Der betreffende Artikel.
Einführung
Moderne Erkennungssysteme beschränken sich auf die Klassifizierung in eine relativ kleine Anzahl semantisch nicht verwandter Klassen. Das Anziehen von Textinformationen, auch ohne Bezug zu den Bildern, ermöglicht es, das Modell zu bereichern und bis zu einem gewissen Grad die folgenden Probleme zu lösen:
- Wenn das Erkennungsmodell einen Fehler macht, liegt dieser Fehler häufig semantisch nicht in der Nähe der richtigen Klasse.
- Es gibt keine Möglichkeit, ein Objekt vorherzusagen, das zu einer neuen Klasse gehört, die nicht im Trainingsdatensatz dargestellt wurde.
Der vorgeschlagene Ansatz schlägt vor, Bilder in einem reichhaltigen semantischen Raum anzuzeigen, in dem Bezeichnungen ähnlicher Klassen näher beieinander liegen als Bezeichnungen weniger ähnlicher Klassen. Infolgedessen ist das Modell weniger semantisch von der wahren Klasse von Vorhersagen entfernt. Darüber hinaus kann das Modell unter Berücksichtigung sowohl der visuellen als auch der semantischen Nähe Bilder korrekt klassifizieren, die sich auf eine Klasse beziehen, die nicht im Trainingsdatensatz dargestellt wurde.
Algorithmus Architektur
- Wir trainieren das Sprachmodell vorab, das gute semantisch bedeutsame Einbettungen liefert. Die Raumdimension ist n. Als nächstes wird n gleich 500 oder 1000 genommen.
- Wir trainieren das visuelle Modell vor, das Objekte gut in 1000 Klassen klassifiziert.
- Wir schneiden die letzte Softmax-Schicht aus dem vorab trainierten visuellen Modell ab und fügen eine vollständig verbundene Schicht von 4096 zu n Neuronen hinzu. Wir trainieren das resultierende Modell für jedes Bild, um die Einbettung entsprechend der Bildbezeichnung vorherzusagen.
Lassen Sie uns mit Hilfe von Mappings erklären. Sei LM ein Sprachmodell, VM ein visuelles Modell mit abgeschnittenem Softmax und einer vollständig verbundenen Schicht, I-Bild, L-Label des Bildes, LM (L) -Label, das in den semantischen Raum eingebettet ist. Dann trainieren wir im dritten Schritt die VM so, dass:
Architektur:
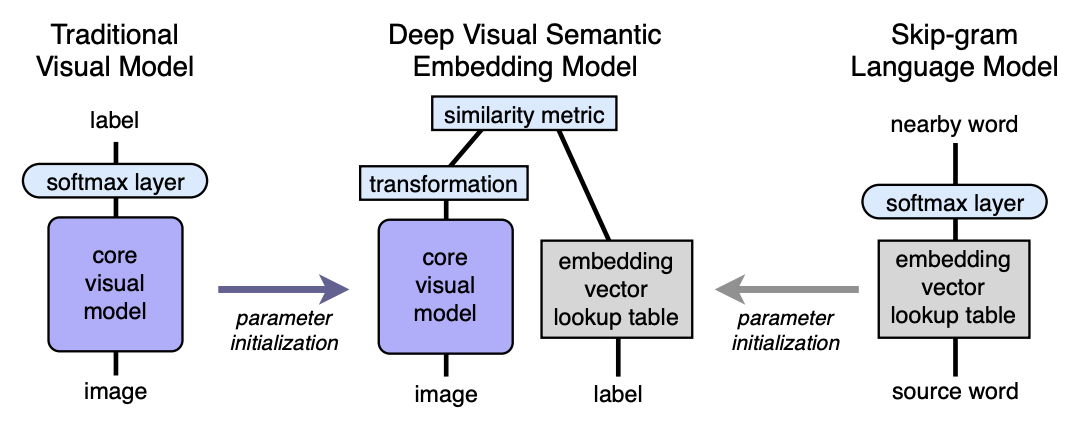
Sprachmodell
Um das Sprachmodell zu lernen, wurde das Skip-Gramm-Modell verwendet, ein Korpus von 5,4 Milliarden Wörtern aus wikipedia.org. Das Modell verwendete eine hierarchische Softmax-Schicht, um verwandte Konzepte vorherzusagen, ein Fenster - 20 Wörter, die Anzahl der Durchgänge durch den Körper - 1. Es wurde experimentell festgestellt, dass die Einbettungsgröße besser für 500-1000 ist.
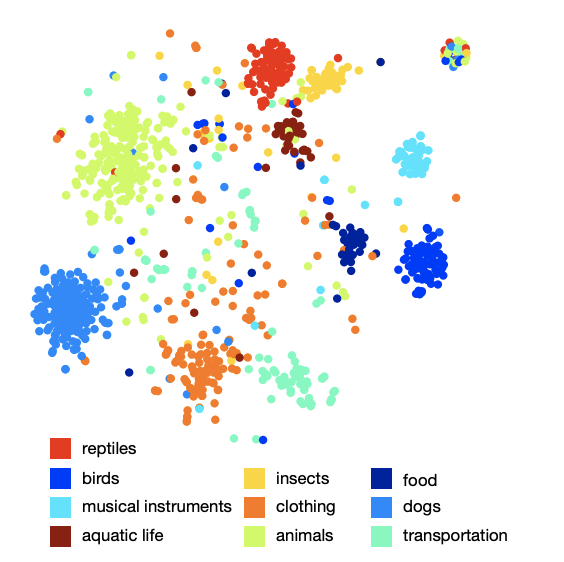
Das Bild der Anordnung von Klassen im Raum zeigt, dass das Modell eine qualitative und reichhaltige semantische Struktur gelernt hat. Beispielsweise sind für eine bestimmte Haiart im resultierenden semantischen Raum 9 nächste Nachbarn die anderen 9 Haiarten.
Visuelles Modell
Die Architektur, die den ILSVRC-Wettbewerb 2012 gewann, wurde als visuelles Modell verwendet. Softmax wurde darin entfernt und eine vollständig verbundene Schicht wurde hinzugefügt, um die gewünschte Einbettungsgröße am Ausgang zu erhalten.
Verlustfunktion
Es stellte sich heraus, dass die Wahl der Verlustfunktion wichtig ist. Eine Kombination aus Kosinusähnlichkeit und Scharnierrangverlust wurde verwendet. Die Verlustfunktion ermutigte ein größeres Skalarprodukt zwischen dem Ergebnisvektor des visuellen Netzwerks und der entsprechenden Etiketteneinbettung und bestrafte ein großes Skalarprodukt zwischen dem Ergebnis des visuellen Netzwerks und den Einbettungen zufälliger möglicher Bildetiketten. Die Anzahl beliebiger zufälliger Markierungen wurde nicht festgelegt, sondern durch die Bedingung begrenzt, dass die Summe der Skalarprodukte mit falschen Markierungen mehr als ein Skalarprodukt mit einer gültigen Markierung abzüglich eines festen Randes (Konstante gleich 0,1) wurde. Natürlich wurden alle Vektoren vornormalisiert.
Trainingsprozess
Zu Beginn wurde nur die zuletzt hinzugefügte vollständig verbundene Schicht trainiert, der Rest des Netzwerks hat das Gewicht nicht aktualisiert. In diesem Fall wurde die SGD-Optimierungsmethode verwendet. Anschließend wurde das gesamte visuelle Netzwerk mit dem Adagrad-Optimierer aufgetaut und trainiert, sodass die Gradienten während der Rückausbreitung auf verschiedenen Schichten des Netzwerks korrekt skaliert werden.
Vorhersage
Während der Vorhersage erhalten wir aus dem Bild unter Verwendung des visuellen Netzwerks einen Vektor in unserem semantischen Raum. Als nächstes finden wir die nächsten Nachbarn, dh einige mögliche Beschriftungen, und zeigen sie auf besondere Weise wieder in ImageNet-Synsets zur Bewertung an. Das Verfahren für die letzte Anzeige ist nicht so einfach, da die Beschriftungen in ImageNet eine Reihe von Synonymen sind, nicht nur eine Beschriftung. Wenn der Leser an Einzelheiten interessiert ist, empfehle ich den Originalartikel (Anhang 2).
Ergebnisse
Das Ergebnis des DEVISE-Modells wurde mit zwei Modellen verglichen:
- Softmax-Basismodell - ein hochmodernes Visionsmodell (SOTA - zum Zeitpunkt der Veröffentlichung)
- Das zufällige Einbettungsmodell ist eine Version des beschriebenen DEVISE-Modells, bei dem Einbettungen nicht vom Sprachmodell gelernt, sondern willkürlich initialisiert werden.
Zur Beurteilung der Qualität wurden "flache" hit @ k-Metriken und hierarchische Precision @ k-Metriken verwendet. Die Metrik "flat" hit @ k ist der Prozentsatz der Testbilder, für die die richtige Bezeichnung unter den ersten k vorhergesagten Optionen vorhanden ist. Die hierarchische Genauigkeitsmetrik @ k wurde verwendet, um die Qualität der semantischen Korrespondenz zu bewerten. Diese Metrik basierte auf der Beschriftungshierarchie in ImageNet. Für jedes wahre Label und festes k die Menge
semantisch korrekte Bezeichnungen - Grundwahrheitsliste. Das Erhalten der Vorhersage (nächste Nachbarn) war der Prozentsatz der Schnittmenge mit der Grundwahrheitsliste.

Die Autoren erwarteten, dass das Softmax-Modell die besten Ergebnisse für flache Metriken zeigen sollte, da es den Kreuzentropieverlust minimiert, was für „flache“ hit @ k-Metriken sehr gut geeignet ist. Die Autoren waren überrascht, wie nahe das DEVISE-Modell am Softmax-Modell liegt, bei großem k die Parität erreicht und bei k = 20 sogar überholt.
In der hierarchischen Metrik zeigt sich das DEVISE-Modell in seiner ganzen Pracht und überholt den Softmax-Baseball um 3% für k = 5 und um 7% für k = 20.
Zero-Shot-Lernen
Ein besonderer Vorteil des DEVISE-Modells ist die Fähigkeit, Bilder, deren Beschriftungen das Netzwerk während des Trainings noch nie gesehen hat, angemessen vorherzusagen. Während des Trainings sah das Netzwerk beispielsweise Bilder mit der Aufschrift Tigerhai, Bullenhai und Blauhai und traf nie die Hai-Marke. Da das Sprachmodell eine Darstellung für Haie im semantischen Raum hat und nahe an der Einbettung verschiedener Haiarten liegt, ist es sehr wahrscheinlich, dass das Modell eine angemessene Vorhersage liefert. Dies nennt man die Fähigkeit zur Verallgemeinerung - Verallgemeinerung.
Lassen Sie uns einige Beispiele für Zero-Shot-Vorhersagen demonstrieren:

Beachten Sie, dass das DEVISE-Modell selbst in seinen fehlerhaften Annahmen näher an der richtigen Antwort liegt als die fehlerhaften Annahmen des Softmax-Modells.
Das vorgestellte Modell verliert also bei flachen Metriken ein wenig an Softmax gegenüber der Basislinie, gewinnt jedoch bei hierarchischer Genauigkeit @ k-Metrik erheblich. Das Modell kann verallgemeinern und angemessene Vorhersagen für Bilder erstellen, deren Beschriftungen das Netzwerk nicht erfüllt hat (Zero-Shot-Lernen).
Der beschriebene Ansatz kann leicht implementiert werden, da er auf zwei vorab trainierten Modellen basiert - Sprache und Bild.