
Hallo Habr! Die Beschreibung des Betriebs der Innenseiten einer großen Zahlungsplattform wird logischerweise mit einer Beschreibung fortgesetzt, wie genau all diese Komponenten in der realen Welt auf physischer Hardware funktionieren. In diesem Beitrag spreche ich darüber, wie und wo sich die Anwendungen der Plattform befinden, wie der Datenverkehr von außen sie erreicht, und ich werde auch das Schema eines Standard-Racks für uns mit Geräten beschreiben, die sich in einem unserer Rechenzentren befinden.
Ansätze und Einschränkungen

Eine der ersten Anforderungen, die wir vor der Entwicklung der Plattform formuliert haben, lautet: "Die Fähigkeit, Ressourcen linear zu berechnen, um die Verarbeitung einer beliebigen Anzahl von Transaktionen sicherzustellen."
Die klassischen Ansätze bezahlter Systeme, die von Marktteilnehmern verwendet werden, implizieren das Vorhandensein einer Obergrenze, wenn auch nach den Aussagen ziemlich hoch. Normalerweise klingt es so: "Unsere Verarbeitung kann 1000 Transaktionen pro Sekunde akzeptieren."
Dieser Ansatz passt nicht zu unseren Geschäftszielen und unserer Architektur. Wir wollen kein Limit haben. In der Tat wäre es seltsam, von Yandex oder Google die Aussage zu hören, dass "wir 1 Million Suchanfragen pro Sekunde verarbeiten können". Die Plattform sollte aufgrund der Architektur so viele Anforderungen verarbeiten, wie das Unternehmen derzeit benötigt. Dies ermöglicht es, vereinfacht gesagt, einen IT-Mitarbeiter mit einem Serverwagen zu schicken, den er in Racks installiert, mit dem Switch verbindet und verlässt. Und der Orchestrator der Plattform wird Kopien von Geschäftsanwendungsinstanzen mit neuen Kapazitäten bereitstellen, wodurch wir die RPS-Erhöhung erhalten, die wir benötigen.
Die zweite wichtige Anforderung besteht darin, die hohe Verfügbarkeit der angebotenen Dienste sicherzustellen. Es wäre lustig, aber nicht zu nützlich, eine Zahlungsplattform zu erstellen, die eine unendliche Anzahl von Zahlungen in / dev / null akzeptieren kann.
Der wahrscheinlich effektivste Weg, um eine hohe Verfügbarkeit zu erreichen, besteht darin, die Entitäten, die den Dienst bedienen, mehrmals zu duplizieren, damit der Ausfall einer angemessenen Anzahl von Anwendungen, Geräten oder Rechenzentren die Gesamtverfügbarkeit der Plattform nicht beeinträchtigt.
Die mehrfache Vervielfältigung von Anwendungen erfordert eine große Anzahl physischer Server und zugehöriger Netzwerkgeräte. Dieses Eisen kostet Geld, dessen Menge wir natürlich haben, wir können es uns nicht leisten, viel teures Eisen zu kaufen. Daher ist die Plattform so konzipiert, dass sie auf einer großen Menge kostengünstigen und nicht zu leistungsstarken Eisens oder sogar in einer öffentlichen Cloud problemlos Platz findet und sich gut anfühlt.
Die Verwendung von Servern, die hinsichtlich der Rechenleistung nicht die stärksten sind, hat ihre Vorteile - ihr Ausfall hat keine kritischen Auswirkungen auf den allgemeinen Zustand des Gesamtsystems. Stellen Sie sich vor, was besser ist - wenn ein teurer, großer und äußerst zuverlässiger Markenserver ausfällt und ein DBMS nach dem Master-Slave-Schema (und nach Murphys Gesetz wird es sicherlich am Abend des 31. Dezember ausbrennt) oder ein paar Server in einem Cluster von 30 Knoten nach Masterless ausgeführt werden Diagramm?
Basierend auf dieser Logik haben wir beschlossen, keinen weiteren massiven Fehlerpunkt in Form eines zentralisierten Festplattenarrays zu erstellen. Gemeinsame Blockgeräte werden uns vom Ceph-Cluster zur Verfügung gestellt, der hyperkonvergent auf denselben Servern bereitgestellt wird, jedoch über eine separate Netzwerkinfrastruktur verfügt.
So kamen wir logischerweise zum allgemeinen Schema eines universellen Racks mit Rechenressourcen in Form von kostengünstigen und nicht sehr leistungsfähigen Servern im Rechenzentrum. Wenn wir mehr Ressourcen benötigen, beenden wir entweder ein freies Rack mit Servern oder stellen ein anderes, vorzugsweise näher.

Nun, am Ende ist es einfach wunderschön. Wenn eine klare Menge des gleichen Eisens in den Gestellen installiert ist, können Sie Probleme mit der hochwertigen Verlegung der Drahtfarm lösen, Schwalbennester loswerden und die Gefahr, sich in Drähten zu verfangen und die Verarbeitung fallen zu lassen. Aus technischer Sicht sollte das System überall schön sein - sowohl von innen in Form von Code als auch von außen in Form von Servern und Netzwerkhardware. Ein schönes System funktioniert besser und zuverlässiger. Ich hatte genug Beispiele, um dies aus eigener Erfahrung zu überprüfen.
Bitte denken Sie nicht, dass wir Gauner sind oder dass das Geschäft durch die Finanzierung eingeschränkt wird. Die Entwicklung und Pflege einer verteilten Plattform ist eigentlich ein sehr teures Vergnügen. Dies ist sogar noch teurer als der Besitz eines klassischen Systems, das unter bestimmten Bedingungen auf einer leistungsstarken Markenhardware mit Oracle / MSSQL, Anwendungsservern und anderen Bindungen basiert.
Unser Ansatz zahlt sich durch hohe Zuverlässigkeit, sehr flexible horizontale Skalierungsfunktionen, fehlende Obergrenze für die Anzahl der Zahlungen pro Sekunde und egal wie seltsam es sich anhört aus - eine Menge Spaß für das IT-Team. Für mich ist die Freude der Entwickler und Entwickler an dem von ihnen erstellten System nicht weniger wichtig als die vorhergesagte Entwicklungszeit, die Quantität und Qualität der eingeführten Funktionen.
Serverinfrastruktur

Logischerweise können unsere Serverkapazitäten in zwei Hauptklassen unterteilt werden: Server für Hypervisoren, für die die Dichte der CPU- und RAM-Kerne pro Einheit wichtig ist, und Speicherserver, bei denen der Schwerpunkt auf dem Speicherplatz pro Einheit liegt und für die CPU und RAM bereits ausgewählt sind Anzahl der Festplatten.
Im Moment sieht unser klassischer Server für Rechenleistung folgendermaßen aus:
- 2xXeon E5-2630 CPU;
- 128 G RAM;
- 3xSATA SSD (Ceph SSD Pool);
- 1xNVMe SSD (dm-Cache).
Server zum Speichern von Status:
- 1xXeon E5-2630 CPU;
- 12-16 Festplatte;
- 2 SSDs für block.db;
- 32G RAM.
Netzwerkinfrastruktur
Bei der Wahl der Netzwerkhardware ist unser Ansatz etwas anders. Für das Wechseln und Routing zwischen vlans verwenden wir weiterhin Marken-Switches. Jetzt handelt es sich um Cisco SG500X-48 und Cisco Nexus C5020 in SAN.
Physisch ist jeder Server über 4 physische Ports mit dem Netzwerk verbunden:
- 2x1GbE - Verwaltungsnetzwerk und RPC zwischen Anwendungen;
- 2x10GbE - Netzwerk zur Speicherung.
Die Schnittstellen innerhalb der Maschinen werden durch Verbinden kombiniert, dann divergiert der markierte Verkehr entsprechend dem gewünschten VLAN.
Vielleicht ist dies der einzige Ort in unserer Infrastruktur, an dem Sie das Etikett eines berühmten Anbieters sehen können. Weil wir für Routing, Netzwerkfilterung und Verkehrsinspektion Linux-Hosts verwenden. Wir kaufen keine spezialisierten Router. Alles, was wir brauchen, konfigurieren wir auf Servern, auf denen Gentoo ausgeführt wird (iptables zum Filtern, BIRD für dynamisches Routing, Suricata als IDS / IPS, Wallarm als WAF).
Typisches Rack in DC
Beim Skalieren unterscheiden sich Racks in DCs praktisch nicht voneinander, mit Ausnahme von Uplink-Routern, die in einem von ihnen installiert sind.
Die genauen Anteile von Servern verschiedener Klassen können variieren, aber im Allgemeinen bleibt die Logik erhalten - es gibt mehr Server zum Rechnen als Server zum Speichern von Daten.
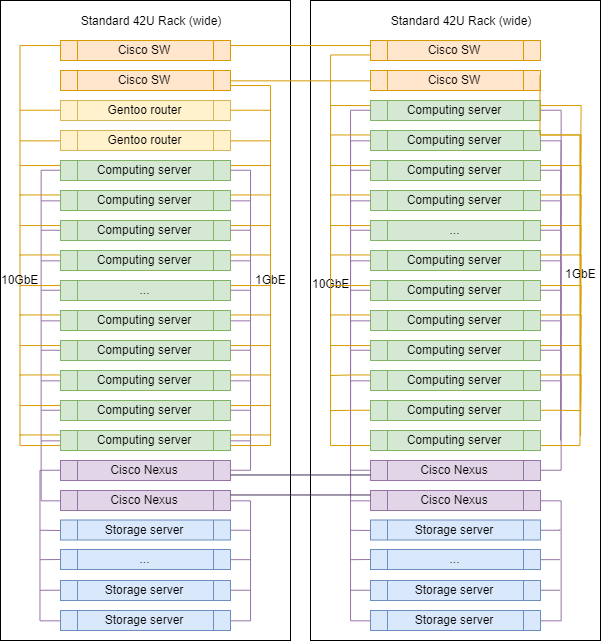
Blockieren Sie Geräte und teilen Sie Ressourcen
Versuchen wir, alles zusammenzusetzen. Stellen Sie sich vor, wir müssen mehrere unserer Mikrodienste in der Infrastruktur platzieren. Zur besseren Übersichtlichkeit sind dies Mikrodienste, die über RPC miteinander kommunizieren müssen. Eines davon ist Machinegun, das den Status im Riak-Cluster speichert, sowie einige Hilfsdienste wie z wie ES- und Consul-Knoten.
Ein typisches Layout würde folgendermaßen aussehen:
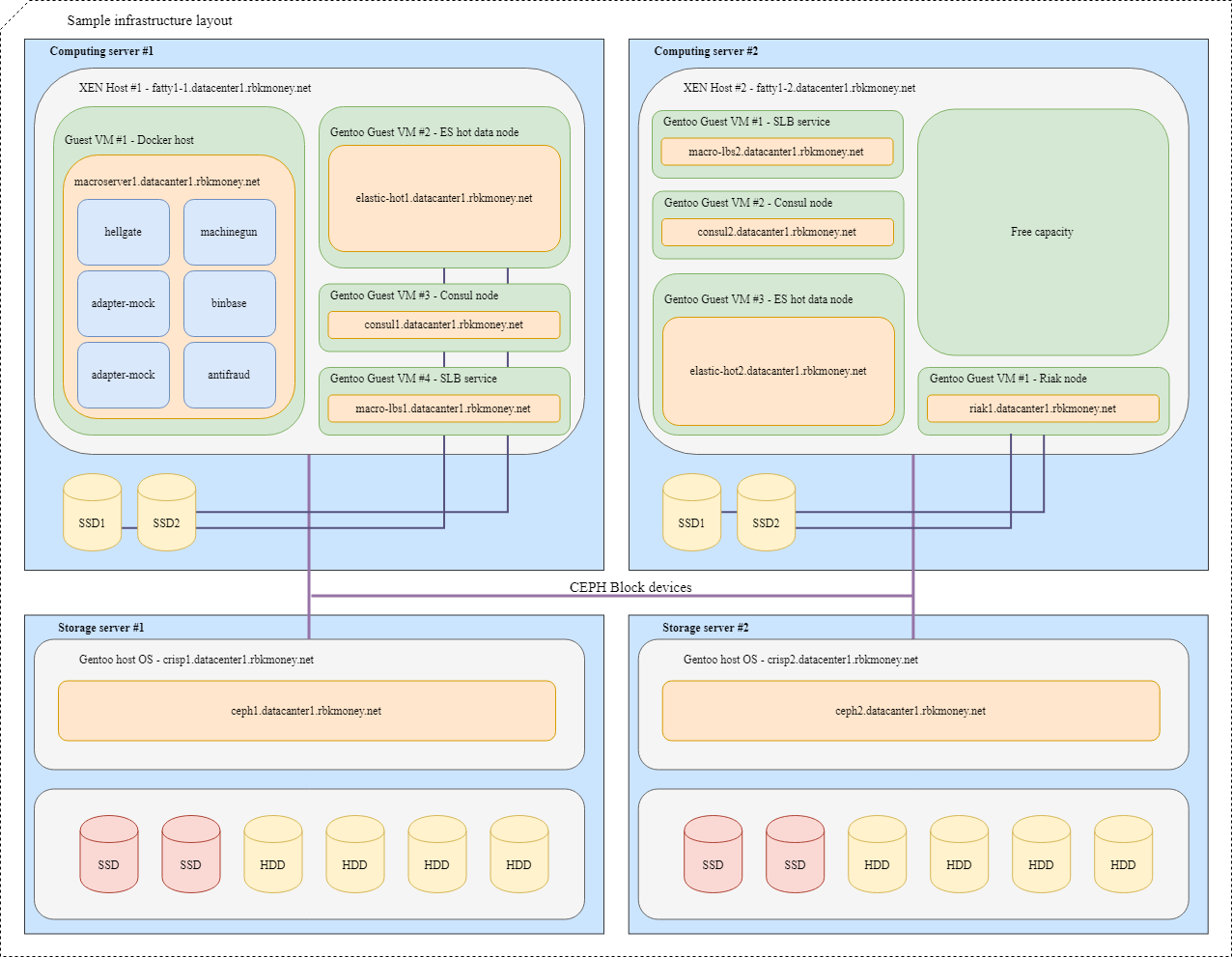
Für VMs mit Anwendungen, die die maximale Geschwindigkeit eines Blockgeräts erfordern, wie z. B. Riak- und Hot Elasticsearch-Knoten, werden Partitionen auf lokalen NVMe-Festplatten verwendet. Solche VMs sind eng mit ihrem Hypervisor verbunden, und die Anwendungen selbst sind für die Verfügbarkeit und Integrität ihrer Daten verantwortlich.
Für gängige Blockgeräte verwenden wir Ceph RBD, normalerweise mit durchschreibbarem dm-Cache auf der lokalen NVMe-Festplatte. Das OSD für das Gerät kann je nach gewünschter Antwortzeit entweder Vollblitz oder Festplatte mit SSD-Protokoll sein.
Übermittlung von Datenverkehr an Anwendungen
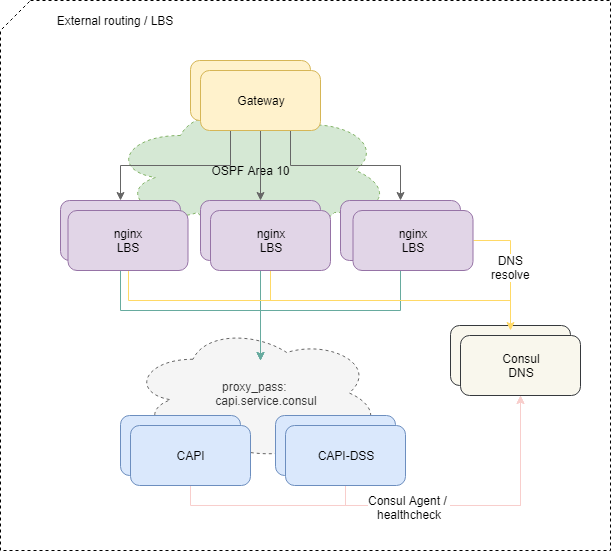
Um Anfragen von außen auszugleichen, verwenden wir das Standard-OSPFv3-ECMP-Schema. Kleine virtuelle Maschinen mit Nginx, Bird, Consul kündigen in der OSPF-Cloud gemeinsame Anycast-Adressen von der lo-Schnittstelle an. Auf Routern erstellt Bird für diese Adressen Multi-Hop-Routen, die einen Ausgleich pro Fluss ermöglichen, wobei der Fluss "src-ip src-port dst-ip dst-port" ist. Um den fehlenden Balancer schnell zu deaktivieren, wird das BFD-Protokoll verwendet.
Wenn einer der Balancer hinzugefügt wird oder ausfällt, erhalten Upstream-Router die entsprechende Route oder löschen sie, und der Netzwerkverkehr wird gemäß den kostengünstigen Multi-Path-Ansätzen an sie geliefert. Und wenn wir nicht speziell eingreifen, wird der gesamte Netzwerkverkehr gleichmäßig auf alle verfügbaren Balancer über jeden IP-Stream verteilt.
Übrigens weist der Ansatz mit ECMP-Balancing nicht offensichtliche Fallstricke auf , die zu völlig nicht offensichtlichen Verlusten von Datenverkehr führen können, insbesondere wenn sich andere Router oder seltsam konfigurierte Firewalls auf der Route zwischen den Systemen befinden.
Um das Problem zu lösen, verwenden wir den PMTUD-Daemon in diesem Teil der Infrastruktur.
Ferner wird der Datenverkehr innerhalb der Plattform gemäß der Nginx-Konfiguration auf den Balancern zu bestimmten Mikrodiensten geleitet.
Und wenn der Ausgleich des externen Datenverkehrs mehr oder weniger einfach und verständlich ist, wäre es schwierig, ein solches Schema weiter nach innen auszudehnen - wir müssen mehr als nur die Verfügbarkeit eines Containers mit einem Mikrodienst auf Netzwerkebene überprüfen.
Damit der Microservice Anfragen empfangen und verarbeiten kann, muss er sich bei Service Discovery registrieren (wir verwenden Consul ), sich jede Sekunde einer Integritätsprüfung unterziehen und über eine angemessene RTT verfügen.
Wenn sich der Mikrodienst gut anfühlt und verhält, beginnt Consul, die Adresse seines Containers aufzulösen, wenn er unter dem Namen des Dienstes auf sein DNS zugreift. Wir verwenden die interne Zone service.consul , und beispielsweise wird der Microservice der Common API Version 2 den Namen capi-v2.service.consul .
Die Nginx-Konfiguration bezüglich des Balancierens am Ende sieht folgendermaßen aus:
location = /v2/ { set $service_hostname "${staging_pass}capi-v2.service.consul"; proxy_pass http://$service_hostname:8022; }
Wenn wir also nicht erneut absichtlich eingreifen, wird der Datenverkehr von den Balancern gleichmäßig auf alle in Service Discovery registrierten Mikrodienste verteilt. Das Hinzufügen oder Entfernen neuer Instanzen der erforderlichen Mikrodienste wird vollständig automatisiert.
Wenn die Anfrage vom Balancer vorgelagert wurde und er unterwegs gestorben ist, geben wir 502 zurück - der Balancer auf seiner Ebene kann nicht feststellen, ob die Anfrage idempotent war oder nicht, daher geben wir die Verarbeitung solcher Fehler einer höheren Logikstufe.
Idempotenz und Fristen
Im Allgemeinen haben wir keine Angst und zögern nicht, 5xx-Fehler mit der API zu machen. Dies ist ein normaler Teil des Systems, wenn Sie die korrekte Verarbeitung solcher Fehler auf der Ebene der RPC-Geschäftslogik vornehmen. Die Prinzipien dieser Verarbeitung werden in unserem Formular als kleines Handbuch mit der Bezeichnung "Fehlerwiederholungsrichtlinie" beschrieben. Wir verteilen es an unsere Händlerkunden und implementieren es in unseren Diensten.
Um diese Verarbeitung zu vereinfachen, haben wir verschiedene Ansätze implementiert.
Erstens können Sie für alle Statusänderungsanforderungen an unsere API einen eindeutigen Idempotenzschlüssel innerhalb des Kontos angeben, der für immer gültig ist und Ihnen die Gewissheit gibt, dass ein wiederholter Anruf mit demselben Datensatz dieselbe Antwort zurückgibt.
Zweitens haben wir einen zusätzlichen Mechanismus in Form einer eindeutigen Kennung für die Zahlungssitzung implementiert, der die Idempotenz von Belastungsanfragen garantiert und Schutz vor fehlerhaften wiederholten Belastungen bietet, auch wenn Sie keinen separaten Idempotenzschlüssel generieren und übertragen.
Drittens haben wir beschlossen, eine vorhersehbare und extern gesteuerte Antwortzeit auf jeden externen Aufruf unserer API in Form eines Zeitbegrenzungsparameters zu aktivieren, der die maximale Wartezeit für den Abschluss eines Vorgangs auf Anfrage bestimmt. Es reicht aus, zum Beispiel den HTTP-Header X-Request-Deadline: 10s zu übertragen, um sicherzustellen, dass Ihre Anfrage innerhalb von 10 Sekunden ausgeführt wird oder von der Plattform irgendwo im Inneren getötet wird. Danach können wir erneut kontaktiert werden Weiterleitungsrichtlinie anfordern.
Wir verwenden SaltStack als Management-Tool sowohl für Konfigurationen als auch für die gesamte Infrastruktur. Separate Tools zur automatisierten Steuerung der Rechenleistung der Plattform sind noch nicht verfügbar, obwohl wir bereits verstehen, dass wir diesen Weg gehen werden. Mit unserer Liebe zu Hashicorp- Produkten ist dies wahrscheinlich Nomad.
Die wichtigsten Tools zur Überwachung der Infrastruktur sind Überprüfungen in Nagios. Für Geschäftseinheiten konfigurieren wir jedoch hauptsächlich Warnungen in Grafana. Es verfügt über ein sehr praktisches Tool zum Festlegen von Bedingungen. Mit einem ereignisbasierten Plattformmodell können Sie alles in Elasticsearch schreiben und die Auswahlbedingungen konfigurieren.
Rechenzentren befinden sich in Moskau. In diesen vermieten wir Rack-Räume, installieren und verwalten alle Geräte unabhängig voneinander. Wir verwenden nirgendwo dunkle Optiken, wir haben das Internet nur außerhalb von lokalen Anbietern.
Ansonsten sind unsere Ansätze zur Überwachung, Verwaltung und damit verbundenen Dienstleistungen für die Branche eher Standard. Ich bin mir nicht sicher, ob die nächste Beschreibung der Integration dieser Dienstleistungen in einem Beitrag erwähnenswert ist.
In diesem Artikel werde ich wahrscheinlich die Reihe von Überprüfungsbeiträgen über die Anordnung unserer Zahlungsplattform beenden.
Ich glaube, dass sich der Zyklus als ziemlich offen herausgestellt hat. Ich habe nur wenige Artikel getroffen, die die innere Küche großer Zahlungssysteme so detailliert enthüllen würden.
Generell ist meiner Meinung nach ein hohes Maß an Offenheit und Offenheit eine sehr wichtige Sache für das Zahlungssystem. Dieser Ansatz erhöht nicht nur das Vertrauen der Partner und Zahler, sondern diszipliniert auch das Team, die Ersteller und Betreiber des Dienstes.
Ausgehend von diesem Prinzip haben wir kürzlich den Status der Plattform und den Betriebsverlauf unserer Dienste öffentlich zugänglich gemacht. Der gesamte nachfolgende Verlauf unserer Verfügbarkeit, Aktualisierungen und Abstürze ist jetzt öffentlich und unter https://status.rbk.money/ verfügbar.
Ich hoffe, Sie waren interessiert, und vielleicht findet jemand unsere Ansätze und die beschriebenen Fehler hilfreich. Wenn Sie an einem der in den Beiträgen beschriebenen Bereiche interessiert sind und möchten, dass ich sie ausführlicher offenlege, zögern Sie bitte nicht, in den Kommentaren oder in PM zu schreiben.
Danke, dass Sie bei uns sind!

PS Für Ihre Bequemlichkeit ein Verweis auf die vorherigen Artikel in der Reihe: