Wir beginnen eine Reihe von Artikeln, die verschiedene Situationen beschreiben, in denen die Verwendung von Intel-Tools für Entwickler die Geschwindigkeit der Software erheblich erhöht und ihre Qualität verbessert hat.
Unsere erste Geschichte ereignete sich an der Universität Nowosibirsk, wo Forscher ein Software-Tool zur numerischen Simulation magnetohydrodynamischer Probleme während der Wasserstoffionisation entwickelten. Diese Arbeit wurde im Rahmen des globalen Projekts zur Modellierung astrophysikalischer Objekte
AstroPhi durchgeführt .
Intel Xeon Phi- Prozessoren wurden als Hardwareplattform verwendet. Durch die Verwendung von
Intel Advisor und
Intel Trace Analyzer und Collector wurde die Rechenleistung um das Dreifache erhöht und die Geschwindigkeit zur Lösung eines Problems von einer Woche auf zwei Tage verringert.
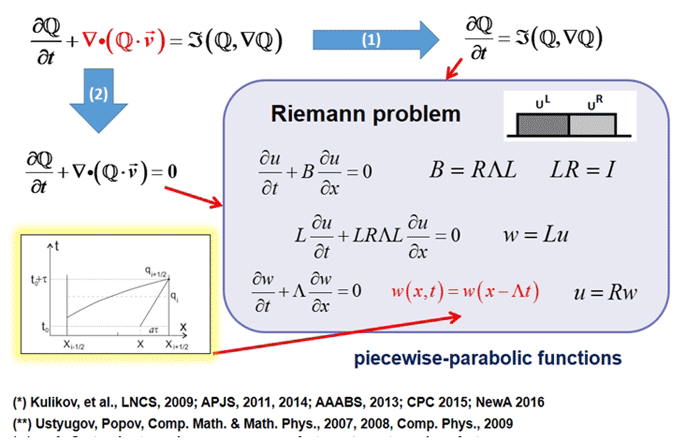
Aufgabenbeschreibung
Die mathematische Modellierung spielt in der modernen Astrophysik wie in jeder Wissenschaft eine wichtige Rolle. Dies ist ein universelles Werkzeug zur Untersuchung nichtlinearer Evolutionsprozesse im Universum. Die hochauflösende Modellierung komplexer astrophysikalischer Prozesse erfordert enorme Rechenressourcen. AstroPhi-Projekt NSU entwickelt astrophysikalischen Softwarecode für Supercomputer auf Basis von Intel Xeon Phi-Prozessoren. Die Schüler lernen, Simulationsprogramme für eine extrem parallelisierte Laufzeit zu schreiben, und erwerben wichtige Kenntnisse, die sie dann für die Arbeit mit anderen Supercomputern benötigen.
Die im Projekt verwendete numerische Modellierungsmethode hatte eine Reihe wichtiger Vorteile:
- Mangel an künstlicher Viskosität,
- Galiläische Invarianz,
- Garantie der Nichtreduzierung der Entropie
- einfache Parallelisierung
- möglicherweise unendliche Erweiterbarkeit.
Die ersten drei Faktoren sind der Schlüssel zur realistischen Modellierung signifikanter physikalischer Effekte bei astrophysikalischen Problemen.
Das Forschungsteam hat ein neues Modellierungswerkzeug für multiparallele Architekturen basierend auf Intel Xeon Phi erstellt. Ihre Hauptaufgabe bestand darin, Engpässe beim Datenaustausch zwischen Knoten zu vermeiden und die Code-Verfeinerung so weit wie möglich zu vereinfachen. Die Parallelisierungslösung verwendet MPI. Für die Vektorisierung bieten die Anweisungen der Intel Advanced Vector Extensions 512 (Intel AVX-512) Unterstützung für 512-Bit-SIMD und ermöglichen dem Programm das Packen von 8 Gleitkommazahlen mit doppelter Genauigkeit oder 16 Zahlen mit einfacher Genauigkeit (32-Bit). ) zu Vektoren mit einer Länge von 512 Bit. Somit werden pro Befehl doppelt so viele Datenelemente verarbeitet wie bei Verwendung von AVX / AVX2 und viermal so viel wie bei Verwendung von SSE.
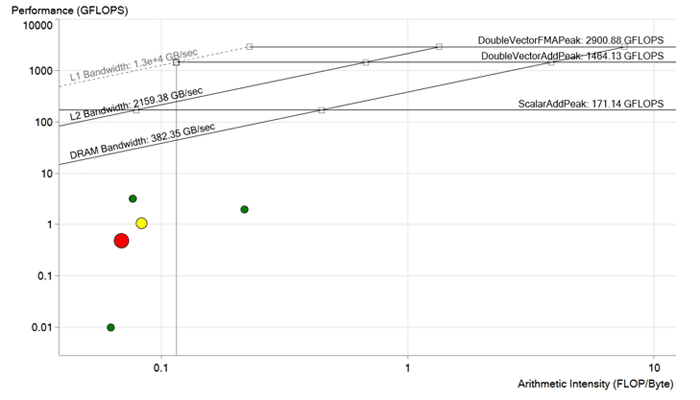 Bild vor der Optimierung. Jeder Punkt ist ein Verarbeitungszyklus. Je größer und roter der Punkt ist, desto länger dauert der Zyklus und desto deutlicher wird der Effekt seiner Optimierung. Der rote Punkt liegt deutlich unter der DRAM-Bandbreitengrenze und wird mit einer Leistung von weniger als 1 GFLOP berechnet. Es hat ein sehr großes Verbesserungspotential.
Bild vor der Optimierung. Jeder Punkt ist ein Verarbeitungszyklus. Je größer und roter der Punkt ist, desto länger dauert der Zyklus und desto deutlicher wird der Effekt seiner Optimierung. Der rote Punkt liegt deutlich unter der DRAM-Bandbreitengrenze und wird mit einer Leistung von weniger als 1 GFLOP berechnet. Es hat ein sehr großes Verbesserungspotential.Codeoptimierung
Vor der Optimierung hatte der Code bestimmte Probleme mit Abhängigkeiten und Vektorgrößen. Das Optimierungsziel bestand darin, die Abhängigkeiten von Vektoren zu beseitigen und die Operationen zum Laden von Daten in den Speicher unter Verwendung der optimalen Größe von Vektoren und Arrays für Xeon Phi zu verbessern. Zur Optimierung verwendeten wir
Intel Advisor und
Intel Trace Analyzer und Collector , zwei Tools von
Intel Parallel Studio XE .
Intel Advisor ist, wie der Name schon sagt, ein Berater - ein Software-Tool, das den Grad der Optimierung bewertet - Vektorisierung (mithilfe von AVX- oder SIMD-Anweisungen) und Parallelisierung, um maximale Leistung zu erzielen. Mit diesem Tool konnte das Team eine Übersichtsanalyse der Zyklen durchführen, wobei diejenigen mit geringer Produktivität hervorgehoben wurden, das Verbesserungspotenzial aufgezeigt und festgestellt wurde, was verbessert werden könnte und ob das Spiel die Kerze wert war. Intel Advisor sortierte die Zyklen nach potenziellen, fügte der Quelle Nachrichten hinzu, um die Lesbarkeit des Compiler-Berichts zu verbessern. Er lieferte auch wichtige Informationen wie Zykluszeiten, Datenabhängigkeiten und Speicherzugriffsmuster für eine sichere und effiziente Vektorisierung.
Intel Trace Analyzer und Collector ist eine weitere Möglichkeit, Ihren Code zu optimieren. Es umfasst die Profilerstellung von MPI-Kommunikations- und Analysefunktionen zur Verbesserung der schwachen und starken Skalierung. Dieses grafische Tool half dem Team, das MPI-Verhalten der Anwendung zu verstehen, Engpässe schnell zu finden und vor allem die Leistung der Intel-Architektur zu steigern.
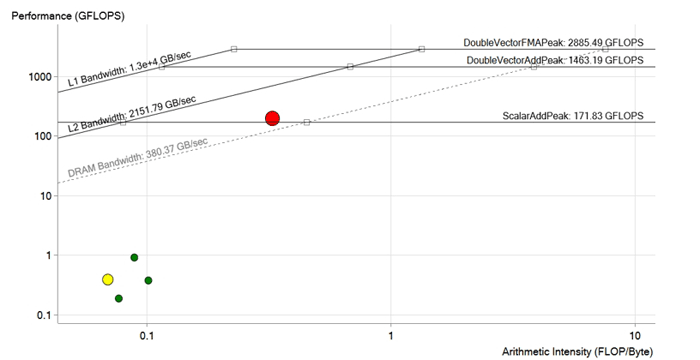 Bild nach der Optimierung. Während der Optimierung des roten Zyklus wurden Vektorisierungsabhängigkeiten entfernt, Ladevorgänge in den Speicher optimiert, die Größen von Vektoren und Arrays für Intel Xeon Phi- und AVX-512-Anweisungen angepasst. Die Leistung wurde auf 190 GFLOPS erhöht, d. H. Ungefähr 200-mal. Jetzt liegt es über der DRAM-Grenze und höchstwahrscheinlich durch die Eigenschaften des L2-Cache begrenzt
Bild nach der Optimierung. Während der Optimierung des roten Zyklus wurden Vektorisierungsabhängigkeiten entfernt, Ladevorgänge in den Speicher optimiert, die Größen von Vektoren und Arrays für Intel Xeon Phi- und AVX-512-Anweisungen angepasst. Die Leistung wurde auf 190 GFLOPS erhöht, d. H. Ungefähr 200-mal. Jetzt liegt es über der DRAM-Grenze und höchstwahrscheinlich durch die Eigenschaften des L2-Cache begrenztErgebnis
Nach all den Verbesserungen und Optimierungen erreichte das Team eine Leistung von 190 GFLOPS mit einer Rechenintensität von 0,3 FLOP / b, einer Auslastung von 100% und einer Speicherbandbreite von 573 GB / s.
 Optimiertes Code-Snippet
Optimiertes Code-Snippet