Der Markt für verteiltes Computing und Big Data wächst laut
Statistik um 18 bis 19% pro Jahr. Die Frage der Auswahl von Software für diese Zwecke bleibt also relevant. In diesem Beitrag beginnen wir damit, warum verteiltes Computing benötigt wird, beschäftigen uns mit der Auswahl der Software, sprechen über die Verwendung von Hadoop mit Cloudera und schließlich über die Auswahl der Hardware und deren Auswirkungen auf die Leistung auf unterschiedliche Weise.
Warum brauchen wir verteiltes Computing in einem regulären Geschäft? Alles ist gleichzeitig einfach und kompliziert. Einfach - weil wir in den meisten Fällen relativ einfache Berechnungen pro Informationseinheit durchführen. Es ist schwierig, weil es viele solcher Informationen gibt. Sehr viel. Daher müssen Sie
Terabyte an Daten in 1000 Threads verarbeiten . Daher sind die Verwendungsszenarien ziemlich universell: Berechnungen können überall dort angewendet werden, wo es erforderlich ist, eine große Anzahl von Metriken für ein noch größeres Datenfeld zu berücksichtigen.
Ein aktuelles Beispiel: Die Pizzakette Dodo Pizza hat auf der Grundlage einer Analyse der Kundenbestellbasis
festgestellt , dass Benutzer bei der Auswahl einer Pizza mit willkürlicher Füllung normalerweise nur mit sechs Grundsätzen von Zutaten plus ein paar zufälligen Zutaten arbeiten. Dementsprechend hat die Pizzeria die Einkäufe angepasst. Darüber hinaus konnte sie den Anwendern zusätzliche Produkte, die in der Bestellphase angeboten wurden, besser empfehlen, was zur Gewinnsteigerung beitrug.
Ein weiteres Beispiel: Durch die
Analyse der Rohstoffpositionen konnte das H & M-Geschäft die Reichweite in einzelnen Geschäften um 40% reduzieren und gleichzeitig das Umsatzniveau beibehalten. Dies wurde erreicht, indem schlecht verkaufte Positionen beseitigt wurden, und die Saisonalität wurde bei den Berechnungen berücksichtigt.
Werkzeugauswahl
Der Industriestandard für diese Art von Computer ist Hadoop. Warum? Weil Hadoop ein ausgezeichnetes, gut dokumentiertes Framework ist (derselbe Habr gibt viele detaillierte Artikel zu diesem Thema heraus), das von einer ganzen Reihe von Dienstprogrammen und Bibliotheken begleitet wird. Sie können große Mengen strukturierter und unstrukturierter Daten eingeben, die vom System selbst auf die Rechenleistung verteilt werden. Darüber hinaus können dieselben Kapazitäten jederzeit erhöht oder deaktiviert werden - dieselbe horizontale Skalierbarkeit in Aktion.
2017 kam das einflussreiche Beratungsunternehmen Gartner zu dem
Schluss, dass Hadoop bald veraltet sein würde. Der Grund ist ziemlich banal: Analysten glauben, dass Unternehmen massiv in die Cloud migrieren werden, weil sie dort für die Nutzung der Rechenleistung bezahlen können. Der zweite wichtige Faktor, der angeblich Hadoop "begraben" kann, ist die Arbeitsgeschwindigkeit. Weil Optionen wie Apache Spark oder Google Cloud DataFlow schneller sind als das MapReduce, das Hadoop zugrunde liegt.
Hadoop basiert auf mehreren Säulen, von denen die MapReduce-Technologien (ein Datenverteilungssystem für die Datenverarbeitung zwischen Servern) und das HDFS-Dateisystem die bemerkenswertesten sind. Letzteres wurde speziell zum Speichern von Informationen entwickelt, die zwischen Knoten in einem Cluster verteilt sind: Jeder Block mit fester Größe kann auf mehreren Knoten platziert werden, und dank der Replikation ist das System immun gegen einzelne Knotenausfälle. Anstelle einer Dateitabelle wird ein spezieller Server namens NameNode verwendet.
Die folgende Abbildung zeigt den MapReduce-Workflow. In der ersten Stufe werden die Daten nach einem bestimmten Merkmal aufgeteilt, in der zweiten - sie werden nach Rechenleistung verteilt, in der dritten - wird die Berechnung durchgeführt.
MapReduce wurde ursprünglich von Google für die Anforderungen seiner Suche erstellt. Dann ging MapReduce in den freien Code und Apache nahm das Projekt auf. Nun, Google hat schrittweise auf andere Lösungen migriert. Eine interessante Nuance: Derzeit hat Google ein Projekt namens Google Cloud Dataflow, das als nächster Schritt nach Hadoop als schneller Ersatz positioniert ist.
Ein genauerer Blick zeigt, dass Google Cloud Dataflow auf einer Vielzahl von Apache Beam basiert, während Apache Beam ein gut dokumentiertes Apache Spark-Framework enthält, mit dem wir über nahezu die gleiche Geschwindigkeit der Entscheidungsausführung sprechen können. Nun, Apache Spark funktioniert gut im HDFS-Dateisystem, sodass Sie es auf Hadoop-Servern bereitstellen können.
Wir fügen hier das Volumen an Dokumentationen und schlüsselfertigen Lösungen für Hadoop und Spark gegen Google Cloud Dataflow hinzu, und die Wahl des Tools wird offensichtlich. Darüber hinaus können Ingenieure selbst entscheiden, welcher Code - unter Hadoop oder Spark - für sie ausgeführt werden soll, wobei sie sich auf die Aufgabe, Erfahrung und Qualifikation konzentrieren.
Cloud oder lokaler Server
Der Trend zu einem universellen Übergang zur Cloud hat sogar einen so interessanten Begriff wie Hadoop-as-a-Service hervorgebracht. In diesem Szenario ist die Verwaltung der verbundenen Server sehr wichtig geworden. Leider ist reines Hadoop trotz seiner Beliebtheit ein ziemlich schwierig zu konfigurierendes Werkzeug, da viele Dinge mit Ihren Händen erledigt werden müssen. Konfigurieren Sie beispielsweise die Server einzeln, überwachen Sie ihre Leistung und konfigurieren Sie viele Parameter sorgfältig. Im Allgemeinen ist die Arbeit für einen Amateur eine großartige Chance, etwas zu vermasseln oder etwas zu verpassen.
Daher erfreuten sich verschiedene Distributionen, die zunächst mit praktischen Bereitstellungs- und Verwaltungstools ausgestattet waren, großer Beliebtheit. Eine der beliebtesten Distributionen, die Spark unterstützen und die Dinge einfacher machen, ist Cloudera. Es gibt sowohl eine kostenpflichtige als auch eine kostenlose Version - und in letzterer sind alle grundlegenden Funktionen verfügbar, ohne die Anzahl der Knoten zu begrenzen.

Während des Setups stellt Cloudera Manager über SSH eine Verbindung zu Ihren Servern her. Ein interessanter Punkt: Während der Installation ist es besser anzugeben, dass dies von den sogenannten
Paketen durchgeführt werden soll : spezielle Pakete, von denen jedes alle erforderlichen Komponenten enthält, die für die Zusammenarbeit konfiguriert sind. Tatsächlich ist dies eine so verbesserte Version des Paketmanagers.
Nach der Installation erhalten wir die Cluster-Verwaltungskonsole, in der Sie die Telemetrie nach Cluster und die installierten Dienste anzeigen sowie Ressourcen hinzufügen / entfernen und die Cluster-Konfiguration bearbeiten können.
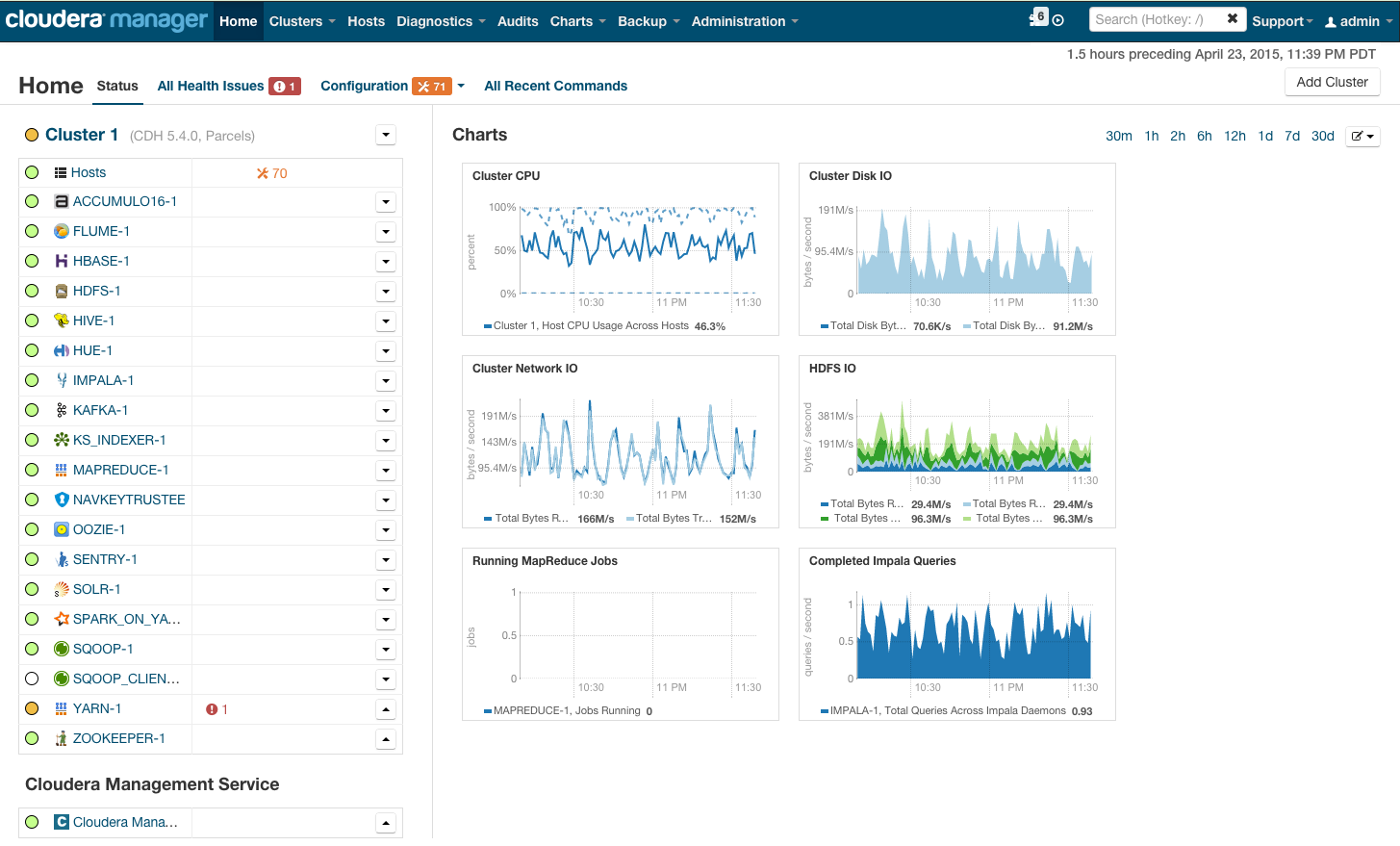
Als Ergebnis sehen Sie die Kabine der Rakete, die Sie in die glänzende Zukunft von BigData führt. Aber bevor Sie sagen "Lass uns gehen", gehen wir unter die Haube.
Hardwareanforderungen
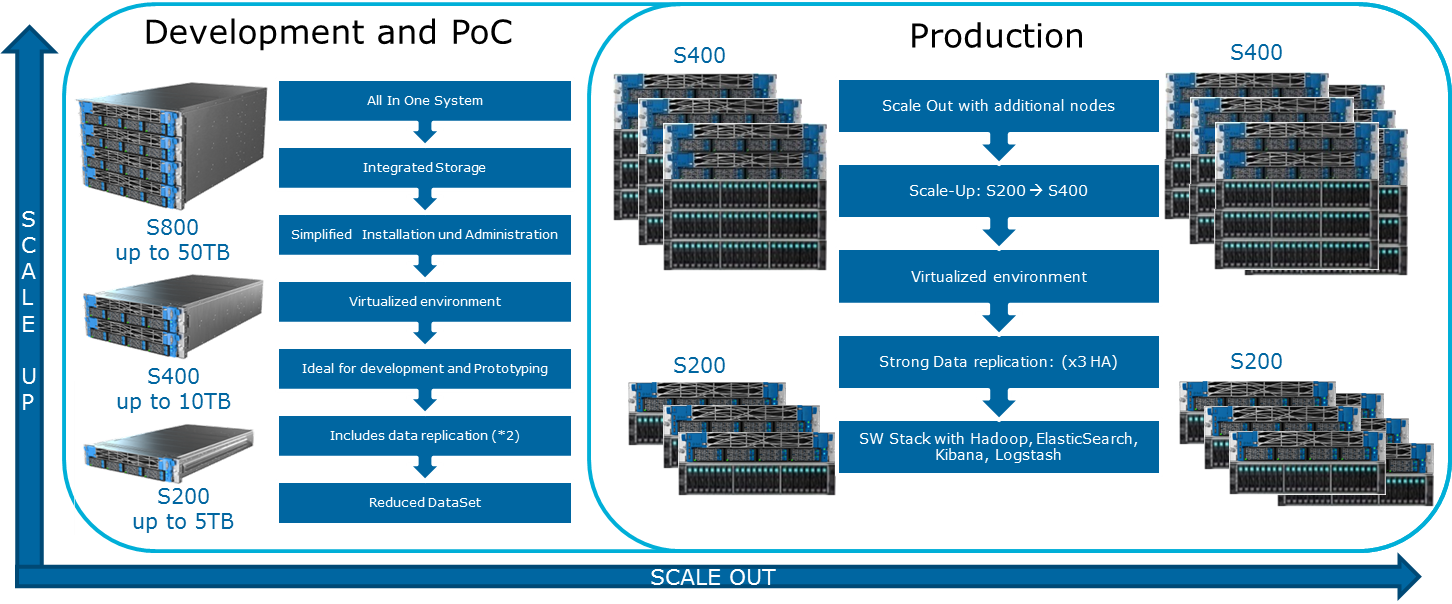
Cloudera erwähnt auf seiner Website verschiedene mögliche Konfigurationen. Die allgemeinen Prinzipien, nach denen sie aufgebaut sind, sind in der Abbildung dargestellt:
Um dieses optimistische Bild zu schmieren, kann MapReduce. Wenn Sie sich das Diagramm aus dem vorherigen Abschnitt noch einmal ansehen, wird deutlich, dass der MapReduce-Job in fast allen Fällen beim Lesen von Daten von der Festplatte oder vom Netzwerk auf einen Engpass stoßen kann. Dies wird auch im Cloudera-Blog vorgestellt. Daher ist für schnelle Berechnungen, einschließlich über Spark, das häufig für Echtzeitberechnungen verwendet wird, die E / A-Geschwindigkeit sehr wichtig. Daher ist es bei der Verwendung von Hadoop sehr wichtig, dass ausgewogene und schnelle Maschinen in den Cluster gelangen, der, gelinde gesagt, nicht immer in der Cloud-Infrastruktur bereitgestellt wird.
Ein ausgeglichener Lastausgleich wird durch die Verwendung der Openstack-Virtualisierung auf Servern mit leistungsstarken Multi-Core-CPUs erreicht. Datenknoten werden ihre Prozessorressourcen und bestimmte Festplatten zugewiesen. In unserer
Atos Codex Data Lake Engine- Lösung wird eine umfassende Virtualisierung erreicht, weshalb wir sowohl bei der Leistung (der Einfluss der Netzwerkinfrastruktur wird minimiert) als auch bei den Gesamtbetriebskosten (unnötige physische Server werden eliminiert) gewinnen.
Bei Verwendung von BullSequana S200-Servern erhalten wir eine sehr gleichmäßige Auslastung ohne einige Engpässe. Die Mindestkonfiguration umfasst 3 BullSequana S200-Server mit jeweils zwei JBODs sowie optionale zusätzliche S200s mit vier Datenknoten, die optional verbunden sind. Hier ist eine Beispiellast im TeraGen-Test:
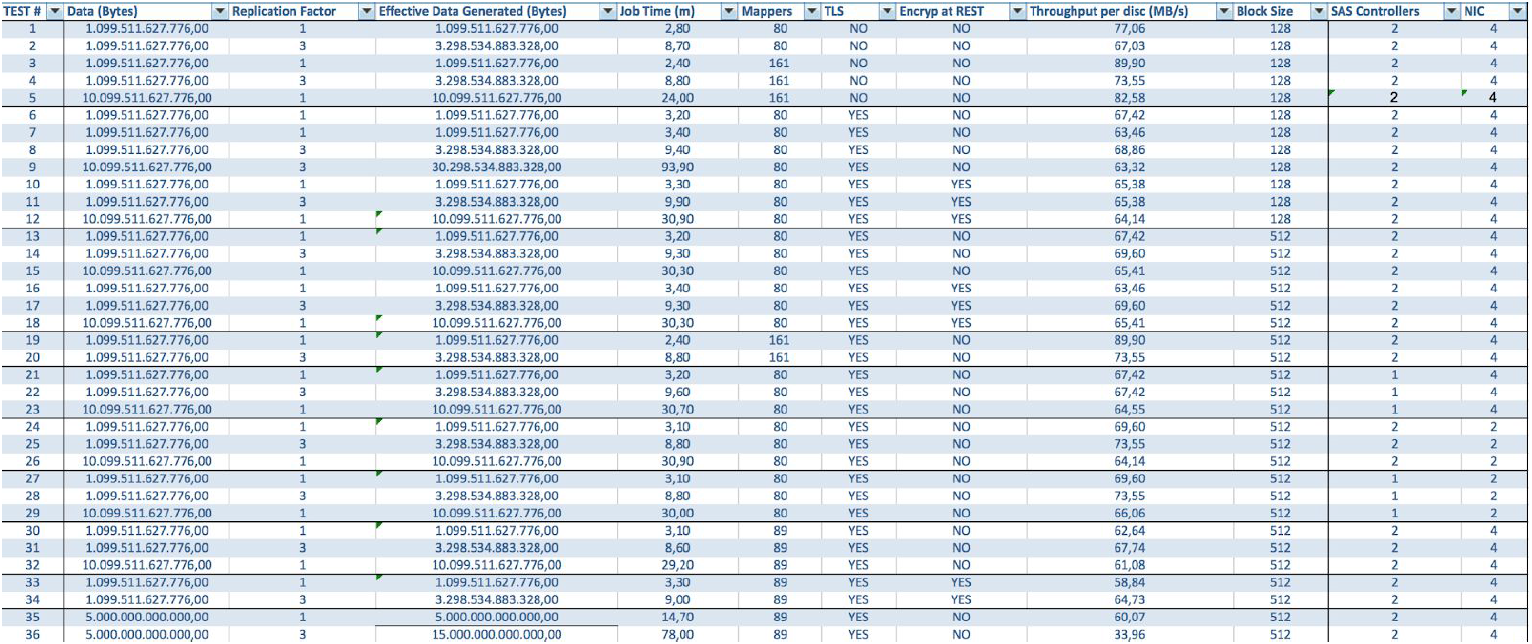
Tests mit unterschiedlichen Datenmengen und Replikationswerten zeigen dieselben Ergebnisse hinsichtlich des Lastausgleichs zwischen Clusterknoten. Unten finden Sie eine grafische Darstellung der Verteilung des Festplattenzugriffs nach Leistungstests.
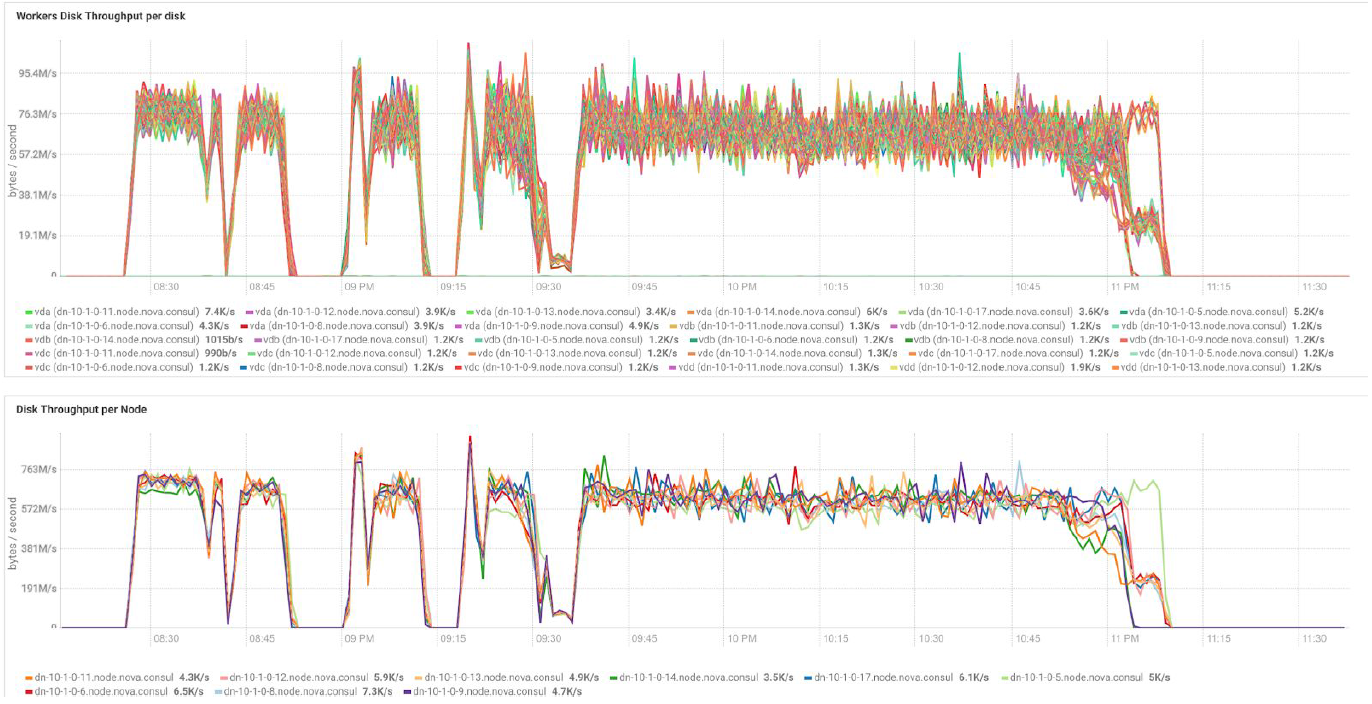
Die Berechnungen basieren auf der Mindestkonfiguration von 3 BullSequana S200-Servern. Es enthält 9 Datenknoten und 3 Hauptknoten sowie reservierte virtuelle Maschinen für den Fall, dass ein auf OpenStack Virtualization basierender Schutz bereitgestellt wird. TeraSort-Testergebnis: Die Blockgröße von 512 MB des Replikationskoeffizienten von drei mit Verschlüsselung beträgt 23,1 Minuten.
Wie kann ich das System erweitern? Für die Data Lake Engine stehen verschiedene Arten von Erweiterungen zur Verfügung:
- Datenknoten: Für jeweils 40 TB nutzbaren Speicherplatz
- Analytische Knoten mit der Möglichkeit, eine GPU zu installieren
- Andere Optionen, abhängig von den Anforderungen des Unternehmens (z. B. wenn Sie Kafka und dergleichen benötigen)
Atos Codex Data Lake Engine enthält sowohl die Server selbst als auch vorinstallierte Software, einschließlich einer lizenzierten Cloudera-Suite. Hadoop selbst, OpenStack mit virtuellen Maschinen, die auf dem RedHat Enterprise Linux-Kernel, einem Datenreplikationssystem und einer Sicherung basieren (einschließlich der Verwendung des Sicherungsknotens und von Cloudera BDR - Sicherung und Notfallwiederherstellung). Die Atos Codex Data Lake Engine war die erste von
Cloudera zertifizierte Virtualisierungslösung.
Wenn Sie an den Details interessiert sind, beantworten wir gerne unsere Fragen in den Kommentaren.