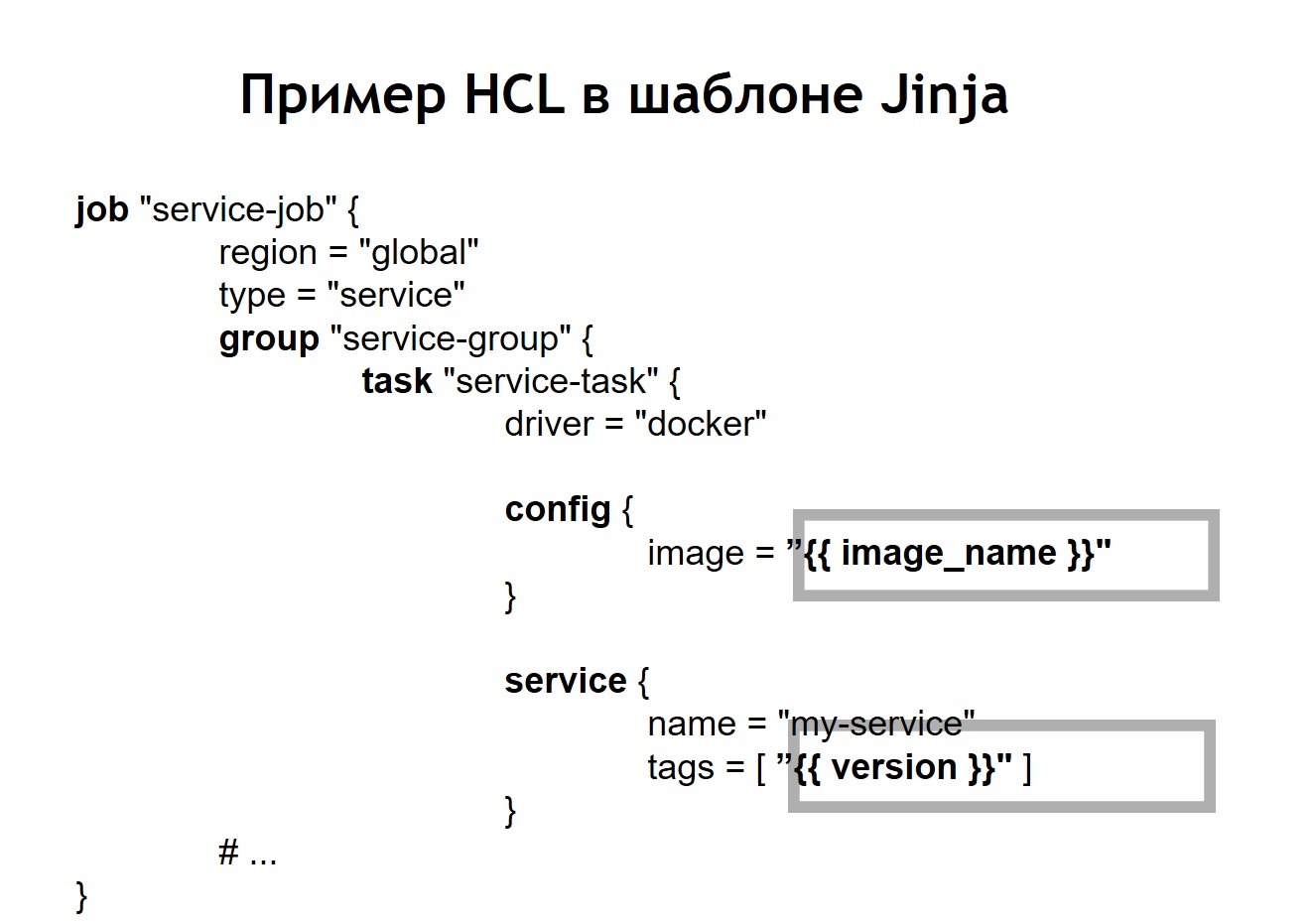
Das heißt, wir haben einige Variablen in der Konfigurationsdatei durch Variableneinfügungen ersetzt, die aus env-Dateien oder aus anderen Quellen stammen. Darüber hinaus konnten wir HL-Dateien dynamisch erfassen, dh wir können nicht nur die üblichen Variableneinfügungen verwenden. Da jinja Schleifen und Bedingungen unterstützt, können Sie dort auch Konfigurationsdateien erstellen, die je nachdem, wo genau Sie Ihre Anwendungen bereitstellen, variieren.
Sie möchten Ihren Service beispielsweise in der Vorproduktion und in der Produktion bereitstellen. Angenommen, Sie möchten in der Vorproduktion keine Crown-Skripte ausführen, sondern den Dienst nur in einer separaten Domäne anzeigen, um sicherzustellen, dass er funktioniert. Für jeden, der einen Dienst bereitstellt, sieht der Prozess sehr einfach und transparent aus. Es reicht aus, die Datei deploy.sh auszuführen, anzugeben, welchen Dienst Sie bereitstellen möchten und in welchem Ziel. Sie möchten beispielsweise ein bestimmtes System in Russland, Weißrussland oder Kasachstan bereitstellen. Ändern Sie dazu einfach einen der Parameter, und Sie erhalten die richtige Konfigurationsdatei.
Wenn der Nomad-Dienst bereits in Ihrem Cluster bereitgestellt ist, sieht dies folgendermaßen aus.
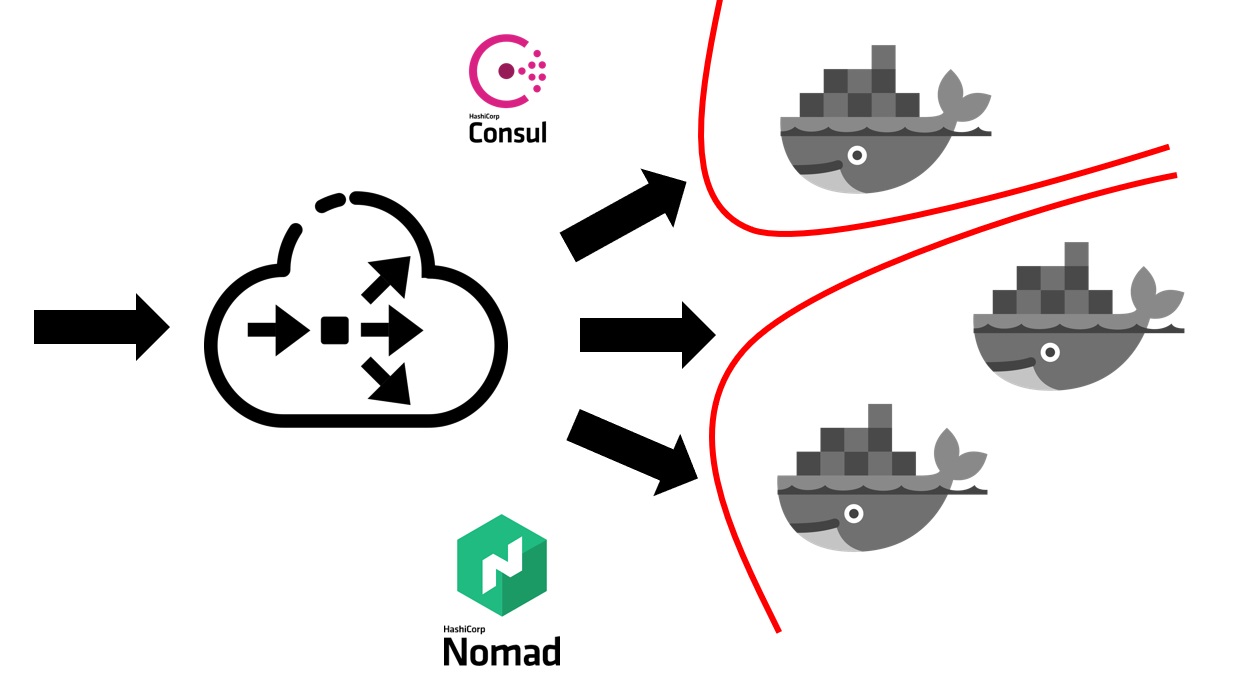
Zuerst benötigen Sie einen Balancer außerhalb, der den gesamten Benutzerverkehr in sich aufnimmt. Er wird mit Consul zusammenarbeiten und von ihm herausfinden, wo, auf welchem Knoten, unter welcher IP-Adresse sich ein bestimmter Dienst befindet, der einem bestimmten Domainnamen entspricht. Dienstleistungen in Consul kommen von Nomad selbst. Da es sich um Produkte desselben Unternehmens handelt, sind sie gut miteinander verbunden. Wir können sagen, dass Nomad out of the box alle darin eingeführten Dienste in Consul registrieren kann.
Nachdem Ihr externer Balancer herausgefunden hat, an welchen Dienst Datenverkehr gesendet werden muss, leitet er ihn an den entsprechenden Container oder an mehrere Container weiter, die Ihrer Anwendung entsprechen. Natürlich muss man auch über Sicherheit nachdenken. Obwohl alle Dienste auf denselben virtuellen Maschinen in Containern ausgeführt werden, erfordert dies normalerweise das Verbot des freien Zugriffs von jedem Dienst auf einen anderen. Dies haben wir durch Segmentierung erreicht. Jeder Dienst wurde in einem eigenen virtuellen Netzwerk gestartet, in dem Routing-Regeln und Regeln zum Zulassen / Verweigern des Zugriffs auf andere Systeme und Dienste vorgeschrieben wurden. Sie können sich sowohl innerhalb als auch außerhalb dieses Clusters befinden. Wenn Sie beispielsweise verhindern möchten, dass ein Dienst eine Verbindung zu einer bestimmten Datenbank herstellt, kann dies durch Segmentierung auf Netzwerkebene erfolgen. Das heißt, auch aus Versehen können Sie nicht versehentlich eine Verbindung von einer Testumgebung zu Ihrer Produktionsbasis herstellen.
Was hat uns der Übergang in Bezug auf die Humanressourcen gekostet?
Der Übergang des gesamten Unternehmens zu Nomad dauerte ca. 5-6 Monate. Wir haben ohne Service gewechselt, aber ziemlich schnell. Jedes Team musste seine eigenen Container für Dienstleistungen erstellen.
Wir haben einen solchen Ansatz gewählt, dass jedes Team für die Docker-Images seiner Systeme selbst verantwortlich ist. Devops stellen auch die allgemeine Infrastruktur bereit, die für die Bereitstellung erforderlich ist, dh Unterstützung für den Cluster selbst, Unterstützung für das CI-System usw. Zu dieser Zeit hatten wir mehr als 60 Systeme auf Nomad umgestellt, es stellte sich heraus, dass es ungefähr zweitausend Container waren.
Devops ist für die gesamte Infrastruktur aller mit der Bereitstellung verbundenen Server verantwortlich. Und jedes Entwicklungsteam ist wiederum für die Implementierung von Containern für sein spezifisches System verantwortlich, da es das Team ist, das weiß, was es im Allgemeinen in einem bestimmten Container benötigt.
Gründe für das Verlassen von Nomad
Welche Vorteile haben wir durch den Wechsel zur Bereitstellung mit Nomad und Docker erzielt?
- Wir haben für alle Umgebungen die gleichen Bedingungen bereitgestellt . In einer Entwicklungsfirma, QS-Umgebung, Vorproduktion, Produktion werden dieselben Container-Images mit denselben Abhängigkeiten verwendet. Dementsprechend haben Sie praktisch keine Chance, dass sich die Produktion von der unterscheidet, die Sie zuvor lokal oder in einer Testumgebung getestet haben.
- Wir haben auch festgestellt, dass es einfach genug ist , einen neuen Service hinzuzufügen . Aus Sicht der Bereitstellung werden neue Systeme sehr einfach gestartet. Es reicht aus, in das Repository zu gehen, in dem die Konfigurationen gespeichert sind, dort die nächste Konfiguration für Ihr System hinzuzufügen, und schon sind Sie bereit. Sie können Ihr System ohne zusätzlichen Aufwand von Entwicklern in der Produktion bereitstellen.
- Es stellte sich heraus, dass alle Konfigurationsdateien in einem gemeinsamen Repository überwacht wurden . In diesem Moment, als wir unsere Systeme mithilfe virtueller Server bereitstellten, verwendeten wir Ansible, in dem sich die Konfigurationen im selben Repository befanden. Für die meisten Entwickler war es jedoch etwas schwieriger, damit zu arbeiten. Hier ist das Volumen an Konfigurationen und Code, das Sie hinzufügen müssen, um den Dienst bereitzustellen, viel kleiner geworden. Außerdem ist es für Entwickler sehr einfach, es zu reparieren oder zu ändern. Bei Übergängen, beispielsweise in der neuen Version von Nomad, können sie alle an derselben Stelle liegenden Betriebsdateien aufnehmen und massiv aktualisieren.
Wir hatten aber auch einige Mängel:
Es stellte sich heraus, dass wir im Fall von Nomad
keine nahtlosen Bereitstellungen erreichen konnten . Wenn Container unter verschiedenen Bedingungen gerollt werden, kann sich herausstellen, dass sie ausgeführt werden, und Nomad hat sie als Container wahrgenommen, der bereit ist, Verkehr aufzunehmen. Dies geschah noch bevor die darin enthaltene Anwendung gestartet werden konnte. Aus diesem Grund begann das System für kurze Zeit 500 Fehler zu erzeugen, da der Verkehr zu dem Container ging, der noch nicht bereit ist, ihn zu empfangen.
Wir sind auf einige
Fehler gestoßen. Der größte Fehler ist, dass Nomad einen großen Cluster nicht sehr gut akzeptiert, wenn Sie über viele Systeme und Container verfügen. Wenn Sie einen der im Nomad-Cluster enthaltenen Server in Betrieb nehmen möchten, besteht eine hohe Wahrscheinlichkeit, dass sich der Cluster nicht sehr gut anfühlt und auseinander fällt. Ein Teil der Container kann beispielsweise fallen und nicht steigen - dies ist anschließend für Sie sehr teuer, wenn sich alle Ihre Produktionssysteme in einem von Nomad verwalteten Cluster befinden.
Aus diesem Grund haben wir uns überlegt, wohin wir als nächstes gehen sollen. Zu dieser Zeit wurden wir uns viel besser bewusst, was wir erreichen wollen. Wir wollen nämlich Zuverlässigkeit, etwas mehr Funktionen als Nomad und ein ausgereifteres, stabileres System.
In dieser Hinsicht fiel unsere Wahl auf Kubernetes als beliebteste Plattform für den Start von Clustern. Vor allem, wenn die Größe und Menge unserer Container recht groß war. Für solche Zwecke schien Kubernetes das am besten geeignete System von denen zu sein, die wir sehen konnten.
Ich gehe nach Kubernetes
Ich werde ein wenig über die Grundkonzepte von Kubernetes sprechen und wie sie sich von Nomad unterscheiden.
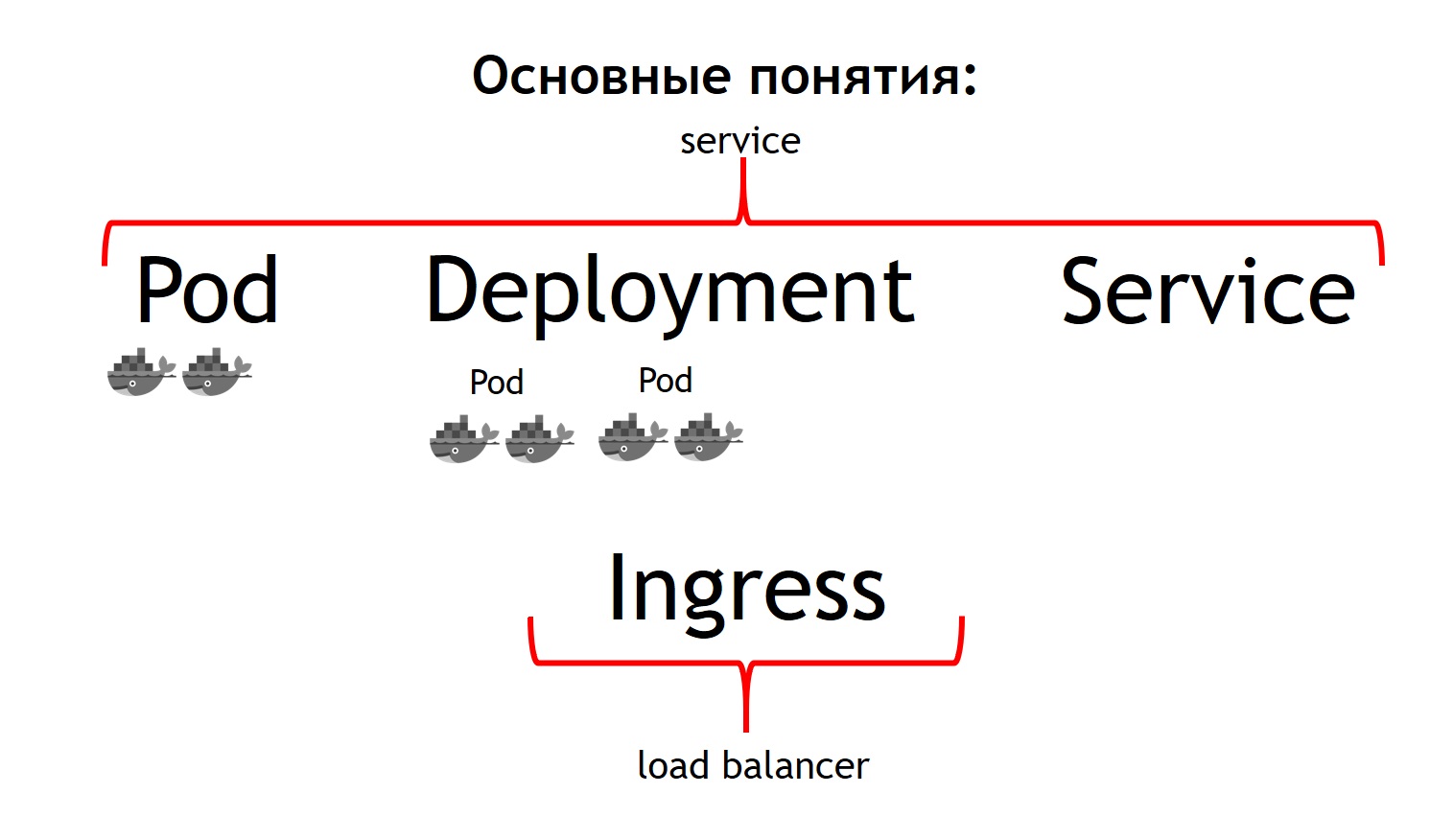
Das grundlegendste Konzept in Kubernetes ist zunächst das Konzept des Pods.
Ein Pod ist eine Gruppe von einem oder mehreren Containern, die immer zusammen laufen. Und sie scheinen immer streng auf derselben virtuellen Maschine zu arbeiten. Sie stehen einander über IP 127.0.0.1 an verschiedenen Ports zur Verfügung.
Angenommen, Sie haben eine PHP-Anwendung, die aus nginx und php-fpm besteht - eine klassische Schaltung. Höchstwahrscheinlich möchten Sie, dass sowohl Nginx- als auch PHP-Fpm-Container immer zusammen sind. Kubernetes beschreibt dies als einen gemeinsamen Pod. Genau das konnten wir mit Hilfe von Nomad nicht erreichen.
Das zweite Konzept ist die
Bereitstellung . Tatsache ist, dass die Kapsel selbst eine vergängliche Sache ist, sie beginnt und verschwindet. Egal, ob Sie zuerst alle Ihre vorherigen Container beenden und dann neue Versionen auf einmal starten oder sie schrittweise einführen möchten - genau für dieses Konzept ist die Bereitstellung verantwortlich. Es wird beschrieben, wie Sie Ihre Pods bereitstellen, wie viele und wie Sie sie aktualisieren.
Das dritte Konzept ist
Service . Ihr Dienst ist eigentlich Ihr System, das Datenverkehr empfängt und ihn dann an einen oder mehrere Pods weiterleitet, die Ihrem Dienst entsprechen. Das heißt, Sie können sagen, dass der gesamte eingehende Verkehr zu einem solchen Dienst mit einem solchen Namen an diese bestimmten Pods gesendet werden muss. Gleichzeitig erhalten Sie einen Verkehrsausgleich. Das heißt, Sie können zwei Pods Ihrer Anwendung ausführen, und der gesamte eingehende Datenverkehr wird gleichmäßig zwischen den Pods verteilt, die sich auf diesen Dienst beziehen.
Und das vierte Grundkonzept ist
Ingress . Dies ist ein Dienst, der in einem Kubernetes-Cluster ausgeführt wird. Es fungiert als externer Load Balancer, der alle Anforderungen übernimmt. Aufgrund der API kann Kubernetes Ingress bestimmen, wohin diese Anforderungen gesendet werden sollen. Und er macht es sehr flexibel. Sie können sagen, dass alle Anforderungen an diesen Host und diese URL an diesen Dienst gesendet werden. Und wir senden diese Anfragen an diesen Host und an eine andere URL an einen anderen Dienst.
Das Coolste aus der Sicht des Entwicklers der Anwendung ist, dass Sie alles selbst verwalten können. Nachdem Sie die Ingress-Konfiguration festgelegt haben, können Sie den gesamten Datenverkehr, der zu einer solchen API kommt, an separate registrierte Container senden, z. B. an Go. Dieser Datenverkehr, der zu derselben Domain, aber zu einer anderen URL gelangt, sollte an in PHP geschriebene Container gesendet werden, in denen viel Logik vorhanden ist, die jedoch nicht sehr schnell sind.
Wenn wir alle diese Konzepte mit Nomad vergleichen, können wir sagen, dass die ersten drei Konzepte alle zusammen Service sind. Und das letzte Konzept in Nomad selbst fehlt. Wir haben einen externen Balancer verwendet: Es kann Haproxy, Nginx, Nginx + und so weiter sein. Im Falle eines Würfels müssen Sie dieses zusätzliche Konzept nicht separat einführen. Wenn Sie sich jedoch Ingress im Inneren ansehen, handelt es sich entweder um Nginx, Haproxy oder Traefik, aber als ob es in Kubernetes eingebaut wäre.
Alle von mir beschriebenen Konzepte sind im Wesentlichen die Ressourcen, die im Kubernetes-Cluster vorhanden sind. Um sie im Cube zu beschreiben, wird das Yaml-Format verwendet, das lesbarer und vertrauter ist als die HCl-Dateien im Fall von Nomad. Aber strukturell beschreiben sie beispielsweise im Fall von Pod das Gleiche. Sie sagen - ich möchte solche und solche Pods hier und da mit solchen und solchen Bildern in dieser und jener Menge einsetzen.

Darüber hinaus haben wir festgestellt, dass wir nicht jede einzelne Ressource mit unseren eigenen Händen erstellen möchten: Bereitstellung, Services, Ingress und mehr. Stattdessen wollten wir jedes bereitgestellte System während der Bereitstellung in Form von Kubernetes beschreiben, damit wir nicht alle erforderlichen Ressourcenabhängigkeiten manuell in der richtigen Reihenfolge neu erstellen müssen. Helm wurde als das System gewählt, das uns dies ermöglichte.
Schlüsselkonzepte bei Helm
Helm ist
Paketmanager für Kubernetes. Es ist sehr ähnlich wie Paketmanager in Programmiersprachen arbeiten. Mit ihnen können Sie einen Dienst, der beispielsweise aus Deployment Nginx, Deployment PHP-Fpm, einer Konfiguration für Ingress, Configmaps (dies ist eine Entität, mit der Sie Env und andere Parameter für Ihr System festlegen können) in Form von sogenannten Diagrammen speichern. Gleichzeitig
läuft Helm
auf Kubernetes . Das heißt, dies ist kein System, das beiseite steht, sondern nur ein weiterer Dienst, der im Cube ausgeführt wird. Sie interagieren mit ihm über seine API über einen Konsolenbefehl. Bequem und charmant ist, dass Ihre Dienste auch dann nicht verschwinden, wenn das Ruder bricht oder Sie es aus dem Cluster entfernen, da das Ruder im Wesentlichen nur zum Starten des Systems dient. Kubernetes selbst ist für die Verfügbarkeit und den Status der Dienste verantwortlich.
Wir haben auch erkannt, dass die Standardisierung , die zuvor durch die Einführung von Jinja in unseren Konfigurationen unabhängig durchgeführt werden musste, eines der Hauptmerkmale des Ruders ist. Alle Konfigurationen, die Sie für Ihre Systeme erstellen, werden in helm in Form von Vorlagen gespeichert, die ein bisschen wie jinja ähneln, aber tatsächlich die Go-Sprachvorlage verwenden, in der helm geschrieben ist, wie Kubernetes.Helm fügt uns weitere zusätzliche Konzepte hinzu.Diagramm ist eine Beschreibung Ihres Dienstes. Andere Paketmanager würden es Paket, Bundle oder ähnliches nennen. Dies wird hier als Diagramm bezeichnet.Werte sind die Variablen, mit denen Sie Ihre Konfigurationen aus Vorlagen erstellen möchten.Lassen Sie los. Jedes Mal, wenn ein Dienst, der mithilfe von helm bereitgestellt wird, eine inkrementelle Version der Version erhält. Helm merkt sich, wie die Servicekonfiguration im vorherigen, im Jahr vor der letzten Version usw. war. Wenn Sie ein Rollback durchführen müssen, führen Sie einfach den Befehl helm callback aus und geben Sie die vorherige Version der Version an. Auch wenn zum Zeitpunkt des Rollbacks die entsprechende Konfiguration in Ihrem Repository nicht verfügbar ist, merkt sich helm immer noch, was es war, und setzt Ihr System auf den Zustand zurück, in dem es in der vorherigen Version war.Wenn wir helm verwenden, werden die üblichen Konfigurationen für Kubernetes auch zu Vorlagen, in denen es möglich ist, Variablen und Funktionen zu verwenden und bedingte Operatoren anzuwenden. Auf diese Weise können Sie die Konfiguration Ihres Dienstes abhängig von der Umgebung erfassen.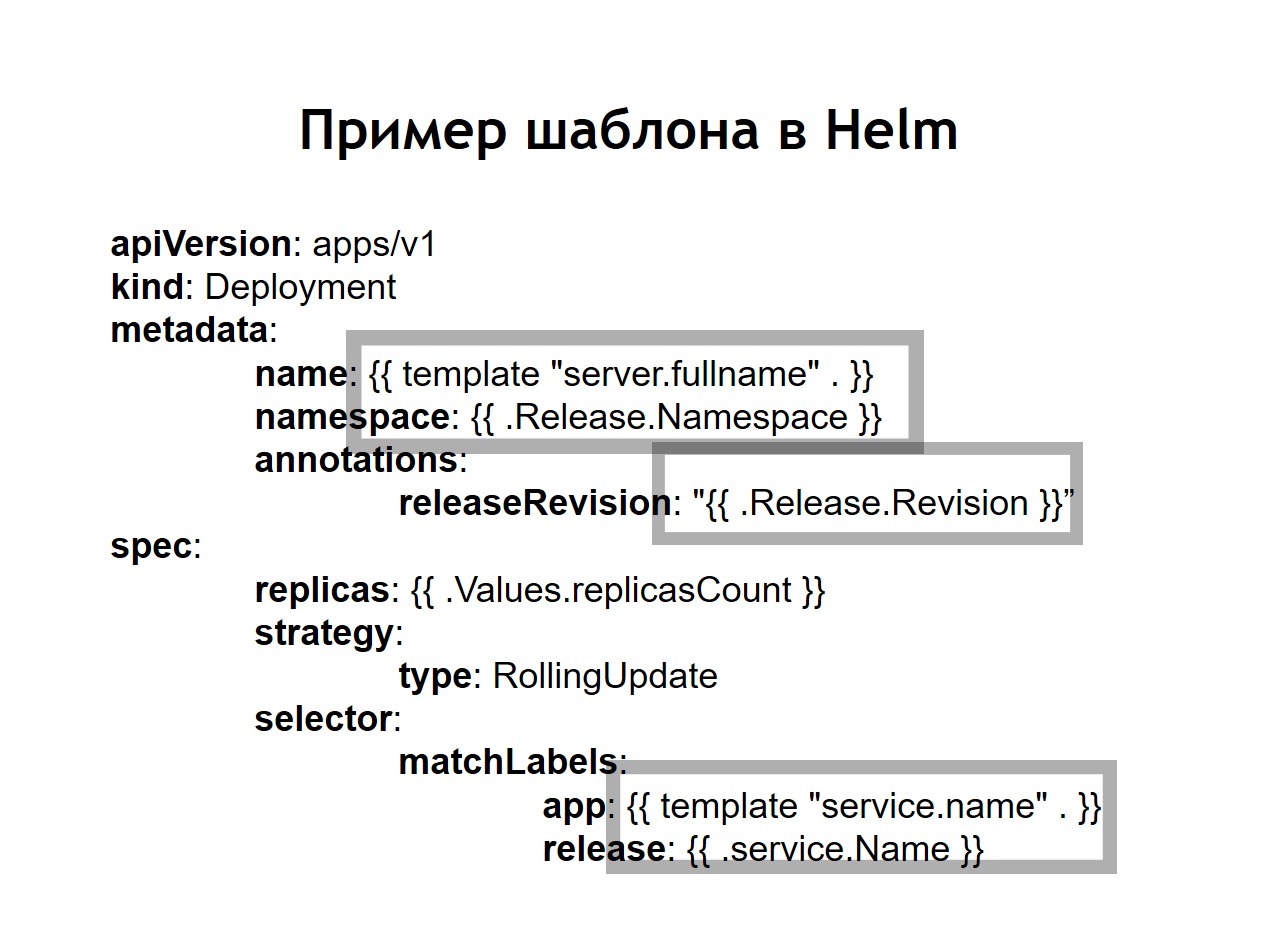 In der Praxis haben wir uns entschlossen, etwas anders zu machen als im Fall von Nomad. Wenn in Nomad im selben Repository sowohl Konfigurationen für die Bereitstellung als auch n-Variablen gespeichert wurden, die für die Bereitstellung unseres Dienstes erforderlich waren, haben wir uns hier entschieden, sie in zwei separate Repositorys aufzuteilen. Nur die für die Bereitstellung erforderlichen n-Variablen werden im Bereitstellungsrepository gespeichert, und Konfigurationen oder Diagramme werden im Steuerungsrepository gespeichert.
In der Praxis haben wir uns entschlossen, etwas anders zu machen als im Fall von Nomad. Wenn in Nomad im selben Repository sowohl Konfigurationen für die Bereitstellung als auch n-Variablen gespeichert wurden, die für die Bereitstellung unseres Dienstes erforderlich waren, haben wir uns hier entschieden, sie in zwei separate Repositorys aufzuteilen. Nur die für die Bereitstellung erforderlichen n-Variablen werden im Bereitstellungsrepository gespeichert, und Konfigurationen oder Diagramme werden im Steuerungsrepository gespeichert. Was hat es uns gegeben?Trotz der Tatsache, dass wir keine wirklich sensiblen Daten in den Konfigurationsdateien selbst speichern. Zum Beispiel Datenbankkennwörter. Sie werden in Kubernetes als Geheimnisse gespeichert, aber es gibt noch einige Dinge, die wir nicht jedem in einer Reihe Zugriff gewähren möchten. Daher ist der Zugriff auf das Bereitstellungsrepository eingeschränkter, und das Steuerrepository enthält lediglich eine Beschreibung des Dienstes. Aus diesem Grund ist es möglich, einem größeren Personenkreis sicher Zugang zu gewähren.Da wir dank dieser Trennung nicht nur über die Produktion, sondern auch über andere Umgebungen verfügen, können wir unsere Steuerkarten wiederverwenden, um Services nicht nur für die Produktion, sondern beispielsweise auch für die QS-Umgebung bereitzustellen. Selbst wenn Sie sie lokal mit Minikube bereitstellen, können Sie Kubernetes lokal ausführen.In jedem Repository haben wir für jeden Service eine Trennung in separate Verzeichnisse hinterlassen. Das heißt, in jedem Verzeichnis befinden sich Vorlagen, die sich auf das entsprechende Diagramm beziehen und die Ressourcen beschreiben, die zum Starten unseres Systems bereitgestellt werden müssen. Im Bereitstellungs-Repository haben wir nur enves hinterlassen. In diesem Fall haben wir kein Templating mit Jinja verwendet, da das Ruder selbst das Templating sofort bereitstellt - dies ist eine seiner Hauptfunktionen.Wir haben das Bereitstellungsskript deploy.sh verlassen, das den Start für die Bereitstellung mithilfe von helm vereinfacht und standardisiert. Daher sieht die Bereitstellungsschnittstelle für alle Benutzer der Bereitstellung genauso aus wie bei der Bereitstellung über Nomad. Dieselbe deploy.sh, der Name Ihres Dienstes und der Ort, an dem Sie ihn bereitstellen möchten. Dies führt dazu, dass das Ruder im Inneren startet. Er sammelt wiederum Konfigurationen aus Vorlagen, ersetzt die erforderlichen Wertedateien in ihnen, stellt sie dann bereit und legt sie in Kubernetes ab.
Was hat es uns gegeben?Trotz der Tatsache, dass wir keine wirklich sensiblen Daten in den Konfigurationsdateien selbst speichern. Zum Beispiel Datenbankkennwörter. Sie werden in Kubernetes als Geheimnisse gespeichert, aber es gibt noch einige Dinge, die wir nicht jedem in einer Reihe Zugriff gewähren möchten. Daher ist der Zugriff auf das Bereitstellungsrepository eingeschränkter, und das Steuerrepository enthält lediglich eine Beschreibung des Dienstes. Aus diesem Grund ist es möglich, einem größeren Personenkreis sicher Zugang zu gewähren.Da wir dank dieser Trennung nicht nur über die Produktion, sondern auch über andere Umgebungen verfügen, können wir unsere Steuerkarten wiederverwenden, um Services nicht nur für die Produktion, sondern beispielsweise auch für die QS-Umgebung bereitzustellen. Selbst wenn Sie sie lokal mit Minikube bereitstellen, können Sie Kubernetes lokal ausführen.In jedem Repository haben wir für jeden Service eine Trennung in separate Verzeichnisse hinterlassen. Das heißt, in jedem Verzeichnis befinden sich Vorlagen, die sich auf das entsprechende Diagramm beziehen und die Ressourcen beschreiben, die zum Starten unseres Systems bereitgestellt werden müssen. Im Bereitstellungs-Repository haben wir nur enves hinterlassen. In diesem Fall haben wir kein Templating mit Jinja verwendet, da das Ruder selbst das Templating sofort bereitstellt - dies ist eine seiner Hauptfunktionen.Wir haben das Bereitstellungsskript deploy.sh verlassen, das den Start für die Bereitstellung mithilfe von helm vereinfacht und standardisiert. Daher sieht die Bereitstellungsschnittstelle für alle Benutzer der Bereitstellung genauso aus wie bei der Bereitstellung über Nomad. Dieselbe deploy.sh, der Name Ihres Dienstes und der Ort, an dem Sie ihn bereitstellen möchten. Dies führt dazu, dass das Ruder im Inneren startet. Er sammelt wiederum Konfigurationen aus Vorlagen, ersetzt die erforderlichen Wertedateien in ihnen, stellt sie dann bereit und legt sie in Kubernetes ab.Schlussfolgerungen
Der Kubernetes-Service sieht komplexer aus als Nomad.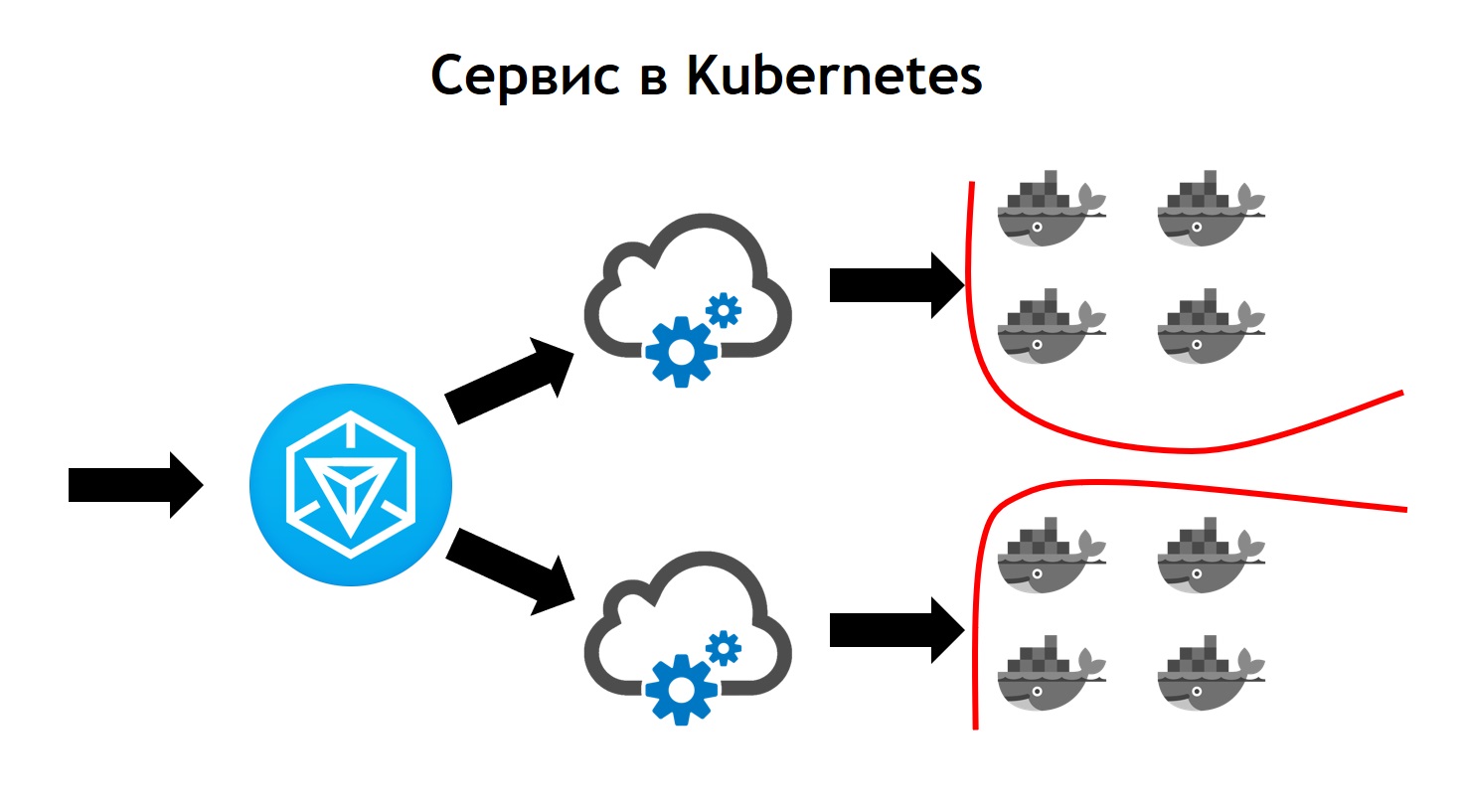 Hier kommt ausgehender Datenverkehr zu Ingress. Dies ist nur der Front-Controller, der alle Anforderungen empfängt und sie anschließend an die den Anforderungsdaten entsprechenden Dienste sendet. Sie werden anhand von Konfigurationen definiert, die Teil der Beschreibung Ihrer Anwendung in helm sind und die Entwickler unabhängig voneinander festlegen. Der Dienst sendet Anforderungen an seine Pods, dh an bestimmte Container, und gleicht den eingehenden Datenverkehr zwischen allen Containern aus, die zu diesem Dienst gehören. Vergessen Sie natürlich nicht, dass wir auf Netzwerkebene nicht von der Sicherheit abweichen sollten. Daher betreibt der Kubernetes-Cluster eine Segmentierung, die auf Tagging basiert. Alle Dienste verfügen über bestimmte Tags, an die die Zugriffsrechte von Diensten auf bestimmte externe / interne Ressourcen innerhalb oder außerhalb des Clusters angehängt sind.Während des Übergangs haben wir gesehen, dass Kubernetes alle Funktionen von Nomad bietet, die wir zuvor verwendet haben, und auch viele neue Funktionen hinzufügt. Es kann durch Plugins und sogar durch benutzerdefinierte Ressourcentypen erweitert werden. Das heißt, Sie haben nicht nur die Möglichkeit, etwas zu verwenden, das sofort in Kubernetes eingeht, sondern auch Ihre eigene Ressource und Ihren eigenen Dienst zu erstellen, die Ihre Ressource lesen. Dies bietet zusätzliche Optionen zum Erweitern Ihres Systems, ohne dass Kubernetes neu installiert werden muss und ohne dass Änderungen erforderlich sind.Ein Beispiel hierfür ist Prometheus, das in unserem Kubernetes-Cluster ausgeführt wird. Damit er Metriken von einem bestimmten Dienst erfassen kann, müssen wir der Dienstbeschreibung einen zusätzlichen Ressourcentyp hinzufügen, den sogenannten Dienstmonitor. Prometheus beginnt aufgrund der Tatsache, dass es lesen kann, automatisch mit dem Sammeln von Metriken aus dem neuen System, wenn es in Kubernetes, einem benutzerdefinierten Ressourcentyp, gestartet wird. Es ist sehr praktisch.Der erste Einsatz bei Kubernetes erfolgte im März 2018. Und in dieser Zeit hatten wir nie Probleme mit ihm. Es funktioniert stabil genug ohne signifikante Fehler. Darüber hinaus können wir es weiter ausbauen. Heute haben wir genug von den Möglichkeiten, die es bietet, und wir mögen das Entwicklungstempo von Kubernetes sehr. Derzeit befinden sich mehr als 3.000 Container in Kubernetes. Der Cluster benötigt mehrere Knoten. Gleichzeitig ist es gewartet, stabil und sehr kontrolliert.
Hier kommt ausgehender Datenverkehr zu Ingress. Dies ist nur der Front-Controller, der alle Anforderungen empfängt und sie anschließend an die den Anforderungsdaten entsprechenden Dienste sendet. Sie werden anhand von Konfigurationen definiert, die Teil der Beschreibung Ihrer Anwendung in helm sind und die Entwickler unabhängig voneinander festlegen. Der Dienst sendet Anforderungen an seine Pods, dh an bestimmte Container, und gleicht den eingehenden Datenverkehr zwischen allen Containern aus, die zu diesem Dienst gehören. Vergessen Sie natürlich nicht, dass wir auf Netzwerkebene nicht von der Sicherheit abweichen sollten. Daher betreibt der Kubernetes-Cluster eine Segmentierung, die auf Tagging basiert. Alle Dienste verfügen über bestimmte Tags, an die die Zugriffsrechte von Diensten auf bestimmte externe / interne Ressourcen innerhalb oder außerhalb des Clusters angehängt sind.Während des Übergangs haben wir gesehen, dass Kubernetes alle Funktionen von Nomad bietet, die wir zuvor verwendet haben, und auch viele neue Funktionen hinzufügt. Es kann durch Plugins und sogar durch benutzerdefinierte Ressourcentypen erweitert werden. Das heißt, Sie haben nicht nur die Möglichkeit, etwas zu verwenden, das sofort in Kubernetes eingeht, sondern auch Ihre eigene Ressource und Ihren eigenen Dienst zu erstellen, die Ihre Ressource lesen. Dies bietet zusätzliche Optionen zum Erweitern Ihres Systems, ohne dass Kubernetes neu installiert werden muss und ohne dass Änderungen erforderlich sind.Ein Beispiel hierfür ist Prometheus, das in unserem Kubernetes-Cluster ausgeführt wird. Damit er Metriken von einem bestimmten Dienst erfassen kann, müssen wir der Dienstbeschreibung einen zusätzlichen Ressourcentyp hinzufügen, den sogenannten Dienstmonitor. Prometheus beginnt aufgrund der Tatsache, dass es lesen kann, automatisch mit dem Sammeln von Metriken aus dem neuen System, wenn es in Kubernetes, einem benutzerdefinierten Ressourcentyp, gestartet wird. Es ist sehr praktisch.Der erste Einsatz bei Kubernetes erfolgte im März 2018. Und in dieser Zeit hatten wir nie Probleme mit ihm. Es funktioniert stabil genug ohne signifikante Fehler. Darüber hinaus können wir es weiter ausbauen. Heute haben wir genug von den Möglichkeiten, die es bietet, und wir mögen das Entwicklungstempo von Kubernetes sehr. Derzeit befinden sich mehr als 3.000 Container in Kubernetes. Der Cluster benötigt mehrere Knoten. Gleichzeitig ist es gewartet, stabil und sehr kontrolliert.